数据的读取
读取 数据文件,得到 DataFrame(pandas 中存储表格数据的核心结构)。
读取csv文件
python
import pandas as pd
# 方式1:加 r 用原始字符串(最推荐)
# r 是 raw string(原始字符串)的标识,告诉 Python忽略转义字符
data1 = pd.read_csv(r'E:\Code\data.csv')
# 方式2:用双反斜杠转义(手动把 \ 转成普通字符)
data2 = pd.read_csv('E:\\Code\\data.csv')
# 方式3:用正斜杠(Python跨平台支持,Windows也能用)
data3 = pd.read_csv('E:/Code/data.csv')读取excel文件
python
# pandas读取excel需要安装openpyxl库,去anaconda prompt中安装
!pip install openpyxl # 加英文输入法下的感叹号,可以在jupyter中直接下载
data =pd.read_excel('E:\Code\data.xlsx')【补充说明】文件路径可以是绝对路径,也可以是相对路径。这里示例的是绝对路径
数据的查看
一、快速概览:看数据的「基本轮廓」
这类函数能让你快速知道数据有多少行、多少列、长什么样。
data.head(n):查看前 n 行数据(默认前 5 行)
data.tail(n):查看后 n 行数据(默认后 5 行)
data.shape:查看数据的行数和列数 # 输出示例:(1000, 8) 表示1000行8列
data.columns:查看所有列名 # 输出列名列表,如 Index('姓名', '年龄', '薪资', dtype='object')
二、详细信息:看数据的「结构和类型」
这类函数能帮你了解数据类型、非空值数量等关键信息。
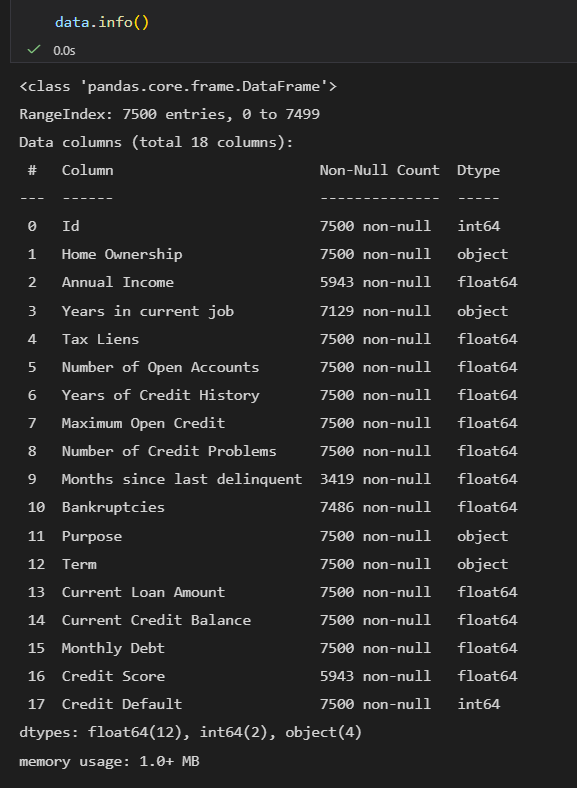
data.info():查看数据的详细结构(最核心)
显示列名、数据类型(int/float/object 等)、非空值数量、内存占用,是排查数据缺失的第一步。
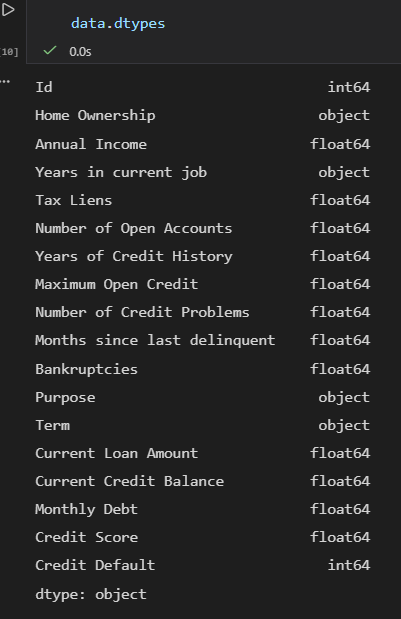
data.dtypes:查看每列的数据类型
单独查看数据类型,比 info() 更简洁,适合快速核对(比如薪资是否应为数值型)。
三、统计信息:看数据的「数值特征」
这类函数主要针对数值型列(int/float),展示统计指标。
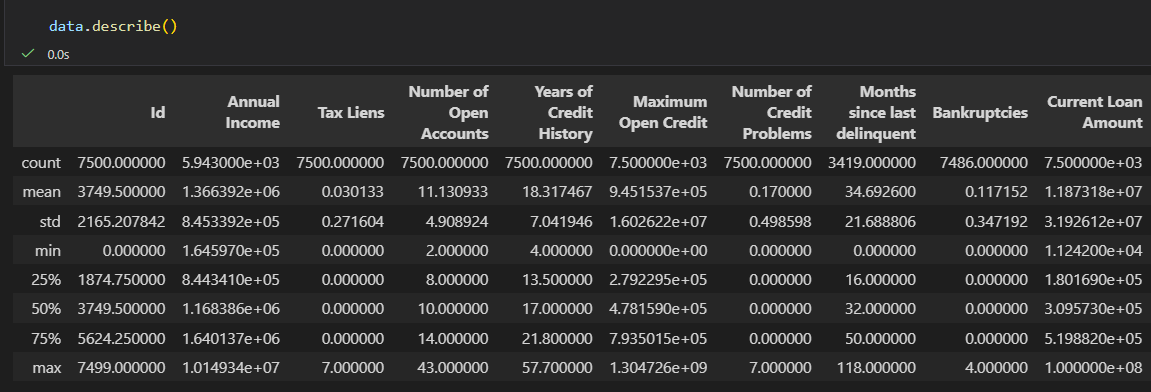
data.describe():查看数值列的统计摘要
返回计数、均值、标准差、最小值、四分位数、最大值,快速了解数值分布。
data.mean()/data.median()/data.max()/data.min():单独查看均值 / 中位数 / 最大值 / 最小值
四、数据质量:检查缺失值 / 重复值
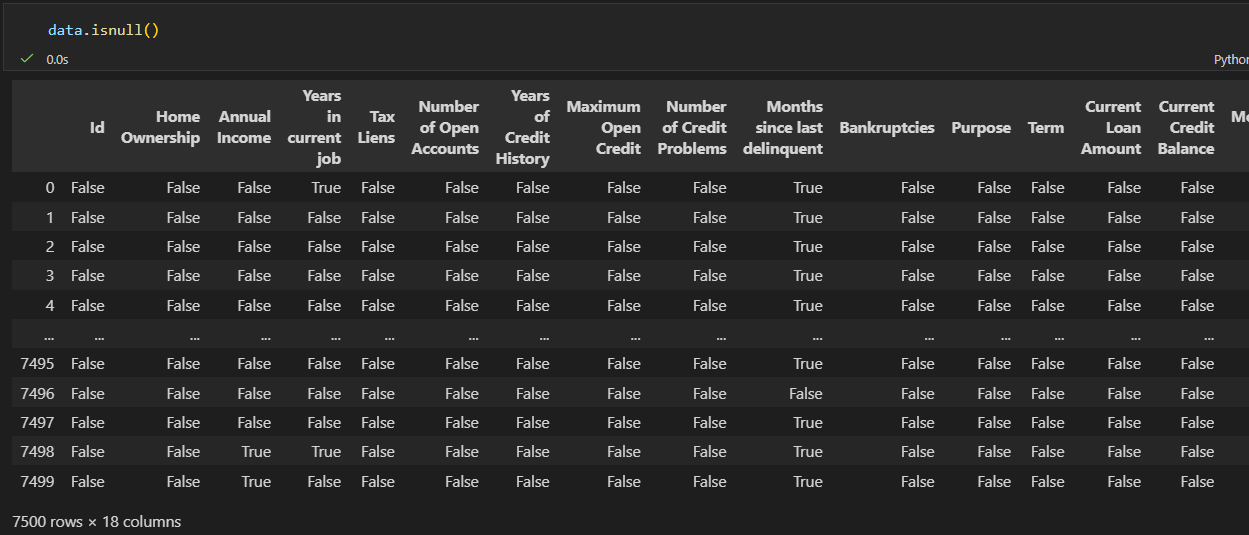
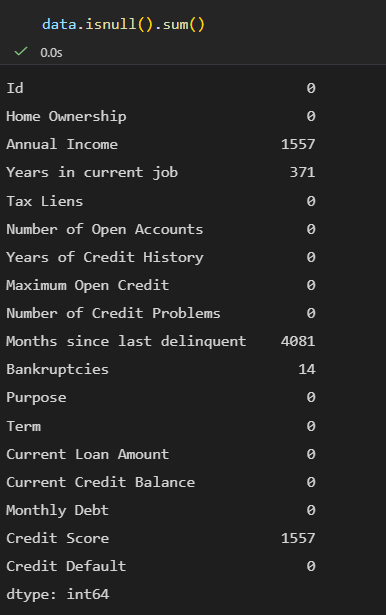
data.isnull():查看每个单元格是否为缺失值
返回和原数据同形状的布尔值 DataFrame,配合 sum() 可统计每列缺失值数量。
【补充说明】布尔值的本质是数值型,True = 1,False = 0
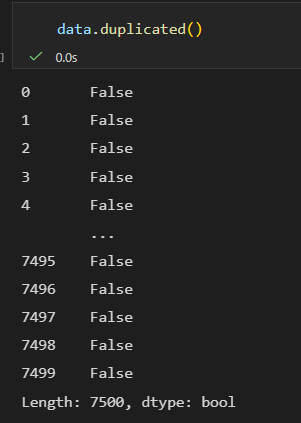
data.duplicated():查看重复行
返回布尔值 Series(True = 重复行),配合 sum() 可统计重复行数量
总结:
- 快速预览 :用
head()/tail()看数据内容,shape看规模,columns看列名;- 结构检查 :用
info()看数据类型和缺失值(最核心),dtypes单独看类型;- 数值分析 :用
describe()看数值列统计特征,mean()/max()等看单一指标;- 质量检查 :用
isnull().sum()查缺失值,duplicated().sum()查重复值。
小练习
按照示例代码的要求,去尝试补全信贷数据集中的数值型缺失值
- 打开数据(csv文件、excel文件)
- 查看数据(尺寸信息、查看列名等方法)
- 查看空值
- 众数、中位数填补空值
- 利用循环补全所有列的空值
python
# 1.读取数据
import pandas as pd
data = pd.read_csv(r'E:\Code\Pythonfuxi\data.csv')
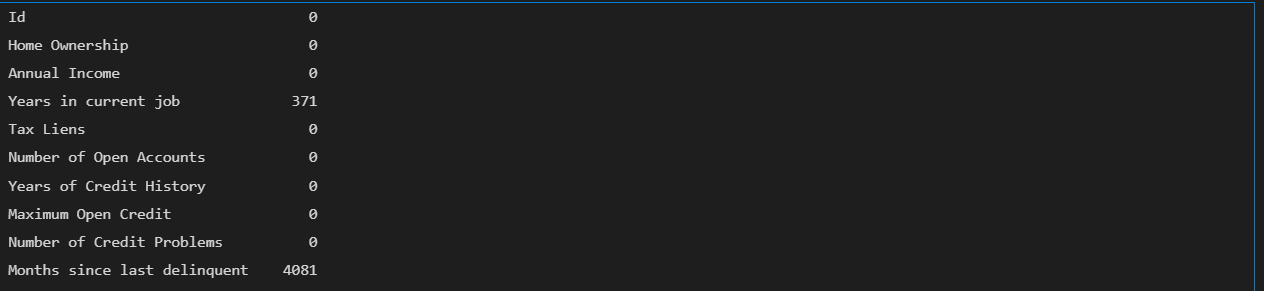
# 2.查看空值
data.isnull().sum()输出结果:
中位数填补缺失值
python
# 4.用中位数进行填补 Annual Income缺失值
median_income = data['Annual Income'].median() # 计算'Annual Income' 列的中位数
data['Annual Income'].fillna(median_income, inplace=True) # 填充inplace=True 参数表示直接在原 DataFrame 上进行修改
如果不设置该参数,fillna() 方法会返回一个新的 DataFrame,原 DataFrame 不会被修改
python
# 检查下是还存在缺失值
data['Annual Income'].isnull().sum()输出结果:
填补所有的 数值型缺失值
写法1:
python
# 获取所有列的列名
c = data.columns.tolist()
# 循环遍历c这个列表中的每一列
for i in c:
# 找到为数值型的列
if data[i].dtype != 'object': # 找到为数值型的列
if data[i].isnull().sum() > 0: # 找到存在缺失值的列
#计算该列的均值
mean_value = data[i].mean()
#用均值填充缺失值
data[i].fillna(mean_value, inplace=True)
# 检验
data.isnull().sum()写法2:
python
print("\n=== 处理数值列缺失值 ===")
# 从data中筛选出所有「数值型」的列,并把这些列的列名保存到 numeric_cols 这个变量中。
numeric_cols = data.select_dtypes(include=['number']).columns
for col in numeric_cols:
if data[col].isnull().sum() > 0:
mean_val = data[col].mean()
data[col].fillna(mean_val, inplace=True)
print(f"{col} 已用均值 {mean_val:.2f} 填补")
print("\n=== 处理后缺失情况 ===")
print(data.isnull().sum())data.select_dtypes(include=['number']):筛选数值型列的 DataFrame
select_dtypes() ,作用是根据列的数据类型筛选列,执行后会返回一个新的 DataFram
参数 include=['number']:指定要保留的类型,'number' 是 pandas 中对「所有数值类型」的统一指代,包括:
- 整数型(
int64/int32) - 浮点型(
float64/float32) - 布尔型(
bool,pandas 也归为数值类)