本系列介绍增强现代智能体系统可靠性的设计模式,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。本系列一共 14 篇文章,这是第 12 篇。原文:Building the 14 Key Pillars of Agentic AI
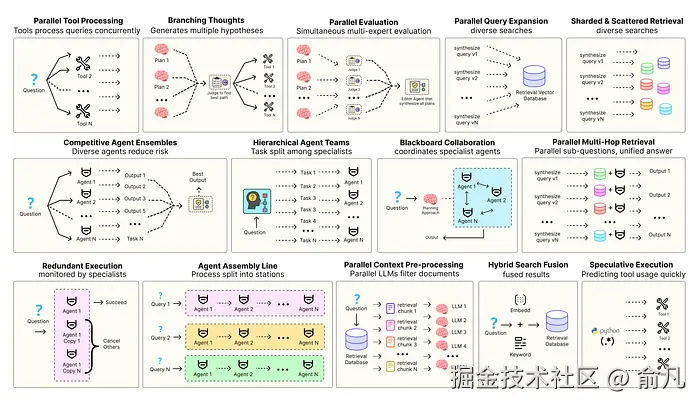
优化智能体解决方案需要软件工程确保组件协调、并行运行并与系统高效交互。例如预测执行,会尝试处理可预测查询以降低时延 ,或者进行冗余执行,即对同一智能体重复执行多次以防单点故障。其他增强现代智能体系统可靠性的模式包括:
- 并行工具:智能体同时执行独立 API 调用以隐藏 I/O 时延。
- 层级智能体:管理者将任务拆分为由执行智能体处理的小步骤。
- 竞争性智能体组合:多个智能体提出答案,系统选出最佳。
- 冗余执行:即两个或多个智能体解决同一任务以检测错误并提高可靠性。
- 并行检索和混合检索:多种检索策略协同运行以提升上下文质量。
- 多跳检索:智能体通过迭代检索步骤收集更深入、更相关的信息。
还有很多其他模式。
本系列将实现最常用智能体模式背后的基础概念,以直观方式逐一介绍每个概念,拆解其目的,然后实现简单可行的版本,演示其如何融入现实世界的智能体系统。
所有理论和代码都在 GitHub 仓库里:🤖 Agentic Parallelism: A Practical Guide 🚀
代码库组织如下:
erlang
agentic-parallelism/
├── 01_parallel_tool_use.ipynb
├── 02_parallel_hypothesis.ipynb
...
├── 06_competitive_agent_ensembles.ipynb
├── 07_agent_assembly_line.ipynb
├── 08_decentralized_blackboard.ipynb
...
├── 13_parallel_context_preprocessing.ipynb
└── 14_parallel_multi_hop_retrieval.ipynb并行混合搜索融合用于高保真上下文
向量搜索(语义) 擅长理解查询的概念含义,但有时会漏掉包含特定、精确关键词的文档。关键词搜索(词法) 则非常适合查找精确术语,却无法理解概念关系。
并行混合搜索融合(Parallel Hybrid Search Fusion) 架构通过结合两种方法的优势,为我们提供了解决方案。
该架构同时执行向量搜索和关键词搜索,然后将其独特发现"融合"成单一、组合的结果集。
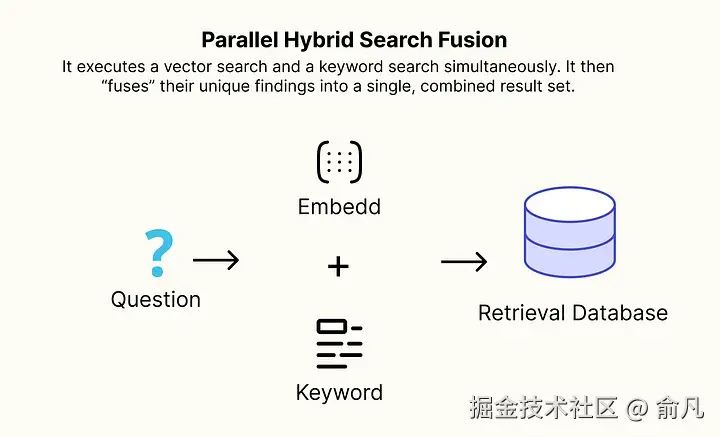
这种模式对任何处理混合文本和特定标识符(产品代码、错误消息、法律案件编号)的 RAG 系统都至关重要。
我们将构建并比较三个 RAG 系统:向量模式、关键词模式和混合模式,以展示混合方法如何检索更优的上下文并生成更完整、准确的最终答案。
首先构建两种不同的检索机制,我们从熟悉的向量搜索开始。
python
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import HuggingFaceEmbeddings
# 为语义搜索创建标准 FAISS 向量存储
vector_store = FAISS.from_documents(kb_docs, embedding=embeddings)
vector_retriever = vector_store.as_retriever(search_kwargs={"k": 2})这是标准的语义搜索引擎,由向量嵌入驱动,在理解查询的"核心内容"方面非常出色。
接下来利用 scikit-learn TfidfVectorizer 从头开始构建经典关键词检索器,作为基于词汇的搜索引擎。
python
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from typing import List
from langchain_core.documents import Document
class TfidfRetriever(BaseRetriever):
"""利用 TF-IDF 进行关键词搜索的自定义 LangChain 检索器"""
# 存储拟合的矢量器和原始文档
vectorizer: TfidfVectorizer
docs: List[Document]
k: int = 2
class Config:
arbitrary_types_allowed = True
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
# 将查询转换为 TF-IDF 向量
query_vec = self.vectorizer.transform([query])
# 获取所有文档的预计算 TF-IDF 向量
doc_vectors = self.vectorizer.transform([doc.page_content for doc in self.docs])
# 计算查询和文档之间的余弦相似度
similarities = cosine_similarity(query_vec, doc_vectors).flatten()
# 获取前 k 个最相似文档的索引
top_k_indices = np.argsort(similarities)[-self.k:][::-1]
# 返回对应的 Document 对象
return [self.docs[i] for i in top_k_indices]
# 在知识库内容上拟合 TF-IDF 矢量
vectorizer = TfidfVectorizer().fit([doc.page_content for doc in kb_docs])
# 创建自定义检索器实例
keyword_retriever = TfidfRetriever(vectorizer=vectorizer, docs=kb_docs, k=2)TfidfRetriever 是词汇检索专家,与向量检索器不同,它不理解含义,纯粹基于词频工作,查找包含用户查询中确切的、字面关键词的文档,无论关键词是否罕见或语义权重较低。
接下来构建混合 RAG 系统,其核心是 LangGraph 节点,并行运行两个检索器,然后融合结果。
python
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class HybridRAGState(TypedDict):
question: str
retrieved_docs: List[Document]
final_answer: str
def parallel_retrieval_node(state: HybridRAGState):
"""该模式的核心是:并行运行矢量和关键字搜索并融合结果"""
print("--- [Hybrid Retriever] Running Vector and Keyword searches in parallel... ---")
# 用同样的问题来调用这两个系统
# 由于其独立性,所以两个调用可以在真正的多线程系统中并发执行
vector_docs = vector_retriever.invoke(state['question'])
keyword_docs = keyword_retriever.invoke(state['question'])
# "融合"步骤:合并两个文档列表,对数据去重
all_docs = vector_docs + keyword_docs
unique_docs = list({doc.page_content: doc for doc in all_docs}.values())
print(f"--- [Hybrid Retriever] Fused results: Found {len(unique_docs)} unique documents. ---")
return {"retrieved_docs": unique_docs}
# 用生成节点组装完整的图
workflow = StateGraph(HybridRAGState)
workflow.add_node("parallel_retrieval", parallel_retrieval_node)
workflow.add_node("generate_answer", generation_node)
workflow.set_entry_point("parallel_retrieval")
workflow.add_edge("parallel_retrieval", "generate_answer")
workflow.add_edge("generate_answer", END)
hybrid_rag_app = workflow.compile()
parallel_retrieval_node 是进行融合的地方,运行 vector_retriever 和 keyword_retriever,然后组合它们的输出。简单的去重 list({doc.page_content: doc for doc in all_docs}.values()) 是一种基本但有效的融合策略,从而确保如果两个检索器找到相同的文档,就只保留一次,如果找到不同的文档,所有独特发现都会保留在最终上下文中。
最后进行直接对比分析,创建一个特定查询,旨在让单一搜索系统失效,包含一个高级语义概念("节能措施")和一个非常具体、罕见的关键词(ERR_THROTTLE_900)。要给出完整答案,需要结合两种搜索方法的优势才能找到信息。
python
# 查询包含概念部分和特定关键字部分
user_query = "What are our company's power saving efforts, and what is the error code for QLeap-V4 overheating?"
# --- 执行向量 RAG ---
vector_answer = rag_chain_vector.invoke(user_query)
# --- 执行关键词 RAG ---
keyword_answer = rag_chain_keyword.invoke(user_query)
# --- 执行混合 RAG ---
hybrid_answer = hybrid_result['final_answer']
# --- 最终分析 ---
print("\n" + "="*60)
print(" ACCURACY & QUALITY ANALYSIS")
print("="*60 + "\n")
print("The User's Goal: The user asked two distinct questions: 1. What are our power saving efforts? (A semantic question) and 2. What is the error code for overheating? (A specific/lexical question).\n")
print("-" * 60)
print("Vector-Only RAG Performance:")
print("- Result: FAILED to answer completely.")
print("- Final Answer:", vector_answer)
print("Keyword-Only RAG Performance:")
print("- Result: FAILED to answer completely.")
print("- Final Answer:", keyword_answer)
print("-" * 60)
print("Hybrid Search RAG Performance:")
print("- Final Answer:", hybrid_answer)最终结果是......
python
#### 输出 ####
============================================================
ACCURACY & QUALITY ANALYSIS
============================================================
The User Goal: The user asked two distinct questions: 1. What are our power saving efforts? (A semantic question) and 2. What is the error code for overheating? (A specific/lexical question).
------------------------------------------------------------
Vector-Only RAG Performance:
- Result: FAILED to answer completely.
- Final Answer: Based on the provided context, the company power saving effort is an initiative called Project 'Titan', which is focused on developing energy-efficient hardware to reduce power consumption in data centers and is part of the green computing strategy. The context does not contain information about an error code for QLeap-V4 overheating.
- Reason: It excelled at the semantic part, finding documents about 'Project Titan' by matching the concept of 'power saving efforts' to 'energy-efficient hardware'. However, the specific error code 'ERR_THROTTLE_900' was not semantically close enough to the query to be retrieved. The agent correctly stated it could not find the answer.
------------------------------------------------------------
Keyword-Only RAG Performance:
- Result: FAILED to answer completely.
- Final Answer: Based on the context, the error code for QLeap-V4 overheating is 'ERR_THROTTLE_900'. Project 'Titan' is an initiative to reduce power consumption.
- Reason: It excelled at the lexical part, perfectly matching the keyword 'ERR_THROTTLE_900' in the query to the document containing it. However, it missed the second, more conceptual document about 'Project Titan' being part of the 'green computing strategy' because the keywords didnt overlap strongly.
------------------------------------------------------------
Hybrid Search RAG Performance:
- Result: SUCCESS. Answered both parts of the question accurately.
- Final Answer: Our companys power saving effort is called Project 'Titan', which is a core part of our green computing strategy aimed at developing energy-efficient hardware to reduce data center power consumption. The official error code for QLeap-V4 overheating is 'ERR_THROTTLE_900'.
- Reason: The parallel execution and fusion step provided the best of both worlds. The vector search contributed the two documents about 'Project Titan', and the keyword search contributed the document with the specific error code. By combining these unique results into a single, rich context, the generator had all the information it needed to construct a complete and correct answer.最终分析对混合方法的优越性做出了明确判断。
- 仅使用向量和仅使用关键词的系统都产生了不完整、部分正确的答案,每个系统都只能看到问题的一部分。
- 向量搜索理解了"节能"的概念,但错过了错误代码的具体关键词。关键词搜索找到了错误代码,但错过了关于公司可持续发展战略的概念性文档。
- 混合搜索系统成功的原因在于它不是专家,而是由专家构建的通才,其并行的"分散-聚集"方法确保从两种检索方法中捕获了独特的发现。
- 融合步骤创建了包含所有必要事实的单一、全面的上下文,使最终的生成式代理能够轻松综合出完整且准确的答案,解决了用户复杂查询的两个部分。
Hi,我是俞凡,一名兼具技术深度与管理视野的技术管理者。曾就职于 Motorola,现任职于 Mavenir,多年带领技术团队,聚焦后端架构与云原生,持续关注 AI 等前沿方向,也关注人的成长,笃信持续学习的力量。在这里,我会分享技术实践与思考。欢迎关注公众号「DeepNoMind」,星标不迷路。也欢迎访问独立站 www.DeepNoMind.com,一起交流成长。