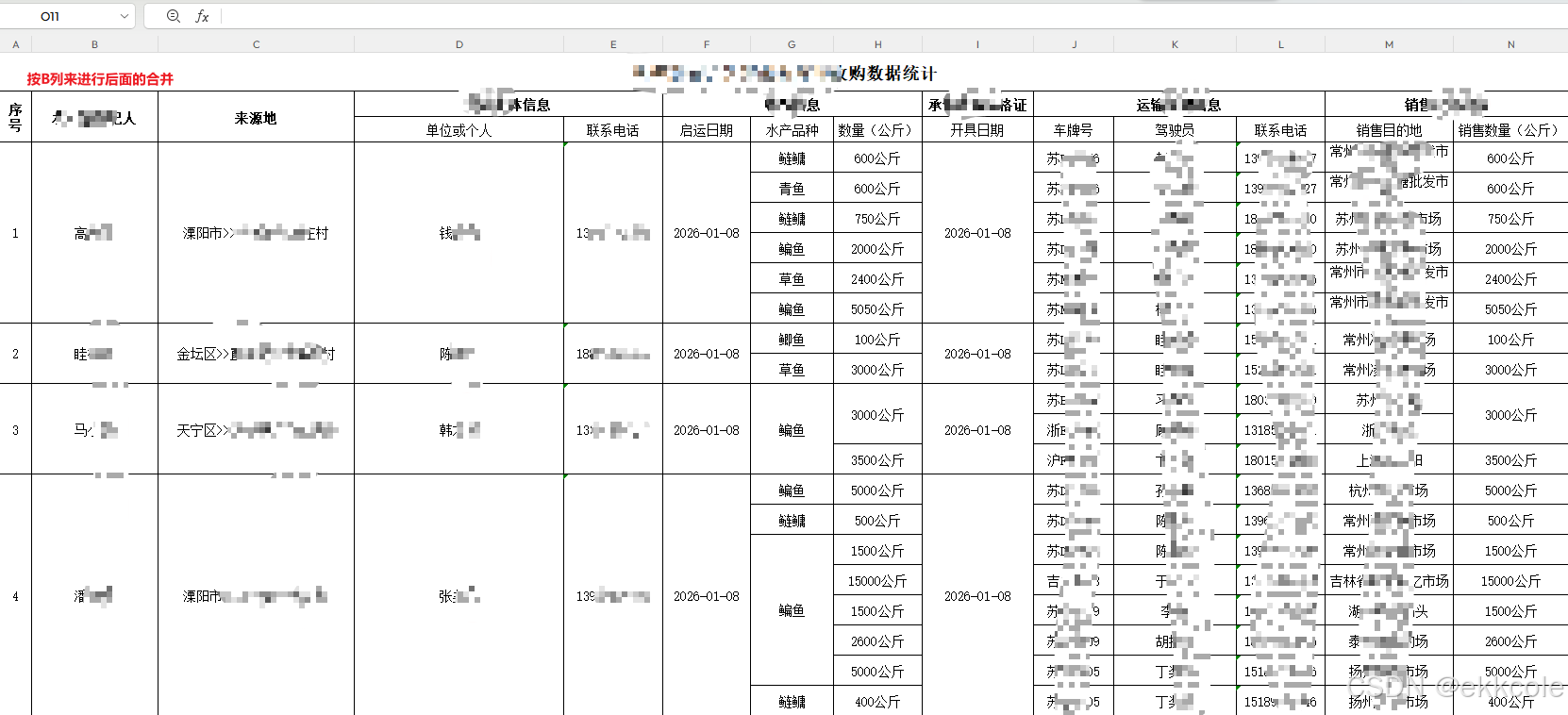
建议使用quickMergeWithDependency方法,手动添加合并规则
filePath Excel文件路径
brokerColumn 合并参考标准:如根据名称合并,正好在B列,那么合并的时候都参考该列,不会跨行
mergeColumns 需要合并的列(字母表示,如"A,C,D,E,F,G,H,I,N")不能包含brokerColumn否则会报错
startRow 起始行(从0开始)从哪行开始合并
dependencyRules 依赖规则,格式:"H:G,N:G" 表示H列依赖G列,N列依赖G列(G列相同才合并后面H或N列相同的值)
java
package org.springblade.modules.api.utils;
import org.apache.poi.ss.usermodel.*;
import org.apache.poi.ss.util.CellRangeAddress;
import org.apache.poi.xssf.usermodel.XSSFWorkbook;
import org.apache.poi.hssf.usermodel.HSSFWorkbook;
import java.io.*;
import java.util.*;
public class ExcelMergeByBroker {
/**
* 根据水产品经纪人列进行合并
* @param filePath Excel文件路径
* @param sheetIndex 工作表索引
* @param brokerColumnIndex 水产品经纪人列索引(从0开始)
* @param mergeColumnIndexes 需要合并的列索引数组
* @param startRow 起始行索引(0开始,通常是表头之后的数据起始行)
* @param specialRules 特殊合并规则
*/
public static void mergeByBroker(String filePath, int sheetIndex, int brokerColumnIndex,
int[] mergeColumnIndexes, int startRow, Map<Integer, Integer> specialRules) {
try {
File file = new File(filePath);
FileInputStream fis = new FileInputStream(file);
Workbook workbook = WorkbookFactory.create(fis);
Sheet sheet = workbook.getSheetAt(sheetIndex);
DataFormatter formatter = new DataFormatter();
int lastRow = sheet.getLastRowNum();
// 1. 先合并水产品经纪人列
List<int[]> brokerMergeRanges = mergeBrokerColumn(sheet, formatter, brokerColumnIndex, startRow, lastRow);
// 2. 根据经纪人的合并范围,合并其他列
for (int[] range : brokerMergeRanges) {
int start = range[0];
int end = range[1];
int brokerRowCount = end - start + 1; // 经纪人合并的行数
if (brokerRowCount > 1) {
// 对每一列,在经纪人合并的范围内检查是否需要合并
for (int colIndex : mergeColumnIndexes) {
// 检查是否有特殊合并规则
if (specialRules != null && specialRules.containsKey(colIndex)) {
int dependentColumn = specialRules.get(colIndex);
mergeColumnWithDependency(sheet, formatter, colIndex, start, end, dependentColumn);
} else {
mergeColumnInRange(sheet, formatter, colIndex, start, end);
}
}
}
}
fis.close();
FileOutputStream fos = new FileOutputStream(file);
workbook.write(fos);
fos.close();
workbook.close();
System.out.println("根据经纪人合并完成!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 原始方法,兼容旧调用
*/
public static void mergeByBroker(String filePath, int sheetIndex, int brokerColumnIndex,
int[] mergeColumnIndexes, int startRow) {
mergeByBroker(filePath, sheetIndex, brokerColumnIndex, mergeColumnIndexes, startRow, null);
}
/**
* 合并水产品经纪人列,并返回合并范围列表
*/
private static List<int[]> mergeBrokerColumn(Sheet sheet, DataFormatter formatter,
int brokerColumnIndex, int startRow, int lastRow) {
List<int[]> mergeRanges = new ArrayList<>();
int currentStart = startRow;
String currentValue = "";
for (int i = startRow; i <= lastRow; i++) {
Row row = sheet.getRow(i);
String brokerValue = getCellValue(row, brokerColumnIndex, formatter);
if (i == startRow) {
// 第一行
currentValue = brokerValue;
currentStart = i;
} else if (!brokerValue.equals(currentValue)) {
// 经纪人发生变化,记录上一个范围
if (i - 1 > currentStart) { // 至少有两行相同的经纪人
mergeRanges.add(new int[]{currentStart, i - 1});
CellRangeAddress region = new CellRangeAddress(currentStart, i - 1, brokerColumnIndex, brokerColumnIndex);
sheet.addMergedRegion(region);
}
currentValue = brokerValue;
currentStart = i;
}
// 处理最后一行
if (i == lastRow && i > currentStart) {
mergeRanges.add(new int[]{currentStart, i});
CellRangeAddress region = new CellRangeAddress(currentStart, i, brokerColumnIndex, brokerColumnIndex);
sheet.addMergedRegion(region);
}
}
return mergeRanges;
}
/**
* 在指定范围内合并列
*/
private static void mergeColumnInRange(Sheet sheet, DataFormatter formatter,
int colIndex, int startRow, int endRow) {
int mergeStart = startRow;
String prevValue = getCellValue(sheet.getRow(startRow), colIndex, formatter);
for (int i = startRow + 1; i <= endRow; i++) {
Row row = sheet.getRow(i);
String currentValue = getCellValue(row, colIndex, formatter);
if (!currentValue.equals(prevValue)) {
// 值发生变化,合并之前的区域
if (i - 1 > mergeStart) { // 至少有2行相同
CellRangeAddress region = new CellRangeAddress(mergeStart, i - 1, colIndex, colIndex);
sheet.addMergedRegion(region);
}
mergeStart = i;
prevValue = currentValue;
}
// 处理范围内的最后一行
if (i == endRow && i > mergeStart) {
CellRangeAddress region = new CellRangeAddress(mergeStart, i, colIndex, colIndex);
sheet.addMergedRegion(region);
}
}
}
/**
* 带依赖关系的列合并(例如:H列依赖G列,N列依赖G列)
*/
private static void mergeColumnWithDependency(Sheet sheet, DataFormatter formatter,
int colIndex, int startRow, int endRow, int dependentColumn) {
int mergeStart = startRow;
String prevValue = getCellValue(sheet.getRow(startRow), colIndex, formatter);
String prevDependentValue = getCellValue(sheet.getRow(startRow), dependentColumn, formatter);
for (int i = startRow + 1; i <= endRow; i++) {
Row row = sheet.getRow(i);
String currentValue = getCellValue(row, colIndex, formatter);
String currentDependentValue = getCellValue(row, dependentColumn, formatter);
// 当列值变化 或 依赖列值变化时,都需要重新开始合并范围
boolean shouldBreakMerge = !currentValue.equals(prevValue) ||
!currentDependentValue.equals(prevDependentValue);
if (shouldBreakMerge) {
// 值发生变化,合并之前的区域
if (i - 1 > mergeStart) { // 至少有2行相同
CellRangeAddress region = new CellRangeAddress(mergeStart, i - 1, colIndex, colIndex);
sheet.addMergedRegion(region);
}
mergeStart = i;
prevValue = currentValue;
prevDependentValue = currentDependentValue;
}
// 处理范围内的最后一行
if (i == endRow && i > mergeStart) {
CellRangeAddress region = new CellRangeAddress(mergeStart, i, colIndex, colIndex);
sheet.addMergedRegion(region);
}
}
}
/**
* 根据水产品经纪人合并指定列(自动检测需要合并的列)
* @param filePath Excel文件路径
* @param sheetIndex 工作表索引
* @param brokerColumnIndex 水产品经纪人列索引
* @param startRow 起始行
* @param allColumns 是否合并所有列(除了经纪人列)
*/
public static void mergeByBrokerAll(String filePath, int sheetIndex, int brokerColumnIndex,
int startRow, boolean allColumns) {
try {
File file = new File(filePath);
FileInputStream fis = new FileInputStream(file);
Workbook workbook = WorkbookFactory.create(fis);
Sheet sheet = workbook.getSheetAt(sheetIndex);
int lastRow = sheet.getLastRowNum();
Row firstRow = sheet.getRow(startRow);
int lastColumn = firstRow.getLastCellNum() - 1; // 最后一列的索引
// 确定需要合并的列
List<Integer> mergeColumns = new ArrayList<>();
if (allColumns) {
// 合并除了经纪人列之外的所有列
for (int i = 0; i <= lastColumn; i++) {
if (i != brokerColumnIndex) {
mergeColumns.add(i);
}
}
} else {
// 合并指定列
// 根据图片,可能需要合并的列:来源地、养殖主体信息、收购信息、承诺达标合格证、运输车辆等
// 这里需要根据实际情况调整
}
// 转换为数组
int[] mergeColumnArray = mergeColumns.stream().mapToInt(Integer::intValue).toArray();
fis.close();
workbook.close();
// 调用合并方法
mergeByBroker(filePath, sheetIndex, brokerColumnIndex, mergeColumnArray, startRow, null);
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 智能合并:根据水产品经纪人自动合并相关列
* @param filePath Excel文件路径
* @param brokerColumn 经纪人列(B列=1)
* @param startRow 数据起始行(从0开始)
*/
public static void smartMergeByBroker(String filePath, int brokerColumn, int startRow) {
// 根据图片中的列结构,设置需要合并的列
// 假设经纪人列是B列(1),那么需要合并的列是:
// C列(2)来源地, D列(3)单位或个人, E列(4)联系电话, F列(5)启运日期,
// G列(6)水产品种, H列(7)数量(公斤), I列(8)开具人,
// J列(9)车牌号, K列(10)驾驶员
int[] mergeColumns = {2, 3, 4, 5, 6, 7, 8, 9, 10};
// 特殊合并规则:H列(7)依赖G列(6),N列(13)依赖G列(6)
Map<Integer, Integer> specialRules = new HashMap<>();
specialRules.put(7, 6); // H列依赖G列
specialRules.put(13, 6); // N列依赖G列
mergeByBroker(filePath, 0, brokerColumn, mergeColumns, startRow, specialRules);
}
/**
* 获取单元格值
*/
private static String getCellValue(Row row, int colIndex, DataFormatter formatter) {
if (row == null) return "";
Cell cell = row.getCell(colIndex);
if (cell == null) return "";
return formatter.formatCellValue(cell);
}
/**
* 快速合并方法(最简单调用方式)
* @param filePath Excel文件路径
* @param brokerColumn 经纪人列(字母表示,如"B")
* @param mergeColumns 需要合并的列(字母表示,如"C,D,E,F,G,H,I,J,K")
* @param startRow 起始行(从0开始)
*/
public static void quickMerge(String filePath, String brokerColumn, String mergeColumns, int startRow) {
int brokerIndex = convertColumnLetterToIndex(brokerColumn);
int[] mergeIndices = convertColumnStringToArray(mergeColumns);
// 默认的特殊合并规则:H列(7)依赖G列(6),N列(13)依赖G列(6)
Map<Integer, Integer> specialRules = new HashMap<>();
// 检查是否包含H列(7)和N列(13)
int gIndex = convertColumnLetterToIndex("G");
int hIndex = convertColumnLetterToIndex("H");
int nIndex = convertColumnLetterToIndex("N");
// 如果合并列中包含H列,则设置H列依赖G列
if (arrayContains(mergeIndices, hIndex)) {
specialRules.put(hIndex, gIndex);
}
// 如果合并列中包含N列,则设置N列依赖G列
if (arrayContains(mergeIndices, nIndex)) {
specialRules.put(nIndex, gIndex);
}
// 如果没有特殊规则,specialRules会是空Map
mergeByBroker(filePath, 0, brokerIndex, mergeIndices, startRow, specialRules.isEmpty() ? null : specialRules);
}
/**
* 检查数组是否包含某个值
*/
private static boolean arrayContains(int[] array, int value) {
for (int item : array) {
if (item == value) {
return true;
}
}
return false;
}
/**
* 高级快速合并方法,可指定依赖规则
* @param filePath Excel文件路径
* @param brokerColumn 经纪人列(字母表示,如"B")
* @param mergeColumns 需要合并的列(字母表示,如"A,C,D,E,F,G,H,I,N")
* @param startRow 起始行(从0开始)
* @param dependencyRules 依赖规则,格式:"H:G,N:G" 表示H列依赖G列,N列依赖G列
*/
public static void quickMergeWithDependency(String filePath, String brokerColumn, String mergeColumns,
int startRow, String dependencyRules) {
int brokerIndex = convertColumnLetterToIndex(brokerColumn);
int[] mergeIndices = convertColumnStringToArray(mergeColumns);
Map<Integer, Integer> specialRules = parseDependencyRules(dependencyRules);
mergeByBroker(filePath, 0, brokerIndex, mergeIndices, startRow,
specialRules.isEmpty() ? null : specialRules);
}
/**
* 解析依赖规则字符串
* @param dependencyRules 格式:"H:G,N:G" 或 "H:G" 或 "N:G"
* @return 依赖规则Map
*/
private static Map<Integer, Integer> parseDependencyRules(String dependencyRules) {
Map<Integer, Integer> rules = new HashMap<>();
if (dependencyRules == null || dependencyRules.trim().isEmpty()) {
return rules;
}
String[] rulePairs = dependencyRules.split(",");
for (String pair : rulePairs) {
String[] parts = pair.split(":");
if (parts.length == 2) {
int targetCol = convertColumnLetterToIndex(parts[0].trim());
int dependentCol = convertColumnLetterToIndex(parts[1].trim());
rules.put(targetCol, dependentCol);
}
}
return rules;
}
/**
* 将列字母转换为索引
*/
private static int convertColumnLetterToIndex(String columnLetter) {
columnLetter = columnLetter.toUpperCase();
int index = 0;
for (int i = 0; i < columnLetter.length(); i++) {
char c = columnLetter.charAt(i);
index = index * 26 + (c - 'A' + 1);
}
return index - 1;
}
/**
* 将列字符串转换为索引数组
*/
private static int[] convertColumnStringToArray(String columns) {
String[] parts = columns.split(",");
int[] result = new int[parts.length];
for (int i = 0; i < parts.length; i++) {
result[i] = convertColumnLetterToIndex(parts[i].trim());
}
return result;
}
/**
* 高级合并:可以根据配置灵活合并
* @param filePath Excel文件路径
* @param config 合并配置
*/
public static void advancedMerge(String filePath, MergeConfig config) {
try {
File file = new File(filePath);
FileInputStream fis = new FileInputStream(file);
Workbook workbook = WorkbookFactory.create(fis);
Sheet sheet = workbook.getSheetAt(config.getSheetIndex());
DataFormatter formatter = new DataFormatter();
int lastRow = sheet.getLastRowNum();
Map<String, List<int[]>> brokerGroups = new HashMap<>();
// 1. 按经纪人分组
for (int i = config.getStartRow(); i <= lastRow; i++) {
Row row = sheet.getRow(i);
if (row == null) continue;
String brokerValue = getCellValue(row, config.getBrokerColumnIndex(), formatter);
if (brokerValue == null || brokerValue.trim().isEmpty()) {
continue;
}
brokerGroups.putIfAbsent(brokerValue, new ArrayList<>());
brokerGroups.get(brokerValue).add(new int[]{i, i});
}
// 2. 合并每个经纪人的数据
for (Map.Entry<String, List<int[]>> entry : brokerGroups.entrySet()) {
List<int[]> rowRanges = entry.getValue();
// 合并每个经纪人的行范围
for (int[] range : rowRanges) {
int start = range[0];
int end = range[1];
if (end - start + 1 > 1) {
// 合并经纪人列
CellRangeAddress brokerRegion = new CellRangeAddress(start, end,
config.getBrokerColumnIndex(), config.getBrokerColumnIndex());
sheet.addMergedRegion(brokerRegion);
// 合并其他列
for (int colIndex : config.getMergeColumnIndices()) {
// 检查是否有特殊依赖规则
if (config.getSpecialRules() != null && config.getSpecialRules().containsKey(colIndex)) {
int dependentColumn = config.getSpecialRules().get(colIndex);
mergeColumnWithDependency(sheet, formatter, colIndex, start, end, dependentColumn);
} else {
mergeColumnInRange(sheet, formatter, colIndex, start, end);
}
}
}
}
}
fis.close();
FileOutputStream fos = new FileOutputStream(file);
workbook.write(fos);
fos.close();
workbook.close();
System.out.println("高级合并完成!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 合并配置类
*/
public static class MergeConfig {
private int sheetIndex = 0;
private int brokerColumnIndex = 1; // B列
private int[] mergeColumnIndices = {2, 3, 4, 5, 6, 7, 8, 9, 10}; // C-K列
private int startRow = 2; // 从第3行开始(0-based)
private Map<Integer, Integer> specialRules; // 特殊合并规则
public MergeConfig() {}
public MergeConfig(int brokerColumnIndex, int[] mergeColumnIndices, int startRow) {
this.brokerColumnIndex = brokerColumnIndex;
this.mergeColumnIndices = mergeColumnIndices;
this.startRow = startRow;
}
// Getters and Setters
public int getSheetIndex() { return sheetIndex; }
public void setSheetIndex(int sheetIndex) { this.sheetIndex = sheetIndex; }
public int getBrokerColumnIndex() { return brokerColumnIndex; }
public void setBrokerColumnIndex(int brokerColumnIndex) { this.brokerColumnIndex = brokerColumnIndex; }
public int[] getMergeColumnIndices() { return mergeColumnIndices; }
public void setMergeColumnIndices(int[] mergeColumnIndices) { this.mergeColumnIndices = mergeColumnIndices; }
public int getStartRow() { return startRow; }
public void setStartRow(int startRow) { this.startRow = startRow; }
public Map<Integer, Integer> getSpecialRules() { return specialRules; }
public void setSpecialRules(Map<Integer, Integer> specialRules) { this.specialRules = specialRules; }
/**
* 添加特殊合并规则
* @param targetCol 目标列(需要合并的列)
* @param dependentCol 依赖列
*/
public void addSpecialRule(int targetCol, int dependentCol) {
if (specialRules == null) {
specialRules = new HashMap<>();
}
specialRules.put(targetCol, dependentCol);
}
}
/**
* 主方法测试
*/
public static void main(String[] args) {
String filePath = "C:\\Users\\Administrator\\Desktop\\23460685336400AgentWater.xlsx";
// 方法2:使用快速合并(自动检测H列和N列依赖G列)
System.out.println("方法2:快速合并");
quickMerge(filePath, "B", "A,C,D,E,F,G,H,I,N", 2);
// 方法3:使用快速合并并指定依赖规则
System.out.println("方法3:快速合并(带依赖规则)");
quickMergeWithDependency(filePath, "B", "A,C,D,E,F,G,H,I,N", 2, "H:G,N:G");
// 方法4:使用高级合并
System.out.println("方法4:高级合并");
MergeConfig config = new MergeConfig(1, new int[]{0, 2, 3, 4, 5, 6, 7, 8, 13}, 2);
// 添加特殊规则:H列(7)依赖G列(6),N列(13)依赖G列(6)
config.addSpecialRule(7, 6);
config.addSpecialRule(13, 6);
advancedMerge(filePath, config);
}
}