🎯 并行化设计核心思想
在AI Agent系统中,并行化设计主要解决两个核心问题:
-
任务并行:将复杂任务拆分为可并行的子任务
-
数据并行:同时处理多个独立的数据项
下面是并行化Agent系统的核心设计模式概览:
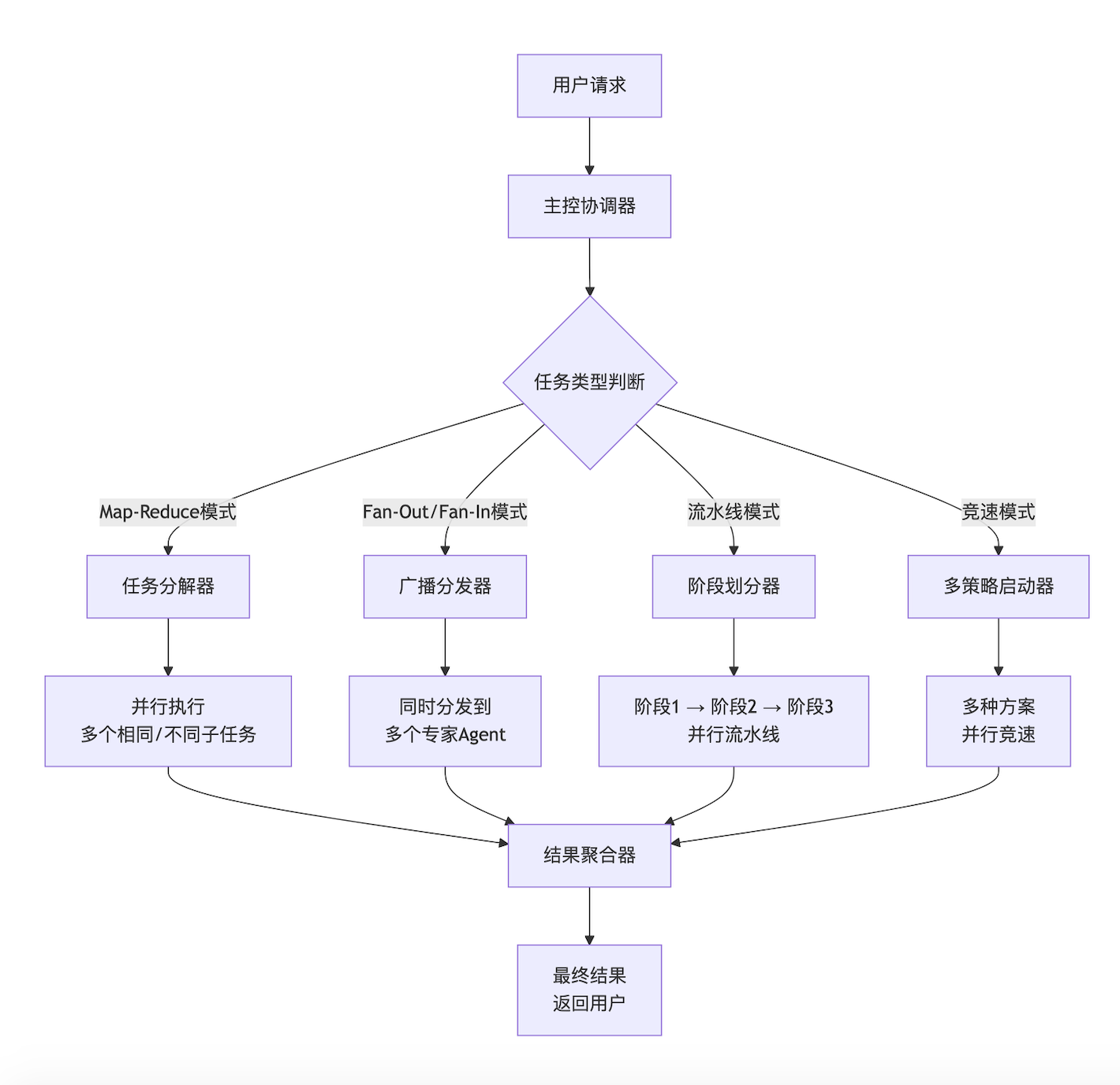
一、LangGraph并行化基础架构
1.1 并行化Agent系统设计
python
# parallel_agent_system.py
import asyncio
from typing import List, Dict, Any, Optional, Annotated
from datetime import datetime
import uuid
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import json
from langgraph.graph import StateGraph, END
from langgraph.checkpoint import MemorySaver
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_openai import ChatOpenAI
from langchain_community.tools import DuckDuckGoSearchRun
from pydantic import BaseModel, Field
from enum import Enum
# ========== 数据模型定义 ==========
class TaskStatus(Enum):
PENDING = "pending"
PROCESSING = "processing"
COMPLETED = "completed"
FAILED = "failed"
class ParallelTask(BaseModel):
"""并行任务单元"""
task_id: str = Field(default_factory=lambda: str(uuid.uuid4())[:8])
description: str
task_type: str
dependencies: List[str] = Field(default_factory=list)
status: TaskStatus = TaskStatus.PENDING
result: Optional[Any] = None
error: Optional[str] = None
created_at: datetime = Field(default_factory=datetime.now)
completed_at: Optional[datetime] = None
executor: Optional[str] = None # 指定执行器类型
timeout: int = 30 # 超时时间(秒)
class AgentState(BaseModel):
"""Agent状态,支持并行执行"""
user_query: str
tasks: List[ParallelTask] = Field(default_factory=list)
completed_tasks: List[ParallelTask] = Field(default_factory=list)
failed_tasks: List[ParallelTask] = Field(default_factory=list)
intermediate_results: Dict[str, Any] = Field(default_factory=dict)
final_result: Optional[str] = None
execution_plan: Optional[Dict] = None
parallelism_level: int = 3 # 默认并行度
current_parallel_index: int = 0
# ========== 并行执行器池 ==========
class ParallelExecutorPool:
"""并行执行器池"""
def __init__(self, max_workers: int = 5):
self.thread_pool = ThreadPoolExecutor(max_workers=max_workers)
self.process_pool = ProcessPoolExecutor(max_workers=max_workers)
self.active_tasks = {}
async def execute_task(self, task: ParallelTask, func, *args, **kwargs):
"""异步执行任务"""
loop = asyncio.get_event_loop()
try:
# 根据执行器类型选择线程池或进程池
if task.executor == "process":
# CPU密集型任务使用进程池
result = await loop.run_in_executor(
self.process_pool, func, *args, **kwargs
)
else:
# I/O密集型任务使用线程池
result = await loop.run_in_in_executor(
self.thread_pool, func, *args, **kwargs
)
task.status = TaskStatus.COMPLETED
task.result = result
task.completed_at = datetime.now()
except Exception as e:
task.status = TaskStatus.FAILED
task.error = str(e)
return task
async def execute_parallel(self, tasks: List[ParallelTask], func, *args, **kwargs):
"""并行执行多个任务"""
# 创建所有任务的协程
task_coroutines = []
for task in tasks:
# 每个任务可以有不同的参数
task_args = kwargs.get(f"args_{task.task_id}", args)
task_kwargs = kwargs.get(f"kwargs_{task.task_id}", kwargs)
coro = self.execute_task(task, func, *task_args, **task_kwargs)
task_coroutines.append(coro)
# 并行执行所有任务
results = await asyncio.gather(*task_coroutines, return_exceptions=True)
# 处理结果
completed = []
failed = []
for i, result in enumerate(results):
if isinstance(result, Exception):
tasks[i].status = TaskStatus.FAILED
tasks[i].error = str(result)
failed.append(tasks[i])
else:
completed.append(result)
return completed, failed
def shutdown(self):
"""关闭执行器池"""
self.thread_pool.shutdown(wait=True)
self.process_pool.shutdown(wait=True)
# ========== 并行化Agent基类 ==========
class ParallelAgent:
"""支持并行执行的Agent基类"""
def __init__(self, llm=None, tools=None, max_parallelism=5):
self.llm = llm or ChatOpenAI(temperature=0, model="gpt-4")
self.tools = tools or []
self.executor_pool = ParallelExecutorPool(max_workers=max_parallelism)
self.workflow = self._create_workflow()
def _create_workflow(self) -> StateGraph:
"""创建并行化工作流"""
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("analyze_query", self.analyze_query)
workflow.add_node("plan_execution", self.plan_execution)
workflow.add_node("execute_parallel_tasks", self.execute_parallel_tasks)
workflow.add_node("aggregate_results", self.aggregate_results)
workflow.add_node("generate_final_answer", self.generate_final_answer)
# 设置边
workflow.set_entry_point("analyze_query")
workflow.add_edge("analyze_query", "plan_execution")
workflow.add_edge("plan_execution", "execute_parallel_tasks")
workflow.add_edge("execute_parallel_tasks", "aggregate_results")
workflow.add_edge("aggregate_results", "generate_final_answer")
workflow.add_edge("generate_final_answer", END)
return workflow
async def analyze_query(self, state: AgentState) -> Dict:
"""分析用户查询,确定是否需要并行处理"""
print(f"[Analyze] 分析查询: {state.user_query}")
# 使用LLM判断查询复杂度
analysis_prompt = f"""
分析以下用户查询的复杂度和是否需要并行处理:
查询:{state.user_query}
请判断:
1. 是否需要拆分为多个子任务?
2. 适合哪种并行模式?(MapReduce, Fan-out/Fan-in, Pipeline等)
3. 预估的并行度是多少?
以JSON格式返回分析结果。
"""
messages = [
SystemMessage(content="你是一个并行任务分析专家。"),
HumanMessage(content=analysis_prompt)
]
response = await self.llm.ainvoke(messages)
try:
analysis = json.loads(response.content)
state.execution_plan = analysis
except:
# 简化分析:如果查询包含"和"、"同时"、"分别"等关键词,则可能适合并行
keywords = ["和", "同时", "分别", "多个", "各", "对比"]
need_parallel = any(keyword in state.user_query for keyword in keywords)
state.execution_plan = {
"need_parallel": need_parallel,
"parallel_mode": "fan_out_fan_in" if need_parallel else "sequential",
"estimated_parallelism": 2 if need_parallel else 1
}
return {"execution_plan": state.execution_plan}
async def plan_execution(self, state: AgentState) -> Dict:
"""规划并行执行方案"""
print(f"[Plan] 规划执行方案")
if not state.execution_plan.get("need_parallel", False):
# 串行执行,创建一个任务
task = ParallelTask(
description=state.user_query,
task_type="sequential",
dependencies=[]
)
state.tasks = [task]
return {"tasks": state.tasks}
# 并行执行,创建多个子任务
# 根据不同的并行模式创建任务
parallel_mode = state.execution_plan.get("parallel_mode", "fan_out_fan_in")
if parallel_mode == "map_reduce":
tasks = self._create_map_reduce_tasks(state.user_query)
elif parallel_mode == "fan_out_fan_in":
tasks = self._create_fan_out_fan_in_tasks(state.user_query)
elif parallel_mode == "pipeline":
tasks = self._create_pipeline_tasks(state.user_query)
else:
tasks = self._create_default_parallel_tasks(state.user_query)
state.tasks = tasks
return {"tasks": state.tasks}
def _create_map_reduce_tasks(self, query: str) -> List[ParallelTask]:
"""创建Map-Reduce模式任务"""
# 示例:将查询拆分为多个部分分别处理,然后汇总
subtasks = [
ParallelTask(
description=f"处理查询的主题部分: {query}",
task_type="map",
dependencies=[],
executor="thread"
),
ParallelTask(
description=f"处理查询的细节部分: {query}",
task_type="map",
dependencies=[],
executor="thread"
),
ParallelTask(
description=f"收集背景信息: {query}",
task_type="map",
dependencies=[],
executor="process" # CPU密集型,使用进程
)
]
# Reduce任务依赖所有Map任务
reduce_task = ParallelTask(
description="汇总所有结果",
task_type="reduce",
dependencies=[t.task_id for t in subtasks],
executor="thread"
)
return subtasks + [reduce_task]
def _create_fan_out_fan_in_tasks(self, query: str) -> List[ParallelTask]:
"""创建Fan-out/Fan-in模式任务"""
# 多个专家同时处理同一个查询的不同方面
experts = [
("技术专家", "分析技术细节"),
("商业专家", "分析商业价值"),
("用户体验专家", "分析用户体验"),
("安全专家", "分析安全性")
]
tasks = []
for expert_name, focus in experts:
task = ParallelTask(
description=f"{expert_name}: {focus} - {query}",
task_type=f"expert_{expert_name}",
dependencies=[],
executor="thread"
)
tasks.append(task)
return tasks
def _create_pipeline_tasks(self, query: str) -> List[ParallelTask]:
"""创建流水线模式任务"""
# 任务之间有依赖关系,形成流水线
stages = [
("数据收集", "收集相关信息"),
("数据处理", "清洗和处理数据"),
("数据分析", "分析数据模式"),
("报告生成", "生成最终报告")
]
tasks = []
previous_task_id = None
for i, (stage_name, description) in enumerate(stages):
dependencies = [previous_task_id] if previous_task_id else []
task = ParallelTask(
description=f"{stage_name}: {description} - {query}",
task_type=f"pipeline_stage_{i+1}",
dependencies=dependencies,
executor="thread"
)
tasks.append(task)
previous_task_id = task.task_id
return tasks
async def execute_parallel_tasks(self, state: AgentState) -> Dict:
"""并行执行所有任务"""
print(f"[Execute] 开始并行执行 {len(state.tasks)} 个任务")
# 根据任务依赖关系确定执行顺序
executable_tasks = self._get_executable_tasks(state.tasks)
if not executable_tasks:
return {"completed_tasks": [], "failed_tasks": []}
# 执行可并行执行的任务
completed, failed = await self.executor_pool.execute_parallel(
executable_tasks,
self._execute_single_task,
query=state.user_query
)
# 更新状态
state.completed_tasks.extend(completed)
state.failed_tasks.extend(failed)
# 从待处理任务中移除已完成/失败的任务
state.tasks = [t for t in state.tasks
if t.task_id not in [c.task_id for c in completed] + [f.task_id for f in failed]]
# 如果有任务失败,记录中间结果
for task in completed:
if task.result:
state.intermediate_results[task.task_id] = task.result
return {
"completed_tasks": completed,
"failed_tasks": failed,
"tasks": state.tasks,
"intermediate_results": state.intermediate_results
}
def _get_executable_tasks(self, tasks: List[ParallelTask]) -> List[ParallelTask]:
"""获取当前可执行的任务(依赖已满足)"""
completed_ids = [t.task_id for t in tasks if t.status == TaskStatus.COMPLETED]
executable = []
for task in tasks:
if task.status == TaskStatus.PENDING:
# 检查依赖是否都满足
deps_satisfied = all(dep in completed_ids for dep in task.dependencies)
if deps_satisfied:
executable.append(task)
return executable
async def _execute_single_task(self, query: str, **kwargs) -> str:
"""执行单个任务(模拟)"""
# 在实际应用中,这里会调用真正的工具或LLM
task_description = kwargs.get("task_description", "")
task_type = kwargs.get("task_type", "")
# 模拟任务执行时间
import random
await asyncio.sleep(random.uniform(0.5, 2.0))
# 根据任务类型返回不同结果
if "expert" in task_type:
expert_name = task_type.split("_")[1]
return f"{expert_name}的分析结果: 针对'{query}',{task_description}。这是详细分析..."
elif "map" in task_type:
return f"Map任务结果: 处理了'{query}'的{task_description}"
elif "reduce" in task_type:
return f"Reduce任务结果: 汇总了所有子任务的分析"
elif "pipeline" in task_type:
stage = task_type.split("_")[-1]
return f"流水线阶段{stage}完成: {task_description}"
else:
return f"任务完成: {task_description} - 查询: {query}"
async def aggregate_results(self, state: AgentState) -> Dict:
"""聚合并行任务的结果"""
print(f"[Aggregate] 聚合 {len(state.completed_tasks)} 个任务的结果")
if not state.completed_tasks:
return {"final_result": "没有任务完成"}
# 收集所有结果
all_results = []
for task in state.completed_tasks:
if task.result:
all_results.append(f"任务 {task.task_id} ({task.description}):\n{task.result}")
# 使用LLM聚合结果
aggregation_prompt = f"""
用户原始查询: {state.user_query}
以下是并行执行的多个子任务的结果,请将它们整合成一个连贯、完整的回答:
{chr(10).join(all_results)}
请生成最终的回答,确保覆盖所有重要信息,并且回答结构清晰。
"""
messages = [
SystemMessage(content="你是一个结果聚合专家,擅长将多个来源的信息整合成连贯的回答。"),
HumanMessage(content=aggregation_prompt)
]
response = await self.llm.ainvoke(messages)
state.final_result = response.content
return {"final_result": state.final_result}
async def generate_final_answer(self, state: AgentState) -> Dict:
"""生成最终答案"""
print(f"[Final] 生成最终答案")
# 如果有失败的任务,在最终答案中说明
if state.failed_tasks:
failed_summary = "\n".join([
f"- {task.description}: {task.error}"
for task in state.failed_tasks
])
state.final_result += f"\n\n注意:以下任务执行失败:\n{failed_summary}"
return {"final_result": state.final_result}
async def run(self, query: str) -> str:
"""运行并行Agent"""
print(f"开始处理查询: {query}")
# 初始化状态
initial_state = AgentState(user_query=query)
# 配置检查点
memory = MemorySaver()
# 编译工作流
app = self.workflow.compile(checkpointer=memory)
# 执行工作流
config = {"configurable": {"thread_id": "parallel_agent_1"}}
final_state = None
async for event in app.astream(initial_state, config=config):
if "aggregate_results" in event:
print(f"聚合结果完成")
elif "generate_final_answer" in event:
final_state = event["generate_final_answer"]
break
# 清理资源
self.executor_pool.shutdown()
return final_state.get("final_result", "未生成结果") if final_state else "执行失败"
# ========== 测试代码 ==========
async def test_parallel_agent():
"""测试并行Agent"""
# 创建并行Agent
agent = ParallelAgent(max_parallelism=4)
# 测试查询
test_queries = [
# 简单查询(可能串行执行)
"中国的首都是哪里?",
# 复杂查询(适合并行)
"对比分析Python、Java和Go语言在Web开发、数据科学和系统编程方面的优缺点,并给出选择建议",
# 多专家分析查询
"从技术可行性、商业价值、用户体验和安全性四个角度分析人脸识别支付系统的前景",
# 流水线处理查询
"收集2023年人工智能领域的重要进展,分析主要趋势,并预测2024年发展方向"
]
for i, query in enumerate(test_queries, 1):
print(f"\n{'='*60}")
print(f"测试 {i}: {query}")
print(f"{'='*60}")
start_time = datetime.now()
result = await agent.run(query)
end_time = datetime.now()
print(f"\n执行时间: {(end_time - start_time).total_seconds():.2f}秒")
print(f"\n最终结果:\n{result[:500]}..." if len(result) > 500 else f"\n最终结果:\n{result}")
print(f"\n{'='*60}")
if __name__ == "__main__":
# 运行测试
asyncio.run(test_parallel_agent())二、高级并行化设计模式
2.1 Map-Reduce模式实现
python
# map_reduce_agent.py
import asyncio
from typing import List, Dict, Any
from dataclasses import dataclass
from concurrent.futures import as_completed
import numpy as np
@dataclass
class MapReduceResult:
map_results: List[Any]
reduce_result: Any
execution_time: float
class MapReduceAgent:
"""Map-Reduce模式Agent"""
def __init__(self, llm, num_mappers=3):
self.llm = llm
self.num_mappers = num_mappers
async def map_phase(self, data: List[Any], map_func) -> List[Any]:
"""Map阶段:并行处理数据"""
print(f"[Map Phase] 启动 {self.num_mappers} 个Mapper")
# 将数据划分为多个分片
chunks = np.array_split(data, self.num_mappers)
# 并行执行Map任务
map_tasks = []
for i, chunk in enumerate(chunks):
task = asyncio.create_task(
self._execute_map(chunk, map_func, mapper_id=i)
)
map_tasks.append(task)
# 等待所有Map任务完成
map_results = []
for completed_task in asyncio.as_completed(map_tasks):
result = await completed_task
map_results.extend(result)
print(f"[Map Phase] 完成,生成 {len(map_results)} 个中间结果")
return map_results
async def _execute_map(self, data_chunk: List[Any], map_func, mapper_id: int) -> List[Any]:
"""执行单个Map任务"""
results = []
for item in data_chunk:
try:
# 实际应用中,这里可能调用LLM或工具
result = await map_func(item, mapper_id)
results.append(result)
except Exception as e:
print(f"Mapper {mapper_id} 处理失败: {e}")
results.append(None)
return results
async def reduce_phase(self, map_results: List[Any], reduce_func) -> Any:
"""Reduce阶段:聚合结果"""
print(f"[Reduce Phase] 开始聚合 {len(map_results)} 个中间结果")
# 可以并行执行多个Reduce任务(如果支持)
# 这里简化处理,使用单个Reducer
result = await reduce_func(map_results)
print(f"[Reduce Phase] 完成,生成最终结果")
return result
async def execute(self, data: List[Any], map_func, reduce_func) -> MapReduceResult:
"""执行完整的Map-Reduce流程"""
import time
start_time = time.time()
# Map阶段
map_results = await self.map_phase(data, map_func)
# Reduce阶段
reduce_result = await self.reduce_phase(map_results, reduce_func)
execution_time = time.time() - start_time
return MapReduceResult(
map_results=map_results,
reduce_result=reduce_result,
execution_time=execution_time
)
# 示例:文档分析Map-Reduce
class DocumentAnalyzer:
"""文档分析Map-Reduce示例"""
def __init__(self, llm):
self.llm = llm
self.map_reduce_agent = MapReduceAgent(llm, num_mappers=4)
async def analyze_documents(self, documents: List[str]) -> Dict[str, Any]:
"""并行分析多个文档"""
async def map_document(doc: str, mapper_id: int) -> Dict[str, Any]:
"""Map函数:分析单个文档"""
prompt = f"""
分析以下文档:
{doc[:1000]} # 截断文档
请提取:
1. 主要主题
2. 关键实体(人名、地名、组织名)
3. 情感倾向(正面/负面/中性)
以JSON格式返回结果。
"""
response = await self.llm.ainvoke([
SystemMessage(content="你是文档分析专家。"),
HumanMessage(content=prompt)
])
return {
"document_snippet": doc[:200],
"analysis": response.content,
"mapper_id": mapper_id
}
async def reduce_analyses(analyses: List[Dict]) -> Dict[str, Any]:
"""Reduce函数:汇总所有文档分析"""
# 提取所有主题
all_topics = []
all_entities = []
sentiment_counts = {"positive": 0, "negative": 0, "neutral": 0}
for analysis in analyses:
if analysis and analysis.get("analysis"):
try:
data = json.loads(analysis["analysis"])
all_topics.append(data.get("topics", []))
all_entities.extend(data.get("entities", []))
sentiment = data.get("sentiment", "neutral").lower()
if sentiment in sentiment_counts:
sentiment_counts[sentiment] += 1
except:
continue
# 使用LLM生成汇总报告
summary_prompt = f"""
基于 {len(analyses)} 个文档的分析,生成汇总报告:
发现的主题: {all_topics}
关键实体: {all_entities}
情感分布: {sentiment_counts}
请生成一个结构化的分析报告。
"""
response = await self.llm.ainvoke([
SystemMessage(content="你是数据分析汇总专家。"),
HumanMessage(content=summary_prompt)
])
return {
"total_documents": len(analyses),
"topics_summary": all_topics,
"entities_summary": list(set(all_entities))[:20], # 去重,取前20
"sentiment_distribution": sentiment_counts,
"comprehensive_report": response.content
}
# 执行Map-Reduce
result = await self.map_reduce_agent.execute(
documents, map_document, reduce_analyses
)
return {
"map_results": result.map_results,
"final_report": result.reduce_result,
"execution_time": result.execution_time,
"parallelism_efficiency": len(documents) / result.execution_time if result.execution_time > 0 else 0
}2.2 竞速模式(最先完成者胜出)
python
# race_condition_agent.py
import asyncio
from typing import List, Dict, Any, Callable
import random
from dataclasses import dataclass
from datetime import datetime
@dataclass
class RaceResult:
winner: Any
winner_index: int
all_results: List[Any]
completion_times: List[float]
race_duration: float
class RaceConditionAgent:
"""竞速模式Agent:多个策略并行执行,最先完成的胜出"""
def __init__(self, strategies: List[Callable]):
self.strategies = strategies
self.timeout = 10 # 全局超时时间
async def race(self, input_data: Any) -> RaceResult:
"""执行竞速"""
print(f"[Race] 启动 {len(self.strategies)} 个策略竞速")
start_time = datetime.now()
# 为每个策略创建任务
tasks = []
for i, strategy in enumerate(self.strategies):
task = asyncio.create_task(
self._execute_with_timeout(strategy, input_data, i)
)
tasks.append(task)
# 使用asyncio.wait等待第一个完成的任务
done, pending = await asyncio.wait(
tasks,
timeout=self.timeout,
return_when=asyncio.FIRST_COMPLETED
)
# 取消所有未完成的任务
for task in pending:
task.cancel()
# 收集所有结果
all_results = []
completion_times = []
for task in tasks:
try:
result = await task # 获取结果(可能抛出CancelledError)
if hasattr(task, 'completion_time'):
completion_times.append(task.completion_time)
all_results.append(result)
except asyncio.CancelledError:
pass
except Exception as e:
print(f"策略执行失败: {e}")
# 确定胜者(最先完成的)
race_duration = (datetime.now() - start_time).total_seconds()
if completion_times:
winner_index = completion_times.index(min(completion_times))
winner = all_results[winner_index]
else:
winner_index = -1
winner = None
return RaceResult(
winner=winner,
winner_index=winner_index,
all_results=all_results,
completion_times=completion_times,
race_duration=race_duration
)
async def _execute_with_timeout(self, strategy: Callable, input_data: Any, index: int):
"""带超时执行的单个策略"""
start_time = datetime.now()
try:
# 执行策略
if asyncio.iscoroutinefunction(strategy):
result = await strategy(input_data)
else:
# 如果是同步函数,在线程池中执行
loop = asyncio.get_event_loop()
result = await loop.run_in_executor(None, strategy, input_data)
completion_time = (datetime.now() - start_time).total_seconds()
# 将完成时间附加到任务对象上
current_task = asyncio.current_task()
if current_task:
current_task.completion_time = completion_time
return {
"strategy_index": index,
"result": result,
"completion_time": completion_time,
"success": True
}
except asyncio.CancelledError:
raise
except Exception as e:
completion_time = (datetime.now() - start_time).total_seconds()
return {
"strategy_index": index,
"result": None,
"completion_time": completion_time,
"success": False,
"error": str(e)
}
# 示例:问题解答竞速
class QuestionAnsweringRacer:
"""问题解答竞速示例"""
def __init__(self, llm):
self.llm = llm
self.strategies = [
self._direct_answer_strategy,
self._step_by_step_strategy,
self._search_based_strategy,
self._analogy_based_strategy
]
self.racer = RaceConditionAgent(self.strategies)
async def _direct_answer_strategy(self, question: str) -> str:
"""策略1:直接回答"""
await asyncio.sleep(random.uniform(0.5, 1.5)) # 模拟处理时间
prompt = f"直接回答这个问题:{question}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"直接回答:{response.content}"
async def _step_by_step_strategy(self, question: str) -> str:
"""策略2:分步推理"""
await asyncio.sleep(random.uniform(1.0, 2.0)) # 模拟处理时间
prompt = f"请分步骤推理回答这个问题:{question}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"分步推理:{response.content}"
async def _search_based_strategy(self, question: str) -> str:
"""策略3:搜索增强(模拟)"""
await asyncio.sleep(random.uniform(1.5, 2.5)) # 模拟搜索时间
# 模拟搜索
search_results = [
f"相关搜索结果1:关于'{question}'的信息",
f"相关搜索结果2:{question}的背景知识"
]
prompt = f"基于以下搜索结果回答问题:\n{chr(10).join(search_results)}\n\n问题:{question}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"搜索增强回答:{response.content}"
async def _analogy_based_strategy(self, question: str) -> str:
"""策略4:类比推理"""
await asyncio.sleep(random.uniform(2.0, 3.0)) # 模拟处理时间
prompt = f"使用类比方法回答这个问题:{question}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"类比推理:{response.content}"
async def answer_question(self, question: str) -> Dict[str, Any]:
"""使用竞速模式回答问题"""
print(f"问题: {question}")
result = await self.racer.race(question)
return {
"question": question,
"winner_strategy": result.winner_index,
"winner_answer": result.winner["result"] if result.winner else None,
"all_strategy_results": result.all_results,
"completion_times": result.completion_times,
"race_duration": result.race_duration,
"efficiency_gain": result.completion_times[0] if result.completion_times else 0
}2.3 动态并行度调整
python
# adaptive_parallelism.py
import asyncio
from typing import List, Dict, Any
import time
from dataclasses import dataclass
from collections import deque
import statistics
@dataclass
class PerformanceMetrics:
task_completion_times: List[float]
success_rate: float
throughput: float # 任务/秒
resource_utilization: float
class AdaptiveParallelAgent:
"""动态调整并行度的Agent"""
def __init__(self,
min_parallelism: int = 1,
max_parallelism: int = 10,
adaptation_interval: int = 10):
self.min_parallelism = min_parallelism
self.max_parallelism = max_parallelism
self.current_parallelism = min_parallelism
self.adaptation_interval = adaptation_interval
self.metrics_history = deque(maxlen=100)
# 性能指标
self.performance_metrics = PerformanceMetrics(
task_completion_times=[],
success_rate=1.0,
throughput=0.0,
resource_utilization=0.0
)
async def execute_with_adaptation(self, tasks: List[Any], task_func) -> List[Any]:
"""自适应并行执行"""
print(f"[Adaptive] 初始并行度: {self.current_parallelism}")
results = []
remaining_tasks = tasks.copy()
batch_size = self.current_parallelism
task_start_time = time.time()
tasks_processed = 0
while remaining_tasks:
# 获取当前批次的任务
current_batch = remaining_tasks[:batch_size]
# 并行执行当前批次
batch_start = time.time()
batch_results = await self._execute_batch(current_batch, task_func)
batch_duration = time.time() - batch_start
# 收集结果
results.extend(batch_results)
# 更新性能指标
self._update_performance_metrics(
batch_size=batch_size,
batch_duration=batch_duration,
successful_tasks=sum(1 for r in batch_results if r is not None)
)
# 更新任务计数
tasks_processed += len(current_batch)
remaining_tasks = remaining_tasks[batch_size:]
# 每隔一段时间调整并行度
if tasks_processed % self.adaptation_interval == 0:
self._adapt_parallelism()
batch_size = self.current_parallelism
print(f"[Adaptive] 调整并行度为: {self.current_parallelism}")
total_duration = time.time() - task_start_time
self.performance_metrics.throughput = tasks_processed / total_duration
print(f"[Adaptive] 完成,最终并行度: {self.current_parallelism}")
print(f"[Adaptive] 吞吐量: {self.performance_metrics.throughput:.2f} 任务/秒")
return results
async def _execute_batch(self, batch: List[Any], task_func) -> List[Any]:
"""执行一个批次的任务"""
tasks = []
for item in batch:
if asyncio.iscoroutinefunction(task_func):
task = asyncio.create_task(task_func(item))
else:
loop = asyncio.get_event_loop()
task = loop.create_task(
loop.run_in_executor(None, task_func, item)
)
tasks.append(task)
# 等待批次完成
batch_results = []
for completed_task in asyncio.as_completed(tasks):
try:
result = await completed_task
batch_results.append(result)
except Exception as e:
print(f"任务执行失败: {e}")
batch_results.append(None)
return batch_results
def _update_performance_metrics(self, batch_size: int, batch_duration: float, successful_tasks: int):
"""更新性能指标"""
# 记录批次完成时间
avg_task_time = batch_duration / batch_size if batch_size > 0 else 0
self.performance_metrics.task_completion_times.append(avg_task_time)
# 更新成功率
success_rate = successful_tasks / batch_size if batch_size > 0 else 1.0
self.performance_metrics.success_rate = (
0.9 * self.performance_metrics.success_rate + 0.1 * success_rate
)
# 添加到历史记录
self.metrics_history.append({
"parallelism": self.current_parallelism,
"batch_duration": batch_duration,
"success_rate": success_rate,
"avg_task_time": avg_task_time
})
def _adapt_parallelism(self):
"""根据性能指标调整并行度"""
if len(self.metrics_history) < 3:
return
# 分析最近的历史记录
recent_metrics = list(self.metrics_history)[-3:]
# 计算平均任务时间的变化
recent_avg_times = [m["avg_task_time"] for m in recent_metrics]
if len(recent_avg_times) >= 2:
time_trend = recent_avg_times[-1] / recent_avg_times[0] if recent_avg_times[0] > 0 else 1.0
# 如果任务时间增加(可能是资源争抢),减少并行度
if time_trend > 1.1: # 时间增加10%以上
new_parallelism = max(self.min_parallelism, self.current_parallelism - 1)
print(f"[Adaptive] 检测到性能下降,减少并行度: {self.current_parallelism} -> {new_parallelism}")
self.current_parallelism = new_parallelism
# 如果任务时间减少且成功率保持,增加并行度
elif time_trend < 0.9 and self.performance_metrics.success_rate > 0.95:
new_parallelism = min(self.max_parallelism, self.current_parallelism + 1)
print(f"[Adaptive] 检测到性能提升,增加并行度: {self.current_parallelism} -> {new_parallelism}")
self.current_parallelism = new_parallelism
# 如果成功率下降,减少并行度
if self.performance_metrics.success_rate < 0.9:
new_parallelism = max(self.min_parallelism, self.current_parallelism - 1)
print(f"[Adaptive] 检测到成功率下降,减少并行度: {self.current_parallelism} -> {new_parallelism}")
self.current_parallelism = new_parallelism三、生产级并行化Agent系统
3.1 完整的并行化工作流系统
python
# production_parallel_agent.py
import asyncio
from typing import List, Dict, Any, Optional
from datetime import datetime, timedelta
import uuid
import logging
from logging.handlers import RotatingFileHandler
from concurrent.futures import TimeoutError as FutureTimeoutError
import psutil
import json
from langgraph.graph import StateGraph, END
from langgraph.checkpoint import MemorySaver
from pydantic import BaseModel, Field
from redis import Redis
import msgpack
# ========== 配置日志 ==========
def setup_logger():
logger = logging.getLogger("parallel_agent")
logger.setLevel(logging.INFO)
# 文件处理器
file_handler = RotatingFileHandler(
"parallel_agent.log",
maxBytes=10*1024*1024, # 10MB
backupCount=5
)
file_handler.setFormatter(
logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
)
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setFormatter(
logging.Formatter('%(levelname)s - %(message)s')
)
logger.addHandler(file_handler)
logger.addHandler(console_handler)
return logger
logger = setup_logger()
# ========== Redis缓存 ==========
class ResultCache:
"""结果缓存,支持并行任务结果共享"""
def __init__(self, redis_url="redis://localhost:6379"):
self.redis = Redis.from_url(redis_url, decode_responses=False)
self.expiry = 3600 # 1小时
def store_result(self, task_id: str, result: Any, dependencies: List[str] = None):
"""存储任务结果"""
cache_key = f"task_result:{task_id}"
cache_data = {
"result": msgpack.packb(result),
"timestamp": datetime.now().isoformat(),
"dependencies": dependencies or []
}
self.redis.setex(
cache_key,
self.expiry,
msgpack.packb(cache_data)
)
logger.info(f"缓存任务结果: {task_id}")
def get_result(self, task_id: str) -> Optional[Any]:
"""获取任务结果"""
cache_key = f"task_result:{task_id}"
cached = self.redis.get(cache_key)
if cached:
data = msgpack.unpackb(cached)
logger.info(f"从缓存获取任务结果: {task_id}")
return msgpack.unpackb(data["result"])
return None
def check_dependencies_ready(self, dependencies: List[str]) -> bool:
"""检查依赖是否都就绪"""
if not dependencies:
return True
for dep in dependencies:
if not self.redis.exists(f"task_result:{dep}"):
return False
return True
# ========== 监控系统 ==========
class ParallelExecutionMonitor:
"""并行执行监控器"""
def __init__(self):
self.metrics = {
"total_tasks": 0,
"completed_tasks": 0,
"failed_tasks": 0,
"avg_execution_time": 0.0,
"parallelism_levels": [],
"resource_usage": []
}
self.start_time = datetime.now()
def record_task_start(self, task_id: str, parallelism: int):
"""记录任务开始"""
self.metrics["total_tasks"] += 1
self.metrics["parallelism_levels"].append({
"timestamp": datetime.now().isoformat(),
"parallelism": parallelism,
"task_id": task_id
})
# 记录资源使用
cpu_percent = psutil.cpu_percent(interval=0.1)
memory_percent = psutil.virtual_memory().percent
self.metrics["resource_usage"].append({
"timestamp": datetime.now().isoformat(),
"cpu_percent": cpu_percent,
"memory_percent": memory_percent,
"active_tasks": parallelism
})
def record_task_completion(self, task_id: str, execution_time: float, success: bool):
"""记录任务完成"""
if success:
self.metrics["completed_tasks"] += 1
else:
self.metrics["failed_tasks"] += 1
# 更新平均执行时间
total_time = self.metrics["avg_execution_time"] * (self.metrics["completed_tasks"] - 1)
self.metrics["avg_execution_time"] = (total_time + execution_time) / self.metrics["completed_tasks"]
logger.info(f"任务完成: {task_id}, 耗时: {execution_time:.2f}s, 成功: {success}")
def get_performance_report(self) -> Dict[str, Any]:
"""获取性能报告"""
total_time = (datetime.now() - self.start_time).total_seconds()
return {
"execution_summary": {
"total_duration": total_time,
"tasks_per_second": self.metrics["completed_tasks"] / total_time if total_time > 0 else 0,
"success_rate": self.metrics["completed_tasks"] / self.metrics["total_tasks"] if self.metrics["total_tasks"] > 0 else 0,
"avg_parallelism": sum(p["parallelism"] for p in self.metrics["parallelism_levels"]) / len(self.metrics["parallelism_levels"]) if self.metrics["parallelism_levels"] else 0
},
"resource_metrics": {
"avg_cpu_usage": sum(r["cpu_percent"] for r in self.metrics["resource_usage"]) / len(self.metrics["resource_usage"]) if self.metrics["resource_usage"] else 0,
"avg_memory_usage": sum(r["memory_percent"] for r in self.metrics["resource_usage"]) / len(self.metrics["resource_usage"]) if self.metrics["resource_usage"] else 0,
"peak_parallelism": max(p["parallelism"] for p in self.metrics["parallelism_levels"]) if self.metrics["parallelism_levels"] else 0
},
"timeline": {
"start_time": self.start_time.isoformat(),
"end_time": datetime.now().isoformat(),
"parallelism_history": self.metrics["parallelism_levels"][-100:] # 最近100条记录
}
}
# ========== 生产级并行Agent ==========
class ProductionParallelAgent:
"""生产级并行Agent"""
def __init__(self,
llm,
cache_url="redis://localhost:6379",
max_parallelism=8,
enable_monitoring=True):
self.llm = llm
self.cache = ResultCache(cache_url)
self.monitor = ParallelExecutionMonitor() if enable_monitoring else None
self.max_parallelism = max_parallelism
# 创建工作流
self.workflow = self._create_production_workflow()
logger.info(f"生产级并行Agent初始化完成,最大并行度: {max_parallelism}")
def _create_production_workflow(self) -> StateGraph:
"""创建生产级工作流"""
class ProductionState(BaseModel):
"""生产环境状态"""
request_id: str = Field(default_factory=lambda: str(uuid.uuid4()))
user_query: str
task_graph: Dict[str, Dict] = Field(default_factory=dict)
execution_queue: List[str] = Field(default_factory=list)
completed_tasks: Dict[str, Any] = Field(default_factory=dict)
failed_tasks: Dict[str, str] = Field(default_factory=dict)
final_result: Optional[str] = None
priority: int = 1 # 任务优先级
timeout_seconds: int = 60
workflow = StateGraph(ProductionState)
# 添加节点
workflow.add_node("validate_request", self._validate_request)
workflow.add_node("build_task_graph", self._build_task_graph)
workflow.add_node("schedule_tasks", self._schedule_tasks)
workflow.add_node("execute_parallel", self._execute_parallel)
workflow.add_node("handle_failures", self._handle_failures)
workflow.add_node("assemble_results", self._assemble_results)
# 设置边和条件边
workflow.set_entry_point("validate_request")
workflow.add_edge("validate_request", "build_task_graph")
workflow.add_edge("build_task_graph", "schedule_tasks")
workflow.add_edge("schedule_tasks", "execute_parallel")
# 条件边:根据执行结果决定下一步
workflow.add_conditional_edges(
"execute_parallel",
self._check_execution_status,
{
"all_success": "assemble_results",
"has_failures": "handle_failures",
"timeout": "handle_failures"
}
)
workflow.add_edge("handle_failures", "assemble_results")
workflow.add_edge("assemble_results", END)
return workflow
async def _validate_request(self, state):
"""验证请求"""
logger.info(f"验证请求: {state.request_id}")
if not state.user_query or len(state.user_query.strip()) == 0:
raise ValueError("用户查询不能为空")
if len(state.user_query) > 10000:
logger.warning(f"请求 {state.request_id} 查询过长: {len(state.user_query)} 字符")
return state
async def _build_task_graph(self, state):
"""构建任务依赖图"""
logger.info(f"构建任务图: {state.request_id}")
# 分析查询,构建任务图
analysis = await self._analyze_query_for_parallelism(state.user_query)
# 创建任务节点
task_graph = {}
for i, task_desc in enumerate(analysis.get("subtasks", [])):
task_id = f"task_{state.request_id}_{i}"
task_graph[task_id] = {
"description": task_desc,
"dependencies": analysis.get("dependencies", {}).get(str(i), []),
"estimated_time": analysis.get("estimated_times", {}).get(str(i), 5),
"priority": state.priority,
"retry_count": 0,
"max_retries": 2
}
state.task_graph = task_graph
logger.info(f"任务图构建完成: {len(task_graph)} 个任务")
return {"task_graph": task_graph}
async def _schedule_tasks(self, state):
"""调度任务,确定执行顺序"""
# 拓扑排序,确定任务执行顺序
from collections import deque
# 计算入度
in_degree = {task_id: 0 for task_id in state.task_graph}
for task_id, task_info in state.task_graph.items():
for dep in task_info["dependencies"]:
if dep in in_degree:
in_degree[dep] += 1
# 拓扑排序
queue = deque([task_id for task_id, degree in in_degree.items() if degree == 0])
execution_order = []
while queue:
task_id = queue.popleft()
execution_order.append(task_id)
# 减少依赖该任务的其他任务的入度
for other_id, other_info in state.task_graph.items():
if task_id in other_info["dependencies"]:
in_degree[other_id] -= 1
if in_degree[other_id] == 0:
queue.append(other_id)
# 如果还有任务剩余,说明有环
if len(execution_order) != len(state.task_graph):
logger.error(f"任务图中有循环依赖: {state.request_id}")
# 简化处理:忽略依赖,按任意顺序执行
execution_order = list(state.task_graph.keys())
state.execution_queue = execution_order
logger.info(f"任务调度完成: {len(execution_order)} 个任务")
return {"execution_queue": execution_order}
async def _execute_parallel(self, state):
"""并行执行任务"""
logger.info(f"开始并行执行: {state.request_id}")
if self.monitor:
self.monitor.record_task_start(state.request_id, len(state.execution_queue))
# 执行任务
start_time = datetime.now()
results = await self._execute_task_batch(state)
execution_time = (datetime.now() - start_time).total_seconds()
# 更新状态
for task_id, result in results.items():
if result.get("success"):
state.completed_tasks[task_id] = result["result"]
else:
state.failed_tasks[task_id] = result.get("error", "未知错误")
if self.monitor:
self.monitor.record_task_completion(
state.request_id,
execution_time,
len(state.failed_tasks) == 0
)
logger.info(f"并行执行完成: {len(results)} 个任务, 耗时: {execution_time:.2f}s")
return {
"completed_tasks": state.completed_tasks,
"failed_tasks": state.failed_tasks
}
async def _execute_task_batch(self, state) -> Dict[str, Dict]:
"""执行一批任务"""
# 分组:可以并行执行的任务 vs 需要等待依赖的任务
executable_tasks = []
waiting_tasks = []
for task_id in state.execution_queue:
task_info = state.task_graph[task_id]
# 检查依赖是否都完成
deps_ready = all(
dep in state.completed_tasks
for dep in task_info["dependencies"]
)
if deps_ready and task_id not in state.completed_tasks and task_id not in state.failed_tasks:
executable_tasks.append(task_id)
else:
waiting_tasks.append(task_id)
# 限制并行度
max_parallel = min(self.max_parallelism, len(executable_tasks))
current_batch = executable_tasks[:max_parallel]
# 并行执行当前批次
tasks = []
for task_id in current_batch:
task = asyncio.create_task(
self._execute_single_task(task_id, state.task_graph[task_id], state.user_query)
)
tasks.append((task_id, task))
# 等待所有任务完成
results = {}
for task_id, task in tasks:
try:
result = await asyncio.wait_for(task, timeout=state.timeout_seconds)
results[task_id] = result
except asyncio.TimeoutError:
results[task_id] = {
"success": False,
"error": f"任务执行超时 ({state.timeout_seconds}s)",
"result": None
}
except Exception as e:
results[task_id] = {
"success": False,
"error": str(e),
"result": None
}
return results
async def _execute_single_task(self, task_id: str, task_info: Dict, user_query: str) -> Dict:
"""执行单个任务"""
logger.debug(f"执行任务: {task_id}")
try:
# 检查缓存
cached_result = self.cache.get_result(task_id)
if cached_result:
return {
"success": True,
"result": cached_result,
"cached": True
}
# 执行任务
# 这里根据任务描述执行不同的逻辑
result = await self._execute_by_task_type(task_info["description"], user_query)
# 缓存结果
self.cache.store_result(task_id, result, task_info["dependencies"])
return {
"success": True,
"result": result,
"cached": False
}
except Exception as e:
logger.error(f"任务执行失败 {task_id}: {e}")
return {
"success": False,
"error": str(e),
"result": None
}
async def _execute_by_task_type(self, description: str, user_query: str) -> Any:
"""根据任务类型执行"""
# 模拟不同类型的任务执行
if "搜索" in description or "查找" in description:
return await self._execute_search_task(user_query)
elif "分析" in description or "处理" in description:
return await self._execute_analysis_task(user_query)
elif "总结" in description or "汇总" in description:
return await self._execute_summary_task(user_query)
else:
# 默认使用LLM处理
prompt = f"任务: {description}\n\n相关上下文: {user_query}\n\n请完成任务。"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return response.content
async def _execute_search_task(self, query: str) -> str:
"""执行搜索任务(模拟)"""
await asyncio.sleep(1) # 模拟网络延迟
return f"搜索 '{query}' 的结果: 相关信息1, 相关信息2, 相关信息3"
async def _execute_analysis_task(self, query: str) -> str:
"""执行分析任务"""
prompt = f"请分析以下内容: {query}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"分析结果: {response.content}"
async def _execute_summary_task(self, query: str) -> str:
"""执行总结任务"""
prompt = f"请总结以下内容: {query}"
response = await self.llm.ainvoke([HumanMessage(content=prompt)])
return f"总结: {response.content}"
def _check_execution_status(self, state):
"""检查执行状态"""
if len(state.failed_tasks) == 0:
return "all_success"
elif datetime.now() - state.get("execution_start_time", datetime.now()) > timedelta(seconds=state.timeout_seconds):
return "timeout"
else:
return "has_failures"
async def _handle_failures(self, state):
"""处理失败任务"""
logger.warning(f"处理失败任务: {len(state.failed_tasks)} 个")
# 重试失败的任務(简化处理)
for task_id, error in list(state.failed_tasks.items()):
task_info = state.task_graph.get(task_id, {})
if task_info.get("retry_count", 0) < task_info.get("max_retries", 2):
logger.info(f"重试任务: {task_id}")
try:
result = await self._execute_single_task(task_id, task_info, state.user_query)
if result["success"]:
state.completed_tasks[task_id] = result["result"]
del state.failed_tasks[task_id]
task_info["retry_count"] = task_info.get("retry_count", 0) + 1
else:
logger.error(f"重试失败: {task_id}, 错误: {result['error']}")
except Exception as e:
logger.error(f"重试异常: {task_id}, 错误: {e}")
return state
async def _assemble_results(self, state):
"""组装最终结果"""
logger.info(f"组装结果: {state.request_id}")
# 收集所有任务结果
all_results = []
for task_id, result in state.completed_tasks.items():
task_desc = state.task_graph.get(task_id, {}).get("description", "")
all_results.append(f"任务 [{task_desc}]:\n{result}")
# 使用LLM生成最终回答
if all_results:
assembly_prompt = f"""
用户原始查询: {state.user_query}
以下是并行执行的多个任务的结果:
{chr(10).join(all_results)}
请将这些结果整合成一个连贯、完整的回答,直接面向用户。
"""
response = await self.llm.ainvoke([
SystemMessage(content="你是结果整合专家,擅长将多个来源的信息整合成连贯的回答。"),
HumanMessage(content=assembly_prompt)
])
state.final_result = response.content
else:
state.final_result = "抱歉,无法生成回答。所有任务都失败了。"
# 如果有失败的任务,添加说明
if state.failed_tasks:
state.final_result += f"\n\n注意:部分任务执行失败,可能影响回答的完整性。"
logger.info(f"结果组装完成: {state.request_id}")
return {"final_result": state.final_result}
async def _analyze_query_for_parallelism(self, query: str) -> Dict[str, Any]:
"""分析查询,确定并行策略"""
prompt = f"""
分析以下用户查询,确定如何将其拆分为可以并行执行的子任务:
查询:{query}
请提供:
1. 可以拆分为几个子任务?
2. 每个子任务的描述
3. 任务之间的依赖关系
4. 每个任务的预估执行时间(1-10,1最快)
以JSON格式返回分析结果。
"""
response = await self.llm.ainvoke([
SystemMessage(content="你是并行任务规划专家。"),
HumanMessage(content=prompt)
])
try:
return json.loads(response.content)
except:
# 默认分析
return {
"subtasks": [
f"处理查询的核心部分: {query}",
f"收集相关信息: {query}",
f"分析和推理: {query}"
],
"dependencies": {
"0": [], # 第一个任务无依赖
"1": [], # 第二个任务无依赖
"2": ["0", "1"] # 第三个任务依赖前两个
},
"estimated_times": {"0": 3, "1": 5, "2": 4}
}
async def process(self, query: str, priority: int = 1) -> Dict[str, Any]:
"""处理查询"""
logger.info(f"开始处理查询: {query[:50]}...")
# 初始化状态
initial_state = {
"user_query": query,
"priority": priority,
"timeout_seconds": 30
}
# 编译工作流
app = self.workflow.compile()
# 执行工作流
try:
final_state = await app.ainvoke(initial_state)
result = {
"success": True,
"request_id": final_state.get("request_id"),
"result": final_state.get("final_result"),
"completed_tasks": len(final_state.get("completed_tasks", {})),
"failed_tasks": len(final_state.get("failed_tasks", {})),
"total_tasks": len(final_state.get("task_graph", {}))
}
# 添加监控报告
if self.monitor:
result["performance_report"] = self.monitor.get_performance_report()
logger.info(f"查询处理完成: {result['request_id']}")
return result
except Exception as e:
logger.error(f"查询处理失败: {e}")
return {
"success": False,
"error": str(e),
"result": None
}
# ========== 使用示例 ==========
async def production_example():
"""生产环境示例"""
from langchain_openai import ChatOpenAI
# 初始化LLM
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
# 创建生产级Agent
agent = ProductionParallelAgent(
llm=llm,
max_parallelism=4,
enable_monitoring=True
)
# 测试查询
test_queries = [
"详细介绍人工智能的历史发展、当前应用和未来趋势",
"从技术、经济、社会三个角度分析区块链技术的优缺点",
"比较Python、Java、C++在性能、生态、学习曲线方面的差异,并给出学习建议"
]
results = []
for query in test_queries:
print(f"\n{'='*60}")
print(f"处理查询: {query[:50]}...")
result = await agent.process(query, priority=2)
if result["success"]:
print(f"成功! 请求ID: {result['request_id']}")
print(f"完成任务: {result['completed_tasks']}/{result['total_tasks']}")
print(f"结果摘要: {result['result'][:200]}...")
if "performance_report" in result:
report = result["performance_report"]
print(f"执行时间: {report['execution_summary']['total_duration']:.2f}s")
print(f"任务/秒: {report['execution_summary']['tasks_per_second']:.2f}")
print(f"成功率: {report['execution_summary']['success_rate']:.1%}")
else:
print(f"失败: {result['error']}")
results.append(result)
return results
if __name__ == "__main__":
# 运行生产示例
asyncio.run(production_example())四、性能优化与最佳实践
4.1 性能优化技巧
python
# performance_optimization.py
import asyncio
from typing import List, Dict, Any
import time
from functools import lru_cache
import hashlib
class ParallelOptimization:
"""并行化性能优化"""
@staticmethod
def batch_processing(items: List[Any], batch_size: int = 10):
"""批处理优化"""
for i in range(0, len(items), batch_size):
yield items[i:i + batch_size]
@staticmethod
def dynamic_batch_size(
total_items: int,
avg_processing_time: float,
target_throughput: float
) -> int:
"""动态计算批处理大小"""
# 根据目标吞吐量和平均处理时间计算
if avg_processing_time == 0:
return 10
optimal_batch = int(target_throughput * avg_processing_time)
return max(1, min(optimal_batch, 100)) # 限制在1-100之间
@staticmethod
def load_balancing(tasks: List[Dict], workers: int) -> List[List[Dict]]:
"""负载均衡分配任务"""
# 根据任务预估时间进行负载均衡
sorted_tasks = sorted(tasks, key=lambda x: x.get("estimated_time", 1), reverse=True)
worker_loads = [[] for _ in range(workers)]
worker_times = [0] * workers
for task in sorted_tasks:
# 分配给当前负载最轻的worker
min_worker = worker_times.index(min(worker_times))
worker_loads[min_worker].append(task)
worker_times[min_worker] += task.get("estimated_time", 1)
return worker_loads
@staticmethod
@lru_cache(maxsize=1000)
def cached_execution(task_id: str, input_hash: str):
"""缓存执行结果"""
# 输入哈希用于识别相同的输入
return f"Cached result for {task_id}: {input_hash}"
@staticmethod
def compute_input_hash(input_data: Any) -> str:
"""计算输入数据的哈希值"""
if isinstance(input_data, str):
data_str = input_data
else:
try:
data_str = json.dumps(input_data, sort_keys=True)
except:
data_str = str(input_data)
return hashlib.md5(data_str.encode()).hexdigest()
class ResourceMonitor:
"""资源监控与限制"""
def __init__(self,
max_cpu_percent: float = 80.0,
max_memory_percent: float = 80.0):
self.max_cpu = max_cpu_percent
self.max_memory = max_memory_percent
self.psutil = __import__('psutil')
def check_resources(self) -> bool:
"""检查资源是否可用"""
cpu_percent = self.psutil.cpu_percent(interval=0.1)
memory_percent = self.psutil.virtual_memory().percent
return cpu_percent < self.max_cpu and memory_percent < self.max_memory
def get_optimal_parallelism(self, base_parallelism: int) -> int:
"""根据资源使用情况确定最优并行度"""
if not self.check_resources():
# 资源紧张,减少并行度
return max(1, base_parallelism // 2)
cpu_percent = self.psutil.cpu_percent(interval=0.1)
memory_percent = self.psutil.virtual_memory().percent
# 根据资源使用率调整
cpu_factor = (100 - cpu_percent) / 100
memory_factor = (100 - memory_percent) / 100
adjustment_factor = min(cpu_factor, memory_factor)
return max(1, int(base_parallelism * adjustment_factor))五、总结与部署建议
5.1 关键总结
-
并行模式选择:
-
Map-Reduce:适合数据处理和分析任务
-
Fan-Out/Fan-In:适合多专家协同分析
-
流水线:适合有严格依赖关系的任务
-
竞速模式:适合需要快速响应的场景
-
-
性能关键点:
-
并行度调整:根据任务类型和资源情况动态调整
-
任务依赖管理:使用DAG(有向无环图)管理任务依赖
-
结果缓存:避免重复计算,提高效率
-
错误处理:实现重试机制和优雅降级
-
-
监控与调试:
-
实时监控任务执行状态
-
记录性能指标和资源使用情况
-
实现详细的日志记录
-
5.2 部署架构建议
python
# docker-compose.yml 示例
version: '3.8'
services:
# 主Agent服务
parallel-agent:
build: .
environment:
- REDIS_URL=redis://redis:6379
- MAX_PARALLELISM=8
- LOG_LEVEL=INFO
ports:
- "8000:8000"
depends_on:
- redis
- monitoring
# 缓存服务
redis:
image: redis:7-alpine
ports:
- "6379:6379"
volumes:
- redis_data:/data
# 监控服务
monitoring:
image: prom/prometheus:latest
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
ports:
- "9090:9090"
# 可视化面板
grafana:
image: grafana/grafana:latest
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/dashboards:/etc/grafana/provisioning/dashboards
ports:
- "3000:3000"
volumes:
redis_data:
prometheus_data:
grafana_data:5.3 快速开始
python
# quick_start.py
async def quick_example():
"""快速开始示例"""
from langchain_openai import ChatOpenAI
# 1. 创建基础Agent
llm = ChatOpenAI(temperature=0)
agent = ParallelAgent(llm=llm, max_parallelism=4)
# 2. 运行并行处理
result = await agent.run(
"请从技术实现、商业模式、用户体验三个角度分析在线教育平台的发展前景"
)
print(f"结果: {result}")
# 3. 使用Map-Reduce模式
from map_reduce_agent import DocumentAnalyzer
analyzer = DocumentAnalyzer(llm)
documents = ["文档1内容...", "文档2内容...", "文档3内容..."]
analysis_result = await analyzer.analyze_documents(documents)
print(f"文档分析结果: {analysis_result['final_report']}")
# 运行
if __name__ == "__main__":
asyncio.run(quick_example())这种基于LangGraph的并行化AI Agent设计模式,通过合理的任务分解、依赖管理、并行执行和结果聚合,可以显著提高复杂任务的执行效率。在实际应用中,需要根据具体业务场景选择合适的并行模式,并注意资源管理和错误处理。