1 导语
在构建AI Agent时,状态(State)是连接各个节点的灵魂。LangGraph 采用消息传递机制来驱动程序的运行,而 State 则是信息的载体。本文将深入探讨 LangGraph 中最基础也最核心的部分------State的定义模式设计 。通过学习本文,你将掌握如何利用字典和 TypedDict 构建可靠的图状态,理解节点间数据流动的底层逻辑,为开发复杂多代理系统打下坚实基础。
2 技术栈清单
- Python == 3.11.14
- langgraph == 1.0.5
- langchain-core == 1.2.7
- typing-extensions == 4.15.0
3 项目核心原理
LangGraph 的核心在于状态管理 。State 本质上是一个共享的数据结构,它在图中从左向右流动。每个节点执行完毕后,会将更新的部分"广播"给状态。默认情况下,状态更新采用覆盖机制 (Overwriting),但通过 Reducer 函数 (如 operator.add),我们可以实现更复杂的逻辑,例如消息的自动追加 。
在AI Agent应用程序的设计中,场景的复杂性直接决定了构建图的复杂度。例如,最简单的场景可能仅涉及一个大模型的问答流程,形式为:START -> Node -> END(其中大模型的交互逻辑被封装在Node中)。而更复杂的场景则可能涉及多个AI Agent的协同工作,包括多个分支和循环的构成。无论是简单还是复杂的图,LangGraph的价值永远不在于如何去定义节点,如何去定义边,而是在于如何有效管理各个节点的输入和输出,以保持图的持续运行状态 。LangGraph的底层图算法采用消息传递机制来定义和执行这些图中的交互流程,其中状态(State)组件扮演着关键的载体角色,负责在图的各个节点之间传递信息 。这也就意味着,LangGraph框架的核心在于State的有效使用和掌握。在复杂的应用中,State组件需要存储和管理的信息量会显著增加。核心功能如工具使用、记忆能力和人机交互等,都依赖State来实现和维护。所以,接下来我们对LangGragh框架的探索,都将紧密围绕State的实现和应用机制展开,这包括LangGraph内置封装好的工具/方法的使用,以及我们自定义构建功能时的实现方法。
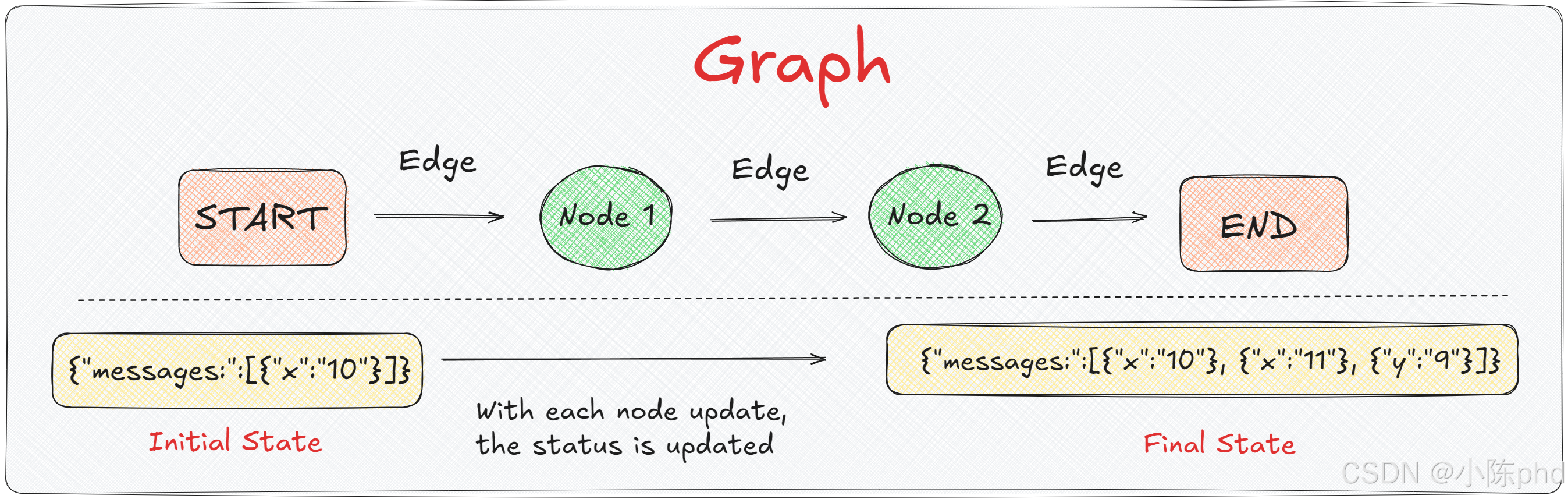
LangGraph构建的图中的每个节点都具备访问、读取和写入状态的权限。当某一个节点去修改状态时,它会将此信息广播到图中的所有其他节点。这种广播机制允许其他节点响应状态的变化并相应地调整其行为。如上图所示,从初始状态(Initial State)开始,其中包含了一条消息 { "x": "10" },随着消息在节点间通过边传递,每个节点根据其逻辑对状态进行更新。Node 1 和 Node 2 分别对状态进行了处理和变更,结果是在图的末端,我们得到了一个包含三条消息的最终状态 { "x": "10" }, { "x": "11" }, { "y": "9" }。**从开发的角度来看,State实际上是一个共享的数据结构。如上图所示,状态表现为一个简单的字典。通过对这个字典进行读写操作,可以实现自左而右的数据流动,从而构建一个可运行的图结构。那么根据前面学习的内容,我们可以利用这个流程来复现并理解图中的动态数据交换,整体的设计如下:
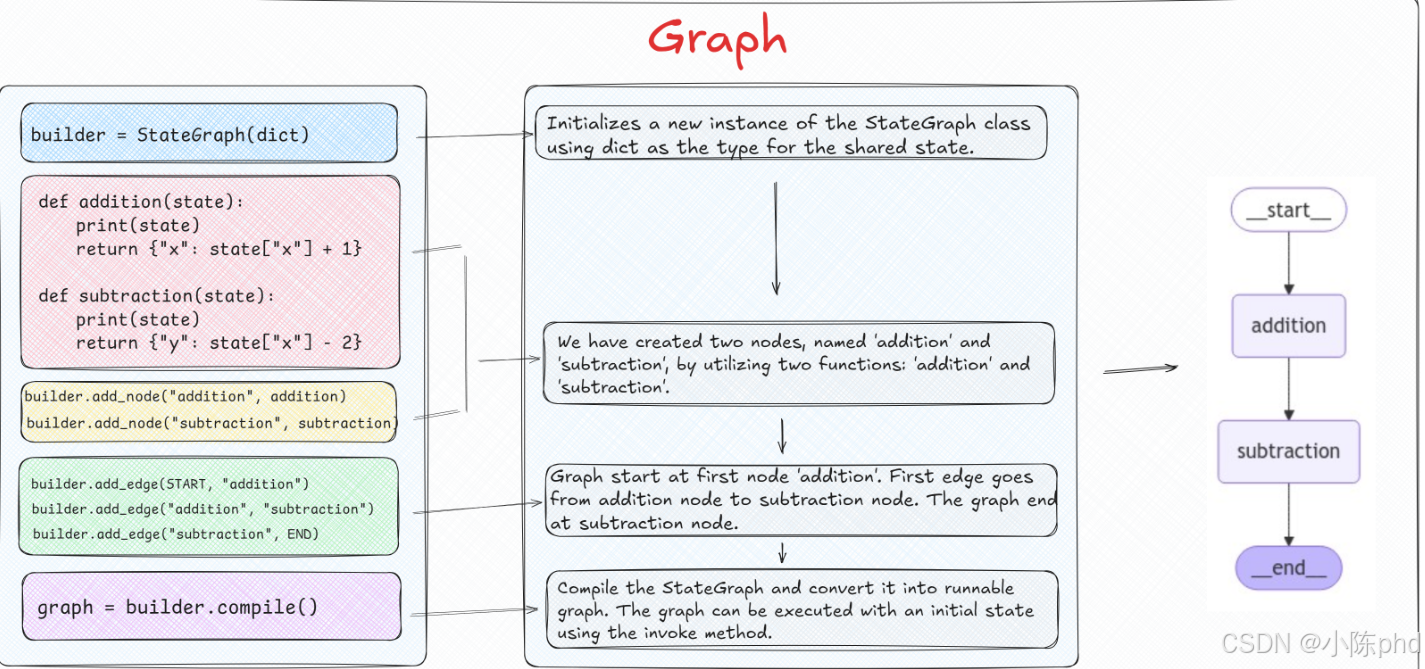
4 实战步骤
4.1 环境准备
在开始代码实现前,确保安装了核心依赖:
bash
pip install langgraph==1.0.5 typing-extensions==4.15.0
4.2 代码实现
我们通过两个示例对比"字典模式"与"TypedDict模式"。代码保存在 02-state-schema.py。
python
import operator
from typing import Annotated
from langgraph.graph import StateGraph, START, END
from typing_extensions import TypedDict
# 1. 使用字典类型定义状态 (灵活但缺乏约束)
def test_dict_state():
# 初始化一个以字典为状态模式的图
builder = StateGraph(dict)
def addition(state):
# 节点仅返回需要更新的部分,LangGraph 内部会自动合并
return {"x": state["x"] + 1}
def subtraction(state):
# 新增一个键 y
return {"y": state["x"] - 2}
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)
graph = builder.compile()
result = graph.invoke({"x": 10})
print(f"字典状态执行结果: {result}")
# 2. 使用 TypedDict 定义状态 (推荐:强类型约束)
class State(TypedDict):
x: int
y: int
def test_typeddict_state():
builder = StateGraph(State)
def addition(state: State):
# 关键逻辑:读取当前状态 x 并加 1
return {"x": state["x"] + 1}
def subtraction(state: State):
# 关键逻辑:基于更新后的 x 计算 y
return {"y": state["x"] - 2}
builder.add_node("addition", addition)
builder.add_node("subtraction", subtraction)
builder.add_edge(START, "addition")
builder.add_edge("addition", "subtraction")
builder.add_edge("subtraction", END)
graph = builder.compile()
result = graph.invoke({"x": 10})
print(f"TypedDict状态执行结果: {result}")
# 3. 使用 Reducer 实现列表追加 (进阶:解决状态覆盖问题)
class ReducerState(TypedDict):
# 使用 Annotated 标注该字段的更新方式为 operator.add (追加而非覆盖)
messages: Annotated[list[str], operator.add]
def test_reducer_state():
builder = StateGraph(ReducerState)
def node_1(state: ReducerState):
# 节点 1 返回第一条消息
return {"messages": ["这是来自节点1的消息"]}
def node_2(state: ReducerState):
# 节点 2 返回第二条消息
return {"messages": ["这是来自节点2的消息"]}
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_edge(START, "node_1")
builder.add_edge("node_1", "node_2")
builder.add_edge("node_2", END)
graph = builder.compile()
# 初始状态带有一条消息
result = graph.invoke({"messages": ["初始消息"]})
print(f"Reducer(追加模式)执行结果: {result}")
if __name__ == "__main__":
test_dict_state()
test_typeddict_state()
test_reducer_state()4.3 功能测试
运行脚本,观察两种模式下状态是如何在节点间传递并完成计算的。

5 核心代码解析
5.1 StateGraph(dict) 灵活模式
python
builder = StateGraph(dict)- 核心作用:定义了一个没有任何模式约束的图。
- 关联逻辑 :这种方式下,节点可以自由增加或修改任何键值。虽然灵活性极高,但在大型项目中容易导致键名冲突或类型错误。
5.2 TypedDict 强约束模式
划重点:这是工业级开发的标准选择。
python
class State(TypedDict):
x: int
y: int- 核心作用:通过 Python 的类型提示(Type Hinting)显式声明状态结构。
- 为何这样实现 :
StateGraph(State)允许 LangGraph 在编译阶段(Compile Time)进行初步校验。解析重点在于它规定了节点返回的字典必须符合声明的 Key 和 Value 类型,有效防止了动态运行时因为访问不存在的键而导致的中断。
5.3 Annotated 与 Reducer 机制
划重点:这是实现对话记忆(Memory)的底层技术。
python
messages: Annotated[list[str], operator.add]- 核心作用 :告诉 LangGraph,当多个节点向
messages写入数据时,不要覆盖,而是将结果add(追加)到一起。 - 关联逻辑:这使得我们可以轻松追踪对话历史。每个节点只需要返回当前产生的消息,LangGraph 会自动维护一个完整的消息链条。
6 效果验证
通过 graph.invoke() 传递初始状态后,系统会顺序执行各节点,并返回合并后的最终状态字典。
【图片占位符:核心功能运行效果截图 - 终端显示 x 与 y 的最终合并结果】
7 踩坑记录
7.1 KeyDoesNotExist 错误
- 错误现象 :
KeyError: 'x' - 根因分析 :在节点函数中尝试访问
state["x"],但初始输入或前置节点未提供该键。 - 解决方案 :确保在
invoke时传入完整的必要字段,或在TypedDict中通过total=False设置可选键。
7.2 节点返回值类型不匹配
- 错误现象 :状态更新后数据类型从
int变成了str。 - 根因分析 :节点返回了错误类型的值,虽然
TypedDict有提示但 Python 运行时默认不强制校验。 - 解决方案 :亲测有效 的方案是配合
Pydantic进行更严格的运行时校验,或者在节点内进行类型转换。
7.3 状态覆盖问题
- 错误现象:后一个节点的返回覆盖了前一个节点的同名键。
- 根因分析:LangGraph 默认使用"覆盖"机制。
- 解决方案 :若需保留历史记录(如对话历史),必须使用
Annotated配合operator.add等 Reducer 函数。
8 总结与扩展
掌握 State 的定义模式 是开启 LangGraph 高阶开发的大门。通过 TypedDict 我们建立了一套可预测的数据契约。划重点 :状态在任何给定时间只包含来自一个节点的更新信息,但 LangGraph 内部的合并机制让它看起来像一个全局共享池。下一步,我们将研究如何通过 Annotated 与 add_messages 实现对话历史的自动追溯。
欢迎评论区留言讨论核心主题相关的问题~