01:地理空间的意图觉醒------从传统分析到自主化探索
在数字化浪潮中,地理空间数据(Geospatial Data)已从简单的"导航底图"演变为支撑城市规划、商业选址及环境监测的底层决策基石。然而,尽管数据量呈爆炸式增长,普通用户与深度地理洞察之间,依然隔着一道难以逾越的技术"深水区"。
传统地图分析的"三座大山"
长期以来,地理空间任务的落地面临着极高的技术门槛。首先是数据获取的碎裂化 :用户常迷失在各类开放接口、坐标偏转(如WGS84与GCJ02转换)及混乱的格式清洗中,分析前的工作量往往占到了整体流程的70%。其次是专业技能的陡峭化 :传统的GIS软件(如ArcGIS、QGIS)界面繁冗,即便使用Python分析,也需精通Geopandas等十余个专业库,这让非技术背景的业务人员望而生畏。最后是成果落地的脱节化:将分析结论转化为一份交互式、符合美学的动态地图,往往涉及前后端深度联调,开发周期动辄以周计算。
概念引入:地图自动化自主化分析
为了重构这一生产关系,我们提出了**"地图自动化自主化分析"的概念。其核心逻辑在于利用大语言模型(LLM)的推理能力,驱动多智能体(Multi-Agents)协作系统**。分析过程不再是死板的脚本执行,而是一个具备"意图感知"的自主化过程。通过将复杂的GIS任务拆解为原子化的步骤,系统能够模拟专家团队,自动完成从数据找寻、空间计算到可视化配置的全生命周期管理。
核心价值:零代码开启空间智能
本系统的目标是将地理分析从"操作驱动"跨越到"意图驱动"。其核心价值在于实现GIS能力的民主化:用户只需输入一句自然语言------"分析北京市静安区咖啡馆的分布密度并找出竞争盲区",系统便能自主规划路径,动态调度各类专家智能体协同作战。
最终,用户无需触碰任何代码,即可获得一份深度地理洞察报告以及可直接交互的数字化地图。这种"零代码"的自主分析模式,正让地理空间数据从冷冰冰的坐标点,转化为每一个决策者都能信手拈来的智慧动力。
02:系统架构:多智能体协作的"神经中枢"
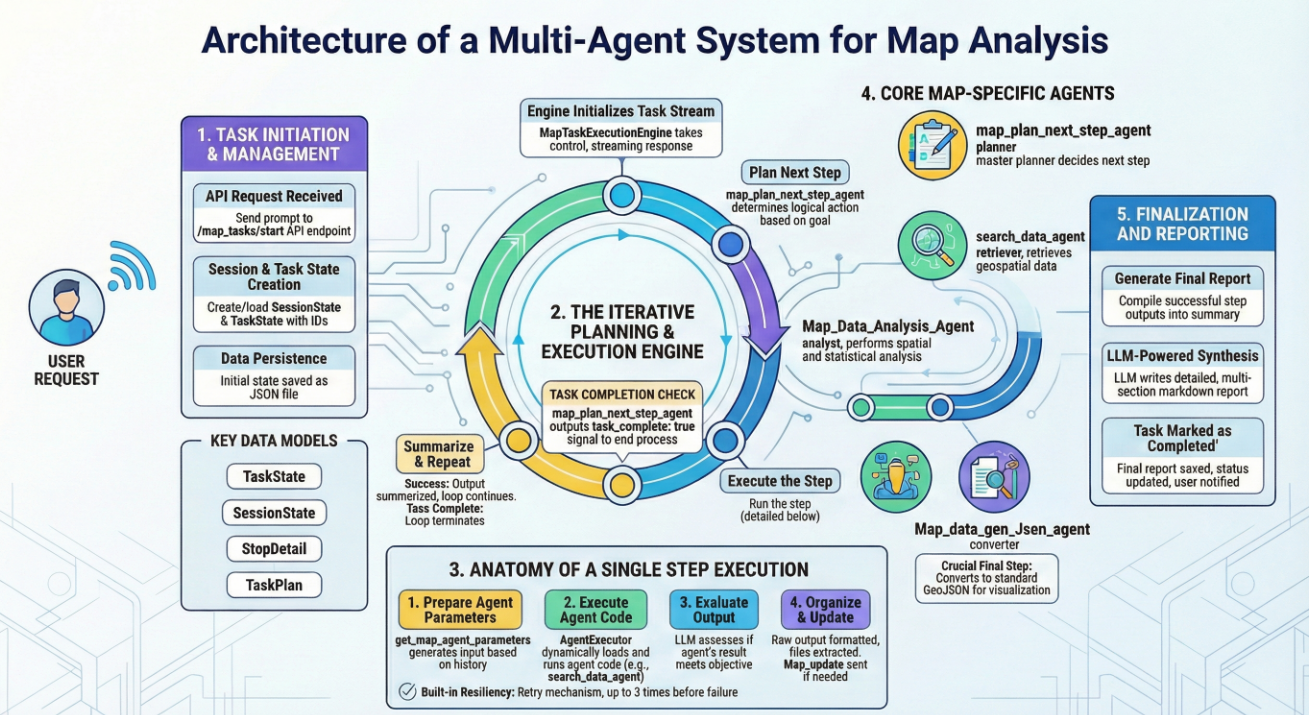
1. 记忆的容器:状态管理与持久化 (State & Persistence)
在多轮对话与复杂的任务执行中,最怕的是"断片"。地理分析往往涉及海量数据的处理,执行过程可能因为网络波动或用户暂时离开而中断。
我们的系统通过 SessionState(会话状态) 和 TaskState(任务状态) 构建了一套严密的记忆体系。
- SessionState 负责维护用户与系统之间的长时关系,它像是一本"日志总账",记录了该会话下产生的所有分析任务、历史对话及当前的活跃任务ID。
- TaskState 则是具体任务的"飞行记录仪"。从用户的一句原始指令开始,它便记录下每一个规划出的步骤(Steps)、每个步骤的输入输出、甚至是智能体执行时的心跳状态。
为了确保这些记忆不因服务器重启或进程崩溃而消失,系统采用了基于 JSON 的本地持久化方案 。每当任务状态发生变化------无论是新规划了一个步骤,还是某个智能体输出了中间结果,系统都会立即将其序列化并写入磁盘。这种设计赋予了系统"断点续传"的能力:用户刷新页面或断网重连后,引擎能迅速从 map_agents_step_tasks 目录中读取状态,无缝衔接之前的分析进度。
2. 资源总管:AgentManager (智能体资源库)
在系统中,智能体(Agent)被视为一种"可插拔"的专业资源。AgentManager 充当了"资源总管"的角色。
它并不直接参与分析,而是负责管理一套动态的智能体索引(通常加载自 enabled_agents.json)。每一个智能体都有其特定的"专家标签":有的擅长搜索矢量数据,有的专攻空间缓冲区分析,有的则负责将分析结果封装为地图配置。当任务引擎需要执行某一特定动作时,AgentManager 会根据名称精准定位对应的代码路径(code_path)和参数规范,确保正确的工具被交到正确的手中。
3. 调度心脏:MapTaskExecutionEngine (执行引擎)
如果说状态是记忆,资源库是工具,那么 MapTaskExecutionEngine 就是整套系统的"调度心脏"。
它的核心职责是管理一个**流式响应(Streaming)**的生命周期。不同于传统的"请求-响应"模式,地理分析任务执行时间长、反馈信息多。执行引擎通过异步生成器(AsyncGenerator),将任务进度以 NDJSON(换行分隔的 JSON)格式实时推送到前端。
从任务初始化的 pending,到执行中的 running,再到最终报告生成的 completed,执行引擎精密地控制着状态机的流转。它还内置了超时检测机制,就像一名严格的监工,确保那些卡死的任务不会无休止地占用系统资源。
4. 逻辑大脑:LLM 驱动的规划者
整个架构最神奇的地方在于,它没有预设任何死板的流程图。这一切的背后,是基于 ChatOpenAI 构建的"逻辑推理大脑"。
这个"大脑"不再只是陪人聊天,而是被赋予了决策权。它通过感知当前的"数据索引"和"知识库",动态地回答三个问题:
- "现在在哪?"(分析用户当前的需求和对话历史)
- "下一步去哪?"(调用规划智能体,决定下一个执行步骤)
- "做对了吗?"(调用评估逻辑,对智能体的输出进行质量检查)
通过这种 LLM 驱动的迭代式规划模式,系统展现出了一种惊人的灵活性:如果数据检索失败,它会尝试更换搜索策略;如果分析结果不符合预期,它会调整参数重新执行。这种"思考-执行-反馈"的闭环,正是多智能体架构优于传统自动化脚本的关键所在。
03:核心逻辑解析------多智能体协作的"神经中枢"
在 EmberTrace AI 的地图分析框架中,MapTaskExecutionEngine 是整个系统的"神经中枢"。它不仅负责调度不同的智能体,还必须在多轮迭代中处理复杂的流式响应、任务状态持久化以及容错重试。本节将深度解析实现这一自动化流程的关键代码逻辑,带你领略"意图驱动"背后的技术细节。
1. 动态迭代规划:单步前进的智慧
与传统的预定义工作流不同,本框架采用了迭代式任务规划(Iterative Planning)。系统不会一次性生成所有步骤,因为地图分析的过程往往具有高度的不确定性(例如:第一步搜索到的数据量多寡,直接决定了第二步是否需要进行空间聚合或抽样)。
通过 map_plan_next_step_agent,系统会根据"用户原始需求"和"当前已完成任务的摘要"实时决定下一步行动。
python
# 迭代式任务计划器的核心逻辑
def map_plan_next_step_agent(user_request: str, completed_steps_summary: str):
# 引导LLM根据当前进度,规划最合理的一步
prompt = f"""
你是一个地图分析多智能体系统的单步任务规划器。
基于用户的总体目标和已完成任务的总结,决定接下来的【唯一】一个步骤。
用户总体需求: "{user_request}"
已完成步骤总结: {completed_steps_summary if completed_steps_summary else "尚未完成任何步骤"}
输出格式要求(JSON):
- 如果需要继续:{{"task_complete": false, "step": {{"step_name": "...", "step_description": "...", "agent_name": "..."}}}}
- 如果已完成:{{"task_complete": true, "final_summary": "..."}}
"""
# 逻辑实现:调用 LLM (如 GPT-4) 并解析返回的 JSON 响应
# ...这种"走一步看一步"的策略确保了任务链的灵活性。例如,当 search_data_agent 发现本地数据库没有相关地理数据时,规划器会自动插入一个"Web爬虫"或"API请求"步骤,而无需预先人工干预。
2. 执行引擎:闭环控制的流水线
执行引擎的核心函数是 execute_and_evaluate_step。这是一个典型的 "Plan-Execute-Evaluate" (规划-执行-评估) 闭环。它负责管理一个步骤的完整生命周期:参数准备、代码动态执行、结果整理及质量评估。
核心执行循环逻辑:
python
async def execute_and_evaluate_step(self, request: Request, task_state: TaskState, step: StepDetail, yield_and_save):
MAX_RETRIES = 3 # 最大重试次数
for attempt in range(MAX_RETRIES):
# 1. 动态参数提取:根据上下文和上一步输出,为当前智能体准备精准输入
parameters = await asyncio.to_thread(
get_map_agent_parameters, f"{step.step_name}: {step.step_description}",
last_output, history_summary, task_state.prompt
)
# 2. 智能体代码执行:执行对应的 Python 插件脚本
result = await self.agent_executor.execute_agent(step.agent_name, parameters.get(step.agent_name, {}))
# 3. 结果评估:由 LLM 作为"质量守门员"判断输出是否符合步骤目标
evaluation = await asyncio.to_thread(evaluate_map_agent_output, str(result), task_state.prompt, step.step_description)
# 4. 结果整理:将原始输出转化为用户易读的报告及结构化文件路径
organized_output = await asyncio.to_thread(organize_map_agent_output, str(result), task_state.prompt, step.step_description)
# 5. 状态更新与反馈循环
if evaluation.get("evaluation") != "不符合预期":
step.status = StepStatus.COMPLETED
step.output = organized_output.get("report")
return # 执行成功,跳出重试循环
else:
# 如果评估不通过,记录反馈并在下一轮尝试中自动修正
step.current_status_text = f"评估失败 (尝试 {attempt + 1}/{MAX_RETRIES}): {evaluation.get('feedback')}"
await asyncio.sleep(2) 在这个过程中,系统表现出了极高的容错性。如果某个地理计算智能体产生的 JSON 格式不规范,评估模块会给出具体反馈,系统会在下一次尝试中利用这些反馈自动修正参数重新发起调用。
3. 智能体的"手脚":动态代码加载机制
系统如何运行形态各异的 Agent 脚本?秘密在于 code_py_exec 函数。它利用 Python 的 importlib 机制,在运行时将磁盘上的 .py 文件动态加载为模块,并调用约定的 agent_run 入口函数。
python
def code_py_exec(file_path: str, input_dict: Dict) -> Dict:
try:
# 生成唯一模块名,避免冲突
module_name = f"agent_{uuid.uuid4().hex[:8]}"
spec = importlib.util.spec_from_file_location(module_name, file_path)
module = importlib.util.module_from_spec(spec)
sys.modules[module_name] = module
spec.loader.exec_module(module)
if hasattr(module, 'agent_run'):
# 统一的执行接口,实现真正的"代码驱动分析"
return module.agent_run(input_dict)
return {"error": "智能体文件中未找到 agent_run 函数"}
except Exception as e:
return {"error": f"执行失败: {str(e)}"}这种设计实现了控制流(Engine)与业务流(Agents)的深度解耦 。开发者只需编写遵循 agent_run(input_dict) 规范的独立脚本,框架就能自动将其纳入协作体系,无需修改任何核心代码。
4. 参数提取:连接上下文的"接力棒"
在多 Agent 协作中,最棘手的问题是"数据接力"。上一步生成的 .csv 结果文件或 GeoJSON 路径,如何准确传递给下一步的分析智能体?get_map_agent_parameters 函数充当了翻译官的角色。
它通过 LLM 读取任务历史摘要(History Summary)和上一步的详细输出,精准提取出当前步骤所需的参数。同时,为了保证安全性与执行稳定性,系统强制执行以下准则:
- 统一目录 :所有 Agent 必须在
./map_agents_task_execution_output下进行读写。 - 绝对路径:参数提取器会将所有涉及文件引用的地方转换为本地绝对路径,彻底规避因路径歧义导致的执行中断。

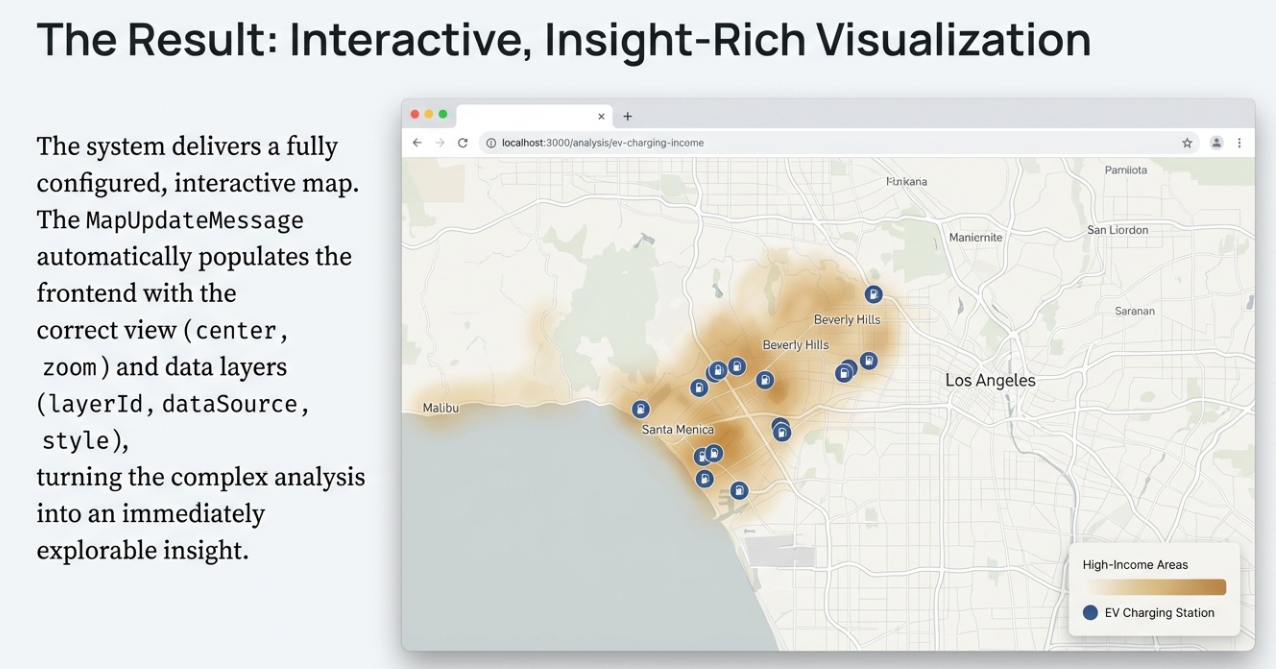
5. "最后一步"准则:确保可视化价值交付
地图分析的最终产物必须是直观的、可交互的。源代码中明确规定了 "Last Step Rule" :无论中间经历了多少次复杂的数据抓取或空间建模,任务计划的最后一步必须分配给 Map_data_gen_Json_agent。
该智能体负责将各种零散的分析结果(如 Shapefile、统计表)转化为前端可以直接渲染的配置:
- viewConfig:自动计算地图的中心点(center)和最合适的缩放级别(zoom)。
- layers:定义图层渲染逻辑(如热力图、聚合点、矢量多边形)及样式配置。
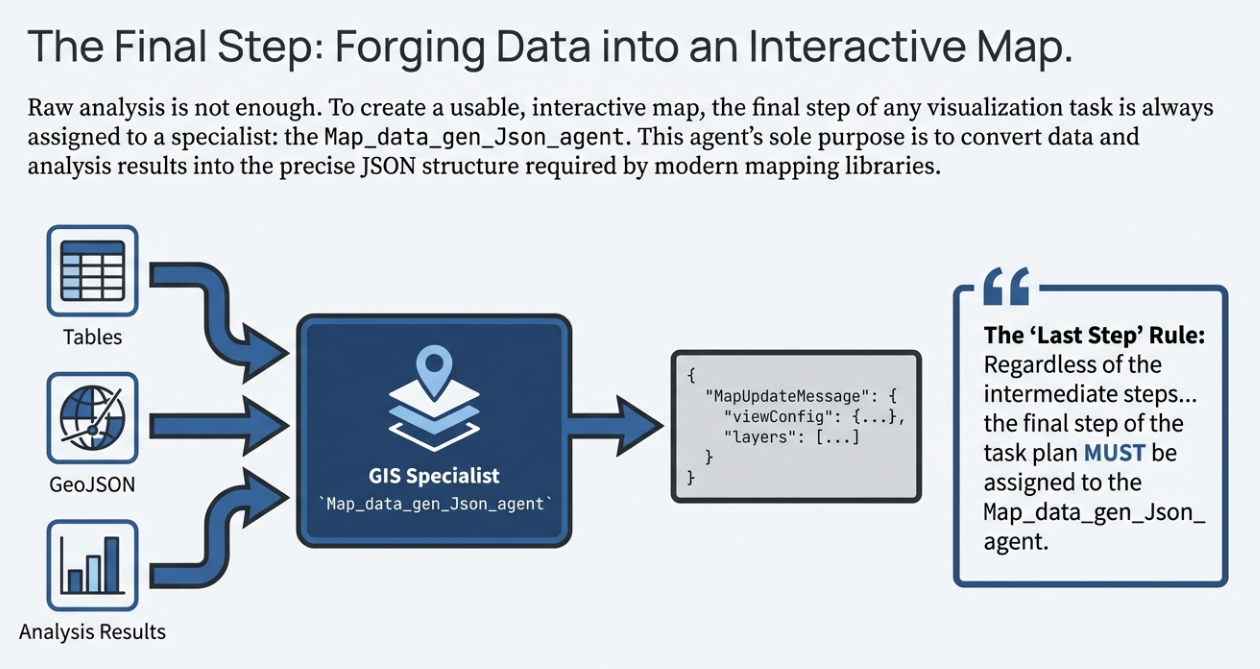
当执行引擎检测到 organized_output 中包含地图配置数据时,会通过 StreamMessage 即时将 map_update 消息推送到前端,让用户实时看到地图上亮起的分析结果。
6. 从执行到洞察:深度报告生成
当所有迭代结束,系统不只是简单地告知用户"任务完成",而是启动一个庞大的报告生成逻辑。它汇总所有步骤的执行轨迹、地理发现和生成的文件链接,利用 LLM 生成一份包含任务概述、步骤详解、空间洞察及核心结论的深度 Markdown 报告。
04:产品逻辑验证------多智能体协作的"实战"
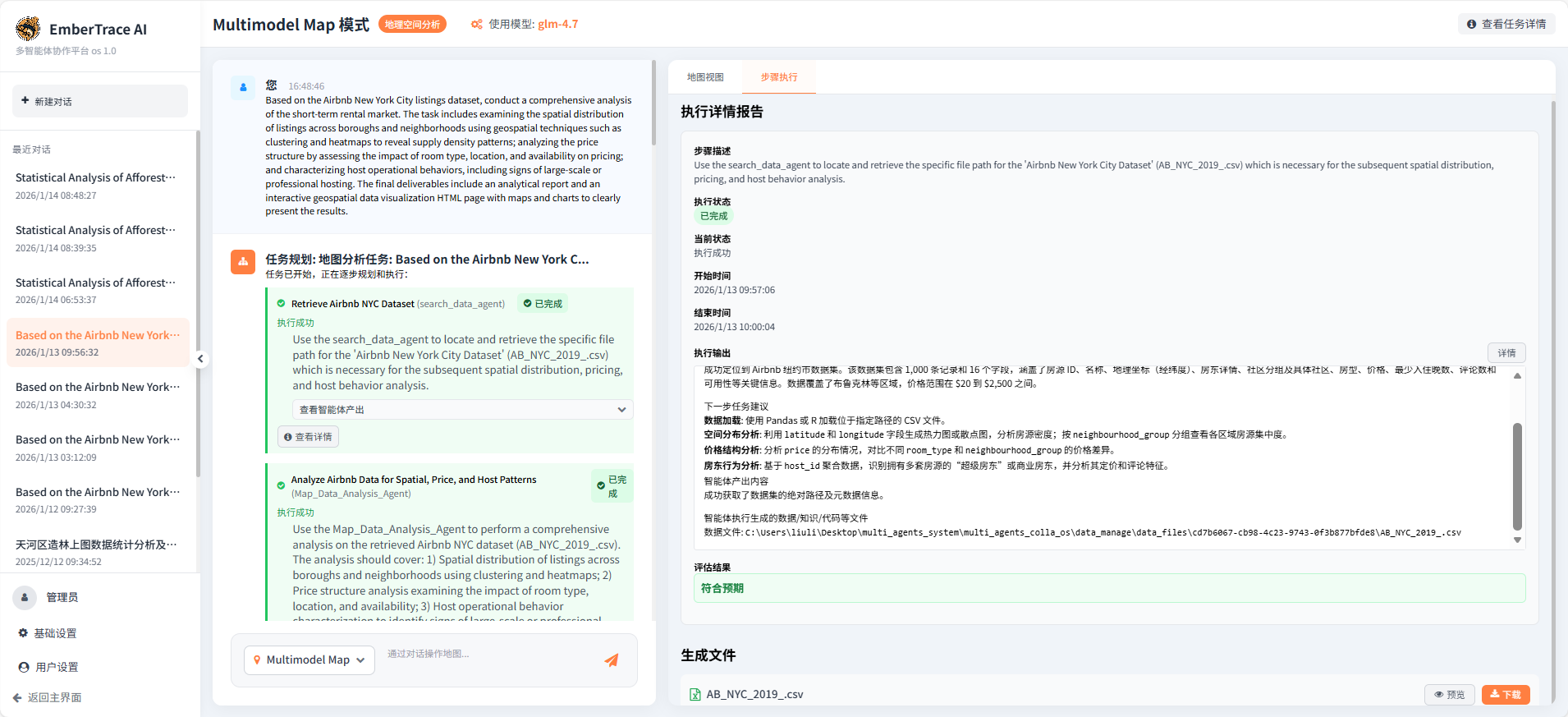
任务一:纽约市 Airbnb 房源地理信息综合分析与可视化
数据来源:Airbnb 纽约市公开数据集(AB_NYC_2019_.csv),包含房源位置、价格、房型、房东信息等字段。
任务目标:完成房源空间分布聚类与热力图展示、价格结构影响因素分析、房东行为特征识别,并输出交互式可视化地图与数据分析报告。
任务执行情况:
本次任务由 EmberTrace AI 系统中的四个智能体协同完成,全程自动化规划、执行与迭代,体现了多智能体系统在复杂地理分析任务中的高效协作与自主纠错能力。
第一步:数据智能检索
search_data_agent 快速定位并加载数据集,准确识别数据规模(约 4.8 万条记录)与关键字段,为后续分析提供可靠输入。该步骤不仅完成数据检索,还主动输出数据洞察建议,体现出智能体对任务上下文的理解能力。
第二步:多维度地理分析
Map_Data_Analysis_Agent 承担核心分析任务,成功执行:
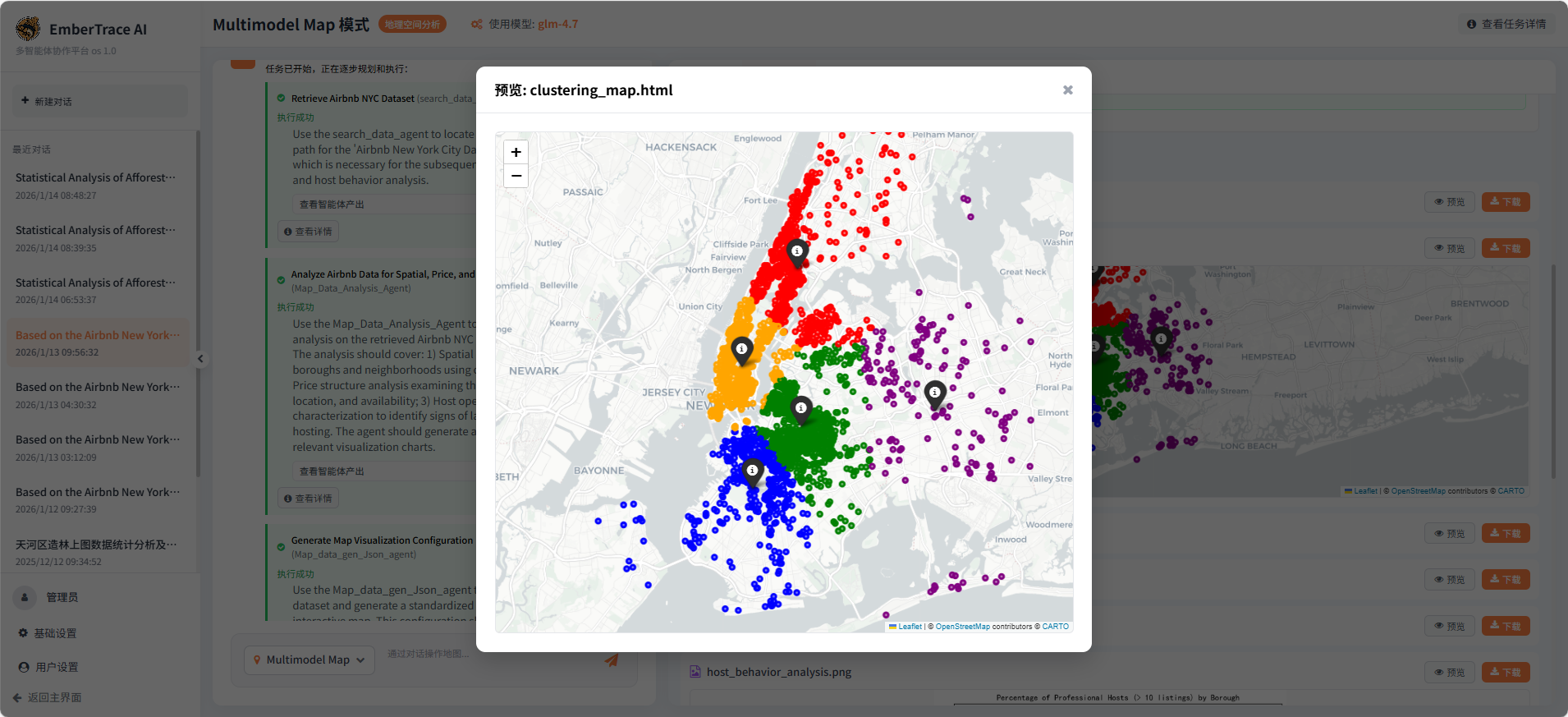
-
空间聚类分析:基于 K-Means 算法识别房源聚集区域,生成交互式聚类地图(clustering_map.html);
-
价格结构建模:通过箱线图可视化不同行政区与房型的价格分布(price_analysis_boxplot.png);
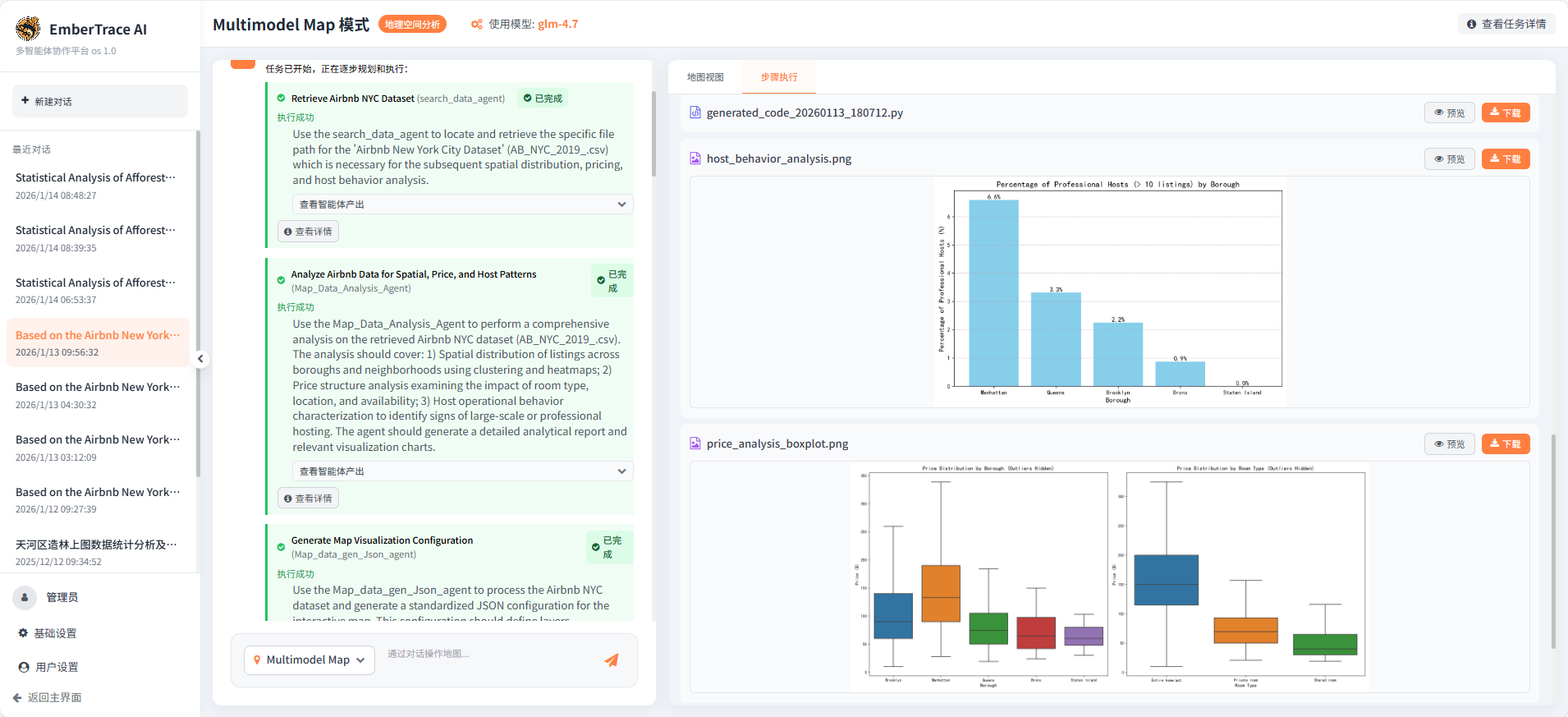
-
房东行为刻画:识别"超级房东"分布,揭示平台商业化运营特征(host_behavior_analysis.png)。
分析过程中,智能体自主完成数据清洗、异常值处理与可视化生成,表现出较强的端到端执行能力。
第三步:地图配置生成与智能纠错
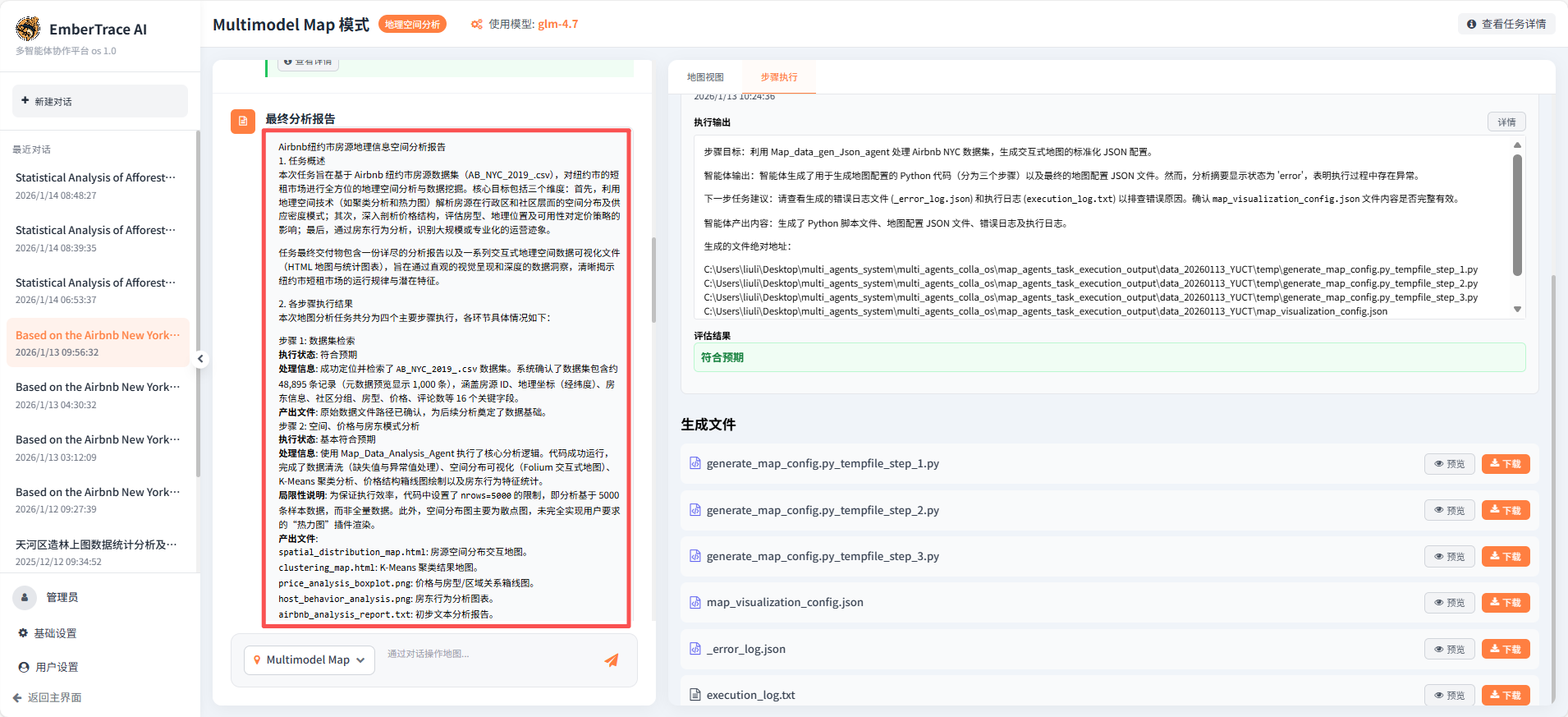
Map_data_gen_Json_agent 负责将分析结果封装为标准化 JSON 配置,供前端调用。该步骤虽在首次执行中触发系统报错,但系统自动启动重试机制,通过多版本代码迭代(初始→修复→最终版)成功输出有效配置文件(map_visualization_config.json)。这一过程充分展现了系统在异常场景下的自我修复与持续优化能力。
步骤四:任务整合与报告生成
执行智能体:系统调度模块 & 报告生成器
关键动作:在所有分析步骤完成后,系统自动整合各智能体的输出(包括地图、图表、数据、配置),并调用报告生成模块,将这些分散的成果组织成一份结构完整、论述严谨的最终分析报告。报告不仅复述了发现,更结合地理与商业逻辑进行了深度解读。
产出与价值:交付了涵盖任务概述、执行过程、可视化成果、地理洞察与综合建议的完整报告(Markdown 格式),以及所有可交互、可复用的数据产品。这标志着系统实现了从"执行任务"到"交付完整数据产品"的闭环。
任务二:天河区造林数据统计分析与地图可视化
任务描述
针对广州市天河区,系统需完成造林数据的统计分析、空间分布规律挖掘以及地图可视化配置生成,形成一套从数据到决策的可视化分析链路。
数据来源
系统在内部数据池中检索到4份广州造林相关数据集,包括:
guangzhou_forest_plots_optimized.csv(带中心点坐标)guangzhou_forest_plots_with_polygons.csv(带多边形边界)- 其他属性表与坐标文件
任务执行情况
本任务由三个智能体接力完成,全程自主化执行,体现了系统的端到端分析能力。
Step 1: 数据检索与提取
search_data_agent 接收任务后,在数据池中进行语义检索,锁定广州造林数据集,并识别出其中"行政区"字段可用于筛选天河区数据。智能体不仅返回文件路径,还自动生成数据筛选与预处理建议,为后续分析奠定基础。该步骤体现了系统的数据感知与智能检索能力 。
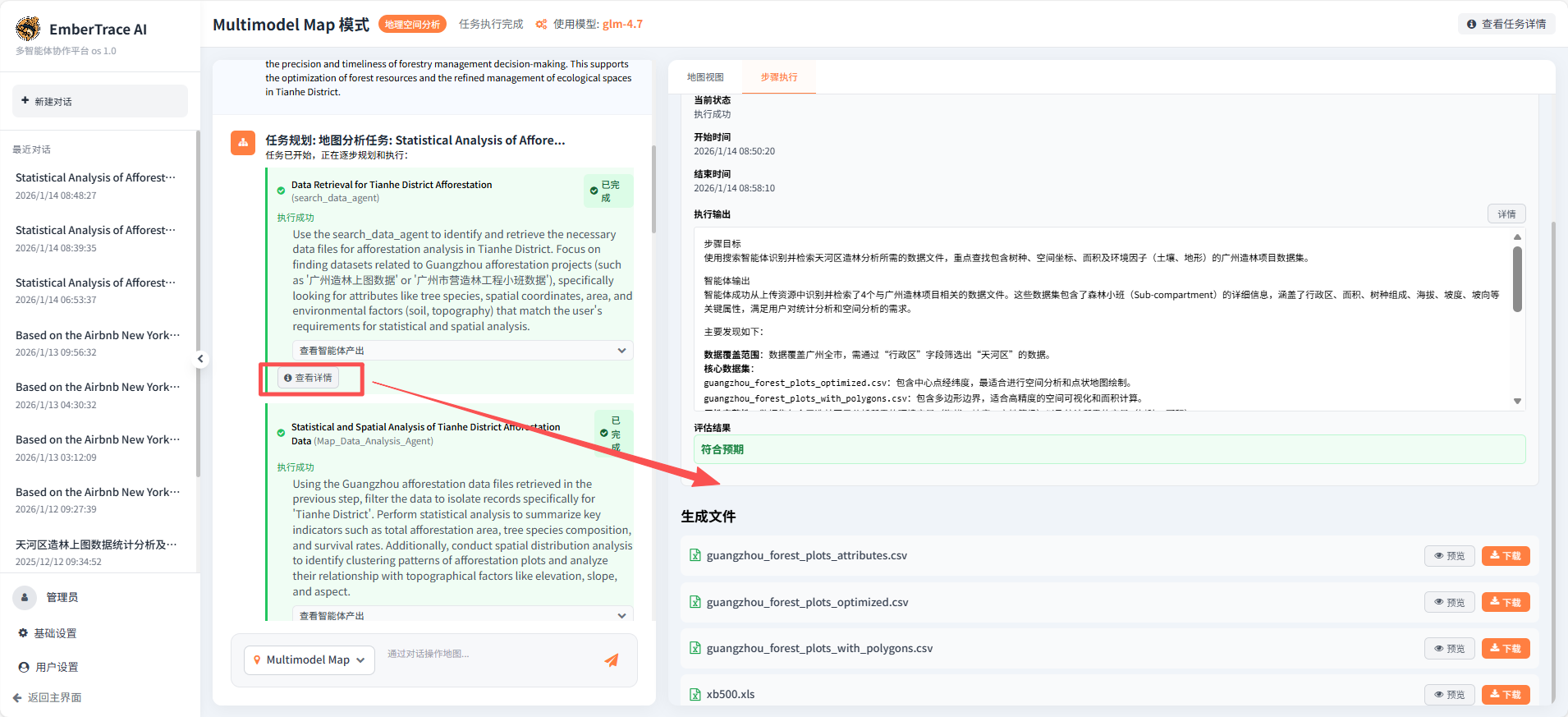
Step 2: 统计分析与空间建模
Map_Data_Analysis_Agent 接手已定位的数据,自动执行以下分析:
- 数据清洗与筛选:提取天河区372条造林小班记录;
- 关键指标统计:汇总总面积、郁闭度分布、树种组成等;
- 空间分析:计算Moran's I空间自相关指数,分析聚类模式;
- 地形因子关联:绘制海拔、坡度、坡向与郁闭度的热力图、箱线图;
- 交互地图生成:输出
tianhe_spatial_map.html,支持属性查看与空间浏览。
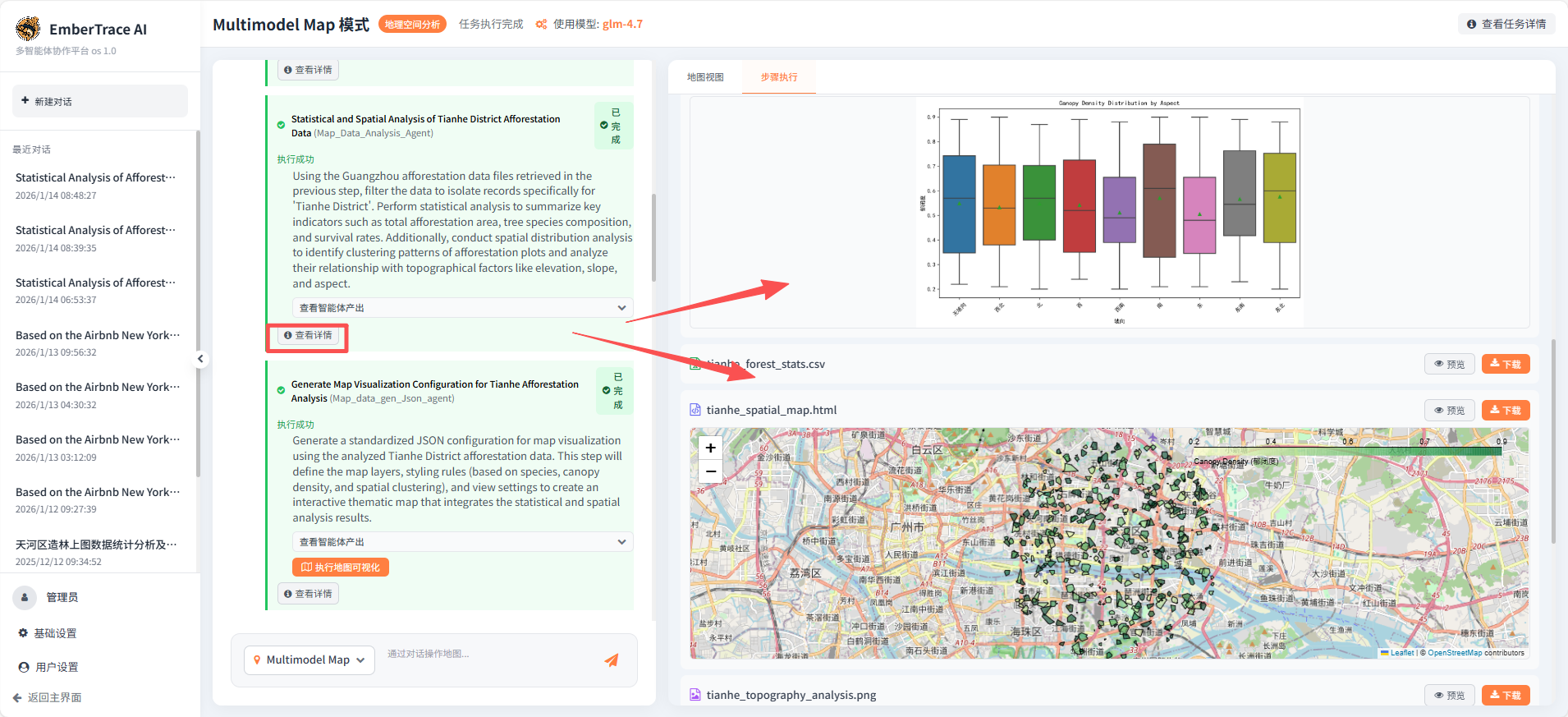
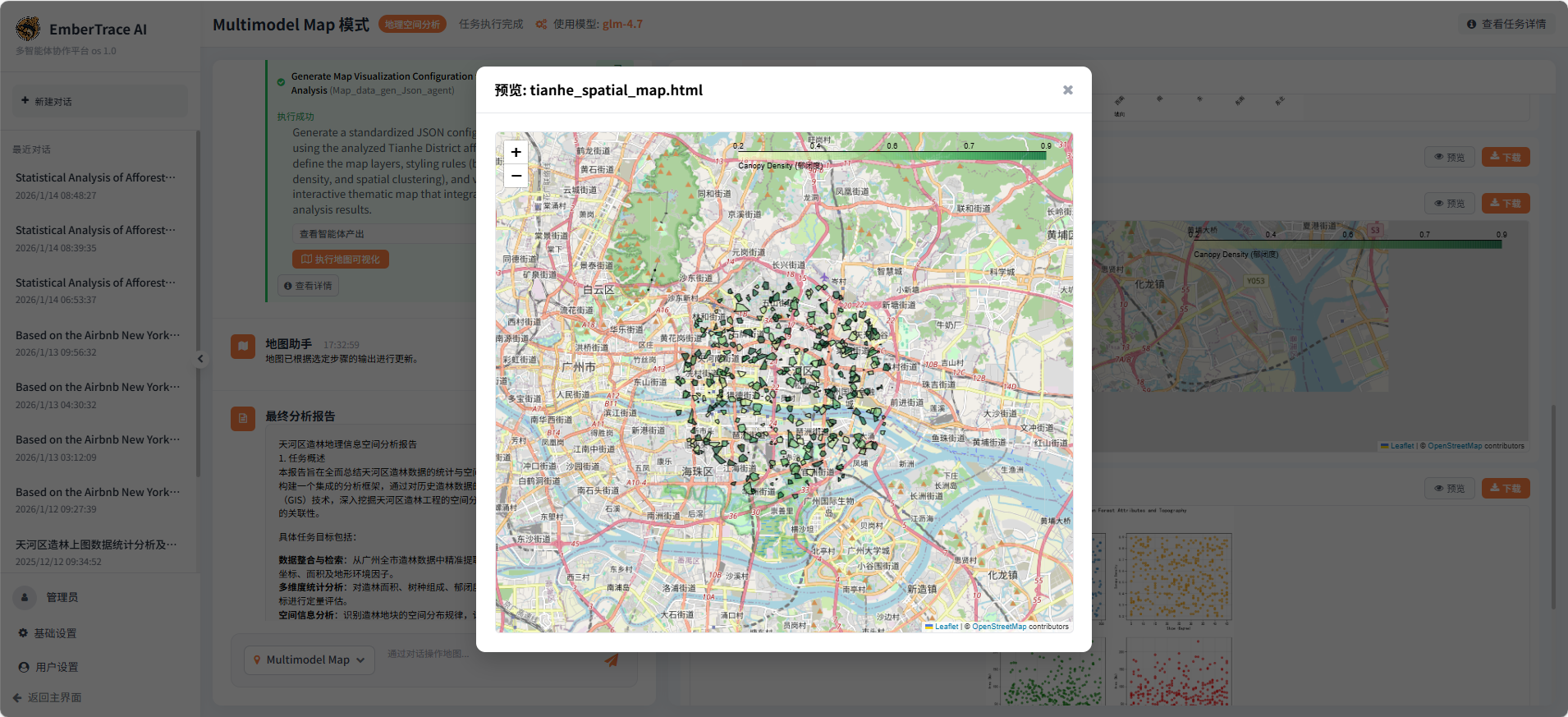
该阶段虽在绘制Moran's I散点图时出现可视化报错,但核心计算与多图表输出均已完成,展现了系统在复杂空间统计与自动化成图方面的强解构能力。
Step 3: 地图可视化配置生成
Map_data_gen_Json_agent 基于前步分析结果,自主构建标准化地图配置。尽管执行日志中提示过程存在异常,智能体仍成功输出 map_visualization_config.json,完成了图层定义、样式规则(按树种、郁闭度设色)与视图设置,为前端动态地图渲染提供"可读化"配置。这验证了系统在分析结果向工程化配置无缝转换 的能力。
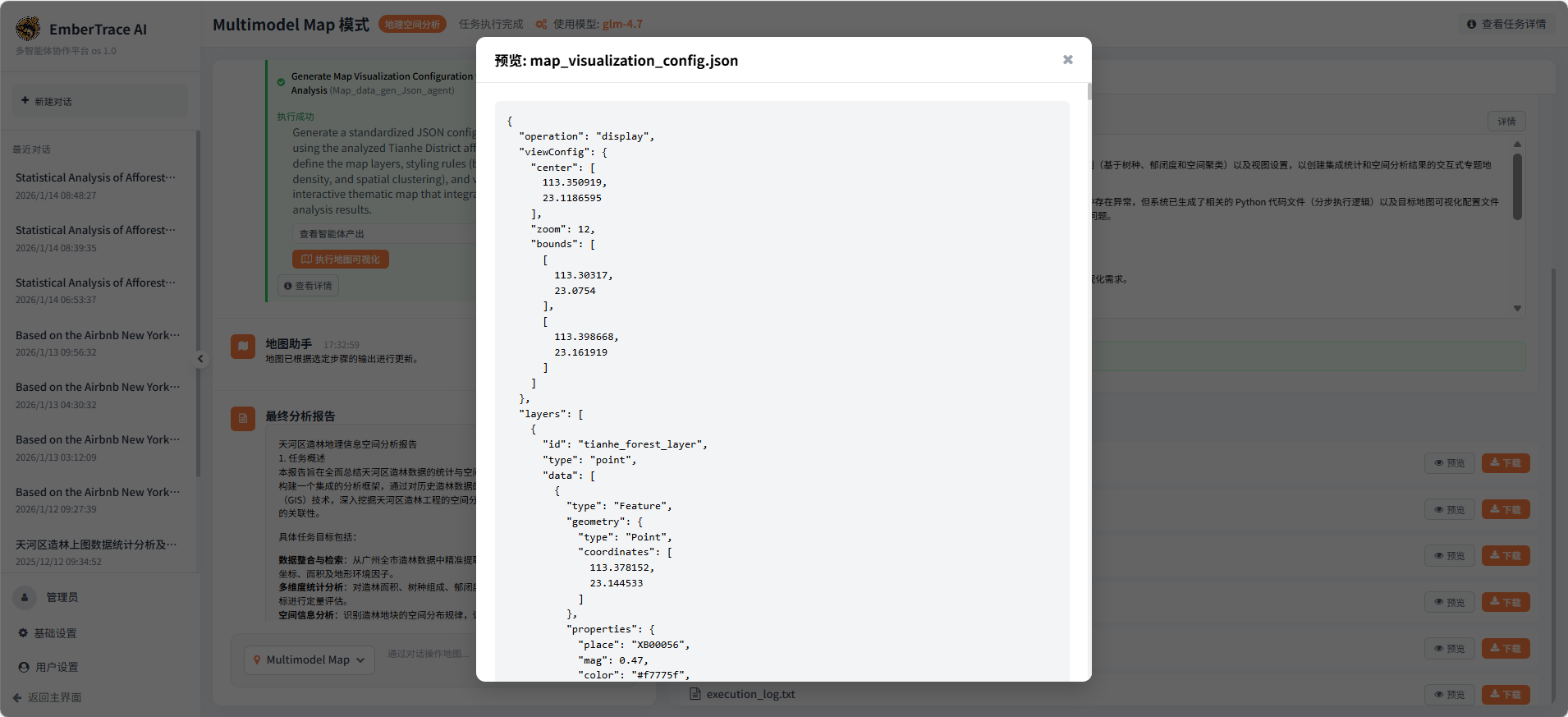
任务总结
本任务全程无人为干预,三大智能体协作流畅:搜索→分析→配置,闭环完整。系统不仅完成数据筛选、统计建模与空间可视化,还输出可直接调用的地图配置文件,体现了EmberTrace AI在多智能体任务编排、专业GIS分析自动化与成果落地一体化方面的成熟能力。这种"分析即配置"的流程,正是面向业务的地图智能系统核心价值所在。
05:EmberTrace AI | Multimodel Map GIS总结

05:总结与展望
一、平台核心能力概述
EmberTrace AI 地图智能分析平台成功构建了一套以"意图驱动"为核心的地理空间信息处理范式。平台将复杂、专业的GIS(地理信息系统)工作流,转化为用户通过自然语言即可触发的自动化任务。其核心能力体现在:
- 端到端的任务自动化 :平台能够理解用户如"分析纽约市Airbnb房源分布"或"统计天河区造林数据"的复杂意图,并自动完成从数据检索与清洗、空间统计与建模、到交互式地图可视化与报告生成的全流程闭环,真正实现了"一句话生成一幅分析地图"。
- 低门槛的自然语言交互:通过集成大语言模型(LLM),平台彻底打破了传统GIS软件的操作壁垒。用户无需具备任何编程或GIS专业知识,仅需用日常语言描述分析目标,即可获得专业级的地理洞察,极大地推动了空间智能的民主化。
- 复杂任务的动态解构与执行:面对不确定的分析路径,平台采用迭代式规划,能够根据中间结果动态调整后续步骤,展现了应对非结构化问题的强大灵活性与鲁棒性。
二、主要创新点
本系统的核心创新在于构建了一个 "语言驱动、智能体协作"的地理空间分析新架构,具体体现在:
- 语言驱动的空间分析(Language-Driven Geospatial Analysis):这是最根本的范式革新。系统将LLM作为"任务规划与调度大脑",使其能够理解用户模糊的、高层次的业务需求,并将其精准翻译、拆解为一系列可执行的原子化GIS操作指令。
- 模块化多智能体协作框架 :系统创新性地采用多智能体(Multi-Agents)架构,将数据检索、空间计算、统计分析、地图配置等专业能力封装为独立的、可插拔的智能体(如
search_data_agent,Map_Data_Analysis_Agent)。MapTaskExecutionEngine作为调度中枢,根据LLM的规划动态组织这些智能体协同工作,模拟了一个专家团队的协作过程。 - 具备"记忆"与"容错"能力的流式执行引擎 :通过
SessionState和TaskState实现任务状态的持久化管理,支持"断点续传"。执行引擎内嵌了"规划-执行-评估"闭环,当某一步骤输出不符合预期时,能自动利用LLM的反馈进行参数调整与重试,显著提升了复杂任务的成功率。 - 分析即配置的成果交付:系统强制要求最终步骤必须生成标准化地图配置(JSON),确保了分析成果能无缝、即时地转化为前端可渲染的交互式地图,实现了从分析过程到可视化产品的一键式交付。
三、面临的问题与挑战
尽管平台在自动化与智能化方面取得了显著进展,但在实际应用与未来发展中也面临若干挑战:
- 大模型上下文窗口的限制:当前LLM的上下文长度有限,在处理极其冗长的任务历史、复杂的中间数据摘要或大型代码库时,可能影响规划与评估的准确性和完整性,制约了对超长流程或高度复杂任务的掌控能力。
- 复杂任务执行能力的边界:虽然系统能处理多数常见分析,但对于需要深度领域知识(如高级空间计量经济学模型)或极端定制化处理的复杂任务,当前智能体的原子化能力库仍需不断丰富和深化。智能体在零样本或少样本场景下的泛化与创造能力有待提升。
- 任务执行效率的优化空间:由于依赖LLM进行多轮规划与评估,并涉及多个智能体的序列化或轻度并行调用,整体任务执行时间可能长于高度优化的手工脚本。在追求完全自主化的同时,如何在响应速度与结果精度间取得最佳平衡,是需要持续优化的工程问题。
展望
EmberTrace AI 系统标志着地理空间分析向"自主化探索"迈出了关键一步。未来,通过持续扩展智能体工具箱、优化LLM的规划与决策效率、并探索更高效的执行架构,平台有望进一步模糊专业分析者与普通用户之间的能力鸿沟,让地理空间智能真正成为赋能各行各业决策的通用基础设施。