第十一章 错误处理体系:异常分层与可恢复策略
-
- [0. 本章目标与适用场景](#0. 本章目标与适用场景)
- [1. 为什么数据/AI工程更需要"体系化错误处理"?](#1. 为什么数据/AI工程更需要“体系化错误处理”?)
- [2. 异常分层:先把"错误的来源"分清楚](#2. 异常分层:先把“错误的来源”分清楚)
-
- [2.1 三层定义(建议)](#2.1 三层定义(建议))
- [3. 设计异常类:把"语义"写进类型里](#3. 设计异常类:把“语义”写进类型里)
- [4. 可恢复策略:终止 / 重试 / 降级 / 跳过](#4. 可恢复策略:终止 / 重试 / 降级 / 跳过)
-
- [4.1 用一个公式抽象"重试的成本"](#4.1 用一个公式抽象“重试的成本”)
- [5. 重试的正确姿势:指数退避 + 抖动 + 上限](#5. 重试的正确姿势:指数退避 + 抖动 + 上限)
- [6. 降级策略:让系统"还能交付一个次优结果"](#6. 降级策略:让系统“还能交付一个次优结果”)
- [7. 批处理场景:失败是"逐条处理"还是"一次终止"?](#7. 批处理场景:失败是“逐条处理”还是“一次终止”?)
- [8. 让错误可观测:日志必须包含 4 个字段](#8. 让错误可观测:日志必须包含 4 个字段)
- [9. 一个可落地的"错误处理流程模板"](#9. 一个可落地的“错误处理流程模板”)
- [10. 小结](#10. 小结)
- 下一章:
你有没有经历过这种"工程事故":
- 数据跑到一半炸了,日志只剩一句:
ValueError: invalid literal for int(),你不知道是哪一行、哪一批数据。 - 同一个接口偶发超时,你加了重试,结果把下游打崩了(重试风暴)。
- 训练/推理 pipeline 里某一步失败了,你不知道应该"立刻终止"还是"跳过继续跑"。
在数据分析 + AI 工程里,错误处理不是"try/except 包一下"。
更像是一套可控的失败机制 :
哪些错误必须立即失败(Fail Fast),哪些可以恢复(Recoverable),哪些应该降级(Degrade),哪些需要人工介入(Escalate)。
本章我们把"错误处理体系"讲成一个可以落地的工程方案:异常分层 + 可恢复策略 + 统一日志与错误码。
0. 本章目标与适用场景
学完你应该能做到:
- 设计一套异常分层(Domain / Application / Infrastructure)
- 明确每层异常的处理策略:终止 / 重试 / 降级 / 跳过
- 在数据管道、爬取、RAG、评测脚本中写出一致的错误处理模式
- 让日志"可定位、可统计、可追踪"
- 把错误处理写成"系统行为",而不是"临时补丁"
1. 为什么数据/AI工程更需要"体系化错误处理"?
因为你的系统天然具备三类不稳定来源:
- 数据不稳定:脏数据、缺字段、类型漂移、分布漂移
- 依赖不稳定:数据库/对象存储/向量库/外部 API 的超时与限流
- 资源不稳定:内存爆、GPU OOM、磁盘满、并发抖动
如果没有体系化的策略,你会陷入两种极端:
- 极端 A:一炸就停,复现成本巨大
- 极端 B:无脑吞异常,结果悄悄变坏
我们要做的是第三条路:
把失败变成可控、可观测、可恢复。
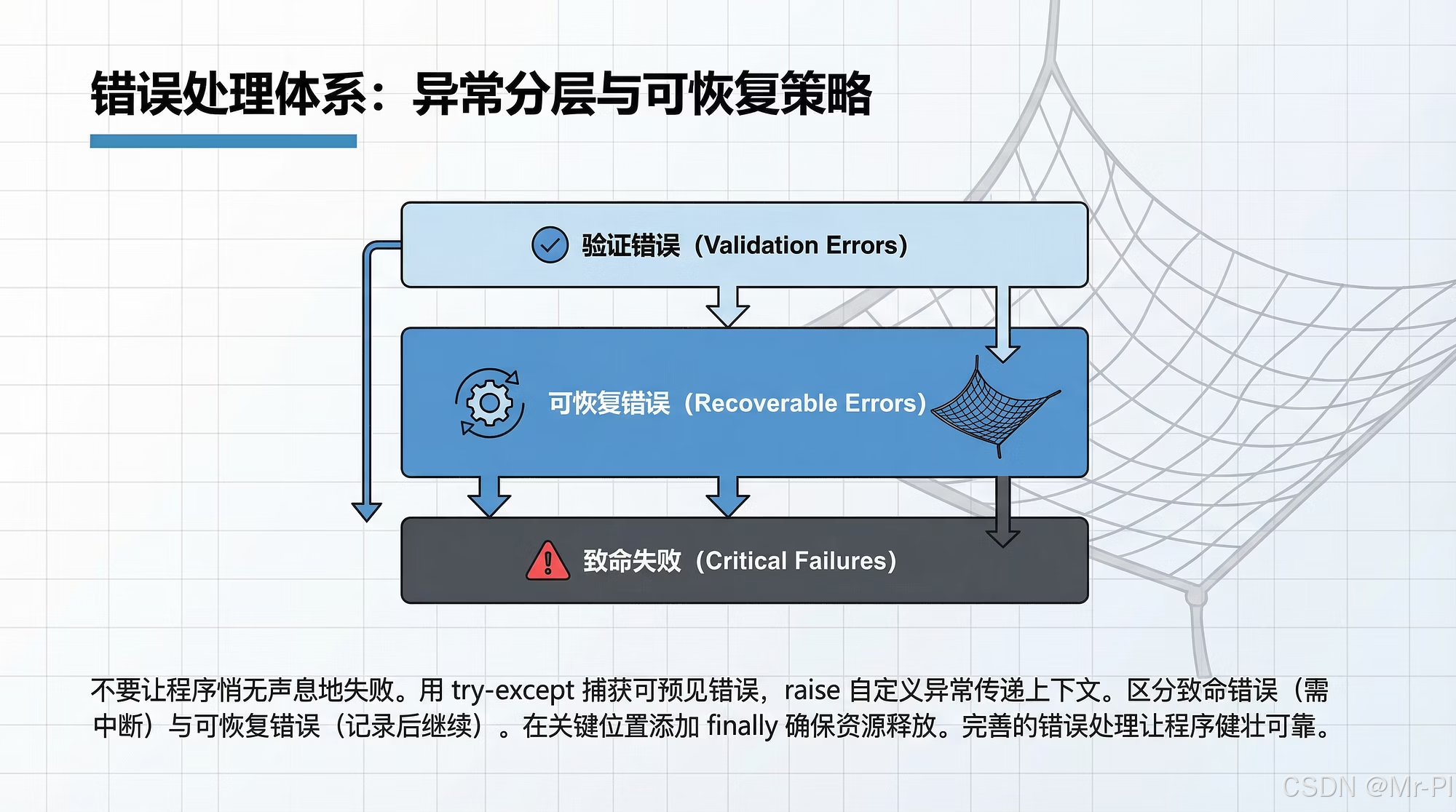
2. 异常分层:先把"错误的来源"分清楚
工程里最常见的反模式:所有异常都 Exception 一把抓。
正确做法是:按来源分层,每层只表达该层关注的语义。
CLI/API/UI
Application Layer: 用例编排
Domain Layer: 业务规则/数据契约
Infrastructure: DB/FS/HTTP/LLM
External Systems
2.1 三层定义(建议)
-
Domain(领域层) :数据契约、业务规则、不可被"重试"解决的问题
例:字段缺失、值域非法、格式不合法、校验失败
-
Application(应用层) :编排流程时的策略与边界
例:某 batch 失败是否跳过、某模块失败是否降级、是否回滚
-
Infrastructure(基础设施层) :外部依赖与资源问题
例:HTTP 超时、数据库连接失败、对象存储 503、GPU OOM
3. 设计异常类:把"语义"写进类型里
建议你在项目里建立一个 errors.py,统一放异常定义。
python
# src/myproj/errors.py
from __future__ import annotations
class AppError(Exception):
"""Base error for the project."""
# --- Domain errors (不可恢复:重试无效) ---
class ValidationError(AppError):
pass
class SchemaMismatchError(ValidationError):
pass
class DomainRuleError(AppError):
pass
# --- Infrastructure errors (通常可恢复:可重试/可降级) ---
class InfraError(AppError):
pass
class TransientError(InfraError):
"""短暂性错误:适合重试(超时/限流/临时不可用)"""
class DependencyUnavailable(TransientError):
pass
class ResourceExhausted(InfraError):
"""资源耗尽:可能需要降级或中止(OOM/磁盘满)"""
# --- Application errors (策略层:用于封装失败上下文) ---
class PipelineStepFailed(AppError):
def __init__(self, step: str, *, cause: Exception):
super().__init__(f"Step failed: {step}: {cause}")
self.step = step
self.cause = cause你会发现:
异常类型本身就回答了"该怎么处理"。
4. 可恢复策略:终止 / 重试 / 降级 / 跳过
先给一个决策表(工程里非常实用):
| 错误类型 | 典型例子 | 推荐策略 |
|---|---|---|
| ValidationError(领域校验) | 缺字段/格式错/值域非法 | 终止或记录后跳过(看业务) |
| TransientError(短暂依赖) | 超时/503/限流 | 有上限的重试 + 指数退避 |
| DependencyUnavailable(依赖不可用) | DB断开/向量库挂 | 降级(换模式)或终止 |
| ResourceExhausted(资源耗尽) | OOM/磁盘满 | 立即降级(小批量/低精度)或终止 |
| 未知异常 | bug/逻辑错 | Fail Fast + 上报 + 保留现场 |
4.1 用一个公式抽象"重试的成本"
重试不是免费的。对下游的压力大致与"重试次数"线性增长:

所以重试一定要配:
- 上限(max_attempts)
- 退避(backoff)
- 抖动(jitter)
- 断路器(circuit breaker)
5. 重试的正确姿势:指数退避 + 抖动 + 上限
指数退避的基本形式:
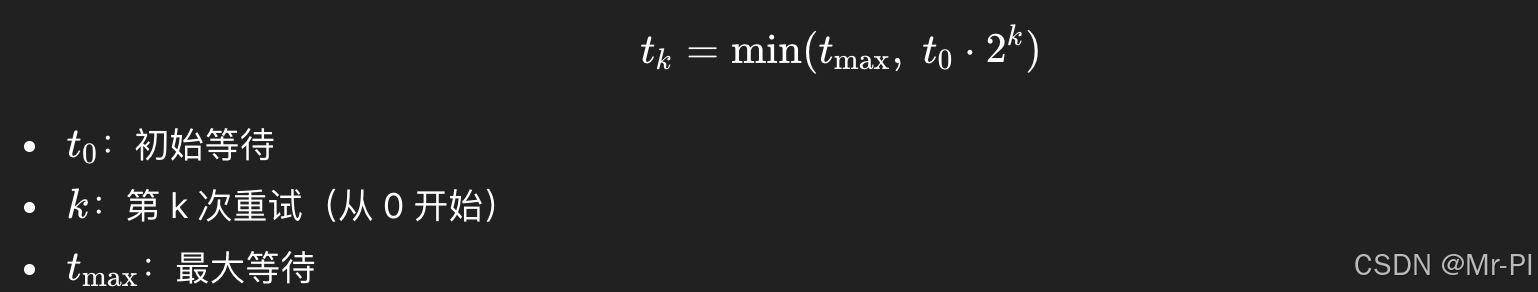
再加一个随机抖动(jitter),避免所有请求同一时刻一起重试。
python
import random
import time
from typing import Callable, TypeVar
from myproj.errors import TransientError
T = TypeVar("T")
def retry(
fn: Callable[[], T],
*,
max_attempts: int = 3,
base: float = 0.5,
cap: float = 5.0,
) -> T:
last_exc: Exception | None = None
for k in range(max_attempts):
try:
return fn()
except TransientError as e:
last_exc = e
sleep = min(cap, base * (2 ** k))
sleep = sleep * (0.8 + 0.4 * random.random()) # jitter
time.sleep(sleep)
raise last_exc # type: ignore[misc]关键点:
只对"短暂性错误"重试。不要对 ValidationError 重试,那是浪费时间。
6. 降级策略:让系统"还能交付一个次优结果"
数据/AI工程里,降级不是耻辱,是工程成熟度。
举几个典型降级:
- LLM 调用失败 → 退回到模板/规则/摘要
- reranker 失败 → 只用向量检索 topK
- OCR 失败 → 标记为"需人工复核",不影响主流程
reranker down
LLM down
Retrieve topK
Rerank
LLM Synthesis
Template Fallback
降级的核心是:显式标记结果质量,让下游知道"这是降级结果"。
7. 批处理场景:失败是"逐条处理"还是"一次终止"?
数据管道最关键的策略点:
单条失败不等于全局失败。
建议你用一个"失败预算"(failure budget)来做决策:

如果失败率超过阈值(例如 1%),立刻终止并上报;否则记录并跳过。
python
from dataclasses import dataclass
@dataclass
class BatchReport:
total: int
failed: int
skipped: int
def process_batch(items: list[dict], *, fail_rate_threshold: float = 0.01) -> BatchReport:
failed = 0
skipped = 0
for it in items:
try:
validate(it) # Domain check
run_pipeline(it) # Infra + App
except ValidationError:
skipped += 1
except Exception:
failed += 1
if failed / max(1, len(items)) > fail_rate_threshold:
raise PipelineStepFailed("batch_process", cause=RuntimeError("failure rate exceeded"))
return BatchReport(total=len(items), failed=failed, skipped=skipped)这比"要么全停,要么全吞"更符合实际交付。
8. 让错误可观测:日志必须包含 4 个字段
你的日志如果只有错误堆栈,定位仍然很慢。
建议最低标准:每条关键错误日志都带上这四个维度:
- where:哪一步(step / module)
- what:错误类型(exception class / error_code)
- which:哪条数据(doc_id / batch_id / request_id)
- how bad:严重程度(fatal / degraded / skipped)
python
import logging
logger = logging.getLogger(__name__)
def log_error(step: str, doc_id: str, err: Exception, *, level: str) -> None:
logger.error(
"pipeline_error step=%s doc_id=%s level=%s err=%s",
step, doc_id, level, repr(err),
exc_info=True
)再进一步,你可以把 request_id/trace_id 打通(RAG/Agent 系统尤其重要),形成完整链路追踪。
9. 一个可落地的"错误处理流程模板"
把本章内容收敛成一张流程图,工程团队按图施工即可:
Success
ValidationError
TransientError
Retry ok
Exhausted
ResourceExhausted
Unknown Error
Start Step
Try Execute
Return Result
Record + Skip OR Fail Fast
Retry with backoff
Degrade OR Escalate
Degrade or Abort
Fail Fast + Alert + Preserve Context
10. 小结
一套可维护的错误处理体系,核心不是"捕获异常",而是三件事:
- 异常分层:错误来自哪里?语义是什么?
- 可恢复策略:终止/重试/降级/跳过,有明确边界
- 可观测性:日志能定位、能统计、能追溯
当你把这三件事做对,你的系统会从"偶发崩溃、难复现"变成:
- 失败可控
- 质量可解释
- 回归可追踪
- 交付可持续
你现在的项目更像哪一种"错误现状"?
- 全靠
try/except Exception,失败原因很难定位 - 重试写了,但经常把下游打挂
- 经常遇到脏数据,不知道该停还是跳过
- 需要降级策略(LLM/依赖不稳定),但缺少统一框架