缓存的分级
缓存的出现是为了解决最开始出现的因为处理器频率和主存频率不匹配而导致的存储墙的问题。但是更大的缓存会导致查询缓存的时间变成,因此目前缓存都会以分级的方式出现: L1容量最小,电路规模小,运行频率和core同频,搜索速度快;之后是L2/L3等缓存,一级比一级容量大。根据设计的不同频率上L2可能和core就是分配关系,L3可能就是异步关系了。
那缓存为啥可以提升命中率呢?这里是因为当前的应用程序中遵循两个原则:
时间局部性:当前被访问的地址的数据,在不久的将来还会被使用;
空间局部性;当前被访问的地址的附近的地址,也即将被访问;
对于前者,L1 的cache就可以在一定程度上提高命中率;
对于后者,可以采用预取到L1或者L2来提升命中率;
Cache 和buffer
缓冲 buffer是指一个临时存放数据的场所,充当数据传递过程的中转站或者暂存站,用以匹配消费者和生产者的速度差异;
缓存是为了减少数据访问延迟,提升命中率,从而构建的存储产所,这些存放的数据有可能会一直呆在cache中不动。
缓冲透明性
缓存相比于存储有一个很重要的区别:缓存是不可以被寻址的,因此缓存不能被程序指定访问;但缓存中存储的地址是可以被程序操作,比如prefetch或者flush。
在很多小core的设计中,会构建一个紧耦合的ram,core可以快速的读取的这个ram的数据,该ram也可以被程序访问,但是这个cache有本质区别。
缓存延迟
在CPU中只有核心内部的寄存器才可以在一个时钟周期内被访问到,而cache的访问通常是需要多个cpu cycle才可以完成,这有几个原因:
- Core发出的地址都是虚拟地址,需要经过MMU转换为物理地址,MMU需要查找TLB/页表才能完成翻译,如果恰好hit tlb,那么可以在数个周期就能完成访问,如果不能hit tlb,那么加载页表的过程往往是比较漫长的;
- 当完成物理地址翻译后,之后向L1发起请求,L1内部在查询数据,读数据,返回数据等步骤也会消耗时间,通过L1没有命中,转而去L2/L3那也将消耗更多的时间。
因此,对于缓存的访问通常都会有多个cycle的延迟;
Inclusive 和exclusive :
在缓存的分级结构中,引入了几个基本的概念,首先是私有缓存和共享缓存;
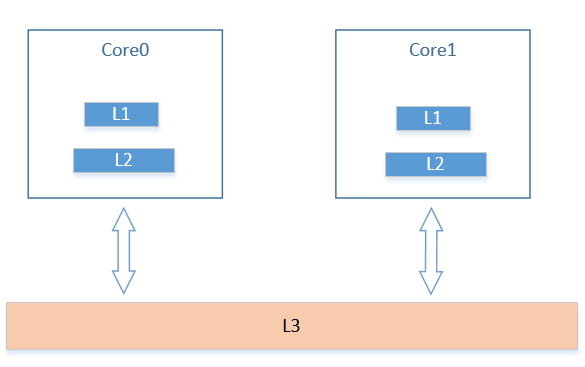
如图所示,私有缓存是指对应缓存只服务于自己,比如图中的L1/L2,共享缓存则是指同时服务于多个核心之间缓存。可以看到在这种结构中,会引入一个问题,就是一个数据备份需要存在于哪里?
答案是都可以,这就引入了另一个概念,inclusive和Exclusive;
Inclusive是指同一个地址的数据可能存在多个数据备份;
Exclusive是指同一个地址的数据只能存在单一备份;
Inclusive的缺点在于浪费了存储的空间,同时会引入很多同步操作,但其也有自身优点,以上图为例,L3会包含L1/L2的所有内容,因此当某个核心在访问L3时,就可以知道其他核心的备份的情况,同时,访问路径可能缩短。
Exclusive的优点在于没有空间的浪费,但是缺点是存在很多数据交换,比如在L2中命中,将数据换到L1时,同时evict 缓存到L2交换一下cacheline位置,同时访问路径可能增加。
Dirty 标记和缓存行
如之前所描述的,缓存是一个对ram数据的存储场所,最终所有数据都会重归RAM中。之前也说了缓存的大小是有限的,那么就可能存在有新的内容进来替换旧的内容,那么怎么确定被更换的缓存可以直接被替换还是需要将缓存中的数据写回到ram,此时就需要一个标记位来标记这个事件。
在缓存中,一般会在每条数据旁边设置一个bit位来表征这个状态,表示该行数据是不是脏的,成为dirty位,所有dirty位形成一个bitmap。
那么缓存的每条数据是怎么确定的呢?一般来讲主流CPU的缓存行的大小都采用64byte,其主要原因是主流DDR SDRAM一次连续数据传输通常最大只能到64byte。