在ClickHouse的日常运维中,数据安全与业务连续性是核心诉求。无论是应对误删表、硬件故障,还是跨环境数据同步,一套清晰可落地的备份与恢复方案必不可少。本文结合实操案例,详细拆解ClickHouse的三类备份场景------逻辑备份、跨实例数据导出,以及专业工具clickhouse-backup的部署与使用,并完整覆盖数据恢复流程,助力运维人员快速上手。
一、逻辑备份:小数据量场景的轻量方案
逻辑备份通过SQL查询将数据导出为通用格式(如CSV),操作简单且跨版本兼容,适合数据量较小的场景。以下是完整实操步骤:
1.1 创建测试表并写入数据
首先在ClickHouse中创建基于MergeTree引擎的测试表(MergeTree是ClickHouse最常用的引擎,支持高效查询与数据分区),并插入测试数据:
plsql
-- 创建测试表(所属数据库为maria,表名为t3)
CREATE TABLE maria.t3
(
`a` Int8, -- 8位整数类型
`b` Int8,
`c` String -- 字符串类型
)
ENGINE = MergeTree() -- 指定引擎
ORDER BY a; -- 按字段a排序
-- 写入测试数据
INSERT INTO maria.t3 VALUES (1,1, 'a');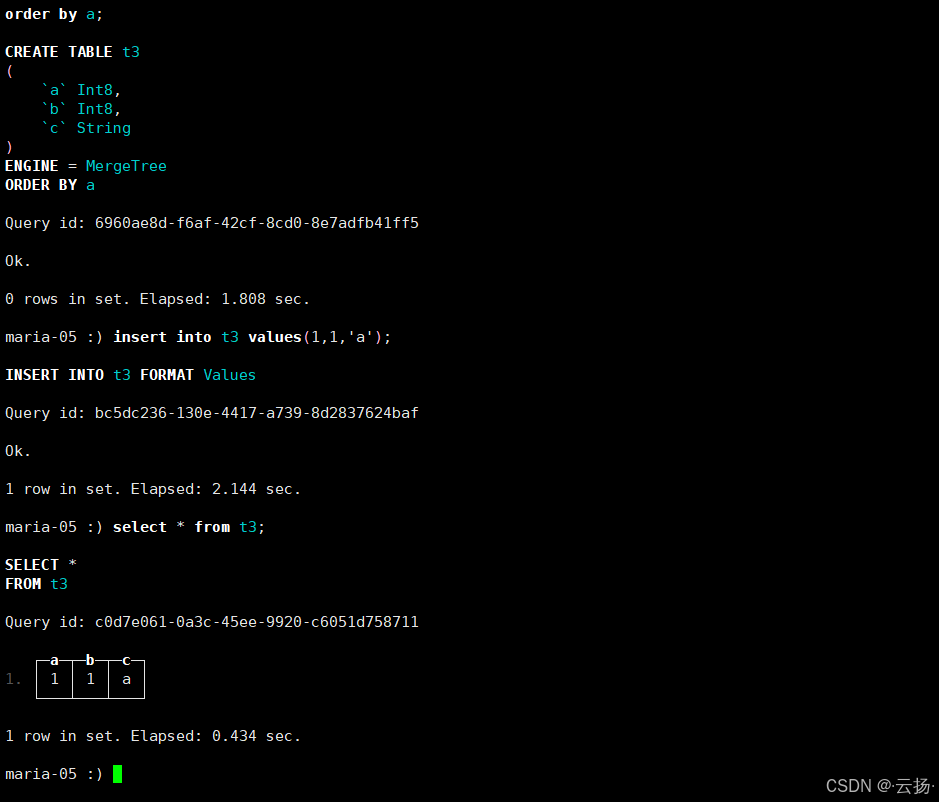
1.2 导出数据为CSV格式
将maria.t3表的数据导出到指定目录(此处为/data/backup/),并保存为CSV文件:
plain
-- 进入备份目录(若目录不存在需先执行mkdir -p /data/backup/)
cd /data/backup/
-- 执行导出命令:通过clickhouse-client查询数据,以CSV格式写入文件
clickhouse-client --query "select * from maria.t3" --format CSV>/data/backup/t3.csv
1.3 验证备份文件
导出后通过cat命令查看文件内容,确认数据是否完整:
plain
cat /data/t3.csv执行后应显示测试数据1,1,a,表明备份成功。

二、跨实例数据导出:实现环境间数据同步
当需要将数据从一台ClickHouse实例同步到另一台时,可直接通过remote函数跨实例读取数据,无需中间文件中转,适用于跨环境数据迁移场景。
2.1 准备目标ClickHouse环境
以目标实例IP192.168.184.156为例,先完成ClickHouse的安装(基于CentOS系统):
plain
-- 安装依赖工具
yum install -y yum-utils
-- 添加ClickHouse官方仓库
yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
-- 安装服务端与客户端
yum install -y clickhouse-server clickhouse-client
-- 修改ClickHouse配置文件
vim /etc/clickhouse-server/config.xml
-- 搜索 listen_host,去掉该行注释,这样其它机器也可以访问这台机器的 clickhouse
<listen_host>0.0.0.0</listen_host>
-- 启动ClickHouse
/etc/init.d/clickhouse-server start
ps -ef | grep click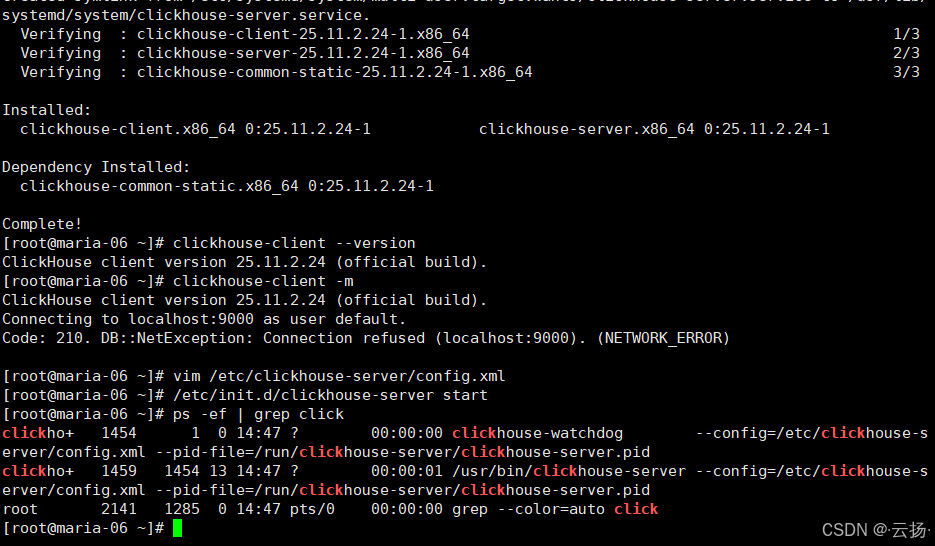
2.2 跨实例导出并写入数据
在目标实例(192.168.184.156)中,创建与源实例一致的数据库和表,再通过remote函数读取源实例(192.168.184.155)数据并写入:
plsql
-- 进入ClickHouse客户端(-m允许多行输入)
clickhouse-client -m
-- 1. 创建与源实例一致的数据库
create database maria;
-- 2. 创建与源实例结构相同的表
CREATE TABLE maria.t3
(
`a` Int8,
`b` Int8,
`c` String
)
ENGINE = MergeTree()
ORDER BY a;
-- 3. 跨实例读取数据并写入:remote函数指定源实例IP、数据库和表
insert into table maria.t3 select * from remote ('192.168.184.155','maria.t3');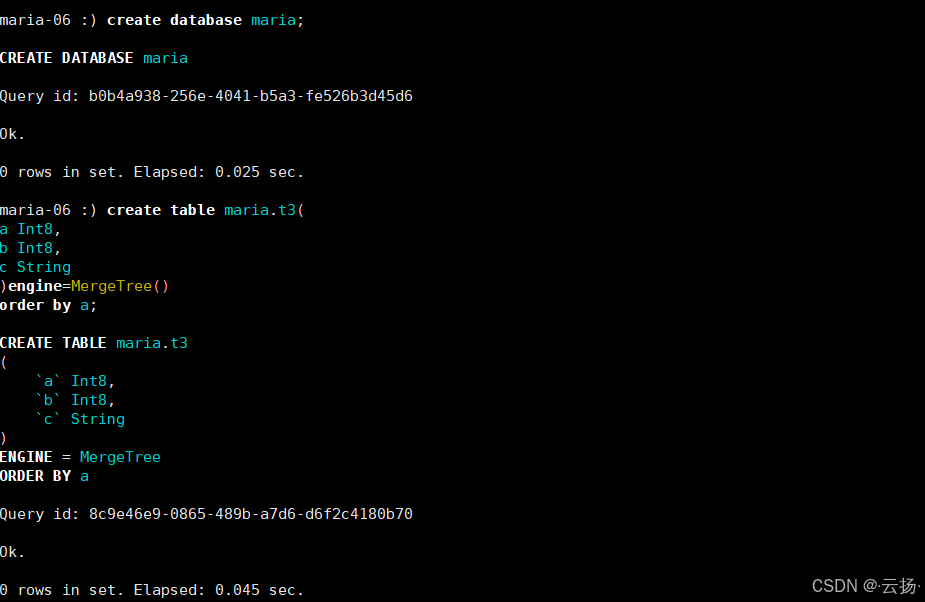
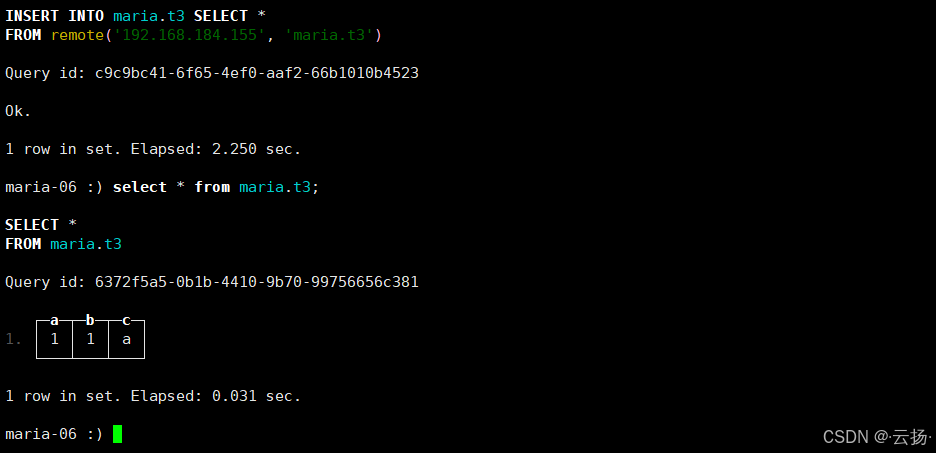
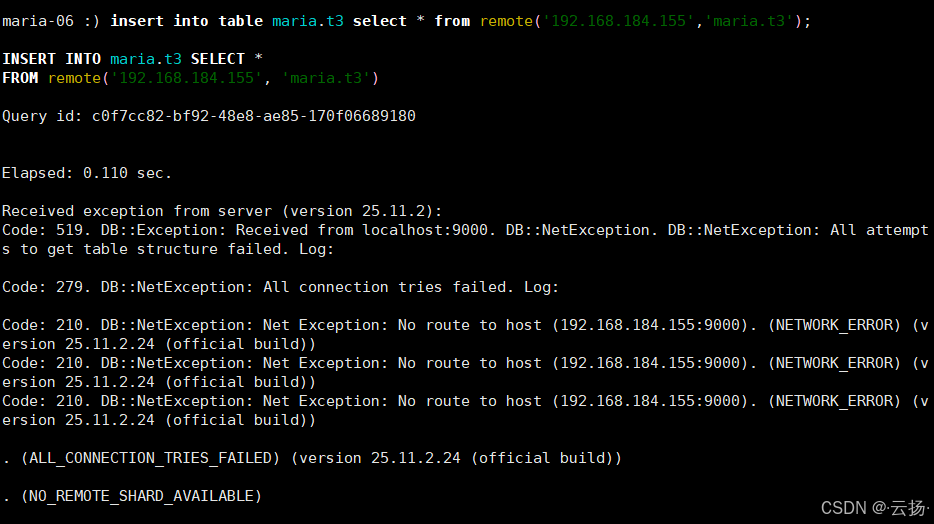
注意:在跨实例读取数据并写入时,如果出现如下图所示报错,可在源实例(192.168.184.155)执行iptables -F清空防火墙规则或添加防火墙 accept 规则,最后查询目标实例数据验证同步结果。
2.3 验证数据同步结果
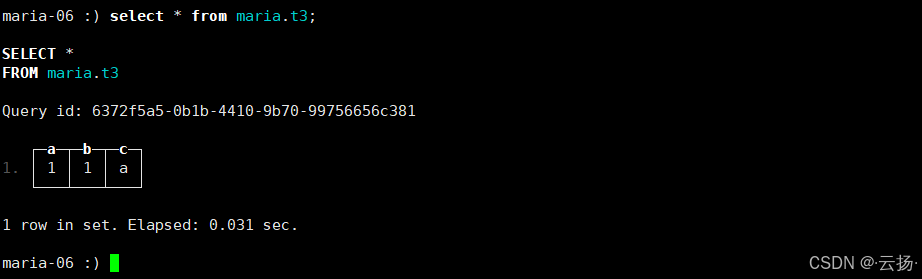
在目标实例中查询表数据,确认同步是否成功:
plain
select * from maria.t3;若返回1,1,a,则说明跨实例数据导出完成。
三、clickhouse-backup:专业物理备份工具的实战
clickhouse-backup是Altinity推出的物理备份工具,直接备份ClickHouse的数据文件,备份效率高、恢复速度快,适用于中大规模数据场景。但需注意其局限性:仅支持ClickHouse 1.1.54394及以上版本,且仅兼容MergeTree系列引擎。
3.1 部署clickhouse-backup
3.1.1 下载工具包
从GitHub Releases页面(https://github.com/Altinity/clickhouse-backup/releases)选择对应版本(此处以v2.6.41为例),通过wget下载:
plain
wget https://github.com/Altinity/clickhouse-backup/releases/download/v2.6.41/clickhouse-backup-2.6.41-1.x86_64.rpm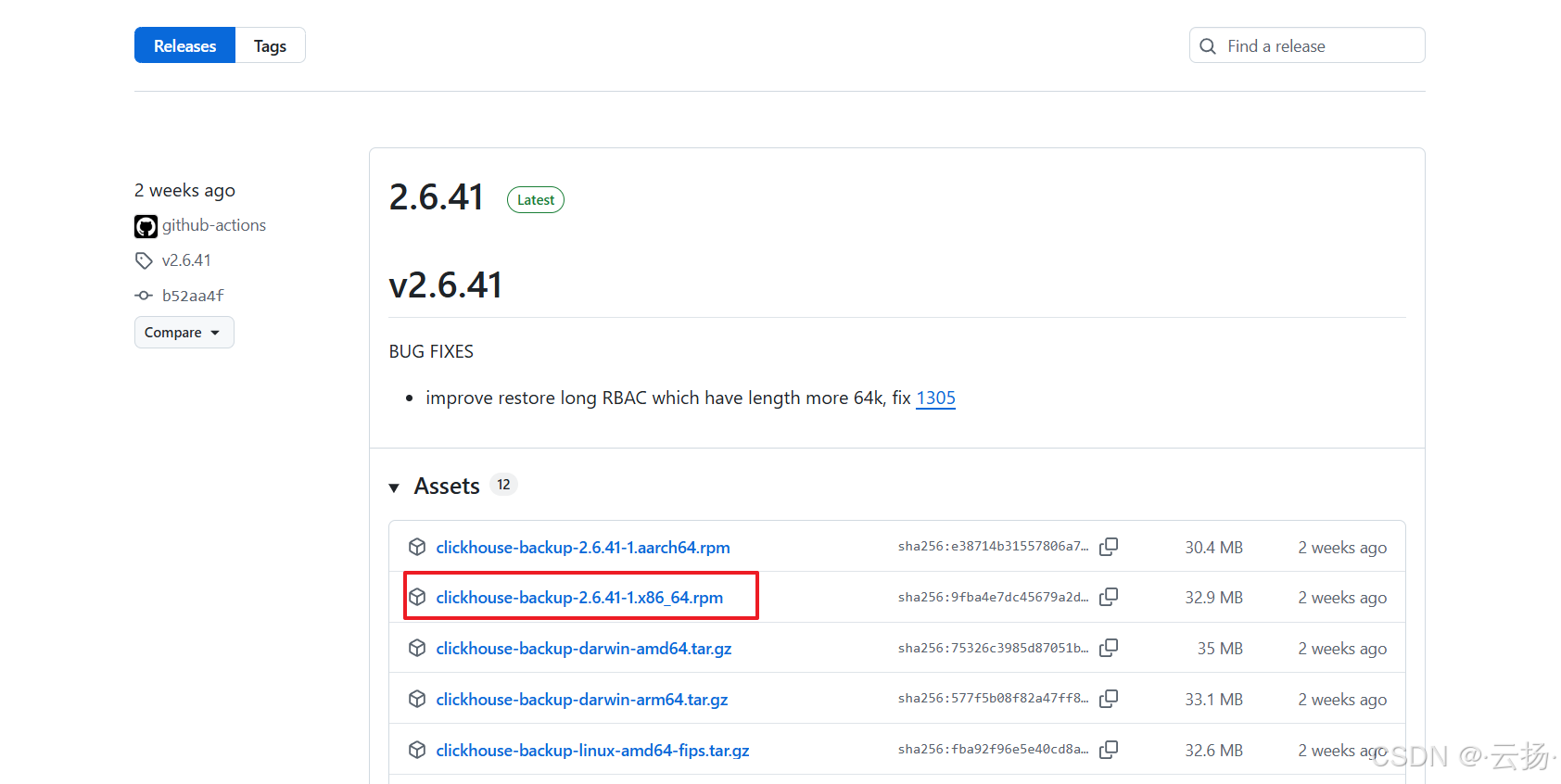
3.1.2 安装并配置
plain
-- 安装RPM包
yum install clickhouse-backup-2.6.41-1.x86_64.rpm -y
-- 复制默认配置文件(若需自定义配置)
cp /etc/clickhouse-backup/config.yml.example /etc/clickhouse-backup/config.yml
-- 修改日志等级:默认info,建议改为warning减少日志量
sed -i 's/log_level: info/log_level: warning/' /etc/clickhouse-backup/config.yml
-- 查看默认配置(验证配置是否生效)
clickhouse-backup default-config3.1.3 查看可备份的表
确认工具能识别ClickHouse中的表,避免后续备份报错:
plain
clickhouse-backup tables执行后会列出所有MergeTree引擎的表(如maria.t3)。

3.2 多样化备份操作
clickhouse-backup支持全库、单表、多表及自定义备份名称,满足不同场景需求:
3.2.1 备份所有业务库
默认备份所有库表:
plain
-- 执行全量备份
clickhouse-backup create backup_20251215
-- 查看备份文件(默认路径:/var/lib/clickhouse/backup/)
cd /var/lib/clickhouse/backup/
ll # 显示备份文件夹
yum install -y tree # 安装tree工具查看目录结构
tree backup_20251215 # 查看备份文件详情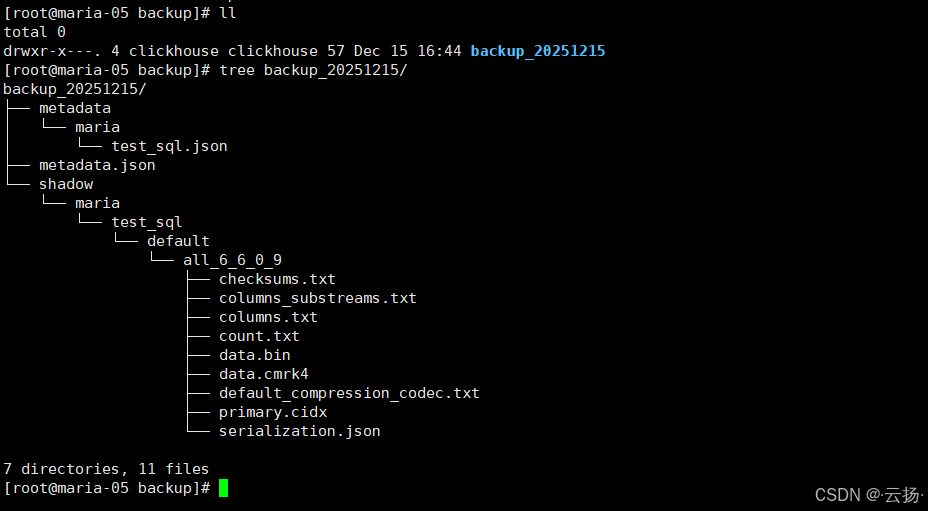
3.2.2 备份单张表
仅备份指定表(如maria.t3),减少备份体积:
plain
clickhouse-backup create -t maria.t3 maria_t3
3.2.3 备份多张表
同时备份多个表,用逗号分隔表名:
plain
clickhouse-backup create -t maria.t3,maria.test_sql maria_t3_test_sql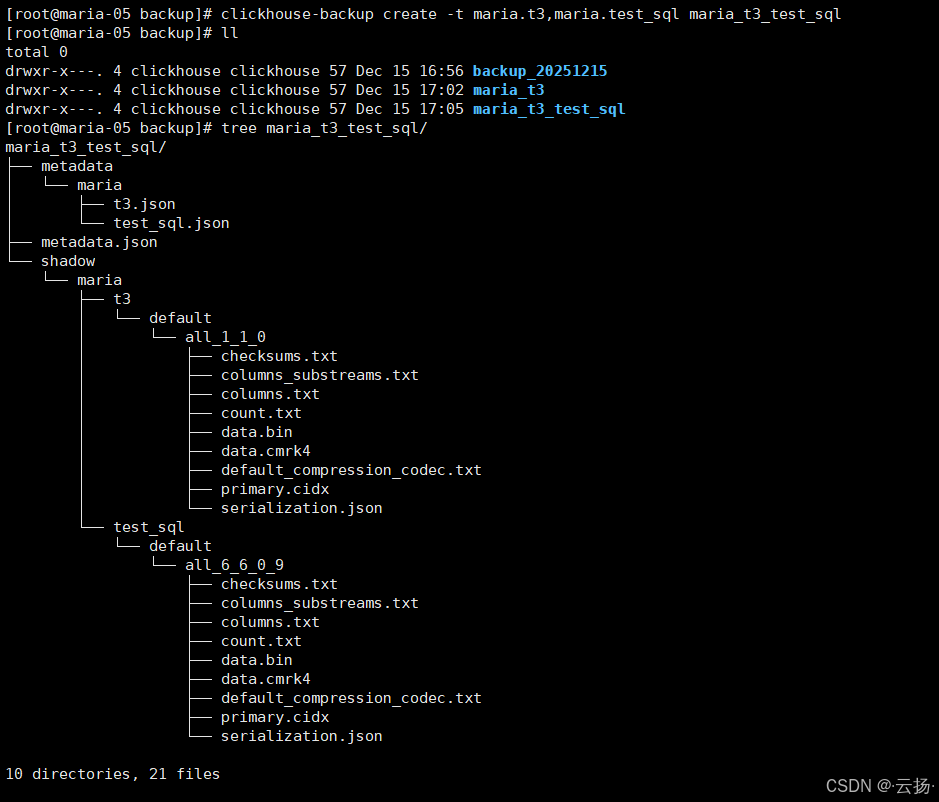
3.2.4 备份指定数据库
备份某个数据库下的所有表(如maria库),用*通配:
plain
clickhouse-backup create -t maria.* maria_all_tables_bak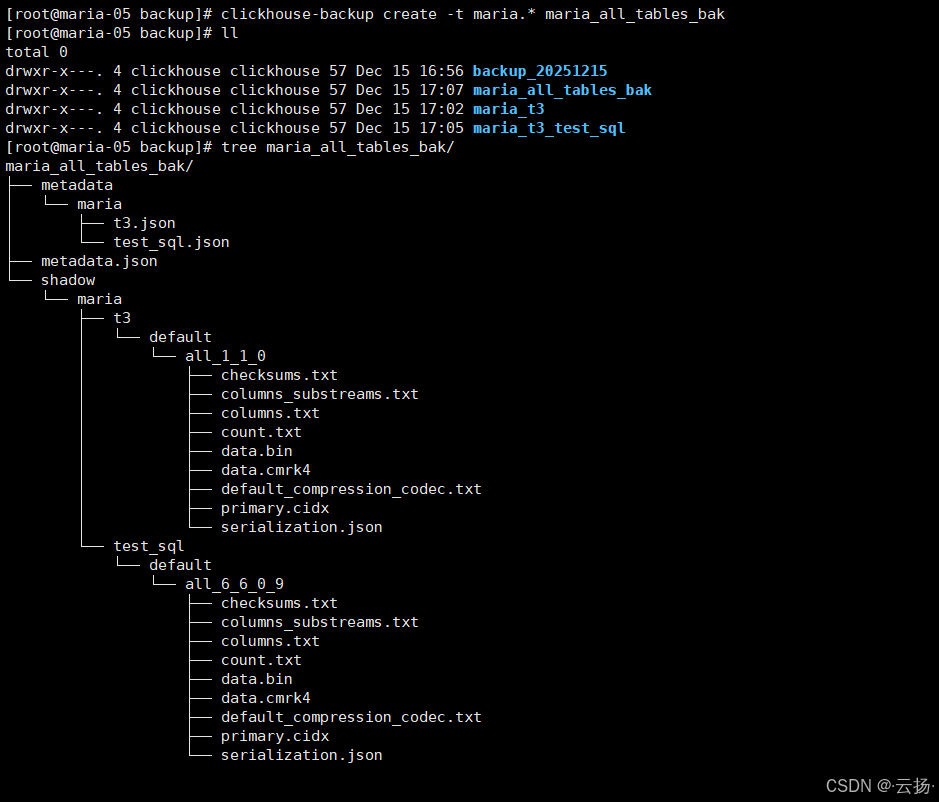
3.2.6 查看备份列表
除了查看目录,还可通过工具直接列出所有备份:
plain
clickhouse-backup list
3.3 数据恢复:从备份中恢复误删表
当表被误删时,可通过clickhouse-backup快速恢复,步骤如下:
3.3.1 模拟误删场景
plain
-- 进入ClickHouse客户端,删除测试表
clickhouse-client -q "drop table maria.t3;"3.3.2 执行恢复操作
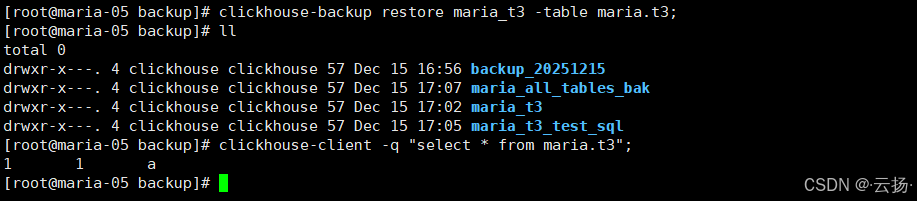
指定备份名称(如t3_bak)和待恢复的表(maria.t3):
plain
clickhouse-backup restore t3_bak -table maria.t3;3.3.3 验证恢复结果
查询表数据,确认恢复成功:
plain
clickhouse-client -q "select * from maria.t3;"返回1,1,a即表示恢复完成。
四、总结:不同备份方案的选型建议
| 备份方案 | 适用场景 | 优势 | 局限性 |
|---|---|---|---|
| 逻辑备份(CSV) | 小数据量、跨版本兼容 | 操作简单、文件通用 | 大数据量时效率低 |
| 跨实例导出(remote) | 跨环境数据同步 | 无需中间文件、实时同步 | 依赖网络稳定性 |
| clickhouse-backup | 中大规模数据、快速恢复 | 备份/恢复效率高、支持多样备份 | 仅支持MergeTree引擎、版本受限 |
在实际运维中,可根据数据量、业务场景组合使用三种方案:小表用逻辑备份,跨环境同步用remote函数,核心业务大数据量则优先选择clickhouse-backup,确保数据安全与业务连续性。