首先从一个问题引入kafka:
kafka为什么是"Producer Push" + "Consumer Pull"?
1. 生产端:Push(推)
Producer(生产者)负责将消息发送给 Broker(Kafka 服务端)。这是一个 Push 动作。
- 原因:生产者通常希望数据产生后尽快发送出去,由生产者决定发送速率和发送的目标分区(Partition)。
2. 消费端:Pull(拉)------ 这是面试/理解的重点
Consumer(消费者)主动向 Broker 请求数据。这是一个 Pull 动作。
为什么 Kafka 坚决选择 Pull 模式,而不是像某些消息队列(如早期的 ActiveMQ)那样由服务端 Push?
- 流量控制(速率匹配) :
- Push 的弊端:Broker 不知道消费者的处理能力。如果 Broker 以每秒 1000 条的速度推送,但消费者每秒只能处理 100 条,消费者瞬间就会被压垮(OOM 或 拒绝服务)。
- Pull 的优势 :消费者可以根据自己的处理能力(处理完一条拉一条,或者批量拉取)来控制消费速度。这天然实现了背压(Backpressure)机制。
- 批处理优化(Batching) :
- 消费者可以攒够一定量的数据或等待一定时间再拉取,极大地减少了网络交互次数,提高了吞吐量。
- 简化 Broker 设计 :
- Broker 不需要维护每个消费者的"忙碌/空闲"状态,只负责存储和被读取,这让 Broker 极其轻量且稳定。
补充:长轮询(Long Polling)机制 既然是 Pull,会不会导致消费者不断循环请求却拿不到数据(空轮询),浪费 CPU? Kafka 引入了 Long Polling。当消费者发起 Pull 请求时,如果 Broker 没有新数据:
- Broker 不会立即返回空结果。
- Broker 会挂起(Hold) 这个请求一段时间(由
fetch.max.wait.ms控制)。 - 一旦有新数据到达,Broker 立即响应;如果超时仍无数据,才返回空。 这兼顾了 Push 的实时性和 Pull 的可控性。
Kafka 的核心原理与架构细节
要讲得细,必须深入到 Kafka 的"高性能"和"高可用"是由哪些底层原理支撑的。
接下来来回顾下kafka的基本架构。(zookeeper在kafka3.x后已经被KRaft替代)
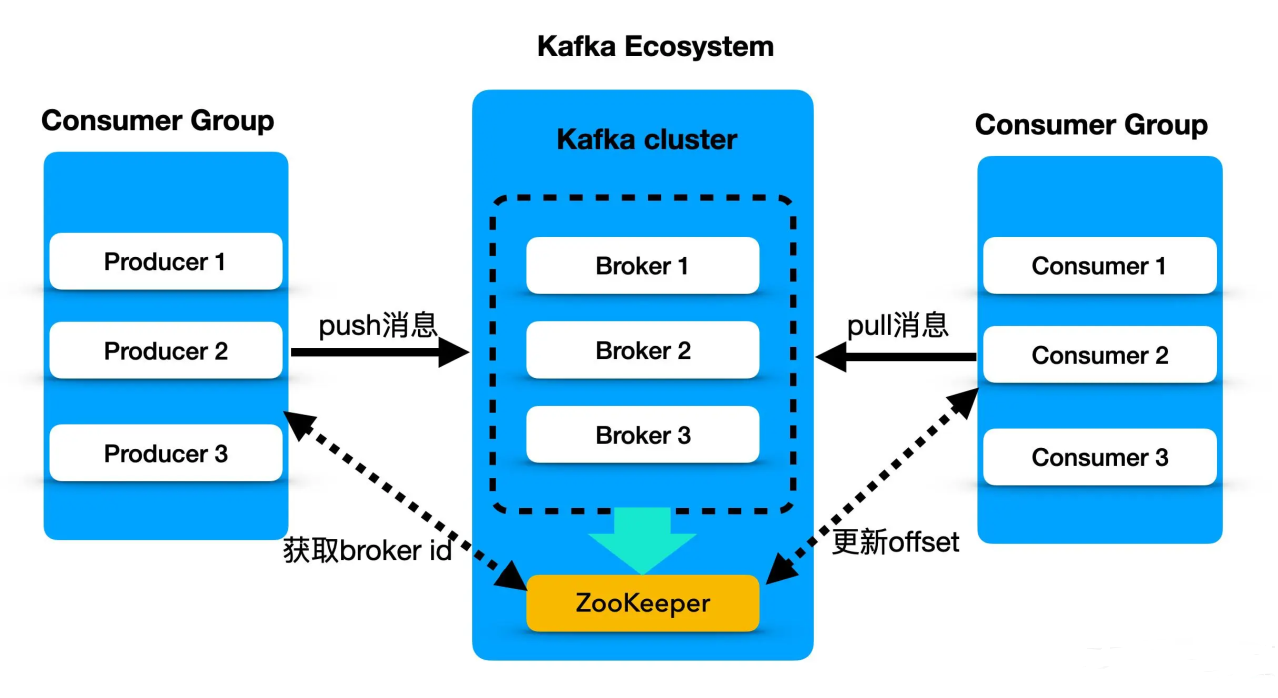
1. 逻辑架构:Topic, Partition 与 Offset
- Topic(主题):逻辑上的消息分类。
- Partition(分区) :物理上的分片。这是 Kafka 高吞吐的核心。
- 一个 Topic 分散在多个 Partition 上,不同的 Partition 可以存在不同的 Broker 上。
- 并发原理:多个消费者可以同时消费同一个 Topic 下的不同 Partition,实现了并行处理。
- Offset(偏移量):消息在 Partition 中的唯一序号。Kafka 不像传统 MQ 那样读完就删,而是通过 Offset 标记读到哪了,消息依然保留在磁盘上(直到过期)。
2. 物理存储原理(由慢变快的秘密)
很多人认为磁盘慢,内存快,但 Kafka 证明了磁盘也能极快。
- 顺序写盘(Sequential Write) :
- Kafka 强制要求每一个 Partition 都是一个追加日志(Append-only Log)。
- 原理:机械硬盘的随机 I/O 极慢(需要寻道),但顺序 I/O 极快(接近内存速度)。Kafka 永远只在文件末尾追加数据,避免了磁盘臂的乱跳。
- 页缓存(Page Cache) :
- Kafka 不在 JVM 堆内存中显式维护大量的消息缓存(避免 GC 压力)。
- 它利用操作系统的 Page Cache(文件系统缓存)。数据写入时,先写到 OS 的 Page Cache,由 OS 决定何时刷盘。读数据时,如果在 Page Cache 命中,直接返回。
- 结论:Kafka 实际上是在读写内存。
3. 网络传输原理:零拷贝(Zero Copy)
这是 Kafka 发送数据给消费者超快的核心技术。
- 传统模式:磁盘 -> 内核 Buffer -> 用户态 Buffer (应用层) -> 内核 Socket Buffer -> 网卡。数据被拷贝了 4 次,上下文切换 4 次。
- Kafka 零拷贝(sendfile) :
- 数据直接从 磁盘 Page Cache -> 网卡。
- 跳过了"拷贝到用户态"和"拷贝到 Socket Buffer"的步骤。
- 原理 :利用 Linux 的
sendfile系统调用。Broker 甚至不需要解压消息,直接把加密/压缩的二进制流透传给消费者。
4. 高可用原理:Replication(副本机制)
- Leader 与 Follower :
- 每个 Partition 有一个 Leader 和多个 Follower。
- 只有 Leader 处理读写请求(注意:Kafka 2.4+ 允许 Follower Fetching,但主流仍是读 Leader)。
- Follower 只是被动地从 Leader 拉取数据同步。
- ISR (In-Sync Replicas) :
- Kafka 维护一个 ISR 列表,包含所有"跟得上 Leader"的副本。
- 只有数据写入了 ISR 中所有的副本(或者根据配置
min.insync.replicas),才被认为"已提交"。 - 如果 Leader 挂了,Controller 会从 ISR 中选一个新的 Leader,保证数据不丢。
5. 消费者组(Consumer Group)
这是 Kafka 处理大规模数据的逻辑。
- 组内互斥 :同一个 Group 内,一个 Partition 只能被一个 Consumer 消费。这保证了消息处理的顺序性(在分区内有序)。
- 组间共享:不同的 Group 可以消费同一个 Topic,互不影响(广播模式)。
- Rebalance(重平衡):当有消费者加入、退出或分区数量变化时,Kafka 会重新分配分区归属。
疑问1.那为什么别的服务或者在写的时候不用追加日志的方式,这样写入都极快?
1. "读数据"的灾难:如何快速找到你要的那条?
追加写最大的代价是:牺牲了检索(Query)性能。
-
Kafka 的场景(流):
- 消费者通常是按顺序消费。比如:"把昨天的所有日志给我"。
- 这种场景下,追加写的文件结构简直完美,从头读到尾就行了。
- Kafka 不需要支持:"请给我找出 ID = 8848 的那条消息"。如果非要找,它必须从文件头开始遍历扫描,效率极低(O(N))。
-
MySQL 的场景(状态):
- 业务通常需要随机读。比如:"查询用户 ID 为 1001 的余额"。
- 如果 MySQL 只用追加写:用户余额变动了 100 次,文件里就有 100 条记录。你要知道当前余额,必须把这 100 条都读出来推演一遍,或者倒序扫描。
- 所以 MySQL 必须用 B+ 树:它把数据像"字典"一样索引起来。虽然写入时要"随机"找到对应的页(慢),但读取时能精准定位(快)。
结论 :追加写是"写得爽,查得火葬场"。 只要你的业务涉及频繁的"按条件随机查询",纯追加写就行不通。
2. 空间膨胀:数据无限增长怎么办?
-
Kafka 的处理:
- Kafka 的数据是有保质期的(比如默认 7 天)。
- 因为它只追加,不修改,磁盘会越来越满。但 Kafka 的策略是:时间一到,直接把旧的日志文件(Segment)整个删掉。简单粗暴。
-
数据库的处理:
- 数据库存的是"当前状态",数据通常不能删。
- 如果用追加写,把所有的
UPDATE操作都变成INSERT(追加新值),那 1GB 的有效数据可能占用 1TB 的磁盘空间(全是历史版本)。 - 传统数据库采用了 Update-in-place(原地更新) 策略,直接覆盖旧值,节省空间。
3. 其实数据库也在用"追加写":WAL (Write-Ahead Logging)
这其实是一个反转。为了解决随机写慢的问题,MySQL 其实也偷学了 Kafka 的这一招!
MySQL(InnoDB 引擎)写入数据时,分为两步:
- 先写日志(Redo Log) :这一步是顺序追加写!非常快。只要日志写成功,就代表事务提交成功。
- 再刷磁盘(Dirty Page Flush) :后台线程会在空闲时,慢慢把内存中的数据更改,以随机写的方式更新到 B+ 树的数据文件中。
这就是著名的"日志先行"技术。
- Kafka:我就是日志,我只存日志。
- MySQL:我先写日志保证速度和不丢数据,然后再慢慢整理成方便查询的 B+ 树结构。
4. 只有 Kafka 用吗?看看 NoSQL (LSM-Tree)
既然追加写这么快,有没有数据库能兼顾"写得快"和"查得还行"? 有,这就是 HBase、Cassandra、RocksDB 使用的 LSM-Tree(Log-Structured Merge Tree) 结构。
- 原理 :
- 写入时:完全采用追加写(像 Kafka 一样快)。
- 读取时:因为数据是乱序追加的,读取会变慢。
- 补救 :后台不断进行 Compaction(合并压缩),把乱序的追加日志整理成有序的文件。
LSM-Tree 是一个折中方案:它的写入速度接近 Kafka,但读取速度不如 MySQL 的 B+ 树。