核心定位与动机
当前机器人操控领域存在两大关键瓶颈:一是主流视觉-语言-动作(VLM)模型(如RT-1/RT-2、OpenVLA)依赖任务与平台特定微调,换机器人或环境后鲁棒性骤降;二是基于世界模型的方法(如DreamGen)需依赖专门训练的预测模型(如Cosmos Predict),且训练数据需精心筛选机器人-场景对,通用性受限。
为解决这些问题,研究团队提出PhysicalAgent------一个融合迭代推理、扩散视频生成与闭环执行的机器人操控框架。其核心思路是:用基础模型(视觉语言模型、扩散视频模型)承担感知与推理的"重活",仅保留轻量级机器人适配层负责执行,最终实现跨形态、跨任务的通用操控,同时通过迭代修正提升执行鲁棒性。
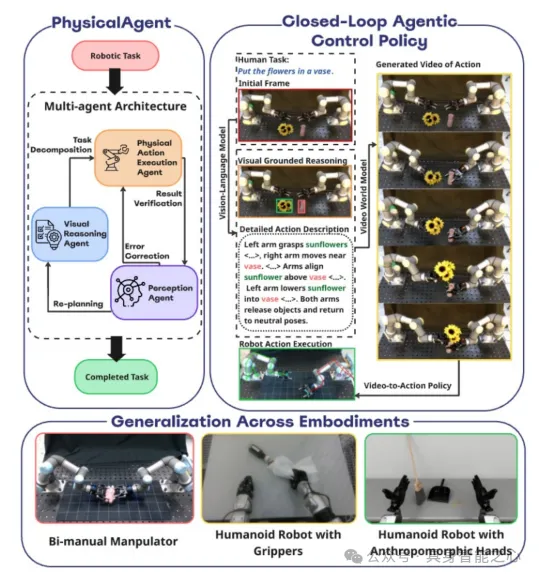
架构设计:泛化性的核心逻辑
该框架的核心原则是感知与推理模块不绑定特定机器人形态,仅需为不同机器人训练轻量级骨骼检测模型(计算开销小、数据需求低)。这种设计的合理性源于三点:
- 视频生成模型的天然优势:主流视频生成模型(如Wan 2.2、Seedance 1.0 Pro)预训练了海量多模态数据(含视频、第一视角活动记录),已隐含对物理过程、物体交互的理解;且支持API调用,无需本地训练即可快速集成,模型更新时直接替换即可。
- 人类式推理的对齐:视频生成模型能通过文本指令生成"执行过程的视觉想象",与人类思考动作的方式一致------无需了解机器人内部结构,仅通过指令即可生成合理动作的视觉描述。
- 跨形态泛化的实现:如figure 2所示,同一感知-推理 pipeline 能为三种不同形态的机器人(双臂UR3、Unitree G1人形、仿真GR1)生成不同操控任务(如捡球、开笔记本、传递保温杯)的视频,无需针对特定机器人重训,直接证明了架构的跨形态适配能力。

视觉语言模型(VLM)的接地推理作用
VLM是该框架的"认知核心",通过多次调用实现"指令-环境-执行"的接地,而非单次规划。具体作用分为四步:
- 任务分解:接收自然语言指令与初始场景图像后,将高level任务拆分为原子子任务(如"抓取物体""稳定容器""插入插槽"),搭建抽象规划与具体执行的桥梁。
- 场景上下文描述:为每个子任务生成带约束的文本提示(需包含物体空间关系、物理约束、机器人适配性),用于指导后续扩散模型生成可行的动作视频。
- 执行监控与修正:每次执行后,VLM对比"执行前-执行后"的图像,判断子任务完成情况,并输出三种决策:继续执行下一个子任务、重试当前动作、返回高层重新规划------这种闭环逻辑是长任务鲁棒性的关键。
- 模型无关性:框架不绑定特定VLM,实验中主要使用Gemini Pro Flash,但GPT-4o、Claude-3.5 Sonnet、QwenVL等模型均可直接替换,降低对单一模型的依赖。
扩散基世界模型:动作生成的新范式
该框架的核心创新是将"动作生成"重构为"条件视频合成",而非传统的直接学习控制策略。具体逻辑如下:
- 核心原理:使用现成的"图像-视频"基础模型(实验中用Wan 2.2,因速度与质量平衡),输入机器人当前相机帧与文本指令(来自VLM的子任务描述),生成物理合理的短动作视频------视频需包含物体动态、接触事件、场景因果关系(如"抓取杯子→移动到桌面"的连贯过程)。
- 与现有方法的差异:对比DreamGen等依赖专门预测模型的方法,该框架直接使用通用"图像-视频"模型,无需为特定机器人-场景对训练模型,大幅降低泛化门槛。
- 三大优势 :
- 降低部署成本:新机器人仅需训轻量级适配层,无需重训"图像-视频"模型;
- 快速迭代:当更优的"图像-视频"模型(如Seedance 1.0 Pro、Google Veo 2)出现时,直接替换即可,无需改动适配层;
- 可解释性:生成的视频可被人类检查,便于发现安全风险(如"动作可能碰倒物体"),提升人机协作安全性。
机器人适配层:从视频到电机指令的落地
生成的动作视频需转化为机器人能执行的电机指令,这一步是框架中唯一需机器人特定适配的部分,流程如figure 3所示:
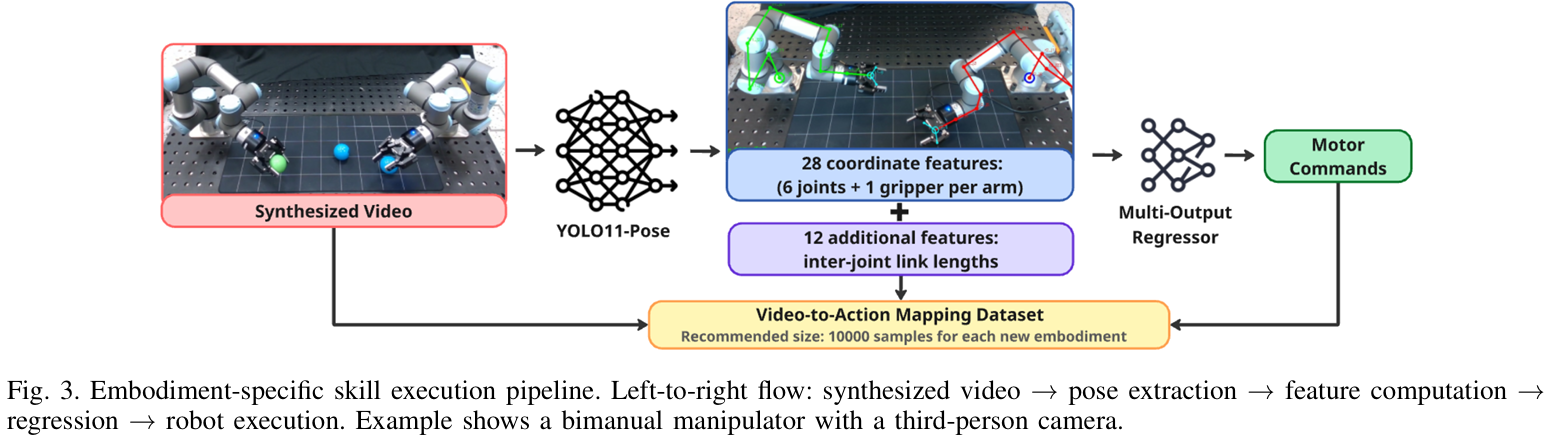
- 关键点提取:用微调后的YOLO11-Pose模型,从合成视频的每帧中提取机器人关节关键点------以双臂机器人为例,每臂需提取6个关节+1个抓手的关键点,共28个坐标特征;再计算关节间长度(12个特征),最终形成40维特征向量/帧。
- 回归器预测电机指令 :用"多输出回归器"(基于HistGradientBoostingRegressor,超参数为
max_iter=500、learning rate=0.1、min samples leaf=20、early stopping=True)将40维特征映射为低level电机指令。 - 适配层训练细节 :
- 数据量:每个新机器人仅需约1000个样本,30分钟即可收集完成;
- YOLO11-Pose训练:预训练后训150轮,batch size=8,图像尺寸=1280,早停耐心=50;优化器参数为
lr0=0.01、momentum=0.937、weight_decay=0.0005,热身3轮;用RTX 4090的4个worker训练,冻结前10层以保留预训练特征; - 兼容性:支持第三人称与第一视角相机,适配不同机器人的感知配置。
实验验证:效果与泛化性
实验分两类,分别验证"跨形态/感知模态的泛化性"与"迭代执行的鲁棒性"。
实验1:形态与感知模态研究
- 目标:验证该框架是否优于任务特定基线,以及跨形态泛化能力。
- 设置 :
- 平台:双臂UR3、Unitree G1人形、仿真GR1;
- 任务:13个操控任务(如盒子操作、捡球、按按钮、开冰箱等);
- 基线:ACT、RVT-LF、PerActLF、PerAct2;
- 流程:每个任务-平台对生成30个视频并执行, success rate按二分类统计。
- 关键结果 :
- 方法影响:ANOVA分析显示,该框架的success rate显著优于基线(
F(4,60)=5.04,p=0.0014),验证了扩散视频生成思路的有效性; - 平台影响:ANOVA显示平台对性能无显著影响(
F(2,36)=2.01,p=0.1485)------虽G1人形机器人的中位数success rate最高(因与人类数据对齐),但差异未达统计显著水平,说明框架跨形态泛化能力稳定,推翻了"特定形态更优"的初始假设。
- 方法影响:ANOVA分析显示,该框架的success rate显著优于基线(
实验2:物理机器人的迭代执行
- 目标:验证迭代"Perceive→Plan→Reason→Act" pipeline在物理场景的鲁棒性。
- 设置 :
- 平台:物理双臂UR3、物理Unitree G1人形;
- 任务:10个固定操控任务;
- 流程:生成计划与视频→执行→评估结果→可恢复则重规划,最多10次尝试;
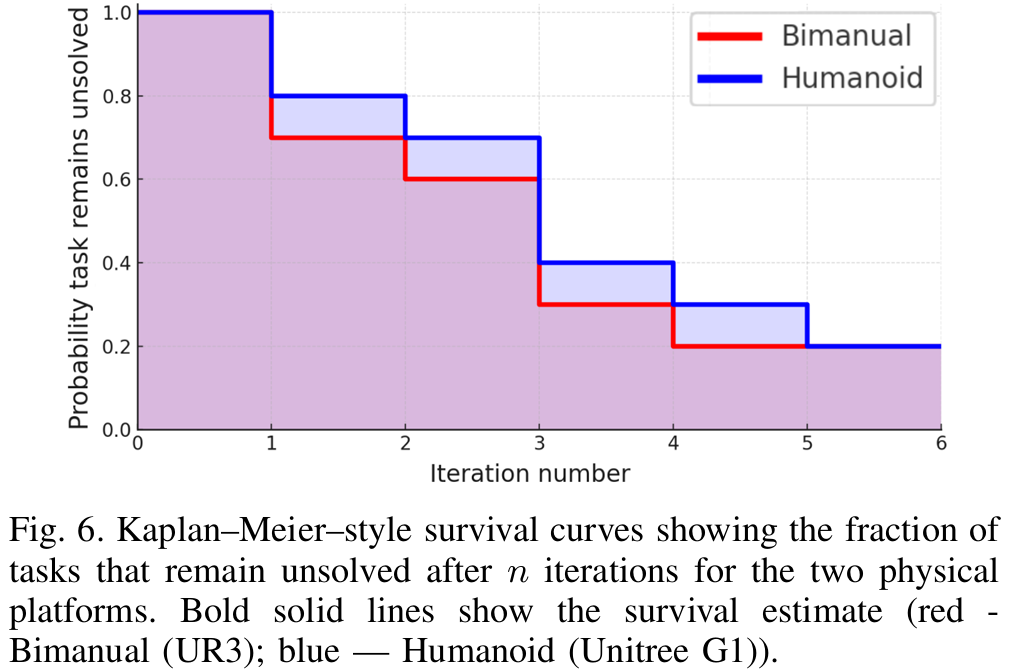
- 指标:最终success rate、首次尝试success rate、成功所需迭代次数、生存曲线(n次迭代后未完成任务比例)。
- 关键结果:
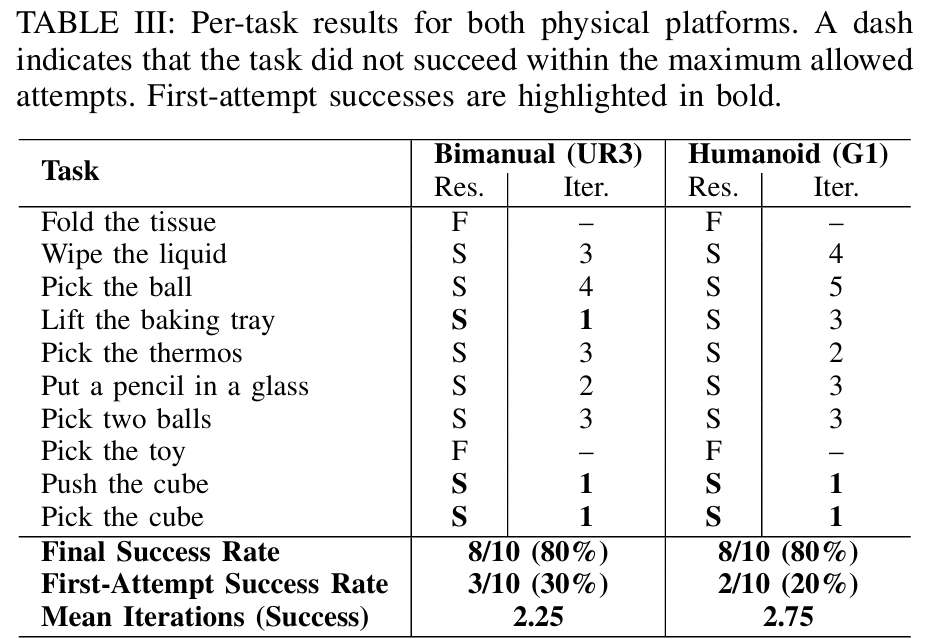
- 最终success rate:两个平台均达80%;
- 首次尝试success rate:UR3为30%,G1为20%;
- 迭代次数:UR3平均2.25次,G1平均2.75次;
- 生存曲线:如figure 6所示,前3次迭代后未完成任务比例骤降,4次迭代后几乎所有可完成任务均成功------证明迭代修正能有效弥补首次执行的不足,是提升鲁棒性的核心。
参考
1PhysicalAgent: Towards General Cognitive Robotics with Foundation World Models
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?