作者:卢旭
引言
随着 AI 技术从实验室走向日常,"机器学习""大模型""Transformer""MOE" 等词汇已不再是技术圈的专属。从智能聊天助手到电商推荐,从语音识别到自动驾驶,AI 正以多元形态融入生活。这篇文章按 "基础→核心→优化→落地→工具→术语" 的逻辑,用最通俗的大白话,把 AI 通识技术点讲透。帮助你我他她建立更完整的 AI 认知框架,理解技术背后的核心逻辑与实际价值,"看透" AI 技术的底层逻辑,让复杂概念变得清晰易懂。
一、基础概念(搞懂 AI 的 "底层逻辑")
1. 什么是 AI(人工智能)?
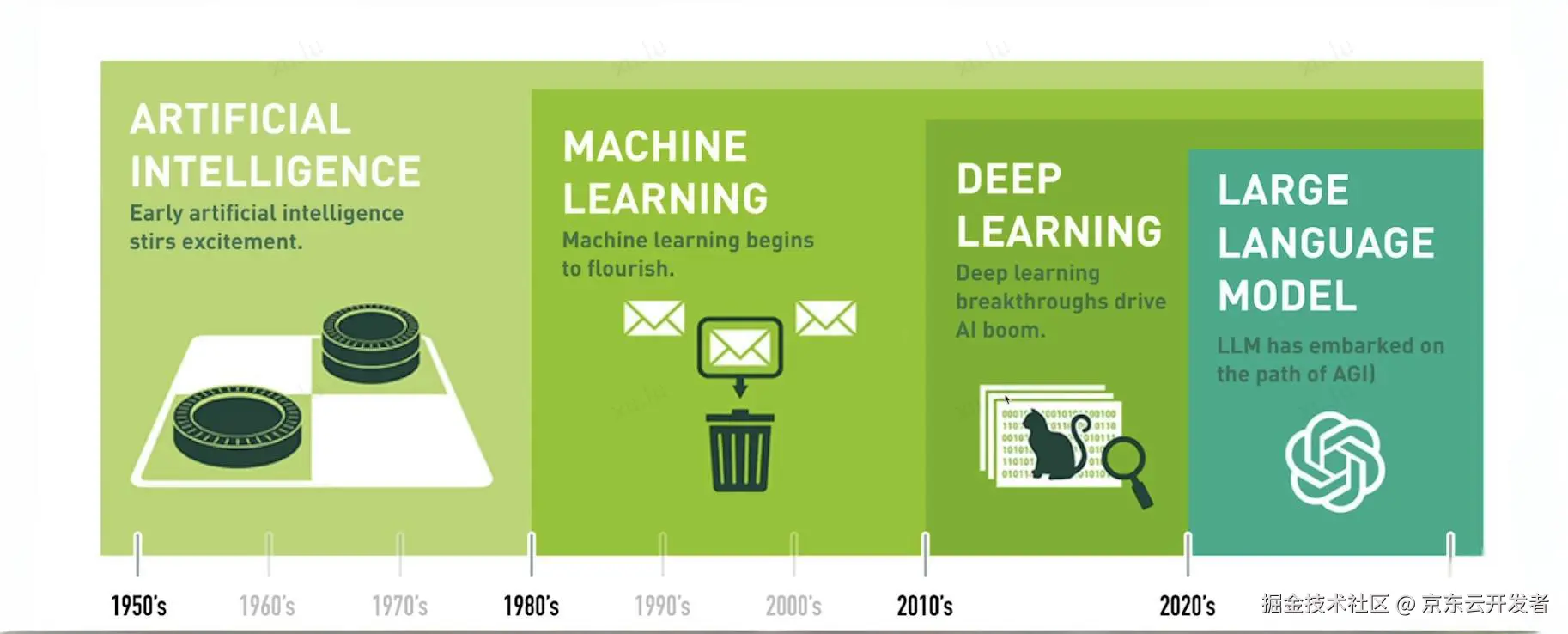
AI 本质就是 "让机器像人一样思考、干活" 的技术体系 ------ 不用人一步步指挥,机器能自己学规律、做决策。比如手机人脸识别、聊天机器人、自动驾驶,都是 AI 的具体应用。它不是单一技术,而是一堆技术的 "总称",就像 "家电" 包含冰箱、电视一样。这张网上流行的图概述了人工智能(AI)随着时间推移的发展历程,从早期阶段到机器学习、深度学习以及大型语言模型(LLM)的出现。
2. 什么是机器学习、强化学习、深度学习,它们的关系?
这仨是 AI 的 "核心方法论",是 "大圈套小圈" 的关系:
•机器学习:AI 的 "基础学习法"------ 让机器像 "学生刷题",从数据里自己找规律(比如看 1000 张猫的照片,自己总结 "尖耳朵 = 猫"),不用人逐条教规则。
•深度学习:机器学习的 "高级版"------ 给机器配了 "多层思考大脑"(神经网络),能分层挖数据的深层规律(比如先看猫的轮廓,再看细节,最后判断),适合处理图片、长文本等复杂任务。
•强化学习:机器学习的 "特训法"------ 让机器像 "宠物学技能",做对了给奖励(赢棋加分),做错了给惩罚(输棋扣分),反复试错后优化策略,比如 AI 玩游戏、下围棋都靠它。
关系总结:机器学习是 "总方法",深度学习是 "高级分支",强化学习是 "训练技巧",三者常搭配使用(比如 ChatGPT 用深度学习架构,靠强化学习优化回答)。
3. 机器学习三大范式
范式就是 "教机器干活的具体方式",核心区别是 "给不给机器'标准答案'"(标准答案叫 "标签",比如 "这张是猫"):
| 范式类型 | 通俗类比 | 核心逻辑 | 实际应用 |
|---|---|---|---|
| 监督学习 | 做 "带答案的习题册" | 给机器的所有数据都标好 "对错 / 结果",机器学完后直接套用规律 | 垃圾邮件识别、翻译软件、图片分类 |
| 无监督学习 | 整理 "无标签的杂物" | 只给机器原始数据,不标答案,让它自己找分类 / 规律 | 电商 "猜你喜欢"、客户群体划分、异常交易检测 |
| 半监督学习 | 做 "一半有答案的习题册" | 少量数据标答案(教基础规律),大量数据无答案(让机器举一反三) | 方言识别、罕见疾病诊断(标注数据少的场景) |
补充:强化学习也常被单独列为一类,核心是 "靠奖励 / 惩罚试错学习"。
4. 什么是神经网络?
神经网络是深度学习的 "核心骨架",模仿人脑神经元的连接方式,本质是 "按层排列的小计算单元集合",像 "工厂流水线":
•输入层:"原材料入口"------ 接收原始数据(比如图片像素、文字);
•隐藏层:"核心加工车间"------ 层数越多,深度学习越 "深",负责一步步提取数据特征(从轮廓到细节);
•输出层:"成品出口"------ 输出最终结果(比如 "这是猫""翻译结果")。
每个 "小计算单元"(神经元)就像 "小计算器",筛选有用信息、弱化无用信息,训练模型就是调整这些单元的 "工作规则",让它越来越精准。
5. 为什么深度学习要 "深"?
"深" 指神经网络的 "隐藏层多",不是为了凑数,而是为了 "挖深层规律":
•1 层网络(浅):只能看表面信息(比如图片的像素颜色),分不清猫和狗;
•3 层网络(中深):第 1 层看 "边缘 / 明暗"→第 2 层拼 "耳朵 / 圆形轮廓"→第 3 层判断 "尖耳朵 = 猫、圆形 = 球";
•10 层以上网络(深):能分层提取特征(先轮廓→再细节→再逻辑),比如识别 "小狗在追蝴蝶",能看懂 "动作" 和 "场景"。
简单说:"深" 的本质是 "分层提取特征":从表面的 "像素 / 文字",挖到深层的 "逻辑 / 场景";任务越复杂(写小说、解数学题),越需要 "深" 网络,才能从表面数据挖到核心逻辑。
6. 什么是预训练?
预训练就是给大模型 "打基础"------ 用海量通用数据(比如几百万本书、网页)让模型先学 "通用知识"(语法、常识、逻辑),相当于让学生先读完小学到大学的通识课程,具备基本能力。
预训练后的模型就像 "有基础的学霸",不用再从零学起,后续只需针对性培训(微调),就能适配具体任务(比如当客服、写代码)。
7. 什么是大模型 LLM?
LLM 是 "大语言模型" 的缩写,核心是 "用超大神经网络,学海量文字数据,能像人一样理解和生成语言"------ 通俗说就是 "读过全世界书的超级学霸"。
"大" 体现在三点:
•参数量大:相当于 "学霸的脑细胞多",能存更多知识(比如 GPT-4 有万亿级参数);
•数据量多:相当于 "学霸读的书多",覆盖书籍、论文、网页等,知识渊博;
•能力全:能聊天、写文案、解数学题、编代码,不用专门训练。
8. 什么是多模态大模型?
"模态" 就是 AI 能处理的 "信息类型"(文字、图片、语音、视频),多模态大模型就是 "全能选手"------ 能同时处理多种信息:
•比如你发一张风景照,它能描述内容、配诗,还能把诗读出来;
•常见例子:GPT-4V、文心一言多模态版,能看图片、听语音、写文字。
二、核心架构与机制(AI 的 "底层骨架")
1. 传统架构与演进:什么是 RNN/LSTM/GRU?
在 Transformer 出现前,处理文字、语音等 "序列数据"(有先后顺序的数据)靠这些架构:
•RNN:"逐字处理" 的架构 ------ 像读文章逐字念,只能记住最近的信息,处理长文本会 "忘事"(比如读 1000 字文章,后面忘了前面);
•LSTM/GRU:RNN 的 "升级版"------ 加了 "记忆单元",能记住更多长距离信息,但效率还是低,处理超长文本仍吃力。
这些架构是 AI 的 "老基建",现在主流大模型已不用,但了解它们能更好理解 Transformer 的创新。
2. 现代大模型基石:什么是 Transformer 架构?
Transformer 架构是一种以 "并行计算 + 自注意力机制" 为核心的神经网络结构,能高效捕捉数据(如文字)间的关联关系,是现代大模型(如 ChatGPT、DeepSeek)的基础骨架。2017 年由 Google 提出,是大模型 "高效运行" 的关键------ 决定了模型能跑多快、处理多长文本、效果多好,彻底解决了传统架构的痛点:
•核心创新:"并行计算 + 注意力机制"------ 不用逐字处理,能同时分析多个关键词,还能记住词与词的关系,又快又准;

•核心结构:分 "编码器(Encoder)" 和 "解码器(Decoder)"------ 编码器负责 "理解信息"(比如读文章),解码器负责 "生成信息"(比如写文章);

简单说,Transformer 架构就是让 AI 能同时看懂文字间的关联、还能快速处理长文本的 "高效大脑骨架"~。
3. 什么是位置编码?
Transformer 架构本身 "不认识文字顺序"------ 如果不加位置编码,机器会把 "我打你" 和 "你打我" 当成一回事。位置编码的核心作用是 "标记文字的先后顺序",让机器理解语序逻辑。
•通俗解释
◦比如处理句子 "小明吃苹果":位置编码给 "小明" 贴 "1 号"、"吃" 贴 "2 号"、"苹果" 贴 "3 号";
◦机器看到标签后,就知道 "1 号(小明)做 2 号(吃)动作,对象是 3 号(苹果)",不会搞反逻辑;
◦注意:位置编码不是简单的 1、2、3,而是用特殊数字编码,让机器同时理解 "相邻词关系更近"(如 "吃" 和 "小明""苹果" 的关系比 "小明" 和 "苹果" 更近)。
•核心作用
◦位置编码解决了 "语序混乱" 的问题,让机器能正确理解 "主谓宾""先后顺序" 等语言逻辑,是处理文本任务的关键小技巧。
4. 语义理解引擎:什么是注意力模型、自注意力机制、多头注意力?
这仨是 Transformer 的 "核心能力",本质是让机器 "抓重点、理关系":
| 概念名称 | 通俗类比 | 核心作用 (输入句子 "北京的故宫和上海的东方明珠,哪个更适合拍照?) |
|---|---|---|
| 注意力模型 | 读书时 "划重点" | 从海量信息中筛选出关键内容(如 "北京""故宫""拍照") |
| 自注意力机制 | 划重点后 "分析关系" | 不仅找重点,还能理清重点间的关联(如 "北京有故宫,故宫适合拍照") |
| 多头注意力 | 用 "多副眼镜看重点" | 从多个角度抓重点(一副看 "谁做什么",一副看 "在哪里做",一副看 "怎么做") |
5. 注意力优化升级:什么是 MLA、NSA 和代理注意力?
普通注意力机制处理长文本(比如 10 万字报告)时,会 "内存不够、跑不动",这三个是 "优化版",核心是 "省资源、提效率":
| 技术名称 | 通俗类比 | 核心逻辑 | 应用场景 |
|---|---|---|---|
| 多头潜在注意力(MLA) | 把厚书做成 "思维导图" | 压缩关键信息,减少内存占用(如把 10 万字报告的重点压缩成 1000 字) | 如DeepSeek 可处理 12 万字长文本 |
| 原生稀疏注意力(NSA) | 读书只看 "核心段落" | 跳过无用信息,只分析关键内容的关系(如忽略 "的、了、吗" 等虚词) | 如超长篇小说分析、论文摘要 |
| 代理注意力 | 先看 "目录" 再看正文 | 用 "摘要 / 目录" 替代原文找重点,再对应到原文(如先看书籍目录,再针对性看章节) | 如百万字级文档处理、知识库问答 |
三者的核心思路都是 "抓大放小",在不影响理解效果的前提下,通过压缩信息、减少计算量,实现长文本的高效处理。
6. 生成逻辑差异:什么是自回归生成与非自回归生成?
大模型生成文字的两种核心方式:
•自回归生成:"逐字写"------ 像人写字一样,写完一个字再写下一个,能保证逻辑连贯,ChatGPT、DeepSeek 都用这种;
•非自回归生成:"同时写多个字"------ 效率高,但容易逻辑混乱,适合对速度要求高、对连贯性要求低的场景(比如简单翻译)。
三、模型优化与适配技术(让 AI 更实用、更易部署)
1. 什么是 MOE 混合专家架构?
MOE(Mixture of Experts)即混合专家架构,核心是让 "专业的人干专业的事"------ 模型里有多个 "专家模块",每个模块只擅长一个领域,处理任务时只激活相关专家,既省算力又高效。主要结构拆解如下:

1.专家模块:不同科室的医生,每个专家只擅长一个领域(如 "代码专家" 专做编程,"数学专家" 专解难题,"中文专家" 专处理诗词和对话);
2.门控网络:医院导诊台,输入任务后先 "判断任务类型"(如 "怎么写 Python 代码" 属于编程任务);接收输入任务后,通过计算判断任务类型,筛选出最适合处理该任务的 1-2 个专家模块;
3.高效协作:只叫醒需要的专家,不会让无关专家参与(如编程任务只激活 "代码专家",不打扰 "数学专家")。
实际案例:DeepSeek-V3 的 MOE 架构
•总参数量:6710 亿(相当于 256 个专家模块);
•激活数量:处理任务时只激活 370 亿参数(8 个专家模块);
•优势:算力浪费少,训练成本仅为传统模型的 1/3,处理任务速度更快。
2. 什么是数据并行、模型并行、张量并行?
大模型参数量太大(比如万亿级),单台电脑装不下、训不动,这三种是 "分工训练" 的方式:
•数据并行:多台电脑 "一起练不同批次的数据"------ 比如甲练第 1-100 条,乙练第 101-200 条,最后汇总经验;
•模型并行:多台电脑 "各负责模型的一部分"------ 比如甲负责输入层,乙负责隐藏层,分工协作;
•张量并行:把模型的 "计算任务拆分"------ 比如一个复杂计算拆成 3 份,3 台电脑同时算,加快速度。
3. 什么是量化、知识蒸馏、剪枝?
大模型原本 "笨重"(需超大内存),这三种是 "给模型瘦身" 的技术,让它能装在普通电脑、手机上:
•量化:把模型里的 "精准数字简化"------ 比如 "1.23456" 改成 "1.23",像把 4K 照片转成清晰缩略图,体积变小但核心信息不变;
•知识蒸馏:让 "小模型学大模型的本事"------ 大模型像 "教授",小模型像 "学生",学生学教授的核心知识,体积变小 10 倍仍保精度;
•剪枝:给模型 "删无用部分"------ 去掉模型里没用的参数(比如很少用到的 "小计算单元"),让它更轻巧。
4. 什么是模型压缩?
就是把量化、蒸馏、剪枝等技术 "打包使用",综合给模型瘦身,比如把 10GB 的大模型压缩到 1GB,适配手机、智能手表等资源受限设备。
5. 什么是模型微调(Fine-tuning)?
微调就是给 "有基础的 AI 学霸" 做 "岗前培训"------ 预训练模型已经会通用知识(会说话、懂常识),微调时用少量专项数据(比如公司客服对话),教它做具体事:
•流程:通用大模型→输入专项数据→训练几天→输出专项模型(比如客服 AI);
•优势:省数据、省时间,不用从零训练;学完专项技能后,仍会聊天、算数学题等通用能力。
6. 什么是 LoRA、QLoRA?
普通微调仍需要不少算力,这俩是 "轻量级微调" 技术:
•核心逻辑:不改变大模型的核心参数,只给它加 "小插件"(少量新参数),教插件专项技能;
•优势:用普通电脑就能做,成本低、速度快,适合中小企业和个人。
7. 什么是领域自适应(Domain Adaptation)?
让大模型 "适配特定行业"------ 比如给通用大模型喂医疗数据,让它学会看病历、答医疗问题;喂金融数据,让它懂股票、基金,成为行业专用模型。
8. 什么是 RLHF(人类反馈强化学习)?
让模型的输出 "符合人类偏好"------ 比如模型回答后,人给打分(好 / 不好),再用这些分数训练模型,让它越来越懂 "人喜欢什么样的回答"(比如更礼貌、更精准)。
9. 什么是 RAG、KAG?
解决大模型 "知识过时、不懂专业领域" 的问题:
•RAG(检索增强生成) :AI "开卷考试"------ 回答问题前,先从外部知识库(比如公司文档、最新新闻)查相关信息,再结合自己的知识生成答案,比如问 "2025 年最新政策",它会先查 2025 年的资料;
•KAG(知识增强生成) :AI "把知识点记牢再答题"------ 预训练时就把结构化知识(比如百科词条、行业术语)融入模型,不用临时查,适合回答固定常识(比如 "牛顿三大定律")。
10. 什么是事实核查(Fact-checking)?
减少大模型 "胡说八道"(幻觉)的技术 ------ 模型生成答案后,自动核对事实(比如查资料确认 "北京到上海的距离"),纠正错误信息,让回答更靠谱。
11. 什么是对齐(Alignment)与安全护栏(Safety Guardrails)?
•对齐:让模型的目标和人类一致 ------ 比如不生成有害内容、不撒谎;
•安全护栏:给模型 "设禁区"------ 禁止生成暴力、歧视等有害内容,确保使用安全。
四、典型模型与生态实践(从理论到应用)
1. 主流大模型分类与代表
•通用大模型:能应对多种任务,比如 GPT 系列(OpenAI)、文心一言(百度)、Llama 系列(Meta)、通义千问(阿里)、Qwen(阿里云);
•垂直领域大模型:专注某一行业,比如医疗大模型(看病历、辅助诊断)、法律大模型(查法条、写合同)、编程大模型(DeepSeek-Coder、GitHub Copilot)。
2. 典型创新案例:DeepSeek 的核心创新点
DeepSeek 的核心创新围绕 "高效、低成本、高适配" 展开,通过架构优化、训练方法创新等,实现了 "用更少资源做出高性能模型" 的目标,让大模型更易普及。
核心创新点:
◦高效架构设计:MOE+MLA结合混合专家架构(MOE)和多头潜在注意力(MLA),6710 亿总参数量仅激活 370 亿参数处理任务,同时通过 MLA 压缩长文本信息,支持 12 万字长文本处理,算力成本降低 70% 以上。
◦低成本训练技术:强化学习 + 知识蒸馏采用 GRPO 强化学习算法,无需大量人工标注数据,通过 "试错反馈" 优化模型推理能力;结合动态知识蒸馏技术,将大模型能力迁移至小模型,体积减少 40% 仍保持精度,训练成本仅为 GPT-4 的 1/18。
◦高适配性部署:多场景 + 轻量化推出通用模型、编程模型(DeepSeek-Coder)、推理模型(DeepSeek-R1)等系列产品,适配不同场景;支持本地、云端、边缘设备部署,普通 GPU 即可运行,企业可快速集成到金融、教育、医疗等行业。
◦强推理能力:分步思考机制基于强化学习实现 "分步推理",模型处理数学、编程等复杂任务时,会像人类一样拆解步骤、逐步求解,准确率比肩 OpenAI o1 系列。
3. 部署形态:云端、边缘、本地部署
•云端部署:模型存在远程服务器上,通过网络使用(比如 ChatGPT 网页版),不用自己装;
•本地部署:把模型装在自己的电脑、服务器上,离线也能用,适合注重数据隐私的场景;
•边缘部署:把模型装在边缘设备上(比如手机、智能摄像头),响应快、不占网络带宽。
五、常用工具与交互技术(高效用 AI)
1. 什么是提示工程(Prompt Engineering)?
就是 "教 AI 怎么说话"------ 通过优化输入指令(提示词),让 AI 输出符合预期的结果:
•比如只说 "写旅游攻略",效果一般;但说 "写一篇适合亲子家庭的北京 3 日游攻略,含景点、餐饮、交通,语言简洁",结果更精准;
•核心:指令清晰、逻辑明确,帮 AI 懂你的需求。
2. 关于提示学习中的思维链、自恰性和思维树?
•一句话总结:
思维链:让 AI "会写步骤";
自洽性:让 AI "会查答案";
思维树:让 AI"会拆难题、选思路";都是为了让 AI 的回答更靠谱,只是简单问题用思维链,易出错问题加自洽性,复杂问题用思维树~
•三者对比
| 概念 | 通俗类比 | 核心动作 | 适合场景 |
|---|---|---|---|
| 思维链(CoT) | 写解题步骤 | 单一线性推理(一步一步) | 简单、有明确步骤的问题 |
| 自洽性 | 反复检查作业 | 多轮独立验证(换思路重算) | 易出错、结果不确定的问题 |
| 思维树(ToT) | 拆难题 + 多条思路探索 | 多分支推理(拆分 + 选优) | 复杂、多选项、需权衡的问题 |
•举例:
1.用思维树(ToT)拆问题:把大题拆成 3 个小题,每个小题想 2 种解法;
2.用思维链(CoT)写步骤:每个解法都写详细推导;
3.用自洽性验证:每个小题的 2 种解法结果一致,再汇总大题答案。
3. 什么是少样本 / 零样本提示?
提示工程的 "进阶技巧":
•少样本提示:给 AI "几个例子"------ 比如让它翻译方言,先给 2 个 "方言→普通话" 的例子,它就会模仿;
•零样本提示:不给例子,直接让 AI 做任务 ------ 比如让它写一首诗,全靠它自己的知识。
六、高频术语(读懂 AI 文档的关键词)
1.Token:AI 处理文字的 "最小单位"------ 中文是单个字或词语(比如 "我 / 爱 / AI"),英文是单词或词根,模型能处理的 Token 数量决定了文本长度(比如 4096 个 Token 约 3000 中文字);
2.标签(Label) :数据的 "标准答案",比如 "这张是猫";
3.批次(Batch) :训练时一次喂给模型的数据量(比如一次喂 32 条文本);
4.训练步长(Step) :模型处理一批数据 + 调整一次参数,算 1 个 Step(衡量训练进度);
5.轮次(Epoch) :把所有训练数据完整学一遍,算 1 个 Epoch(比如 10 万条数据,每批 32 条,约 3125 个 Step=1 个 Epoch)。
6.上下文(Context) :AI 的 "聊天记忆"------ 记住之前的对话内容,比如你先问 "北京天气",再问 "穿什么",AI 知道你指北京;
7.上下文窗口(Context Window) :AI 能记住的 "对话长度上限"------ 比如 4096 个 Token 窗口,超过就会忘前面的内容;
8.多轮对话(Multi-turn Conversation) :和 AI 聊好几轮(比如问问题→追更→再问),AI 能连贯回应;
9.Agent(AI 智能体) :"有自主能力的 AI 助手"------ 不用你一步步指挥,能自己理解任务、用工具、解决问题(比如让它规划旅游,自己查景点、订酒店);
10.A2A(Agent-to-Agent) :A2A是谷歌公开的一个协议,它能够实现不同的Agent之间能够实现直接互通,让智能体之间能够协作起来解决多任务的问题;A2A是让多个Agent能够连接起来,形成一个能力更加强大的Agent,解决多个Agent的通信效率问题。简单说就是多个 AI 智能体 "协作干活"------ 比如一个查资料、一个写文案、一个校对,合力完成复杂任务。
11.幻觉(Hallucination) :AI "胡说八道"------ 编造不存在的事实(比如假新闻、假数据)。
12.MCP(模型上下文协议) :MCP(Model Context Protocol)即 "模型上下文协议",简单说就是AI 聊天的 "记忆管理规则"------ 规定能记多少轮对话、优先保留什么信息,确保连贯又省内存。MCP让所有的API、工具、数据源能够按照统一的协议通信,只要按此规范,这些工具都可以被开发者直接调用;MCP解决了搭建单个Agent的效率问题,让搭建单个Agent的效率变得更高。
13.AGI(通用人工智能) :AI 的 "终极目标"------ 具备人类级智慧,能做任何人类能做的事(做饭、编程、科研),目前还在理论阶段;
14.ASI(超级人工智能) :比人类智慧还强的 AI,目前仅存在于设想中。
结语
AI 技术的核心逻辑可概括为 "从数据找规律到落地实用" 的递进过程,本质简洁且层层聚焦:
核心是让机器从数据中学习规律 ------ 机器学习是基础 "找规律",深度学习是 "多层递进找规律",大模型则是 "海量数据 + 多层架构" 的高效找规律。具体通过四层实现:
1.基础层:机器学习让机器 "从数据中找规律",神经网络是实现这一目标的 "骨架";
2.进阶层:Transformer 架构 + 注意力机制让机器 "高效找规律、记重点",解决长文本、高难度任务;
3.优化层:量化、蒸馏、微调、MOE 等技术让机器 "变小、变快、变便宜",适配更多场景;
4.应用层:大模型(如 ChatGPT、DeepSeek)是最终成果,直接服务于日常聊天、办公、编程等需求。
这篇文章覆盖 AI 全链路知识,从基础概念到架构、优化技术、落地应用及术语,希望能在此找到自己需要的内容。而学习 AI 的关键,正如 Transformer 架构的逻辑 ------ 先掌握整体全貌与基本原理,再层层深入剖析细节.....