计算规则
基于事实表数据集
如果你不做其他的限定,下面的这个公式就是计算A产品的revenue,用Price*Quantity。但是你这里都没管时间。
MEMBERSET [d/Product] ="A"
DATA([d/Account] ="Revenue")=RESULTLOOKUP([d/Account]="Price") * RESULTLOOKUP([d/Account]="Quantity")如果我要计算下面这个公司2018年四季度的所有收入。那用高级公式可以这么弄。
| Account | Product | Entity | Date | Value |
|---|---|---|---|---|
| Price | Sparkling Water | * | Oct.2018 | 500 |
| Price | Sparkling Water | * | Nov.2018 | 600 |
| Price | Sparkling Water | * | Dec.2018 | 700 |
| Quantity | Sparkling Water | Germany | Oct.2018 | 50 |
| Quantity | Sparkling Water | Germany | Nov.2018 | 70 |
| Quantity | Sparkling Water | Germany | Dec.2018 | 90 |
| Quantity | Sparkling Water | France | Oct.2018 | 30 |
| Quantity | Sparkling Water | France | Nov.2018 | 50 |
| Quantity | Sparkling Water | France | Dec.2018 | 80 |
MEMBERSET [d/Date]=("201810","201811","201812")
DATA([d/Account] ="Revenue")=RESULTLOOKUP([d/Account] ="Price",[d/Entity]="*") * RESULTLOOKUP([d/Account]="Quantity")这里面的第一个RESULTLOOKUP去找它的范围了:
| Account | Product | Entity | Date | Value |
|---|---|---|---|---|
| Price | Sparkling Water | * | Oct.2018 | 500 |
| Price | Sparkling Water | * | Nov.2018 | 600 |
| Price | Sparkling Water | * | Dec.2018 | 700 |
第二个RESULTLOOKUP也去找它的范围了:
| Account | Product | Entity | Date | Value |
|---|---|---|---|---|
| Quantity | Sparkling Water | Germany | Oct.2018 | 50 |
| Quantity | Sparkling Water | Germany | Nov.2018 | 70 |
| Quantity | Sparkling Water | Germany | Dec.2018 | 90 |
| Quantity | Sparkling Water | France | Oct.2018 | 30 |
| Quantity | Sparkling Water | France | Nov.2018 | 50 |
| Quantity | Sparkling Water | France | Dec.2018 | 80 |
然后去做乘法,是怎么样的呢?
| Account | Account | Product | Entity | Date | Value (Price) | Value (Quantity) | Result |
|---|---|---|---|---|---|---|---|
| Price | Quantity | Sparkling Water | Germany | Oct.2018 | 500 | 50 | 25000 |
| Price | Quantity | Sparkling Water | Germany | Nov.2018 | 600 | 70 | 42000 |
| Price | Quantity | Sparkling Water | Germany | Dec.2018 | 700 | 90 | 63000 |
| Price | Quantity | Sparkling Water | France | Oct.2018 | 500 | 30 | 15000 |
| Price | Quantity | Sparkling Water | France | Nov.2018 | 600 | 50 | 30000 |
| Price | Quantity | Sparkling Water | France | Dec.2018 | 700 | 80 | 56000 |
在最后的DATA()里返回值就会是这样的计算值。
| Account | Product | Entity | Date | Value |
|---|---|---|---|---|
| Revenue | Sparkling Water | Germany | Oct.2018 | 25000 |
| Revenue | Sparkling Water | Germany | Nov.2018 | 42000 |
| Revenue | Sparkling Water | Germany | Dec.2018 | 63000 |
| Revenue | Sparkling Water | France | Oct.2018 | 15000 |
| Revenue | Sparkling Water | France | Nov.2018 | 30000 |
| Revenue | Sparkling Water | France | Dec.2018 | 56000 |
新建数据
MEMBERSET [d/Date]=BASEMEMBER([d/Date]. [h/YQM],"2018")
DATA([d/Audit]="LogicCalc")=RESULTLOOKUP([d/Audit]="Input",[d/Date]=PREVIOUS(12))当我想新生成数据,比如上面把Audit = Input的从2017年1-12月的数据重新复制到Audit = LogicCalc的所有维度下,复制到2018年。
如果2017年只有半年有数据,那2018年的7-12月份也不会被填充,这时候就要去把CONFIG.GENERATE_UNBOOKED_DATA 设置成ON
符号反转
SAC计划中有四种财务账户类型:AST资产LEQ负债INC收入EXP费用
每一种账户类型都有一个预定义的符号。
不过高级公式默认是用绝对值计算的。
DATA([d/Account] ="Revenue")=RESULTLOOKUP([d/Account]="Income") + RESULTLOOKUP([d/Account]="Expense")比如INCOME是100,EXPENSE是50,结果会显示150.
如果你想用S4里设置好的EXP类型是负号。那你就把CONFIG.FLIPPING_SIGN_ACCORDING_ACCTYPE 设置成ON 。
CONFIG.FLIPPING_SIGN_ACCORDING_ACCTYPE=ON
DATA([d/Account] ="Revenue")=RESULTLOOKUP([d/Account]="Income") + RESULTLOOKUP([d/Account]="Expense")使用维度的属性值限定维度值
在MEMEBERSET里直接限定维度的值。
MEMBERSET [d/Entity].[p/Region]="Europe"这个比较简单,是限定所有属性里有Europe的Entity是哪些。
维度属性值定义计算
这个下面的就比较有意思了。
可以用维度的属性来定义计算范围。
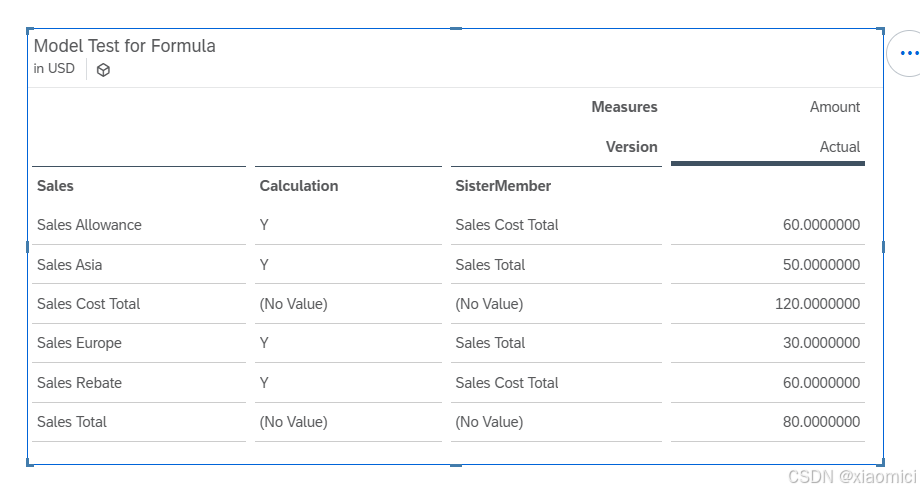
举例,你有一个特定的维度,它带了一个计算属性还有一个上级分组属性。
| Entity | Calculation | SisterMember |
|---|---|---|
| Sales Europe | Y | Sales Total |
| Sales Asia | Y | Sales Total |
| Sales Allowance | Y | Sales Cost Total |
| Sales Rebate | Y | Sales Cost Total |
| Sales Total | ||
| Sales Cost Total |
代码是这么写:
MEMBERSET [d/Entity].[p/Calculation] ="Y"
DATA() = RESULTLOOKUP([d/Sales] = [d/Sales].[p/SisterMember] )MEMBERSET的返回值是"Sales Europe", "Sales Asia", "Sales Allowance", "Sales Rebate",先把4个calculation是Y的成员选出来。
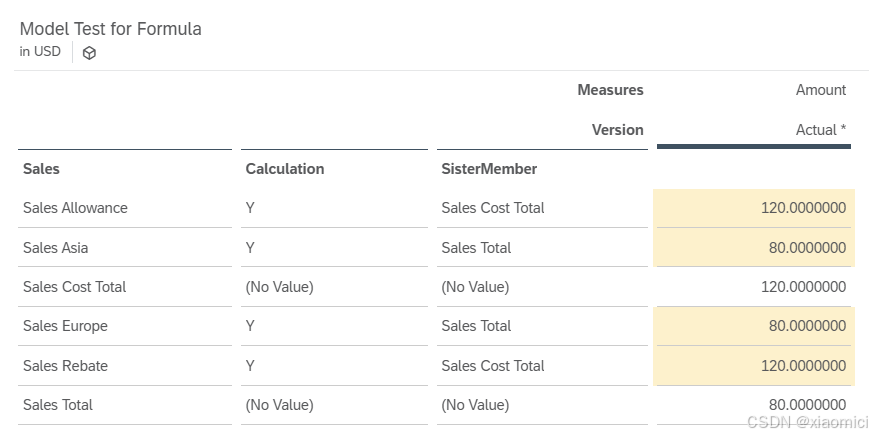
下一行是为前面MEMBERSET选中的成员,设置他们的DATA值等于他们各自的sistermember的DATA值。RESULTLOOKUP来找对应的sistermember的结果。所以最后会是"Sales Europe", "Sales Asia"的值被填充成Sales Total的值, "Sales Allowance", "Sales Rebate"的值被填充成Sales Cost Total的值。
最终结果显示为: