一、环境
Ubuntu20.04(virtualbox虚拟机)+mayan-edms4.10(docker版)
二、安装docker
sudo apt install docker.io配置docker国内源
sudo vi /etc/docker/daemon.jsondaemon.json文件内容:
{
"registry-mirrors": [
"https://docker.m.daocloud.io",
"https://docker.xuanyuan.me",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.ccs.tencentyun.com"
]
}三、docker安装mayan-edms
1、创建mayan目录
mkdir /home/hzy/mayan
cd /home/hzy/mayan2、下载docker-compose安装脚本
curl https://gitlab.com/mayan-edms/mayan-edms/-/raw/master/docker/docker-compose.yml -O
curl https://gitlab.com/mayan-edms/mayan-edms/-/raw/master/docker/.env -O3、运行脚本安装
sudo docker-compose up -d安装完毕后查看在运行的容器:
sudo docker-compose ps运行结果:

mayan-edms应用已经在运行,安装完默认OCR不支持中文 的。
文档管理系统 Mayan EDMS默认采用Tesseract,可以自己后端封装。
四、配置mayan-edms支持中文
1、安装Tesseract中文文件库
(1)进入mayan-edms应用容器:
sudo docker-compose exec app bash(2)安装中文OCR库与字体
apt-get update && apt-get install -y \
tesseract-ocr \
tesseract-ocr-chi-sim \
tesseract-ocr-chi-tra \
tesseract-ocr-chi-sim-vert \
tesseract-ocr-chi-tra-vert \
fonts-wqy-zenhei \
fonts-wqy-microhei(3)重命名OCR库文件
Tesseract库文件在/usr/share/tesseract-ocr/5/tessdata,安装完成后有chi_sim.traineddata 、chi_tra.traineddata、chi_sim_vert.traineddata、chi_tra_vert.traineddata等。chi_sim.traineddata表示简体中文,chi_tra.traineddata表示繁体中文。
mayan-edms使用的是ISO 639标准,zho 表示中文,所以将chi_sim.traineddata复制一份,命名为zho.traineddata

2、设置环境变量文件.env
docker方式安装的mayan-edms支持通过环境变量文件.env设置修改环境变量,容器启动的时候,会将变量传入容器。
修改.env文件,在文件末尾添加行:
MAYAN_LANGUAGE_CODE=zh-hans
MAYAN_TIME_ZONE=Asia/Shanghai
MAYAN_TESSERACT_LANGUAGE=chi_sim
MAYAN_OCR_LANGUAGE=chi_sim
MAYAN_OCR_PARSER_TESSERACT_LANGUAGE=chi_sim
MAYAN_PARSER_PDFTOTEXT_LANGUAGE=chi_sim
MAYAN_DOCUMENTS_LANGUAGE_CODES='["eng", "zho"]'
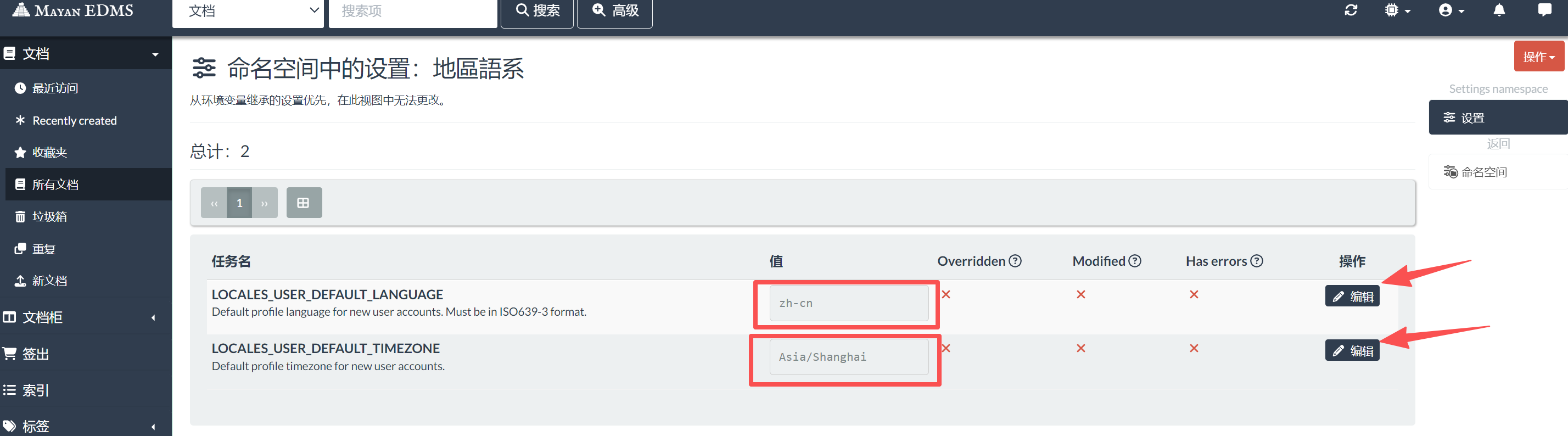
MAYAN_DOCUMENTS_LANGUAGE='zho'Mayan EDMS使用的标准是ISO 639-3,默认显示很多语言,我们删去不要的,默认支持中文和英语(MAYAN_DOCUMENTS_LANGUAGE_CODES='"eng", "zho"'),默认为中文(MAYAN_DOCUMENTS_LANGUAGE='zho')
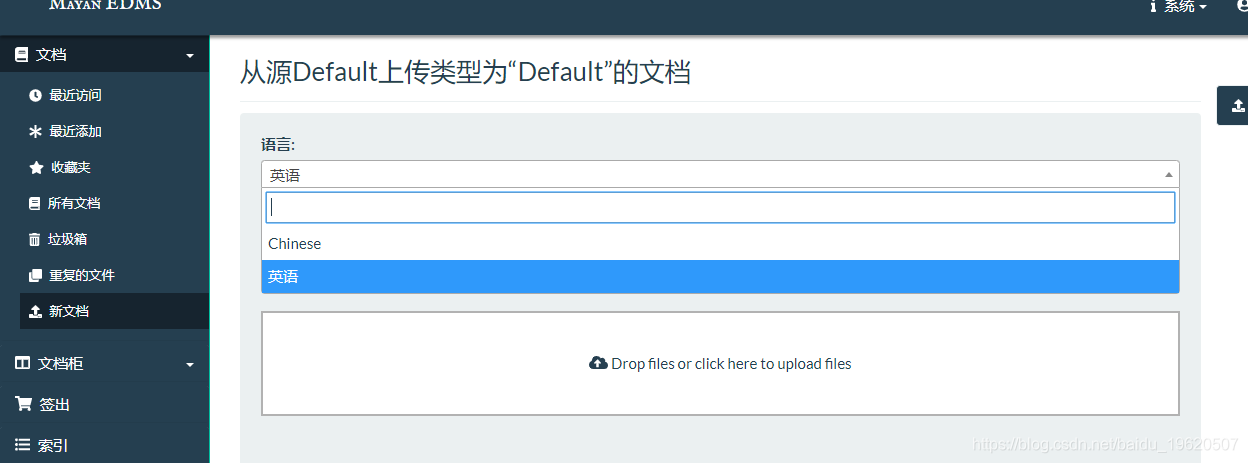
3、Web界面修改界面语言
4、制作中文OCR版docker镜像
docker镜像每次用命令 sudo docker-compose up -d 重新加载,都会还原设置,导致在容器里安装的服务或修改的设置丢失,所以在配置好容器后,制作一个中文本版docker镜像
(1)查看mayan-edms容器id
sudo docker ps //查看容器id
(2)制作容器
sudo docker commit CONTAINER_ID mayanedms-cn:s4.10 //将CONTAINER_ID替换为实际的容器id。就会得到一个名称为mayanedms-cn:s4.10的镜像
(3)运行中文OCR版docker镜像
修改.env文件中的镜像名称:
MAYAN_DOCKER_IMAGE_NAME=mayanedms-cn
运行命令 sudo docker-compose up -d 时,就会加载中文OCR版镜像了
五、其他
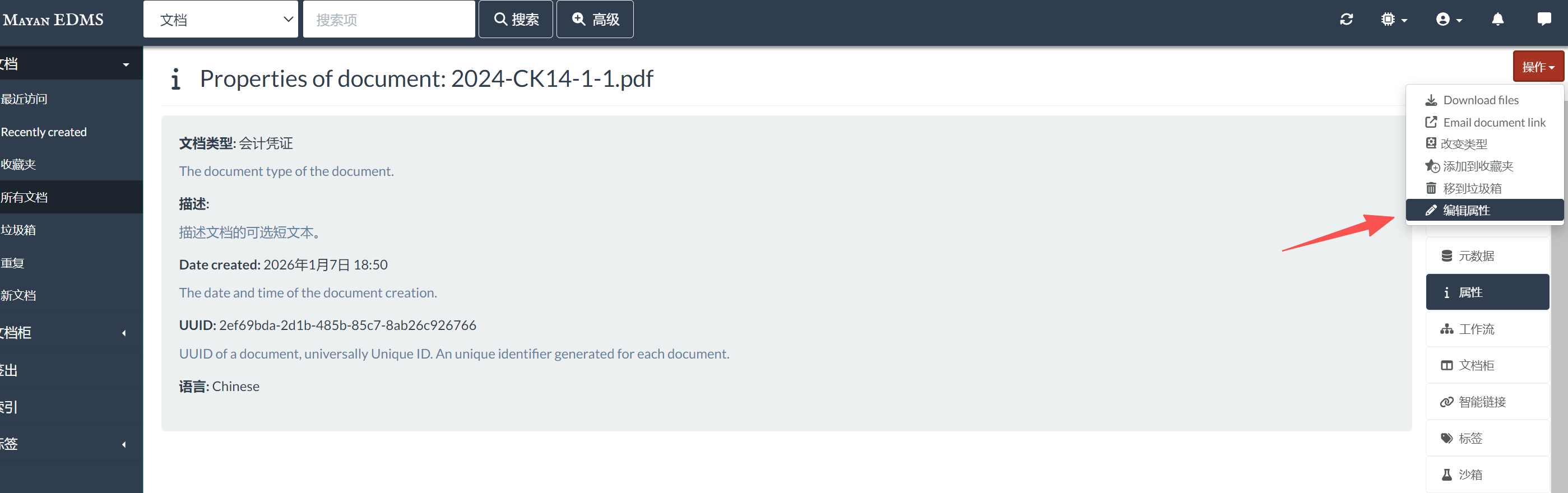
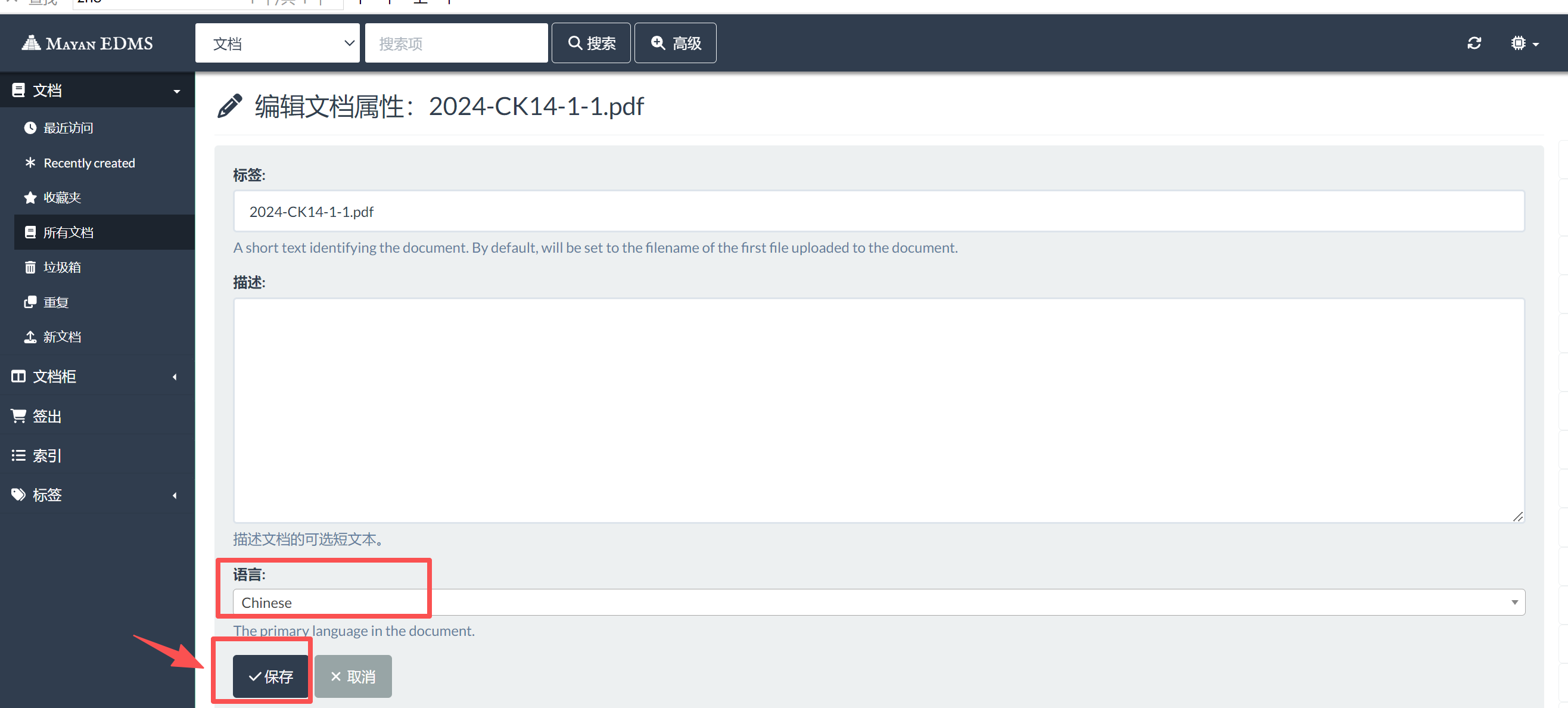
1、如果在设置中文OCR前已经上传了文档,导致文档语言错误,怎么办
(1)在文档详情页面,右上角操作,修改文档语言,保存
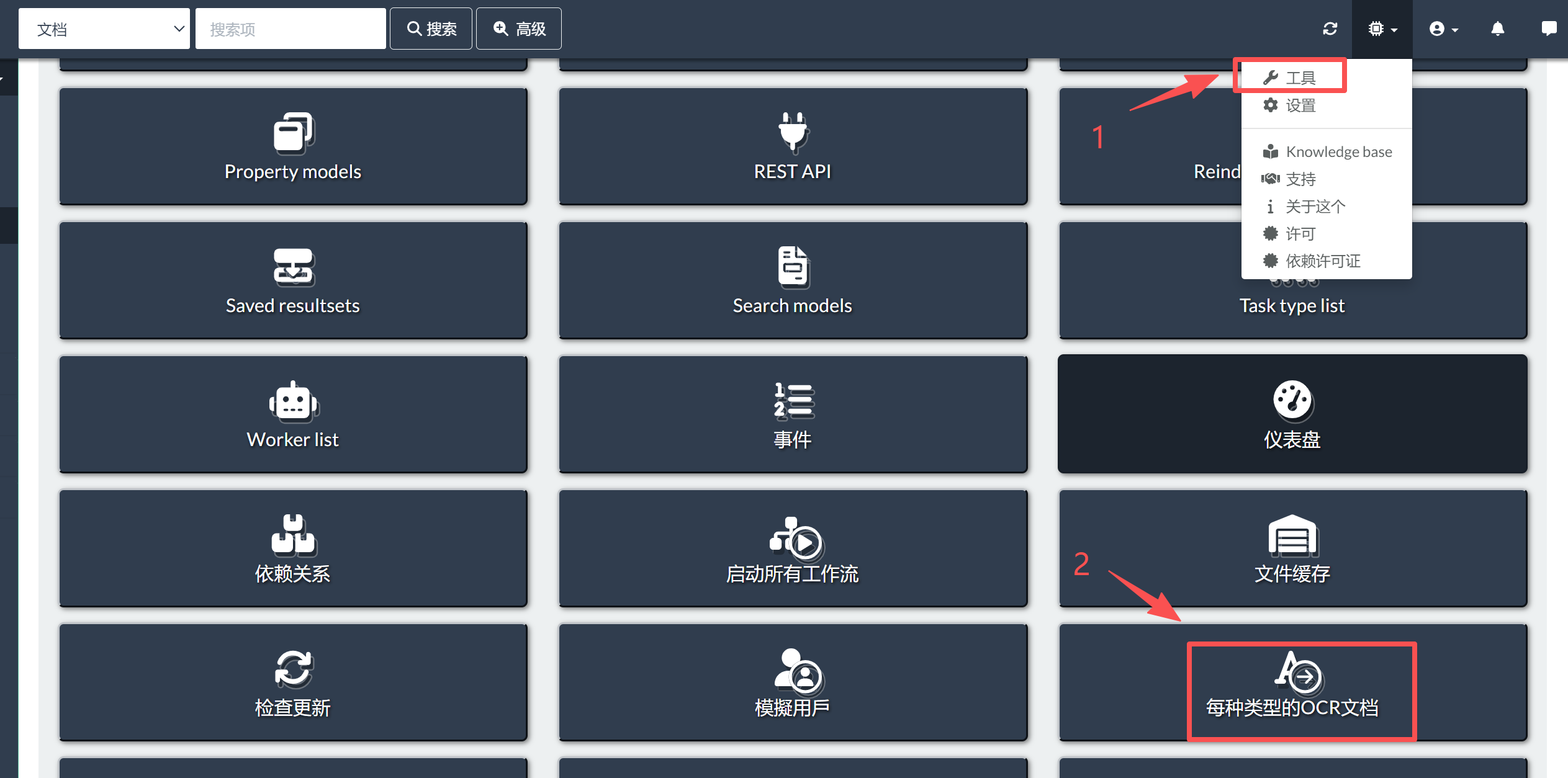
(2)重新进行OCR识别
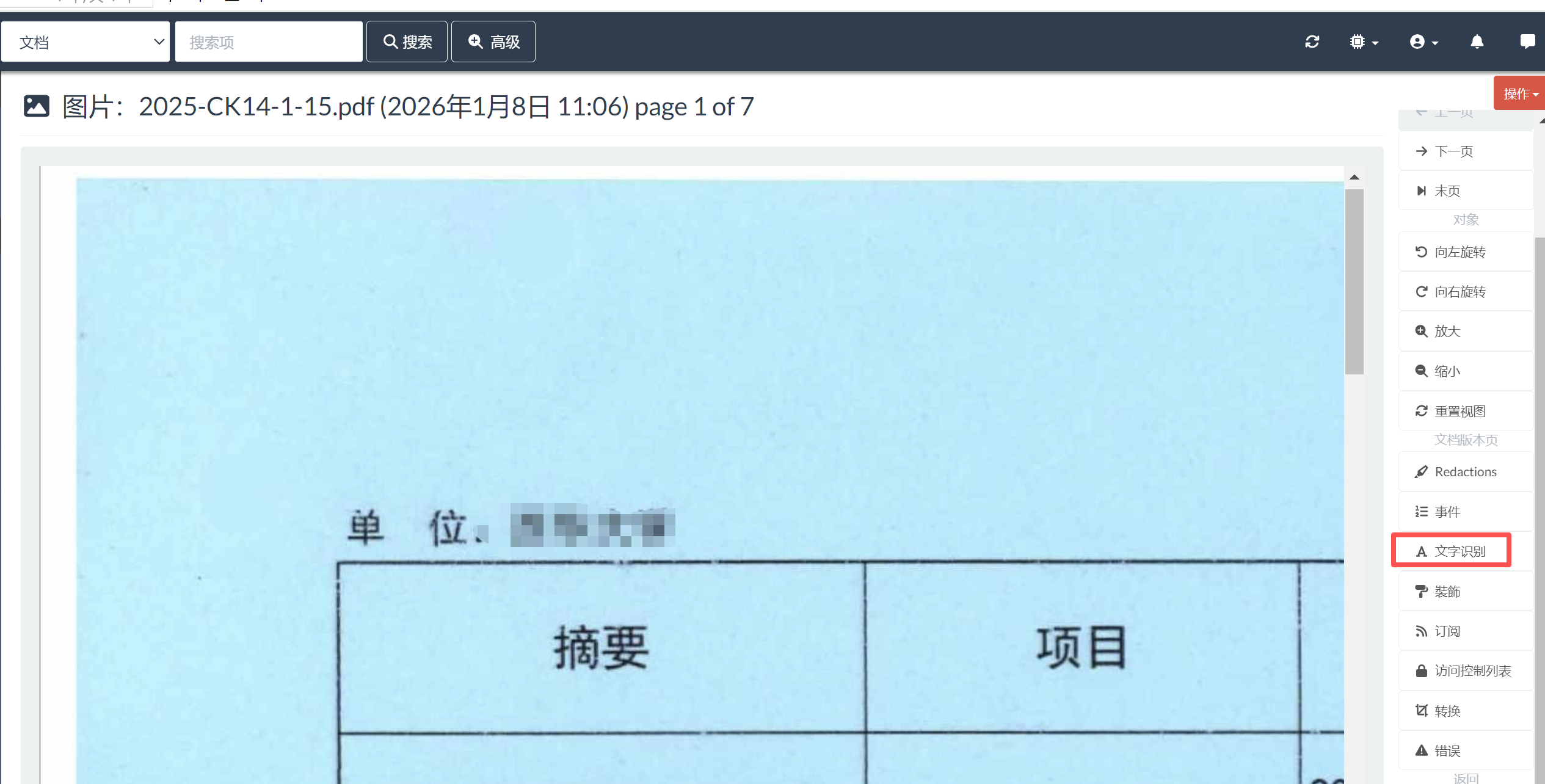
(3)测试文档页面文字识别,正常会显示识别到的文字: