前言
上一篇我们把"从 go build 进入 module 加载包"的入口梳理了从 go build 到模块加载的调用路径:当需要加载第三方包时,cmd/go/internal/load 包会调用 cmd/go/internal/modload 包来完成 module 相关的加载工作。
从这一篇开始,我们进入 modload 内部:它到底"加载并解析 module"指的是什么,解决了哪些问题,依赖图怎么被构建并回答"一个 import path 属于哪个 module"。
本文基于 Go 1.25.0 源码。
1. modload 到底负责什么
cmd/go/internal/modload 首先需要明确:
- 它不负责编译
- 它不负责单个 package 的语义
- 它负责构建
- module 依赖图
- build list
- module → 目录 映射
更具体一点,它的核心职责如下:
- 确定上下文 :当前是在
module模式还是workspace模式?主模块(main modules)有哪些?根目录在哪? - 解析配置 :读取并解析
go.mod(以及go.work),理解require/replace/exclude/...等规则。 - 构建依赖图并选版本 :把根依赖扩展成一张依赖图,并用
MVS收敛成"这次构建最终会用到的模块列表"(build list)。 - 查询:给定 import path,判定它属于标准库/主模块/第三方模块中的哪一个,并能定位到对应源码目录(必要时触发下载与校验)。
它不会亲自做所有事情:网络下载主要在 cmd/go/internal/modfetch,版本选择算法实现主要在 cmd/go/internal/mvs(以及 modload 对它的封装),包语义加载在 cmd/go/internal/load。modload 更像"总线/调度 + 状态容器 + 查询服务"。
2. 从哪里进入 modload
在"要编译/分析哪些包"这件事上,cmd/go/internal/load 是入口;当它判定需要 module 时,会调用 cmd/go/internal/modload/load.go 中的 LoadPackages(第 7 篇已经给出大致位置与链路)。
对 modload 来说,LoadPackages 需要两类输入:
- 要加载哪些包 :比如你执行
go build ./cmd/server,这里的./cmd/server就是目标包;modload还需要递归收集这个包 import 的所有包(直接依赖、间接依赖等)。 - 当前执行环境 :当前是在 workspace 模式还是普通 module 模式?是否使用了 vendor?
-mod=readonly还是允许写入?go.mod文件在哪(通过GOMOD环境变量或向上查找)?
modload 的输出是"包的位置信息和模块信息",而不是编译后的二进制文件。具体包括:每个包对应的源码目录路径、每个包属于哪个模块、这次构建需要哪些模块(build list)、有哪些依赖缺失或版本冲突。这些信息会被传给编译流程,用于实际编译。
3. 初始化:module 模式 / workspace 模式是怎么被确定的
在 modload 开始处理依赖之前,首先要确定的是执行环境:当前是在普通的 module 模式还是 workspace 模式?确定这次执行到底处在什么依赖语境。
3.1 主模块(main module)从哪来
- 普通 module 模式 :通常由
GOMOD(或向上查找到的go.mod)确定"主模块根目录"。 - workspace 模式 :由
GOWORK(或向上查找到的go.work)确定 workspace 根目录,然后由use列表确定"参与构建的主模块集合"。
这一步非常重要,因为它决定了:
- "哪些模块算 main modules"(在 workspace 里可能不止一个)
replace的解析基准路径(本地路径替换要相对谁)- 包在本地源码树中是否可见(某个包可能在另一个 main module 中)
3.2 -mod= / vendor 等策略如何影响 modload
对 modload 来说,"策略"主要影响两件事:
- 能不能写 :比如只读模式下,算出来缺了
go.sum或go.mod需要更新,也只能报错而不是落盘。 - 从哪拿源码 :vendor 模式下优先从
vendor/取包,不必(也不应)去下载模块缓存。
这些策略的判断并不都发生在 modload 内部,但 modload 会把它们统一归并为自身的状态,从而决定后续流程走哪条分支。
4. modload 的核心状态:Requirements 与 "build list"
理解 modload 的最快路径,是先理解它在维护什么。
4.1 Requirements 是"依赖要求"的载体
cmd/go/internal/modload/buildlist.go 中的 Requirements 用来表达:
- 根模块(root modules):从主模块(或 workspace 主模块集合)的直接依赖集合。
- direct/indirect 信息 :哪些依赖被认为是直接依赖(影响
go.mod里// indirect的标注与剪枝行为)。 - 图剪枝策略(pruning):module 图是"剪枝"还是"未剪枝",决定构图范围与查询方式。
- 模块图缓存 :
Graph()往往是懒加载的:第一次需要完整 module 图时才真正构建,并缓存起来供后续查询。
从语义上看:Requirements 不是最终结果,而是一组输入条件,用来算出最终的 build list 和 module 图。
4.2 build list 是"这次构建会用到的模块清单"
当 modload 做完版本收敛后,会得到一份 build list:一组 module@version,它代表这次构建的"模块边界"。
之后的大量工作都围绕 build list 展开:
- import path 的归属判定(候选模块集合来自 build list)
- 模块源码定位(缓存目录通常按
module@version组织) - 错误诊断(比如"这个包可能来自哪些模块"需要在 build list 上给出候选)
5. 解析 go.mod:从语法到规则
modload 自己不实现 go.mod 的语法解析,语法解析通常由 golang.org/x/mod/modfile(在 Go 源码树中以内部形式集成 vendor)完成。modload 关心的是:解析后指令的"依赖要求"和"查询结果"。
这里有三类指令对 modload 的影响最大:
5.1 require
require 的作用是提供"根模块"和"扩图的起点":
- 主模块:
go.mod里的require主要用来确定roots。 - 依赖模块:各自
go.mod的require提供依赖,推动module图继续扩展。
5.2 replace
replace 会改变"一个 module@version 应该从哪拿内容",带来两类效果:
- 替换为本地目录:模块内容从本地路径读取,版本在很多场景下退化为"占位信息",但 module path 仍然用于匹配 import path。
- 替换为另一个 module@version:图上的节点仍是"被替换者",但解析/下载/校验的对象可能变成"替换目标"。
对 modload 来说,关键不是"replace 语法",而是"当我要解析某个包或下载某个模块时,我应该获取哪个具体来源"。
5.3 exclude(以及其它约束类指令)
exclude 的作用更像对版本空间施加约束:某些版本不可选。
它通常不会直接决定"选哪个版本",而是影响"当 MVS 试图选到某个版本时是否需要回退/报错/改道"。在具体实现上,modload 会在图构建与版本查询过程中把这些约束考虑进去。
6. 构建 module 图:modload 如何把依赖加载成一张图
从外部看,"构图"像是一口气把所有依赖都拉下来;但从 modload 内部看,它更像一个按需扩展、可缓存的过程。
6.1 图的边从哪来
module 图的边来自各个模块自己的 go.mod:
- 节点:
module.Version(module path + version) - 有向边:
A@v -> B@w(表示 A 的go.mod里 require 了 B@w)
因此,要得到边,必须能读到依赖模块的 go.mod。modload 有两条分支:
- 定位模块内容:本地 replace、模块缓存目录、或需要下载。
- 读取 go.mod :对外部模块,常见做法是先拿到它的
go.mod(可能不需要完整源码树),并把 require 边加入图中。
6.2 "按需构图"与缓存
modload 并不总是立刻把整张图构出来:
- 只关心少量包(
go list,go mod why等)时:通常只扩展与这些包相关的那部分依赖边。 - 需要完整依赖分析时:才会触发更完整的建图。
实现上一般是 Requirements.Graph()(或类似入口)第一次调用时建图并缓存;后续查询直接读缓存,避免重复下载和重复解析。
6.3 版本收敛:modload 如何接入 MVS
MVS(Minimal Version Selection)的输入是"根模块 + 图的边(每条边给出最低版本要求)",输出是对每个 module path 的一个选中版本。
modload 的核心工作,是把现实中的各种约束整理成 MVS 能理解、能参与计算的输入,比如:
- 从各模块的
require收集"最低版本要求" - 把
replace/exclude这类规则在合适的阶段应用到"版本查询/模块读取"的行为上 - 在
workspace场景下,把多个main modules的根依赖合并成roots(但仍要保留各自的本地可见性语义)
最终产物就是 build list:后续 import 解析与模块定位基本都围绕它运转。
7. 解析 import path:modload 怎么回答"这个包属于哪个 module"
当 build list 在手时,modload 才真正有能力稳定回答"包归属"。
这一步的关键点在 cmd/go/internal/modload/import.go(典型入口是 importFromModules 函数),它主要做三件事:
7.1 候选模块选择:最长前缀匹配
Go 的 import path 到 module 的映射核心是"module path 是 import path 的前缀",因此候选 module 来自 build list 里所有满足前缀条件的 module。
当有多个候选时,通常采用最长前缀优先:
example.com/a与example.com/a/b都可能是前缀- 但对
example.com/a/b/c,更可能属于example.com/a/b
这正是第 4 篇提到的"最长前缀匹配"在代码里的具体实现:它不只是概念规则,而是 modload 基于 build list 做出的一个确定性选择。
7.2 确认包目录是否存在
"前缀匹配"只给出候选模块,并不能保证该模块里确实有这个包目录。
因此 modload 会进一步做"目录存在性确认":
- 计算包相对模块根的子路径
- 在模块真实根目录下检查该子目录是否存在且可作为包目录
如果目录不存在,modload 会把它记为"候选但不包含"(常用于后续更好的错误信息提示),并继续尝试下一个候选模块,直到找到真正包含该包的模块,或宣告失败。
7.3 replace 与 workspace 对目录解析的影响
同一个 module@version,在不同规则下"真实根目录"可能不同:
- 有本地
replace:根目录直接指向本地路径 - 在
workspace:如果包属于某个 main module,那它可能直接从该 main module 的源码树解析,而不是模块缓存
因此,modload 解析包时并非只是遍历 build list;build list 负责限定范围,而具体落到哪个 module 则由规则进一步判定。
8. 什么时候会触发下载与校验
modload 自己不实现下载,但它决定"何时必须拿到模块内容",从而触发 modfetch 的动作。
在 module 模式下,典型触发点有两类:
- 为了读依赖模块的
go.mod:构图阶段需要边信息,就必须能拿到依赖模块的go.mod。 - 为了确认某个包目录存在:解析 import path 时,需要进入模块根目录检查包目录,这通常要求模块内容在本地可用。
对 go.sum 的参与,通常体现为:当某个模块内容需要被下载/读取时,会进入校验流程,确保内容与 go.sum 记录一致(细节后续再说)。
modload 在这里的关键点是"延迟":能不下载就不下载,能只拿 go.mod 就先只拿 go.mod,并把已获取的结果缓存,避免重复 IO。
9. 图剪枝(pruning):为什么 modload 不能"永远按整图思考"
从 Go 1.17 起,模块加载进入"更强的剪枝语义":并不是所有 go.mod 里出现的 require 都必须在任意构建中被加载进完整图里;很多时候,图是围绕"你实际要加载的包集合"被裁剪过的。
对 modload 来说,剪枝影响两件事:
- 图的构建范围:是否需要扩展到"所有传递依赖",还是只需要扩展到"与目标包相关的那部分"。
- 错误语义 :同样一个缺包问题,在剪枝与未剪枝模式下,可能对应不同的诊断文本与修复建议(但
modload本身只负责产出诊断所需的信息)。
这种差异会在 Requirements 的 pruning 状态中被明确标出来:它不只是为了构建,而是会改变模块加载规则的一个关键设定。
10. workspace(go.work)场景下,modload 多做了什么
workspace 模式可以看作:把多个 module 根目录拼成一个"更大的主工程",并允许它们之间通过本地源码直接互相可见。
因此 modload 在 workspace 下会多承担两类工作:
- 管理多个 main modules :同一次构建可能同时包含多个主模块,它们各自都有
go.mod、各自的replace、各自的直接依赖集合。 - 合并依赖要求并保持本地优先级 :最终
build list仍需全局一致(版本要收敛),但包解析时要优先解析到workspace内的源码树(属于 main modules 的包不应退化到模块缓存去找)。
从实现上,workspace 更像把 main module 从一个变成一个集合,并在"包归属判断"阶段增加"先在 main modules 中找"的分支。
11. 落盘:go.mod / go.sum 的更新在 modload 里处于什么位置
modload 在计算与查询过程中,会产生"应该更新"的信息,例如:
- build list 推导出来后发现某些依赖需要补充到
go.sum - 依赖剪枝、以及
direct/indirect重新判定后,发现需要更新go.mod里require的条目或注释标记
但"是否允许写入"取决于命令与策略(如只读、vendor 等)。因此 modload 通常把"需要写入的变化"作为一种派生结果保留,并由更上层的命令流程决定是否实际写文件或报错退出。
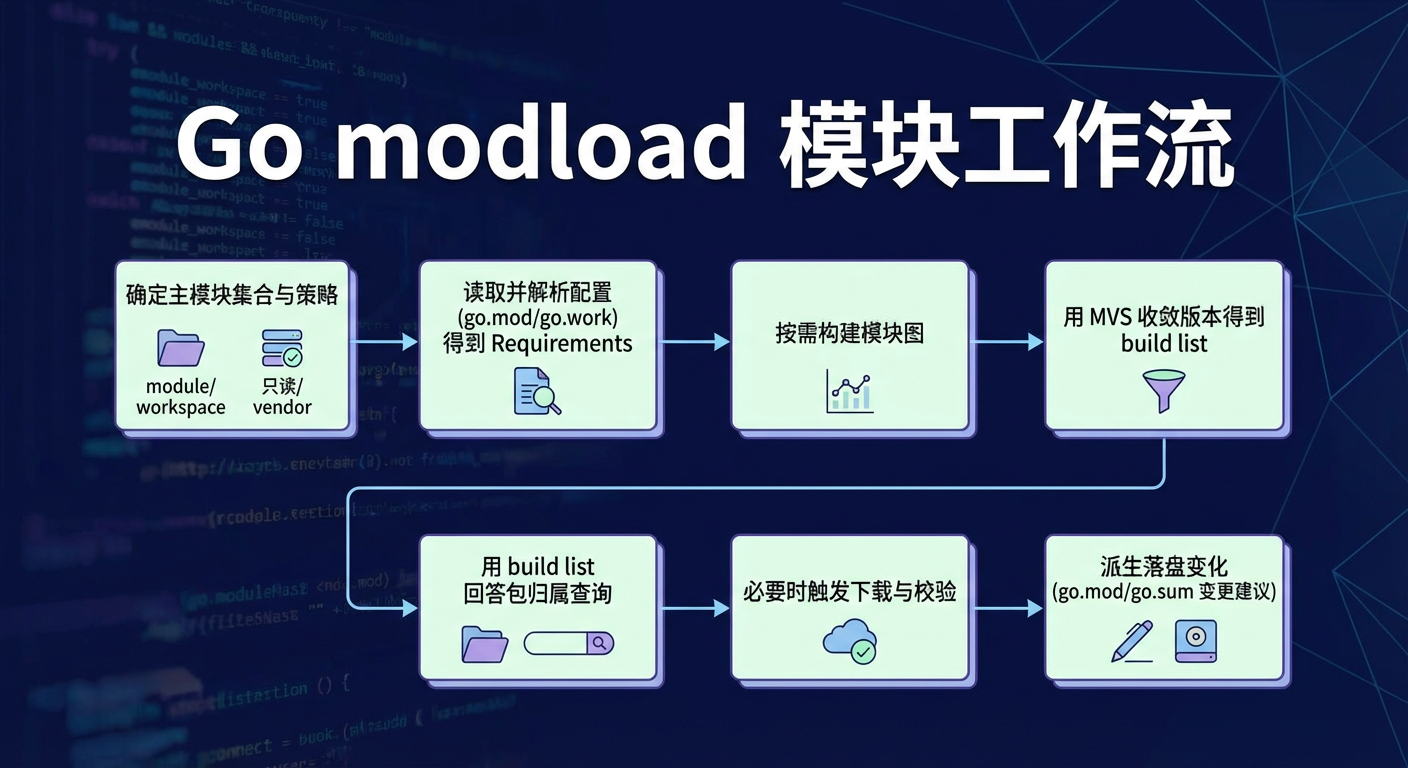
12. modload 的数据流
如果你把 modload 当成一个黑盒,它的内部数据流大致是:
- 确定主模块集合(module/workspace)与策略(只读/vendor 等)
- 读取并解析配置 (
go.mod/go.work)得到Requirements(roots + 规则) - 按需构建模块图 (读取依赖模块的
go.mod,扩展边,缓存图) - 用 MVS 收敛版本得到 build list
- 用 build list 回答包归属查询(最长前缀匹配 + 目录存在性确认 + replace/workspace 规则)
- 必要时触发下载与校验,补齐查询所需的模块内容
- 派生落盘变化 (
go.mod/go.sum变更建议),由上层决定写入或报错
到这里,你可以把 modload 理解为:它既要"讲道理"(依赖规则与版本算法),也要"跑现场"(本地目录与模块缓存、下载与校验),最终为包加载提供一个可重复、可缓存、可诊断的模块世界。
可以这样理解 modload:落实依赖规则和版本选择,处理本地目录、模块缓存与下载校验,最终为包加载构建出一个可复现、可缓存、可排查的确定环境。