| 大家好,我是工藤学编程 🦉 | 一个正在努力学习的小博主,期待你的关注 |
|---|---|
| 实战代码系列最新文章😉 | C++实现图书管理系统(Qt C++ GUI界面版) |
| SpringBoot实战系列🐷 | 【SpringBoot实战系列】SpringBoot3.X 整合 MinIO 存储原生方案 |
| 分库分表 | 分库分表之实战-sharding-JDBC分库分表执行流程原理剖析 |
| 消息队列 | 深入浅出 RabbitMQ-RabbitMQ消息确认机制(ACK) |
| AI大模型 | 零基础学AI大模型之LLM大模型存储记忆功能 |
前情摘要
1、零基础学AI大模型之读懂AI大模型
2、零基础学AI大模型之从0到1调用大模型API
3、零基础学AI大模型之SpringAI
4、零基础学AI大模型之AI大模型常见概念
5、零基础学AI大模型之大模型私有化部署全指南
6、零基础学AI大模型之AI大模型可视化界面
7、零基础学AI大模型之LangChain
8、零基础学AI大模型之LangChain六大核心模块与大模型IO交互链路
9、零基础学AI大模型之Prompt提示词工程
10、零基础学AI大模型之LangChain-PromptTemplate
11、零基础学AI大模型之ChatModel聊天模型与ChatPromptTemplate实战
12、零基础学AI大模型之LangChain链
13、零基础学AI大模型之Stream流式输出实战
14、零基础学AI大模型之LangChain Output Parser
15、零基础学AI大模型之解析器PydanticOutputParser
16、零基础学AI大模型之大模型的"幻觉"
17、零基础学AI大模型之RAG技术
18、零基础学AI大模型之RAG系统链路解析与Document Loaders多案例实战
19、零基础学AI大模型之LangChain PyPDFLoader实战与PDF图片提取全解析
20、零基础学AI大模型之LangChain WebBaseLoader与Docx2txtLoader实战
21、零基础学AI大模型之RAG系统链路构建:文档切割转换全解析
22、零基础学AI大模型之LangChain 文本分割器实战:CharacterTextSplitter 与 RecursiveCharacterTextSplitter 全解析
23、零基础学AI大模型之Embedding与LLM大模型对比全解析
24、零基础学AI大模型之LangChain Embedding框架全解析
25、零基础学AI大模型之嵌入模型性能优化
26、零基础学AI大模型之向量数据库介绍与技术选型思考
27、零基础学AI大模型之Milvus向量数据库全解析
28、零基础学AI大模型之Milvus核心:分区-分片-段结构全解+最佳实践
29、零基础学AI大模型之Milvus部署架构选型+Linux实战:Docker一键部署+WebUI使用
30、零基础学AI大模型之Milvus实战:Attu可视化安装+Python整合全案例
31、零基础学AI大模型之Milvus索引实战
32、零基础学AI大模型之Milvus DML实战
33、零基础学AI大模型之Milvus向量Search查询综合案例实战
33、零基础学AI大模型之新版LangChain向量数据库VectorStore设计全解析
34、零基础学AI大模型之相似度Search与MMR最大边界相关搜索实战
35、零基础学AI大模型之LangChain整合Milvus:新增与删除数据实战
36、零基础学AI大模型之LangChain+Milvus实战:相似性搜索与MMR多样化检索全解析
37、零基础学AI大模型之LangChain Retriever
38、零基础学AI大模型之MultiQueryRetriever多查询检索全解析
39、零基础学AI大模型之LangChain核心:Runnable接口底层实现
40、零基础学AI大模型之RunnablePassthrough
41、零基础学AI大模型之RunnableParallel
42、零基础学AI大模型之RunnableLambda
43、零基础学AI大模型之RunnableBranch
44、零基础学AI大模型之Agent智能体
45、零基础学AI大模型之LangChain Tool工具
46、零基础学AI大模型之LLM绑定Tool工具实战
47、零基础学AI大模型之LangChain Tool异常处理
48、零基础学AI大模型之CoT思维链和ReAct推理行动
49、零基础学AI大模型之Zero-Shot和Few-Shot
50、零基础学AI大模型之LangChain智能体执行引擎AgentExecutor
51、零基础学AI大模型之个人助理智能体之tool_calling_agent实战
52、零基础学AI大模型之旅游规划智能体之react_agent实战
53、零基础学AI大模型之LLM大模型存储记忆功能
本文章目录
- 零基础学AI大模型之LLM存储记忆功能之BaseChatMemory
-
- 一、什么是BaseChatMemory?
- 二、BaseChatMemory的核心作用
-
- [1. 标准化接口:统一"存"和"取"的方法](#1. 标准化接口:统一“存”和“取”的方法)
- [2. 状态管理:维护对话历史](#2. 状态管理:维护对话历史)
- [3. 高扩展性:支持自定义逻辑](#3. 高扩展性:支持自定义逻辑)
- 三、BaseChatMemory的关键属性和核心方法
-
- [1. 关键属性:chat_memory](#1. 关键属性:chat_memory)
- [2. 核心方法:3个常用技能](#2. 核心方法:3个常用技能)
- 四、BaseChatMemory的常用子类:不用自己写,直接用!
- 五、子类实战:3个案例
- 六、怎么选BaseChatMemory子类?一张表搞定!
- 总结
零基础学AI大模型之LLM存储记忆功能之BaseChatMemory
哈喽,各位小伙伴!👋 上一篇我们聊了LLM存储记忆的核心概念和应用场景,知道了短期记忆和长期记忆的区别。今天咱们就往深了钻------聚焦LangChain中聊天记忆的"老祖宗"BaseChatMemory,搞懂它是怎么定义记忆接口、管理对话历史的,还有它的几个常用子类怎么实战使用。就算部分API有过期情况,咱们也能掌握核心思想,轻松上手!
一、什么是BaseChatMemory?

BaseChatMemory是LangChain中所有聊天型记忆模块的基类,简单说就是"所有聊天记忆的模板"------它定义了记忆存储和检索的通用规则,不管是我们后面要学的ConversationBufferMemory,还是自定义记忆,都得遵守它的规范。
python
# 核心导入方式
from langchain.memory.chat_memory import BaseChatMemory它的核心价值在于"标准化":不管你是想存原始对话,还是存对话摘要,甚至想加密存储、过滤敏感信息,都能通过继承它来实现,不用从零造轮子。
二、BaseChatMemory的核心作用
作为基类,BaseChatMemory主要干三件大事,撑起所有聊天记忆的基础功能:
1. 标准化接口:统一"存"和"取"的方法
不管什么聊天记忆,都得实现两个核心方法,这是BaseChatMemory定好的规矩:
save_context():存上下文------把用户输入和模型输出保存到记忆里;load_memory_variables():取记忆------把保存的对话历史加载出来,供大模型使用。
有了统一接口,我们切换不同记忆模块时,代码不用大改,兼容性拉满!
2. 状态管理:维护对话历史
BaseChatMemory会通过内部属性,帮我们管好对话消息的增删改查,不用自己手动维护列表。不管是加一条用户消息,还是清空所有记忆,都有现成的方法可用。
3. 高扩展性:支持自定义逻辑
这是最实用的点!我们可以继承BaseChatMemory,重写它的方法,实现自己的需求:比如保存时过滤"密码"等敏感词,加载时只取最近3天的对话,甚至把记忆加密存储。
三、BaseChatMemory的关键属性和核心方法
要用好BaseChatMemory,先搞懂它的"核心装备"------属性和方法,用起来就像玩游戏用技能一样简单!
1. 关键属性:chat_memory
这是存储对话消息的"容器",类型是ChatMessageHistory,里面有个messages列表,所有对话消息都存在这里。
每条消息都是BaseMessage的子类,常见的有两种:
HumanMessage:用户发送的消息;AIMessage:模型回复的消息。
简单说,chat_memory就像一个"聊天笔记本",每一页就是一条HumanMessage或AIMessage。
2. 核心方法:3个常用技能
(1)save_context():保存对话上下文
作用:把用户输入和模型输出成对保存到chat_memory里。
用法有两种,效果完全一样:
python
# 方法1:直接调用save_context(推荐,简洁)
memory.save_context(
{"input": "你好"}, # 用户输入
{"output": "你好!有什么可以帮您?"} # 模型输出
)
# 方法2:手动添加消息到chat_memory
memory.chat_memory.add_user_message("你好") # 添加用户消息
memory.chat_memory.add_ai_message("你好!有什么可以帮您?") # 添加AI消息(2)load_memory_variables():加载记忆
作用:把保存的对话历史取出来,默认返回一个字典,key是"history",value是对话字符串。
示例:
python
# 加载记忆
variables = memory.load_memory_variables({})
# 打印对话历史
print(variables["history"])
# 输出结果:
# Human: 你好
# AI: 你好!有什么可以帮您?(3)clear():清空记忆
作用:一键清空chat_memory里的所有对话消息,相当于"格式化笔记本"。
示例:
python
# 清空所有记忆
memory.clear()
# 再加载就是空的了
print(memory.load_memory_variables({})) # 输出:{"history": ""}四、BaseChatMemory的常用子类:不用自己写,直接用!
BaseChatMemory是基类,不能直接用,LangChain已经帮我们实现了几个常用子类,覆盖大部分场景,直接拿来用就行~
| 子类名称 | 核心特点 | 适用场景 |
|---|---|---|
| ConversationBufferMemory | 存储完整原始对话历史 | 短对话、需要保留全部对话细节 |
| ConversationBufferWindowMemory | 只保留最近k轮对话(滑动窗口) | 长对话、避免token占用过多 |
| ConversationSummaryMemory | 存储对话摘要(用大模型总结历史) | 超长对话、需要压缩对话内容 |
五、子类实战:3个案例
案例1:ConversationBufferMemory------存储完整对话
适合短对话,需要保留每一句聊天内容的场景。
python
# 1. 导入需要的包
from langchain.memory import ConversationBufferMemory
# 2. 初始化记忆(return_messages=True:返回消息对象列表,False返回字符串)
memory = ConversationBufferMemory(
memory_key="chat_history", # 加载记忆时的key(默认就是"history")
return_messages=True # 这里设为True,方便看消息类型
)
# 3. 保存对话上下文
memory.save_context({"input": "你的名字是什么?"}, {"output": "我叫工藤助手"})
memory.save_context({"input": "我叫张三"}, {"output": "你好张三!很高兴认识你"})
# 4. 加载并查看记忆
chat_history = memory.load_memory_variables({})["chat_history"]
print("对话记忆:")
for msg in chat_history:
print(f"类型:{type(msg).__name__},内容:{msg.content}")
# 输出结果:
# 对话记忆:
# 类型:HumanMessage,内容:你的名字是什么?
# 类型:AIMessage,内容:我叫工藤助手
# 类型:HumanMessage,内容:我叫张三
# 类型:AIMessage,内容:你好张三!很高兴认识你
# 5. 清空记忆
memory.clear()
print("\n清空后记忆:", memory.load_memory_variables({})) # 输出:清空后记忆: {'chat_history': []}案例2:ConversationBufferWindowMemory------只记最近k轮对话
适合长对话,比如聊了100轮,只想让模型记住最后3轮,避免token不够用。
python
# 1. 导入需要的包
from langchain.memory import ConversationBufferWindowMemory
# 2. 初始化记忆:k=2表示只保留最近2轮对话(一轮用户+一轮AI为一轮)
memory = ConversationBufferWindowMemory(
k=2, # 窗口大小:最近2轮
memory_key="chat_history",
return_messages=False # 返回字符串格式,更直观
)
# 3. 保存3轮对话(会自动只留最后2轮)
# 第1轮
memory.save_context({"input": "今天天气怎么样?"}, {"output": "今天晴天,适合出游"})
# 第2轮
memory.save_context({"input": "适合去公园吗?"}, {"output": "适合,公园花开了"})
# 第3轮
memory.save_context({"input": "公园要门票吗?"}, {"output": "不需要,免费开放"})
# 4. 加载记忆:只保留最后2轮(第2、3轮)
chat_history = memory.load_memory_variables({})["chat_history"]
print("窗口内对话记忆:")
print(chat_history)
# 输出结果:
# 窗口内对话记忆:
# Human: 适合去公园吗?
# AI: 适合,公园花开了
# Human: 公园要门票吗?
# AI: 不需要,免费开放案例3:ConversationSummaryMemory------用摘要压缩对话
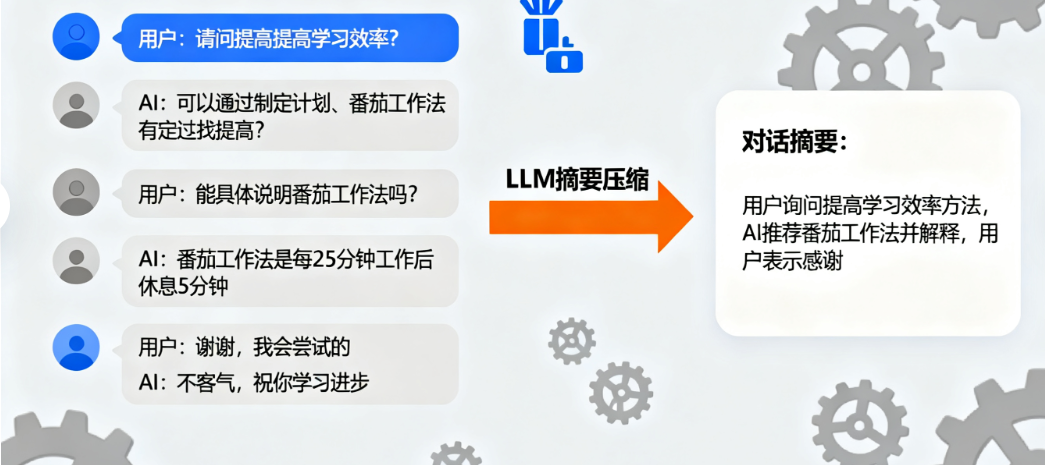
适合超长对话,比如聊了100轮,用大模型把历史对话总结成一段话,既省token又能保留关键信息。
python
# 1. 导入需要的包
from langchain.memory import ConversationSummaryMemory
from langchain.chat_models import ChatOpenAI # 需要大模型来生成摘要
# 2. 初始化大模型(也可以用开源模型,如通义千问、智谱清言)
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo")
# 3. 初始化记忆:传入大模型用于生成摘要
memory = ConversationSummaryMemory(
llm=llm,
memory_key="chat_history",
return_messages=False
)
# 4. 保存多轮对话
memory.save_context({"input": "我叫张三,想学习微积分"}, {"output": "好的,我会帮你规划学习路径"})
memory.save_context({"input": "微积分先学什么?"}, {"output": "先学极限,这是微积分的基础"})
memory.save_context({"input": "极限怎么学容易?"}, {"output": "多练例题,理解无穷小和无穷大的概念"})
# 5. 加载记忆:返回的是对话摘要,不是原始对话
summary = memory.load_memory_variables({})["chat_history"]
print("对话摘要:")
print(summary)
# 输出结果(大模型生成,简洁保留关键信息):
# 用户张三表示想学习微积分,助手表示会帮他规划学习路径。用户询问微积分先学什么,助手建议先学极限,因为极限是微积分的基础。用户又问极限怎么学容易,助手建议多练例题,理解无穷小和无穷大的概念。六、怎么选BaseChatMemory子类?一张表搞定!
不知道用哪个子类?看场景选就行,一目了然:
| 场景需求 | 推荐子类 | 关键参数 |
|---|---|---|
| 短对话、需要完整保留所有对话细节 | ConversationBufferMemory | return_messages |
| 长对话、只想记最近几轮 | ConversationBufferWindowMemory | k(窗口大小) |
| 超长对话、想压缩对话省token | ConversationSummaryMemory | llm(摘要用的大模型) |
| 要自定义逻辑(过滤敏感词、加密) | 继承BaseChatMemory重写方法 | - |
总结
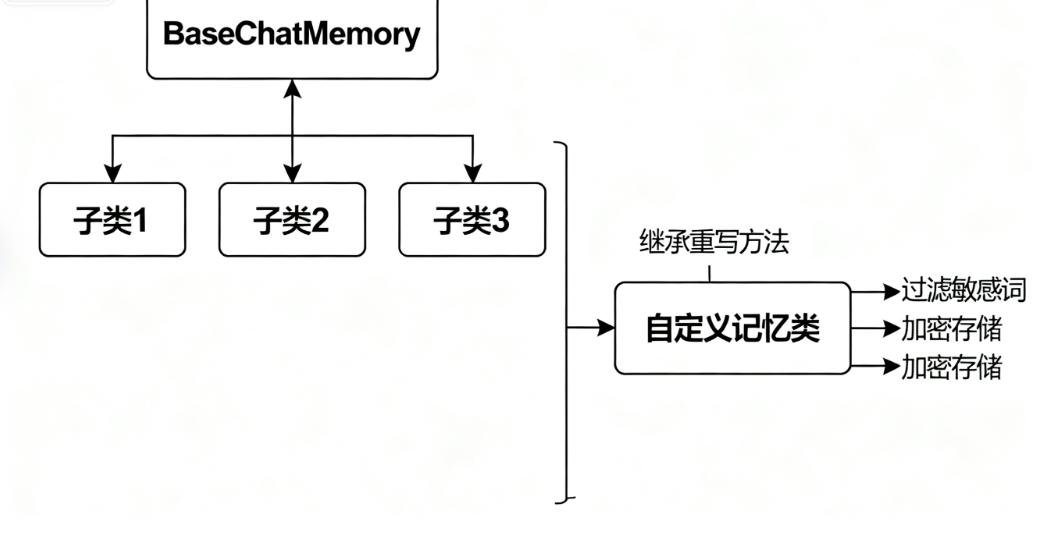
BaseChatMemory作为LangChain聊天记忆的基类,核心是定了"存(save_context)、取(load_memory_variables)、清(clear)"的标准接口,让各种记忆模块有章可循。它的子类不用我们自己写,直接根据场景选:短对话用ConversationBufferMemory,长对话用窗口记忆,超长对话用摘要记忆。
有疑问欢迎在评论区交流,咱们下期再见!👋