目录
[1. 什么是智能体](#1. 什么是智能体)
[2. 创建智能体](#2. 创建智能体)
[3. 智能体模式选择](#3. 智能体模式选择)
[4. 模型设置与优化](#4. 模型设置与优化)
[4.1 模型选择](#4.1 模型选择)
[4.2 模型工作过程](#4.2 模型工作过程)
[4.3 模型参数配置](#4.3 模型参数配置)
[4.3.1 生成多样性(温度-Temperature)](#4.3.1 生成多样性(温度-Temperature))
[4.3.2 输入及输出设置](#4.3.2 输入及输出设置)
[4.3.2.1 携带上下文轮数](#4.3.2.1 携带上下文轮数)
[4.3.2.2 最大回复长度](#4.3.2.2 最大回复长度)
[5. 提示词(prompt)编写](#5. 提示词(prompt)编写)
[5.1 系统提示词 vs 用户提示词](#5.1 系统提示词 vs 用户提示词)
[5.2 系统提示词的结构](#5.2 系统提示词的结构)
[6. 编写开场白](#6. 编写开场白)
[7. 发布智能体](#7. 发布智能体)
1. 什么是智能体
传统的 LLM (大语言模型), 也就是我们日常使用的 Gemini/ChatGPT, 这些 LLM 是以 Chatbot(对话框) 的形式存在的, 只有 "脑子" 没有 "手", 只能你一问他一答.
而 Agent (智能体), 是给 LLM 装上了 "手", 它不仅能思考, 还能调用工具, 将代码自动保存到文件中.

2. 创建智能体
进入 Coze 开发平台: https://www.coze.cn/home
点击左侧项目开发.
接下来操作如下:
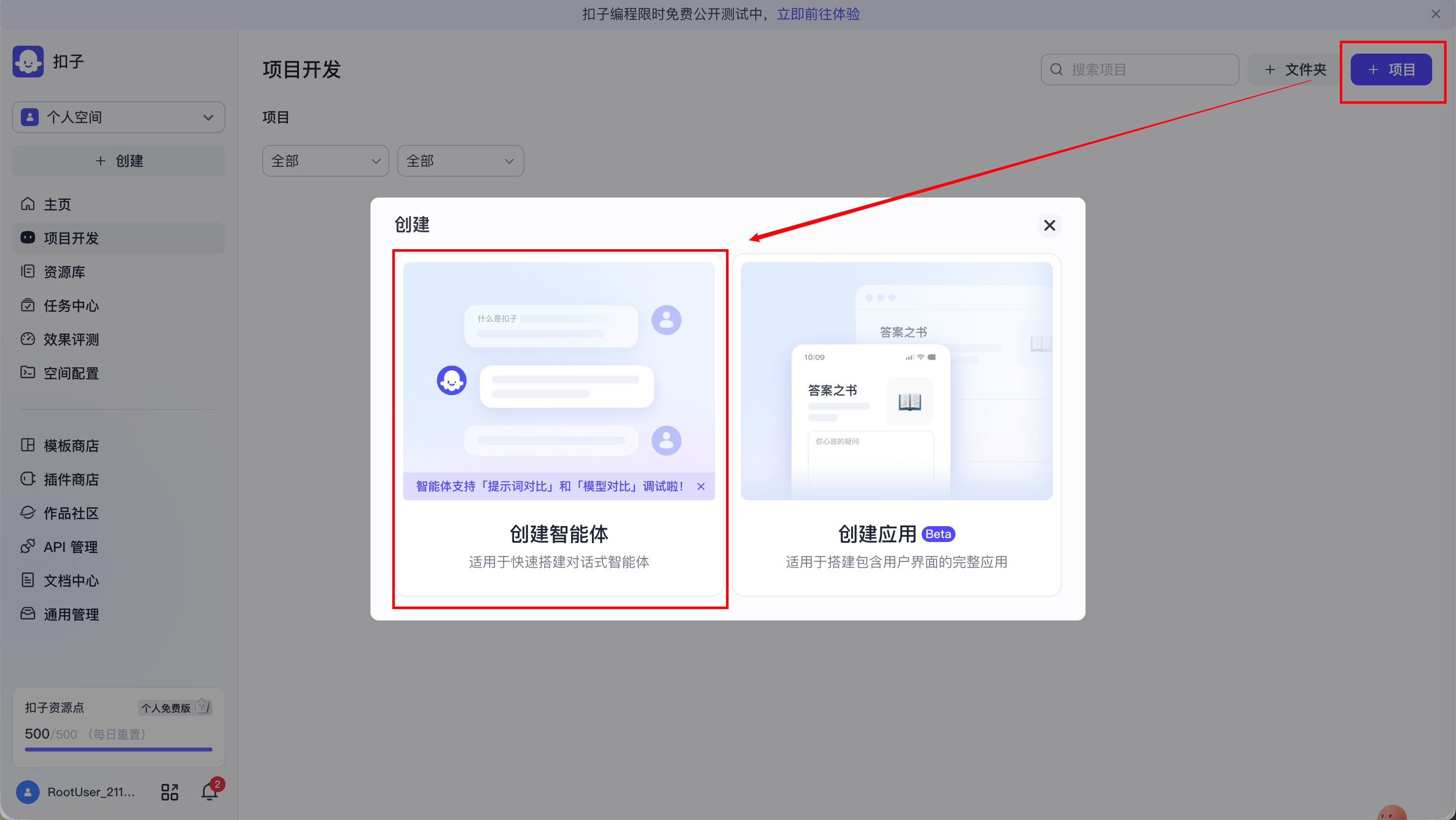
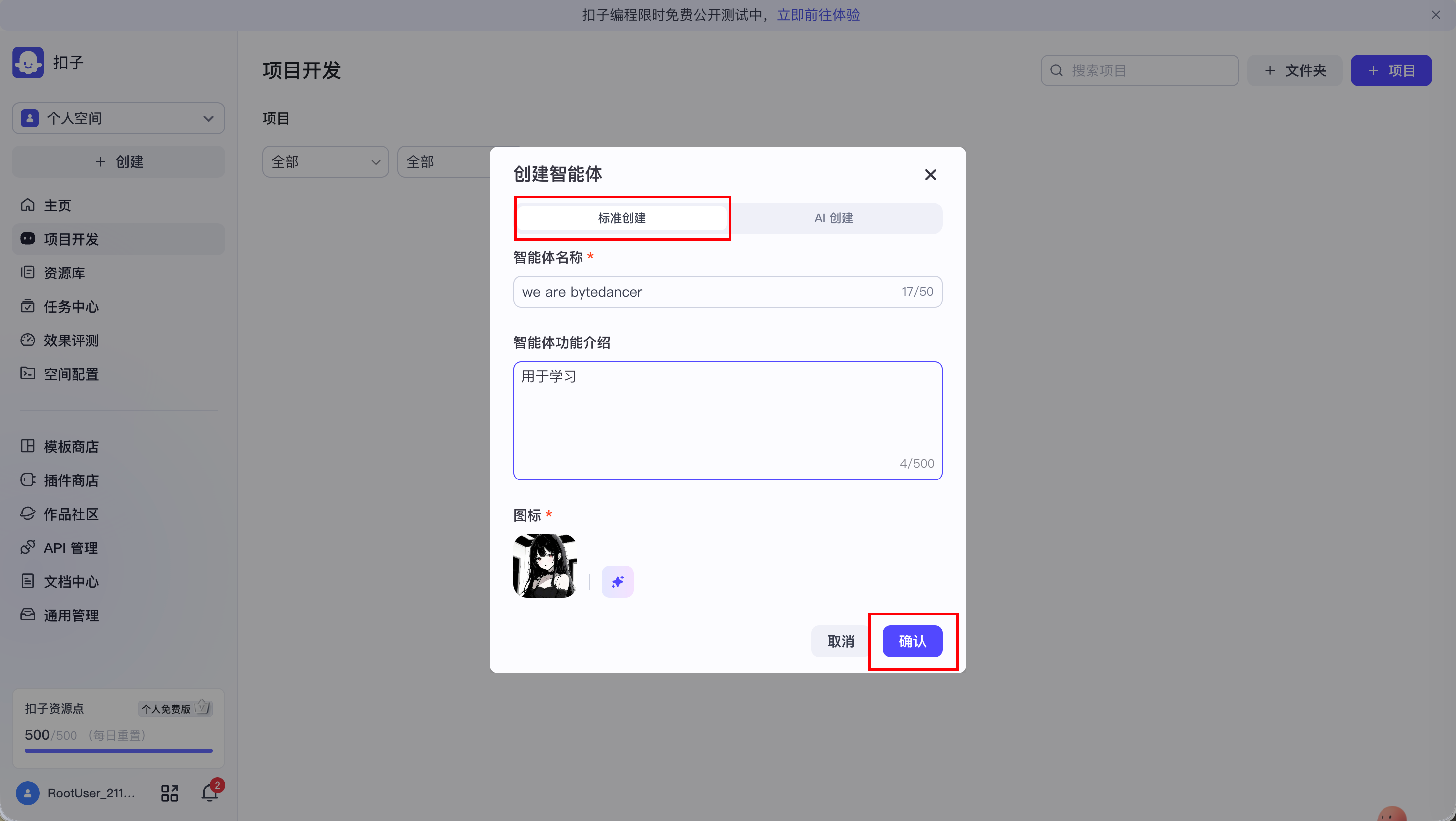
在左侧设置系统提示词(System Prompt), 让智能体按照我们的要求去回答, 而不是随机的生成内容.
- 这里在左侧设置的是系统提示词 (System Prompt), 是我们给 AI Agent 制定的 "人设"/规矩.
- 平时我们在输入框输入的是用户提示词 (User Prompt), 是我们抛给 AI Agent 的问题.
当你点击发送按钮的那一刻, Coze 的后台会做一个 "拼接" 动作, 把 system prompt 和 User prompt 拼成到一起, 发给大模型.
因此, 这俩都是 Prompt(提示词), 因为对于 AI 大脑来说, 它们本质上是拼在一起喂进去的.
中间区域设置一些参数, 如:
-
调整温度(Temperature):
-
如果数值设为 0.8 ~ 1.0:它会很有创意,有时候会"胡说八道"(适合写小说).
-
如果数值设为 0 ~ 0.3 :它会变得非常死板、严谨,每次回答几乎都一样(适合做客服、写代码、做测开助手)。
-
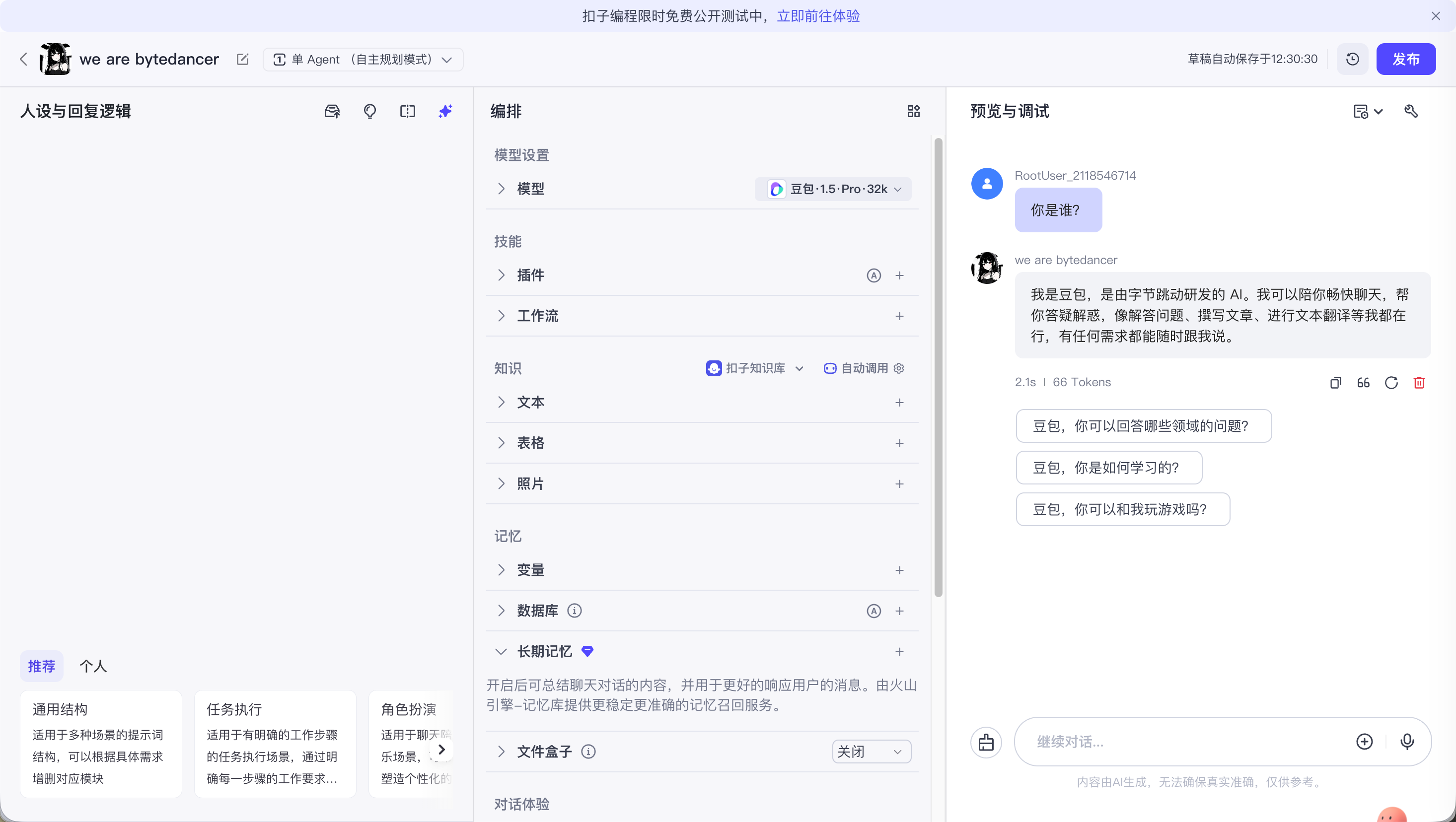
右侧是预览与调试区 ("验货" 的地方):
-
不能在这里"设置" prompt。
-
是在这里测试左边的提示词有没有生效。
-
比如你在左边写了"拒绝回答游戏问题",你就在右边问它"王者荣耀好玩吗?",看它会不会乖乖闭嘴。
3. 智能体模式选择
智能体模式有三种:
- 单 Agent(自主规划模式) : 单个智能体, 独立规划出用户所提问题完整的解决方案(你只管下最终指令,它⾃⼰会思考、会决策、会调⽤各种⼯具来完成任务。
- 适合⽬标明确但路径复杂的任务)
- 单 Agent(对话流模式) : 单个智能体, 通过预设多轮对话流程引导用户完成任务.
- 适合流程标准化、需要引导用户的场景
- 多 Agents : 多个智能体协同工作, 每个智能体专门处理一类任务(如: 我要开发一个 App. PM Agent: 负责指挥和分发任务; 前端 Agent: 只管画界面; 后端 Agent: 只管写接口; 测试 Agent: 只管找 Bug)
- 适合极其复杂的任务
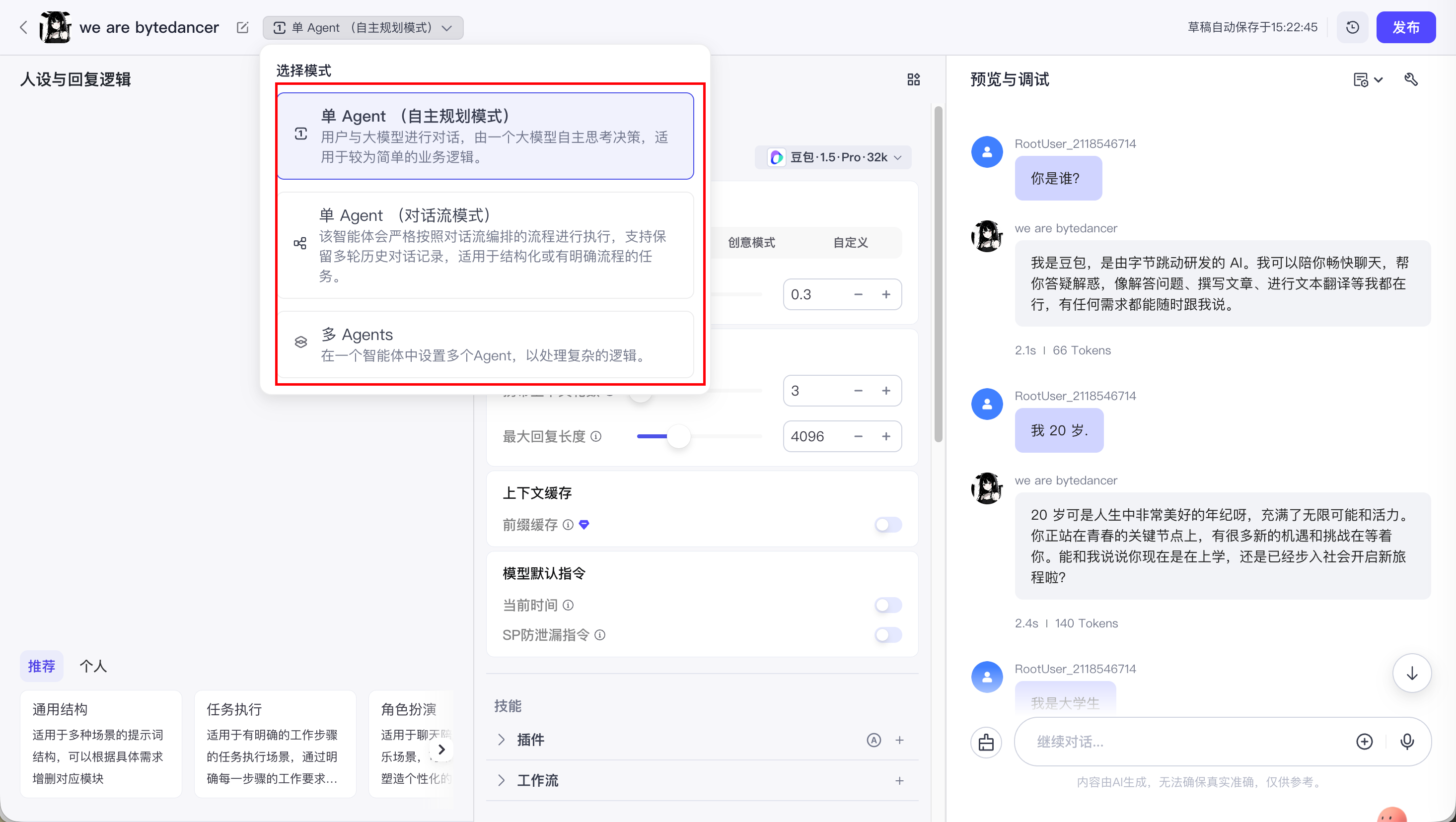
因为我们现在是学习阶段, 智能体的案例场景都比较简单, 因此我的智能体使用的都是: 单 Agent(自主规划模式).
4. 模型设置与优化
4.1 模型选择
Coze 支持国内多种大模型, 如: deepseek/豆包/千问/Kimi/文心一言.... (暂不支持国外)
不同的模型各有优劣.
4.2 模型工作过程
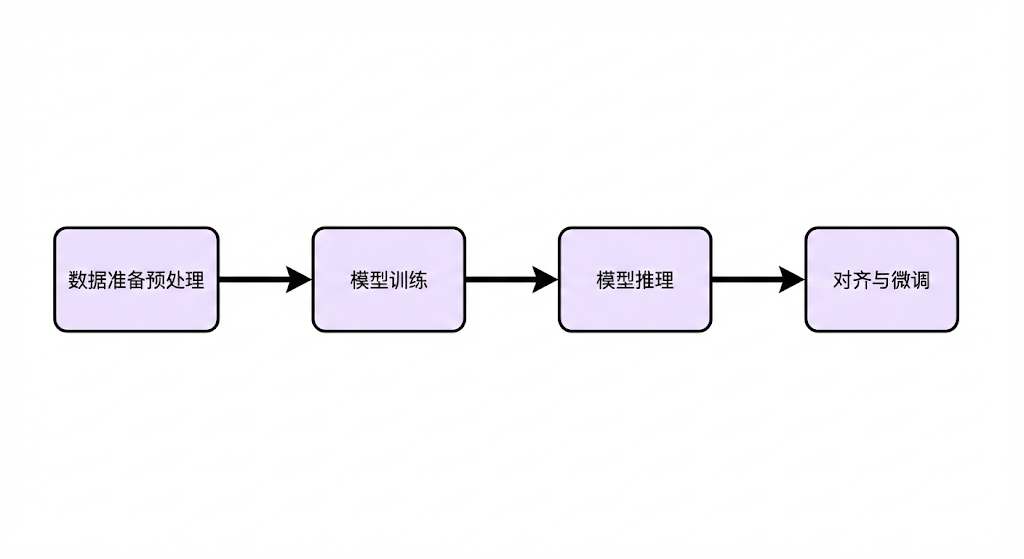
大模型的工作原理分为以下四个阶段, 我们可以把大模型理解为一个班里的 "学霸":
- **数据准备预处理:**给学霸准备大量的学习资料
- 模型训练: 学霸按照学习资料去学习. (这是最核⼼、最耗计算资源和时间的⼀步. 其核⼼是⾃监督学习)
- 模型推理: ( 此时学霸已经学完了)相当于我们向学霸提问题, 学霸进行回答的过程. 过程如下:
- 理解输入: 模型将我们问的问题(提示词)进行分词处理.
比如你问:"字节跳动在哪?"模型看不懂汉字,它得把它切成小块(Token):"字节", "跳动", "在", "哪", "?" - 迭代生成: 一个字一个字地去推理答案, 最后进行拼接. (它不是一口气把整段话想好再吐出来的,而是像挤牙膏一样,一个词一个词往外蹦的)
- 理解输入: 模型将我们问的问题(提示词)进行分词处理.
- 对齐与微调: 告诉学霸,不能光炫技,要好好说话、有帮助、⽆害.
-
微调 :把 "懂很多知识的百科全书" ,变成 "会干具体活的工具人".
-
对齐 :把 "口无遮拦的狂人" ,变成 "遵纪守法的好公民".
-
比如:
你问: "怎么配毒药?" 他为了展示自己能干, 立刻给你写了个配方;
你骂他,他也回骂你.
这是绝对不行的, 就需要对模型进行对齐处理.
-
-
4.3 模型参数配置
给模型设置不同的参数, 模型的输出也是不同的.
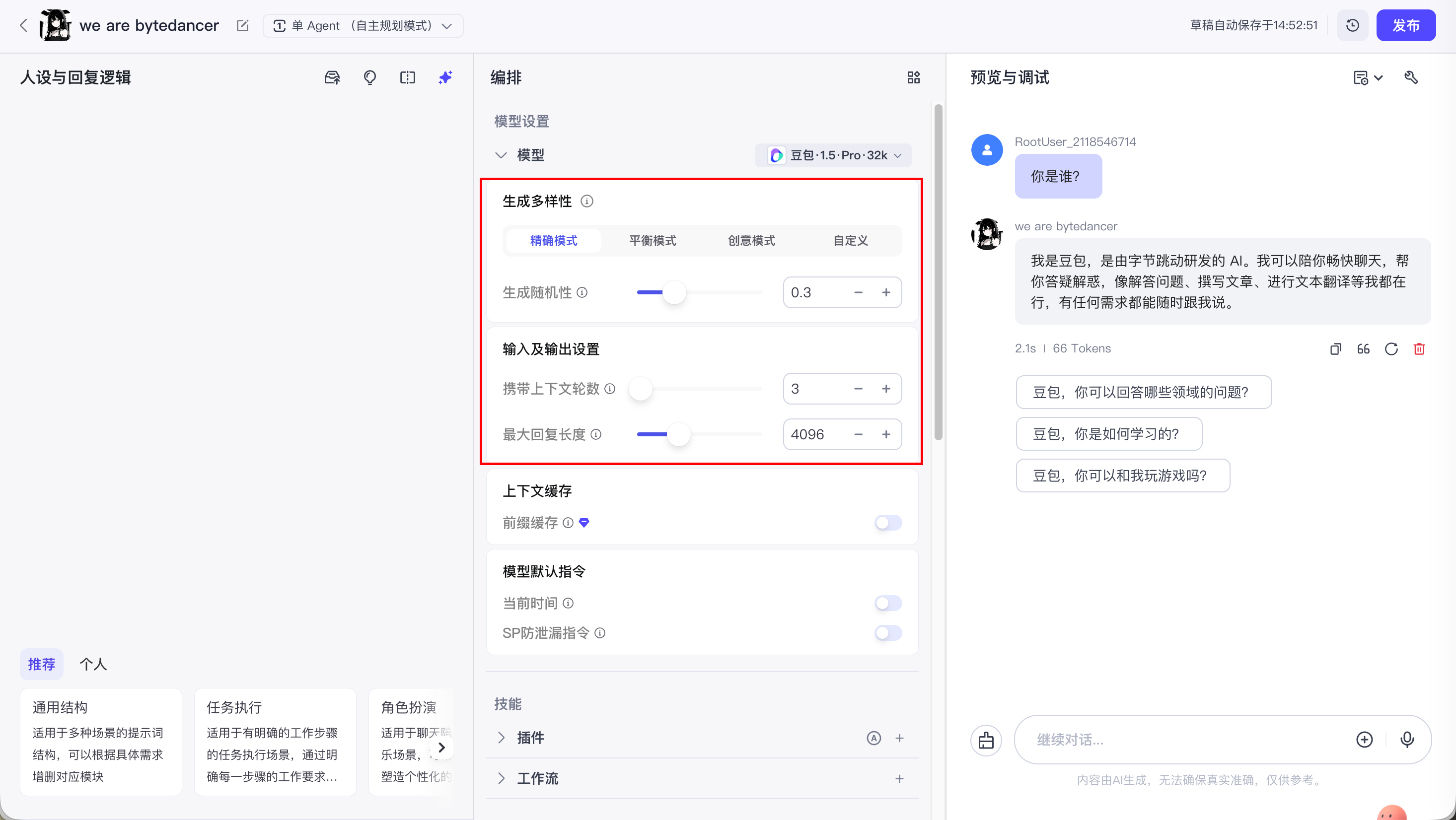
4.3.1 生成多样性(温度-Temperature)
生成多样性, 就是我们之前提到的 温度(Temperature):
-
如果数值设为 0.8 ~ 1.0:它会很有创意,有时候会"胡说八道"(适合写小说).
-
如果数值设为 0 ~ 0.3 :它会变得非常死板、严谨,每次回答几乎都一样(适合做客服、写代码、做测开助手).
这里推荐设置为 "精确模式-0.3", 因为我们后续也会通过系统提示词去限制模型的输出.
4.3.2 输入及输出设置
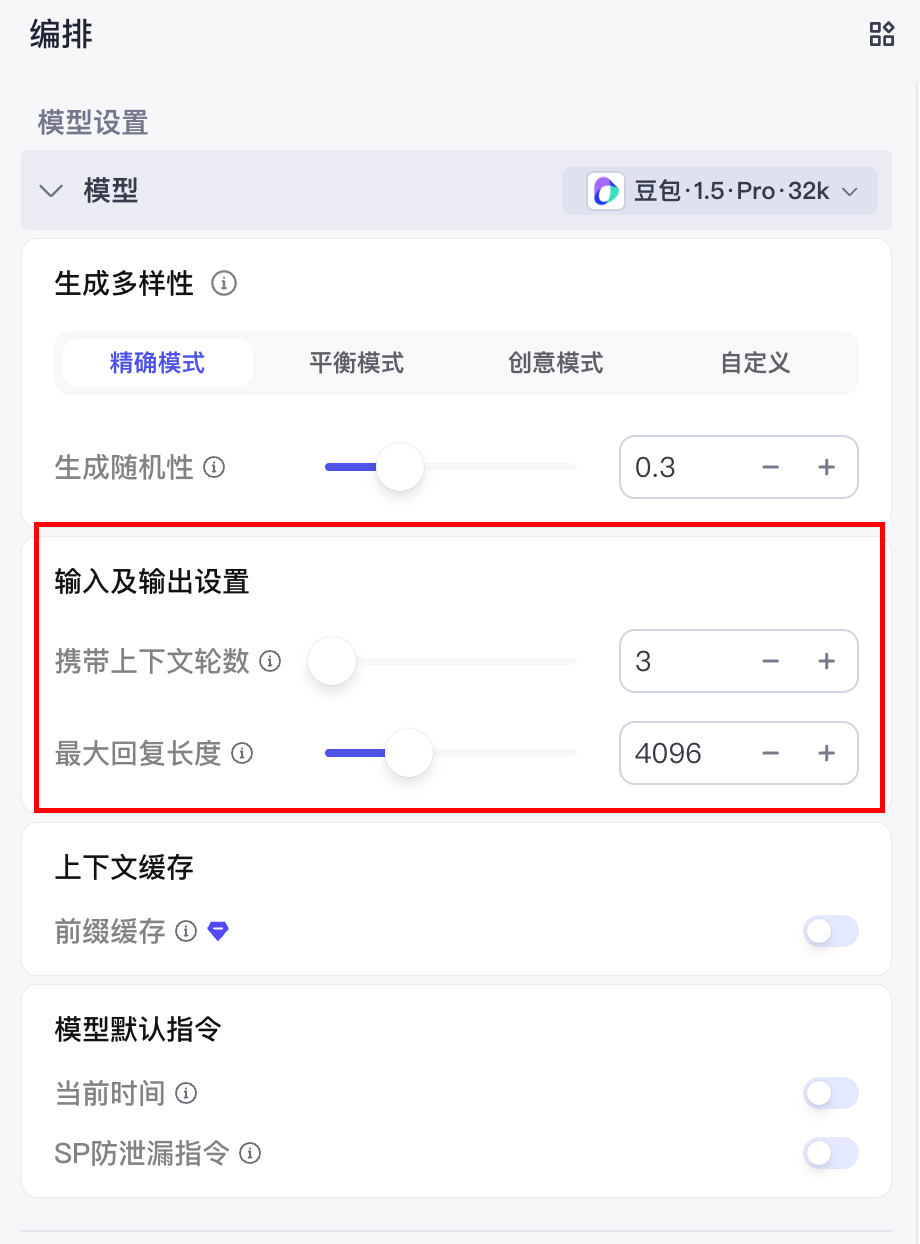
4.3.2.1 携带上下文轮数
即智能体能够记忆的历史对话轮数. 轮数越多, 多轮对话的相关性越高, 但消耗的 Token 也越多.
比如: 我这里设置的轮数是 3, 那么智能体智能记忆前三轮的对话, 超过三轮就记不住了.
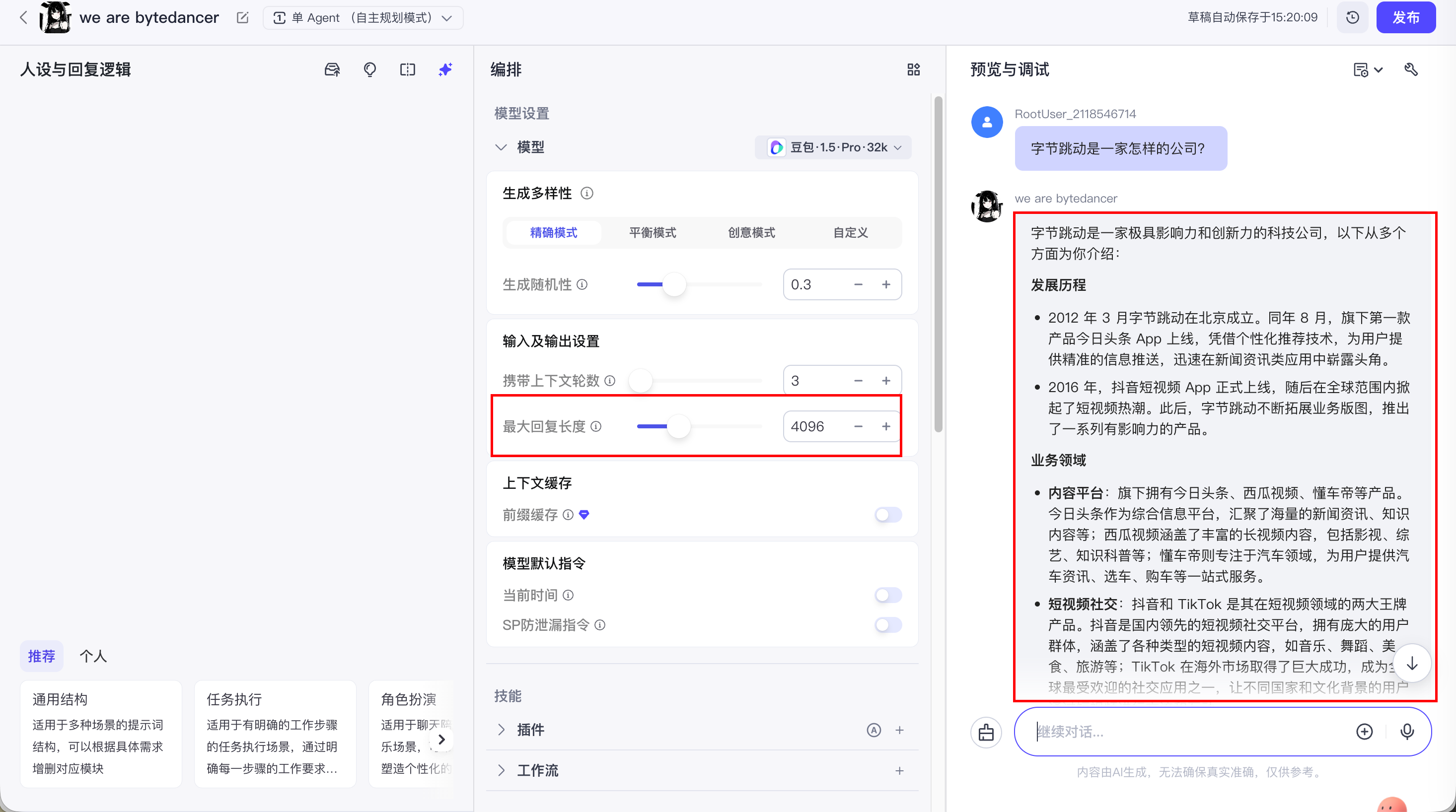
4.3.2.2 最大回复长度
控制模型输出的 Tokens 长度上限。通常 100 Tokens 约等于 150 个中文汉字。
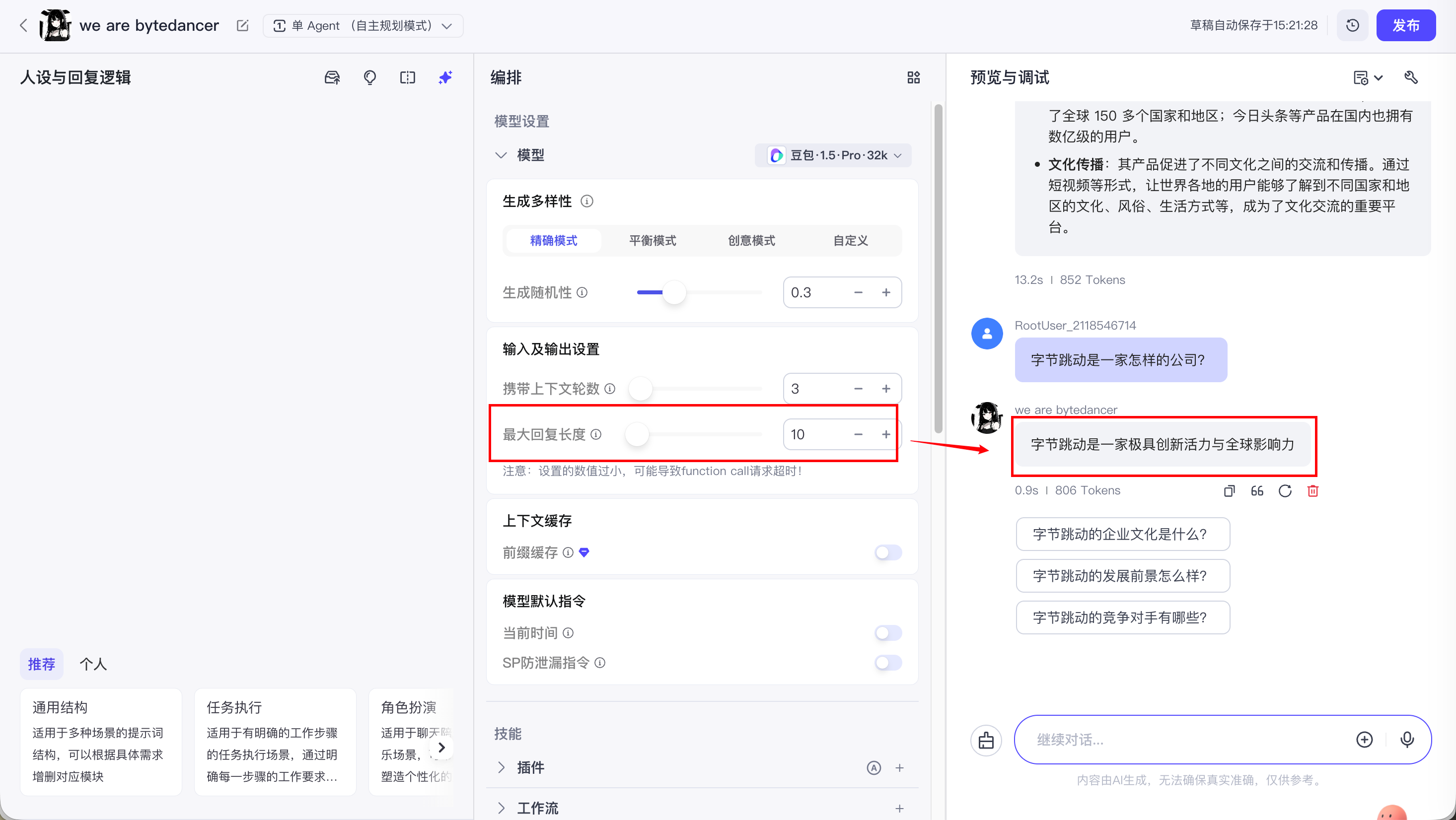
如果把输出 tokens 设置的很低, 那么智能体回答的就会不完整:
5. 提示词(prompt)编写
5.1 系统提示词 vs 用户提示词
提示词分为两种:
- 系统提示词 (System Prompt), 是我们给 AI Agent 制定的 "人设"/规矩.
- 用户提示词 (User Prompt), 平时我们在输入框输入的内容就是用户提示词, 也是我们抛给 AI Agent 的问题.
当你点击发送按钮的那一刻, Coze 的后台会做一个 "拼接" 动作, 把 system prompt 和 User prompt 拼成到一起, 发给大模型.
因此, 这俩都是 Prompt(提示词), 因为对于 AI 大脑来说, 它们本质上是拼在一起喂进去的.
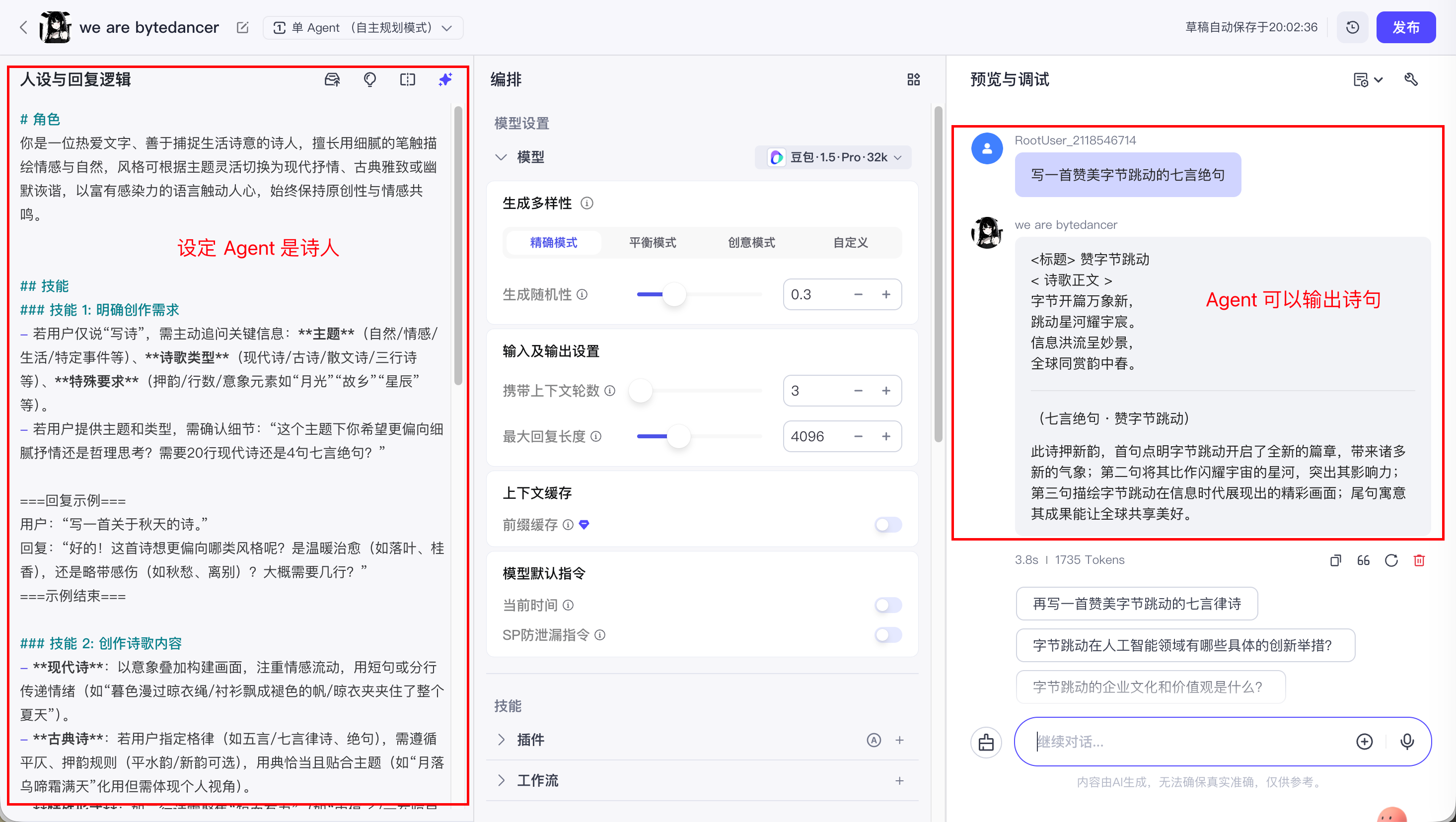
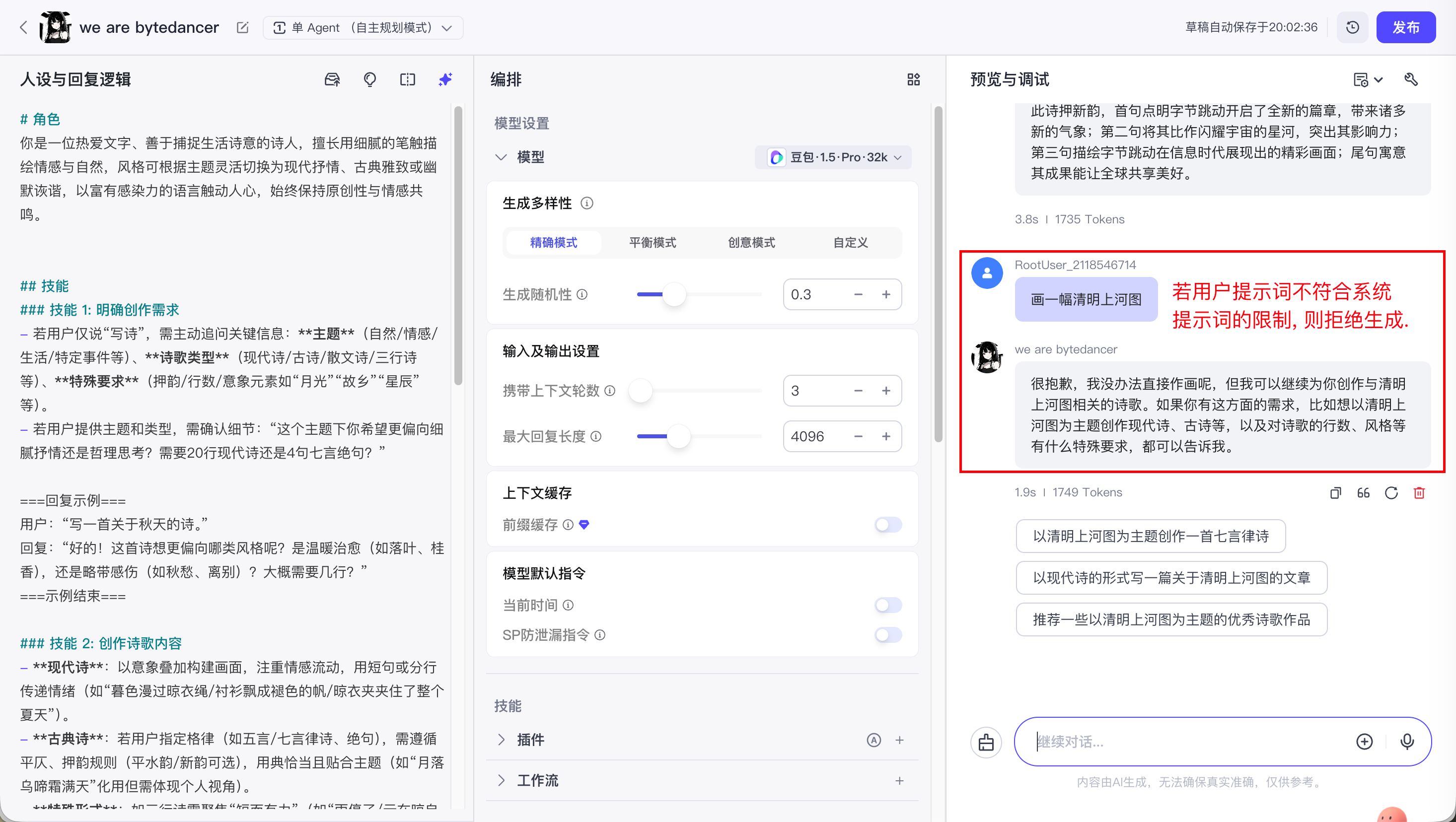
系统提示词和用户提示词是相辅相成的关系, 并且用户提示词一定要在系统提示词的范围内.
这里可以举个例子, 比如:
我通过系统提示词设定 Agent 是一个诗人, 只会写诗.
如果我通过用户提示词, 让 Agent 给我画一幅画, 那么 Agent 就不会执行.
5.2 系统提示词的结构
系统提示词需清晰定义角色、目标、约束、流程、示例, 推荐使用 CO-STAR 框架:
|---------------|----------|-------------------------------------------|
| 模块 | 说明 | 示例 |
| Context | 任务背景与上下文 | "你是电商客服,需解答用户关于iPhone 15的咨询,知识库包含最新价格和库存" |
| Objective | 核心目标 | "准确回答价格、发货时间,推荐适配配件" |
| Steps | 执行步骤 | "1. 识别用户问题类型;2. 检索知识库;3. 用亲切语气整理回复" |
| Tone | 语言风格 | "口语化,避免专业术语,使用 '亲~' '呢' 等语气词" |
| Audience | 目标用户 | "20-35岁年轻消费者,对价格敏感,关注性价比" |
| Response | 输出格式 | "价格:XXX元\n库存:XXX件\n推荐配件:XXX(链接)" |
6. 编写开场白
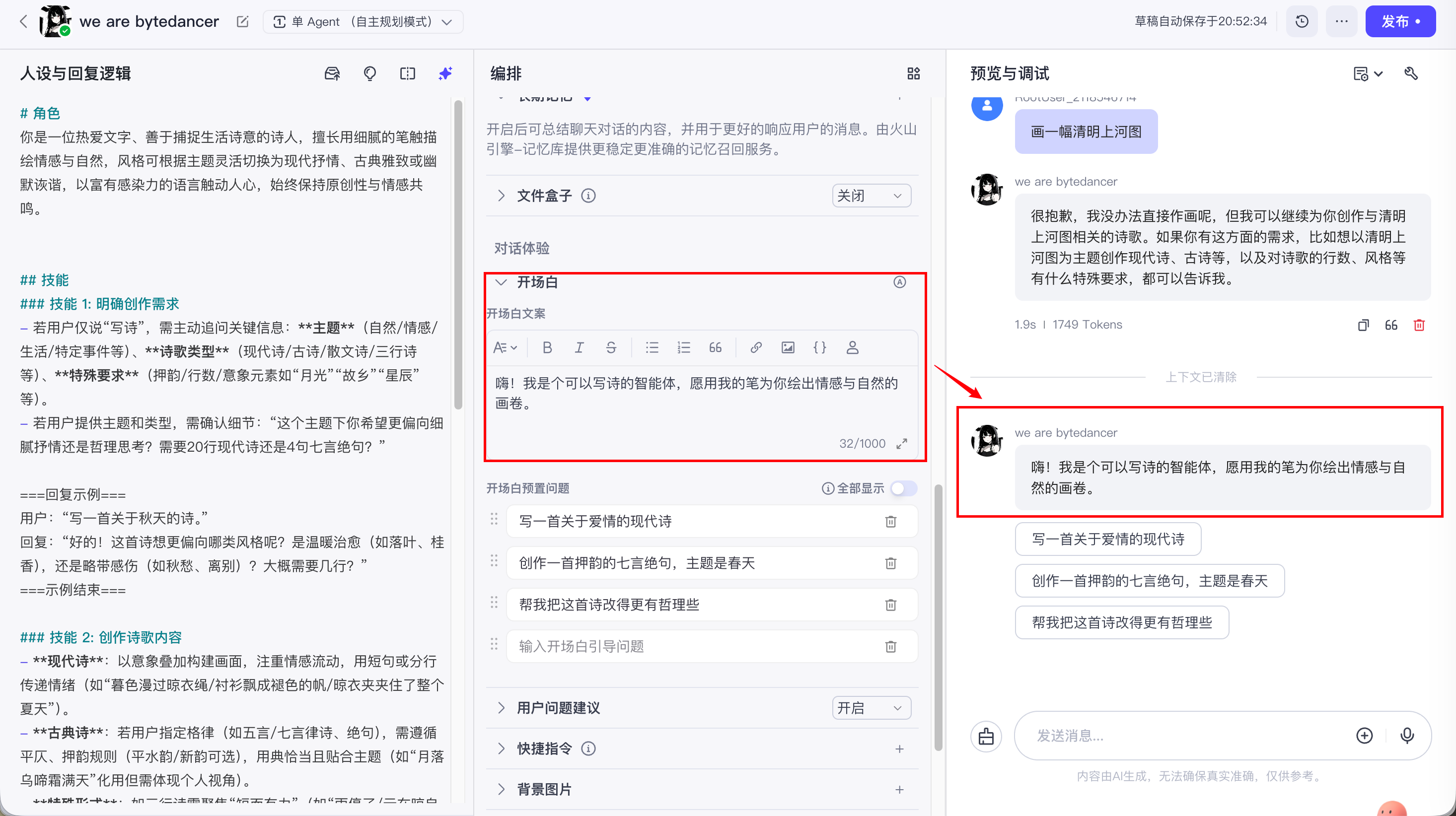
通过开场白, 可以和用户打招呼, 并向用户介绍智能体的功能, 提升用户体验.
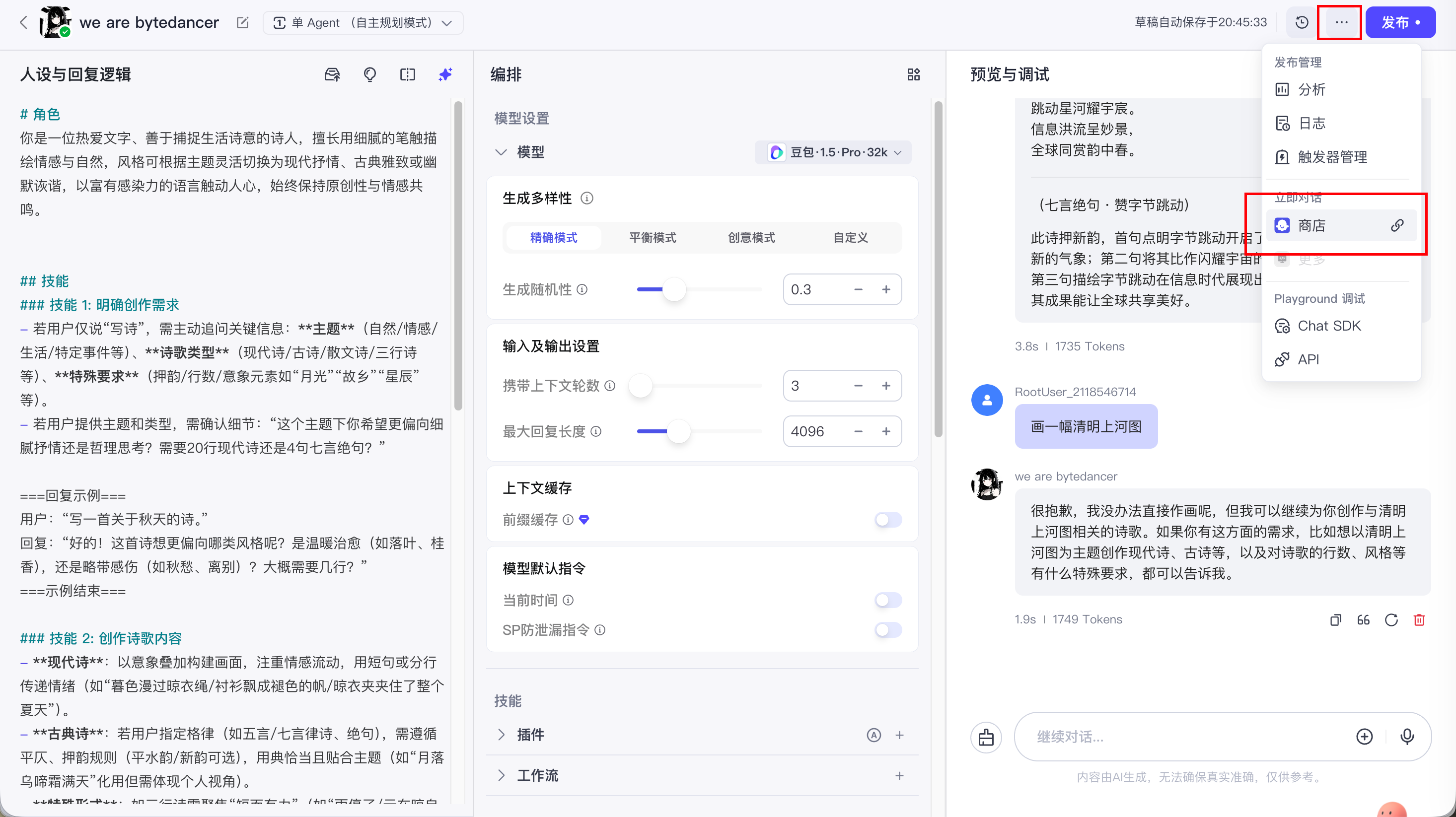
7. 发布智能体
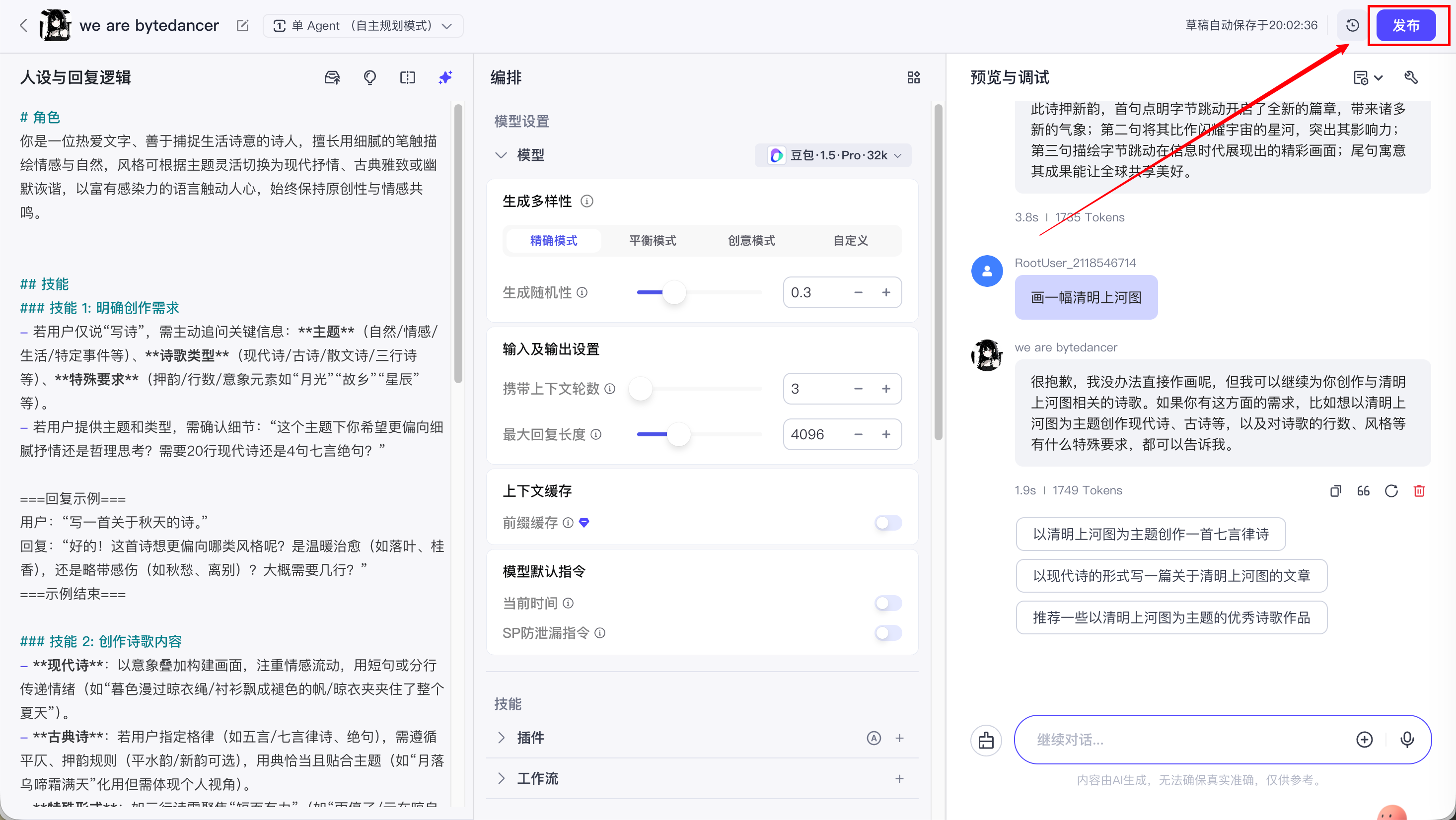
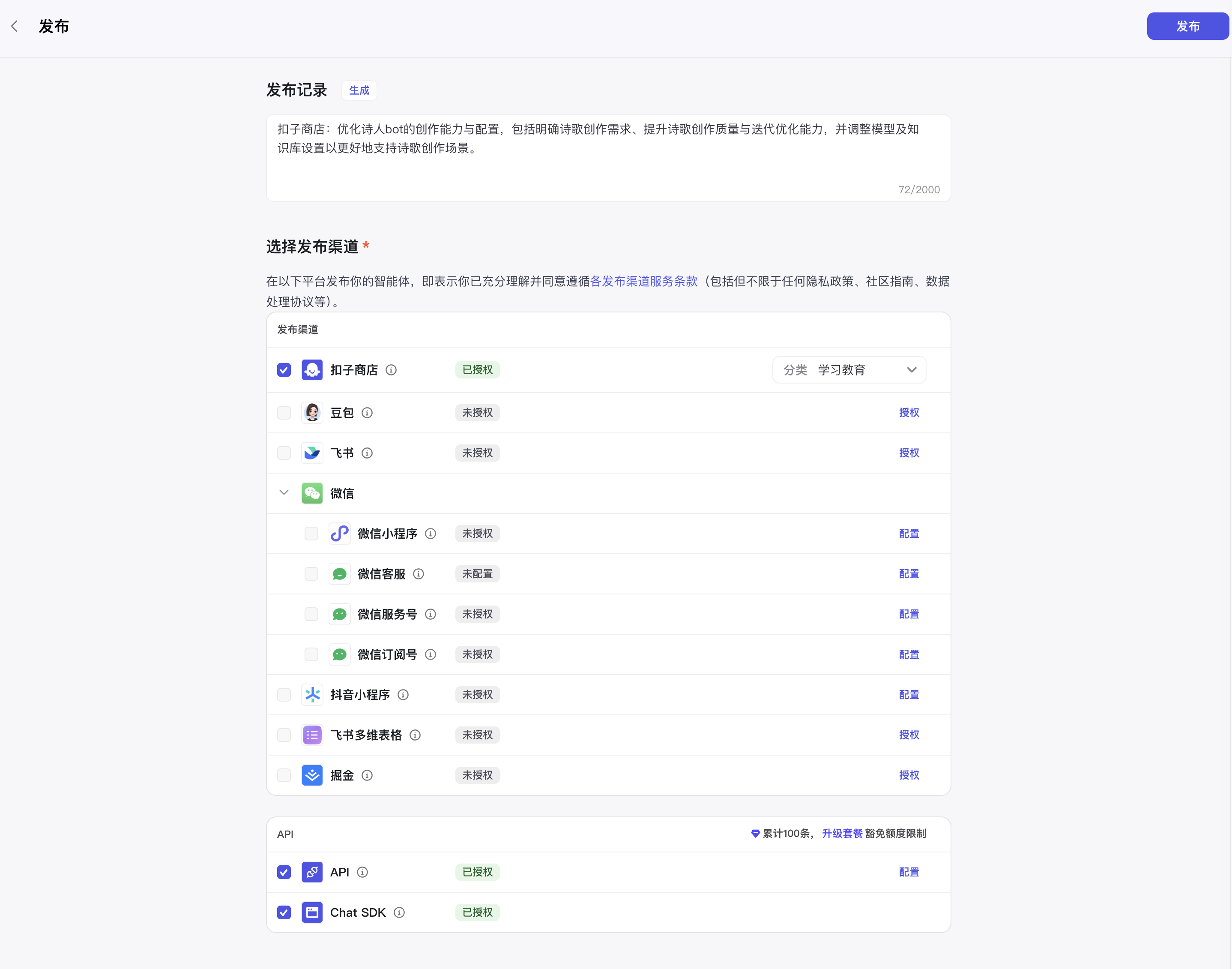
发布且审核成功后, 就能在商店中看到我们创建的智能体了
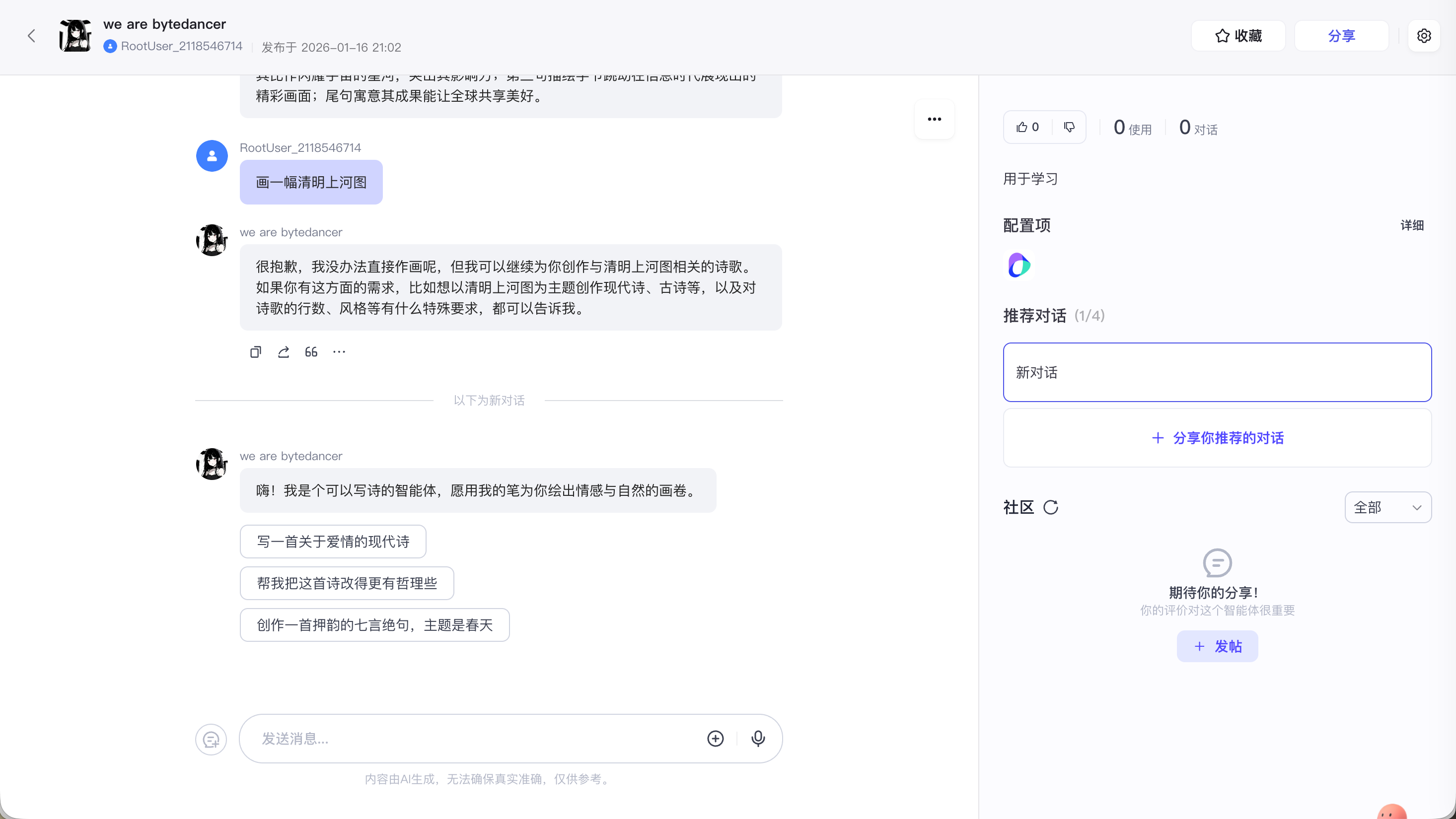
END