目录
一.RPC介绍
当我们在一个进程里面需要调用另一个进程中实现的函数时,应当如何实现?
这种场景下,RPC 技术提供了一种成熟的解决方案。
RPC(远程过程调用)是一种计算机通信协议,允许当前程序调用位于另一个程序(通常是在网络中的远程机器上)的函数,而开发者无需显式编写处理网络通信的代码。
它的核心目标是让远程调用在形式上尽可能接近本地调用,从而简化分布式系统的开发。
也就是说,无论函数是在本地还是远程,对程序员而言,调用方式看起来基本一致。这极大地降低了网络编程的复杂度,使开发者能够更专注于业务逻辑,而不必深入处理底层网络细节。RPC 框架通常会隐藏数据传输、序列化、网络通信和错误处理等实现,使得跨进程或跨网络的服务调用像调用本地函数一样简单直观。
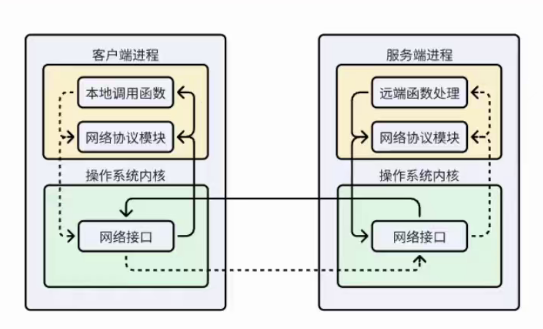
为什么需要RPC?------ 从本地调用到远程调用
-
本地函数调用:
-
场景 :你在自己的程序里写了一个函数
int add(int a, int b)。 -
调用 :
result = add(10, 20); -
过程 :编译器/解释器知道函数地址,CPU直接跳转到该地址执行代码,参数和返回值通过栈或寄存器传递。一切发生在同一个进程的同一内存空间内,速度极快,完全可靠。
-
-
远程调用面临的根本挑战:
-
目标函数在另一个进程,甚至另一台机器的另一个进程里。
-
两个进程的内存空间完全隔离,无法直接传递参数或获取结果。
-
两者之间只有网络 相连,而网络是不可靠、有延迟、会丢包的。
-
RPC就是为了解决"如何跨越进程和网络边界,安全可靠地发起调用并获得结果"这一系列问题而产生的方案。
RPC通信的流程
现在,我们来详细解析流程中的每个环节:
第一步:客户端发起调用(本地感觉)
-
你写的代码 :
result = userService.getUserInfo(123); -
你以为的 :直接调用了
userService的一个方法。 -
实际发生的 :你调用的
userService并不是真正的服务实现,而是一个由RPC框架在本地生成的一个"代理"(Proxy)或"存根"(Stub)对象。
第二步:客户端存根工作(序列化与编码)
-
代理对象收到调用后,它知道自己代表的是一个远程服务。它的工作是:
-
方法标识 :确定你调用的方法是哪个(例如,
getUserInfo)。 -
参数序列化 :将参数(
123)从内存中的对象格式,转换为一个可以在网络中传输的字节流 。这个过程叫序列化(或编码、Marshalling)。常见的序列化协议有JSON、XML、Protobuf、Thrift、Hessian等。 -
组装消息 :将方法标识、序列化后的参数等,按照RPC协议约定的格式,打包成一个完整的请求消息。这个消息里还通常包含请求ID、协议版本等信息。
-
第三步:网络传输
- 客户端存根通过网络模块(如Socket)将打包好的请求消息字节流,通过底层网络协议(最常用的是TCP ,因为需要可靠连接)发送给事先配置好的服务端地址(IP:Port)。
第四步:服务端接收与处理
-
服务端网络模块监听特定端口,收到请求字节流。
-
服务端存根(Skeleton)做与客户端存根相反的工作:
-
解码消息:从字节流中按照协议解析出方法名、参数等信息。
-
参数反序列化 :将参数部分的字节流,转换回服务端内存中可识别的对象格式。这个过程叫反序列化(或解码、Unmarshalling)。
-
路由与调用 :根据方法名,找到本地真正的服务实现类 ,并调用其对应的方法,传入反序列化得到的参数。
-
获取本地结果:服务实现方法执行本地业务逻辑(如查询数据库),返回结果。
-
第五步:服务端返回响应
-
服务端存根将本地执行的结果 (或异常)进行序列化 ,并按照响应格式打包成响应消息。
-
通过网络模块将响应消息发送回客户端。
第六步:客户端处理响应
-
客户端的网络模块收到响应字节流。
-
客户端存根对其进行解码 和反序列化,得到最终的结果对象(或异常)。
-
客户端存根将这个结果作为本地代理方法调用的返回值,返回给你写的业务代码。
至此,对你而言,一次远程调用就像本地调用一样完成了。所有网络通信的复杂性都被RPC框架隐藏了。
RPC通信框架
一个完整的RPC通信框架通常包含以下核心模块:
-
序列化协议:将数据结构或对象转换为可传输的格式
-
通信协议:约定数据传输的格式与规则
-
连接复用:高效管理网络连接,减少建立连接的开销
-
服务注册:将服务提供者的信息注册到中心节点,
-
服务发现:消费者动态查找可用服务地址
-
服务订阅和通知:订阅服务变更并及时接收通知
-
负载均衡:合理分配请求至多个服务实例
-
服务监控:跟踪服务调用状态与性能指标
-
同步调用:发起调用后阻塞等待结果返回
-
异步调用:调用后立即返回,通过回调或Future获取结果
本项目基于C++ 、JsonCpp (序列化)与muduo网络库(高性能网络层),实现了一个轻量且易用的RPC通信框架。即使是不具备深厚网络编程经验的开发者,也能凭借简洁的API快速上手。
框架支持同步调用 、异步回调调用 、异步Future调用 等多种调用方式,并集成了服务注册与发现 、服务上线/下线动态感知 以及发布订阅机制等分布式系统常用功能,致力于在保持简洁性的同时,覆盖常见RPC场景所需的核心能力。
二.技术方案选型
目前,实现 RPC 框架主要有两种常见方案:
1. 基于公共接口与 IDL(接口描述语言)的方案
-
首先通过 IDL(如 Protobuf、Thrift 等)定义服务与方法
-
使用代码生成工具根据 IDL 自动生成对应语言(如 C++、Java)的客户端和服务端基础代码
-
客户端和服务器程序通过继承或实现这些生成的公共接口来完成远程调用
-
例如,Protobuf 不仅可以定义数据结构,也可结合 gRPC 生成完整的 RPC 代码框架
-
缺点:自动生成的代码较多,对初学者理解底层通信细节不够直观;若使用 JSON 等自定义 IDL,还需自行开发代码生成器,实现门槛较高
2. 基于通用调用接口的方案
-
实现一个统一的远程调用入口(例如
call方法) -
调用时通过传入函数名、参数等信息来动态指定要执行的远程方法
-
该方案更贴近直接操作,易于理解和扩展
综合比较,为降低实现复杂度并便于理解框架运行机制,本项目选择第二种方案进行实现。我们将设计一个简洁明了的调用接口,让用户通过方法名和参数即可完成 RPC 调用,从而更直观地体现 RPC 的工作原理。
2. 参数与返回值的映射:如何将网络数据对应到RPC接口?
为将网络传输的参数和返回值正确映射到具体的RPC接口,常见技术方案包括:
-
使用 Protobuf 反射机制:利用 Protobuf 提供的运行时类型信息动态解析和构建消息。
-
使用 C++ 模板与类型萃取:通过编译期类型推导和函数特征提取,实现静态类型安全的调用适配。
-
使用通用数据类型(如 JSON):设计统一的参数与返回值协议,所有数据以 JSON 等通用结构表示,在调用端与服务端按约定解析。
前两种方案性能较高且类型控制严格,但实现复杂度与学习成本也相对较高。为保持项目简洁、易于理解和扩展,本项目采用第三种方式,基于 JSON 设计统一的通信格式,从而降低实现门槛并保持较好的可读性与灵活性。
3. 网络传输层的实现方案
在网络通信层的实现上,主要有以下几种常见选择:
-
原生 Socket 编程:灵活性最高,但需自行处理连接管理、协议解析、多路复用等底层细节,实现复杂度较高。
-
Boost.Asio 异步网络库:功能强大,支持异步高性能网络编程,但需引入额外的依赖库,且其编程模型有一定学习曲线。
-
muduo 网络库:基于 Reactor 模式设计,结构清晰,与现代 C++ 风格结合较好,且与当前项目的技术栈相匹配,学习与开发成本相对较低。
综合实现难度、项目契合度与学习成本,本项目选用 muduo 作为底层网络库,以便更专注于 RPC 框架本身的逻辑实现。
4. 序列化与反序列化方案
序列化负责将数据结构转换为可传输或存储的格式,反序列化则是其逆过程。可选方案包括:
-
Protobuf:二进制协议,序列化效率高、体积小,适合高性能场景。
-
JSON:文本格式,可读性好,通用性强,易于调试和跨语言交互。
由于本项目已确定使用 JSON 作为参数与返回值的通用表示格式,为保持架构一致性与实现简便,直接采用 JSON 完成序列化与反序列化。该选择虽在性能上不及二进制协议,但更符合本项目强调易用、易懂和快速上手的定位。
三.环境搭建(ubuntu22.04)
3.1.基本工具
安装wget(一般情况下默认会自带)
bash
sudo apt-get install wget更换国内软件源
先备份原来的`/etc/apt/sources.list`文件
bash
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak添加软件源文件内容,新增以下内容
bash
#阿里源
deb https://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
# deb https://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
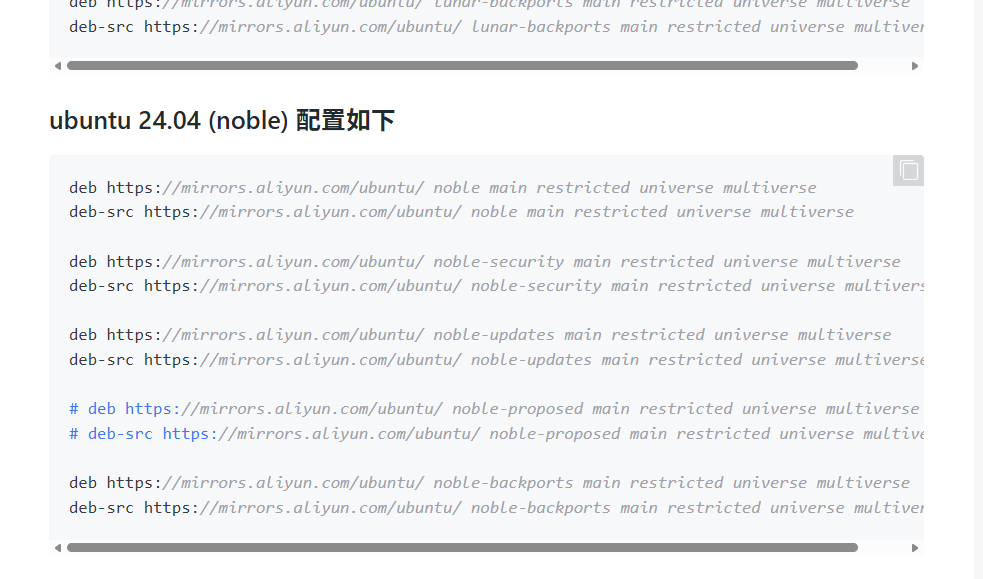
# 清华源 Ubuntu 24.04 (noble) 配置
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-security main restricted universe multiverse这里的镜像源就涉及两个网址
- 阿里源
阿里源:Ubuntu镜像-Ubuntu镜像下载安装-开源镜像站-阿里云
这里都告诉你怎么进行配置了,其实是很方便的
- 清华源
清华源:Index of /ubuntu/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
这个网站就比较难看懂
进去之后看自己的系统版本的代号是啥,找对应的就行了
我这个系统的代号就是noble,我们往下滑就找到了
noble (主仓库)
noble-updates (更新)
noble-backports (向后移植)
noble-security (安全更新)
noble-proposed (建议更新,但通常不稳定,不建议普通用户启用)
因此我们配置前面4个目录里面的文件即可
这几个目录点进去看,基本都是下面这样子
- main/ - 官方维护的自由开源软件(Canonical官方支持)
- restricted/ - 专有驱动程序(如显卡驱动)
- universe/ - 社区维护的自由开源软件(最多软件在这里)
- multiverse/ - 受版权或法律限制的软件
我们配置这4个即可。
当然,你不需要点击这些链接。这些都是Ubuntu软件源的目录结构,不是让你点击的。
网站上的这些目录是给系统
apt命令自动访问的,不是让你在浏览器中点击下载的。apt系统会自动访问这些目录来获取软件包信息。我们只需要知道怎么配置这个APT源即可
bash# 清华源 Ubuntu 24.04 (noble) 配置 deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-updates main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-backports main restricted universe multiverse deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-security main restricted universe multiverse如果说我们需要别的版本的话,把后面的目录换一下即可

新增完毕后,更新源
bash
sudo apt-get update安装lrzsz传输工具
bash
sudo apt-get install lrzsz
rz --version安装编译器gcc/g++
bash
sudo apt-get install gcc g++安装项目构建工具make
bash
sudo apt-get install make安装调试器gdb
bash
sudo apt-get install gdb安装git
bash
sudo apt-get install git
git --version安装cmake
bash
sudo apt-get install cmake
cmake --version安装jsoncpp
bash
sudo apt-get install libjsoncpp-dev觉得麻烦的,就执行下面这个命令来一键完成
bash
sudo apt-get install wget && sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak && sudo sh -c 'echo "#阿里源
deb https://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-security main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-updates main restricted universe multiverse
# deb https://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
# deb-src https://mirrors.aliyun.com/ubuntu/ noble-proposed main restricted universe multiverse
deb https://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
deb-src https://mirrors.aliyun.com/ubuntu/ noble-backports main restricted universe multiverse
# 清华源 Ubuntu 24.04 (noble) 配置
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ noble-security main restricted universe multiverse
" > /etc/apt/sources.list' && sudo apt-get update && sudo apt-get install -y lrzsz gcc g++ make gdb git cmake libjsoncpp-dev3.2.Muduo库安装
首先,Muduo库的官网:GitHub - chenshuo/muduo: Event-driven network library for multi-threaded Linux server in C++11
那么在安装Muduo库之前呢,我们需要先安装一些依赖工具
bash
sudo apt-get install libz-dev libboost-all-dev然后呢,我们去官网去下载源码:GitHub - chenshuo/muduo: Event-driven network library for multi-threaded Linux server in C++11
我们通过rz命令把这个文件上传到我们的远端服务器里面
bash
unzip muduo-master.zip
cd muduo-master
接下来我们就进行安装
bash
./build.sh
这个命令就是编译的过程啊
bash
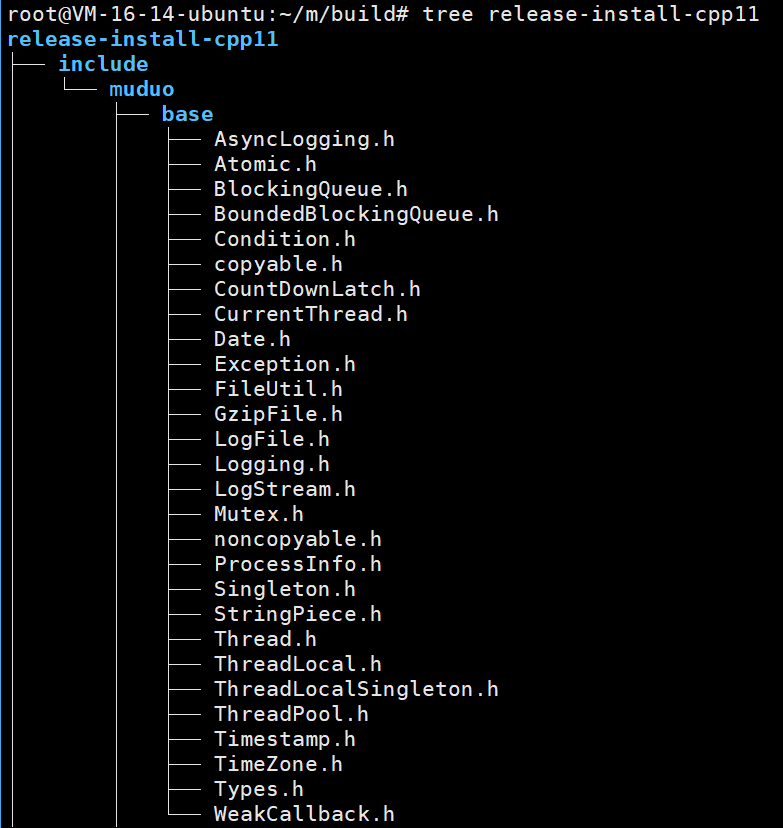
./build.sh install这个是安装的过程,那么这个到底安装到哪里了呢?
事实上,它其实是安装到了上一层目录的build目录


我们需要的库都在这里面哦!!
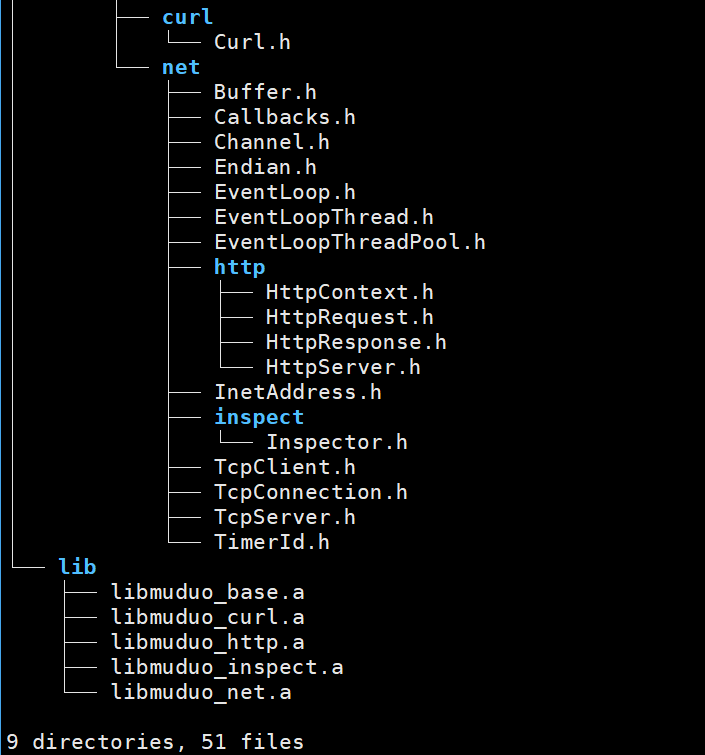
注意这里其实已经给了很多的使用示例,下面这些都是已经编译好的程序
我们拿一个出来测试一下

我们打开另外一个终端
这个时候我们发现原来那个终端变成了下面这样子

这就代表成功了!!
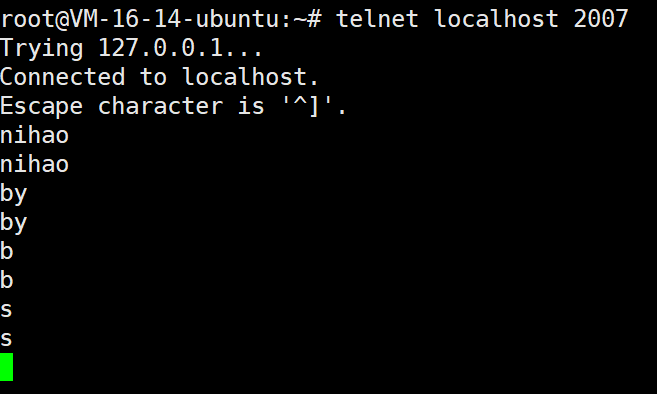
可以看到,我们发送一个字符,服务器就回显过来,这是完全没有问题的.
这就说明我们的Muduo库一切正常。
3.3.Muduo库实现翻译服务
我们这里其实很简单
server.cpp
cpp
/*
实现一个翻译服务器,客户端发送过来一个英语单词,返回一个汉语词语
*/
#include <muduo/net/TcpServer.h> // TCP服务器类
#include <muduo/net/EventLoop.h> // 事件循环类
#include <muduo/net/TcpConnection.h> // TCP连接类
#include <muduo/net/Buffer.h> // 缓冲区类
#include <iostream> // 输入输出流
#include <string> // 字符串类
#include <unordered_map> // 无序映射(哈希表)
// 字典服务器类
class DictServer {
public:
// 构造函数,初始化服务器
DictServer(int port): _server(&_baseloop,
muduo::net::InetAddress("0.0.0.0", port), // 监听所有网卡,指定端口
"DictServer", muduo::net::TcpServer::kReusePort) // 服务器名称,设置端口重用
{
// 设置连接事件(连接建立/断开)的回调
_server.setConnectionCallback(std::bind(&DictServer::onConnection, this, std::placeholders::_1));
// 设置消息接收的回调
_server.setMessageCallback(std::bind(&DictServer::onMessage, this,
std::placeholders::_1, std::placeholders::_2, std::placeholders::_3));
}
// 启动服务器
void start() {
_server.start(); // 开始监听
_baseloop.loop(); // 启动事件循环(阻塞调用)
}
private:
// 连接状态变化的回调函数
//连接建立的时候,连接断开的时候会被调用
void onConnection(const muduo::net::TcpConnectionPtr &conn) {
if (conn->connected()) {
std::cout << "连接建立!\n";
}else {
std::cout << "连接断开!\n";
}
}
// 接收到消息的回调函数
void onMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buf, muduo::Timestamp)
{
// 静态字典映射表(英语->汉语)
static std::unordered_map<std::string, std::string> dict_map = {
{"hello", "你好"},
{"world", "世界"},
{"bite", "比特"}
};
// 从缓冲区读取客户端发送的数据
std::string msg = buf->retrieveAllAsString();
std::string res;
// 在字典中查找对应的翻译
auto it = dict_map.find(msg);
if (it != dict_map.end()) {
res = it->second; // 找到翻译
}else {
res = "未知单词!"; // 未找到翻译
}
// 将翻译结果发送回客户端
conn->send(res);
}
private:
muduo::net::EventLoop _baseloop; // 事件循环对象
muduo::net::TcpServer _server; // TCP服务器对象
};
// 主函数
int main()
{
// 创建字典服务器,监听8080端口
DictServer server(8080);
// 启动服务器
server.start();
return 0;
}client.cpp
cpp
// 包含必要的头文件
#include <muduo/net/TcpClient.h>
#include <muduo/net/EventLoop.h>
#include <muduo/net/EventLoopThread.h>
#include <muduo/net/TcpConnection.h>
#include <muduo/net/Buffer.h>
#include <muduo/base/CountDownLatch.h>
#include <iostream>
#include <string>
// 字典客户端类
class DictClient {
public:
// 构造函数:初始化客户端,连接服务器
DictClient(const std::string &sip, int sport):
_baseloop(_loopthread.startLoop()), // 启动事件循环线程,获取事件循环指针
_downlatch(1), // 初始化计数器为1,因为为0时才会唤醒
_client(_baseloop, muduo::net::InetAddress(sip, sport), "DictClient") // 创建TcpClient对象
{
// 设置连接事件(连接建立/断开)的回调
_client.setConnectionCallback(std::bind(&DictClient::onConnection, this, std::placeholders::_1));
// 设置消息接收的回调
_client.setMessageCallback(std::bind(&DictClient::onMessage, this,
std::placeholders::_1, std::placeholders::_2, std::placeholders::_3));
// 连接服务器
_client.connect();
// 等待连接建立完成
_downlatch.wait();
}
// 发送消息到服务器
bool send(const std::string &msg) {
if (_conn->connected() == false) {
std::cout << "连接已经断开,发送数据失败!\n";
return false;
}
_conn->send(msg);
return true; // 注意:原代码缺少返回值,这里添加return true
}
private:
// 连接状态变化的回调函数
void onConnection(const muduo::net::TcpConnectionPtr &conn) {
if (conn->connected()) {
std::cout << "连接建立!\n";
_downlatch.countDown(); // 计数减1,为0时唤醒阻塞的wait()
_conn = conn; // 保存连接对象
}else {
std::cout << "连接断开!\n";
_conn.reset(); // 重置连接指针
}
}
// 接收到消息的回调函数
void onMessage(const muduo::net::TcpConnectionPtr &conn, muduo::net::Buffer *buf, muduo::Timestamp){
std::string res = buf->retrieveAllAsString(); // 从缓冲区读取所有数据
std::cout << res << std::endl; // 打印接收到的消息
}
private:
muduo::net::TcpConnectionPtr _conn; // 当前TCP连接指针
muduo::CountDownLatch _downlatch; // 用于等待连接建立的同步工具
muduo::net::EventLoopThread _loopthread; // 事件循环线程
muduo::net::EventLoop *_baseloop; // 事件循环指针
muduo::net::TcpClient _client; // TCP客户端对象
};
// 主函数
int main()
{
// 创建字典客户端,连接到127.0.0.1:8080
DictClient client("127.0.0.1", 8080);
// 主循环:从标准输入读取消息并发送到服务器
while(1) {
std::string msg;
std::cin >> msg; // 读取用户输入
client.send(msg); // 发送消息到服务器
}
return 0;
}makefile
CFLAG= -std=c++11 -I ../../third/m/build/release-install-cpp11/include/
LFLAG= -L../../third/m/build/release-install-cpp11/lib -lmuduo_net -lmuduo_base -pthread
all: server client
server: server.cpp
g++ $(CFLAG) $^ -o $@ $(LFLAG)
client: client.cpp
g++ $(CFLAG) $^ -o $@ $(LFLAG)

接下来我们运行这个客户端
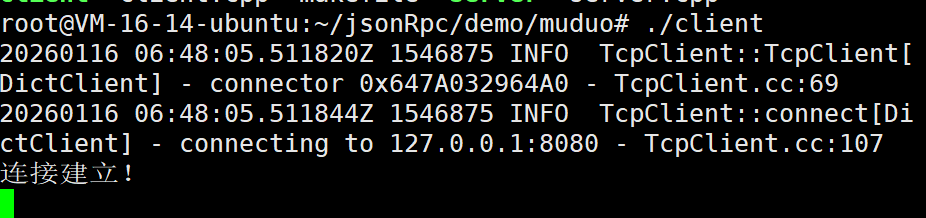
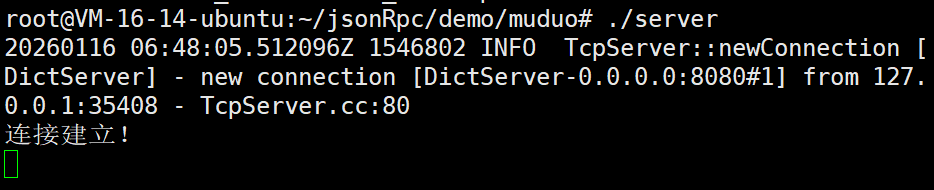
现在我们就在客户端输入一些信息
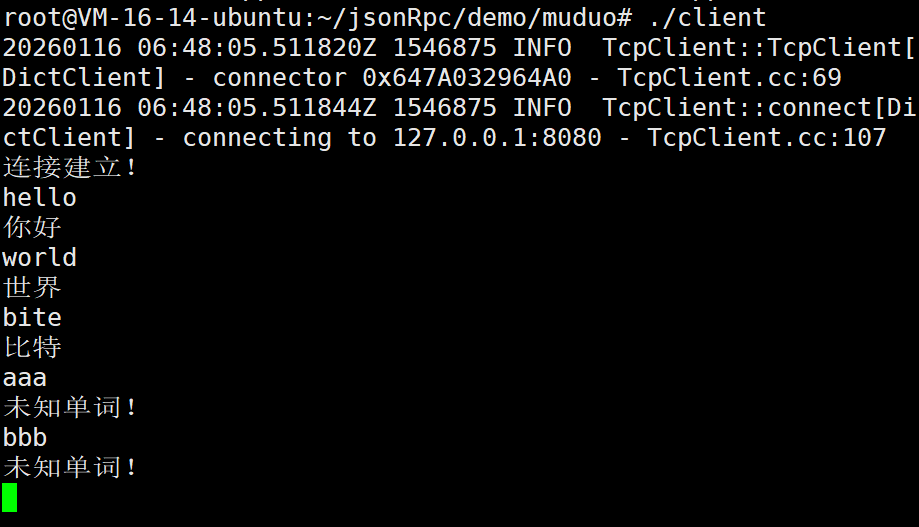
完全没有问题。
四.jsoncpp库
如果说:大家想要学习JSON,大家可以先看看:【云备份项目】json以及jsoncpp库的使用_jsoncpp 数组-CSDN博客
jsoncpp 是一个广泛使用的 C++ 库,用于处理 JSON(JavaScript Object Notation)数据格式。它提供了将 C++ 数据对象序列化为 JSON 格式字符串的功能,以及将 JSON 格式字符串反序列化为 C++ 数据对象的功能。
以下是对 jsoncpp 库的一些关键特性和使用方法的概述:
关键特性
- **序列化与反序列化:**jsoncpp 可以将 C++ 对象(如 STL 容器、基本数据类型等)转换为 JSON 格式的字符串。同样,它也可以将 JSON 格式的字符串解析回 C++ 对象。
- **易于使用:**提供了直观的 API,使得序列化和反序列化过程相对简单。
- **支持多种数据类型,**包括整数、浮点数、字符串、布尔值、数组(对应 C++ 中的 std::vector 等)和对象(对应 C++ 中的 std::map、std::unordered_map 或自定义类)。
- **跨平台:**jsoncpp 可以在多种操作系统上运行,包括 Windows、Linux 和 macOS。
- **性能:**对于大多数应用场景,jsoncpp 提供了足够的性能。然而,在极端情况下,可能需要考虑其他更高效的 JSON 库。
4.1.***json数据对象类------***jsonvalue
我们可以在我们安装的jsoncpp库里面找到下面这个文件
bash
ls /usr/include/jsoncpp/json/
我们现在要讲的value就在value.h里面
我们打开来
bash
vim /usr/include/jsoncpp/json/value.h往下翻就能看到

非常多信息啊,我们只讲一小部分啊!!
javascript
//Json数据对象类
class Json::Value{
Value &operator=(const Value &other); //Value重载了[]和=,因此所有的赋值和获取数据都可以通过
Value& operator[](const std::string& key);//简单的方式完成 val["姓名"] = "小明";
Value& operator[](const char* key);
Value removeMember(const char* key);//移除元素
const Value& operator[](ArrayIndex index) const; //val["成绩"][0]
Value& append(const Value& value);//添加数组元素val["成绩"].append(88);
ArrayIndex size() const;//获取数组元素个数 val["成绩"].size();
std::string asString() const;//转string string name = val["name"].asString();
const char* asCString() const;//转char* char *name = val["name"].asCString();
Int asInt() const;//转int int age = val["age"].asInt();
float asFloat() const;//转float
bool asBool() const;//转 bool
};**注意:代码片段是一个简化的、概念性的 Json::Value 类的声明,它模拟了 jsoncpp 库中 Json::Value 类的一些关键功能。**然而,请注意,这并不是 jsoncpp 库中实际的 Json::Value 类的完整或准确实现。以下是对您提供的类声明的一些解释和补充:
- 赋值运算符重载:
cpp
Value &operator=(const Value &other); 这个成员函数允许您将一个 Json::Value 对象赋值给另一个。在 jsoncpp 中,这是必需的,因为 Json::Value 是一个可以表示多种 JSON 数据类型(如对象、数组、字符串、数字等)的类。
- 下标运算符重载:
cpp
Value& operator[](const std::string& key);
Value& operator[](const char* key);
const Value& operator[](ArrayIndex index) const; 这些成员函数允许您使用字符串键或数组索引来访问 Json::Value 对象中的元素。这是处理 JSON 对象和数组时非常有用的功能。
- 移除成员:
cpp
Value removeMember(const char* key); 这个函数允许您从 JSON 对象中移除一个成员。注意,根据您的声明,这个函数的返回类型是 Value,但在 jsoncpp 的实际实现中,它可能返回被移除的值(如果有的话)或某种表示操作成功的状态。
- 添加数组元素:
cpp
Value& append(const Value& value); 这个函数允许您向 JSON 数组中添加一个新元素。在 jsoncpp 中,这是通过修改内部的数组结构来实现的。
- 获取数组大小:
cpp
ArrayIndex size() const; 这个函数返回 JSON 数组中元素的数量。在 jsoncpp 中,ArrayIndex 通常是一个无符号整数类型,用于表示数组索引。
- 类型转换函数:
cpp
std::string asString() const;
const char* asCString() const;
Int asInt() const; // 注意:在 jsoncpp 中,Int 是一个定义好的类型,通常是 long long 或类似的整数类型
float asFloat() const;
bool asBool() const; 这些函数允许您将 Json::Value 对象转换为相应的 C++ 数据类型。这是从 JSON 数据中提取信息时非常常见的操作。
重要提示:
- 在实际使用 jsoncpp 时,您应该包含 <json/json.h> 头文件,并链接到 jsoncpp 库。
4.2.json序列化类
我们可以在我们安装的jsoncpp库里面找到下面这个文件
bash
ls /usr/include/jsoncpp/json/我们现在要讲的writer就在writer.h里面
我们打开来
bash
vim /usr/include/jsoncpp/json/writer.h往下翻就能看到


我们总结一下就是下面这个
cpp
// StreamWriter 抽象基类
class JSON_API StreamWriter {
public:
virtual ~StreamWriter() = default; // 虚析构函数
virtual int write(const Value& root, std::ostream* sout) const = 0; // 纯虚函数,要求派生类实现
};
// StreamWriterBuilder 类,继承自 StreamWriterFactory
class JSON_API StreamWriterBuilder : public StreamWriterFactory {
public:
std::unique_ptr<StreamWriter> create() const override; // 重写基类的纯虚函数
// ... 可能提供设置序列化选项的成员函数
};- StreamWriter和StreamWriterBuilder类
StreamWriter是另一个抽象基类,它定义了一个将Value对象序列化到输出流中的write函数。与Writer不同,StreamWriter允许将序列化后的数据直接写入到std::ostream对象中,如文件流、字符串流等。
StreamWriterBuilder是一个工厂类,它继承自一个假设的StreamWriterFactory接口(在上面的代码中已经进行了定义)。StreamWriterBuilder实现了create函数,用于创建StreamWriter对象。通过提供不同的配置选项,StreamWriterBuilder可以生成具有不同序列化行为的StreamWriter实例。
4.3.json实现序列化案例
当需要将一个Json::Value对象序列化为JSON字符串时,使用jsoncpp库的程序通常会执行以下步骤(基于下面的代码示例和新版jsoncpp库的接口):
准备数据:
- 创建一个Json::Value对象,并根据需要向其添加键值对、数组、嵌套对象等。
创建序列化器:
- **使用Json::StreamWriterBuilder对象的newStreamWriter方法创建一个Json::StreamWriter的智能指针。**这个序列化器将负责将Json::Value对象转换为JSON格式的字符串。
准备输出流:
- **创建一个输出流对象,如std::stringstream,用于存储序列化后的JSON字符串。**也可以使用其他输出流,如std::ofstream来写入文件。
执行序列化:
- 调用Json::StreamWriter智能指针的write方法,将Json::Value对象作为参数传入,并指定输出流。write方法会遍历Json::Value对象的结构,并将其转换为JSON格式的字符串,然后写入到指定的输出流中。
获取和使用JSON字符串:
- 如果使用了std::stringstream,可以通过调用其str方法来获取序列化后的JSON字符串。然后,可以将这个字符串用于各种目的,如打印到控制台、发送到网络、保存到文件等。
这些步骤概述了使用jsoncpp库将Json::Value对象序列化为JSON字符串的典型过程。
cpp
/*
json 序列化示例
*/
#include <iostream> // 引入标准输入输出流库
#include <sstream> // 引入字符串流库
#include <memory> // 引入内存管理库(用于智能指针)
#include <jsoncpp/json/json.h> // 引入jsoncpp库,用于JSON处理
int main()
{
// 定义并初始化一个常量字符指针,指向字符串"小明"
// 定义一个整型变量并初始化为18,表示年龄
int age = 18;
// 定义一个浮点型数组,存储三门课程的成绩
float score[] = {77.5, 88, 93.6};
// 定义一个Json::Value对象,作为JSON数据的根节点
Json::Value root;
// 向root中添加一个键值对,键为"name",值为name所指向的字符串
root["name"] ="xiaoming";
// 向root中添加一个键值对,键为"age",值为整型变量age
root["age"] = age;
// 向root中添加一个键为"成绩"的数组,并依次添加score数组中的元素
// 使用append函数向数组中插入数据
root["chengji"].append(score[0]);
root["chengji"].append(score[1]);
root["chengji"].append(score[2]);
// 创建一个Json::StreamWriterBuilder对象,用于配置StreamWriter的创建
Json::StreamWriterBuilder swb;
// 使用swb的newStreamWriter方法创建一个StreamWriter的智能指针
// std::unique_ptr是一个智能指针,它会在离开作用域时自动释放所管理的资源
std::unique_ptr<Json::StreamWriter> sw(swb.newStreamWriter());
// 创建一个字符串流对象,用于存储序列化后的JSON字符串
std::stringstream ss;
// 调用StreamWriter的write方法,将Json::Value对象序列化为JSON字符串,并写入到字符串流中
sw->write(root, &ss);
// 从字符串流中提取出序列化后的JSON字符串,并输出到标准输出流(控制台)
std::cout << ss.str() << std::endl;
return 0;
}makefile
bash
test:main.cc
g++ -o $@ $^ -ljsoncpp
.PHONY:clean
rm -rf test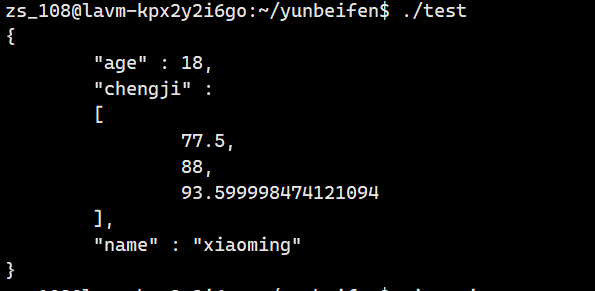
4.4.json反序列化类
我们可以在我们安装的jsoncpp库里面找到下面这个文件
bash
ls /usr/include/jsoncpp/json/我们现在要讲的就在reader.h里面
我们打开来
bash
vim /usr/include/jsoncpp/json/reader.h往下翻就能看到类似于下面的内容
cpp
json反序列化类,高版本更推荐
class JSON_API CharReader {
virtual bool parse(char const* beginDoc, char const* endDoc,
Value* root, std::string* errs) = 0;
}
class JSON_API CharReaderBuilder : public CharReader::Factory {
virtual CharReader* newCharReader() const;
}- CharReader 类
CharReader 类是一个更底层的、面向字符数组的JSON解析接口。它定义了一个纯虚函数 parse,该函数接受字符数组的起始和结束指针,一个指向 Value 对象的指针(用于存储解析后的数据),以及一个指向字符串的指针(用于存储错误信息)。
- beginDoc 和 endDoc:分别指向JSON文档字符数组的起始和结束位置。
- root:一个指向 Value 对象的指针,用于存储解析后的JSON数据结构。
- errs:一个指向字符串的指针,用于存储解析过程中遇到的错误信息。如果解析成功,该字符串应该为空。
与 Reader 类不同,CharReader 类直接操作字符数组,而不是字符串。这使得它更加灵活,因为字符数组可以来自不同的源(如文件、网络流等),并且不需要额外的字符串复制操作。
- CharReaderBuilder 类
CharReaderBuilder 类是一个工厂类,它继承自 CharReader::Factory 接口。CharReaderBuilder 类实现了 newCharReader 函数,该函数用于创建 CharReader 对象的实例。
newCharReader 函数返回一个指向新创建的 CharReader 对象的指针。这个 CharReader 对象可以被用来解析JSON文档。
注意:这个只适用于高版本JSON,我们这里就使用它了啊
4.5.json实现反序列化案例
- 工作机制
- 当需要将一个JSON格式的字符串解析为程序对象时,可以使用CharReader 类。
- 首先,通过 CharReaderBuilder 类创建一个 CharReader 对象的实例。
- 然后,调用该实例的 parse 函数,传入字符数组的起始和结束指针、一个指向 Value 对象的指针和一个指向字符串的指针(用于存储错误信息)。
- 在解析过程中,Reader 或 CharReader 类会遍历JSON文档,并根据JSON的语法规则构建相应的 Value 对象结构。如果遇到错误(如语法错误、类型不匹配等),解析器会停止解析,并通过返回值或错误信息字符串来指示错误。
- 解析成功后,调用者可以访问 Value 对象来获取解析后的JSON数据。
cpp
/*
json 反序列化示例
*/
#include <iostream> // 引入标准输入输出流库
#include <string> // 引入字符串库
#include <memory> // 引入内存管理库(用于智能指针)
#include <jsoncpp/json/json.h> // 引入jsoncpp库,用于JSON处理
int main()
{
// 定义一个字符串,存储JSON格式的文本数据
std::string str = R"({"姓名":"小黑", "年龄":19, "成绩":[58.5, 44, 20]})";
// 创建一个Json::Value对象,用于存储解析后的JSON数据
Json::Value root;
// 创建一个Json::CharReaderBuilder对象,用于配置CharReader的创建
Json::CharReaderBuilder crb;
// 使用crb的newCharReader方法创建一个CharReader的智能指针
std::unique_ptr<Json::CharReader> cr(crb.newCharReader());
// 定义一个字符串,用于存储解析过程中可能发生的错误信息
std::string err;
// 调用CharReader的parse方法,尝试将字符串str解析为JSON数据,并存储在root中
// parse方法的参数包括:待解析的字符串的起始指针、结束指针、存储解析结果的Json::Value对象的指针、存储错误信息的字符串的指针
bool ret = cr->parse(str.c_str(), str.c_str() + str.size(), &root, &err);
// 检查解析是否成功
if(ret == false)
{
// 如果解析失败,输出错误信息并返回-1
std::cout << "parse error: " << err << std::endl;
return -1;
}
// 从解析后的JSON数据中提取"姓名"字段的值,并作为字符串输出
std::cout << root["姓名"].asString() << std::endl;
// 从解析后的JSON数据中提取"年龄"字段的值,并作为整数输出
std::cout << root["年龄"].asInt() << std::endl;
// 获取"成绩"字段(一个数组)的大小
int sz = root["成绩"].size();
// 遍历"成绩"数组,并输出每个元素的值
for(int i = 0; i < sz; i++)
{
std::cout << root["成绩"][i].asDouble() << std::endl; // 注意:这里使用asDouble()来确保输出浮点数的精度
}
// 程序正常结束,返回0
return 0;
}JSON的反序列化(也称为解析)是将JSON格式的字符串数据转换回其对应的程序数据结构(如对象、数组、键值对等)的过程。在jsoncpp库中,这一过程主要通过Json::CharReader(或其派生类)的parse方法来实现。以下是对jsoncpp库中JSON反序列化实现过程的详细解释:
JSON字符串准备:
- 首先,你需要有一个包含JSON数据的字符串。这个字符串可能来自文件、网络请求、用户输入等。
Json::Value对象创建:
- 创建一个Json::Value对象,它将用于存储解析后的JSON数据。Json::Value是jsoncpp库中的一个核心类,用于表示JSON中的各种数据类型(如对象、数组、字符串、数字等)。
CharReader配置与创建:
- 使用Json::CharReaderBuilder来配置并创建一个Json::CharReader对象(或其派生类)。CharReaderBuilder允许你设置一些解析选项,但大多数情况下,你可以使用默认设置。
- Json::CharReader是负责实际解析JSON字符串的类。它通过其parse方法来完成解析工作。
调用parse方法:
- 调用Json::CharReader对象的parse方法,将JSON字符串、字符串的起始和结束指针、Json::Value对象的引用以及一个用于存储错误信息的字符串的引用作为参数传入。
- parse方法会尝试将JSON字符串解析为Json::Value对象表示的数据结构。如果解析成功,Json::Value对象将被填充为相应的数据;如果解析失败,错误信息将被存储在提供的字符串中。
检查解析结果:
- 解析完成后,你需要检查parse方法的返回值来确定解析是否成功。如果返回true,则表示解析成功;如果返回false,则表示解析失败,并且你可以通过提供的错误信息字符串来获取详细的错误信息。
访问解析后的数据:
- 一旦解析成功,你就可以使用Json::Value对象提供的各种方法来访问和操作解析后的数据了。例如,你可以使用operator\[\]来访问对象中的键或数组中的元素,并使用asString()、asInt()、asDouble()等方法来将数据转换为适当的类型。
在jsoncpp库的内部实现中,Json::CharReader的parse方法会逐字符地分析JSON字符串,并根据JSON的语法规则构建相应的Json::Value对象。这个过程涉及到对JSON各种数据类型的识别和处理(如对象、数组、字符串、数字、布尔值、null等),以及对JSON语法错误(如缺少引号、括号不匹配、逗号放错位置等)的检测和报告。
makefile
bash
test:main.cc
g++ -o $@ $^ -ljsoncpp
.PHONY:clean
rm -rf test
五.C++异步操作------std::future
在C++中,std::future是一个模板类,它提供了一种机制来获取异步操作的结果。这里我将以纯文字方式详细描述std::future的使用和相关概念。
首先,我们需要了解异步操作。异步操作是指那些可以在后台执行的操作,不会阻塞当前线程。当我们需要执行一个耗时操作(比如计算、文件读写、网络请求等)时,我们可以将其作为异步任务,这样主线程可以继续执行其他任务,直到需要异步任务的结果时再等待其完成。
std::future就是用来表示这个异步任务的结果。它并不存储结果,而是作为一个句柄,通过它可以获取异步任务的结果。当异步任务完成时,结果会被存储在一个共享状态中,std::future可以访问这个共享状态。
使用std::future的基本步骤:
-
启动异步任务:我们可以使用std::async、std::packaged_task或者std::promise来创建一个异步任务,并获取与这个任务关联的std::future对象。
-
在需要结果的地方,通过std::future对象获取结果。
5.1.std::async
5.1.1.通俗版介绍
你可以把 std::async 想象成一个帮你"外包任务"的聪明管家。
- 你:就是主线程,正在处理主要工作(比如做菜)。
- 任务:一件你想完成,但又不想自己停下来去做的耗时工作(比如去楼下买瓶酱油)。
- **std::async 管家:**你把这个买酱油的任务"外包"给了他。
- **std::future 收据/承诺:**管家不会立刻把酱油给你,而是给你一张"收据"或一个"承诺"。这张收据上写着"未来会有一瓶酱油"。这张收据就是 std::future 对象。
现在,关键来了:这个管家派谁去执行"买酱油"这个任务呢?这取决于你给他的指令,也就是 std::launch 启动策略。
三种"外包"策略(启动策略)
策略一:懒汉模式 - std::launch::deferred
- 管家行为:管家接过你的任务,说:"好的,我知道了。"但他立刻就把任务忘在脑后了,根本没派人出去。
- 实际执行时机:什么时候才执行呢?直到你拿着那张收据(future),主动对他说:"喂,我的酱油呢?我现在就要 !"(即调用 get() 或 wait() 方法 )。这时,管家才一拍脑袋:"哎呀!我还没派人去呢!"然后他会立刻、亲自、就在你面前(在当前调用 get() 的线程里)跑去把酱油买回来给你。
- 特点:**根本没有创建新线程。任务是"延迟"执行的,并且是同步的(你必须停下来等他把事办完)。**适合那些"可能不需要,但如果需要就马上做"的任务。
策略二:勤快模式 - std::launch::async
管家行为:管家接过任务,立刻转身雇佣了一个新的临时工(创建一个新线程),把钱和任务清单交给他说:"快去快回!"
实际执行时机:任务立刻就开始了。新线程(临时工)立刻出发去买酱油。
你的状态:你可以继续做你的主菜(主线程继续运行),完全不用等待。
取结果:当你需要酱油时(调用 get()),会有两种情况:
- 如果临时工已经回来了,你直接拿到酱油。
- 如果临时工还没回来,那你必须停下来等他(主线程被阻塞),直到他回来把酱油交给你。
特点:明确创建了新线程,任务是真正异步执行的。适合那些明确需要后台并发执行的任务。
策略三:自动模式 - std::launch::deferred | std::launch::async(默认策略)
管家行为:管家很精明。他没有立刻决定。他会根据一些内部因素(比如系统忙不忙、任务重不重等)自己偷偷做决定。
可能的结果:
- 他可能选择"懒汉模式"(deferred),先记下来,等你要的时候再做。
- 他也可能选择"勤快模式"(async),立刻派个新线程去做。
对你的影响:你无法预测任务会怎么执行! 这对程序的行为有重大影响:
- 如果你假设它是异步的(认为它在新线程运行了),而它实际是延迟的,那么当你第一次调用 get() 时,会意外地导致长时间等待,破坏你的并发计划。
- 如果你依赖它创建新线程(比如任务有线程局部变量),而它选择了延迟执行,那么这些依赖就会出错。
给初学者的建议:**尽量不要使用这个默认的自动模式。**明确指定你想要的策略(async 或 deferred),这样代码的行为才是清晰、可预测的。不确定的时候,问问自己:"这个任务我必须立刻开始做吗?",如果答案是"是",就用 async;如果"不一定,也许等会儿做也行",就用 deferred。
一个生活化的比喻总结
想象你要写一封信并寄出去。
- std::launch::deferred:你把信和邮票放在桌上,继续工作。只有当邮差上门问你"有信要寄吗?"的时候(get()),你才停下工作,现场写信、贴邮票、交给他。
- std::launch::async:你立刻叫来一个跑腿小弟,把写好的信和钱给他,说:"去帮我寄了。"然后你继续工作。小弟立刻出发。等他回来问你要小费(get())时,你才需要理他。
- 默认策略:你可能把信放在桌上(打算等邮差),也可能立刻叫了跑腿小弟。但你记性不好,过一会儿就忘了自己是怎么安排的了,导致邮差来时你措手不及。
5.1.2.专业描述
首先,std::async 是C++11中提供的一个用于异步任务处理的工具。
它可以将一个可调用对象(比如函数、Lambda表达式、函数对象等)包装起来,并使其可能在新线程中运行,然后返回一个std::future对象,通过这个future对象可以获取异步任务的结果。
当我们使用std::async时,我们可以指定一个启动策略(launch policy),这个策略决定了任务何时以及如何运行。
-
std::launch::deferred(延迟启动):
如果我们使用这个策略,那么任务不会立即开始执行。相反,它会延迟到我们调用future的get()或wait()方法时才会执行。而且,任务会在调用get()或wait()的线程中执行,而不是在新线程中。也就是说,任务会同步执行,直到任务完成,get()或wait()才会返回。
-
std::launch::async(异步启动):
这个策略会立即开始执行任务,任务会在一个新创建的线程中运行。我们可以在主线程中继续做其他事情,然后在需要的时候通过future来获取任务的结果。注意,如果任务已经开始执行,那么即使我们不调用get(),它也会在后台运行,直到完成。
-
默认策略(std::launch::deferred | std::launch::async):
当我们不指定策略时,或者指定为两者组合时,由系统决定是立即启动一个新线程(类似async)还是延迟执行(类似deferred)。这取决于系统当时的资源状况和实现。因此,使用默认策略时,我们无法确定任务是会延迟执行还是异步执行。
5.1.3.示例
示例1:std::launch::deferred(延迟执行)
cpp
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
int compute(int x, int y) {
std::cout << "计算线程ID: " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
return x + y;
}
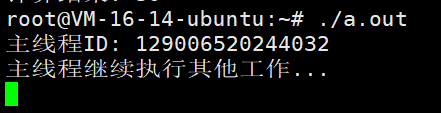
int main() {
std::cout << "主线程ID: " << std::this_thread::get_id() << std::endl;
// 使用延迟策略
auto future = std::async(std::launch::deferred, compute, 10, 20);
std::cout << "主线程继续执行其他工作..." << std::endl;
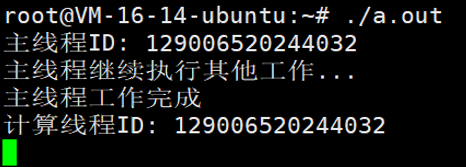
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "主线程工作完成" << std::endl;
// 只有在这里才会真正执行compute函数
int result = future.get();
std::cout << "计算结果: " << result << std::endl;
return 0;
}
停顿1秒
停顿2秒
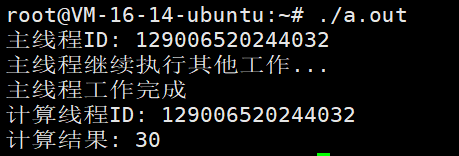
恰好说明了如果我们使用这个策略,那么任务不会立即开始执行。相反,它会延迟到我们调用future的get()或wait()方法时才会执行。
示例2:std::launch::async(异步执行)
cpp
#include <iostream>
#include <future>
#include <thread>
#include <chrono>
int compute(int x, int y) {
std::cout << "计算线程ID: " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(2));
return x * y;
}
int main() {
std::cout << "主线程ID: " << std::this_thread::get_id() << std::endl;
// 使用异步策略
auto future = std::async(std::launch::async, compute, 10, 20);
std::cout << "主线程继续执行其他工作..." << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "主线程工作完成" << std::endl;
// 任务已经在执行,这里只是等待结果
int result = future.get();
std::cout << "计算结果: " << result << std::endl;
return 0;
}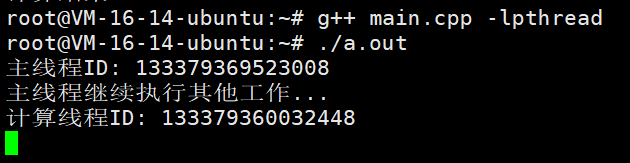
可以看到,这里主线程和计算线程是同时存在的,也就是说这个策略会立即开始执行任务,任务会在一个新创建的线程中运行。
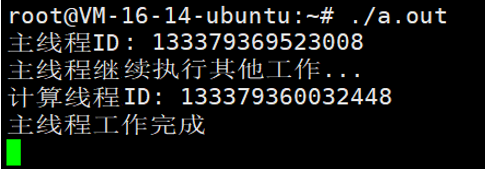
这里就是在等待计算线程返回结果了(等待事件不足2秒)
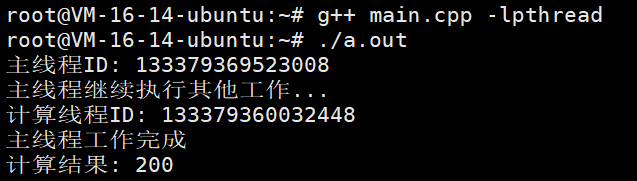
示例3------默认策略(std::launch::deferred | std::launch::async)
当我们不指定策略时,或者指定为两者组合时,由系统决定是立即启动一个新线程(类似async)还是延迟执行(类似deferred)。
cpp
auto future = std::async(compute, 10, 20);完全等价于:
cpp
auto future = std::async(std::launch::async | std::launch::deferred, compute, 10, 20);至于效果我就不演示了,没什么好说的,就是上面两种策略的任意一种!!
5.2.std::packaged_task
5.2.1.介绍
std::packaged_task也是一个将任务和future关联起来的工具,但是它的使用方式与std::async不同。你可以把std::packaged_task看作是一个包装了可调用对象(如函数、lambda表达式等)的包装器,并且它允许你获取一个与包装的任务相关联的std::future对象。
核心概念:将任务"打包"
想象一下,你有一个任务(比如一个函数),你想在未来的某个时候执行它,并且希望得到它的结果。
你可以使用std::packaged_task来打包这个任务,然后你可以把这个打包好的任务传递给其他线程,或者稍后执行。
同时,你可以通过这个打包的任务获取一个std::future对象,用于在将来获取任务的结果。
一个简单的比喻
假设你是一个公司的老板,你有一个任务(比如做一份财务报告)。你把这个任务写在一张任务卡上,然后把这张任务卡放进一个特殊的信封里(这个信封就是std::packaged_task)。
这个信封有一个特点:当你把任务卡放进去的时候,信封会给你一张收据(std::future),这张收据可以用来领取任务完成后的结果(财务报告)。
然后,你可以把这个信封交给一个员工(另一个线程)去执行,或者你可以选择在某个时候自己打开信封执行任务。
如何使用?
-
创建打包任务 :你需要创建一个std::packaged_task对象,并指定它要包装的任务(函数、lambda等)。注意,模板参数是函数签名,例如
int(int, int)表示一个返回int并接受两个int参数的函数。 -
获取future :通过调用
get_future()方法,你可以获得一个与任务结果关联的std::future对象。这样,当任务执行完毕后,你就可以通过这个future来获取结果。 -
执行任务:std::packaged_task本身是一个可调用对象,你可以直接调用它(就像调用函数一样),或者将它传递给另一个线程,让那个线程去执行。注意,任务通常只会被执行一次。
-
获取结果:通过之前获得的std::future对象,你可以获取任务的结果。如果任务还没有执行完毕,调用get()会阻塞直到结果可用。
与std::async的区别
-
std::async:它直接创建了一个异步任务,并且返回一个future。你不需要显式地管理任务的执行,它可能会在新线程中执行,也可能在调用get()时同步执行(取决于启动策略)。
-
std::packaged_task :它只是将任务包装起来,并允许你获取一个future,但是任务的执行需要你自己来安排。**你可以选择在哪个线程、什么时候执行这个任务。**它更像是一个可以移动和传递的任务对象,并且与future关联。
一个生活化的例子
假设你周末要做两件事:
-
去超市买东西(主线程任务)。
-
计算家庭月度开销(一个计算任务,比较耗时)。
你可以这样安排:
-
你创建一个计算家庭月度开销的任务,并用std::packaged_task把它打包。然后你得到一个future,用于以后获取计算结果。
-
然后,你可以把这个打包的任务(packaged_task)交给你的另一半,让他/她在你有空的时候去计算(或者你可以自己稍后计算)。同时,你可以先去超市买东西。
-
当你从超市回来,你需要知道家庭月度开销的结果时,你可以通过之前得到的future来获取。如果另一半已经计算完了,你立刻得到结果;如果还没算完,你就得等他/她算完。
为什么使用std::packaged_task?
它提供了更多的灵活性。
你可以控制任务的执行时机和方式,而且可以将任务对象(packaged_task)在多个线程之间传递,而std::async则不能这样控制。
另外,std::packaged_task还可以用于线程池等更复杂的并发模式中。
5.2.2.示例
示例1:基础使用(在同一线程中执行)
cpp
#include <iostream>
#include <future>
#include <thread>
int add(int a, int b) {
std::this_thread::sleep_for(std::chrono::seconds(1)); // 模拟耗时操作
return a + b;
}
int main() {
// 1. 创建packaged_task,包装add函数
// 模板参数是函数签名:int(int, int)
std::packaged_task<int(int, int)> task(add);
// 2. 获取与任务结果关联的future
std::future<int> result = task.get_future();
// 3. 执行任务(直接调用)
// 可以直接调用,也可以在线程中执行
task(10, 20); // 在这里调用,当前线程会执行任务
// 4. 获取结果(如果任务未完成,会阻塞等待)
std::cout << "计算结果: " << result.get() << std::endl;
return 0;
}我们直接编译运行

等待了1秒

示例2:在子线程中执行任务
我们可以将任务移交给其他线程!!!
cpp
#include <iostream>
#include <future>
#include <thread>
#include <memory>
int multiply(int x, int y) {
std::this_thread::sleep_for(std::chrono::seconds(2));
return x * y;
}
int main() {
// 使用shared_ptr包装packaged_task
auto taskPtr = std::make_shared<std::packaged_task<int()>>(
std::bind(multiply, 5, 6)
);
// 获取future
std::future<int> result = taskPtr->get_future();
// 创建一个线程来执行任务
// 使用lambda表达式捕获shared_ptr,这样任务可以安全地在线程中执行
std::thread worker([taskPtr]() {
// 调用packaged_task
(*taskPtr)();
});
// 主线程可以做其他事情
std::cout << "主线程正在做其他工作..." << std::endl;
// 当需要结果时,获取它(会阻塞直到结果可用)
std::cout << "计算结果: " << result.get() << std::endl;
// 等待工作线程结束
worker.join();
return 0;
}
等待2秒(注意这两秒是父进程在等待子进程退出)

注意:我们想要使用std::packaged_task来封装一个函数,然后通过std::future来获取结果。
但是,std::packaged_task不能直接传递给std::thread, 因为std::packaged_task不可拷贝,而且它也不是一个函数对象(虽然它重载了(),但它的类型是类模板,不能直接作为线程函数)。
5.3.std::promise
5.3.1.介绍
首先,我们需要理解std::future和std::promise的基本概念:
-
std::future:这是一个模板类,它提供了一种访问异步操作结果的机制。我们可以通过它来获取一个异步任务(比如在另一个线程中运行的函数)的返回值。但是,这个返回值可能还没有准备好,所以std::future提供了等待(wait)或检查(通过valid()等方法)的功能,直到异步操作完成并设置了值。
-
std::promise:这也是一个模板类,它提供了一种存储值(或异常)的方式,这个值可以被同一个线程或其他线程中的std::future对象读取。换句话说,std::promise允许你手动设置一个值,然后与它关联的std::future就可以读取这个值。
现在,我们来看它们如何配合工作:
-
当我们创建一个std::promise对象时,它内部会有一个共享状态 (shared state),这个共享状态可以存储一个值(或异常)。
-
通过调用std::promise的get_future()成员函数,我们可以获得一个与这个promise对象关联的std::future对象。
-
然后,我们可以在某个线程中运行一个任务,这个任务会计算一个值,然后通过调用std::promise的set_value()方法将值存储到共享状态中。
-
同时,在另一个线程(或同一个线程)中,我们可以通过std::future的get()方法来获取这个值。如果共享状态中还没有值,那么get()方法会阻塞,直到值被设置。
这样,我们就实现了一个线程向另一个线程传递数据的效果。
注意:一个std::promise对象只能关联一个std::future对象,并且只能设置一次值。如果多次设置,会抛出异常。
详细的工作流程
让我们跟着代码的典型生命周期走一遍:
步骤 1:创建配对
cpp
std::promise<int> prom; // 创建一个 promise 对象,用于将来产生一个 int 类型的值。
std::future<int> fut = prom.get_future(); // 从 promise 获取与之关联的 future 对象。此时,共享状态被创建,但里面是"空"的。future 还没有就绪。
步骤 2:生产者设置值(让 future "就绪")
在生产者线程(比如一个工作线程)中,你操作 promise:
cpp
// 生产者线程
void producer(std::promise<int>& prom) {
// ... 执行一些复杂的计算 ...
int result = 42;
prom.set_value(result); // 关键操作!
}prom.set_value(result) 做了两件至关重要的事:
- 存储数据:将计算结果 42 写入到共享状态中。
- 通知就绪:将共享状态标记为"就绪",并唤醒任何正在等待这个 future 的线程(比如消费者线程)。
步骤 3:消费者获取值
在消费者线程(比如主线程)中,你操作 future:
cpp
// 消费者线程
int main() {
// ... 创建 promise 和 future,启动生产者线程 ...
int x = fut.get(); // 关键操作!
std::cout << "Got value: " << x << std::endl; // 输出 42
}fut.get() 也做了两件关键的事:
- 等待就绪:如果共享状态还没就绪(即生产者还没调用 set_value),那么 get() 会阻塞当前线程,直到就绪。
- 取回数据:一旦就绪,它就从共享状态中取出值(这里是 42),然后返回。
关键点:**get() 只能调用一次。**调用后,共享状态中的数据就被取走(移动)了,future 变为无效。
5.3.2.示例
示例1------基本用法
- 步骤1:创建一个std::promise对象。
- 步骤2:通过这个std::promise对象获取一个std::future对象。
- 步骤3:启动一个线程,将std::promise对象传递给这个线程(或者通过其他方式让线程可以访问到这个promise)。
- 步骤4:在这个线程中执行一些计算,然后通过set_value()方法将结果设置到promise中。
- 步骤5:在原来的线程中,通过future的get()方法获取结果。
示例代码:
cpp
#include <iostream>
#include <thread>
#include <future>
void compute(std::promise<int> prom) {
// 模拟一个耗时的计算
std::this_thread::sleep_for(std::chrono::seconds(1));
int result = 42;
prom.set_value(result); // 将结果设置到promise中
}
int main() {
std::promise<int> prom; // 步骤1:创建一个std::promise对象
std::future<int> fut = prom.get_future(); // 步骤2:获取对应的future
std::thread t(compute, std::move(prom)); // 步骤3:启动线程,并将promise移动给线程
// 步骤5:在主线程中通过future获取结果
int result = fut.get(); // 这会阻塞,直到compute线程设置了值
std::cout << "Result: " << result << std::endl;
t.join();
return 0;
}直接编译运行

等待1秒后
