文章目录
很高兴和大家见面,给生活加点impetus!!开启今天的编程之路
作者:٩( 'ω' )و260
我的专栏:Linux,C++进阶,C++初阶,数据结构初阶,题海探骊,c语言
欢迎点赞,关注!!

linux--Ext系列文件系统
理解硬件
理解硬件,首先需要理解磁盘,磁盘的物理结构,磁盘的存储结构。
首先先来背景知识,磁盘是外设,访问速度是很慢的。知道这些就大致差不多了。
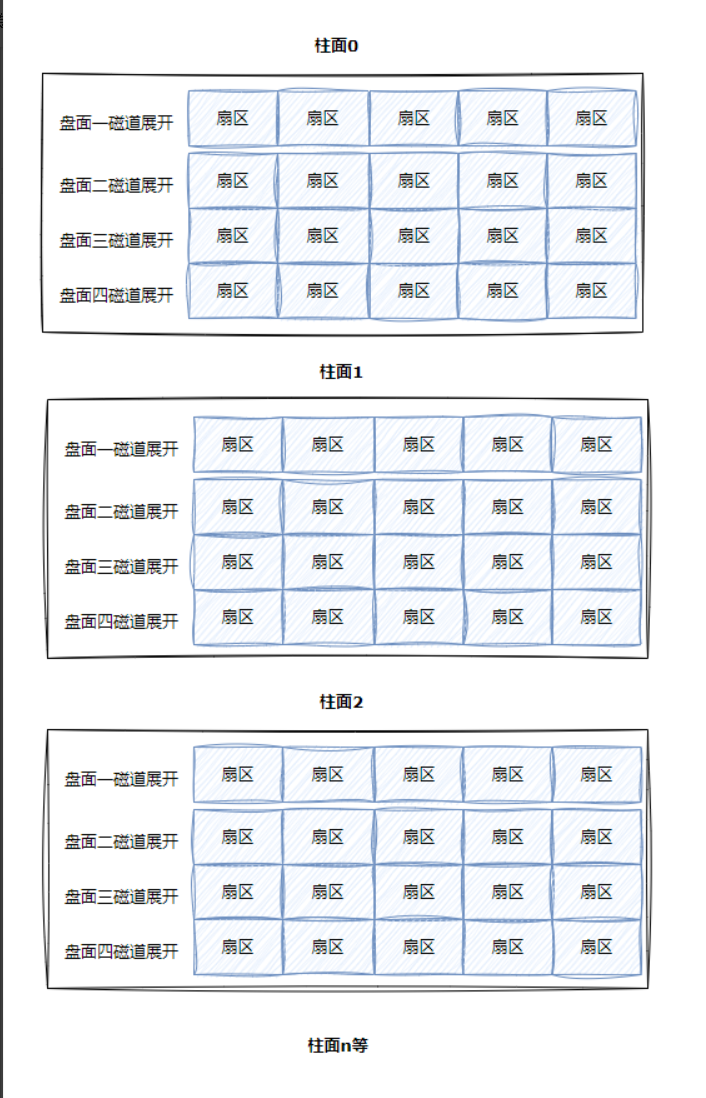
磁盘物理结构
磁盘的物理结构:包含盘片,磁头,主轴马达,磁头臂,永磁铁。

盘片包含正反面,即正反面都可以存储数据,每一个磁头都有编号,因为不同编号的磁头可以用来定位不同的盘片。
在每一个盘片上,包含不同半径的磁道,所有盘片上相同半径的磁道可以构成一个柱面:
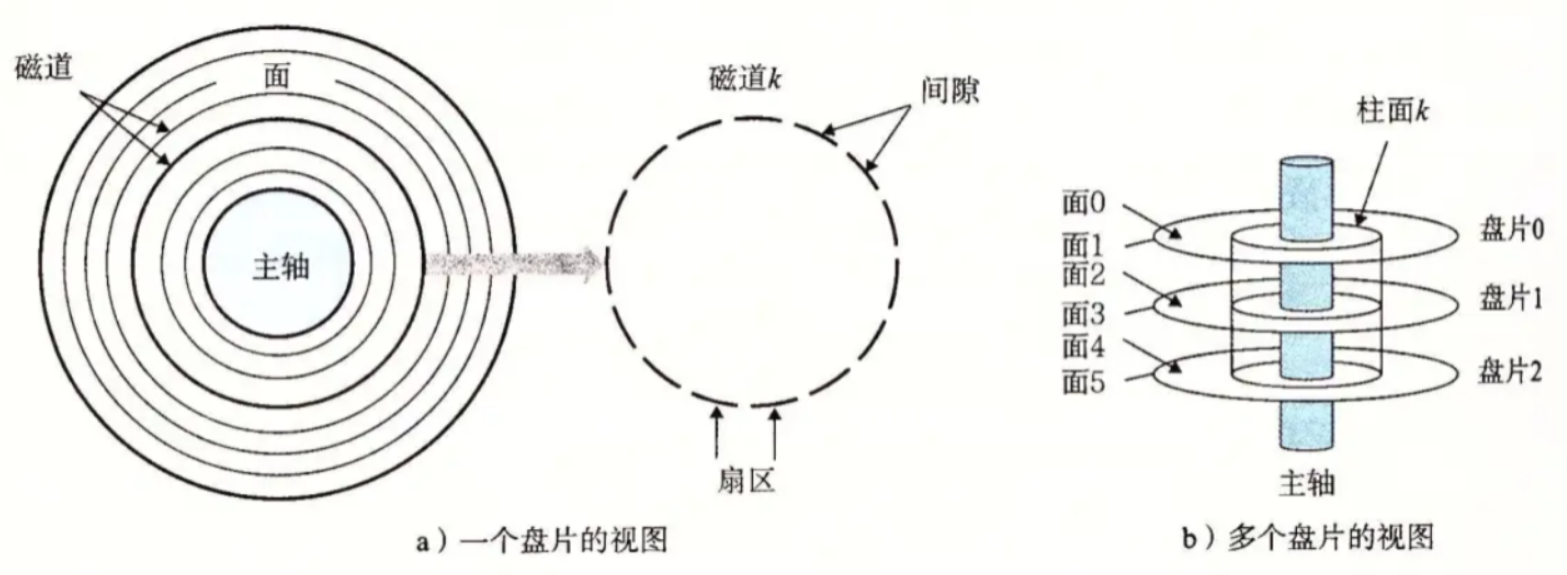
磁道有多少个,对应的柱面就有多少个,磁头来回摆动的作用就是定位不同的柱面。
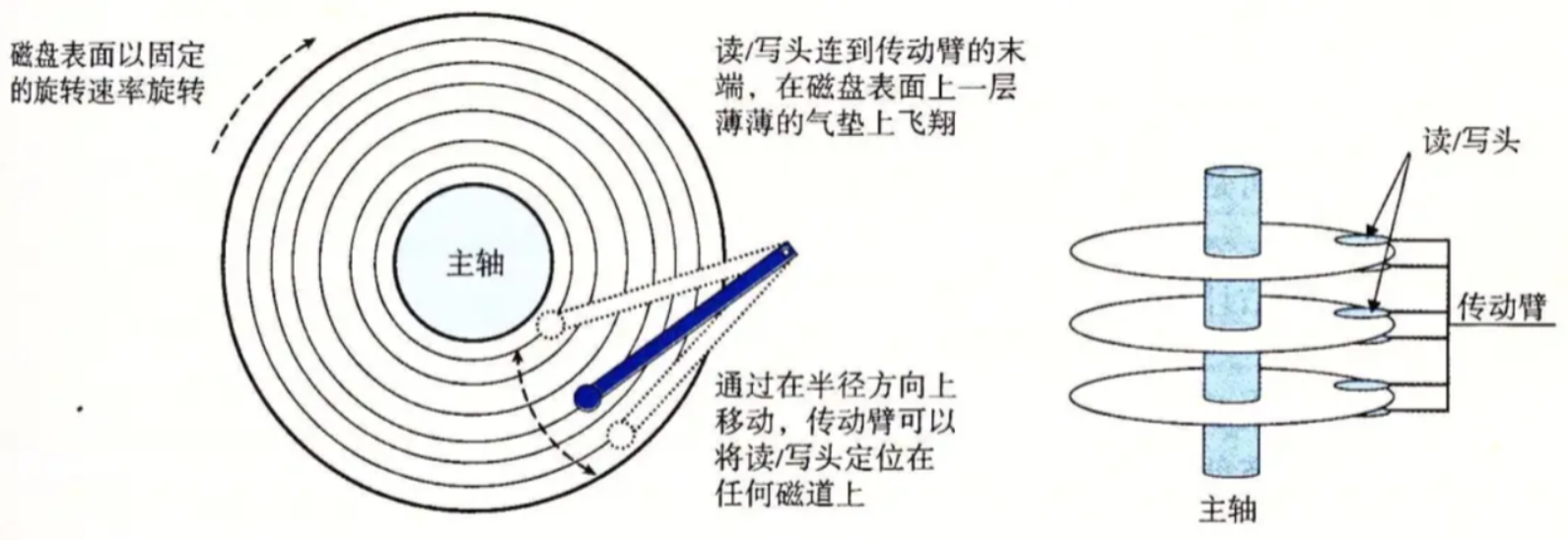
结论:传动臂摆动时,因为上面链接了所有磁头,即所有磁头同进退。
磁盘的存储结构:
为什么磁盘能够存储数据,因为磁盘上具有磁道,磁道上有对应的扇区,扇区能够来存储数据。
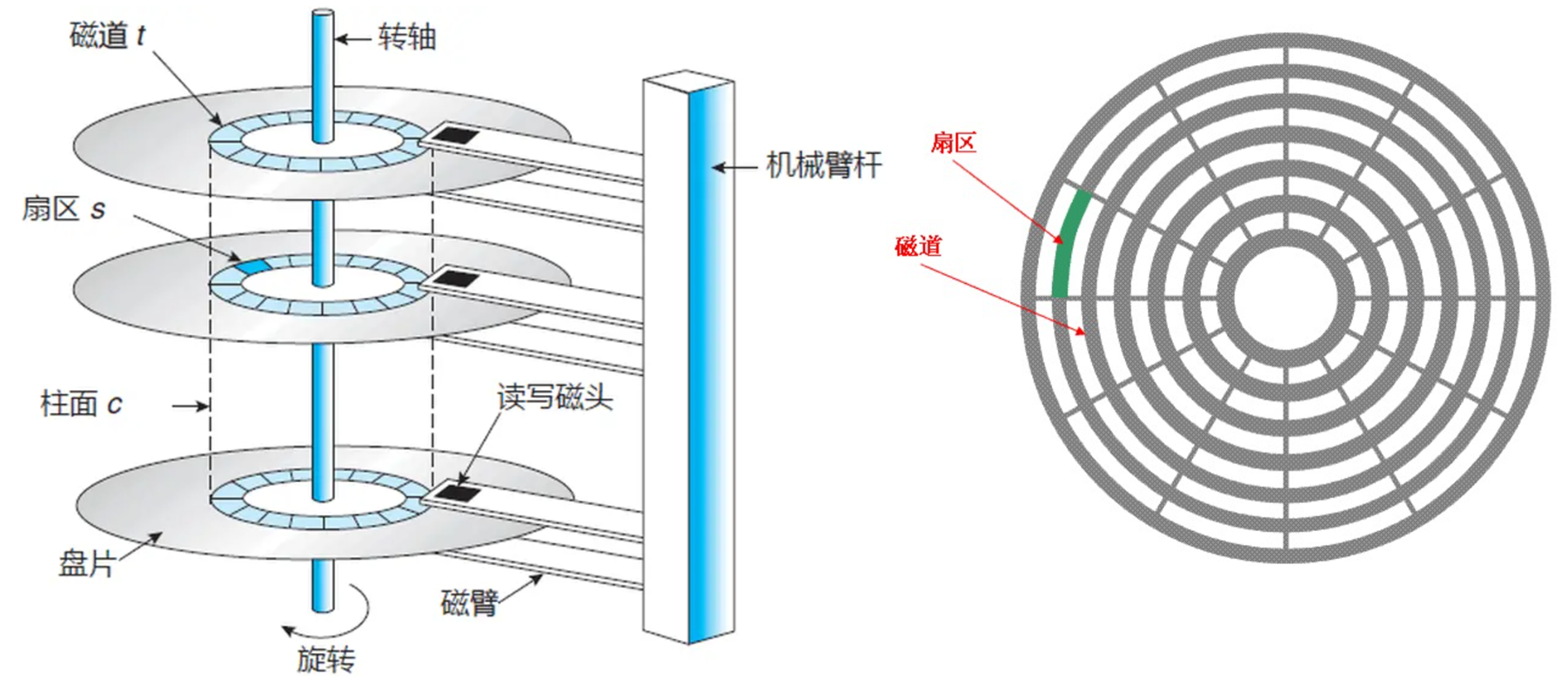
那么我们该如何在一个磁盘上定位一个扇区呢?
先定位柱面(cylinder)->随后再根据磁头(hand)编号定位一个磁道->随后再定位扇区(section)。这种定位方式叫做CHS。
既然机械硬盘能够存储数据,为什么随着时候更新,电脑上的硬盘换成了SSD呢?
机械硬盘因为磁头和盘片不能接触,注定了含机械硬件的电脑不能剧烈抖动,防止磁头刮花盘片。
那磁头是如何写数据的呢?
磁盘上是由无数个的小磁铁构成,每一个小磁铁有正负极,其实就是表示0/1,表示一个bit位,对每一个bit的修改对应到修改一个小磁铁的南北极即可。
IO读取数据时只能够读取以512字节的整数倍,即扇区的整数倍
我们可以使用指令来看看这个信息:fdisk -l
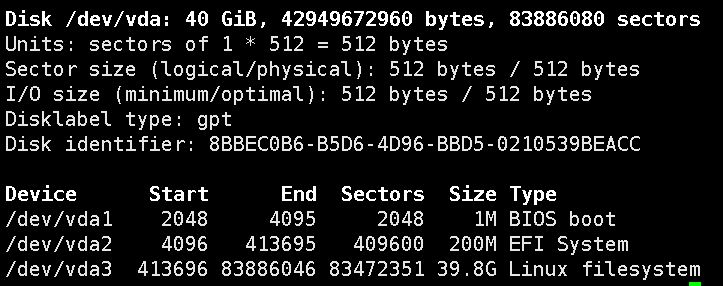
说明了远程的电脑配置是40G等等。服务器也是台电脑,只不过没有键盘和显示器
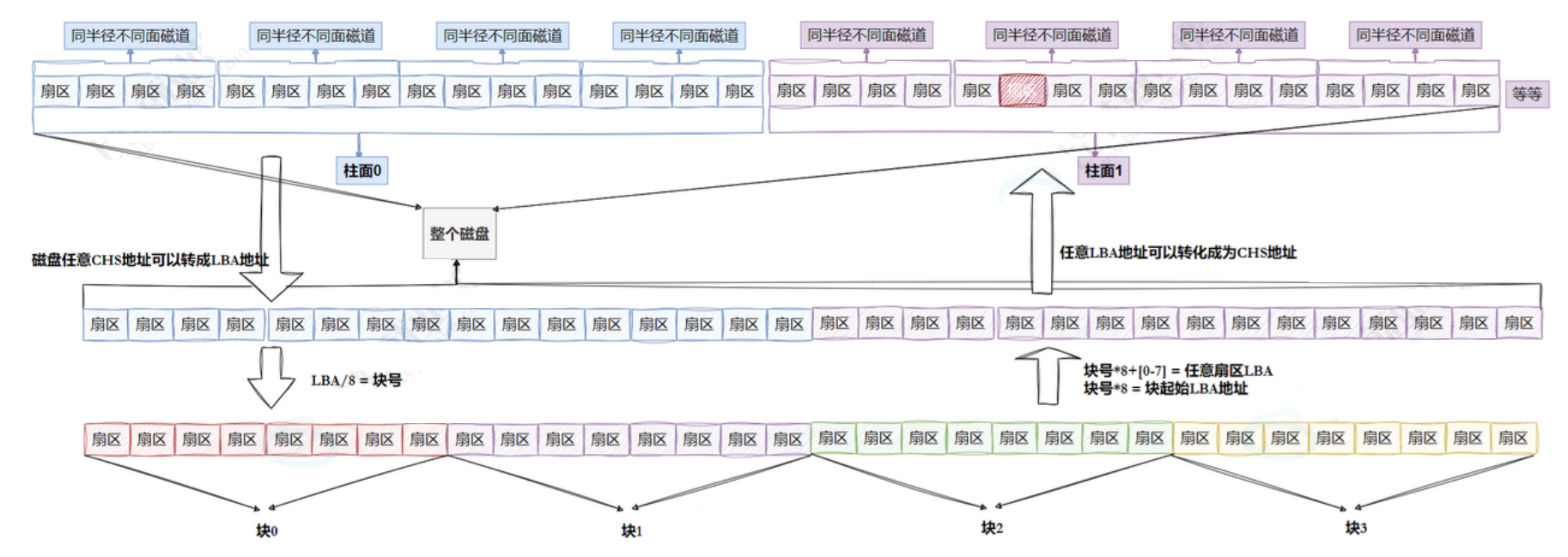
CHS & LBA
我们已经知道了CHS找到对应扇区,这种定位扇区的方式需要三个参数,柱面编号,磁道编号,扇区编号,即我们需要一个三维数组。即 dchs。
所以我们访问一个扇区的时候,利用三个参数访问这个数组即可。即CHS的本质就是在访问数组下标。
如果我们再抽象一点,在上层用户开辟的是三维数组,底层开辟的其实也是一维的,这个一维数组的元素就是一个扇区。一维数组的下标我们叫做LBA。
CHS与LBA的相互转换。其实就是三维与一维的转换。
CHS->LBA:三维转一维
公式:LBA = 柱⾯号C* 单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
最后为什么要减1呢?
因为扇区下标是从0开始计数的。
LBA->CHS:一维转三维,反过来就行了。
1:柱⾯号C = LBA / (磁头数每磁道扇区数) 就是单个柱⾯的扇区总数
2:磁头号H = (LBA % (磁头数 每磁道扇区数)) // 每磁道扇区数
第二个公式就是再求该LBA在该柱面上的偏移量,即是哪个磁道
3:扇区号S = (LBA % 每磁道扇区数) + 1
这个比较简单,这里不再过多讨论。
最后再来引出结论:
CHS与LBA的相互转换是由磁盘内置的算法完成的,当我们访问一个扇区时,只需给出LBA即可
磁盘是如何向指定扇区读写数据的?
在磁盘中包含伺服系统(控制器),其中包含寄存器,在寄存器中,存在存储w/r(读写类型),LBA,data,就能够对一个扇区完成数据读写
引入文件系统
块的概念
是什么?怎么做?
OS读写文件时不会只对一个扇区进行访问,而会同时访问一个块(8个扇区:512 * 8 = 4kb),同理:申请内存,文件加载到内存等操作都是以块为单位的。本质都是为了提高效率。能够一次性访问多个位置。
此时,转换关系就成了三维坐标< -- >一维坐标 < -- > 块坐标
为什么要有块的概念呢?
第一是为了提高效率(主要),第二是为了解耦合,OS与磁盘(软硬件)解耦合:因为扇区是512字节,8个即4kb,如果扇区大小改变,OSS访问的规格也会改变,解耦合之后,直接修改OS访问的算法即可。
分区
是什么?为什么有?
磁盘空间很大,OS难以对这么大的空间进行管理,所以将磁盘->若干块->若干组,将对磁盘这个大空间的管理就能够转换成对每一个组进行管理,如果能将每一个组管理得当,同样的,就能够将OS管理好。
怎么做?如何区分组?
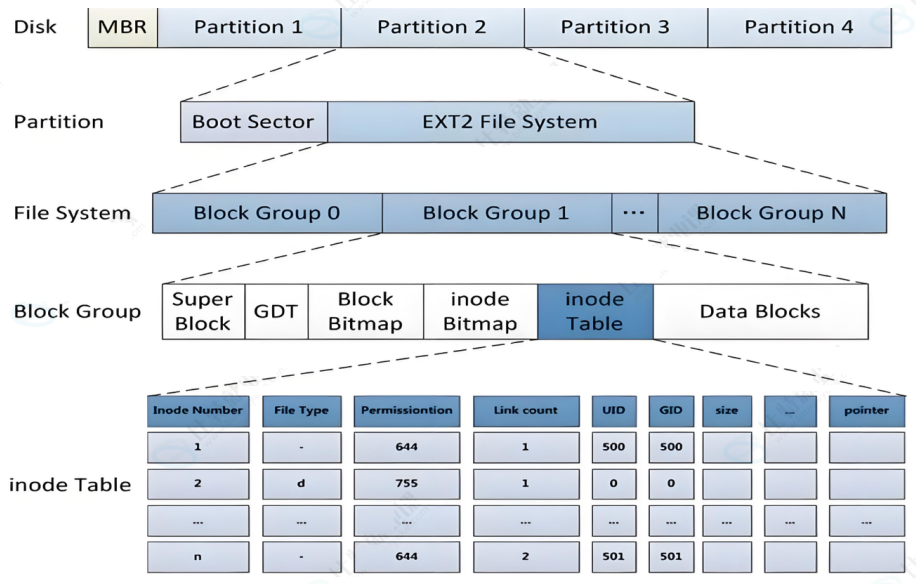
在每一个分组中,存储普通文件,包含管理信息和数据信息。
我们先引出一个innode的概念。
在用户上层,我们使用的是struct file描述已经被打开的文件,但在内核中,标识文件的唯一性使用的是innode,每一个文件都有自己的innode号,查看指令:ll -i。
数据信息:
1:innode Table:当文件被被创建时,磁盘上对文件进行描述(struct inode),该结构体中包含inode_number,知道了这个innode_number,我们就可以找到对应的文件,可以简单理解为innode_number为数组inode Table的下标。
内核描述文件为struct inode,上层我们描述打开文件的结构体struct file其实就是拷贝了struct innode中的部分结构体,但是拷贝的都是用户需要关心的,有关内核的属性并没有拷贝。
先来直接抛出一个结论:struct inode结构体通常是固定大小,一般是128字节或者是256字节,这个是如何保证的?
想要是inode是固定大小,只能保证该结构体内必须是固定长度的属性,即文件名不属于文件属性。因为文件名是变长的。即剔除了所有的变长属性
一个块是4096字节 == 4kb,一个文件为128字节,一个块可以存储32个inode,虽然一个块可以存储32个inode,但是加载时仍然是以块为单位加载的,当访问文件时拿需要的即可.
2:Data Block:用来存储文件的数据,存储数据的数据块肯定也是有编号的,这样才能够保证访问文件数据时直接在struct innode结构体中找数据块的编号即可。不然找不到
数据块编号存储在struct inode的i_block\[\]数组中。
什么时候数据块的编号确定了呢?
我们知道磁盘空间的大小,也知道每一个块石4kb,这样就能够算出块的数据有多少,
直接引出结论:文件 = innode编号(innode Table) + 内容(Data Block)。
知道了innode_number如何找到一个文件呢?
innode_number->innode->i_blocks\[\]->data Block。
管理信息:
为什么要有管理信息?磁盘中含有很多文件,有的刚创建,有的马上就要被销毁,所以这些文件肯定是需要被管理的,即先描述,再组织。而组织,使用的是位图的形式
inode_Bitmap:用来标记innode table的哪些位置已经被占用。
Block_BitMap:用来标记哪些编号的数据块已经被使用了
GDT:块组描述符表,统计块组描述符,多是描述组内概念,如块组起始位置,该块组内innode Table和data Block使用情况如何。
GDT表不是每个组内都有的,只有部分组有,防止数据丢失了,如导致某些组就无法使用了,找不到组的起始位置了。
super Block:表示分区的概念,描述分区的起始位置,使用情况等等情况。
既然是描述分区的,为什么不放在分区中而放到组中呢?
防止super Block区域受损,如果受损不修复,整个分区都将报废,分区大小大于组大小,影响更大,放在组中即使被损坏,能够修复,同时组大小小,影响也不大 -- 即备份
所以文件系统其实就是这些管理信息,初始化文件系统就是在加载这些管理信息,日常所说的格式化就是创建分区 + 分组 + 管理信息形成文件系统。
当我们删文件时,其实就是将位置由1->0,即使文件被删除,但是文件其实还是文件系统中,只要此时我们不新增任何文件,就能够保证该文件不会被覆盖。保证文件一直在!
理解创建/删除/修复/查看文件
创建文件:
1:从GDT表中找,找到空闲的innode位置,并将该位置bit位从0修改为1
2:创建并初始化innode对象,如初始化i_block\[\],如果是空文件,同理该数组也是空的
3:建立文件名与innode的关联,为什么要建立呢?因为innode对象是定长128字节,剔除了变长信息,如文件名。所以需要建立,所以路径 + 文件名具有唯一标识文件的作用,本质是innode唯一
4:修改管理信息,如innode Table等等
删除文件:
用户通过文件名访问文件,底层本质上是通过inode_number访问innode,找到inode中的数据块,同时修改管理信息即可。
修改/查看文件:
底层本质上通过innode_number访问inode,查看innode数据块的内容即可,修改会修改管理信息,看文件改大了还是改小了。
查看/修改时会将数据块加载到内存中,结束后重新刷新回磁盘中。
用户访问文件时,都是通过路径 + 文件名访问的,但是底层是通过innode唯一标识文件,且文件名不属于innode属性,那么是怎么通过文件名找到文件的呢?
在文件创建的第三点中其实也提及了。
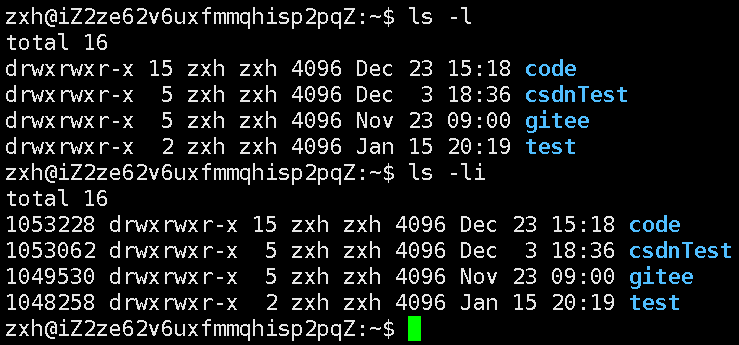
前面的如1053228该数字就是inode_number,inode是内核中唯一标识文件的,一般是不会暴露给上层的。
有一些细节问题:
从磁盘和文件系统角度看待普通文件和目录文件,其实上都是没有任何区别的
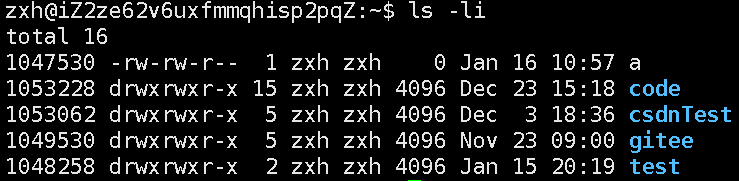
访问普通文件和目录文件都是通过inode_number来访问。而普通文件和目录文件的区分,因为是本身的属性,加载的时候就能够进行区分了。
复习目录的rwx权限问题:
缺少r,能够进入目录,但是无法访问目录内容
缺少w,无法创建目录和文件
缺少x:无法进入目录
重谈块号和inode编号
当我们靠inode_number找inode,难道不会找到其他组中相同inode_number编号的inode吗?
所以inode_number和块号并不是一个组中有效,而是整个分区内有效的。但是是不能跨分区的,即另一个分区肯定还会有相同的inode_number和块号。
而且,在一个分区内部,在文件系统中,如果一个分区的大小确定了,那么这个分区的inode_number和块号一定就确定了,因为每个块占4096字节(即4kb)。所以直接相除,inode_number和块号就确定了。
那么既然分区与分区独立,那么我该如果确定该文件是在哪个分区中呢?
这个主要是涉及分区挂载的内容。
前置知识
分区加载进入文件系统后(就是将管理信息加载入数据块之后),该分区能使用吗?
不能,必须需要挂载分区 -- 将分区挂在到目录中,当在目录中进行操作的时候,其实就是在对这个分区进行操作
先直接抛出结论:区分哪个分区,本质上是通过路径前缀来区分的且分区写⼊⽂件系统,⽆法直接使⽤,需要和指定的⽬录关联,进⾏挂载才能使⽤。
指令:df -h查看使用的分区
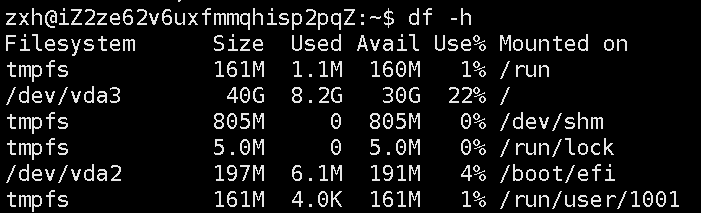
dev表示一个机械硬盘,其中挂载了两个vda3和vda2分区,vda3分区和我的根目录相关量,而vda2和我的/boot/efi目录关联。当我们在对应目录下进行操作时,就能够知道此时在对哪个分区进行操作。
那么分区和目录是如何进行匹配的呢?
是使用的就近原则匹配,按照路径最长原则进行匹配。
如:/home/zxh/test/bashtest/log.txt,现在除log.txt之前的目录在df -h有没有,否则就再找除了log.txt 和bashtest的路径在df -h中有没有,这样一次类推。
验证的话这里就不谈了。
其实在这里还有一点问题,倘若我们存储特别大的文件,一个分组就那么大,那么是如何存储大文件的呢?
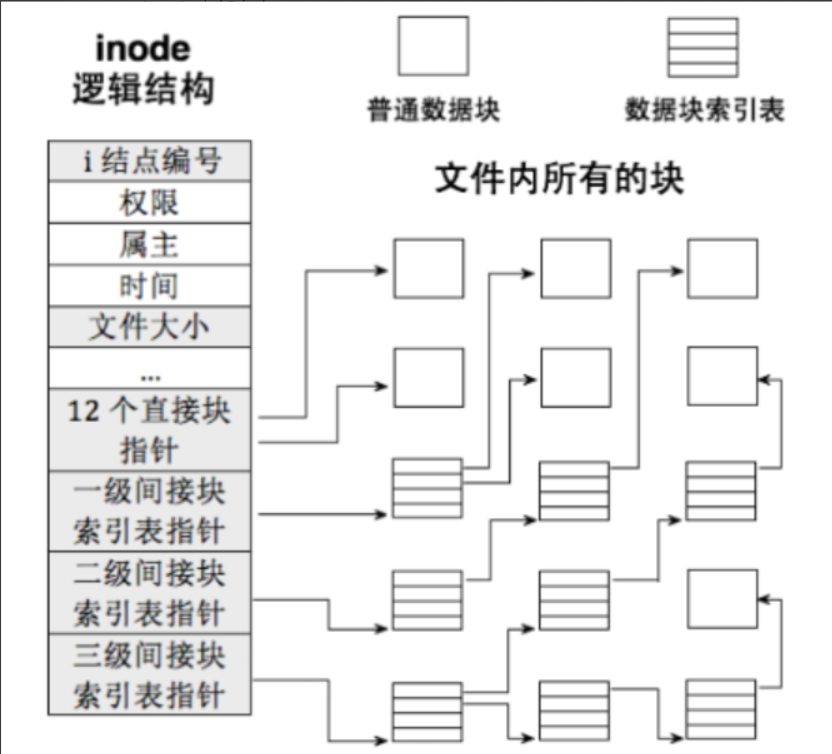
这里我们直接说明结论:inode中的存储数据块块号的i_block\[\]不仅能够存储单个块号,而且还能够存储间接块号
i_block\[\]总共15个空间固定,前12个空间存储单个块的块号,第13个是存储间接块的块号,而间接块其中存储的就是数据块的块号;第14个存储双重间接块的块号,双重间接块中存储间接块的块号;第15个存储三重间接块的块号,三重间接块中存储双重间接块的块号。这样就能够保证一个innode结构体中可以存储很大的文件。而且经过计算,这个大小是远超磁盘的总大小的!!
路径解析与路径缓存
直接来说明路径解析的过程
当我们需要访问一个文件,如test,需要知道一个test文件的inode_number,即需要知道文件名与inode编号之间的键值对关系。该关系被保存在目录d的数据块中,因为目录的内容就是普通文件或者目录嘛。
所以我们想要办法访问目录d的数据块内容,就需要知道目录d的inode_number编号,因为上面说了,磁盘和文件系统看待目录和普通文件时,都是一样的,都是通过inode_number进行访问的。目录d的inode_nubmer与文件名d的键值对信息作为内容保存在目录c的数据块中,即我们需要访问目录c的数据块内容,就需要找到目录c的inode_number,以此类推,直到推到根目录。而根目录的inode_number是系统启动时就会自动加载的。
在上面这套流程中,如果我一直访问test文件访问100次,难道就会这样给我解析100次吗?那效率未免也太低了,所以需要路径缓存!!
当我们访问一个innode_number所对应的文件时,会先去缓存中找,如果找到就会直接用,反之,就会边路径解析,边路径缓存。
当缓存中的内容一段时间没有被访问过,此时该缓存就是被释放。
那么缓存是有些刚被记录的,有些是马上就要被删除的,所以OS需要对缓存进行管理,怎么做呢?先描述,再组织。
描述结构体为struct dentry,而组织是使用树组织的。为什么是使用树组织呢?缓存是对目录文件进行缓存,目录和文件在linux中组成的一定是树形结构(linux最开始部分提及过).
所以struct dentry所形成的树一定是linux属性结构的子集!!!
联系struct file:
联系struct file:file中包含struct dentry*指针,file结构体可以通过dentry指针找到该文件(file描述的这个文件)的innode_number。
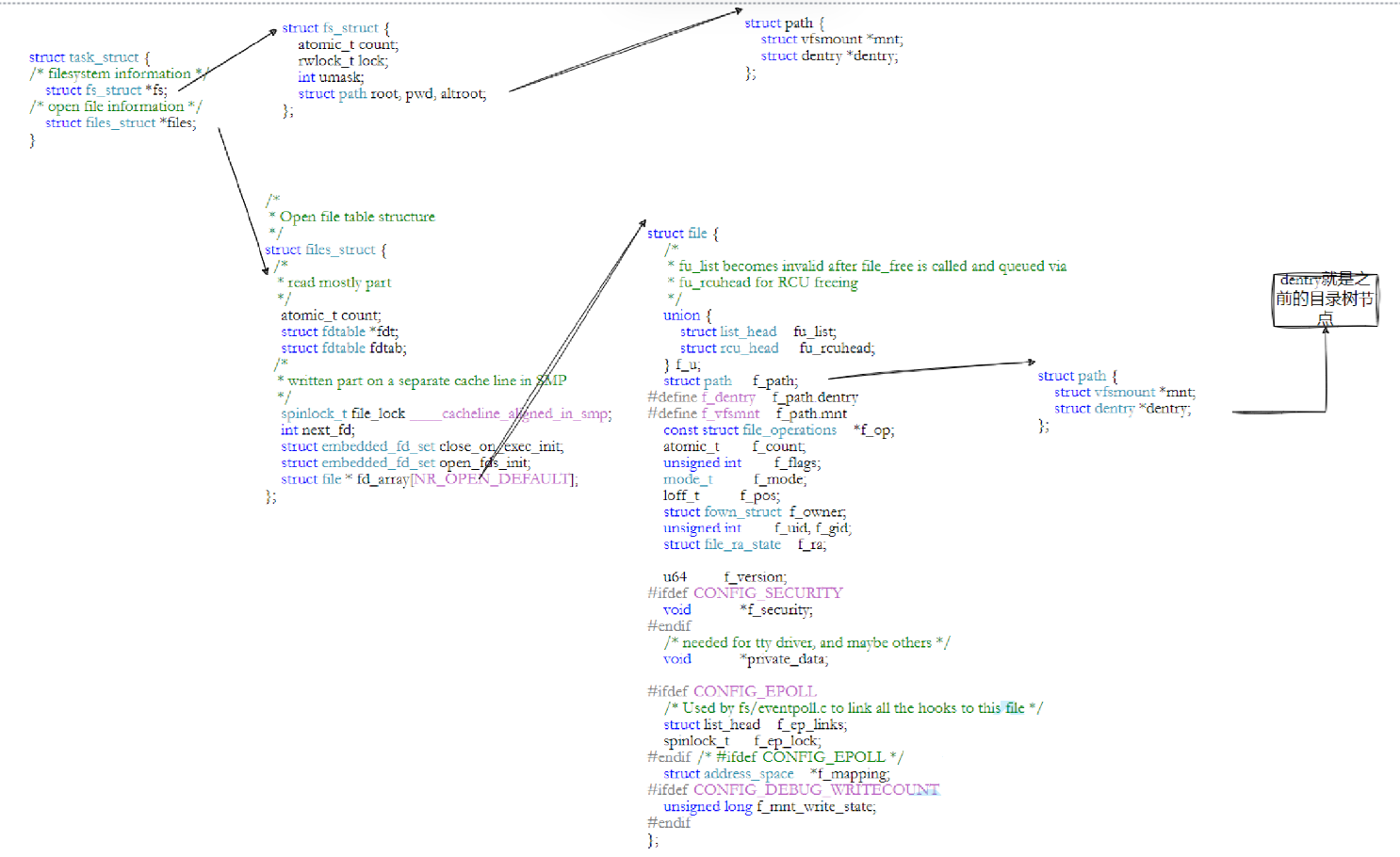
硬链接
我们先来使用指令,通过现象,来引出本质:
指令 ln 目标文件 硬链接文件名
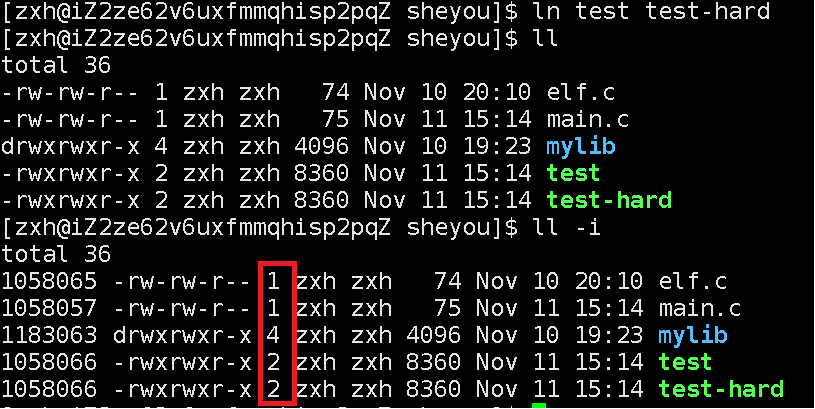
我们发现,目标文件与被硬链接的文件的innode_number是相同的。
即建立硬链接的本质其实就是在当前目录下新建一个文件(字符串)与目标文件的innode_number之间的映射关系。
那么为什么有硬链接呢?
通过建立硬链接,我们建立了一个与目标文件innode_number相同的文件,而且一个innode_number对应一个文件,即我们完成了一个文件的备份!!
从这里我们能够反推,当rm一个有硬链接关系的文件时,真的把该文件的bit位修改了吗?其实没有,这个类似于智能指针,当引用计数为0时,该结构体才会被释放,当一个文件的硬链接数为0时,该文件的bit才会被修改为0。
那么什么是硬链接数(图中红框)呢?
硬链接数就是统计有几个文件与该innode_number发生了映射。如图,该test文件硬链接数为2,因为有两个文件指向innode_number为1058066。
我们没有给目录建立硬链接,那为什么mylib有4个硬链接数呢?又有哪些文件指向mylib目录呢?
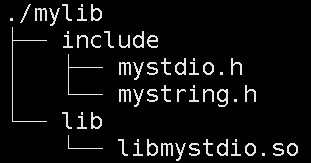
在我们之前学习cd命令时,学习了点表示当前路径,点点表示上一级路径。
那么当前路径,不就是XXX/mylib吗?mylib中的目录中的上一级路径,不就是XXX/mylib吗?
结论:点和点点就是目录的硬链接。
那么我们通过目录的硬链接数,就可以推断其中有几个目录了。
mylib中的目录中包含点,已经mylib本身,其余能够指向mylib的只能是mylib中目录中的点点,即目录中的目录个数 = 目录的硬链接数 - 2。
结论:硬链接有什么用?帮助备份文件 + 帮助理解以前学习过的知识。
再来看一个示例;
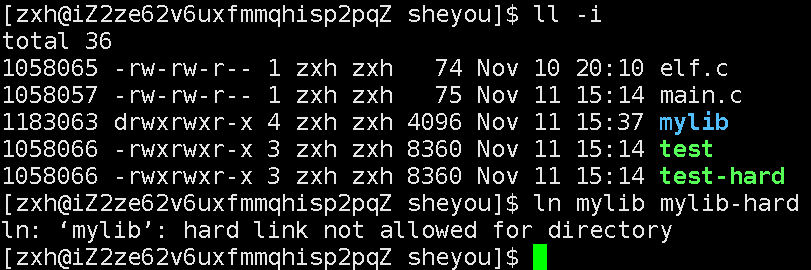
为什么不能给目录建立硬链接?
因为会导致环形路径的问题。如果我们建立了mylib-hard硬链接,如当我们访问/home/zxh/mylib/include/mylib-hard/xxx.txt路径的的某xxx.txt文件时,进行路径解析,当我们解析到mylib-hard,因为mylib-hard文件等于mylib文件,此时是不是相当于又是解析到mylib文件呢?
环形路径不可避免,即在linux下本身就具有环形路径,点不是当前路径吗,cd .不是进入当前路径吗?cd .不就是环形路径吗?因为路径一直没。
软链接
还是通过现象来观察:
指令:ln -s 目标文件 软连接文件名
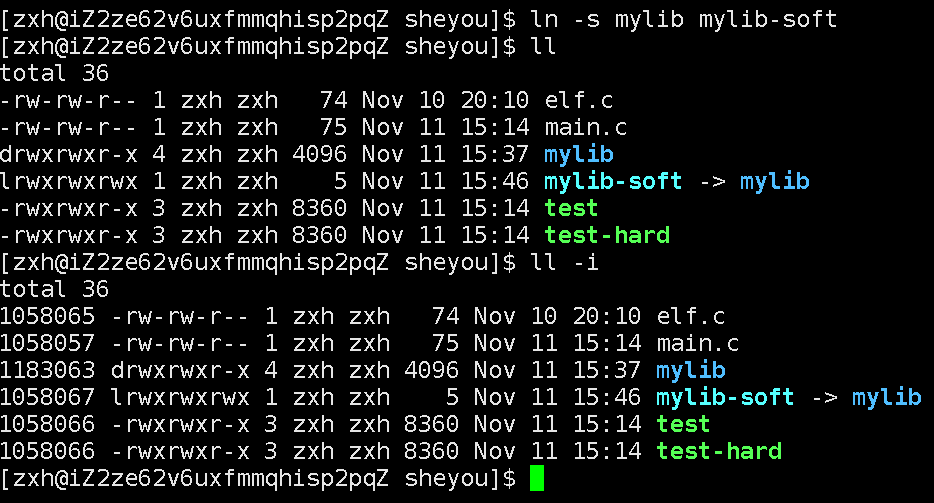
软链接是直接建立了一个独立的文件,因为innode_number和目标文件不同了。
同时该独立的文件也含有内容和属性,属性我们能看到,那么内容是什么呢?
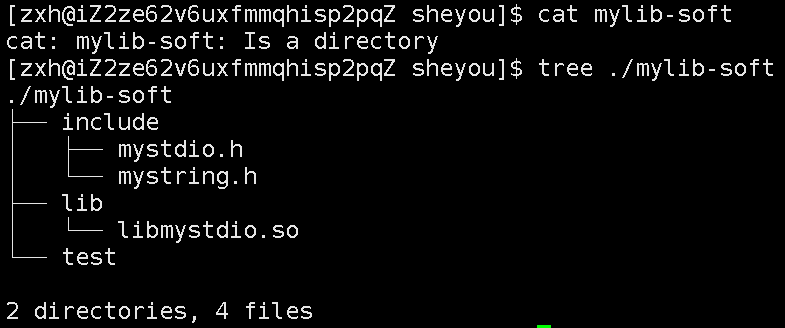
因为是目录,直接cat无法查看目录的内容,当tree时,发现直接查看到目标文件的内容了。即结论:软链接文件存储的是目标文件的文件路径 ,此时对软连接文件操作,就直接操作到了目标文件,因为能够通过软连接文件中的路径,找到目标文件。
而目标文件的路径也是字符串,也是数据,所以需要再数据块中存储
在linux下其实也有软连接,我们双击运行的程序,就是软连接,因为到文件中找exe文件很麻烦。
该快捷方式就是软连接。