RAG,全称Retrive Augment Generate,检索增强生成。大模型使用RAG技术主要原因在于其所使用的数据集的不完全,比如数据集的非即时性、缺乏专业领域数据等等。
RAG的一个典型应用场景是销售领域。例如我们现在部署某模型(如7B Qwen)需要租赁算卡,现在分别问deepseek和腾讯云端的ai助手,让其推荐配置,结果如下:
deepseek输出:

腾讯云AI输出:

腾讯云AI助手的输出是参考了自己的知识库的,甚至可以看到其知识库的内容,而deepseek输出只参考公开的数据。
RAG整体流程如下:
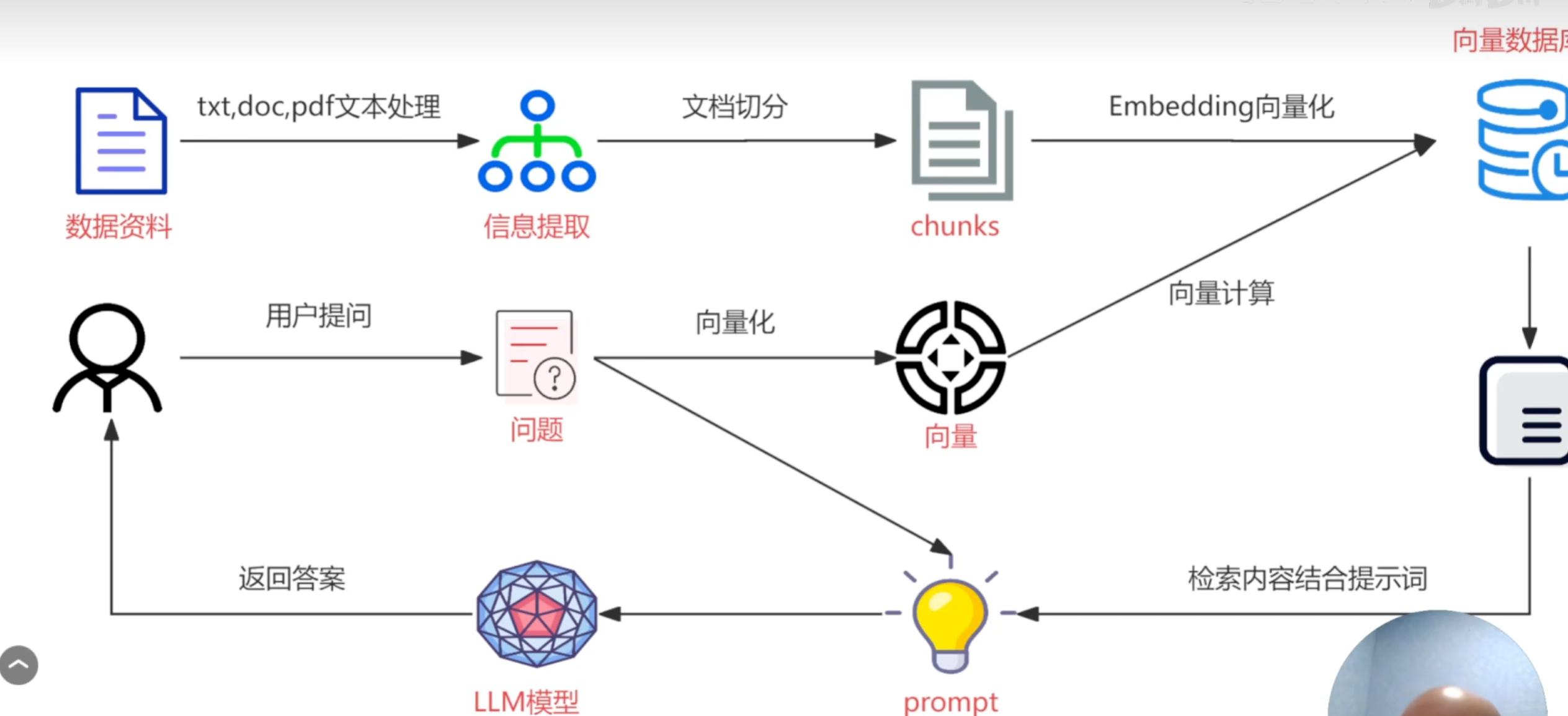
实现RAG的第一步是需要输入一个知识库,知识库有多种形式,如word、pdf、md等等。在输入知识库之后,需要对知识库进行预处理。如现在需要向大模型提问金融法相关问题,知识库是一本完整的刑法,显然只需要把刑法中和金融法相关的内容截取出来作为知识库即可。
对知识库进行预处理之后,接着对其进行切片,因为1.大模型无法一次性读取太大的文件2.完整的文档处理起来较为繁琐。
切片效果如下:
切片前:

切片后:

可以看到文章被切分成了一个一个的page_content。
切片完成后,对输入的知识库通过嵌入模型进行Embedding向量化
举例,如对于词语"西红柿",经过嵌入模型Embedding之后可以转化为一个768维的列向量,但这样得到的向量维度过高,难以处理,可以使用降为算法将其降为二维。

对一百个汉语词语使用嵌入模型进行embedding之后,再将其降为二维,可以得到100个点(100个二维向量)
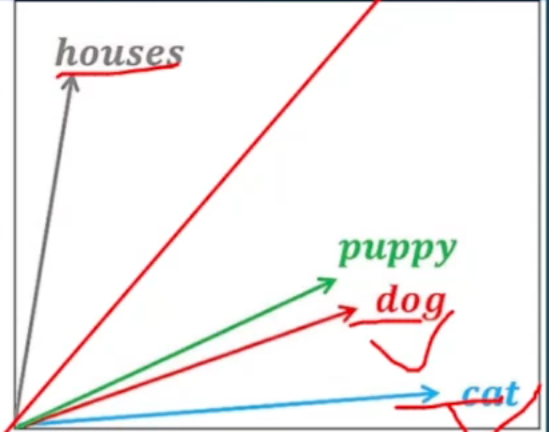
经过embedding处理过后的词语会具备一些特征:
1.可分性。不同意义词语的向量具有明显的区分(如一个动词,一个名词,其对应向量的几何距离会很远,图中的例子是houses和dog,一个是房子,一个是宠物,其向量的距离较远)
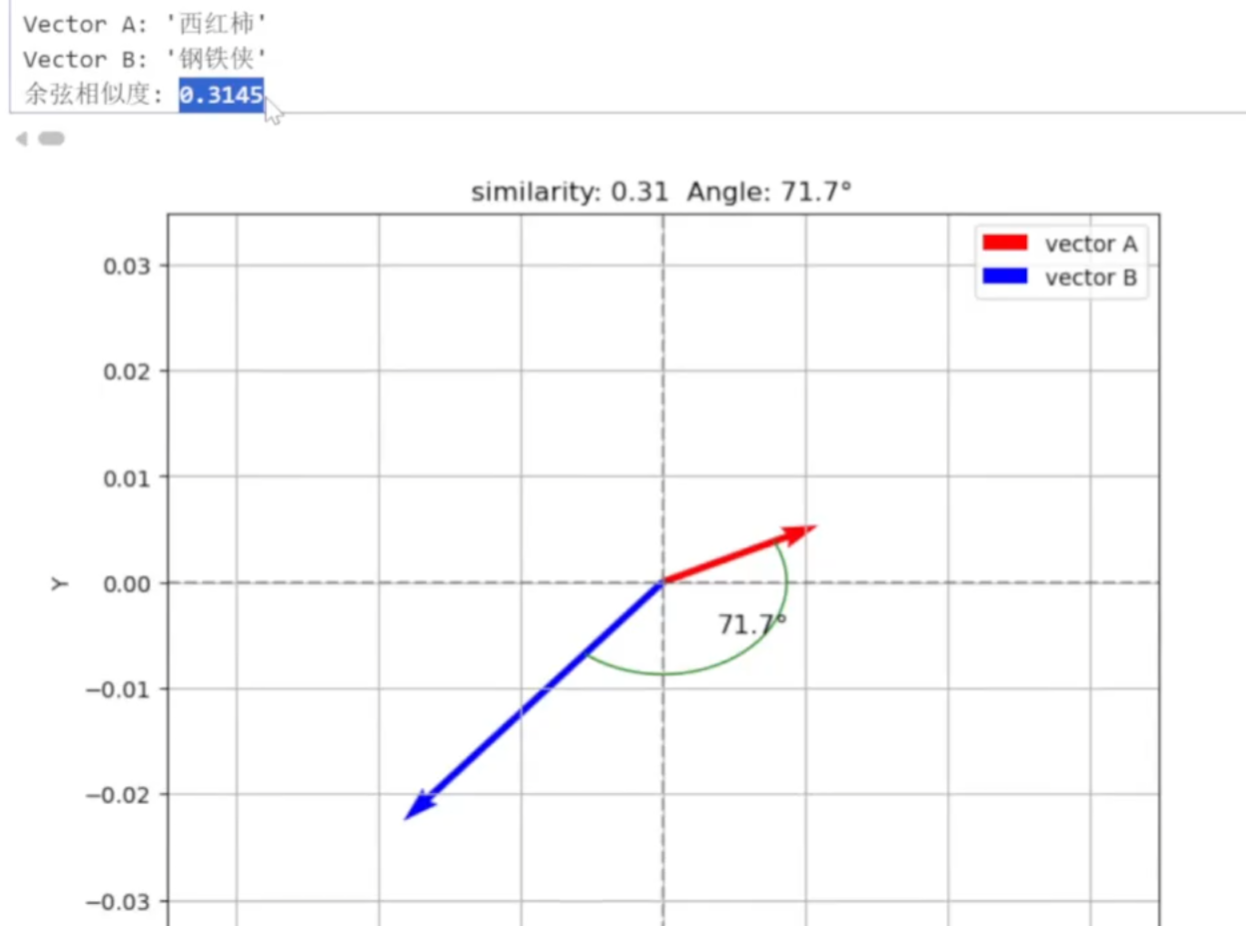
2.可解释性。可以计算出两个向量的语义相似度
如词语西红柿和钢铁侠,其语义相对较远,用余弦相似度描述他们的相似度也较小。
3.可推理性。被嵌入模型向量化的词语之间将展现出一定的可推理性,如对一个词语的语义进行拓展解释,国王:即男人+王
知识库被嵌入模型转化成向量后,将被存入到向量数据库。
用户提出的问题同样会被嵌入模型转化成向量,但并不存入到向量数据库中,而是通过计算相似度,在数据库中找到和问题向量最相似的向量,并将向量对应的文本输入给大模型,大模型根据其生成答案。
生成答案之后,将会有对应的指标来评估生成的答案的合理性

如上图,用户问题:张三抢劫获得十万元,将受到什么判罚?
回答:处三年以上十年以下有期徒刑,并处罚金
之后的是对应的几个指标
context_precision: 上下文精确度。在问llm问题之后,将会返回Top-k个文档。如Top-k=5,但假如只有3个文档块和问题相关,那么上下文精确度就是3/5=0.6。对上下文精确度的要求一般在90%以上。
提高上下文精确度的方法有:1.对知识库更精细的清洗,排除无关知识2.将llm返回的文档块重排序,把最相似的放在最上面3.更换嵌入模型
**context_recall:**上下文召回率。Top-k=5,召回的文档中只有3个和问题相关,向量库中一共有4个向量(或其对应的文档块)和问题相关,则上下文召回率为3/4=0.75。
提高召回率的方法:多样化的检索策略。比如文档块中有一个pdf文件,直接用问题向量检索较为困难。可以对pdf的内容做一个摘要,摘要对应的向量映射到pdf对应的向量,提问时可以用问题向量来和摘要向量做相似度检索
**faithfulness:**忠实度。忠实度考查的是大模型的答案是否是基于知识库回答的,如果忠实度低,则对应大模型的幻觉率高。解决幻觉率可以通过提示词来禁止大模型进行编造,或者通过显示引用要求大模型给出对应的知识库
**answer_relevancy:**问题和答案的相关度。该指标主要来判断大模型的答案是否足够简洁。