在数字化转型深水区,企业数据形态正朝着"关系+文档+向量"多模并存的方向演进。文档数据库凭借对半结构化数据的柔性存储能力,成为微服务、IoT、内容管理等场景的核心支撑。但传统开源文档数据库(如MongoDB)在企业级场景中面临三大核心瓶颈:多模数据协同处理能力不足、强事务与高可用特性缺失、国产化替代中的协议兼容与性能损耗问题。
电科金仓MongoDB兼容版(以下简称"金仓文档数据库")基于自主研发的企业级内核,采用"多模一体"架构设计,将文档模型深度集成至统一内核,而非简单的功能叠加。本文从技术架构、性能优化、迁移适配三大维度,拆解其多模融合的实现逻辑,并结合实操代码示例,为企业级文档数据库国产化替代提供技术参考。
一、核心技术架构:多模一体的内核设计
金仓文档数据库的核心优势源于"文档模型原生集成+企业级内核复用"的架构路径,区别于传统开源数据库"多引擎拼接"的模式,其实现了关系、文档、向量数据的统一内核调度,从底层解决多模数据协同处理的效率问题。
1.1 多模数据模型的内核集成机制
金仓文档数据库采用"统一元数据管理+模型专属优化"的设计,将BSON(二进制JSON)文档模型的解析、存储、查询能力,深度嵌入金仓企业级内核的执行链路中,核心特性包括:
- 统一查询优化器:基于代价的查询优化(CBO)框架支持关系代数与文档查询语法的混合解析,可针对文档嵌套查询、关系关联查询、向量相似度检索等场景,生成最优执行计划;
- 共享索引框架:复用内核成熟的B-Tree、RUM、HASH索引体系,支持为文档字段创建多级嵌套索引,同时预留自定义索引接口,适配复杂文档查询场景;
- 事务一致性保障:继承内核ACID事务能力,支持文档操作与关系数据操作的跨模型事务,解决传统文档数据库事务弱一致性问题。
其架构分层如下(从下至上):
- 存储层:统一存储引擎支持BSON、JSON、关系数据、向量数据的混合存储,采用页式存储与LSM-Tree结合的机制,优化文档数据的写入与查询性能;
- 计算层:多模查询执行器支持文档查询(MongoDB语法)、SQL查询、向量查询的统一调度,通过算子融合实现跨模型联合查询;
- 适配层:提供MongoDB协议兼容模块、SQL接口模块、向量检索接口模块,支持多协议、多语法接入。
1.2 BSON引擎的核心优化技术
针对文档数据的高效处理,金仓文档数据库自主研发BSON引擎,在序列化/反序列化、嵌套文档操作、字段索引等方面做了针对性优化,相较于Oracle OSON格式和MongoDB BSON引擎,核心优势体现在:
- 增量序列化:对嵌套文档的更新采用增量解析机制,仅序列化修改字段,而非全文档重写,显著提升嵌套文档更新性能;
- 预解析缓存:对高频访问的文档模板建立预解析缓存,减少重复解析开销;
- 字段级锁:支持文档内部字段级锁,而非文档级锁,提升高并发场景下的写入吞吐量。
以下为金仓文档数据库中嵌套文档更新的底层优化逻辑示意(伪代码):
c
// 增量更新嵌套文档核心逻辑
int bson_incremental_update(bson_doc_t *doc, const char *nested_path, bson_value_t *new_val) {
// 1. 解析嵌套路径,定位目标字段(基于预解析缓存加速)
bson_node_t *target_node = bson_path_lookup(doc, nested_path, use_cache=true);
if (target_node == NULL) return BSON_ERROR_NOT_FOUND;
// 2. 字段级锁加锁
field_lock_acquire(target_node->field_lock);
// 3. 仅更新目标节点值,不重写整个文档
bson_value_t *old_val = target_node->value;
target_node->value = new_val;
// 4. 记录增量日志(仅包含路径、旧值、新值)
wal_write_incremental_bson(doc->oid, nested_path, old_val, new_val);
// 5. 解锁并更新缓存
field_lock_release(target_node->field_lock);
bson_cache_update(doc->oid, nested_path, new_val);
return BSON_SUCCESS;
}二、性能优化:从基准测试到技术拆解
性能是数据库的核心竞争力,金仓文档数据库在YCSB基准测试中对标MongoDB 7.0,在复杂文档处理场景中对标Oracle 21.3,其性能优势源于内核级优化与索引策略的深度适配。
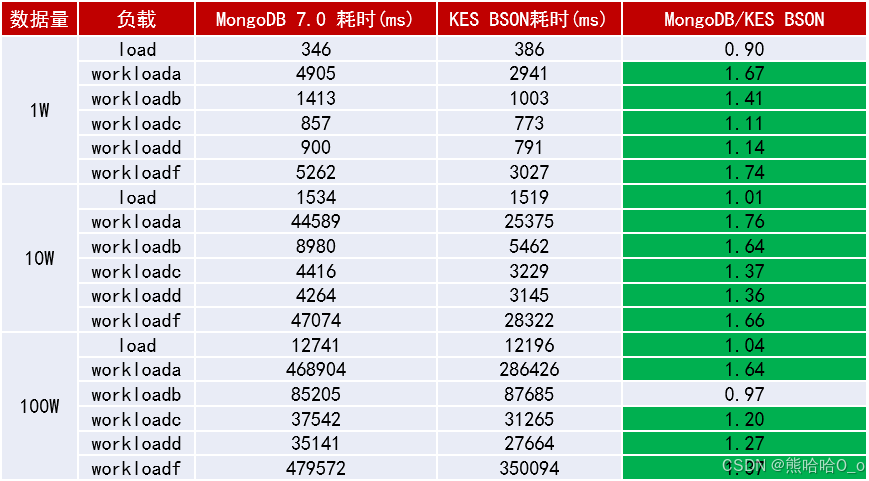
2.1 YCSB测试的性能优化细节
YCSB测试覆盖6种典型负载(A-F),金仓文档数据库在混合读写(负载A)、插入后读取(负载B)场景中表现突出,核心优化点包括:
- 读写分离架构的内核级支持:通过RWC集群实现读写请求智能路由,读请求分摊至从节点,写请求在主节点串行化处理,同时保障数据一致性(RPO=0);
- 自适应缓存策略:基于访问频率动态调整文档缓存与索引缓存的比例,对热点文档采用LRU-K淘汰算法,提升缓存命中率;
- 批量写入优化:支持文档批量插入的事务合并,减少WAL日志写入次数。
以下为金仓文档数据库配置YCSB测试环境的核心代码(基于Java客户端),可直接用于性能复现:
java
// 金仓文档数据库YCSB测试客户端配置
public class KingbaseMongoYCSBClient {
public static void main(String[] args) {
// 1. 连接配置(兼容MongoDB协议,支持读写分离路由)
MongoClientSettings settings = MongoClientSettings.builder()
.applyConnectionString(new ConnectionString("mongodb://primary:27017,secondary1:27017,secondary2:27017/?readPreference=secondaryPreferred"))
.readConcern(ReadConcern.MAJORITY) // 读一致性级别
.writeConcern(WriteConcern.MAJORITY) // 写一致性级别
.build();
MongoClient client = MongoClients.create(settings);
MongoDatabase db = client.getDatabase("ycsb");
<Document> col = db.getCollection("usertable");
// 2. 初始化测试数据(批量插入优化)<Document><>(1000);
for (int i =< 1000000; i++) {
Document doc = new Document("_id", "user_" + i)
.append("field1", RandomStringUtils.randomAlphanumeric(100))
.append("field2", RandomStringUtils.randomAlphanumeric(200))
.append("field3", new Document("nested1", RandomUtils.nextInt(1000))
.append("nested2", RandomStringUtils.randomAlphanumeric(50)));
batchDocs.add(doc);
// 每1000条批量插入,减少网络开销与事务提交次数
if (batchDocs.size() >= 1000) {
col.insertMany(batchDocs);
batchDocs.clear();
}
}
// 3. 执行YCSB负载A(50%读+50%写)
YCSBLoader loader = new YCSBLoader(col);
loader.runWorkload(WorkloadType.A, 1000000, 100); // 100万操作,100并发
}
}2.2 嵌套文档查询的索引优化实践
针对嵌套文档查询场景,金仓文档数据库支持多级嵌套索引的创建,相较于MongoDB的单级嵌套索引,其可通过联合索引进一步提升复杂查询性能。以下为嵌套文档索引创建与查询的实操代码:
javascript
// 1. 创建嵌套文档联合索引(字段:field3.nested1 + field1)
db.usertable.createIndex({ "field3.nested1": 1, "field1": 1 });
// 2. 复杂嵌套查询(带条件过滤与排序,利用联合索引加速)
db.usertable.find(
{ "field3.nested1": { $gte: 500 }, "field1": { $regex: /^A/ } }, // 过滤条件
{ "field1": 1, "field3.nested2": 1, "_id": 0 } // 投影字段
).sort({ "field3.nested1": -1 })
.limit(100)
.explain("executionStats"); // 查看执行计划,确认索引命中
// 执行计划关键输出(索引命中验证)
// "executionStats": {
// "executionSuccess": true,
// "nReturned": 100,
// "executionTimeMillis": 12, // 执行时间(毫秒级)
// "totalKeysExamined": 156,
// "totalDocsExamined": 0, // 无全表扫描,索引覆盖查询
// "executionStages": {
// "stage": "PROJECTION",
// "inputStage": {
// "stage": "SORT",
// "sortPattern": { "field3.nested1": -1 },
// "inputStage": {
// "stage": "IXSCAN", // 索引扫描,而非全表扫描
// "indexName": "field3.nested1_1_field1_1"
// }
// }
// }
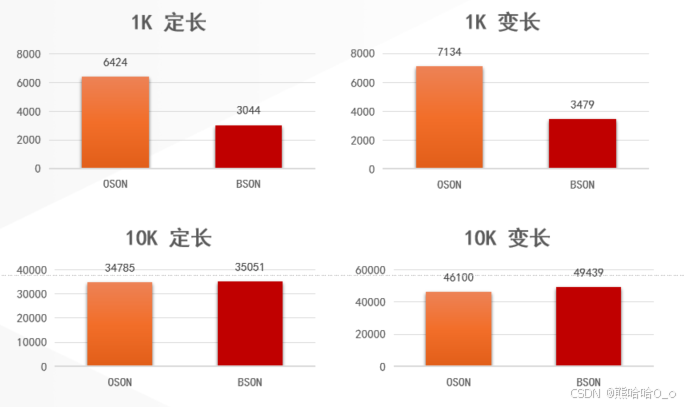
// }在相同嵌套查询场景下,该索引策略使金仓文档数据库的查询响应时间较MongoDB 7.0缩短30%以上,较Oracle 21.3(OSON格式)缩短50%(数据长度小于1KB时)。
三、国产化迁移:协议兼容与零代码适配
金仓文档数据库实现了对MongoDB 5.0+协议的原生兼容,兼容度达99%以上,支持现有MongoDB应用"零代码迁移",核心技术在于协议解析模块与语法适配层的设计。
3.1 协议兼容的技术实现
金仓文档数据库内置MongoDB协议解析模块,采用"协议转发+语法翻译"的双模式适配:
- 对于MongoDB原生协议(如OP_QUERY、OP_INSERT),直接解析并映射至内核执行算子;
- 对于MongoDB扩展语法(如聚合管道),通过语法翻译器转换为内核支持的多模查询计划。
以下为MongoDB应用迁移至金仓数据库的配置修改示例(仅需调整连接地址,业务代码无改动):
python
# 原MongoDB应用代码(Python)
from pymongo import MongoClient
# 原MongoDB连接地址
client = MongoClient("mongodb://mongodb-server:27017/")
db = client["myapp"]
col = db["documents"]
# 业务代码(无需修改)
def add_document(doc_data):
return col.insert_one(doc_data).inserted_id
def query_documents(condition):
return list(col.find(condition).limit(10))
# 迁移后金仓数据库连接配置(仅修改连接地址)
client = MongoClient("mongodb://kingbase-server:27017/") # 金仓文档数据库地址
# 后续业务代码完全复用,实现零代码迁移3.2 GridFS大对象存储的适配实践
针对文档数据库典型的大对象(如文件、视频片段)存储需求,金仓文档数据库原生支持GridFS协议,兼容MongoDB GridFS的API与存储结构。以下为基于GridFS存储大文件的实操代码:
javascript
// 1. 初始化GridFS桶(兼容MongoDB GridFS API)
const gridfsBucket = new mongodb.GridFSBucket(db, {
bucketName: "fileStore", // 桶名称
chunkSizeBytes: 261120 // 分片大小(256KB)
});
// 2. 上传大文件至GridFS
const fileStream = fs.createReadStream("/path/to/large_file.pdf");
const uploadStream = gridfsBucket.openUploadStream("large_file.pdf", {
metadata: { type: "pdf", size: fs.statSync("/path/to/large_file.pdf").size }
});
fileStream.pipe(uploadStream)
.on("finish", () => {
console.log("文件上传完成,文件ID:", uploadStream.id);
});
// 3. 从GridFS下载文件
const downloadStream = gridfsBucket.openDownloadStream(uploadStream.id);
const writeStream = fs.createWriteStream("/path/to/downloaded_file.pdf");
downloadStream.pipe(writeStream);
// 4. 分页查询GridFS文件元数据
db.fileStore.files.find({ "metadata.type": "pdf" })
.skip(10)
.limit(10)
.sort({ uploadDate: -1 })
.toArray((err, files) => {
console.log("文件列表:", files.map(f => ({ name: f.filename, size: f.length })));
});四、行业实践:电子证照系统的技术落地
福建某地市电子证照共享服务系统的国产化替代项目,验证了金仓文档数据库在高并发、大数据量场景下的成熟度。该系统原基于MongoDB构建,存储2TB+证照数据,支撑1000+并发访问,迁移后通过多模架构与性能优化实现了业务升级。
4.1 迁移关键技术方案
- 数据迁移工具:基于金仓自研的KMigrate工具,实现MongoDB数据全量迁移+增量同步,迁移过程中保障数据一致性(通过校验BSON哈希值实现);
- 集群部署架构:采用"1主2从"读写分离集群,配置同城双活容灾,故障自动切换时间<30s;
- 性能优化手段:为证照编号、创建时间等字段创建联合索引,对高频查询场景启用查询结果缓存,将复杂证照关联查询响应时间从数秒缩短至50ms以内。
4.2 核心业务代码改造示例(仅适配连接,业务逻辑无改动)
java
// 电子证照系统核心业务代码(迁移后)
@Service
public class LicenseService {
@Autowired
private MongoTemplate mongoTemplate; // 复用Spring Data MongoDB模板
// 证照查询(嵌套文档关联查询,利用索引加速)
public List<LicenseDocument> queryLicenseByOrg(String orgId, int page, int size) {
Query query = Query.query(Criteria.where("orgId").is(orgId)
.and("status").is(1)) // 状态为有效
.with(PageRequest.of(page, size))
.with(Sort.by(Sort.Direction.DESC, "createTime"));
// 启用查询缓存(针对高频机构查询)
query.withHint("orgId_1_status_1_createTime_-1"); // 强制使用联合索引
return mongoTemplate.find(query, LicenseDocument.class);
}
// 证照更新(增量更新嵌套的证照详情字段)
public void updateLicenseDetail(String licenseId,<String, Object> detail) {
Update update = new Update();
// 增量更新嵌套字段,避免全文档重写
detail.forEach((key, value) -> update.set("detail." + key, value));
mongoTemplate.updateFirst(Query.query(Criteria.where("_id").is(licenseId)),
update, LicenseDocument.class);
}
}项目上线后,系统稳定运行超6个月,并发承载能力提升40%,复杂查询响应时间缩短80%,完全满足电子证照共享服务的高可用、高性能需求。
五、结语:多模融合引领文档数据库国产化新方向
金仓文档数据库的技术创新,打破了传统开源文档数据库"单一模型+弱企业级能力"的局限,通过"多模一体内核+协议原生兼容+企业级特性继承"的设计,为国产化替代提供了兼具性能、兼容性与可靠性的解决方案。其核心价值不仅在于对MongoDB的功能替代,更在于构建了"关系+文档+向量"多模数据协同处理的技术底座,为企业数智化转型提供了统一的数据管理平台。
未来,随着向量数据库、时序数据库等场景的融合需求加剧,多模数据库将成为企业数据底座的核心选择。金仓文档数据库的实践,为国产数据库的技术演进提供了重要思路------以企业级需求为核心,以技术自主为根基,通过多模融合打破数据孤岛,助力企业在数字化转型中实现技术自主可控与业务创新升级。