本推文介绍的是CIKM 2025收录的一篇论文《Mixture of Semantic and Spatial Experts for Explainable Traffic Prediction》。随着城市化进程加速,智能交通系统对交通预测的需求日益增长。尽管大语言模型LLMs已被引入该领域,但现有方法大多仅将其作为简单的数据编码器,忽略了LLMs强大的语义理解能力。且难以灵活适应流量、速度和需求等多种不同的预测场景。为突破这一瓶颈,论文提出了SS-MoE框架,通过构建分层提示词和混合专家机制,不仅提升了预测精度,还实现了对预测结果的人类可读解释。该研究设计了粗粒度与细粒度结合的分层提示策略,并引入包含空间、语义及通用专家的混合架构,有效捕捉了复杂的时空依赖与语义信息。在五个公共交通数据集上的广泛实验表明,SS-MoE在多项任务中均优于现有最先进基线,且在少样本场景下表现出色。
**论文链接:**https://dl.acm.org/doi/abs/10.1145/3746252.3761412
推文作者为韩煦,审校为邓镝
一、研究背景
交通预测利用历史时空数据预估未来交通状态,对于缓解城市拥堵、优化物流路径及管理交通信号具有重要意义。传统统计模型难以捕捉非线性交通动态,而基于深度学习的方法如RNN和时空图神经网络STGNN虽然提升了建模能力,但在处理多模态数据及低质量数据时仍面临挑战。近期研究尝试将大语言模型引入交通领域,如ST-LLM和UrbanGPT。然而,这些方法通常仅利用LLM进行时空数据编码,存在两大局限:一是未能充分利用LLM对文本信息的语义理解能力,忽略了文本提示对下游任务的指导作用;二是由于数据格式限制,LLM在直接处理时空依赖性方面存在困难。
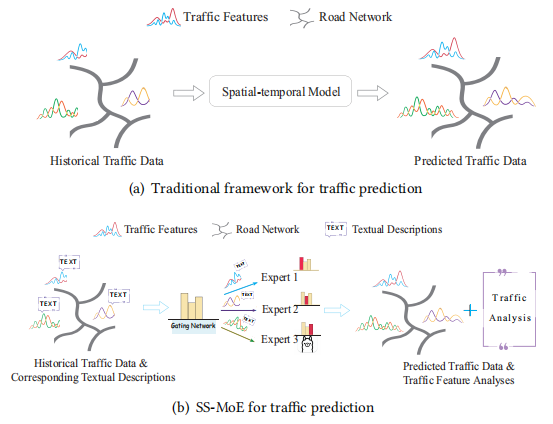
图1 传统框架与SS-MoE的对比
论文旨在解决的关键问题:
**(1)语义理解能力的闲置与误用:**现有方法多将LLM视为简单的时空数据编码器,直接输入数字化数据,忽略了LLM处理文本信息的强大语义推理能力。这导致模型无法从路网背景、流量模式描述等文本信息中获益,限制了对下游任务的深层理解。
**(2)多模态场景下的适应性不足:**现实世界的交通场景具有高度多样性,不同任务对语义信息和时空依赖的侧重不同。现有的单一架构难以根据任务需求动态分配注意力权重,无法灵活适应从交通流到出行需求等多种预测场景。
二、研究方法
为应对上述挑战,论文提出了SS-MoE框架,如图2所示。该框架主要包含四个步骤:分层描述符构建、多模态表征聚合、语义与空间混合专家层以及预测与解释模块。
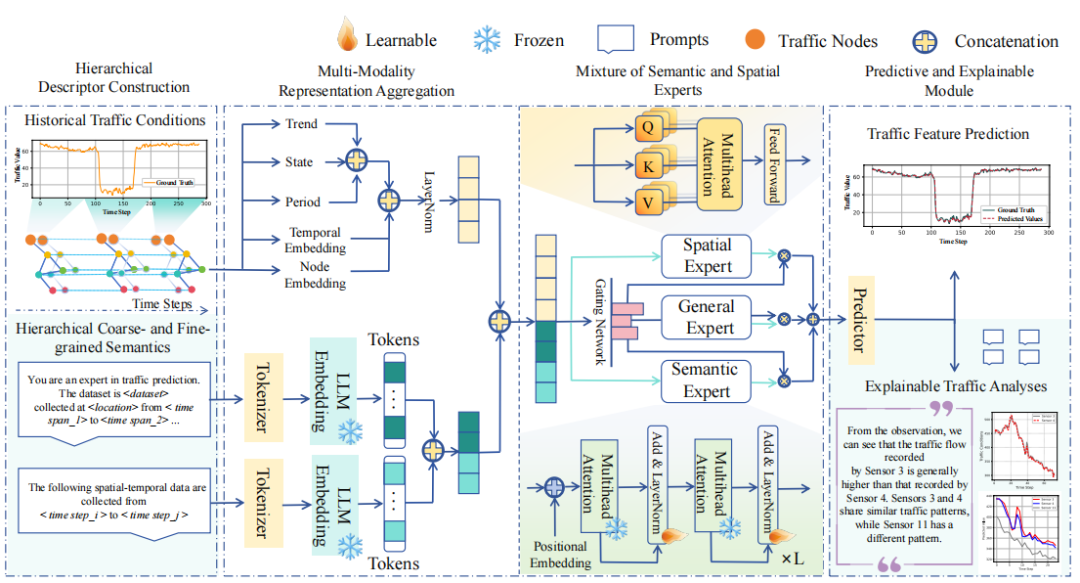
图 2 SS-MoE 框架组成
2.1 分层描述符构建
如何有效地设计提示词以指导LLM进行交通预测是一个难题。当前方法难以构建能够涵盖任务细微差别及完整背景知识的提示,导致LLM无法通过指令充分发挥其推理优势。该论文设计了一套分层提示策略,旨在为模型提供丰富的语义上下文:
**(1)粗粒度提示:**提供系统性的背景知识。包括赋予模型"交通预测专家"的角色设定,以及数据集的宏观描述,如数据采集的城市位置、完整时间跨度及数据类型说明。
**(2)细粒度提示:**针对具体样本的时间戳信息生成描述。精确指出数据采集的具体星期、日期和时间段,帮助模型捕捉特定时间节点的交通规律。
2.2 多模态表征聚合
在SS-MoE框架中,多模态表征聚合模块起到了承上启下的关键作用。它负责将原始的交通数据和构建好的文本提示转化为模型可理解的高维潜在表征,具体分为以下两个核心过程:
(1)时空特征增强: 除了基础的流量数据,SS-MoE初始化了一个可学习的空间嵌入矩阵Es,通过端到端的训练自动捕获节点间的关联,从而减少对先验地理信息的依赖,提高模型的适应性。考虑到交通流量具有明显的早晚高峰和周内周末模式,模型引入了专门的时间嵌入TE 。具体包括一天内的时刻嵌入Ed 将一天划分为288个时间片和一周内的日期嵌入Ew,精准捕捉细粒度的时间特征。特别的是,本文还利用傅里叶变换提取周期性特征,并计算非周期性短期趋势和瞬时状态,通过多层感知机将这些特征融合全面捕捉交通数据的动态变化。
**(2)文本特征编码:**模型采用Llama3-1B的分词器作为工具。它将上一阶段构建的粗粒度提示和细粒度提示转化为序列化的Token。这些Token被映射为高维的文本嵌入为后续的语义专家提供了丰富的先验知识。
最后,模型将处理好的时空表征与文本表征进行拼接。构建了一个包含物理规律和背景知识的综合嵌入H
2.3 语义与空间混合专家层
混合专家层是本框架的核心推理模块。SS-MoE通过引入三大专用专家模块和一个智能门控网络,实现了对多模态特征的动态路由和精细化处理。门控网络引入可学习机制,根据输入数据的特性自动计算权重,将不同的样本动态分配给最合适的专家组合。
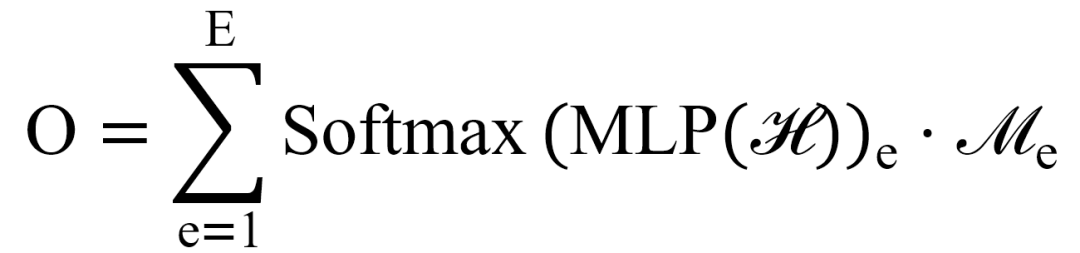
**(1)空间专家:**采用多头自注意力机制(Multi-Head Self-Attention)。它将输入的综合表征映射为查询(Q)、键(K)和值(V)矩阵,计算节点间的注意力分数。专注于捕捉交通路网中节点之间的复杂空间依赖关系。
**(2)语义专家:**利用冻结参数的预训练大语言模型Llama3-1B作为骨干网络。它直接处理包含丰富背景知识的输入表征。
**(3)通用专家:**旨在捕捉跨场景、跨任务的通用交通模式,增强模型的鲁棒性,特别是在数据稀缺(Few-shot)的场景下防止过拟合,确保模型在面对未见过的路网或极端情况时仍能保持稳定的预测能力。
2.4 预测与解释模块
**(1)预测分支:**经过混合专家层处理后的输出汇集了空间依赖、语义背景和通用特征。预测分支通过一个多层感知机(MLP)将这些高维潜在表征投影为未来的交通流量、速度或需求数值。
**(2)解释分支:**论文引入Llama3-7B模型作为解释器,对预测结果进行分析。模型能够生成关于单个节点趋势的统计评估、节点对之间的模式差异分析以及节点三元组的相似性解释,基于这些分析,LLM还能进一步生成具体的管理建议,形成从数据预测到智能决策支持的完整闭环。
三、实验结果
论文在PEMS08、PEMS07(M)、PEMS07(L)、NYCTaxi及NYCBike五个公开数据集上进行了广泛实验,涵盖交通流、速度及需求预测任务。对比基线包括GRU、STGCN、GWNet、ST-LLM及STD-PLM等主流模型。
表1 预测性能对比
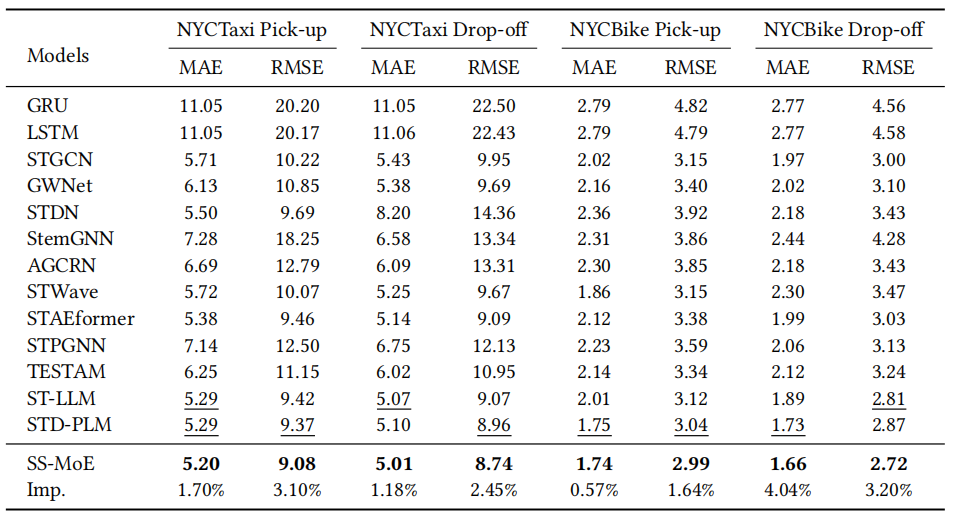
实验结果显示,SS-MoE在所有数据集和指标上均表现优异。在NYCTaxi和NYCBike的需求预测任务中,SS-MoE显著优于所有基线模型。
表2 少样本学习能力对比
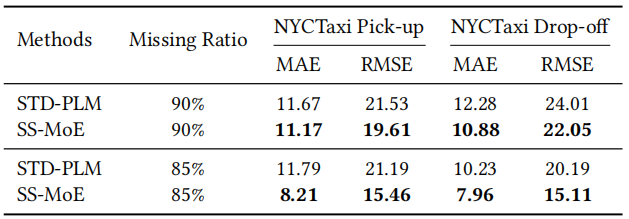
针对现实中常见的传感器故障或数据缺失情况,论文进行了少样本实验。结果表明,仅使用10%的训练数据时,SS-MoE在NYCTaxi下车预测任务上的表现甚至优于使用完整数据的GRU模型,展现了极强的泛化能力。
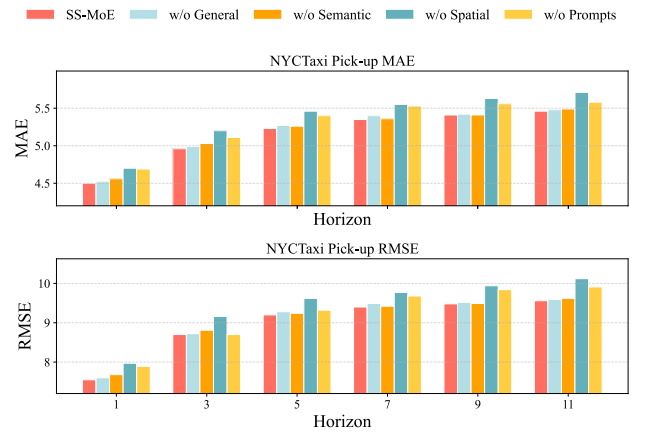
图3 消融实验结果
为了验证SS-MoE框架中各个组件的有效性,论文在NYCTaxi Pick-up数据集上进行了详尽的消融研究。实验设置了多种变体,分别移除了通用专家、语义专家、空间专家,以及移除了所有文本提示词。实验结果表明,移除粗细粒度提示词会导致预测误差上升,证明了文本语义信息是对时空嵌入特征的有效补充。此外,移除任一专家模块均导致所有预测时间步上的性能下降,这有力验证了混合专家MoE架构在捕捉多样化交通模式方面的必要性。
四、总结
本推文介绍一个名为SS-MoE的创新性交通预测框架,有效解决了现有LLM交通模型语义利用率低和任务适应性差的问题。该框架设计了粗细粒度分层提示词作为辅助知识库;构建了包含空间、语义及通用专家的混合架构以动态适应多模态数据;并实现了预测结果的自然语言解释。广泛的实验结果证明,SS-MoE不仅在标准预测和少样本场景下结果均优于基线模型,还能提供具有洞察力的交通分析,为构建更智能、透明的交通管理系统提供了有力支持。