快速理解
这份 Google《AI 智能体入门白皮书》在"智能体"话题上,真正"与众不同"的并非再次强调"模型+工具+编排"的三件套,而是把镜头全部拉向**"如何让一套会自己长出新能力、自我演化的系统,在大规模生产环境里可观测、可度量、可治理、可赚钱"**。下面把与此前主流叙事最拉开距离、也最容易被忽视的五条"分水岭"观点拎出来:
-
智能体不是"自动化脚本",而是**"第三类安全主体"**
白皮书把 Agent 正式抬到跟"人-User、服务-Service Account"并列的新 Principal ,必须发"数字护照"(SPIFFE ID)、单独授权、可审计。过去谈安全都在说"别让模型说错话",这里第一次把"Agent 身份、最小权限、可撤销"当底座,不给护照就不准上路。
-
从"单点提示工程"跃迁到**"Agent Ops"------用 A/B 实验思维管理不可确定性的软件**
文档把传统 DevOps 的"断言 == 预期"判死刑,提出质量分数 + LM-as-Judge + 黄金数据集的三板斧:
- 用强模型给弱模型打分(Rubrics 评分)
- 跑通百条"黄金用例"才允许灰度上线
- 用 OpenTelemetry 轨迹替代断点调试,把"黑盒思维链"拆成可检索的 Span
等于把"不可复现的语言生成"强行关进 CI/CD 流水线。
-
"Agent 也会老"------把"自演化"做成闭环产品机制,而不是研究彩蛋
过去提到 Self-Evolving 往往停留在"会写新提示"的 Demo;这里给出工程化回路:
- 运行时日志 → 人类专家纠正 → Learning Agent 提炼成可复用规则/新工具 → 自动补丁进下一代
- 再配一个离线"Agent Gym",用合成数据+红队+Critique Agent 做影子训练 ,解决线上不能"试错"的矛盾
结果让"老化"变成可度量的"知识衰减系数",触发自动升级,真正让系统越跑越新。
-
"多智能体"不是分工那么简单,而是"Agent 即经济"------A2A + AP2 + x402 把机器间交易做成协议栈**
- A2A(Agent-to-Agent)协议= HTTP + 异步任务 + 能力广告(Agent Card),让 Agent 像调用 API 一样"雇佣"另一个 Agent
- AP2(Agent Payment Protocol)+ x402(HTTP 402 微支付)把"点击购买"从人类界面搬到机器界面:带签名的数字 Mandate 让 Agent 可以替人花钱,且链上可审计
第一次把"Agent 生态"从科幻拉到商务:以后采购单、发票、合同都可能由 Agent 在毫秒间完成谈判与结算。
-
"治理层"提前于"能力层"------用 Control-Plane 扼杀"Agent 无序扩张"
Google 提出企业级必须建集中网关,所有流量(人↔Agent、Agent↔Tool、Agent↔Agent)强制过站:
- 运行时:统一鉴权、预算配额、敏感数据过滤
- 治理时:中心化注册表(企业 Agent Store)+ 版本审批 + 细粒度策略
把"Shadow IT"式的模型、工具、Agent 野蛮生长问题,在架构层面就埋好红绿灯,而不是事后补洞。
一句话总结:
这份白皮书把"智能体"从"大模型外挂工具"的 Demo 阶段,一步推到**"可自我进化、可相互雇佣、可替人花钱、可被统一治理"**的新软件物种,并给出身份、支付、Ops、合规全套协议栈------它不是在教你怎么造一个更聪明的 Agent,而是在画一张"让 Agent 文明可持续运转"的城市规划图。
AI智能体入门白皮书


Introduction to Agents
作者:Alan Blount, Antonio Gulli, Shubham Saboo, Michael Zimmermann, and Vladimir Vuskovic
目录
1 从预测型AI到自主智能体 ... 3
2AI智能体简介. 4
2.1 Agentic AI 的问题解决流程 ... 5
3 Agentic AI系统的分类体系 8
AI 智能体能力层级金字塔 8
第0级:核心推理系统(The Core Reasoning System)
第1级:互联型问题解决者(The Connected Problem-Solver) 10
第2级:策略型问题解决者(The Strategic Problem-Solver) 10
第3级:协作型多智能体系统(The Collaborative Multi-Agent System) ...11
第4级:自我进化系统(The Self-Evolving System) 11
4 AI 智能体的核心架构:模型、工具与编排 ... 12
4.1 模型:AI智能体的"大脑" 12
4.2工具:AI智能体的"双手" 13
4.3编排层:AI智能体的"中枢神经" 14
4.4 AI 智能体的部署与服务搭建 ... 16
4.5 智能体运维 AgentOps:应对不可预测性的结构化方法 ... 18
4.6 AI 智能体的互操作性 ... 23
4.7 单个智能体的安全:信任的权衡 ... 28
4.8 从单个智能体到企业级集群的规模化扩展 ... 33
4.9 智能体如何进化与学习 35
5 高级智能体案例 43
5.1 Google Co-Scientist (谷歌协同科学家) 43
5.2 AlphaEvolve Agent (阿尔法进化智能体) 44
6 结语 47
7尾注 48
1 从预测型AI到自主智能体
AI 智能体:大语言模型的自然演进与自主化新范式
AI 智能体是大语言模型技术自然演进的产物,也是让这类模型在软件领域真正发挥实用价值的关键形态。
人工智能正迎来变革。多年来,AI研发的重心一直放在擅长被动执行独立任务的模型上:比如回答问题、翻译文本,或是根据提示词生成图像。这种模式虽然实力强劲,但每一步操作都需要人类持续下达指令。如今,人工智能的发展正迎来范式转变------从单纯生成内容或做预测的AI,转向具备自主解决问题、执行任务能力的全新软件类别。
这一全新领域的核心,正是AI智能体。它并非只是静态工作流中嵌入的一个AI模型,而是一套能自主制定计划、采取行动以达成目标的完整应用。AI智能体融合了大语言模型的推理能力与实际行动能力,得以处理那些单一模型根本无法应对的复杂多步骤任务。其核心优势在于自主性:无需人类步步指引,就能自行规划达成目标的后续步骤。
本文是系列科普内容的第一篇(全系列共五篇),专为那些正将AI智能体从概念验证阶段推向稳健的生产级系统的开发者、架构师和产品负责人打造实用指南。搭建一个简单的AI智能体原型并不难,但要保证系统的安全性、质量与可靠性,却是一项极具挑战的工作。本文将为你夯实核心基础,主要涵盖以下内容:
-
核心架构解析:将AI智能体拆解为三大核心组件------负责推理的模型、可执行操作的工具,以及统筹管理的编排层。
-
能力分类体系:从简单的关联式问题解决者,到复杂的协作式多智能体系统,为AI智能体做清晰的能力分级。
-
架构设计实操:深入讲解各组件的实际设计要点,从模型选型到工具落地全流程解析。
-
生产级构建策略:建立"智能体运维(Agent Ops)"体系,实现对AI智能体系统的评估、调试、安全管控与规模扩展,支持从单一实例到企业级大规模集群的管理。
本文在先前《Agents》1与《Agent Companion》2的基础上展开,为你提供构建、部署和管理新一代智能应用所需的基础概念与战略框架------这类应用能通过推理、行动与观察,自主完成设定目标3。
用语言描述人类与AI的交互方式,其实存在天然的局限性。我们总会不自觉地将AI拟人化,用"思考"、"推理"、"知晓"这类描述人类行为的词汇来形容它。目前,我们还没有专门的词汇来区分两种"知晓":一种是"基于语义的理解式知晓",另一种是"基于最大化奖励函数的高概率式知晓"。这是两种截然不同的认知模式,但在 99.0%99.0\%99.0% 的场景中,它们产生的结果却完全一致。
2 AI 智能体简介
用最通俗的话来说,AI智能体可以定义为模型、工具、编排层和运行时服务的组合体------它通过让大语言模型(LM)在循环中持续工作,最终实现既定目标。这四个要素共同构成了任何自主系统的核心架构:
-
模型("大脑"):作为智能体核心推理引擎的大语言模型或基础模型,负责处理信息、评估选项并做出决策。模型的类型(通用型、微调型或多模态型)决定了智能体的"认知能力"水平。一个Agentic AI系统,本质上是大语言模型输入上下文窗口的"终极管理者"。
-
工具("双手"):这些机制将智能体的推理能力与外部世界连接起来,让它能完成文本生成之外的实际操作。工具包括 API 扩展、代码函数和数据存储(如数据库或向量数据库),用于获取实时、真实的信息。Agentic AI 系统能让大语言模型自主规划使用哪些工具、执行工具调用,并将工具返回的结果填入下一次模型调用的输入上下文窗口。
-
编排层("神经系统"):管理智能体运行循环的"指挥中枢",负责处理规划、记忆(状态)和推理策略的执行。这一层通过提示框架和推理技术(如思维链3、ReAct4等),将复杂目标拆解为具体步骤,并判断何时该"思考"、何时该"调用工具"。同时,它还赋予智能体"记住信息"的能力。
-
部署("身体与腿脚"):在笔记本电脑上搭建智能体原型很简单,但要让它成为可靠、可访问的服务,就必须进行生产环境部署。这包括将智能体部署在安全可扩展的服务器上,并集成监控、日志、管理等关键生产级服务。部署完成后,用户既能通过图形界面访问智能体,其他智能体也能通过"智能体对智能体(A2A)"API进行程序化调用。
归根结底,构建 GenAI 智能体是一种解决任务的全新开发思路。传统开发者像"砌砖工",需要精确定义每一个逻辑步骤;而智能体开发者更像"导演"------不用为每个动作编写明确代码,只需搭建场景(指导指令和提示词)、挑选"演员"(工具和 API)、提供必要背景(数据)。核心任务变成了引导这个自主"演员"呈现出预期的"表演效果"。
你很快会发现:大语言模型最大的优势------极致的灵活性,同时也是最让你头疼的问题。大语言模型"什么都能做"的特性,反而让它难以可靠且完美地专注做某一件事。我们过去所说的"提示词工程",现在更名为"上下文工程",其核心就是引导大语言模型生成期望的输出。每次调用大语言模型时,我们会输入指令、事实、可调用的工具、示例、会话历史、用户画像等信息------把上下文窗口填满"恰好需要的信息",以获取我们想要的结果。而智能体,正是通过管理大语言模型的输入来完成工作的软件。
当问题出现时,调试就变得至关重要。"智能体运维(Agent Ops)"本质上重新定义了我们熟悉的"测量-分析-系统优化"循环。通过追踪记录和日志,你可以监控智能体的"思考过程",找出它偏离预期执行路径的地方。随着模型的演进和框架的完善,开发者的角色更多是提供关
键组件:领域专业知识、明确的"个性设定",以及与完成实际任务所需工具的无缝集成。必须记住:全面的评估和测试,往往比最初的提示词影响力更大。
当一个智能体被精确配置------拥有清晰的指令、可靠的工具、作为记忆的集成上下文、优秀的用户界面、规划与问题解决能力,以及通用世界知识时,它就不再是简单的"工作流自动化工具"。它开始成为一个协作实体:一个效率极高、适应性极强、能力卓越的"新团队成员"。
本质上,智能体是一个专注于"上下文窗口管理艺术"的系统。它在"组装上下文 →\rightarrow→ 提示模型 →\rightarrow→ 观察结果 →\rightarrow→ 为下一步重新组装上下文"的循环中持续运转。这里的上下文可能包括系统指令、用户输入、会话历史、长期记忆、来自权威来源的基础知识、可使用的工具列表,以及已调用工具的结果。这种对模型注意力的精细管理,让它的推理能力能够应对新情况、完成目标。
2.1 Agentic AI 的问题解决流程
我们将AI智能体定义为一种完整的、以目标为导向的应用程序,它整合了推理模型、可执行工具和核心的编排层。简单来说,就是"让大语言模型与工具形成循环,以此完成特定目标"。
但这个系统实际是如何运转的呢?从接收到请求到给出结果,AI 智能体究竟经历了哪些步骤?
AI 智能体的核心运作逻辑,是通过一个持续的循环流程来实现目标。尽管这个循环可能变得极为复杂,但正如《智能体系统设计》一书详细阐述的那样,它可以拆解为五个基础步骤:
第一步:接收任务指令
整个流程由一个具体且宏观的目标启动。这个任务指令既可以由用户提出(比如"为我团队安排即将到来的会议出行"),也可能来自自动化触发(比如"有新的高优先级客户工单生成")。
第二步:扫描环境信息
AI智能体会感知周边环境以收集相关背景信息。这一步中,编排层会调用所有可用资源:比如"用户的请求具体说了什么?""我的长期记忆里有哪些相关信息?我之前尝试过完成这个任务吗?用户上周是否给出过相关指导?""我能从日历、数据库、API等工具中获取什么信息?"
第三步:梳理执行方案
这是AI智能体核心的"思考"环节,由推理模型驱动。智能体会结合第一步的任务指令和第二步的环境信息,制定出具体执行计划。这并非单一的思考过程,而是往往形成一条推理链:"要预订行程,首先得知道团队成员有哪些,我需要调用getteam roster工具;之后还要通过calendar api查看他们的时间是否空闲。"
第四步:执行具体行动
编排层会按照计划,执行第一个具体步骤。它会选择并调用合适的工具------比如调用API接口、运行代码函数或查询数据库。这一步是AI智能体跳出内部推理、与外部世界产生交互的关键动作。
第五步:观察结果并迭代
AI智能体会观察行动产生的结果。例如get-team roster工具返回了五个人的姓名列表,这些新信息会被添加到智能体的上下文或"记忆"中。随后循环会再次启动,回到第三步:"既然已经拿到了团队名单,下一步就要通过calendar api查看这五个人的日程了。"
这种"思考-行动-观察"的循环会持续进行------由编排层统筹管理、推理模型负责分析决策、工具完成实际执行------直到AI智能体的内部计划全部完成,最初的任务指令也得以实现。
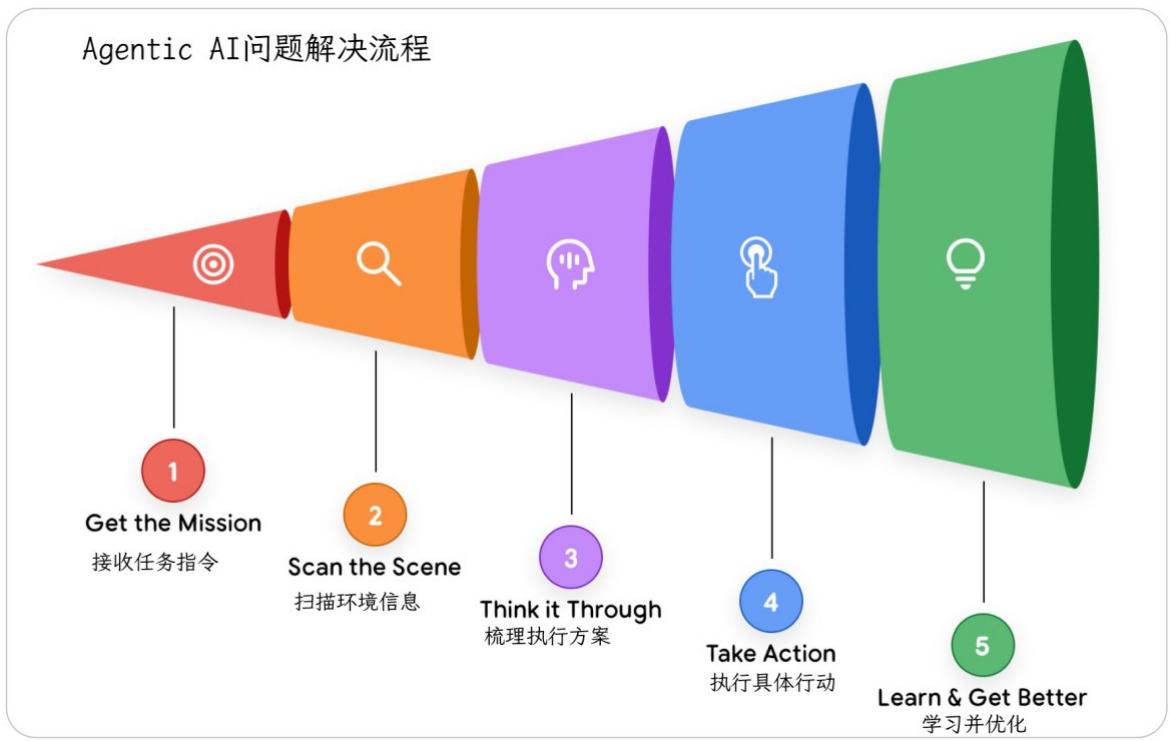
图1:AgenticAI问题解决流程
-
接收任务指令:这是流程的起点,AI 智能体获取用户或系统触发的目标任务。
-
扫描环境信息:AI 智能体收集任务相关的背景、资源(如记忆、工具数据)等信息。
-
梳理执行方案:AI智能体基于任务和环境信息,推理并制定具体的执行步骤。
-
执行具体行动:AI 智能体调用工具(如 API、数据库),落实计划中的具体步骤。
-
学习并优化:AI智能体观察行动结果,将新信息存入"记忆",随后回到"梳理执行方案"环节,循环推进直到任务完成。
我们以客户支持 AI 智能体为例,看看它如何在这五步循环中运作:
假设用户询问:"我的订单#12345在哪里?"
智能体不会立刻行动, 而是先进入"梳理执行方案"阶段, 制定完整的策略。它会这样推理: "用户想知道订单的配送状态。要给出完整的回答, 我需要制定一个多步骤计划:
-
查询订单:首先得在内部数据库中找到这个订单,确认其存在并获取详细信息。
-
追踪物流:从订单详情中提取快递公司的运单编号,再调用外部快递公司的API查询实时物流状态。
-
反馈结果:最后,把收集到的信息整理成清晰、易懂的回复,反馈给用户。"
确定了这个多步骤计划后,智能体开始执行。
在第一个"执行具体行动"阶段,它按计划执行第一步,调用 find_order("12345")工具。随后观察到结果------一份完整的订单记录,其中包含运单编号"ZYX987"。
智能体的编排层识别到计划的第一部分已完成,随即推进到第二步。它调用getshipping_status("ZYX987")工具执行行动,然后观察到新的结果:"正在派送中"。
最终,在完成了计划中的信息收集阶段后,智能体进入"反馈结果"步骤。它判断已获取所有必要信息,规划好最终的回复内容,然后生成并给出回应:"你的订单#12345 目前状态为'正在派送中'!"
3 Agentic AI系统的分类体系
理解五步操作循环只是拼图的第一块。拼图的第二块在于认识到:这个循环可以通过增加复杂度进行"缩放",从而构建出不同层级的Agentic AI系统。对于架构师或产品负责人来说,一个关键的初始决策就是------我们要打造什么样的AI智能体?
我们可以将Agentic AI系统大致划分为几个层级,每一级都在前一级能力的基础上进一步扩展。
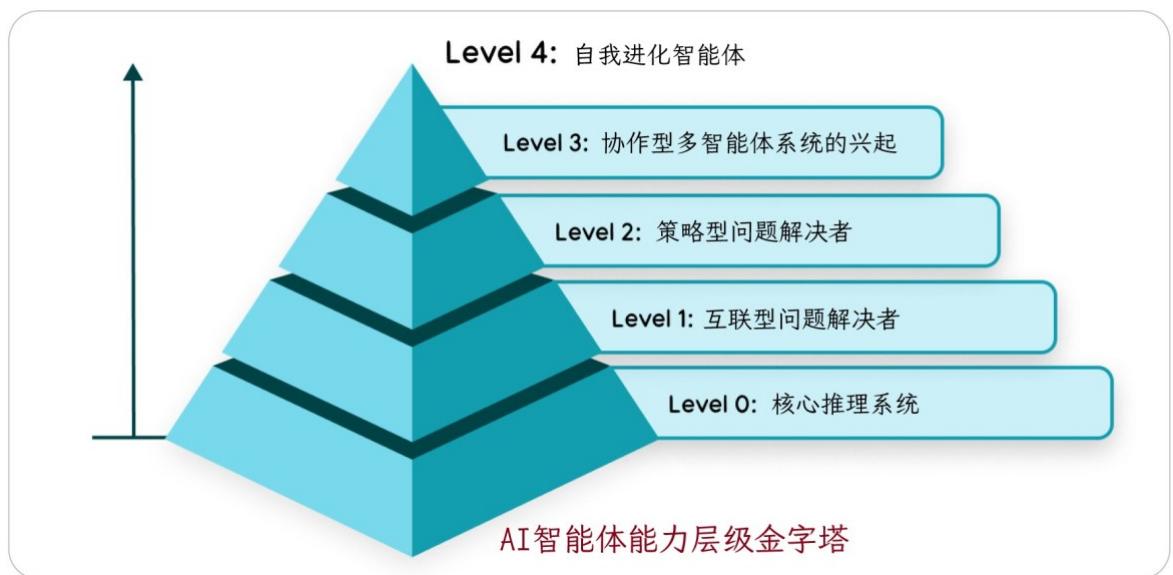
图2:AI智能体的五步操作循环
AI 智能体能力层级金字塔(Agentic AI Capability Pyramid),它以直观的金字塔结构展示了 Agentic AI 从基础到高级的五个发展阶段。每一层代表一种更复杂、更强大的智能体形态,层层递进,构建出一个清晰的能力演进路径。
从下到上,象征着智能体能力的提升方向:从简单推理 →\rightarrow→ 连接世界 →\rightarrow→ 战略规划 →\rightarrow→ 协作分工 →\rightarrow→ 自我进化。
-
L0: 核心推理系统。最基础的"大脑"------仅依赖大语言模型自身知识,无外部交互。相当于"会说话的知识库"。
-
L1:连接型问题解决者。能调用外部工具(如搜索、API)获取实时信息,实现"感知+行动"。这是第一个真正意义上的"AI智能体"。
-
L2:策略型问题解决者。不再只是执行任务,而是能制定多步骤计划,并进行上下文管理(Context Engineering)。具备战略思维。
-
L3:协作型多智能体系统的兴起。多个专业智能体组成团队,彼此协作完成复杂任务。模仿人类组织分工模式。
-
L4:自我进化智能体。系统能够识别自身短板,自主创建新工具或新智能体来扩展能力,实现真正的"自我成长"。
演进逻辑:从"单一大脑"到"智能组织"
这个金字塔揭示了一个关键思想:
AI智能体的发展不是单点突破,而是一场由内而外、逐层叠加的系统性进化。
-
底层(Level 0~1)是"个体智能"的建立:先有思考能力,再有行动能力。
-
中层(Level 2~3)是"组织智能"的萌芽:从个人决策升级为团队协作。
-
顶层(Level 4)是"生命智能"的雏形:系统不再被动响应,而是主动演化,具备类似生物的适应性。
用大白话来说就是,你可以把这五个层级想象成一个人类的成长过程:
-
婴儿期(Level 0):只会背诵学过的东西,不知道外面发生了什么。
-
幼儿期 (Level 1):开始学会使用工具,比如拿手机查天气、问问题。
-
青少年期 (Level 2) : 能独立规划路线, 比如找一家好餐厅, 还会考虑距离、评分等细节。
-
成年期(Level 3):组建团队工作,比如项目经理带领市场、技术、设计一起做项目。
-
未来人类 (Level 4) : 不仅能指挥团队, 还能在发现缺人时, 自己 "创造"一个新成员来补位。
这张图告诉我们:真正的AI智能体不是"更聪明的大脑",而是"会思考、会动手、会合作、甚至会自我进化的数字组织"。
它不仅是技术架构的分层,更是对未来人工智能形态的一种深刻展望。
第0级:核心推理系统(The Core Reasoning System)
在拥有一个真正的AI智能体之前,我们首先要有一个最基础的"大脑"------也就是推理引擎本身。
在这个阶段,一个大语言模型(LLM)是孤立运行的:它仅依靠自身庞大的预训练知识来回答问题,没有工具、没有记忆,也无法感知外部世界。它的优势在于海量训练数据赋予的强大解释力------比如能详细讲解棒球规则,或者完整复述纽约洋基队的历史。
但它的短板也同样明显:它对现实世界毫无实时感知能力。换句话说,它对训练数据截止之后发生的任何事情都"视而不见"。
举个例子:如果你问它"昨晚洋基队比赛的最终比分是多少?",它就无能为力了。因为那场比赛发生在它的训练数据"冻结"之后,相关信息根本不在它的知识库中。
第1级:互联型问题解决者(TheConnected Problem-Solver)
到了这一级,推理引擎终于"活"了过来------它开始连接并使用外部工具,也就是获得了"双手"。
通过五步操作循环,它现在可以完成第0级做不到的任务。比如面对同样的问题:"昨晚洋基队比赛的比分是多少?"
-
任务(Mission):获取昨晚洋基队比赛的比分。
-
思考(Think):意识到这需要实时数据。
-
行动(Act):调用 Google 搜索 API,输入相关关键词和日期。
-
观察 (Observe) : 收到结果: "洋基队以 5 比 3 获胜。"
-
输出 (Output) : 将这一信息整合成自然语言回答用户。
这种与外部世界互动的能力------无论是调用搜索引擎查比分、通过金融API获取股价,还是利用检索增强生成(RAG)查询数据库------正是第1级AI智能体的核心特征。
第2级:策略型问题解决者(TheStrategicProblem-Solver)
第2级标志着能力的一次重大跃升:从执行单一任务,升级为规划并完成复杂的多步骤目标。其关键新能力是"上下文工程"(Context Engineering)------即智能体能够主动筛选、组织并管理每一步所需的最关键信息。
为什么这很重要?因为大语言模型的注意力资源有限。如果一股脑塞入太多无关信息,反而会降低准确性和效率。上下文工程就像一位聪明的助理,只把当前最相关的资料递给"大脑"。
举个例子,用户提出任务:"帮我找一家位于我办公室(山景城 Amphitheatre Parkway 1600 号)和客户办公室(旧金山 Market St 1 号)之间的优质咖啡馆。"
一个第2级的AI智能体会这样规划:
1)思考:"我得先算出两地的中点。"
-
行动:调用地图工具,输入两个地址。
-
观察:"中点是米尔布雷(Millbrae, CA)。"
2)思考:"现在要在米尔布雷找咖啡馆。用户说要'优质',那我就找评分4星以上的。"
- 行动:调用"谷歌地点"工具,搜索"Millbrae的咖啡馆",并设置
minRating = 4.0。 (这就是上下文工程:它自动把上一步的结果转化为精准的新查询条件。)
- 观察:"找到两家:'米尔布雷咖啡'和'每日研磨'。"
3)思考:"现在我可以汇总结果,给出推荐了。"
这种策略性规划还能实现主动式服务。比如,一个智能体读到一封冗长的航班确认邮件后,能自动提取关键信息(航班号、日期),并直接帮你添加到日历中。
第3级:协作型多智能体系统(TheCollaborativeMulti-AgentSystem)
到了这一层级,设计思路发生根本转变:我们不再追求打造一个"全能超级智能体",而是模仿人类组织的方式------组建一支由多个专业智能体组成的团队。
在这个系统中,智能体可以把其他智能体当作"工具"来使用。
想象一下,一个"项目经理智能体"接到任务:"推出我们的新款'Solaris'耳机。"
它不会自己完成所有工作,而是像真实世界的项目经理一样,分派子任务给专业团队:
-
指派给市场调研智能体:"分析市面上降噪耳机的竞品定价,明天前提交摘要报告。"
-
指派给营销智能体:"基于'Solaris'的产品说明书,起草三版新闻稿。"
-
指派给网页开发智能体:"根据设计稿,生成新产品页面的 HTML 代码。"
这种协作模式虽然目前仍受限于当前大语言模型的推理能力,但它代表了自动化复杂业务流程的前沿方向------从头到尾,无需人工干预。
第4级:自我进化系统(The Self-Evolving System)
第4级是一次质的飞跃:系统不仅能分配任务,还能自主识别自身能力的不足,并动态创建新的工具甚至新的智能体来填补空白。
继续上面的例子:项目经理智能体在推进"Solaris"发布时,突然意识到:"我需要监控社交媒体上关于'Solaris'的讨论热度,但现在团队里没有这样的能力。"
于是它启动元推理(Meta-Reasoning):
-
思考:"我必须追踪'Solaris'的社交声量,但目前没有相应工具。"
-
行动:调用一个高级的"智能体创建器"(AgentCreator)工具,下达新指令:"请创建一个能监控关键词'Solaris 耳机'、执行情感分析、并每日生成摘要报告的新智能体。"
-
观察:一个新的"情感分析智能体"被自动生成、测试并通过验证,随即加入团队,开始为原任务贡献力量。
这种自我扩展、自我进化的特性,让整个多智能体系统不再是一组静态工具的集合,而真正成为一个能学习、能适应、能成长的数字组织。
4 AI 智能体的核心架构:模型、工具与编排
我们已经了解了AI智能体能做什么,以及它的能力如何逐级扩展。但真正的问题是:我们该如何把它从概念变成现实?
答案在于构建一个清晰的架构,它由三个核心部分组成:模型(Model)、工具(Tools)和编排(Orchestration)。这三者共同构成了一个可运行、可扩展、可维护的Agentic AI系统。
4.1 模型:AI智能体的"大脑"
大语言模型是 AI 智能体的推理核心,选择何种大语言模型是一项关键的架构决策,它直接决定了 AI 智能体的认知能力、运营成本和响应速度。但如果把这种选择简单等同于挑选基准测试分数最高的模型,那多半会走向失败------毕竟 AI 智能体在实际生产环境中的表现,很少由通用的学术基准测试来决定。
想要让 AI 智能体在现实场景中发挥作用,需要模型在 Agentic AI 的核心能力上表现出色:一方面要具备强大的推理能力,能应对复杂的多步骤问题;另一方面要能可靠地使用工具,实现与外部世界的交互。
要选对模型,不妨按这几步来:先明确具体的业务问题,再用与业务结果直接挂钩的指标去测试模型。比如如果你的 AI 智能体需要编写代码,那就用企业内部的私有代码库来测试;如果它负责处理保险理赔,就评估它从企业特定格式的文档中提取信息的能力。完成这一步后,还得结合成本和延迟等实际因素综合考量。说到底,针对特定任务,能在效果、速度和成本之间达到最佳平衡的模型,才是真正的"最优解"。
你也可以选择不止一种模型,打造一个"专家团队"。毕竟杀鸡焉用牛刀,一个稳健的AI智能体架构可以这样设计:用Gemini2.5Pro这类前沿模型承担初始规划、复杂推理这类核心工作,而把用户意图分类、文本总结这类简单且高频的任务,智能分流给Gemini2.5Flash这类速度更快、成本更低的模型。这种模型分流机制可以是自动的,也可以是硬编码实现的,它是同时优化AI智能体性能和成本的关键策略。
这一思路也适用于处理不同类型的数据。虽然 Gemini 实时模式这类模型原生的多模态模型, 能为处理图像、音频数据提供简洁高效的方法, 但你也可以选择另一种方式: 借助 Cloud Vision API (云端视觉接口)、Speech-to-Text API (语音转文字接口) 这类专业工具来处理数据。这种模式下, 先把各类非文本信息转换成文本, 再交给纯语言模型进行推理。它能带来更高的灵活性, 让你可以挑选各领域最优秀的工具组件, 但同时也会让系统的复杂度大幅增加。
最后要注意的是,AI领域的发展节奏始终是高速且动态的,今天选的模型可能半年后就会被淘汰,"一劳永逸"的想法显然不现实。要适应这种变化,就需要搭建一套灵活的运营框架,也就是"智能体运营(Agent Ops)"体系。通过构建完善的CI/CD流水线,持续用核心业务指标去评估新模型,你就能降低模型升级的风险、加快迭代速度,让AI智能体始终用上最顶尖的"大脑",而无需对整体架构进行彻底重构。
4.2 工具:AI 智能体的"双手"
如果说模型是AI智能体的"大脑",那工具就是它连接推理与现实的"双手"。有了工具,AI智能体才能突破静态训练数据的限制,获取实时信息并在现实世界中采取行动。一个稳健的工具接口包含三个核心环节:明确工具的功能、调用工具、观察结果。
下面为你介绍AI智能体开发者常会为"双手"配备的几类主要工具。若想深入了解,可参考本系列中专门聚焦智能体工具的白皮书。
4.2.1 信息检索:让智能体扎根现实
最基础的工具是获取最新信息的能力。检索增强生成(Retrieval-Augmented Generation,RAG)就像给AI智能体一张"图书馆借阅卡",能查询外部知识------这些知识通常存储在向量数据库或知识图谱中,范围从企业内部文档到通过谷歌搜索获取的网络知识都有。对于结构化数据,自然语言转SQL(Natural Language to SQL,NL2SQL)工具能让智能体查询数据库来解答分析类问题,比如"上季度我们最畅销的产品是什么?"。通过在回答前先查阅资料(无论是文档还是数据库),智能体的结论会基于事实,从而大幅减少"幻觉"(即编造虚假信息)的情况。
4.2.2 执行行动:让智能体改变世界
当 AI 智能体从"读取信息"升级到"主动做事",它的真正力量才会被释放。通过将现有 API 和代码函数包装成工具,智能体可以发送邮件、安排会议,或是在 ServiceNow 中更新客户记录。对于更动态的任务,智能体还能实时编写并执行代码。在安全的沙箱环境里,它
可以生成 SQL 查询语句或 Python 脚本,用来解决复杂问题或进行计算------这让它从一个"知识渊博的助手"变成了"能自主行动的执行者"。
这其中也包括人际交互工具。AI智能体可以使用"人机协同(Human in the Loop,HITL)"工具暂停工作流程,向人类请求确认(比如调用ask_for Confirmation()函数),或是从用户界面获取特定信息(比如调用ask_for_date_input()函数),确保关键决策有人类参与。人机协同功能可以通过短信和数据库中的任务来实现。
4.2.3 函数调用:为智能体连接工具
要让AI智能体可靠地进行"函数调用"和使用工具,需要清晰的指令、安全的连接和编排。像OpenAPI规范这样的长期标准就提供了这些支持,它给智能体一份结构化"合同",详细说明工具的用途、所需参数和预期响应。这份schema(schema:模式、架构)能确保模型每次都生成正确的函数调用,并准确解读API返回的结果。对于更简单的工具发现和连接,像模型上下文协议(Model Context Protocol,MCP)这样的开放标准因其便捷性而广受欢迎。此外,部分模型拥有模型原生工具,比如具备原生谷歌搜索功能的Gemini,其函数调用直接作为大语言模型调用过程的一部分完成。
4.3 编排层:AI智能体的"中枢神经"
如果说大语言模型是AI智能体的"大脑",工具是它的"双手",那编排层就是连接二者的"中枢神经系统"。它是驱动"思考-行动-观察"循环的核心引擎,是管控AI智能体行为的状态机,更是开发者精心设计的逻辑落地的载体。这一层绝非简单的"管线连接",而是整台AI智能体"交响乐"的指挥家------它决定着大语言模型何时进行推理、该调用哪款工具执行任务,以及如何根据行动结果规划下一步操作。
4.3.1 核心设计选择
搭建编排层的首要架构决策,是确定AI智能体的自主化程度,这一选择呈"光谱式"分布:一端是高度确定、可预测的工作流,仅将大语言模型作为工具完成特定任务,相当于给现有流程"加一点Albuff";另一端则是让大语言模型掌握主导权,自主动态调整策略、规划并执行任务,直至达成目标。
与之并行的另一项抉择是实现方式:无代码构建工具胜在高效、易上手,能让业务人员快速自动化结构化任务、搭建简单的AI智能体;而对于更复杂的核心业务系统,谷歌Agent Development Kit(ADK)等代码优先的框架(code-first framework),能为工程师提供深度的控制权、定制化能力和系统集成能力。
无论选择哪种方式,一个面向生产的企业级框架都必须满足三个核心要求:
-
开放性:支持接入任意模型和工具,避免被单一厂商绑定;
-
精准控制:可实现"混合模式",允许将大语言模型的非确定性推理与硬编码的业务规则结合,形成"混合智能"------既灵活又可靠;
-
可观测性:这是最关键的一点------当 AI 智能体行为异常时,我们无法像调试代码那样在模型的"思考过程"中加断点,因此健壮的框架必须能自动生成详细的追踪日志,完整暴露推理轨迹,包括模型的"内心独白"、选择的工具、传入的参数以及观察到的结果。
4.3.2 用领域知识与角色设定指导智能体
在这个框架中,开发者最有力的"抓手",是为AI智能体注入领域知识和鲜明的角色设定。这一过程通过系统提示词(system prompt)或核心指令集实现,这绝非简单的命令,而是AI智能体的"行为章程"。
比如你可以这样定义:"你是Acme公司的智能客服智能体......",同时明确约束条件、期望的输出格式、交互规则、特定的语气风格,以及使用工具的时机和原因。在指令中加入几个典型示例场景,通常能显著提升智能体的行为一致性、专业度和用户体验。
4.3.3 用上下文拓展智能体的"记忆"
AI智能体的"记忆"会在运行时被整合进大语言模型的上下文窗口(若想深入了解,可参考本系列中聚焦智能体记忆的白皮书),主要分为短期和长期两类:
短期记忆(short-term memory)
相当于智能体的"即时草稿本",记录当前对话的实时历史,追踪"思考-行动-观察"循环中产生的(行动、观察)数据对,为模型的下一步决策提供即时上下文。它通常以状态(state)、工件(asset)、会话session)或线程 thread)等抽象形式实现。
长期记忆(long-term memory)
实现跨会话的记忆持久化,在架构上几乎都通过专用工具实现------即连接向量数据库或搜索引擎的RAG(检索增强生成)系统。编排层让智能体能够预取并主动查询自身历史,比如"记住"用户几周前的偏好或同类任务的结果,从而提供真正个性化、连续的服务体验。
4.3.4 多智能体系统与设计模式
当任务复杂度提升,构建一个"全能超级智能体"会变得效率低下,更优的方案是借鉴人类组织的运作模式,采用"专家团队"思路------这正是多智能体系统的核心:将复杂流程拆解
为独立子任务,为每个子任务分配专门的AI智能体。这种分工让每个智能体更简单、聚焦,也更易开发、测试和维护,非常适合动态或长期运行的业务流程。
架构师可采用经过验证的Agentic AI设计模式(尽管智能体能力和相关模式仍在快速演进):
-
协调器模式(Coordinator Pattern):适用于动态或非线性任务,引入一个"管理者"智能体,负责分析复杂请求、拆分主任务,并将子任务智能分配给研究员、写手、程序员等专业智能体,最后汇总所有专业智能体的结果,形成完整的最终答案;
-
顺序模式(Sequential Pattern):更适配线性工作流,像数字化流水线一样,一个智能体的输出直接作为下一个智能体的输入;
-
迭代优化模式(Iterative Refinement Pattern):侧重内容质量,由"生成者"智能体创作内容,再由"评判者"智能体根据质量标准(如准确性、安全性、格式规范)进行评估并提出改进意见,形成反馈循环;
-
人机协作模式(Human-in-the-Loop,HITL):针对高风险任务,在智能体执行关键操作前设置人工审核环节,确保操作安全。例如,在执行大额转账或发布敏感内容前,必须由真人审批。
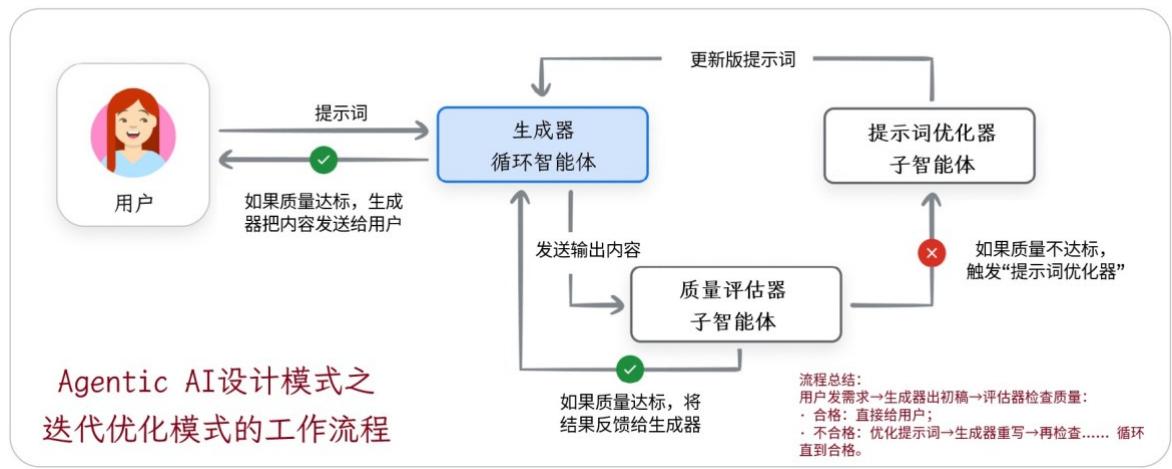
图3:"迭代优化"模式
4.4 AI 智能体的部署与服务搭建
当你在本地完成AI智能体的开发后,接下来自然会想把它部署到服务器上------让它能全天候运行,也能被其他人或其他AI智能体调用。打个比方,部署和服务就像是给AI智能体装上了"身体"和"腿脚",让它真正能落地发挥作用。
一个能有效工作的AI智能体,需要依托多项服务的支撑,比如会话历史的保存、记忆的持久化存储,还有更多配套功能。作为AI智能体的开发者,你还得决定要记录哪些日志信息,以及采取哪些安全措施来保障数据隐私、满足数据存储地域要求和相关法规的合规性。这些服务环节,都是把AI智能体部署到生产环境时需要考虑的范畴。
要让一个智能体在生产环境中高效、可靠地工作,光有核心逻辑还不够,还需要一系列支撑服务,例如:
-
会话历史管理(记录用户与智能体的完整对话)
-
长期记忆持久化(跨会话记住用户偏好或任务进展)
-
日志记录、监控告警、安全审计等运维能力
好在,AI智能体开发者可以借助已经发展了数十年的应用托管基础设施。毕竟AI智能体只是一种新型软件,很多传统软件的部署原则依然适用。开发者既可以选择专门为AI智能体打造的部署方案,比如Vertex AI Agent Engine(顶点AI智能体引擎),它能在一个平台内提供运行时环境和所有配套功能;也可以如果是想更直接地掌控应用架构,或者要把AI智能体部署到现有的DevOps(开发与运维)基础设施中,那么任何AI智能体以及大多数智能体服务,都能被封装到Docker容器里,再部署到Cloud Run(云运行)、GKE(谷歌容器引擎)这类行业标准的运行时环境中。
作为智能体的构建者,你还需要主动思考:
-
哪些操作需要被记录下来用于调试或合规?
-
如何保护用户数据的隐私?
-
数据是否必须存储在特定地区(满足"数据驻留"要求)?
-
如何确保系统符合行业法规(如GDPR、HIPAA等)?

图4:Vertex AI智能体构建工具
如果你并非专业的软件开发人员或 DevOps 专家,第一次部署 AI 智能体的过程可能会让你觉得棘手。不过很多 AI 智能体框架都简化了这个流程,只需要执行一条部署命令,或者通过专门的平台就能完成部署,这些方式很适合用来进行早期的探索和上手尝试。但要搭建一个安全、可投入生产使用的环境,通常还需要投入更多时间,并且遵循行业最佳实践,比如为 AI 智能体搭建 CI/CD(持续集成/持续部署)流程、开展自动化测试等。
要迈向安全、稳定、可扩展的生产环境,通常还需要投入更多精力,引入工程最佳实践,例如:
-
CI/CD 流水线(持续集成与持续部署)
-
自动化测试(验证智能体在各种场景下的行为)
-
版本管理与回滚机制
·权限控制与审计日志
部署一个AI智能体,不只是"让它跑起来",而是为它打造一个安全、可观测、可扩展、合规的数字身体。无论是借助一站式平台快速起步,还是通过容器化深度定制,最终目标都是让Agentic AI在真实世界中稳健前行。
4.5 智能体运维 AgentOps:应对不可预测性的结构化方法
当你开始构建第一个AI智能体时,需要一遍又一遍地手动测试它的表现。新增一个功能后,它真的能正常工作吗?修复一个漏洞时,会不会引发其他问题?测试在软件开发中本是常规操作,但对于GenAI而言,测试的方式却截然不同。
从传统的确定性软件,转向具有随机性的Agentic AI系统,需要全新的运维理念。在传统软件的单元测试中,只需验证输出结果是否与预期完全一致即可;但AI智能体的响应本质上具有概率性,这种测试方法显然不再适用。此外,语言本身十分复杂,要评估AI智能体响应的"质量"------比如是否完成了所有任务、有没有产生多余内容、语气是否恰当------往往需要借助大语言模型来实现。
传统软件是确定性的:输入相同,输出就一定相同。因此,开发者可以用简单的断言来验证结果,比如 assert output == "expected"。但 AI 智能体的本质是概率性的(stochastic):即使面对完全相同的请求,大语言模型也可能生成略有不同的回答。这是设计使然,而非缺陷。
更复杂的是,判断一个回答"好不好",往往不能靠字符串比对。
-
它是否完整回答了用户的问题?
-
是否避免了不该说的内容(比如泄露隐私或胡编乱造)?
-
语气是否专业、友好、符合品牌调性?
这些问题的答案通常只能由另一个大语言模型来评估------因为只有具备语言理解能力的系统,才能真正判断"质量"。
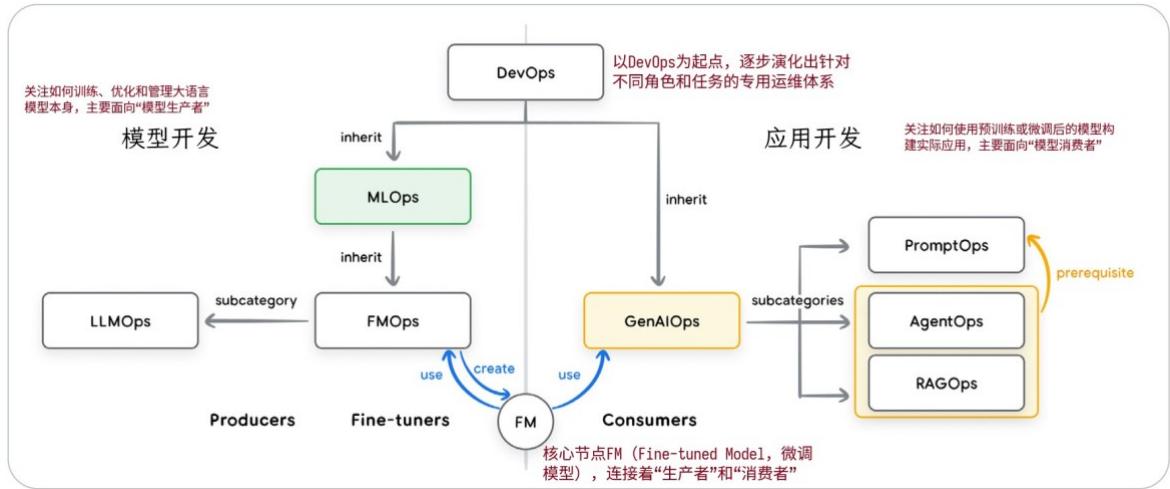
图5:DevOps、MLOps与GenAIOps运维领域的关联
智能体运维 (AgentOps) 正是应对这一新现状的系统化、规范化方法。它是 DevOps 和 MLOps 理念的自然演进,专门针对 AI 智能体在开发、部署和治理过程中遇到的独特挑战而设计,能将 AI 智能体的不可预测性从风险因素,转化为可管理、可量化、可信赖的特性。若想深入了解,可参考本系列中聚焦智能体质量的白皮书。
AgentOps 的目标,不是消除不确定性,而是将它变成一种可管理、可度量、可信赖的能力。通过结构化的监控、评估、反馈和迭代机制,AgentOps 帮助团队:
-
系统性地衡量智能体的表现;
-
快速发现行为漂移或逻辑漏洞;
-
在保证安全与合规的前提下,持续优化用户体验。
构建AI智能体不是"写完代码就结束"的一次性工程,而是一个持续观察、评估和调优的闭环过程。AgentOps正是支撑这一过程的方法论和工具集------它让看似"随机"的GenAI行为,变得透明、可控、值得信赖。
4.5.1 量化成败:像A/B测试一样衡量AI智能体的表现
要优化 AI 智能体,首先得明确在你的业务场景中,"更好"究竟意味着什么。不妨把智能体的可观测性策略设计得像一场 A/B 实验,先问自己:哪些关键绩效指标(KPI)能证明智
能体确实创造了价值?这些指标不能只看技术层面的正确性,更要衡量实际业务影响,比如目标完成率(比如成功订票、提交表单)、用户满意度(如"点赞/点踩"反馈)、任务延迟时间(用户等了多久?)、每次交互的运营成本(用了多少算力?调用了多少API?),而最重要的,是对营收、转化或客户留存等业务目标的推动作用。这种自上而下的视角会指导后续所有测试工作,让你走上数据驱动的开发之路,还能帮你计算投资回报率。
4.5.2 告别"非对即错",用大模型做质量裁判
业务指标没法告诉你 AI 智能体的行为是否合理。既然简单的"通过/失败"评判标准行不通,我们就转而用"大语言模型充当裁判"的方式来评估智能体的输出质量。具体来说,就是用一个性能强大的大语言模型,对照预设的评分标准来检验智能体的输出:答案是否正确?回复是否有事实依据?是否遵循了指令要求?基于一套标准化的提示词数据集来开展这种自动化评估,能得到客观且一致的质量评分结果。
构建评估数据集------其中包含理想的(或"标准的")问题和正确回复------是个繁琐的过程。搭建这类数据集时,你需要从智能体在生产或开发环境中的实际交互案例里抽取场景。数据集不仅要覆盖用户可能遇到的所有常规使用场景,还得包含一些意外情况。虽然投入精力做评估能很快看到回报,但评估结果在被认定有效前,必须经过领域专家的审核。如今,在领域专家的支持下,设计和维护这些评估体系,正逐渐成为产品经理的核心职责之一。
用一个更强大的大语言模型作为"裁判"(LM as Judge),来自动评估智能体的回答质量。具体怎么做?
- 事先定义一套清晰的评分标准(rubric),比如:
。它给出了正确的答案吗?
○内容是否有事实依据(而非胡编乱造)?
。是否遵守了指令(比如语气、格式、安全限制)?
- 然后,让这个"裁判模型"对智能体在一组标准测试问题上的回答打分。这套自动化评估系统,通常运行在一个叫"黄金数据集"(golden dataset)的测试集上------里面包含精心设计的问题和理想答案。它能提供一致、可重复的质量度量。
黄金数据集怎么来?
构建这个数据集确实费时,但回报巨大。建议:
-
从真实用户与智能体的历史对话中抽样;
-
覆盖所有预期的使用场景;
-
还要故意加入一些"意外情况"(比如模糊提问、极端请求)。
虽然自动化评估很强大,但每次结果都应由领域专家复核,确保评分合理。如今,越来越多的产品经理开始承担起评估体系的设计与维护职责,并在领域专家的支持下持续优化。
4.5.3 以指标驱动开发:决定智能体是否上线的关键
当你完成了数十个评估场景的自动化搭建,并且确立了可靠的质量评分体系后,就可以放心地测试开发版智能体的改动效果了。流程其实很简单:让新版本智能体跑完整个评估数据集,再将它的评分与当前生产环境中的版本直接对比。这套完善的体系能杜绝主观猜测,让你对每次上线都胸有成竹。不过,自动化评估虽然关键,也别忘了延迟、成本和任务成功率这些其他重要指标。为了最大程度保证安全,你可以采用A/B发布的方式逐步推出新版本,同时对比真实生产环境中的这些指标和模拟测试的评分。
彻底告别"凭感觉上线"
当你积累了几十个甚至上百个自动化评估场景,并建立了可信的质量评分体系后,就可以自信地测试智能体的任何改动了。
流程很简单:
-
用新版本的智能体跑一遍完整的评估数据集;
-
将它的各项得分与当前线上版本直接对比。
这套机制彻底告别"凭感觉上线",让你对每一次部署都心中有数。
当然,除了质量分数,别忘了其他关键因素:
-
响应速度 (latency)
-
运行成本
-
实际任务成功率
为了最大限度保障安全,建议采用A/B部署:先让一小部分用户试用新版本,同时对比模拟评估分数和真实生产环境中的业务指标,双重验证效果。
4.5.4 用OpenTelemetry追踪调试:找到问题的"根因"
当指标出现下滑,或者用户反馈 bug 时,你得弄清楚问题的"症结"所在。
OpenTelemetry追踪功能就像一份高保真的"执行日志",能一步步记录下AI智能体的完整运行路径(轨迹),帮你调试智能体的每一步操作。通过追踪记录,你能看到发送给模型的具体提示词、模型的内部推理过程(如果可获取)、智能体选择调用的具体工具、为该工具生成的精确参数,以及工具返回的原始观测数据。初次接触追踪记录可能会觉得复杂,但它
能提供诊断和修复问题根本原因所需的全部细节。追踪记录里的关键信息可以转化为指标,但查看追踪记录主要是为了调试,而非对整体性能做概览。像谷歌云追踪(Google Cloud Trace)这类平台能无缝收集追踪数据,还能对海量追踪记录进行可视化展示和检索,让根因分析的过程更高效。
OpenTelemetry追踪会完整记录智能体执行过程中的每一步轨迹(trajectory),包括:
-
发送给大语言模型的完整提示词 (prompt)
-
模型的内部推理过程(如果可用)
-
它选择了哪个工具
-
为该工具生成的具体参数
-
工具返回的原始观测数据(observation)第一次看追踪日志可能会觉得复杂,但它提供了定位根本原因所需的全部细节。
4.5.5 珍视人工反馈:为自动化优化指明方向
人工反馈绝非需要应付的麻烦事,而是优化AI智能体最有价值、信息最丰富的资源。当用户提交bug报告,或是点击"差评"按钮时,其实是给了你一份礼物:一个自动化评估场景没覆盖到的真实边缘案例。收集并汇总这些数据至关重要------当你发现大量相似的反馈,或是指标出现显著下滑时,必须把这些情况与分析平台关联起来,从中提炼洞察,并为运营问题触发告警。一套高效的智能体运营流程会形成"闭环":捕捉用户反馈、复现问题,再将这个具体场景转化为评估数据集中一个全新的、永久的测试用例。这样做不仅能修复当前的bug,还能让系统从此规避这类问题的再次发生。
一个成熟的AgentOps流程,会"闭环"处理这类反馈:
-
捕获用户反馈;
-
复现问题场景;
-
将这个案例永久加入黄金评估数据集。
这样一来,你不仅修复了当前bug,还给系统打了"疫苗"------同类错误再也不会发生。
4.6 AI 智能体的互操作性
当你精心打造了一个高质量的AI智能体后,下一步自然是要让它走出"孤岛"------不仅能与用户互动,还能与其他智能体协作,甚至参与交易。如果继续用"身体"来打比方,那么互联互通就是智能体的"面孔"和"社交能力":它决定了别人能否认出你、听懂你、信任你,并
愿意和你合作。假设你已经为智能体接入了各种工具(如数据库、API、浏览器等),接下来我们就来看看如何让智能体融入更广阔的生态系统。
4.6.1 智能体与人类的交互
智能体与人类最常见的交互方式是通过用户界面实现的。最简单的形式就是聊天机器人:用户输入请求,作为后端服务的智能体处理后返回一段文本。更先进的智能体还能输出JSON这类结构化数据,为丰富、动态的前端体验提供支持。"人机协同(HITL)"的交互模式则包含意图细化、目标拓展、信息确认以及请求澄清等环节。
"计算机操控"是一类特殊的工具应用场景,大语言模型会接管用户界面,过程中通常需要人类的参与和监督。具备计算机操控能力的智能体能够自主判断下一步最优操作,比如跳转到新页面、高亮特定按钮,或是用相关信息预填表单。
高级智能体可以返回结构化数据(如JSON),驱动前端实现动态、丰富的交互体验;还能主动发起"人机交互"(HITL),比如:1)澄清意图:"您是想查订单状态,还是申请退款?";2)扩展目标:"除了航班信息,需要我帮您预订酒店吗?";3)请求确认:"即将为您取消订阅,确定继续吗?"
除了代用户操作界面,大语言模型还能实时调整界面以满足当下需求。实现这一功能的方式有多种:可以借助控制界面的工具(MCP UI),也能通过专门的界面消息系统实现客户端与智能体的状态同步(AG UI),甚至还能生成定制化的专属界面(A2UI)。
MCP UI是基于Anthropic推出的MCP(模型上下文协议)打造的开源工具,主要作用是为AI应用构建丰富且动态的交互界面,让大语言模型能通过它实现对界面的控制与交互。其主要特点如下:
-
多端SDK支持:提供客户端和服务器端软件开发工具包,客户端有React组件和Web组件方便前端集成;服务器端则能通过TypeScript和Ruby等语言的工具,轻松构建交互式界面,比如生成网页表单、操作按钮等元素。
-
安全且灵活:所有远程代码都在沙箱化的 iframe 中执行,能保障主机和用户的使用安全;同时还支持 iframe、远程 DOM 组件等多种内容类型,可匹配不同应用的界面风格。
-
实用场景丰富:常被用于智能聊天应用中,既能提供支持 Markdown 和代码高亮的聊天界面,还能让 AI 通过它调用浏览器自动化、文件操作等外部工具。
AGUI全称为智能体-用户交互协议,是2025年5月由CopilotKit推出的轻量型开源协议,专门解决AI智能体与前端应用的交互标准化问题,能实现客户端与智能体的高效状态同步。其主要优势如下:
-
事件驱动且低开销:采用事件驱动架构,后端会发出约16种标准事件类型,同时接收简洁输入作为参数,这种方式既能减少资源消耗,又能实现高效通信,比如在实时聊天场景中可保障对话流畅不卡顿。
-
兼容性极强:跨框架、跨传输协议,能适配 SSE、WebSocket、Webhook 等多种通信方式,还支持主流的 Agent 框架如 LangGraph、CrewAI 等,且多种语言的 SDK 也在逐步开发中。
-
适配多交互场景:可实现实时流传输、生成式元素展示和协作式工作流,适合客服平台的实时问答、跨设备任务同步、游戏中 NPC 与玩家的实时交互等场景。
当然,人类与智能体的交互并非只局限于屏幕和键盘。先进的智能体正突破纯文本的限制,通过"实时模式"实现多模态的实时沟通,建立更自然、更贴近人类交流的连接。像 Gemini Live API 这类技术支持双向流式传输,用户可以和智能体语音对话,还能像日常交流一样随时打断它。
这种能力从根本上改变了人机协作的本质。智能体借助设备的摄像头和麦克风,能"看到"用户所见、"听到"用户所说,并以接近人类对话的延迟生成语音回应。这催生了许多纯文本交互无法实现的应用场景:技术人员维修设备时可获得免手持的语音指导,消费者购物时能得到实时的穿搭建议。智能体由此成为更直观、更易使用的协作伙伴。
4.6.2 智能体与智能体的交互
智能体既要与人类交互,也需要彼此互联。当企业扩大AI的应用规模时,不同团队会开发出不同的专业智能体。如果没有统一标准,连接这些智能体就需要搭建一套杂乱且脆弱的定制API集成体系,其维护难度极高。这一问题的核心挑战主要体现在两个方面:一是发现(我的智能体如何找到其他智能体,并知晓它们的功能?);二是通信(如何确保它们能"听懂"彼此的"语言"?)。
随着企业广泛采用Agentic AI,不同团队会开发出各种专业智能体------客服智能体、财务智能体、研发智能体......如果不加管理,它们就会变成一个个"信息孤岛",彼此之间靠脆弱、定制化的API艰难沟通,维护成本极高。
Agent2Agent(A2A)协议正是为解决这一问题设计的开放标准,堪称智能体经济的"通用握手协议"。通过A2A协议,任何智能体都能发布一份数字"名片"(即Agent Card)。这份简洁的JSON文件会列明智能体的功能、网络端点,以及与之交互所需的安全凭证,让智能体的发现过程变得简单且标准化。与聚焦于处理事务性请求的MCP不同,A2A协议下的智能体间通信通常用于协同解决更复杂的问题。
智能体完成发现后,会基于任务导向的架构进行通信。它们不再局限于简单的"请求-响应"模式,而是将交互转化为异步的"任务":客户端智能体向服务端智能体发送任务请求,服务端智能体则能通过长连接在处理问题的过程中持续推送进度更新。这套稳健、标准化的通信协议,是实现自动化前沿领域------协作式三级多智能体系统的最后一块拼图。A2A协议让原本孤立的一堆智能体,真正融合成一个可互操作的智能生态。
与专注于事务性请求的MCP不同,A2A通信更侧重于协同解决问题。一旦发现彼此,智能体就通过面向任务的架构进行协作:
1)不再是简单的"请求-响应";
2)而是发送一个异步任务(task);
3)接收方在长时间连接中持续返回进度更新。这种稳健、标准化的通信机制,正是构建Level3多智能体系统(即高度自主、深度协作的自动化系统)的关键拼图。
4.6.3 智能体与交易的结合
当智能体帮我们完成越来越多的任务时,其中一些自然会涉及购买、销售、谈判或促成交易。当前的互联网是为人类点击"购买"按钮设计的,责任由人类承担。但如果是自主智能体点击了"购买",就会引发信任危机------一旦出现问题,该由谁来负责?这涉及到授权、真实性和问责制等深层问题。要构建真正的Agentic AI经济,就需要全新的信任基础设施来保障智能体能代表用户安全、可靠地完成交易。
这一新兴领域尚未形成成熟体系,但已有两大核心协议奠定了基础。智能体支付协议(Agent Payments Protocol,AP2)是为智能体商务打造的权威开放式协议,它在A2A等协议的基础上引入了加密签名的数字"授权书"。这份授权书可作为用户意图的可验证证明,为每一笔交易建立不可抵赖的审计追踪记录,让智能体能基于用户的委托授权,在全球范围内安全地浏览商品、协商交易并完成支付。
与之互补的是 x402 协议,这是一种开放式互联网支付协议,它利用标准的 HTTP 402"Payment Required(需要支付)"状态码,实现了无摩擦的机器对机器的微支付。借助 x402,智能体可以按使用量为 API 调用、数字内容等服务付费,无需搭建复杂的账户体系或订阅服务。这两大协议共同为 Agentic AI 网络构建起了关键的信任基础层。
4.7 单个智能体的安全:信任的权衡
在AI智能体的开发与应用中,安全始终是绕不开的核心问题。从单智能体的权限平衡,到为智能体赋予独立身份,再到通过策略与工具构建多层防护体系,每一步都决定着智能体能否在发挥效用的同时,规避潜在风险。本文将拆解AI智能体安全的核心逻辑,让你理解如何打造"既好用又安全"的智能体。
当你开发出第一个AI智能体时,会立刻面临一个核心矛盾:实用性与安全性的权衡。要让智能体发挥作用,就必须赋予它一定的"权力"------自主做决策的能力,以及发送邮件、查询数据库等操作工具的权限。但每多赋予一分权限,就会多一分风险。智能体的主要安全隐患集中在两方面:一是越权行为(非预期或有害的操作),二是敏感数据泄露。理想状态是给智能体一条足够长的"狗绳",让它能完成任务;但又不能太长,以免它冲上马路------尤其是当这条马路通向不可逆的操作(比如删除数据)或核心商业机密时。
要管控这类风险,不能只依赖大语言模型的自主判断,因为它可能被提示词注入等手段操控。业界公认的最佳实践是采用混合式的纵深防御策略,通过两层防护构建安全屏障:
为什么不能只靠大模型自己判断。因为大语言模型很容易被"骗"。比如通过提示词注入(Prompt Injection)攻击,攻击者可能诱导智能体绕过限制、执行恶意指令。
1)第一层:硬性规则(传统防护)
这是一套写死在代码里的规则,相当于智能体外部的"安全卡口",和模型的推理过程相互独立。比如可以搭建一个策略引擎,设定"禁止执行超过100美元的采购操作"、"智能体调用外部API前必须获得用户明确确认"等规则。这一层防护为智能体的权限划定了明确、可审计的硬边界,让风险可控。
这是最外层的"安全闸口",由确定性的代码规则构成,完全独立于模型推理过程。这类规则的好处是:可预测、可审计、绝对可靠------无论模型怎么想,这些红线都不能碰。
2)第二层:AI辅助防御(智能防护)
简单来说,就是"用AI守护AI"。一方面通过对抗训练让大语言模型更能抵御攻击,另一方面部署小型的专业"防护模型",让它们像安全分析师一样工作。这些防护模型会在智能体执行计划前,先检查其拟定的步骤,标记出可能有风险或违反策略的操作,等待人工复核。这种"代码的刚性约束+AI的语境感知"相结合的混合模式,即便是单个智能体,也能拥有稳健的安全状态,确保其能力始终服务于预设目标。
4.7.1 智能体身份:全新的主体类型
在传统的安全模型里,只有两类核心主体:一是使用 OAuth 或单点登录(SSO)的人类用户,二是采用身份与访问管理(Identity and Access Management, IAM)或服务账号的服务程序。而AI智能体的出现,带来了第三类主体。
智能体不只是一段代码,更是一个能自主行动的个体,需要专属的、可验证的身份。就像员工会获得工牌一样,平台上的每个智能体都该拥有一个安全、可核验的"数字护照"。这种智能体身份,和调用它的用户、开发它的工程师的身份完全独立。这一变化,彻底改写了企业在身份与访问管理(IAM)领域的传统思路。
这标志着企业级IAM体系的一次根本性升级。
为每个智能体赋予可验证的身份,并为其设置精准的访问控制,是智能体安全的基石。当智能体拥有基于SPIFFE等标准的加密可验证身份后,就能被授予"最小权限"------比如让销售智能体拥有客户关系管理系统(CRM)的读写权限,同时明确禁止人力资源入职智能体访问该系统。这种精细化管控至关重要:即便某个智能体被入侵或行为异常,其造成的破坏范围也能被限制。如果没有独立的智能体身份体系,智能体就无法在有限的委托权限下代表人类完成工作。
没有独立身份,智能体就无法代表人类行使有限授权------它要么权限过大,要么寸步难行。
加密可验证的"数字身份证",让这些非人类的"参与者"能在复杂的网络环境中,安全地证明"我是谁",并与其他参与者建立可信通信。它解决的核心问题是:在云原生、多平台、跨组织的系统中,传统的基于IP地址、域名或用户名密码的身份认证方式,要么安全性低,要么难以规模化管理,而SPIFFE能提供与位置无关、统一化的身份体系。
表 1: 不同认证主体的示例 (非完整清单)
|------------------|-------------------------|--------------------------|
| 主体类型 | 认证/验证方式 | 说明 |
| 用户 | 通过 OAuth 或单点登录 (SSO) 认证 | 拥有完全自主权,需为自身行为负责的人类个体 |
| AI 智能体(新型主体、新类别) | 通过 SPIFFE 标准验证 | 拥有委托权限,代表用户执行操作的 AI 个体 |
| 服务账号 | 集成于身份与访问管理 (IAM) 系统 | 完全遵循预设逻辑的应用程序或容器,无需为行为负责 |
4.7.2 用策略约束访问权限
策略是一种授权(AuthZ)机制,和身份认证(AuthN)是两回事。简单来说,策略是用来限制主体能力的规则,比如"市场部员工只能访问这27个API端点,且禁止执行删除(DELETE)指令"。
在开发智能体时,我们需要把权限管控延伸到智能体本身、它使用的工具、企业内部其他智能体、它能共享的上下文,以及外部的远程智能体。可以这么理解:当你把各类API、数据、工具和智能体都纳入系统后,必须把它们的访问权限限定在"完成工作所需的最小范围"内。这就是业界推荐的最小权限原则,同时还要保证权限与实际业务场景相匹配。
认证(AuthN)解决"你是谁",而授权(AuthZ)解决"你能做什么"。策略(Policy)就是授权的具体体现。对智能体而言,策略必须覆盖更广的范围:
-
智能体自身能做什么;
-
它使用的工具能访问哪些资源;
-
它能否与其他内部或远程智能体通信;
-
它能共享哪些上下文信息。核心原则是:只开放完成任务所必需的最小能力集,同时保持足够的上下文灵活性。
4.7.3 ADK 智能体的安全保障
确立了身份与策略的核心原则后,用智能体开发工具包(ADK)构建安全的智能体,就变成了通过代码和配置落地这些理念的实操过程。
有了身份和策略两大基石,使用Agent Development Kit(ADK)构建安全智能体就变成了一项工程实践。
首先要清晰定义三类身份:用户身份(如基于 OAuth 的账号------谁在使用?)、服务身份(用于运行代码的账号------谁在托管?)、智能体身份(用于行使委托权限的 SPIFFE 数字护照------谁在行动?)。完成身份认证后,下一步是通过策略构建防护层,约束智能体对各类服务的访问------这通常在 API 治理层实现,同时为 MCP 和 A2A 服务提供治理支持。
再往下,需要在工具、模型和子智能体中嵌入防护规则,确保无论大语言模型做出何种推理,或是遭遇恶意提示词诱导,工具自身的逻辑都会拒绝执行不安全、违反策略的操作。这种方式能打造可预测、可审计的安全基线,将抽象的安全策略转化为具体、可靠的代码逻辑。
在每个工具、子智能体甚至模型内部,硬编码安全逻辑。无论大语言模型如何推理,也无论提示词多么狡猾,工具本身会拒绝执行越权或危险操作。这将抽象的安全策略,转化为可执行、可审计的代码。
为了实现能适配智能体运行时行为的动态安全防护,ADK还提供了回调函数与插件机制:before_tool_callback(工具调用前回调)能在工具执行前检查调用参数,结合智能体现有状态验证参数合法性,避免操作偏差;如果需要可复用的策略,还能开发专属插件。一种常见的做法是"以Gemini为裁判":用GeminiFlash-Lite这类轻量、高速的模型,或是自研微调的Gemma模型,实时筛查用户输入和智能体输出,识别提示词注入或有害内容。
对于希望采用全托管企业级方案来实现动态安全检查的机构,还可以选装Model Armor服务。这款专用安全层能全面筛查提示词和响应内容,防范提示词注入、越狱攻击、个人敏感信息(PII)泄露、恶意链接等多种威胁。把这些复杂的安全任务交给专业服务,开发者无需自行构建和维护防护规则,就能获得一致、稳健的安全保障。
在 ADK 中,将强身份体系、工具内的确定性逻辑、AI 驱动的动态防护栏,与 Model Armor 这类可选托管服务相结合的混合方案,正是打造"既强大又可信"的单智能体的关键所在。
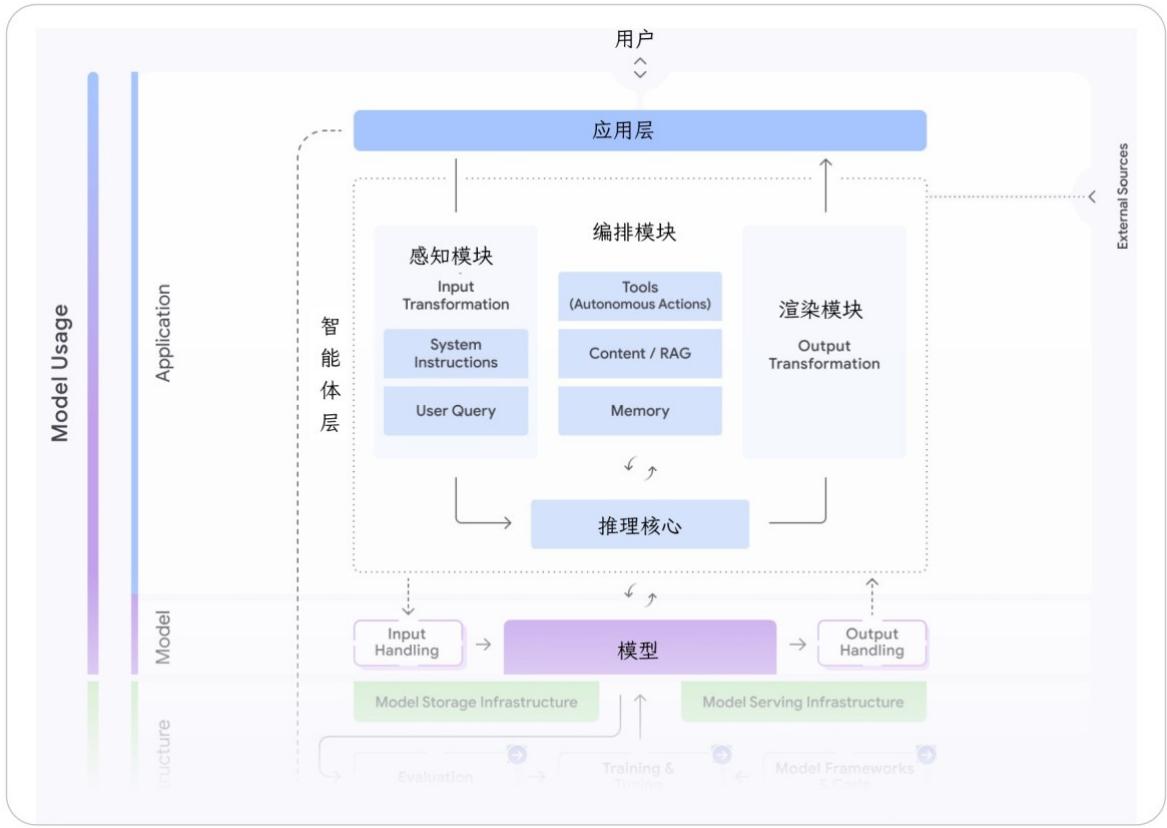
图6:安全与智能体
ADK 提供了更灵活的动态安全机制:
-
回调函数(Callbacks)。例如 before_tool_callback:在工具执行前检查参数;可根据当前任务状态,阻止不匹配的操作。
-
插件系统 (Plugins)。可封装通用安全策略,比如部署一个轻量级"裁判模型";使用 Gemini Flash-Lite 或微调后的 Gemma 模型,实时扫描输入输出,防范提示词注入或有害内容。这就是所谓的 "Gemini as a Judge" 模式------用一个小而快的模型,为大模型的行为把关。
-
托管安全服务:Model Armor(可选)。对于希望开箱即用的企业,Google 提供 Model Armor 作为增强防护层。它能自动检测:提示词注入;越狱攻击(Jailbreak);敏感信息(如身份证号、银行卡)泄露;恶意链接等威胁。开发者无需自行构建这些复杂机制,即可获得一致、可靠的安全保障。
一个既强大又可信的 AI 智能体,依赖于以下四层防护的协同:
-
独立身份:每个智能体都有自己的"数字护照";
-
最小权限策略:只给完成任务所需的最低权限;
-
确定性护栏:在工具层硬编码安全规则;
-
动态 AI 防护:通过回调、插件或 Model Armor 实现实时防御。这不仅是技术方案,更是 Agentic AI 时代的安全新范式。只有这样,我们才能放心地让智能体走出实验室,真正融入工作流,成为值得托付的数字伙伴。
4.8 从单个智能体到企业级集群的规模化扩展
单个 AI 智能体的成功是胜利,成百上千个则是架构的挑战。
如果你只构建一两个AI智能体,你的主要关注点可能是安全问题。但当你需要部署成百上千个智能体时,挑战就不再只是"是否安全",而是"如何系统性地管理整个体系"。
这就像API(应用程序接口)数量失控一样------当AI智能体和它们所调用的工具在企业内部迅速扩散时,会形成一个错综复杂的交互网络:数据四处流动、权限边界模糊、潜在的安全漏洞激增。要驾驭这种复杂性,就必须引入更高层级的治理体系,把所有身份认证、策略规则和监控报告都整合进一个中央控制平台。
4.8.1 安全与隐私:筑牢AgenticAI的防线
即使是运行单个AI智能体,企业级平台也必须认真应对GenAI带来的独特安全与隐私挑战。因为智能体本身就是一个新的攻击入口。
恶意用户可能通过"提示词注入"(prompt injection)篡改智能体的行为指令,或者通过"数据投毒"污染其用于推理或检索增强生成(RAG)的信息源。更危险的是,如果智能体缺乏有效约束,它可能在回答中无意泄露客户敏感信息或公司机密。
一个真正可靠的平台,必须采用"纵深防御"策略来化解这些风险:
-
从数据源头做起:确保企业的专有数据绝不会被用于训练基础大语言模型,并通过如VPC服务边界(VPC Service Controls)等机制加以保护。
-
输入输出双重过滤:就像为网络通信设置防火墙一样,对用户输入的提示词和智能体输出的回复进行严格审查。
-
法律与技术双重保障:平台应提供知识产权赔偿承诺,既覆盖训练数据,也覆盖生成内容,让企业在部署智能体时既有技术底气,也有法律信心。
4.8.2 智能体治理:用控制平面替代无序扩张
当 AI 智能体及其工具在组织内大量涌现时,就会出现所谓的"智能体蔓延"(agent sprawl)------无数独立运行的组件彼此交织,形成难以管控的复杂生态。
解决之道,不是逐个加固每个智能体,而是构建一个统一的架构中枢:一个作为所有Agentic AI活动"必经之路"的中央网关,也就是控制平面(control plane)。
想象一座拥有成千上万辆自动驾驶汽车的城市------用户、智能体、工具都在其中自主运行。如果没有红绿灯、车牌管理和交通指挥中心,城市将陷入混乱。而这个控制平面,正是那个"交通指挥系统"。
它强制所有Agentic AI的交互都必须经过这一关口,包括:
-
用户向智能体发送提示或操作界面请求;
-
智能体调用外部工具(通过MCP协议);
-
智能体之间的协作(通过A2A协议);
-
甚至直接向大语言模型发起的推理请求。
在这个关键节点上,企业可以对每一次交互进行检查、路由、监控和管理。
这个控制平面承担两大核心功能,二者紧密相连:
-
运行时策略执行。它是安全策略落地的"咽喉要道"。在这里,系统验证身份("我知道你是谁吗?")并检查权限("你有权做这件事吗?")。集中化的策略执行带来了"一屏统览"的可观测性------所有交互都会生成统一的日志、指标和追踪记录,把原本杂乱无章的智能体网络变成透明、可审计的系统。
-
集中化治理。要有效执行策略,控制平面需要一个权威的"信息源"------这就是中央注册中心,你可以把它理解为企业内部的"智能体与工具应用商店"。
开发者可以在这里发现并复用已有的智能体或工具,避免重复造轮子;管理者则能掌握完整的资产清单。更重要的是,它支持对智能体和工具实施全生命周期管理:上线前的安全审查、版本控制,以及精细化的访问策略(例如,"只有财务部门才能使用报销智能体")。
通过将运行时网关(runtime gateway)与中央治理注册表(central governance registry)相结合,企业就能把原本失控的"智能体蔓延"转化为一个有序、安全且高效运转的生态系统。
4.8.3 成本与可靠性:夯实基础设施的根基
最终,企业级AI智能体必须同时做到可靠和经济。一个经常出错或响应迟缓的智能体,投资回报率为负;而一个成本高昂到无法承受的智能体,则根本无法规模化。
因此,底层基础设施必须能在性能、成本与合规之间取得平衡------尤其是在满足数据主权和监管要求的前提下。
具体来说:
-
对于访问量不稳定的智能体或子功能,平台应支持"按需伸缩至零"(scale-to-zero),避免资源浪费;
-
对于关键业务场景(如客户服务或实时决策),则需要专用资源保障,比如大语言模型服务的"预置吞吐量"(Provisioned Throughput),或运行环境(如Cloud Run)提供的 99.9%99.9\%99.9% 服务等级协议(SLA),确保在高负载下依然快速响应。
通过提供多样化的基础设施选项,并配套全面的成本与性能监控能力,企业才能真正把AI智能体从"有趣的实验"转变为值得信赖的核心业务组件。
4.9 智能体如何进化与学习
在现实世界中部署的AI智能体,往往运行在不断变化的环境中------政策法规、技术工具和数据格式都在持续演进。如果智能体缺乏自我适应能力,其表现就会随着时间推移而逐渐退化,这种现象常被称为"老化"(aging),最终导致其效用下降,用户信任流失。
手动为大量AI智能体逐一更新以跟上这些变化,既费时又昂贵。更可扩展的解决方案,是设计能够自主学习与进化的智能体------它们可以在实际工作中不断提升自身能力,几乎无需人工干预。
4.9.1 智能体如何学习与自我进化
就像人类一样,AI智能体也通过经验与外部反馈来学习。这种学习过程主要依赖以下两类信息来源:
-
运行时经验(Runtime Experience):智能体从实际运行中积累知识,比如会话日志、执行轨迹、内部记忆等,这些记录了成功与失败案例、工具调用过程以及决策路径。尤其重要的是人机协同(Human-in-the-Loop, HITL)------即人类用户提供的明确纠正或指导,这是最权威的学习信号。
-
外部信号(External Signal):智能体也会从新出现的外部资料中学习,例如企业最新政策、公开的监管指南,甚至来自其他智能体的批评意见。
有了这些信息,智能体就能优化未来的行为。先进的系统不会仅复述过去的交互,而是会生成可泛化的知识产物,用于指导后续任务。目前最有效的自适应方法主要分为两类:
-
增强上下文工程(Enhanced Context Engineering):系统会持续优化提供给大语言模型的提示词(prompt)、少量示例(few-shot examples)以及从记忆中检索的信息。通过动态调整每次任务的上下文,提高任务成功的概率。
-
工具优化与创建(Tool Optimization and Creation):智能体在推理过程中能识别自身能力的不足,并主动弥补。例如,它可以接入一个新工具、即时编写一个Python脚本,或修改现有工具的接口定义(如更新API规范)。
此外,还有一些前沿技术正在积极探索中,比如动态重构多智能体协作模式,或采用基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF)等方法。
实例:学习新的合规指南
设想一个在金融或生命科学等强监管行业工作的企业级AI智能体,它的任务是生成符合隐私与法规要求(如GDPR)的报告。
这一过程可通过一个多智能体协作流程实现:
-
查询智能体 (Querying Agent):响应用户请求,获取原始数据。
-
报告智能体(Reporting Agent):将数据整合成初步报告。
-
审查智能体(Critiquing Agent):依据已知合规规则审核报告。若遇到模糊地带或需最终确认,它会将问题提交给人类专家。
-
学习智能体(Learning Agent):全程观察整个流程,特别关注人类专家的修正意见,并将这些反馈提炼为可复用的新规则------例如更新审查智能体的判断标准,或优化报告智能体的生成上下文。
举个例子:如果人类专家指出"家庭统计数据必须匿名化",学习智能体会记录这一规则。下次生成类似报告时,审查智能体就会自动应用该规则,从而减少对人工干预的依赖。
这种"审查一反馈一泛化"的闭环机制,使整个系统能够自主适应不断变化的合规要求。
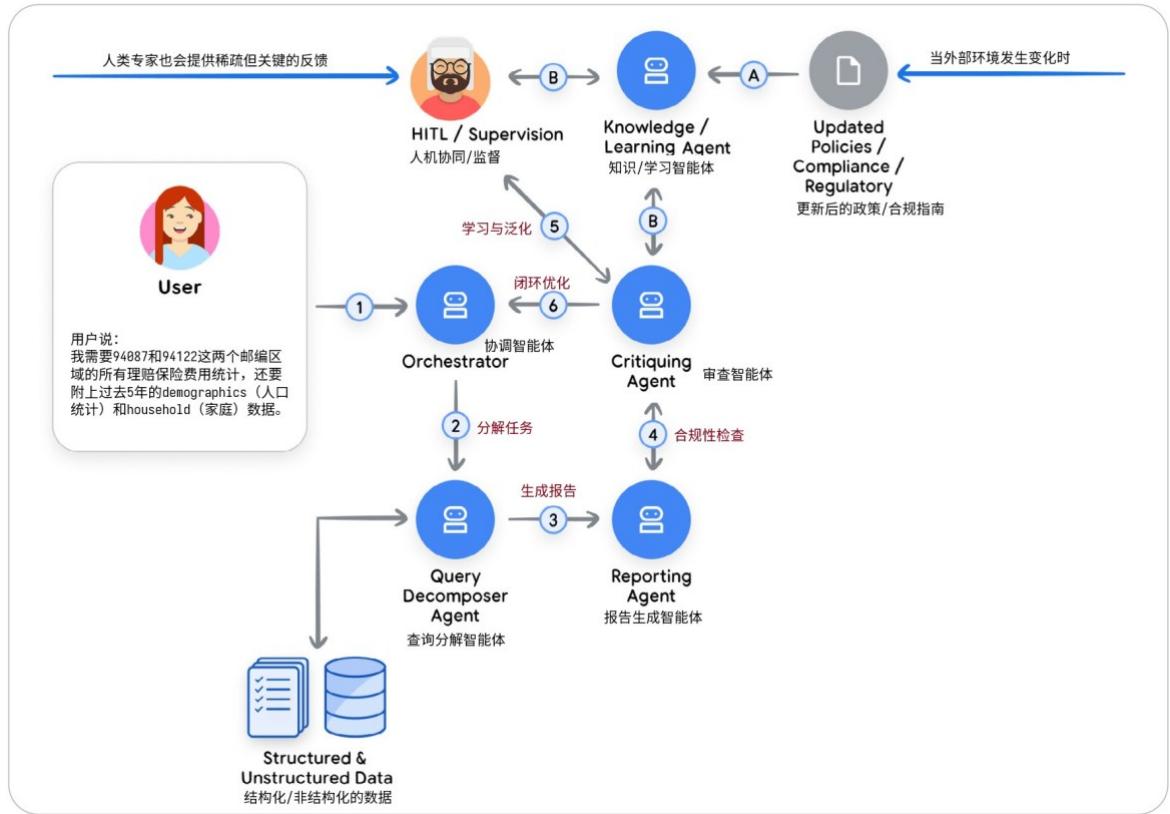
图7:多智能体协作系统在处理合规性任务时的典型工作流程
第1步:用户提出需求(1)。用户说:"我需要94087和94122这两个邮编区域的所有理赔保险费用统计,还要附上过去5年的demographics(人口统计)和household(家庭)数据。"这个请求被发送给系统的"总指挥"------协调智能体(Orchestrator)。
第2步:分解任务(2)。协调智能体将用户的复杂请求拆分成多个子任务,交给专门的智能体去执行。它把任务交给:查询分解智能体(Query Decomposer Agent),负责理解并解析具体的数据需求。接着,查询分解智能体从数据库中提取结构化和非结构化的数据(比如表格、文档等)。
第3步:生成报告( 3→43\rightarrow 43→4 )。获取到数据后,系统进入下一步:报告生成智能体(Reporting Agent)开始撰写初稿报告。然后,这份报告交给审查智能体(Critiquing Agent)进行合规性检查。审查智能体的作用是:"这个报告有没有违反隐私政策?有没有暴露敏感信息?是否符合最新的监管要求?"如果一切正常,报告就可以交付;但如果发现问题,就会触发后续的学习机制。
第4步:引入外部信号(A和B)。当外部环境发生变化时(例如:新的合规政策出台),系统会接收这些更新:A路径:更新后的政策/合规指南(如GDPR修订版)被输入到知识/学习智能体(Knowledge/Learning Agent)。B路径:人类专家也会提供稀疏但关键的反馈(sparse domain expert feedback),比如:"注意!不能透露家庭收入细节!"这些信息都汇集到"知识/学习智能体",它是整个系统的"大脑升级中心"。
第5步:学习与泛化(5)。当审查智能体发现某个问题(比如某项数据未匿名化),而人类专家确认了这个问题并给出纠正建议时:学习智能体会记录下这次互动;它会从中提炼出一条通用规则(例如:"所有涉及家庭收入的数据必须脱敏");并将这条新规则传递给审查智能体或其他相关智能体。
第6步:闭环优化(6)。最后,学习到的新规则会反馈回系统中,影响未来的决策过程:下次生成类似报告时,审查智能体会自动应用这条新规则;协调智能体也可能根据新知识调整任务分配逻辑。
这形成了一个完整的"执行---反馈---学习---优化"闭环。这种"在线运行 + 离线学习"的模式,正是Agentic AI走向成熟的关键一步。它不仅能让AI智能体更聪明、更可靠,也让它们真正具备了适应复杂现实世界的能力。
4.9.2 仿真与智能体训练环境:下一代进化平台
上述模式属于内嵌式学习(in-line learning)------即智能体只能依靠其运行时已有的资源和架构进行学习。而更前沿的研究正聚焦于一种全新的范式:智能体健身房(Agent Gym)。
这是一种专为优化多智能体系统而设计的离线训练平台,具备以下关键特性:
-
独立于生产环境:它不在实际执行路径中,因此可以自由调用任意大语言模型、离线工具、云服务等资源,不受线上系统限制。
-
高保真仿真环境:智能体可在模拟环境中"练习"处理新任务,安全地进行试错,并探索多种优化路径。
-
合成数据驱动的压力测试:平台能生成高度逼真的合成数据,甚至引入"红队攻击"(red-teaming)、动态评估机制,以及由多个批评型智能体组成的评估体系,全面检验智能体的鲁棒性。
-
灵活扩展的工具库:工具集并非固定不变。平台可通过开放协议(如MCP或A2A)接入新工具,甚至在高级场景下,自主学习新概念并为其定制专属工具。
-
连接人类专家网络:尽管功能强大,但某些极端边缘情况(尤其是涉及企业内部"部落知识"(tribal knowledge)的问题)仍难以仅靠算法解决。此时,智能体健身房可主动对接领域专家,获取关键指导,为下一轮优化提供方向。
这种"线上运行 + 离线进化"的双轨机制,使得Agentic AI正朝着真正自适应、自完善、自进化的方向迈进------不仅响应变化,更能预见变化,持续为人类创造价值。
5 高级智能体案例
5.1 Google Co-Scientist (谷歌协同科学家)
Google Co-Scientist 是一个高度先进的 AI 智能体系统,旨在扮演科学家的虚拟研究伙伴。它能系统性地探索复杂的科学问题空间,帮助研究人员加速发现新知识。
具体来说,研究人员只需设定一个宏观的研究目标,并指定可信赖的知识来源(包括公开文献和内部专有数据),Co-Scientist 就能自动生成大量新颖的科学假设,并对它们进行评估和筛选------就像一位不知疲倦、知识渊博的合作者。
为了实现这一能力,Co-Scientist并非单打独斗,而是构建了一个由多个AI智能体组成的协作生态系统,各司其职、协同推进。
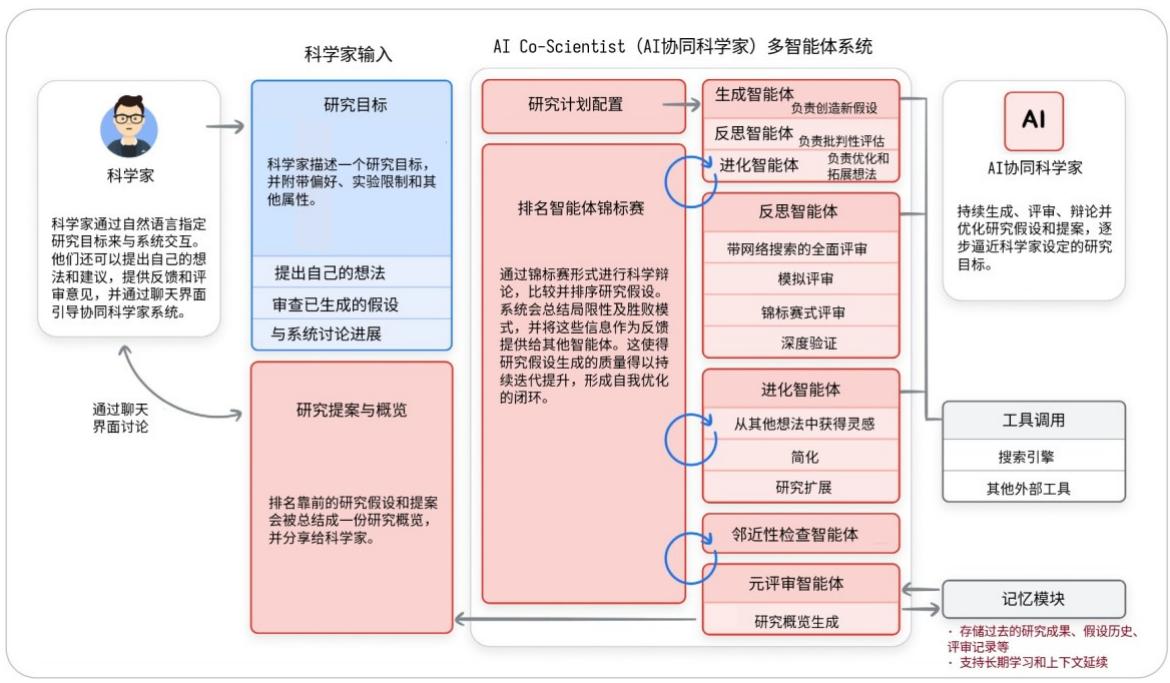
图8:AI"协同科学家"的系统设计
可以把这个系统想象成一位AI项目负责人。
-
它首先接收一个宽泛的研究目标(例如:"寻找治疗某种罕见病的新靶点")。
-
然后,它会自动生成一份详细的科研计划,包括关键步骤、所需资源和评估标准。
-
接着,一个名为"监督智能体(Supervisor Agent)"的角色登场------它就像项目经理,负责将任务分配给不同领域的专业智能体,并动态调配计算资源(如GPU时间、存储等)。
这种架构不仅让整个研究过程具备极强的可扩展性(从一个小想法扩展到大规模探索),还能在推进过程中不断优化方法论,越做越聪明。
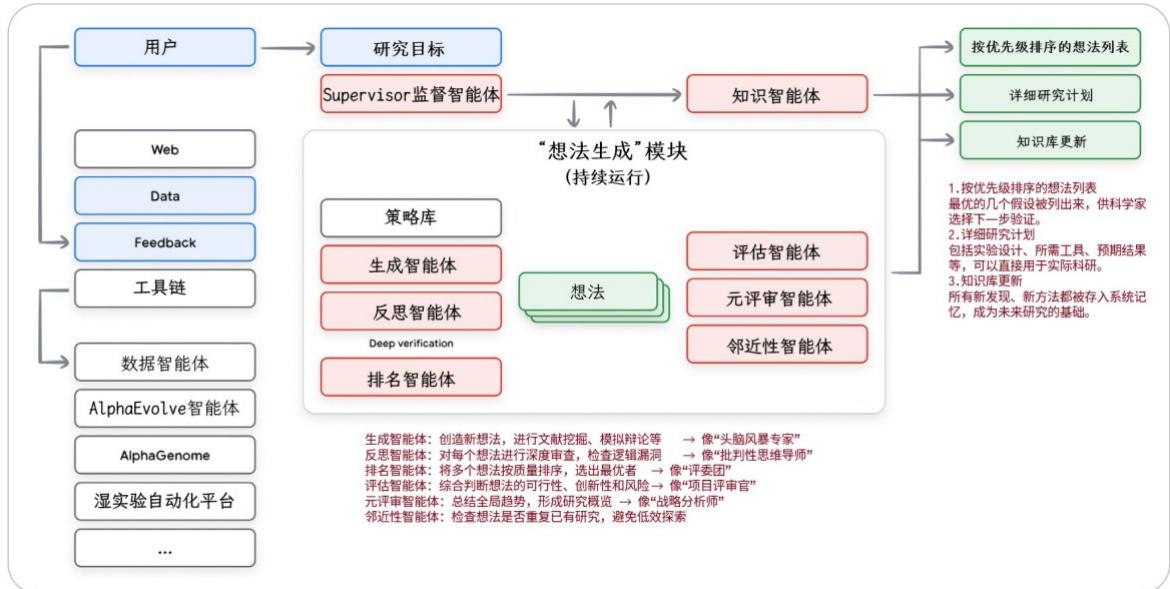
图9:协同科学家的多智能体工作流
在这个系统中,各类AI智能体会持续工作数小时甚至数天,反复迭代、精炼所生成的科学假设。
它们运行的不仅是简单的循环,还有"元循环"(meta-loops)------也就是说,它们不仅改进假设本身,还会反思并优化:
-
如何生成更好的想法?
-
如何更准确地评判一个假设的价值?
这种双重进化机制,使得整个系统不仅能产出高质量的科学洞见,还能不断提升自身的"科研思维能力"。
5.2 AlphaEvolve Agent (阿尔法进化智能体)
另一个先进的Agentic AI系统是AlphaEvolve------一个能够自主发现并优化复杂数学与计算机科学问题算法的AI智能体。
AlphaEvolve 智能体的核心思路很巧妙:它将 Gemini 大语言模型的创造性代码生成能力
与一套自动化的评估系统结合起来,通过类似"生物进化"的方式不断改进解决方案。
具体来说,它的运作流程如下:
-
生成:AI智能体提出多种可能的算法或程序;
-
评估:一个独立的"评判器"对每个方案打分(比如看它是否更快、更省资源);
-
进化:得分最高的方案被保留下来,并作为"基因模板",启发下一代代码的生成。
这个过程会反复迭代,就像大自然通过"适者生存"筛选出更优物种一样,AlphaEvolve能逐步演化出越来越高效的算法。
AlphaEvolve 智能体这种"进化式编程"方法已经带来了多项实际成果,包括:
-
提升谷歌数据中心、芯片设计和 AI 训练的效率(例如:优化任务调度,节省大量电力)
-
发现更快的矩阵乘法算法(矩阵运算是AI和科学计算的基础,哪怕提速 1%1\%1% ,全球都能受益)
-
为一些长期悬而未决的数学难题找到新解法
AlphaEvolve 智能体特别擅长解决一类"验证容易、发现极难"的问题------人类很难凭空想出最优解,但一旦给出答案,却能快速判断它是否正确。这正是 AI 大显身手的舞台。
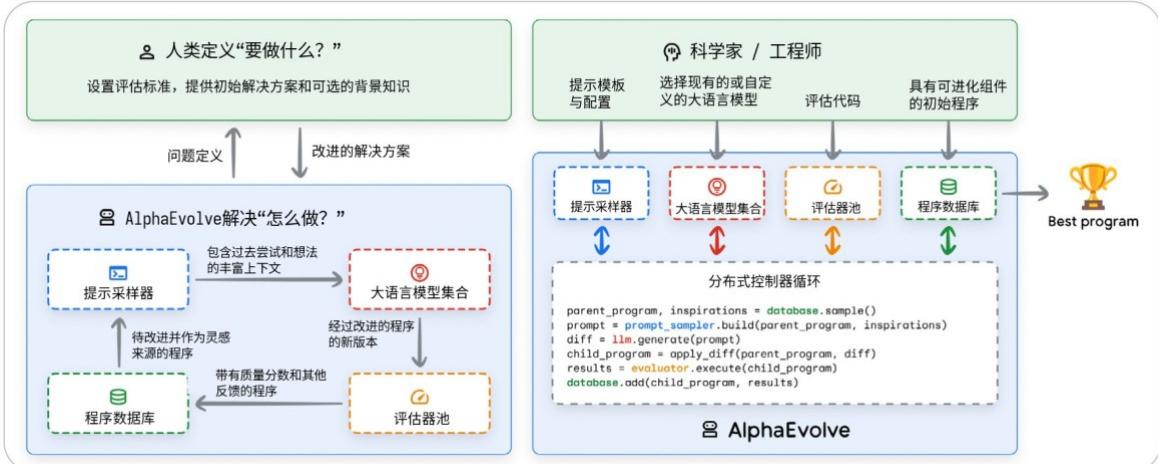
图10:AlphaEvolve设计系统
AlphaEvolve的设计核心,是实现人类与AI之间一种深度、持续迭代的协作关系。这种人机合作主要通过两个关键机制来实现:
1)透明可读的解决方案。AI智能体生成的不是黑箱结果,而是人类可读、可理解的代码。这种透明性让用户能够:看懂算法背后的逻辑,从中获得新的技术洞见,建立对结果的信任,并根据实际需求直接修改或复用代码。换句话说,它交出的不仅是一个"答案",更是一份清晰的"解题过程"。
2)专家引导式探索。人类的专业知识在问题定义阶段至关重要。用户通过以下方式引导AI智能体:一是不断优化评估指标(例如:"不仅要快,还要省电");二是调整搜索方向,避免系统钻规则空子(比如利用评估漏洞生成看似高效但无法落地的"花招代码")。
这种"人机协同"的互动循环,确保最终产出的算法既强大又实用,真正贴合现实需求。
最终,这个AI智能体带来的成果,是一套持续进化的代码------它会不断优化,直到显著提升人类设定的关键指标为止。
图11:算法演化
6 结语
GenAI驱动的AI智能体正标志着人工智能的一次关键跃迁:它不再只是一个被动的内容生成工具,而是转变为能主动思考、自主行动的问题解决伙伴。
本文提出了一套系统的框架,帮助我们理解并构建真正可靠的AI智能体系统------从零散的原型迈向可投入生产环境的成熟架构。
我们将AI智能体拆解为三个核心组成部分:
-
推理模型 (Model) ------相当于"大脑",负责思考与决策;
-
可执行工具(Tools)------相当于"双手",用于与现实世界互动;
-
编排层(Orchestration Layer)------相当于"神经系统",统筹全局流程。
正是这三者通过一个持续不断的"思考 →\rightarrow→ 行动 →\rightarrow→ 观察"循环紧密协作,才真正释放出AI智能体的潜力。
我们还对AgenticAI系统进行了分级:
-
L1 级:连接式问题解决者 (Connected Problem-Solver)
-
L2 级:自主优化型智能体 (Autonomous Optimizer)
-
L3 级:协作式多智能体系统 (Collaborative Multi-Agent System)
这一分类让技术负责人和产品设计师能够根据任务复杂度,合理规划系统能力边界,避免"小题大做"或"力不从心"。
然而,真正的挑战------也是最大的机遇------在于开发范式的根本转变。
我们不再是仅仅堆砌逻辑的"码农"或"砖瓦匠",而是成为系统架构师与智能体导演:需要引导其行为、设定边界、调试其"想法",甚至管理它的"个性"。
大语言模型的强大灵活性,恰恰也是其不可靠性的来源。因此,成功的关键不在于写得多漂亮的初始提示词(prompt),而在于整个系统的工程严谨性------包括:
-
健壮的工具接口契约(tool contracts),
-
强韧的错误处理机制,
-
精细的上下文管理,
-
以及全面的评估体系。
本文所阐述的原则与架构模式,正是迈向这一新范式的基础蓝图。它们是指引我们穿越软件新边疆的路标,帮助我们构建的不只是"自动化流程",而是真正能协作、有能力、可进化的团队新成员。
随着这项技术不断成熟,唯有坚持这种系统化、工程化、架构驱动的方法,我们才能真正驾驭Agentic AI的全部潜能。