PVE安装Ubuntu系统详细过程

1、下载镜像
- 部署主机PVE,确保 PVE 有足够的资源
Ubuntu建议最低配置:1 核 CPU、2GB 内存、20GB 存储
2、上传镜像
- 登录 PVE Web 管理界面(默认地址:https://PVE主机IP:8006)
- 点击ISO镜像,选择上传
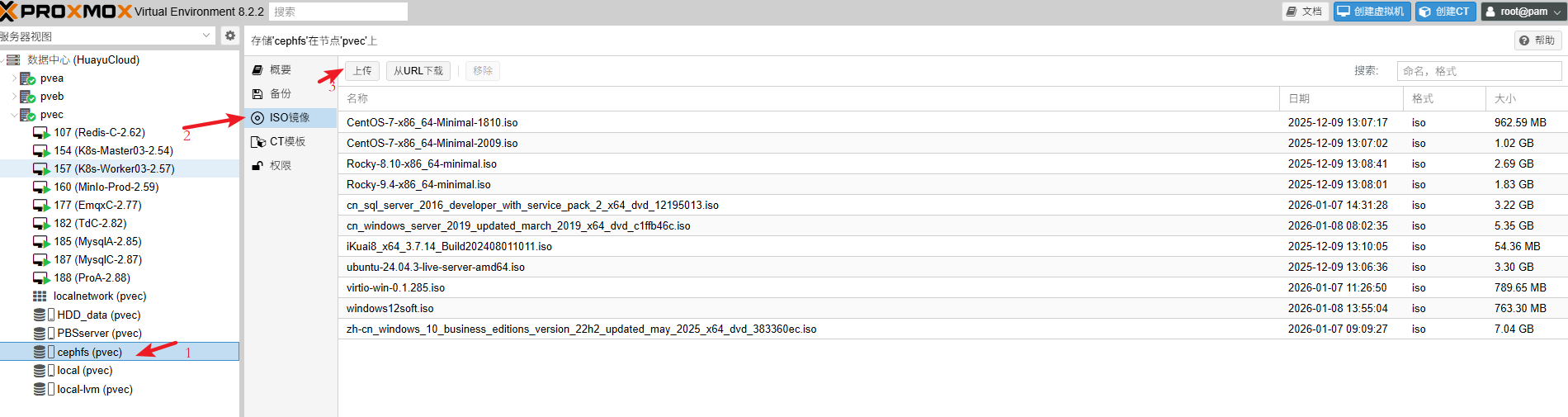
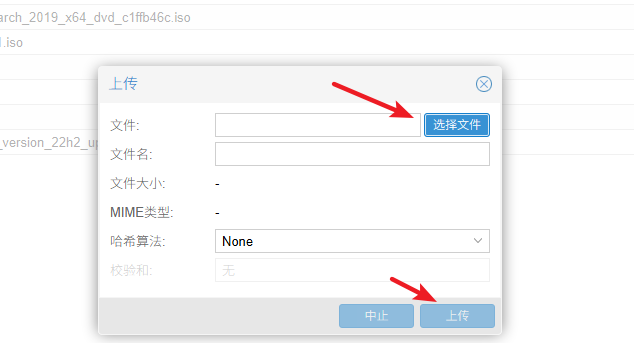
上传完成后,点击完成关闭即可。
3、创建Ubuntu虚拟机
- 选择"创建虚拟机"
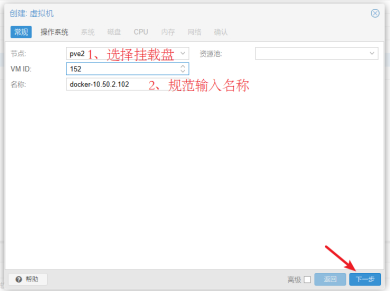
- 选择节点(挂载盘),规范输入名称,点击进入"下一步"
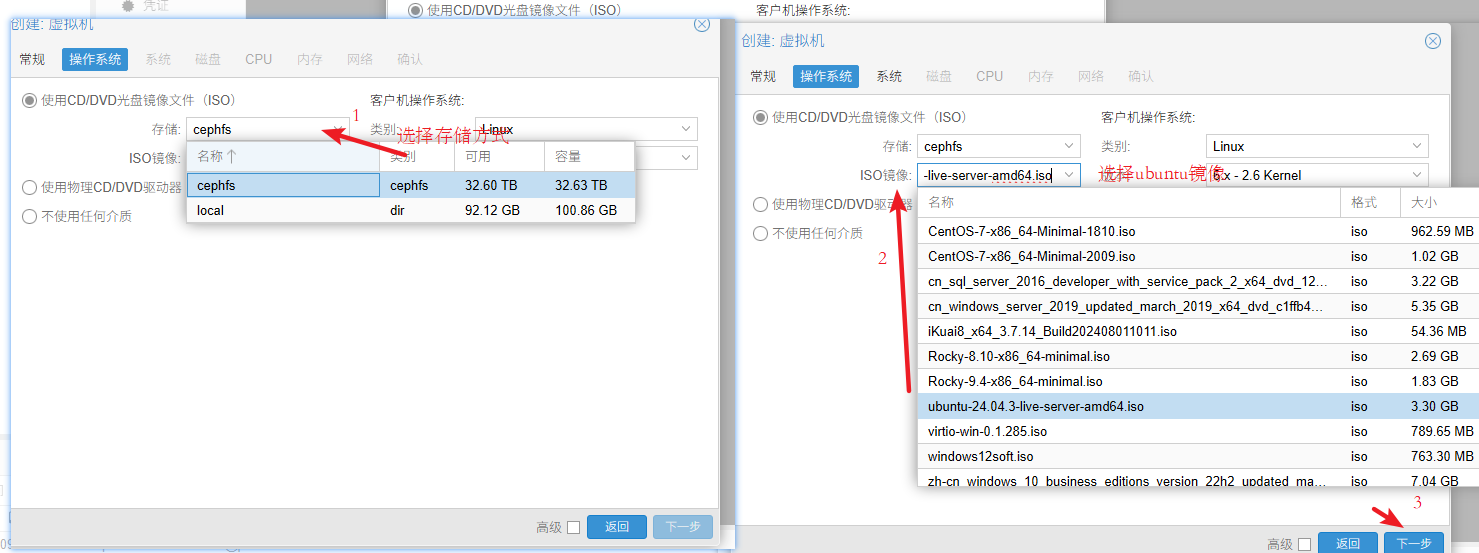
- 选择存储方式和ISO镜像,点击进入"下一步"
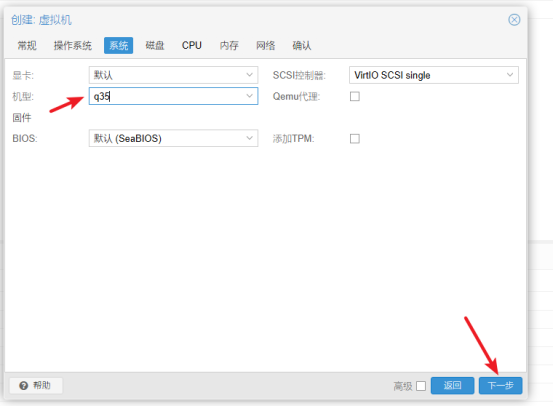
- 系统中选择机型,点击进入"下一步"
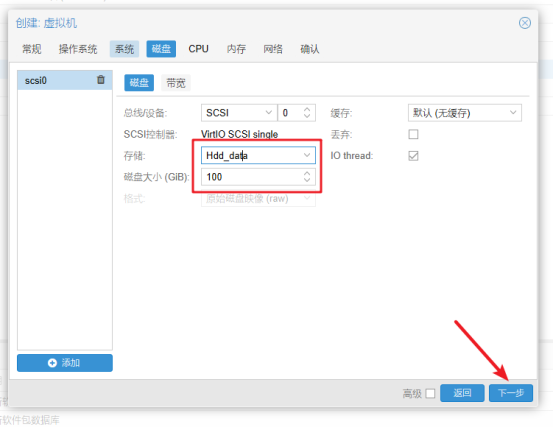
- 磁盘中选择存储,输入磁盘存储内存大小,点击进入"下一步"
- CPU中输入插槽数、核心数和类别,点击进入"下一步"(根据实际服务器需要设置,一般是2的n次方)
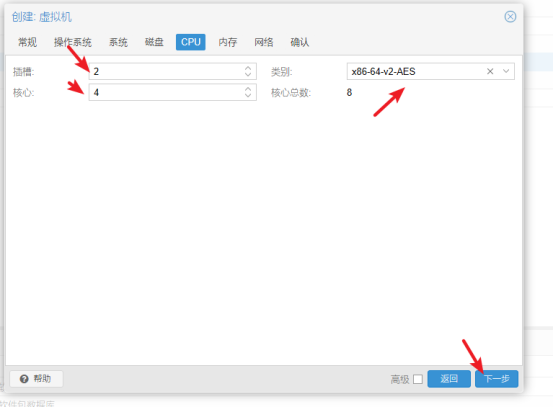
- 在内存中输入运行内存大小(一般是1024* n G),点击进入"下一步"
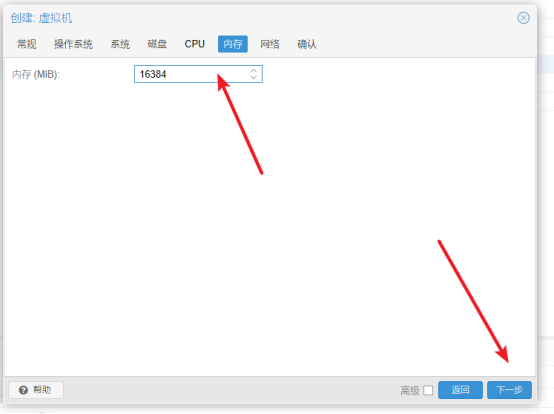
- 在网络中选择桥接方式,点击进入"下一步"
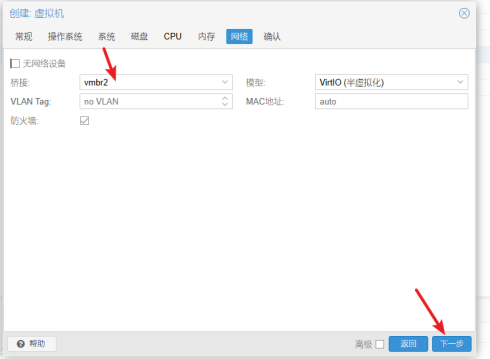
- 确认信息是否正确,无误后点击"完成"
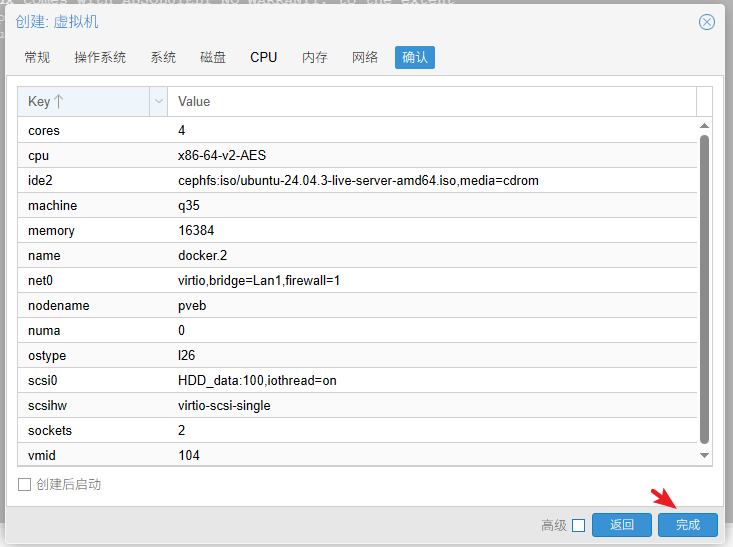
成功创建虚拟机
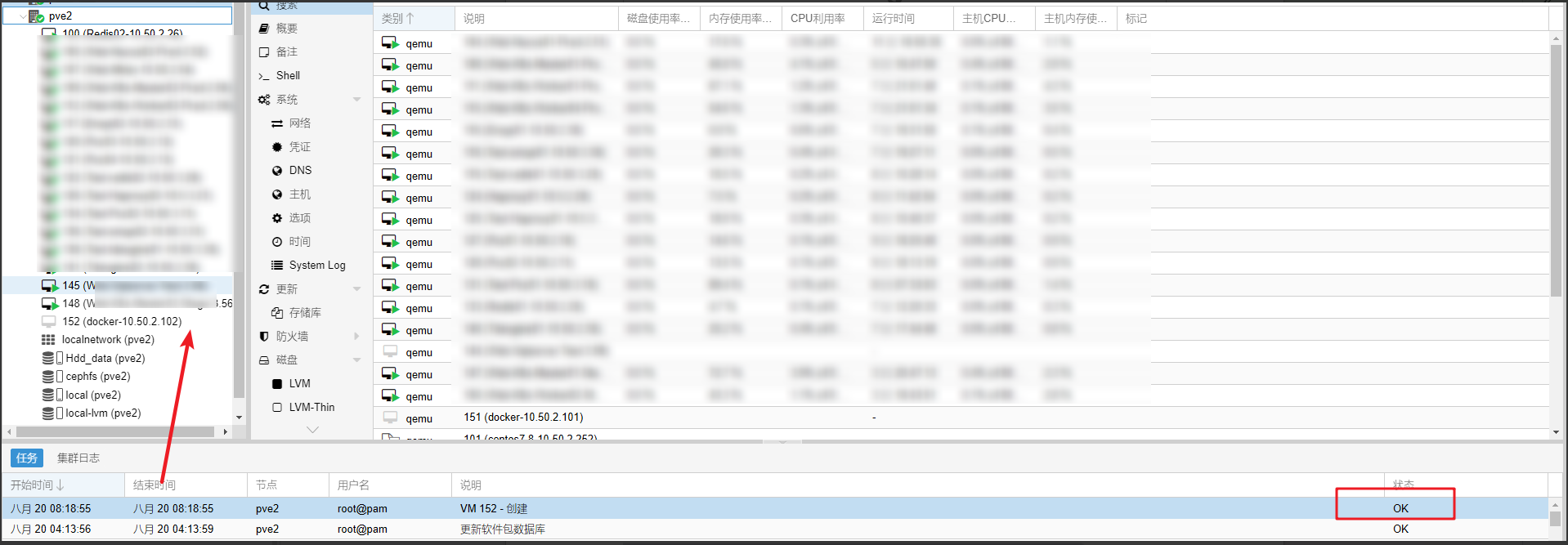
回到目录
4、安装Ubuntu操作系统步骤
-
点击创建好的虚拟机,进入虚拟机操作系统安装
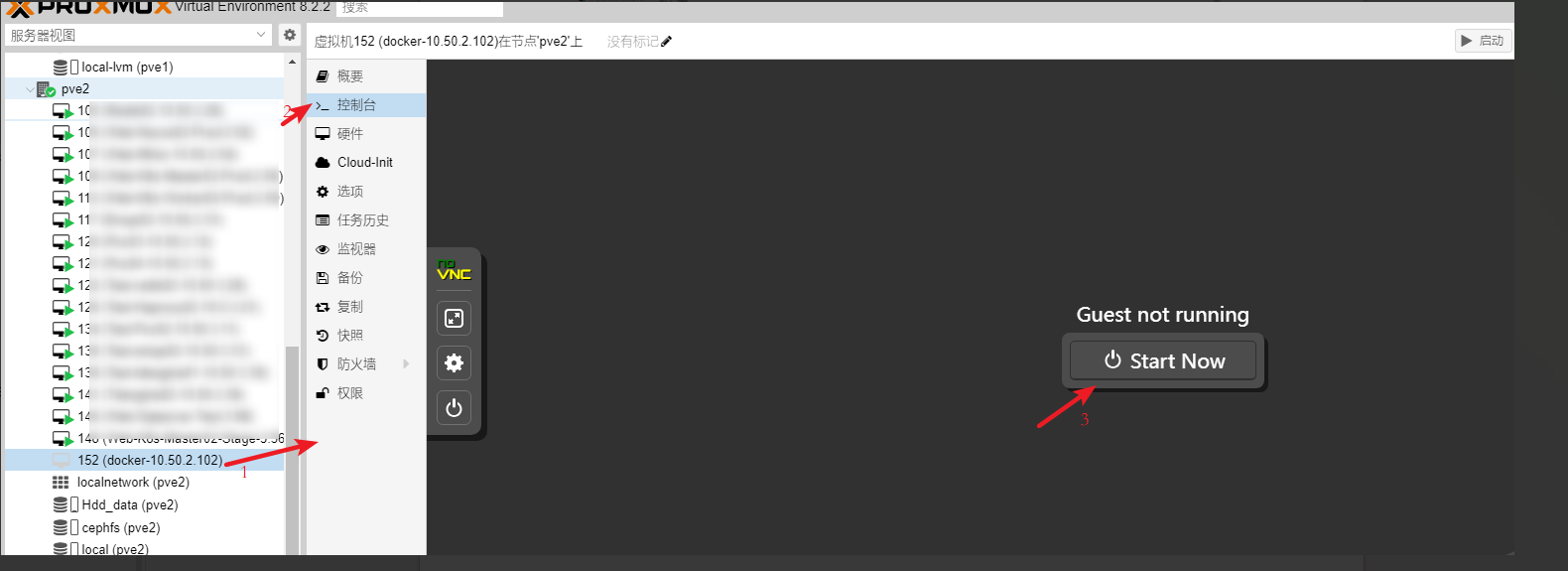
虚拟机启动后,会进入Ubuntu文本模式的安装引导界面(这里需要使用方向键进行选择,enter键确认选择,进入下一步)
-
选择"Engilish" -
-
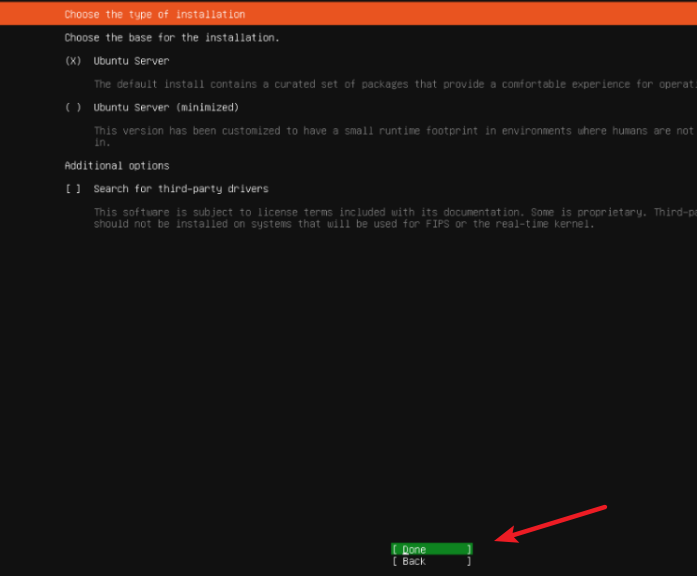
默认进入下一步"Done"
-
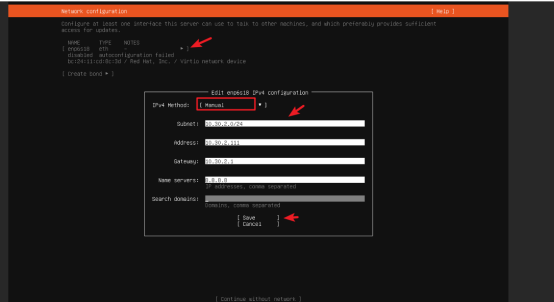
进行网络配置:配置完成后,点击"save"保存
系统会自动检测网络(通过 DHCP 获取 IP),如需静态 IP,选择Edit IPv4
静态 IP 配置示例:
- 选择方法:Manual
- 输入静态IP配置详细信息:
子网subnet:如10.30.2.0/24
地址address:设置静态 IP(如10.30.2.111)
网关gateway:如10.30.2.1
DNSname servers:如8.8.8.8(谷歌 DNS)或223.5.5.5(阿里云 DNS)
Search domain:(如果不是有特殊要求,这里可以不填)搜索域。
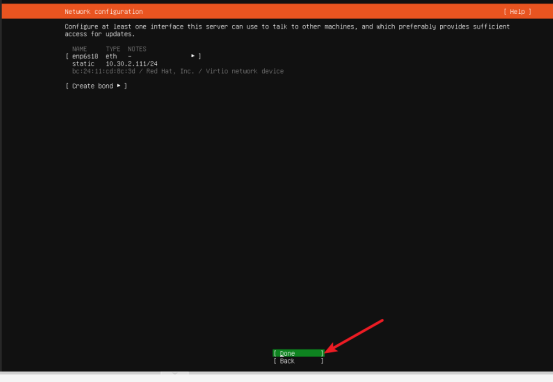
- 代理配置(可选):如无代理服务器,直接点击【Done】
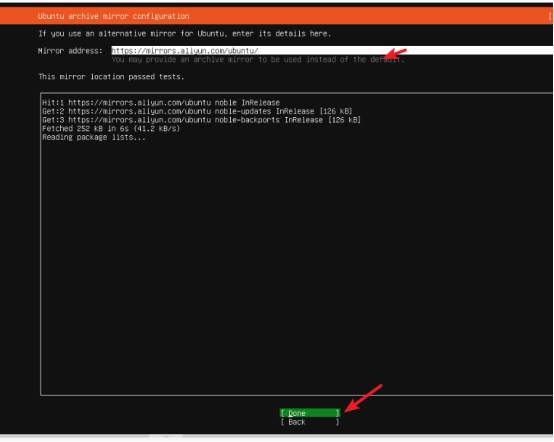
- 镜像源配置(默认使用 Ubuntu 官方镜像源(国外地址,速度较慢),建议替换为国内镜像源)
- 选择【Change】,输入国内镜像源地址(如阿里云:http://mirrors.aliyun.com/ubuntu/)
完成点击Done,进入下一步
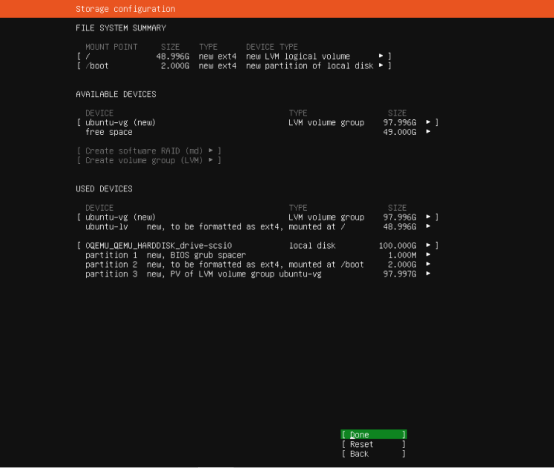
- 磁盘分区:(这里可以直接进行默认选择,点击done进入下一步)如果有特殊要求可以根据下面的步骤进行选择分区方案
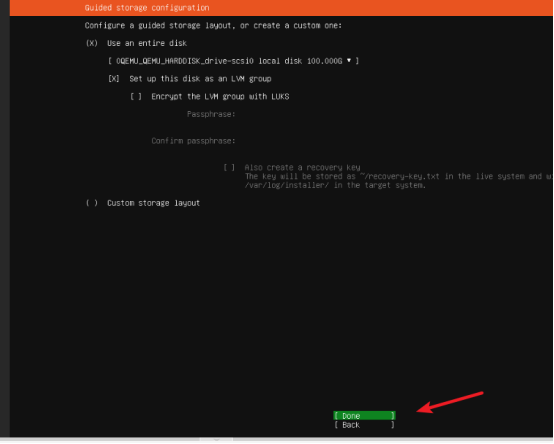
- 选择【Use entire disk】(使用整个磁盘,适合新手,自动分区)
- 选择要分区的磁盘(默认是虚拟机创建的磁盘,如/dev/vda)
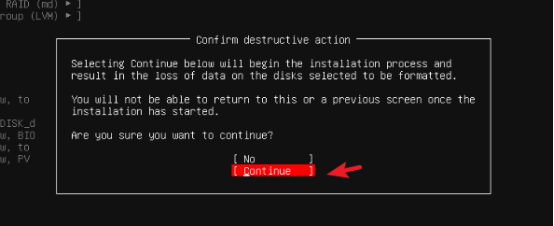
- 选择【Done】,确认分区方案,点击【Continue】(确认格式化磁盘)
这里选择"continue"继续
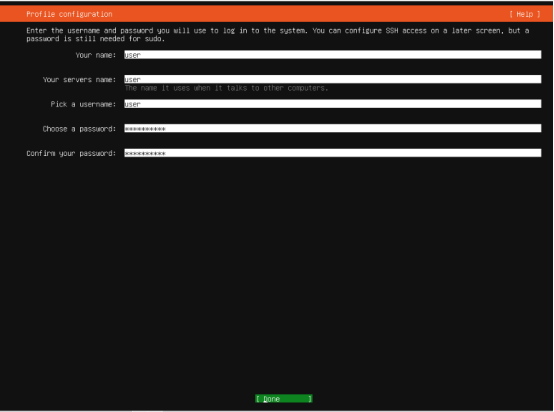
- 设置用户信息:
- 名字(Your name):自定义(如user)
- 服务器名称(Your server's name):自定义(如hsl)
- 用户名(Pick a username):自定义(如user,建议非 root 用户)
- 密码(Choose a password):设置强密码(至少 8 位,包含字母、数字、符号)
- 确认密码:重复输入密码
- 是否加密家目录(Encrypt your home directory):选择【No】(服务器无需加密,避免启动时需要输入密码)
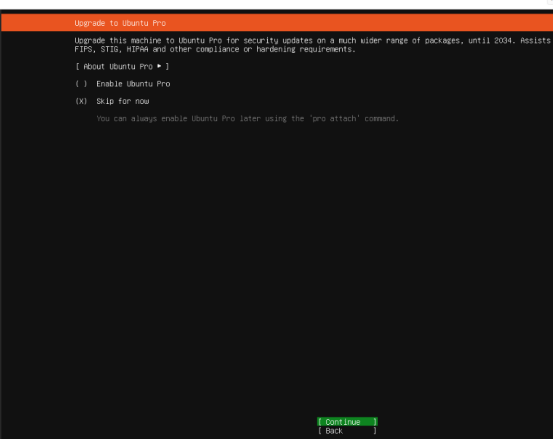
- (重要,必须选择 )SSH 服务器安装:
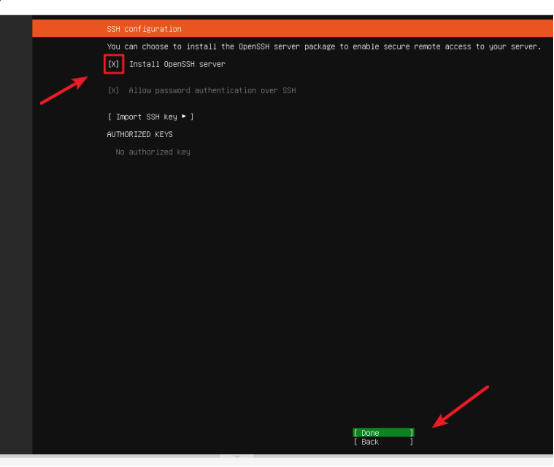
进入【Featured Server Snaps】界面,使用方向键选中【Install OpenSSH server】
,按空格键勾选(出现x表示已勾选),后续可通过 SSH 远程连接服务器, 点击Done进入下一步
- 自带安装器配置(默认都不选即可,最好不用这个自带的安装,有需要的安装好后自定义安装)
- 等待安装完成,安装过程大概需要 5分钟以上(取决于硬件性能和镜像源速度)
- 安装完成后,下面会出现"Reboot Now",选择【Reboot Now】重启系统
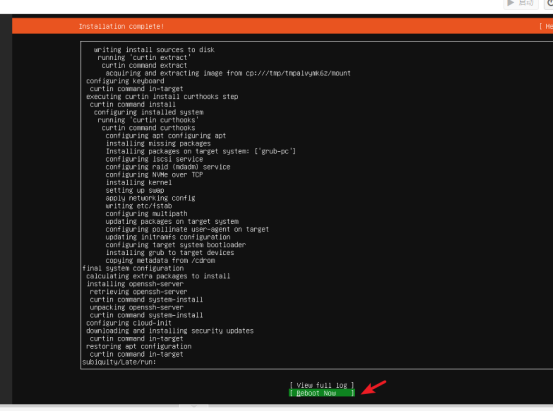
重启时会提示 "Remove the installation medium",直接按回车键(PVE 会自动卸载 ISO 镜像)。开机后就安装完成了,用刚刚设置的用户名和密码登录即可。
回到目录