一、Linux
1、cpu使用率跟负载的区别
CPU使用率:
表示CPU在特定时间间隔内的繁忙程度百分比
统计的是CPU时间片的使用情况
100%表示所有CPU核心都在满负荷工作
CPU负载:
表示系统平均负载,即单位时间内系统中处于运行状态和不可中断状态的进程平均数
统计的是等待CPU资源的进程数量
通常显示为三个值:1分钟、5分钟、15分钟的平均负载
对于多核CPU,负载值÷CPU核心数 = 相对负载
关键区别:
使用率是"当前有多忙",负载是"有多少任务在排队"
低使用率高负载:可能I/O阻塞导致进程排队
高使用率低负载:CPU密集型任务但队列不长
2、什么情况会导致CPU使用率或负载高
CPU使用率高的情况:
CPU密集型应用(科学计算、视频编码)
无限循环或递归调用
大量小文件处理(频繁系统调用)
垃圾回收频繁(Java/Python等)
锁竞争激烈(线程等待后集中执行)
配置不当(线程池过大)
负载高但CPU使用率不高的情况:
I/O密集型操作(磁盘读写瓶颈)
大量进程等待I/O(不可中断状态)
内存不足导致频繁swap
网络拥堵导致进程阻塞
锁竞争导致进程排队
3、kill -9 跟 kill -15 的区别
kill -15(SIGTERM):
优雅终止信号,允许程序进行清理工作
程序可以捕获此信号,执行关闭前的清理操作(如保存数据、关闭连接)
是默认的kill信号
kill -9(SIGKILL):
强制终止信号,无法被捕获或忽略
立即终止进程,不进行任何清理
可能导致资源泄漏或数据损坏
使用建议:
先使用 kill -15 或 kill PID
等待几秒后再考虑 kill -9
系统服务应正确处理SIGTERM信号
4、inode空间是什么
inode(索引节点):
文件系统数据结构,存储文件的元数据(不包括文件名和文件内容)
包含:权限、所有者、大小、时间戳、数据块位置等
inode空间:
文件系统分配的inode总数,创建文件系统时确定
每个文件或目录占用一个inode
inode耗尽:即使磁盘有空间也无法创建新文件
检查命令:
df -i # 查看inode使用情况
inode耗尽常见原因:
大量小文件(日志、缓存文件)
未清理的临时文件
Docker/容器产生大量层文件
邮件系统产生大量小邮件
5、TCP三次握手
TCP三次握手 是 TCP/IP 协议中,客户端和服务器在开始传输应用数据之前,必须完成的一个建立可靠双向通信信道的过程。这个过程通过三次报文交换来完成,因此得名。
核心目的:同步双方的初始序列号,这是TCP实现可靠性、流量控制和有序传输的基础。
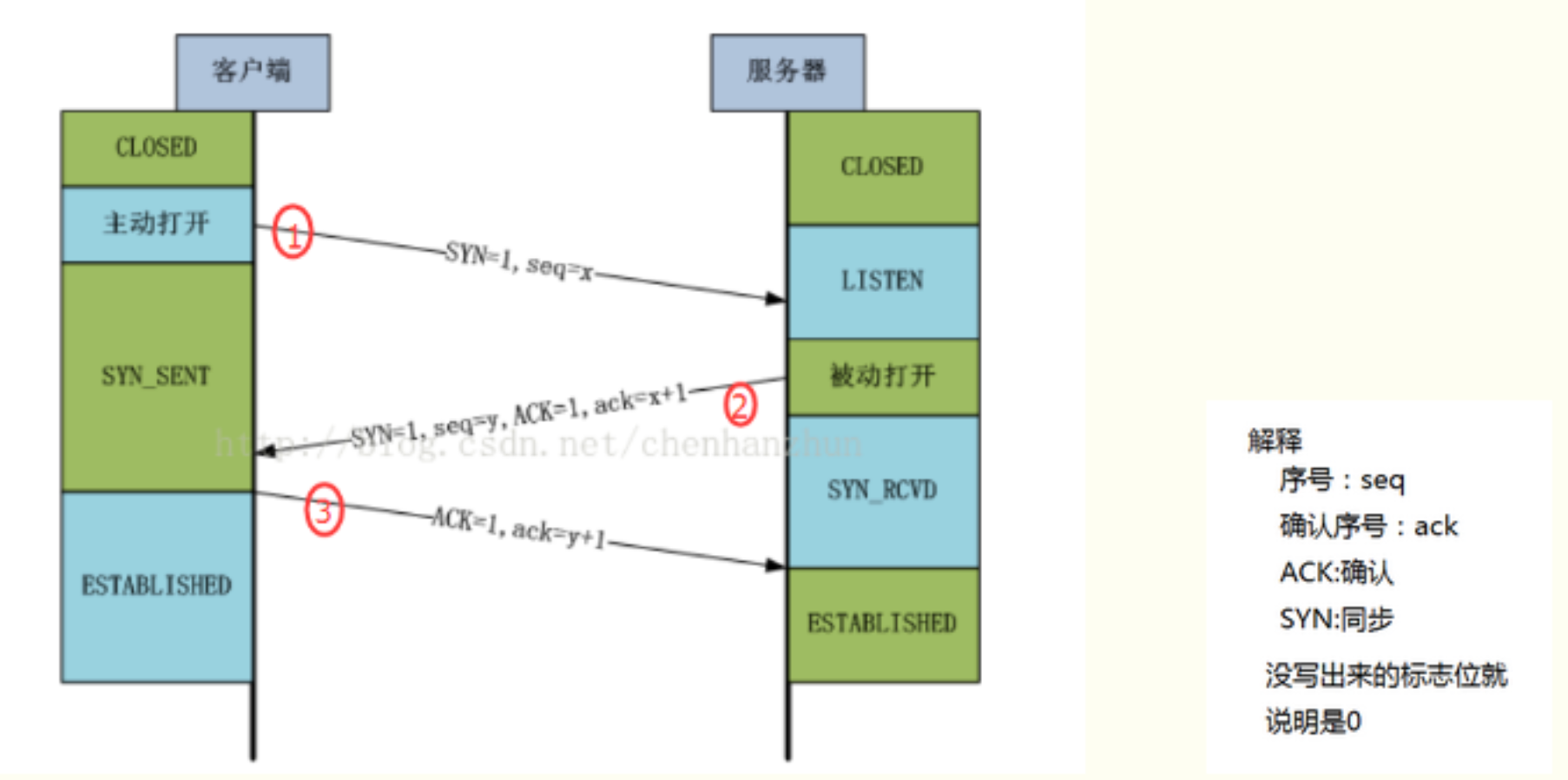
详细流程:如何工作?
假设客户端(Client)想要主动连接服务器(Server)。
第一次握手 (SYN):
发起方:客户端
动作:客户端发送一个TCP报文,其中:
标志位 SYN=1:表示这是一个"同步"报文,请求建立连接。
序列号 seq = x:客户端随机生成一个初始序列号(ISN)。
状态变化:客户端进入 SYN_SENT 状态。
第二次握手 (SYN + ACK):
发起方:服务器
动作:服务器收到SYN报文后,如果同意连接,则回复一个报文,其中:
标志位 SYN=1,ACK=1:SYN=1 表示这也是一个同步报文;ACK=1 表示确认字段有效。
序列号 seq = y:服务器随机生成自己的初始序列号。
确认号 ack = x + 1:确认客户端的序列号,意思是"我收到了你的序列号x,期待你下次发送从x+1开始的数据"。
状态变化:服务器进入 SYN_RCVD 状态。
第三次握手 (ACK):
发起方:客户端
动作:客户端收到服务器的SYN-ACK报文后,必须再次确认。发送一个报文,其中:
标志位 ACK=1:纯确认报文。
序列号 seq = x + 1:因为第一次握手的SYN消耗了一个序列号,所以这里从x+1开始。
确认号 ack = y + 1:确认服务器的序列号,意思是"我收到了你的序列号y,期待你下次发送从y+1开始的数据"。
状态变化:客户端进入 ESTABLISHED 状态。服务器收到这个ACK后,也进入 ESTABLISHED 状态。
至此,连接建立成功,双方可以开始传输应用数据。
可以用一个生活中的比喻:
客户:"你好,我想和你通话。"(SYN)
客服:"收到,我准备好了,你也能听到我吗?"(SYN + ACK)
客户:"能听到,我们开始吧。"(ACK)
------ 正式通话开始。关键问题:为什么是三次?不是两次或四次?
这是面试中最常被追问的深层原理问题。
为什么不是两次?
核心原因:防止已失效的连接请求报文突然又传送到服务器,导致错误。
场景:客户端发送了一个SYN报文,由于网络拥塞迟迟未到。客户端超时重发了一个SYN并成功建立连接、传输数据、关闭连接。此时,第一个迟到的SYN 终于到达了服务器。如果只是两次握手(服务器回复SYN-ACK后连接就建立),服务器会以为客户端又发起新连接,从而一直保持这个"幽灵连接",浪费服务器资源。第三次握手让客户端有机会告诉服务器:"你刚才同意的那个请求,我(在有效期内)确认了",如果是过期的请求,客户端不会发出第三次ACK,服务器收不到确认就会关闭这个半连接。
为什么不是四次?
三次已经足以完成 双方初始序列号的同步与确认。在第二次握手时,服务器已经将 ACK(确认客户端的SYN)和 SYN(自己的同步请求)合并到了一个报文里发送,效率最高。再增加一次握手只是冗余,没有必要。
二、脚本相关
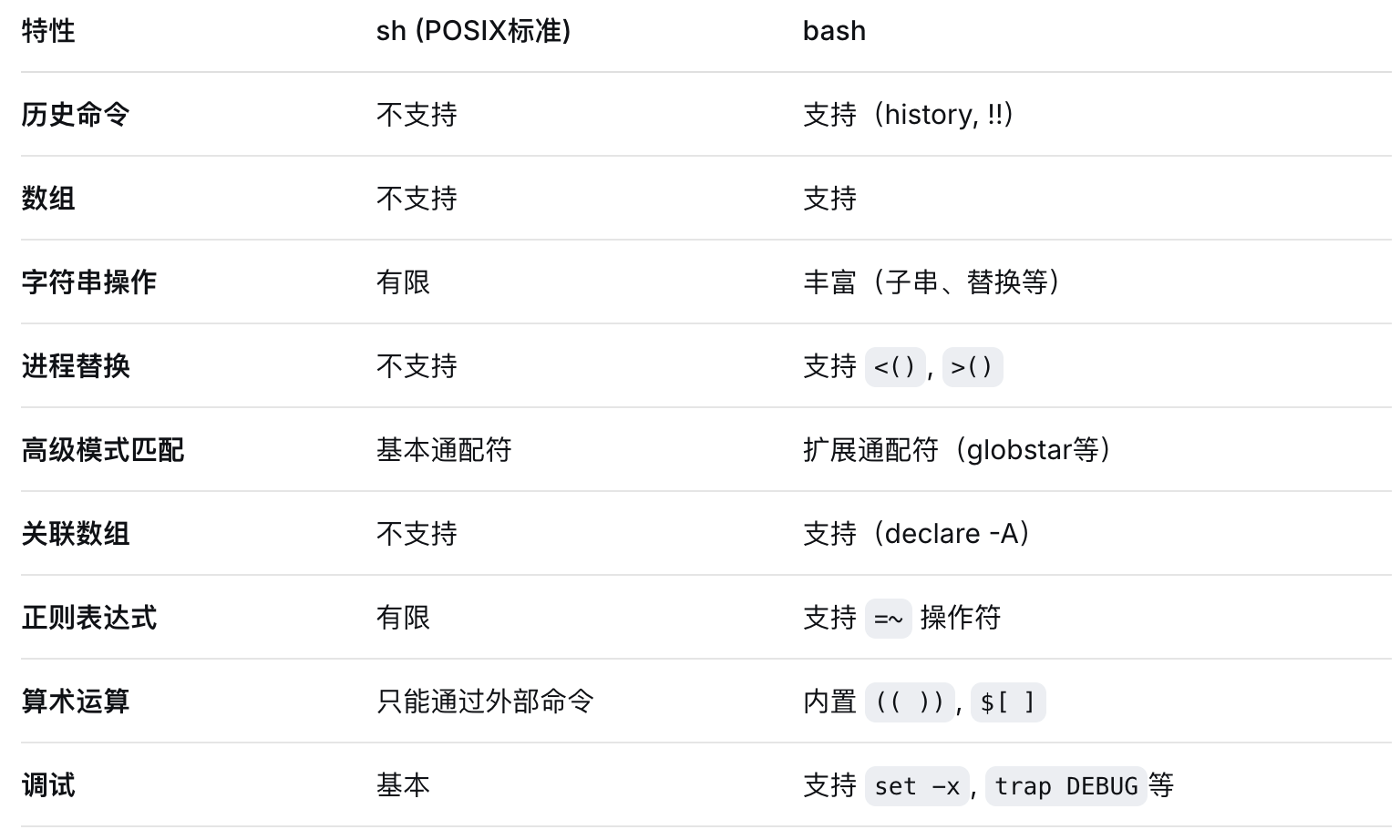
1、shell脚本的/bin/bash和/bin/sh的区别
sh (Bourne Shell):原始的Unix shell,由Stephen Bourne开发,功能较为基础
bash (Bourne Again Shell):sh的增强版,兼容sh并添加了大量新功能
使用 #!/bin/sh 当:
需要最大兼容性(跨Unix系统)
脚本只使用POSIX标准特性
追求更快的执行速度(dash通常比bash快)
使用 #!/bin/bash 当:
需要使用bash特有功能
脚本只在Linux系统运行
需要更丰富的编程特性
2、shell脚本如何统计数组的长度,如何截取数组
统计
array=("apple" "banana" "cherry" "date")
# 方法1:使用 ${#array[@]}
echo "元素个数: ${#array[@]}" # 输出: 4
# 方法2:使用 ${#array[*]}
echo "元素个数: ${#array[*]}" # 输出: 4
# 统计单个元素的长度
echo "第一个元素长度: ${#array[0]}" # 输出: 5截取
array=("a" "b" "c" "d" "e" "f" "g")
# 基本切片:${array[@]:起始位置:长度}
echo "${array[@]:2:3}" # 输出: c d e
# 等价于 array[2]到array[4],共3个元素
# 从指定位置到末尾
echo "${array[@]:3}" # 输出: d e f g
# 从末尾开始(使用负数索引)- 需要bash 4.2+
echo "${array[@]:(-3):2}" # 输出: e f(倒数第3个开始,取2个)
echo "${array[@]: -3:2}" # 注意空格:-3前要有空格
# 保存切片到新数组
new_array=("${array[@]:1:4}")
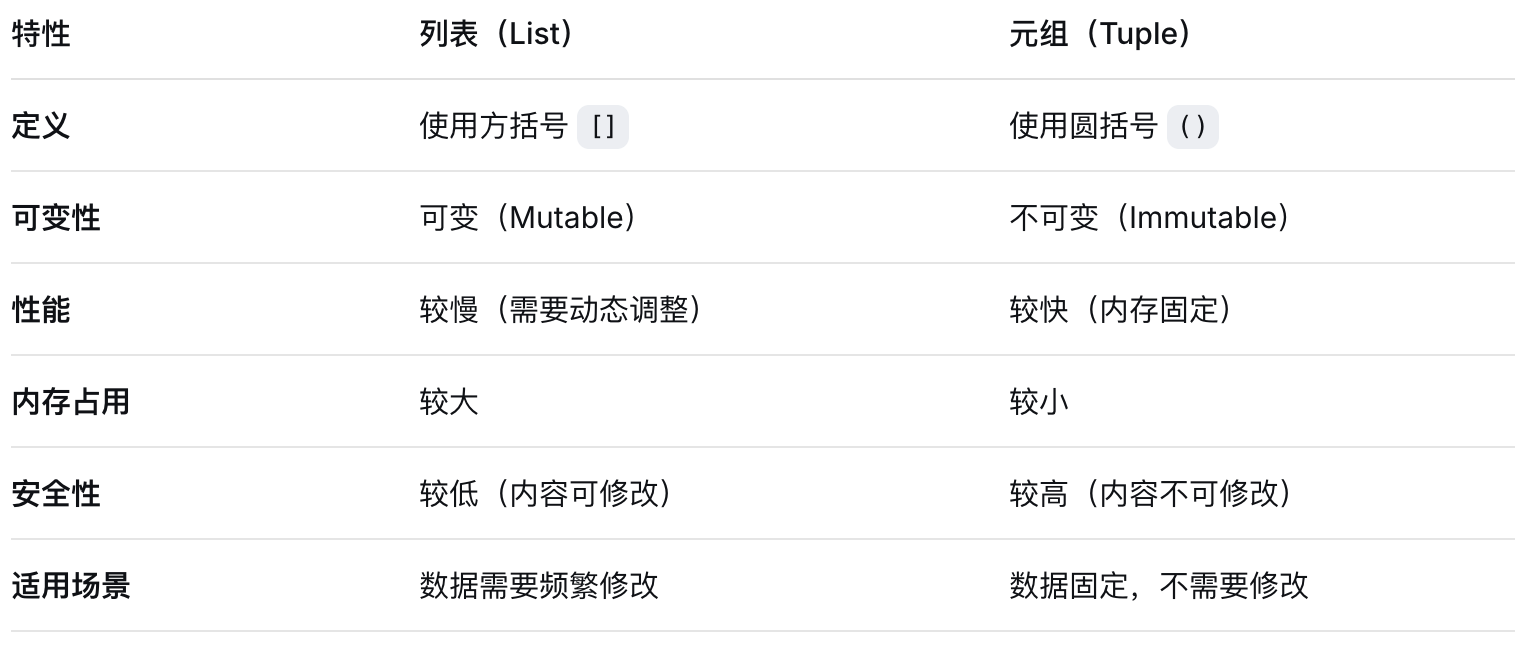
echo "新数组: ${new_array[@]}" # 输出: b c d e3、python中列表和元组的区别
定义
# 列表 - 方括号
my_list = [1, 2, 3, 'hello']
empty_list = []
list_from_range = list(range(5)) # [0, 1, 2, 3, 4]
# 元组 - 圆括号(括号可以省略)
my_tuple = (1, 2, 3, 'hello')
single_tuple = (5,) # 单元素元组必须有逗号!
no_parens = 1, 2, 3 # 也是元组
empty_tuple = ()
tuple_from_list = tuple([1, 2, 3]) # (1, 2, 3)可变性 - 最关键区别
# 列表 - 可以修改
my_list = [1, 2, 3]
my_list[0] = 10 # ✅ 修改元素
my_list.append(4) # ✅ 添加元素
my_list.remove(2) # ✅ 删除元素
my_list.extend([5,6]) # ✅ 扩展列表
del my_list[1] # ✅ 删除指定元素
# 元组 - 不可修改
my_tuple = (1, 2, 3)
my_tuple[0] = 10 # ❌ TypeError
my_tuple.append(4) # ❌ AttributeError
del my_tuple[1] # ❌ TypeError需要修改数据? → 用列表
数据固定不变? → 用元组
需要字典键或集合元素? → 用元组
关注性能? → 用元组
初学者不确定? → 先用列表,有需要再转为元组
三、k8s&docker
1、Deployment、StatefulSet的区别
Deployment:
用于无状态应用
Pod完全相同的副本,可随意创建、删除、替换
随机名称和唯一标识
适用于Web服务器、API服务等
支持滚动更新、回滚
StatefulSet:
用于有状态应用
Pod有稳定的、唯一的网络标识和持久存储
有序的部署、扩展、删除(顺序保证)
每个Pod有稳定的主机名:statefulset名称-序号
适用于数据库、消息队列等需要稳定标识的应用
2、Docker中PID 1进程隔离技术
实现原理:
(1)Linux命名空间(Namespaces)
PID命名空间:每个容器有自己的PID编号体系
容器内的进程看不到主机或其他容器的进程
PID 1只在各自的PID命名空间内有效
(2)控制组(Cgroups)
资源隔离和限制(CPU、内存、I/O等)
防止容器内进程占用过多主机资源
(3)联合文件系统(UnionFS)
提供独立的文件系统视图
每个容器有自己的根文件系统
PID命名空间具体工作方式:
容器启动时,Docker创建新的PID命名空间
容器内第一个进程成为该命名空间的PID 1
主机上该进程有真实的PID(如PID 1000)
信号传播:主机向容器PID 1发信号,会被正确传递
重要性:
容器内PID 1进程需要正确处理信号(如SIGTERM)
僵尸进程回收:PID 1进程需要负责回收子进程
使用docker run --init可添加轻量级init进程
3、docker查看容器cpu内存使用的命令
docker stats - 实时监控
docker top - 查看进程详情