在2025年9月举办的 YOLO Vision 2025 大会上,Ultralytics 就说预期十月份发布YOLO261。
结果跳票了3个月,终于在昨天正式发布出来了。
Ultralytics 发布的上一代YOLO 还是YOLO11,这次直接改名YOLO26,估计是有两方面的考量:
- ultralytics要推商业化,必然要主导YOLO的命名权,如果还是按照之前的那种习惯,到时候别人又开始发论文占坑(比如YOLO12),这样做彻底把这条路堵死了。
- 作为一个长期维护的开源项目,学习苹果操作系统的命名模式,估计是打算一年做一次大版本更新,这样做也更有规律和识别度。
当然,和前几代"挤牙膏"式的性能提升略有不同,这次YOLO26比前面YOLO11的提升幅度是略大的,从下面的曲线图也能看出来,在COCO数据集上的性能表现曲线明显变高了。
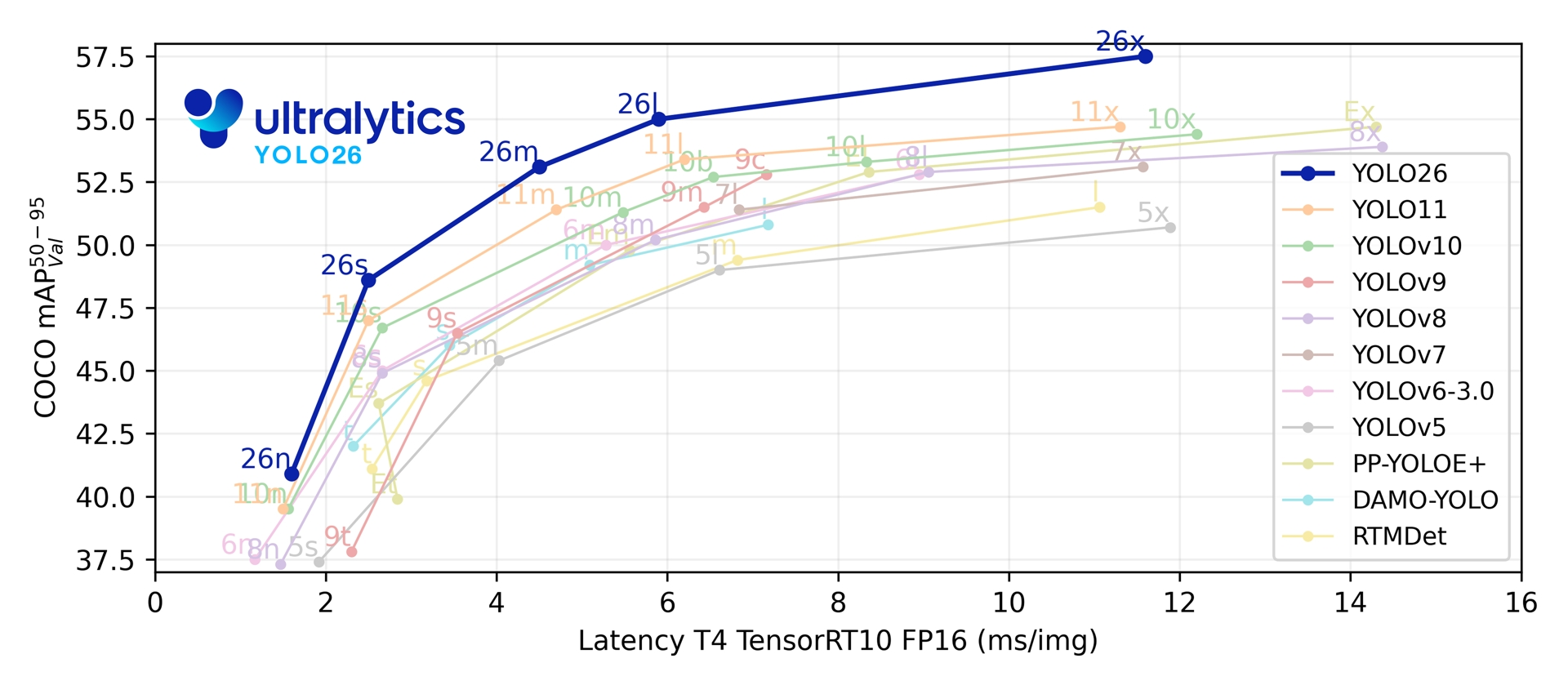
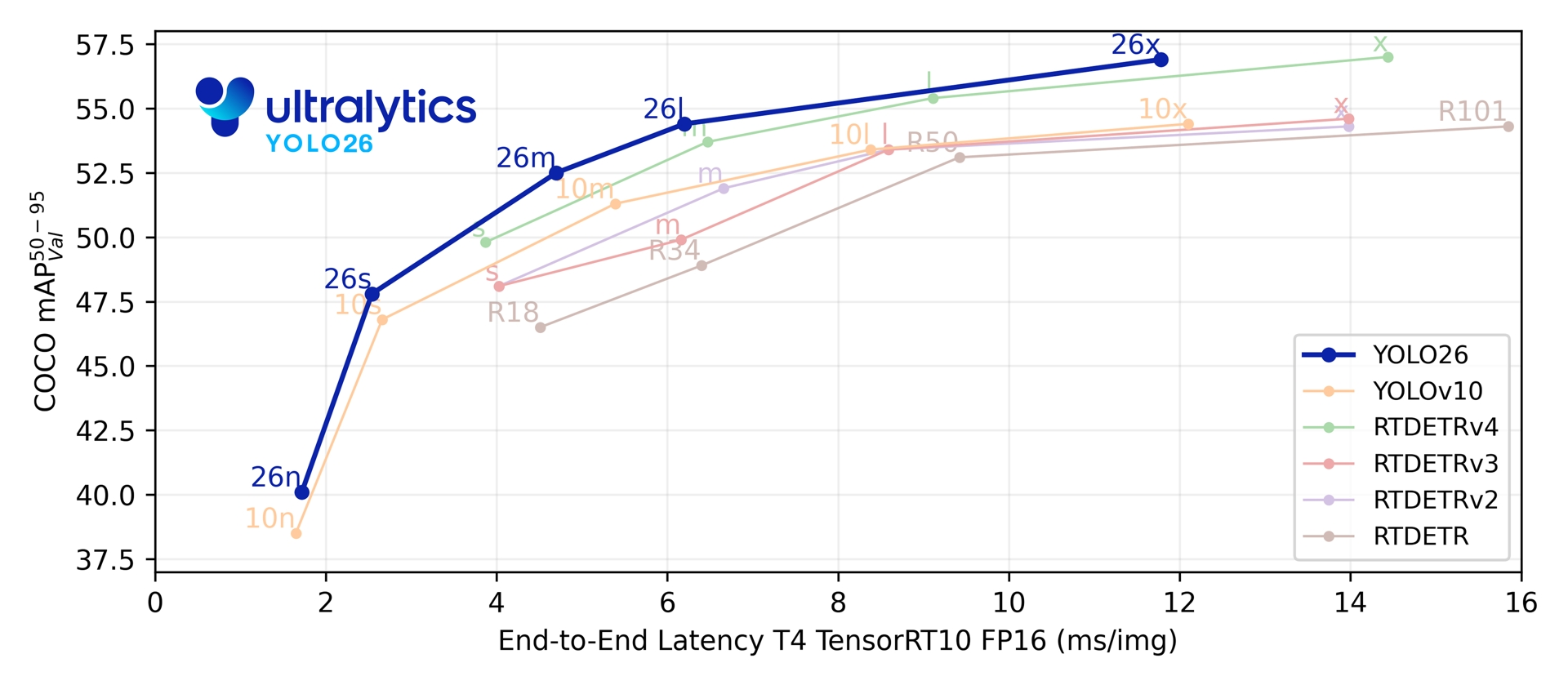
这一代模型依然是n/s/m/l/x五个型号,性能和速度也比RT-DETR更好。
下面来看看主要的更新亮点。
更新内容概述
根据其博客1描述,YOLO26主要有以下内容更新:
-
DFL 移除
分布焦损 (DFL) 模块虽然有效,但导出过程通常较为复杂,且硬件兼容性有限。YOLO26 完全移除了 DFL,简化了推理过程,并扩展了对边缘计算和低功耗设备的支持。
-
端到端无 NMS 推理
与依赖非极大值抑制(NMS)作为独立后处理步骤的传统检测器不同,YOLO26 本身就是端到端的 。它直接生成预测结果,从而降低延迟,使集成到生产系统中更快、更轻量、更可靠。
-
ProgLoss + STAL
改进的损失函数提高了检测精度,尤其是在小目标识别方面取得了显著改进,这对于物联网、机器人、航空图像和其他边缘应用来说至关重要。
-
MuSGD 优化器
一种结合了 SGD 和 Muon 的新型混合优化器。受 Moonshot AI 的 Kimi K2 启发,MuSGD 将 LLM 训练中的先进优化方法引入计算机视觉领域,从而实现更稳定的训练和更快的收敛速度。
-
CPU 推理速度提升高达 43%
YOLO26 专为边缘计算而优化,可提供更快的 CPU 推理速度,确保在没有 GPU 的设备上实现实时性能。
-
实例分割增强
引入语义分割损失以改善模型收敛性,并升级了原型模块,利用多尺度信息以获得更优的掩码质量。
-
精确姿态估计
集成残差对数似然估计 (RLE) 以实现更准确的关键点定位,并优化解码过程以提高推理速度。
-
改进的 OBB 解码
引入专门的角度损失来提高方形物体的检测精度,并优化 OBB 解码以解决边界不连续问题。
细节分析
深扒其开源代码2,可以对上述内容进行更详细的分析。
NMS替代
在取消NMS之后,实际上是用 TopK 替代 NMS
在 ultralytics/nn/modules/head.py 代码中,可以看到相关代码:
python
def postprocess(self, preds):
"""用 TopK 替代 NMS"""
boxes, scores = preds.split([4, self.nc], dim=-1)
scores, conf, idx = self.get_topk_index(scores, self.max_det)
boxes = boxes.gather(dim=1, index=idx.repeat(1, 1, 4))
return torch.cat([boxes, scores, conf], dim=-1)
def get_topk_index(self, scores, max_det):
"""选择 Top-K 个最高分的预测"""
k = max_det
ori_index = scores.max(dim=-1)[0].topk(k)[1].unsqueeze(-1)
scores = scores.gather(dim=1, index=ori_index.repeat(1, 1, nc))
scores, index = scores.flatten(1).topk(k)
idx = ori_index[..., index // nc]
return scores[..., None], (index % nc)[..., None].float(), idx TopK是通过计算每个目标框的 预测得分,选择得分最高的 max_det 个框。
例如,假设有 1000 个候选框,在推理阶段,通过 TopK 筛选出前300个具有最高置信度的框。
python
y = self._inference(preds["one2one"] if self.end2end else preds)
if self.end2end:
y = self.postprocess(y.permute(0, 2, 1)) # TopK 后处理
return y 在模型训练的时候,通过一个 One2One分支 来进行一对一的目标匹配,通过这种方式,让模型自身学习如何去除多余的框。
ProgLoss
取缔NMS这步是有点激进的,为此,YOLO26使用了ProgLoss去进行渐进式损失计算,旨在通过在训练过程中逐渐调整不同损失的权重,以帮助模型更有效地学习。
在 ultralytics/utils/loss.py 文件中,E2ELoss 类实现了 ProgLoss 的核心逻辑:
python
class E2ELoss:
def __init__(self, model, loss_fn=v8DetectionLoss):
self.one2many = loss_fn(model, tal_topk=10) # 一对多分配,topk=10
self.one2one = loss_fn(model, tal_topk=7, tal_topk2=1) # 一对一分配,topk2=1
# 初始权重
self.o2m = 0.8 # one-to-many 初始权重 80%
self.o2o = 0.2 # one-to-one 初始权重 20%
self.final_o2m = 0.1 # one-to-many 最终权重 10%
def __call__(self, preds, batch):
loss_one2many = self.one2many.loss(one2many, batch)
loss_one2one = self.one2one.loss(one2one, batch)
# 加权混合
return loss_one2many[0] * self.o2m + loss_one2one[0] * self.o2o, ...
def decay(self, x) -> float:
"""渐进衰减公式"""
return max(1 - x / max(epochs - 1, 1), 0) * (0.8 - 0.1) + 0.1翻译一下代码,这个损失的变化如下表所示:
| 阶段 | one2many 权重 | one2one 权重 | 目的 |
|---|---|---|---|
| 早期 | 高 (0.8) | 低 (0.2) | 多正样本快速学习特征 |
| 中期 | 渐减 | 渐增 | 平滑过渡,逐步调整模型焦点 |
| 后期 | 低 (0.1) | 高 (0.9) | 专注一对一精确匹配,减少冗余 |
ProgLoss 通过在训练的不同阶段调整权重,模型能够在初期专注于广泛学习特征(one-to-many),而在后期聚焦于精确地进行目标匹配(one-to-one)。
STAL
STAL (Small-Target-Aware TAL)是一个针对小目标的改进,核心代码在 ultralytics/utils/tal.py 的 select_candidates_in_gts 函数中:
python
def select_candidates_in_gts(self, xy_centers, gt_bboxes, mask_gt, eps=1e-9):
gt_bboxes_xywh = xyxy2xywh(gt_bboxes) # 将边界框格式从 (x_min, y_min, x_max, y_max) 转换为 (x_center, y_center, width, height)
# 关键:检测小于最小stride的目标
wh_mask = gt_bboxes_xywh[..., 2:] < self.stride[0] # stride[0] = 8,用来检测目标宽高小于stride的目标
stride_val = torch.tensor(self.stride[1], dtype=..., device=...) # stride[1] = 16,为大目标的stride值
# 关键优化:将小目标的宽高扩展到第二个stride尺度
gt_bboxes_xywh[..., 2:] = torch.where(
(wh_mask * mask_gt).bool(), # 如果是小目标且在mask中,则执行扩展
stride_val, # 小目标 → 扩展到16
gt_bboxes_xywh[..., 2:] # 其他目标 → 保持原尺寸
)
gt_bboxes = xywh2xyxy(gt_bboxes_xywh) # 将修改后的边界框转换回 (x_min, y_min, x_max, y_max) 格式它的原理是通过将小目标的边界框虚拟扩展到16px,使得小目标能匹配更多的锚点。
例如,原始的小目标尺寸为 6x6 px,而在特征图上,锚点的尺度通常较大(如 stride=8),导致原始的小目标无法匹配足够多的锚点,可能只有一个或者没有匹配的锚点。
虚拟扩展通过扩展小目标的边界框尺寸(将 6x6 px 扩展到 16x16 px),模拟一个较大的目标。这个扩展不是物理上修改目标的尺寸,而是改变了计算过程中的目标尺寸,使得它能够匹配更多的锚点。
扩展后的效果:扩展后的虚拟目标(如 16x16 px)可以与更多的锚点进行匹配,这样就会增加正样本的数量,同时也增强了小目标的学习信号。这样一来,模型就能够更好地识别和学习小目标的特征。
MuSGD
Muon的创新点是通过Newton-Schulz迭代对梯度矩阵进行正交化,从而让收敛速度更加稳定。
MuSGD其实不是纯创新的优化器,而是Muon和SGD的加权混合。
在代码 ultralytics/engine/trainer.py 中,可以看到具体权重。
muon, sgd = (0.5, 0.5) if iterations > 10000 else (0.1, 1.0)翻译一下就是:
| 条件 | muon 权重 | sgd 权重 |
|---|---|---|
| 迭代次数 > 10000 (大数据集) | 0.5 | 0.5 |
| 迭代次数 ≤ 10000 (小数据集/微调) | 0.1 | 1.0 |
这样混合是发挥了两者各自的优势:
- Muon:提供正交化的"探索"方向
- SGD:提供稳定的更新方向
从权重上看,Muon 只有在大数据集上才会重点使用,对于小样本的数据集来说,作用不明显。
总结
YOLO26 主要的优化倾向是增加小目标的检测性能和优化推理速度,同时,在目标检测领域,YOLO依然是那个SOTA。