
引言
在数字经济时代,全球数据总量正以指数级增长。据IDC预测,到2025年全球数据总量将突破175ZB,其中时序数据占比超过30%。这类数据广泛存在于工业物联网、金融交易、环境监测等场景,具有高频写入、海量存储、时间敏感等特性。传统关系型数据库在处理时序数据时面临写入性能瓶颈、存储成本高昂、查询效率低下等挑战,而专为时序数据设计的时序数据库(TSDB)成为破局关键。本文将从技术架构、性能指标、生态兼容性等维度,系统解析时序数据库选型要点,并重点阐述Apache IoTDB在物联网场景中的核心优势。
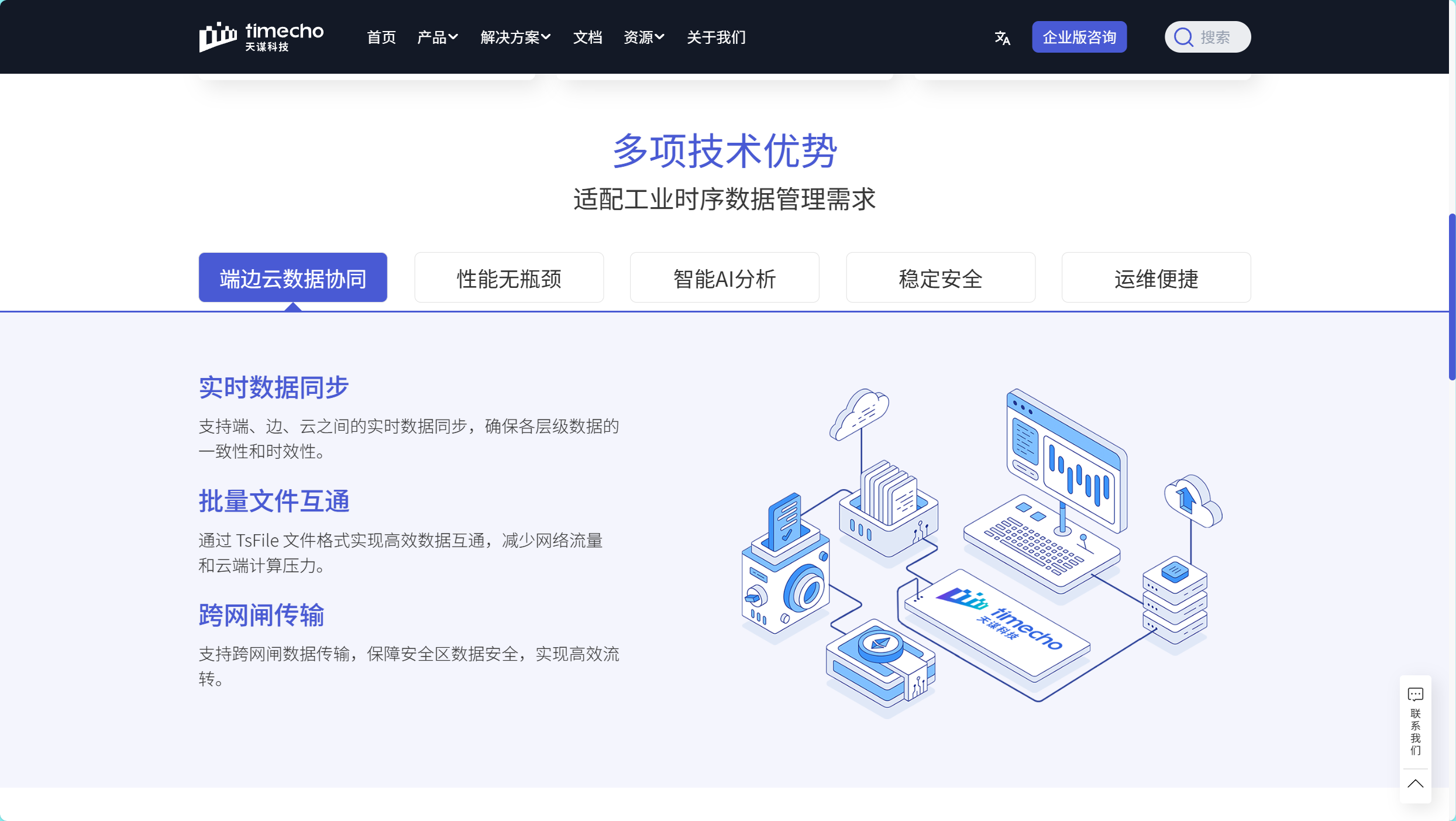
一、时序数据库选型的核心维度
1. 数据模型适配性
时序数据具有独特的结构特征:设备层级关系复杂(如工厂-产线-设备-传感器)、数据维度多样(温度、压力、状态等)、时间戳唯一性。传统扁平化指标模型难以表达设备间的层级关系,而树状数据模型通过路径式命名(如root.factory.area1.line1.sensor01)天然适配工业场景。例如,某风电企业通过IoTDB的树形结构管理数百台风力发电机的SCADA数据,实现从风机轮毂温度到整场发电效率的多层级查询。
2. 写入性能与扩展性
物联网场景下,单个智能工厂可能产生每秒百万级数据点。时序数据库需具备:
- 高吞吐能力:单节点支持千万级数据点/秒写入
- 水平扩展性:通过分布式架构实现线性性能提升
- 乱序数据处理:适应边缘设备网络不稳定导致的时序错乱
IoTDB采用列式存储与LSM树结构,在国际TPCx-IoT基准测试中创下2465万IoTps的写入纪录,较InfluxDB等传统产品提升3倍以上。其独特的内存缓冲区与批量写入机制,使某汽车制造企业实现每秒200万条传感器数据的稳定写入。
3. 存储效率与成本优化
时序数据压缩需兼顾效率与精度:
- 专用压缩算法:针对浮点数采用Gorilla编码,整型数据使用Delta+RLE编码
- 自动分区管理:按时间窗口划分数据块,支持TTL过期策略
- 冷热数据分层:热数据存储在SSD,冷数据自动迁移至HDD
IoTDB在某智慧城市项目中实现100:1的压缩比,将10亿数据点的存储成本从传统方案的1.4万元降至140元。其存储引擎通过时间分区与列式压缩技术,使单节点可存储PB级数据而无需频繁扩容。
4. 查询性能与计算能力
时序查询具有鲜明特征:
- 时间范围查询:需快速定位特定时间段数据
- 聚合计算:支持滑动窗口统计、降采样等操作
- 多维度分析:跨设备、跨传感器的关联查询
IoTDB通过倒排索引与多级缓存机制,在十亿级数据量下实现毫秒级响应。某能源集团利用其内置的FFT分析函数,实时检测发电机振动频率异常,将故障预警时间从小时级缩短至秒级。
5. 生态兼容性与部署灵活性
现代时序数据库需无缝集成大数据生态:
- 协议支持:MQTT、CoAP等物联网协议
- 计算框架:与Spark、Flink的流批一体处理
- 可视化工具:Grafana、Superset等BI平台对接
- 部署模式:支持云端、边缘端、端边云协同
IoTDB提供完整的工具链:
- 边缘轻量化版本:仅数MB安装包,支持ARM架构设备
- 云原生部署:通过Kubernetes实现容器化编排
- 国产化适配:与华为鲲鹏、麒麟OS完成兼容认证

二、Apache IoTDB的核心技术突破
1. 端边云一体化架构
IoTDB采用"设备-边缘-云端"协同设计:
- 边缘节点:支持本地存储与实时计算,断网续传
- 云端集群:通过Raft协议实现高可用,自动故障转移
- 数据同步:边缘数据可增量同步至云端,减少网络传输
某轨道交通企业通过该架构,在列车车载终端部署IoTDB边缘节点,实现运行数据实时处理,同时将关键指标同步至云端进行全局分析,使数据传输量减少90%。
2. 时序数据专用存储引擎
IoTDB存储引擎针对时序数据特性优化:
- 列式存储:减少I/O操作,提升压缩效率
- 时间分区:按天/月自动划分数据文件
- 内存管理:采用两级缓存策略,热数据驻留内存
在某钢铁企业的实践中,该引擎使历史数据查询速度提升50倍,同时将存储空间占用降低至OpenTSDB的1/10。
3. 智能查询优化器
IoTDB查询引擎具备以下创新:
- 时间范围过滤:查询时跳过无关时间分区
- 并行扫描:多线程读取数据文件
- 谓词下推:在存储层提前过滤数据
测试显示,在处理包含10万个设备、持续3年的监测数据时,IoTDB的复杂聚合查询耗时仅0.8秒,而Prometheus需要12秒以上。
三、IoTDB与国外产品的对比分析
1. 与InfluxDB的性能对比
| 指标 | IoTDB | InfluxDB |
|---|---|---|
| 单节点写入吞吐量 | 2465万IoTps | 800万points/s |
| 压缩比 | 100:1 | 10:1 |
| 查询延迟(亿级数据) | <50ms | 200-500ms |
| 集群扩展性 | 线性扩展 | 存在性能瓶颈 |
2. 与TimescaleDB的架构差异
- 数据模型:IoTDB的树形结构 vs TimescaleDB的关系模型
- 存储优化:IoTDB专用时序编码 vs TimescaleDB的通用PostgreSQL存储
- 查询语言:IoTDB支持类SQL与TSQL vs TimescaleDB的纯SQL
3. 与OpenTSDB的生态优势
- 部署复杂度:IoTDB独立部署 vs OpenTSDB依赖HBase+ZooKeeper
- 维护成本:IoTDB一键安装 vs OpenTSDB多组件协同
- 国产化支持:IoTDB全面适配信创生态 vs OpenTSDB缺乏国产适配
四、企业级应用实践指南
1. 典型应用场景
- 工业互联网:设备状态监测、预测性维护
- 能源管理:风电/光伏发电效率优化
- 智慧城市:环境监测、交通流量分析
- 车联网:车辆轨迹追踪、驾驶行为分析
2. 实施路线图
- 需求分析:明确数据规模、查询模式、部署环境
- POC测试:使用真实业务数据验证性能
- 架构设计:选择单机、集群或端边云架构
- 生态集成:对接现有大数据平台与可视化工具
- 运维优化:配置压缩算法、分区策略、监控告警
3. 性能调优要点
- 批量写入:避免单条插入,建议每次写入1000条以上
- 合理分区:按设备类型或时间周期划分存储组
- 索引优化:为高频查询字段创建倒排索引
- 资源隔离:通过多租户机制保障关键业务SLA
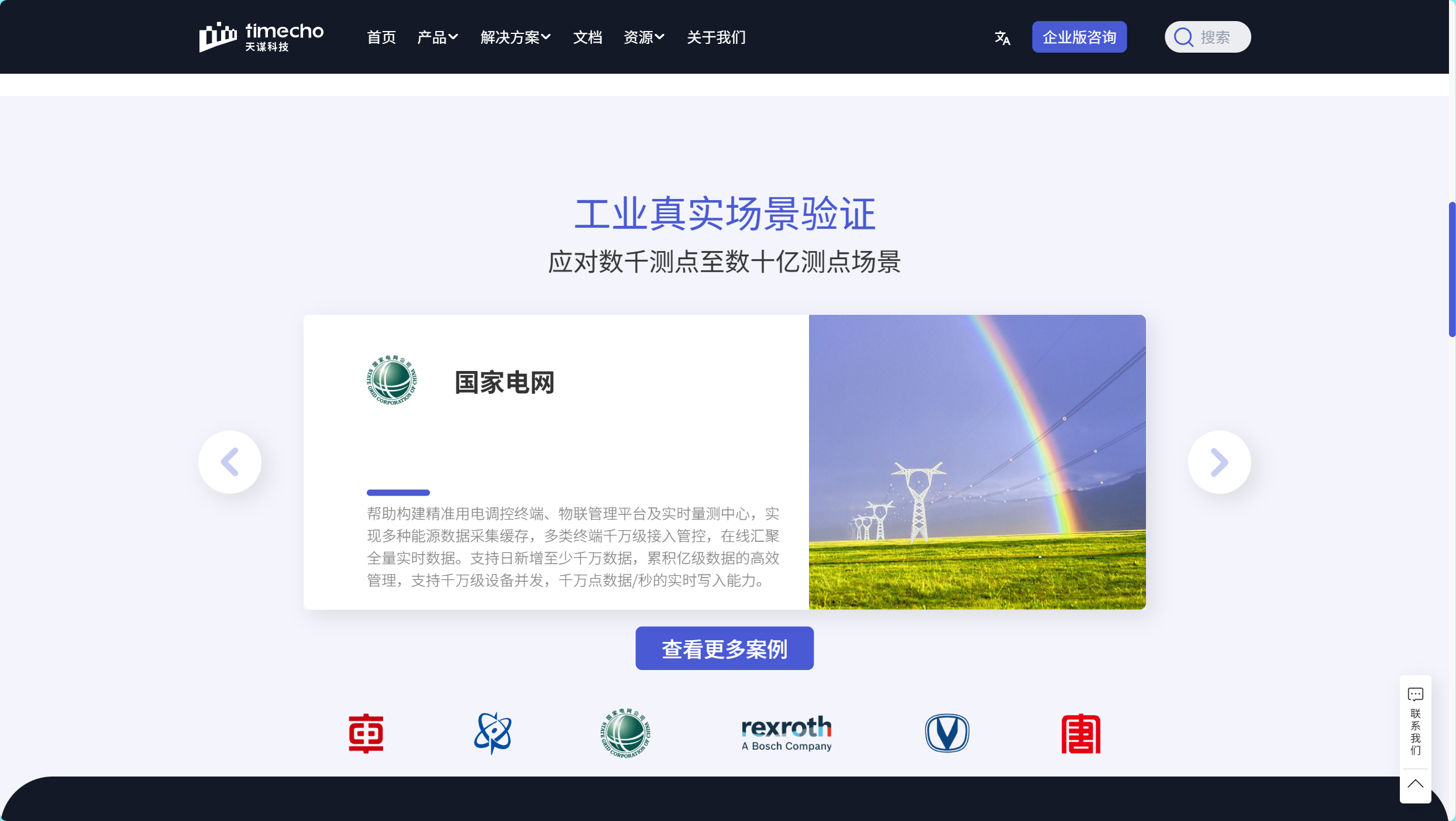
五、下载与技术支持
Apache IoTDB提供开源社区版与企业增强版:
- 开源版下载 :https://iotdb.apache.org/zh/Download/
- 企业版官网 :https://timecho.com
- 技术支持:通过邮件列表、GitHub Issues、社区论坛获取帮助
- 培训服务:官方提供线上课程与认证考试
结语
在时序数据爆发式增长的今天,选择合适的时序数据库已成为企业数字化转型的关键决策。Apache IoTDB凭借其端边云一体化架构、百万级写入吞吐、百倍压缩比等核心优势,在工业物联网、能源管理等领域展现出显著技术领先性。通过与Hadoop、Spark等大数据生态的深度集成,IoTDB正在重新定义时序数据处理的标准,为智能制造