背景
后台服务部署到容器后,平台会对后台服务进行探测,但连续多次探测超时不通过时,会触发服务重启。应用出现GC请求,但所有线程迟迟不到齐,导致系统卡顿。
这里解释一下,当需要GC时候,虚拟机会首先设置一个标志,然后等待所有线程进入Safepoint,但是不同线程进入Safepoint的时间点不一样,先进入Safepoint的线程需要等待其他线程全部进入Safepoint, 才会触发GC。
例如下面这串代码:
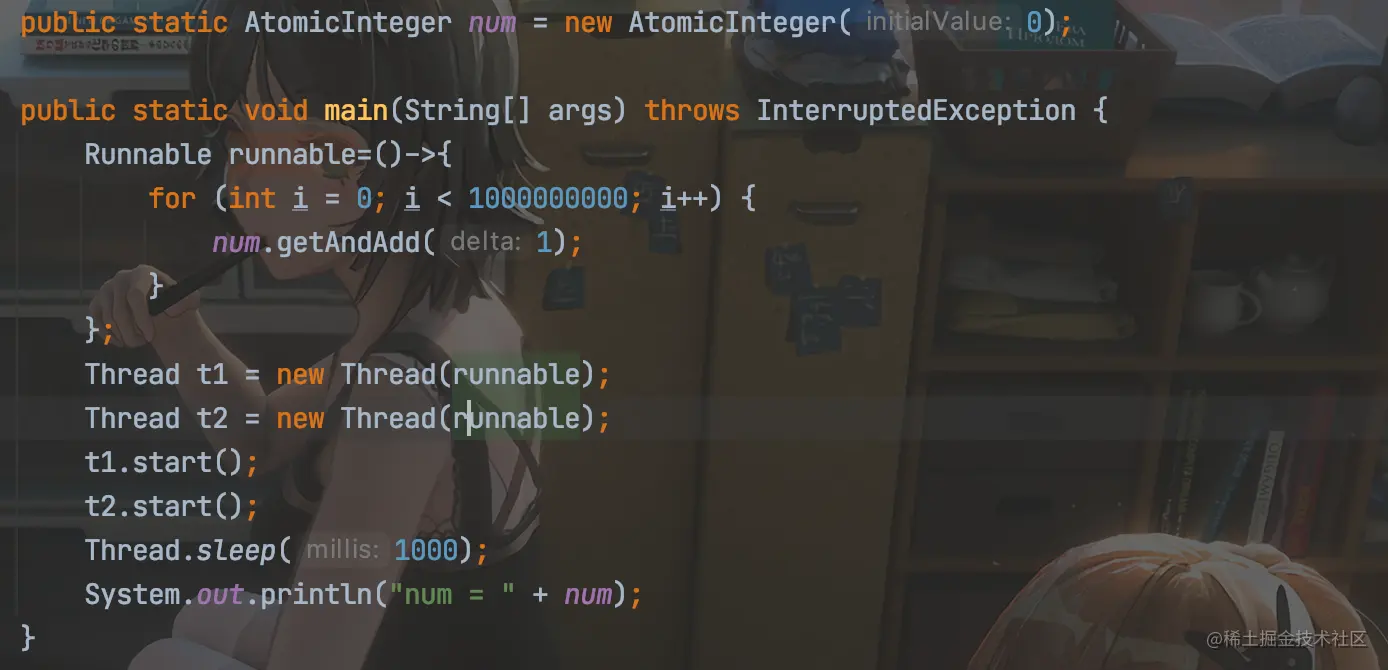
上述代码创建了两个线程进行原子类的递增,并且由于循环数较大,在睡眠1s之后,必定还未执行完。
所以最终结果应该是先打印出内容:num = xx。 接着主线程结束,另外两个线程结束。但现实往往出乎意料!!!
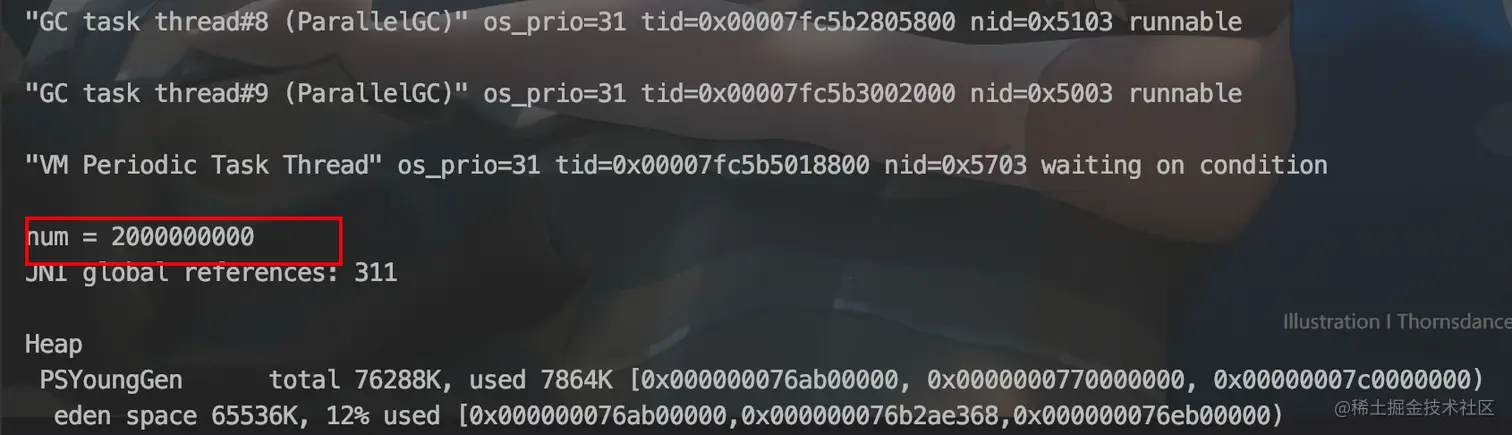
从上图可以看到,最终结果是产生了GC的日志,并且最终等待两个线程循环结束才打印出来。
JVM safePoint
JVM SafePoint(安全点)是 HotSpot 等虚拟机实现"Stop-the-World "式全局暂停的核心机制。它的本质是一组由 JIT 在编译期植入、线程运行期主动轮询的"约定检查点"。只有当所有 Java 线程都到达这些点后,JVM 才能安全地执行需要全局一致状态的操作(GC、de-optimize、撤销偏向锁、线程栈快照等)。
常见 SafePoint 触发场景
-
所有分代/并发 GC 的初始标记、最终标记阶段
-
JIT 去优化(deoptimization)需把线程从编译帧转换成解释帧
-
偏向锁撤销、类卸载、JFR 线程栈快照等需要全局一致视图的操作
-
定时"保健"------参数
-XX:GuaranteedSafepointInterval默认每 1 s 强制一次,防止后台线程长期进不了 Safepoint 导致统计/超时类功能异常
性能注意
如果应用出现"GC 已请求但所有线程迟迟不到齐 "的卡顿,多数是因为某段代码里既没有方法调用、也没有循环回跳(例如超大 while(true) 里只做纯算术),此时可适当插入 Thread.yield()/LockSupport.parkNanos(1) 等"人工检查点",或调小 -XX:GuaranteedSafepointInterval 让 JVM 定期强插。
SafePoint演示
int 版------"可数短循环"
static volatile int sink; // 防止循环被优化掉
public static void main(String[] args) throws Exception {
for (int i = 0; i < 60; i++) { // 外层 60 次
long s = System.nanoTime();
for (int j = 0; j < 1_000_000_000; j++) { // 内层 10 亿次
sink = j; // 纯 int 计数
}
System.out.printf("round %d %.3f ms%n", i, (System.nanoTime()-s)/1e6);
}
System.gc(); // 这里会请求 Safepoint
}运行参数
-XX:+PrintGCApplicationStoppedTime -XX:+PrintSafepointStatistics --XX:PrintSafepointStatisticsCount=1
结果:
每轮大约 300 ms 就能跑完 10 亿次 int 自增;
GC 日志里 "Stopped: ..." 只有几十微秒,几乎感知不到停顿。
原因:
HotSpot 的"可数循环"优化发现内层循环上限是常量 10 亿,于是把 Safepoint 轮询指令从回跳点里删掉了 ------反正跑完 10 亿次就能出来,不会太久。
但 JVM 同时规定:外层循环次数 < 内部循环次数 / SafepointPollInterval(默认 10)时,仍然要在回跳点插 Poll 。
上面外层只跑 60 次,60 < 10 亿/10,所以每 10 亿次回跳里还是会插一次 Poll,线程很快就能到检查点,GC 几乎无延迟。
long 版------"不可数循环"
把计数器改成 long,其余不动:
for (long j = 0; j < 1_000_000_000L; j++) { // 注意 long
sink = (int)j;
}再跑一遍,现象立刻不同:
-
每轮时间飙到 1.2 s(int 版 4 倍);
-
GC 日志里 "Stopped: ..." 前面出现一条 "vmop force gc ..., threads: total=13, ..., time_to_safepoint=1208 ms"。
原因:
循环上限是 long 常量 1_000_000_000L,JIT 无法静态判定它一定落在 int 范围内,于是放弃"可数循环"优化 ,老老实实在每次回跳都插入 Safepoint 轮询指令 。
可这段代码里除了回跳,没有任何函数调用、显式阻塞或内存屏障 ,于是线程一直在跑,不到回跳点就不检查。结果------
-
当 System.gc() 发出 Safepoint 请求时,VMThread 把轮询页设为 bad_page;
-
但当前线程还在狂奔,得等到下一次回跳执行到那条 test 指令才能自陷;
-
如果循环体足够大(10 亿次),就得把这一大段跑完才能"到点",于是 TTSP 直接 ≈ 跑完 10 亿次的时间(1.2 s)。
这就是"long 循环比 int 循环更容易踩出 Safepoint 延迟"的根本原因:JIT 对 int 可数循环会省略轮询,而对 long 循环则不会。
立刻缓解的两种办法
a) 手动插检查点------在循环里每跑 1000w 次就 yield 一下:
if ((j & 0x3FFFFFF) == 0) Thread.yield(); // 约 64 M 次让一次b) 强制 JVM 定期插点------把 GuaranteedSafepointInterval 从默认 1000 ms 改小: -XX:GuaranteedSafepointInterval=100
这样即使线程跑在"不可数"循环里,最多 100 ms 也会被时钟信号打断、拉到 Safepoint,TTSP 就被削到百毫秒级。
小结
-
SafePoint 是"协作式"暂停,线程必须主动跑到检查点才能被拦住。
-
JIT 会根据"循环是否可数"决定要不要在回跳点插轮询指令;int 常量上限常被判定为可数,long 常量则多半不可数。
-
当循环体里既没调用、也没检查点、又跑得巨久 时,TTSP 就会拖成"一次循环跑多久,GC 就得等多久"。
把计数器类型、循环边界、手动 yield/GuaranteedSafepointInterval 这些因素放在一起调,就能直观地看到"long vs int"带来的 Safepoint 行为差异。