核心贡献:AdaWorld 不再依赖显式动作标注,而是从视频中自监督地"抽取可迁移的隐式动作(latent actions)",并用它们进行动作感知预训练,从而得到一个在新环境中能用极少交互就快速适配的新型世界模型。
传统世界模型的痛点
现有 world model(VideoGPT、SVD、Genie、Dreamer 类)普遍存在三个问题:
-
动作依赖强
-
要么必须有明确 action label
-
要么每换一个环境/动作空间就要重新训练
-
-
动作格式不可统一
-
机器人是连续动作
-
游戏是离散动作
-
真实视频根本没动作标注
-
-
适配成本高
-
新环境 → 大量交互 → 长时间 finetune
-
👉 这与"人类只看别人做一次,就能在新环境模仿"的能力差距很大
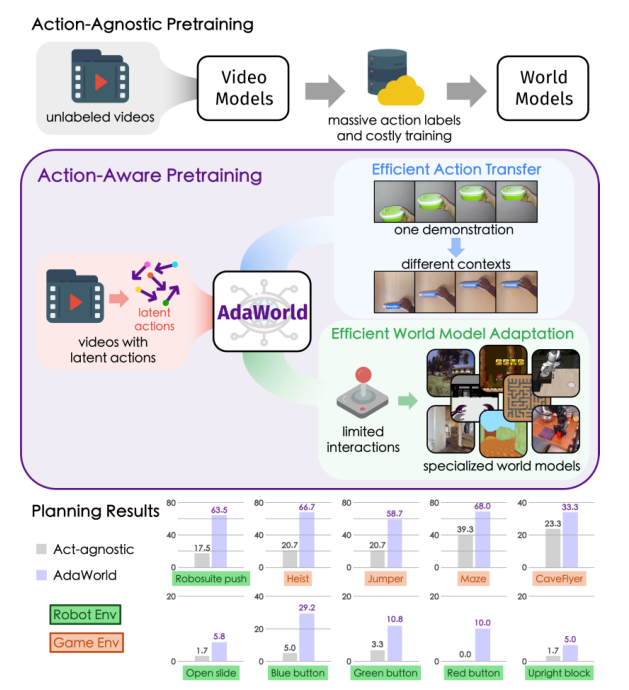
图 1. 不同的世界模型学习范式。 以往的方法通常需要昂贵的动作标注和训练过程,才能在新的环境中实现动作可控性。为了解决这一问题,提出将潜在动作(latent actions)作为统一的条件,用于基于视频的动作感知预训练,从而实现高度可适应的世界模型学习。提出的世界模型 AdaWorld 能够在无需训练的情况下,在不同上下文之间直接迁移动作。此外,通过使用相应的潜在动作对控制接口进行初始化,AdaWorld 还可以高效地适配为特定任务的世界模型,并在规划任务中相较于无动作感知的基线方法取得显著更优的性能。
摘要:
世界模型旨在学习受动作控制的未来预测,并已被证明是智能体发展的关键组成部分。然而,现有的大多数世界模型高度依赖大量带有动作标注的数据以及高昂的训练成本,这使得它们在仅通过有限交互、面对动作异构的新环境时难以高效适配。这一局限性在一定程度上制约了世界模型在更广泛领域中的应用。
为克服上述问题,我提出了一种创新的世界模型学习方法------AdaWorld,其目标是实现高效的模型适配。该方法的核心思想是在世界模型的预训练阶段引入动作信息。具体通过自监督方式从视频中提取潜在动作(latent actions),以捕获相邻帧之间最关键的状态转移因素。在此基础上,构建了一个以潜在动作为条件的自回归世界模型。
这一学习范式使世界模型具备高度的可适应性,即使在交互数据和微调样本极其有限的情况下,也能够高效迁移并学习新的动作。大量跨多种环境的实验结果表明,AdaWorld 在仿真质量和视觉规划任务中均取得了显著优于现有方法的性能。
贡献:
-
提出了 AdaWorld,一种具有高度跨环境适应能力的自回归世界模型。
该模型能够在不同上下文之间直接迁移动作,并且仅需极少量交互即可实现高效适配。
-
在来源极为多样的大规模数据集上对 AdaWorld 进行了构建与训练。
通过充分的预训练,AdaWorld 在多个不同领域中展现出强大的泛化能力。
-
在多种环境中开展了全面的实验验证 AdaWorld 的有效性。
实验结果表明,AdaWorld 在动作迁移、世界模型适配以及视觉规划等任务中均取得了具有竞争力的优异性能。
AdaWorld 的核心思想
关键思想:
在"预训练阶段"就让世界模型学会"动作的本质",而不是等到下游再教它什么是动作。
提出一个极其关键的认知转变:
动作 ≠ 控制信号
动作 = 帧与帧之间最关键的"变化因子"
于是问题变成:
能否从 无标注视频 中,自动抽取"真正驱动状态变化的因素"?
这就是 latent action 的来源。
三、方法机制拆解
1️⃣ Latent Action Autoencoder
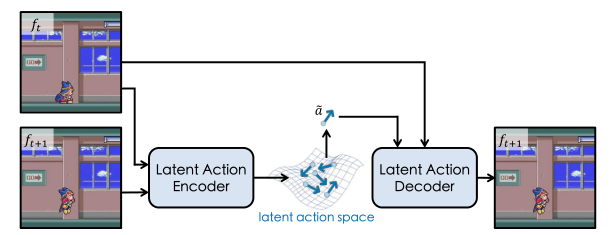
**图 2. 潜在动作自编码器。**通过引入信息瓶颈设计,潜在动作自编码器能够从视频中提取最关键的动作信息,并将其压缩为连续的潜在动作表示。
目标 :

关键设计(非常巧):
-
输入:两帧图像
-
输出:一个 低维连续 latent action
-
约束:
-
latent 很小(信息瓶颈)
-
decoder 必须用它预测下一帧
-
👉 结论:
-
latent action 被"逼迫"只保留
-
与 变化 有关的信息
-
而不是纹理、背景、颜色
-
这就是他们能做到:
-
跨场景迁移动作
-
上下文不敏感
本质上,这是一个"变化最小充分统计量"的学习过程。
2️⃣ β-VAE 的意义
没有用普通 VAE,而是 β-VAE:

3️⃣ Action-aware World Model
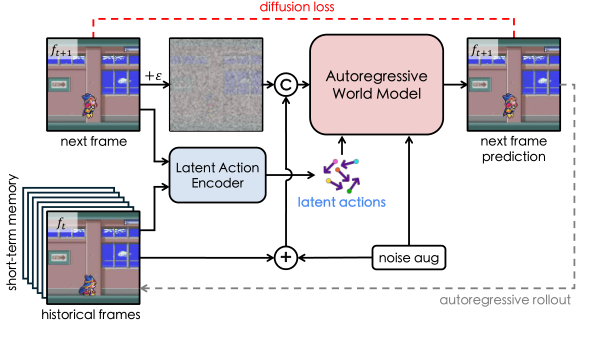
**图 3. 动作感知预训练。**利用潜在动作编码器从无标注视频中提取潜在动作,并将这些潜在动作作为统一的条件,对世界模型进行预训练,使其在推理阶段能够执行自回归式的状态(或帧)展开。
传统预训练:
video → video
(完全不懂"控制")
AdaWorld 预训练:
(history frames + latent action) → next frame
也就是说:
-
世界模型在 预训练阶段就学会:
"如果我施加某种变化因子,世界会怎么变"
重要细节:
-
用 Diffusion world model(基于 SVD)
-
每一步只预测一帧(frame-level control)
-
autoregressive rollout
👉 这一步让模型获得了:
-
动作可控性
-
动作可迁移性
四、效果分析
1️⃣ Action Transfer(不训练,直接迁移)

**图 4. 基于示例的动作迁移。**通过在不同上下文中提取并复用潜在动作,AdaWorld 能够在无需训练的情况下,将源视频中示范的动作直接迁移到多种目标场景中。
-
看一段视频
-
抽 latent actions
-
换一个新场景
-
直接 replay 这些 latent actions
👉 70%+ 的人类评估成功率
(对比 baseline 基本是个位数)
这在认知上非常接近:
"看到别人怎么做 → 在新环境照着做"
2️⃣ 少量交互快速适配
只用:
-
每个动作 100 条样本
-
finetune 800 steps
就能在:
-
Habitat
-
Minecraft
-
DMLab
-
nuScenes(连续动作)
全面超过:
-
action-agnostic
-
optical flow
-
VQ latent action
👉 这对机器人 / embodied AI 是质变级的

**图 5. 动作组合。**在连续的潜在动作空间中,通过对两个潜在动作进行平均来实现动作组合,从而得到一个同时融合两种动作功能的新动作。这表明我们学习到的潜在动作空间在动作语义上具有连续性。
3️⃣ 规划(Planning)能力明显提升
在:
-
Procgen 游戏
-
RoboSuite / VP2 机器人任务
用 MPC / MPPI
AdaWorld:
-
明显优于 action-agnostic
-
甚至优于 Q-learning(在低样本下)
这说明:
latent action 不是"好看",而是真的 可用于决策
真正的创新点
把"动作"从控制信号提升为"可学习的抽象变化因子"
预训练阶段就解决可控性问题
latent 连续 → 可组合 → 可创造新动作
潜在局限
latent action 仍是"隐语义",可解释性有限
对极复杂、多主体交互,是否仍能 disentangle?
diffusion world model 成本仍然不低