1. 前言:从基础到中级的技能跃迁
通过前面的基础语法《金仓数据库KingbaseES基础语法详解与实践指南》的学习,我们已经掌握了KingbaseES的数据操作基本能力。在实际企业级应用开发中,我们面临的往往是更复杂的业务场景:海量数据的高效查询、复杂业务逻辑的封装、并发访问的安全控制、系统性能的持续优化等。中级语法正是连接基础操作与高级应用的桥梁,掌握这些技术将使您能够设计更稳健的数据库架构,编写更高效的SQL语句,解决更复杂的业务问题。
中级语法正是连接基础操作与高级应用的桥梁。掌握这些技术,意味着你能设计出更稳健的数据库架构,编写出更高效的SQL语句,解决更复杂的业务问题。本指南将深入探讨KingbaseES的六大核心中级技术,每个部分都会结合真实的业务场景,通过实际可用的示例和深入分析,帮助你真正理解这些技术的精髓。
2. 高级查询与数据分析技术
2.1 窗口函数:数据分析的利器
窗口函数是KingbaseES中最强大的数据分析功能之一。使用窗口函数(Window Functions)可以让你执行一些复杂的聚合计算,而不需要将数据分组到单独的行中。这对于分析数据中的排名、移动平均、累计总和等场景特别有用。与普通聚合函数不同,窗口函数能够在保留原始行细节的同时,进行跨行的计算分析,这为复杂的数据分析场景提供了极大的便利。
举个例子,销售团队的月度业绩分析:我们不仅要看每个人的销售额,还要知道他在团队中的排名、与平均业绩的差距、累计销售额等等。传统SQL可能需要多次自连接或子查询才能实现,而窗口函数可以一次性搞定。
-- 销售团队业绩多维分析实战
SELECT
salesperson_id,
sales_month,
monthly_sales,
-- 计算销售排名
RANK() OVER (PARTITION BY sales_month ORDER BY monthly_sales DESC) AS rank_in_month,
-- 计算与平均值的差距
monthly_sales - AVG(monthly_sales) OVER (PARTITION BY sales_month) AS diff_from_avg,
-- 计算年度累计(从年初到当前月)
SUM(monthly_sales) OVER (
PARTITION BY salesperson_id
ORDER BY sales_month
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW
) AS ytd_sales,
-- 最近3个月的移动平均
AVG(monthly_sales) OVER (
PARTITION BY salesperson_id
ORDER BY sales_month
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW
) AS moving_avg_3month
FROM sales_performance
WHERE sales_year = 2023
ORDER BY salesperson_id, sales_month;窗口框架的核心理解:这是窗口函数的关键。简单说,它定义了计算时考虑哪些行。比如:
-
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW表示从第一行到当前行 -
ROWS BETWEEN 2 PRECEDING AND CURRENT ROW表示前2行到当前行 -
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING表示前一行、当前行、后一行
2.2 通用表表达式(CTE):复杂查询的模块化工具
CTE让复杂查询变得清晰。它把复杂的SQL分解成多个逻辑步骤,就像写代码时把大函数拆成小函数一样。递归CTE尤其强大,它能优雅处理树形结构数据,比如组织架构、产品分类、评论嵌套等场景。
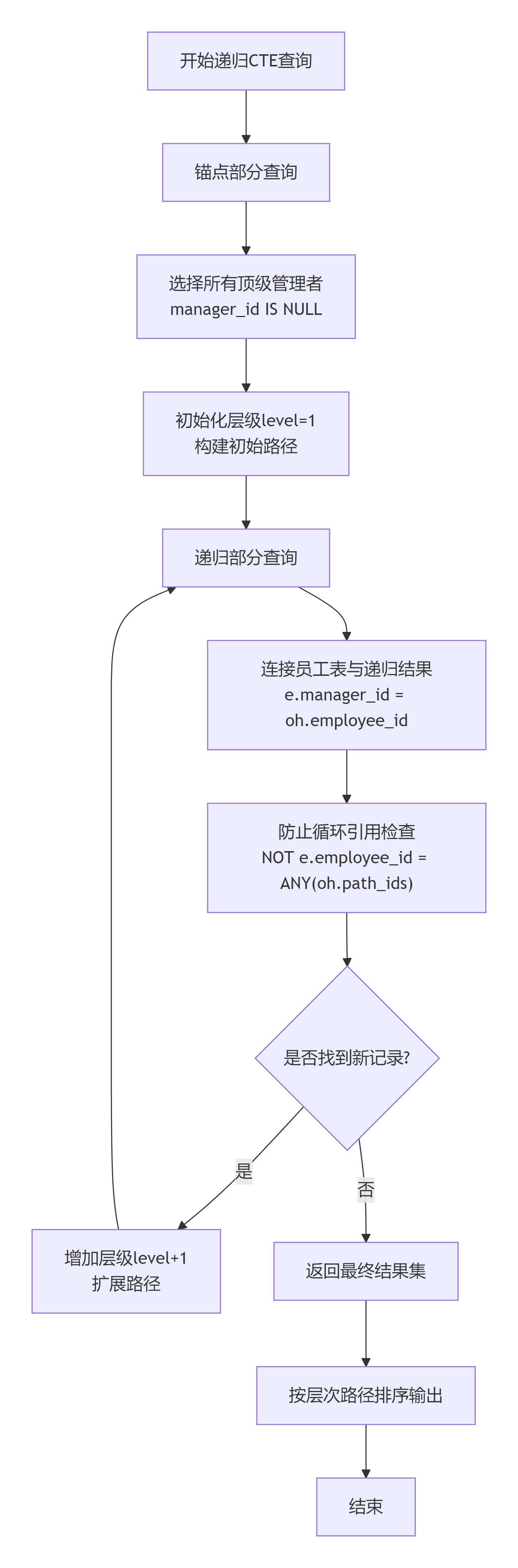
递归CTE实战:构建组织架构全路径
-- 构建完整的组织架构路径
WITH RECURSIVE org_hierarchy AS (
-- 找到所有大领导(没有上级的人)
SELECT
employee_id,
employee_name,
manager_id,
1 AS level,
employee_name AS hierarchy_path,
ARRAY[employee_id] AS path_ids -- 用数组记录路径,防止循环引用
FROM employees
WHERE manager_id IS NULL
UNION ALL
-- 逐级向下找下属
SELECT
e.employee_id,
e.employee_name,
e.manager_id,
oh.level + 1,
oh.hierarchy_path || ' → ' || e.employee_name,
oh.path_ids || e.employee_id
FROM employees e
INNER JOIN org_hierarchy oh ON e.manager_id = oh.employee_id
-- 重要:防止无限递归
WHERE NOT e.employee_id = ANY(oh.path_ids)
)
SELECT
employee_id,
employee_name,
level,
hierarchy_path,
-- 按层级生成缩进,更直观
REPEAT(' ', level - 1) || employee_name AS indented_name
FROM org_hierarchy
ORDER BY hierarchy_path;CTE的性能优势:除了让代码更清晰,CTE还能帮优化器生成更好的执行计划。把复杂查询拆开,KingbaseES能更好地利用统计信息,选择更优的执行策略。
3. 存储过程与函数编程
3.1 函数开发:封装业务逻辑的艺术
在KingbaseES中,函数不只是简单的代码复用,更是业务逻辑的封装。好的函数设计能大幅减少重复代码,确保数据操作的一致性和安全性。
实战:订单价格计算函数
这个函数要考虑商品价格、数量、折扣、会员等级、促销活动等多个因素:
CREATE OR REPLACE FUNCTION calculate_order_price(
p_product_id INTEGER,
p_quantity INTEGER,
p_customer_id INTEGER,
p_coupon_code VARCHAR(20) DEFAULT NULL
) RETURNS DECIMAL(12,2) AS $$
DECLARE
v_base_price DECIMAL(10,2);
v_discount_rate DECIMAL(5,4) DEFAULT 0.0;
v_member_level VARCHAR(10);
v_final_price DECIMAL(12,2);
v_coupon_discount DECIMAL(5,2) DEFAULT 0.0;
BEGIN
-- 1. 先验证参数是否有效
IF p_quantity <= 0 THEN
RAISE EXCEPTION '购买数量必须大于零';
END IF;
-- 2. 获取商品价格,同时检查库存
SELECT price INTO v_base_price
FROM products
WHERE product_id = p_product_id
AND is_active = true
AND stock_quantity >= p_quantity;
IF NOT FOUND THEN
RAISE EXCEPTION '商品不存在或库存不足';
END IF;
-- 3. 获取会员折扣
SELECT
member_level,
CASE member_level
WHEN 'VIP' THEN 0.10
WHEN 'GOLD' THEN 0.08
WHEN 'SILVER' THEN 0.05
ELSE 0.0
END INTO v_member_level, v_discount_rate
FROM customers
WHERE customer_id = p_customer_id;
-- 4. 检查优惠券是否有效
IF p_coupon_code IS NOT NULL THEN
SELECT discount_amount INTO v_coupon_discount
FROM coupons
WHERE coupon_code = p_coupon_code
AND valid_from <= CURRENT_DATE
AND valid_until >= CURRENT_DATE
AND usage_limit > used_count;
IF NOT FOUND THEN
RAISE WARNING '优惠券无效或已过期,将按正常价格计算';
v_coupon_discount := 0.0;
END IF;
END IF;
-- 5. 计算最终价格
v_final_price := v_base_price * p_quantity * (1 - v_discount_rate) - v_coupon_discount;
-- 价格不能是负数
v_final_price := GREATEST(v_final_price, 0);
-- 6. 记录计算日志(方便对账)
INSERT INTO price_calculation_log (
product_id, customer_id, quantity, base_price,
discount_rate, coupon_discount, final_price, calculated_at
) VALUES (
p_product_id, p_customer_id, p_quantity, v_base_price,
v_discount_rate, v_coupon_discount, v_final_price, CURRENT_TIMESTAMP
);
RETURN v_final_price;
EXCEPTION
WHEN NO_DATA_FOUND THEN
RAISE EXCEPTION '相关数据不存在,请检查参数';
WHEN NUMERIC_VALUE_OUT_OF_RANGE THEN
RAISE EXCEPTION '价格计算超出范围,请联系管理员';
WHEN OTHERS THEN
RAISE EXCEPTION '价格计算失败:%', SQLERRM;
END;
$$ LANGUAGE plpgsql SECURITY DEFINER;函数设计经验:
-
**输入验证要严格:**在函数设计中,输入验证是首要考虑因素。对传入参数进行严格检查,包括数据类型、取值范围、格式规范等。对于不符合预期的参数,应在函数入口处立即拒绝,避免无效参数进入后续处理流程。可采用断言或条件判断实现参数校验,确保函数在合法输入下运行。
-
**异常处理要全面:**异常处理机制应覆盖所有可能的错误场景。针对不同错误类型抛出特定异常,并提供清晰易懂的错误信息,包括错误原因和解决方案建议。错误信息应当具体到参数名和期望值,避免使用笼统提示。通过结构化异常处理,帮助调用方快速定位和解决问题。
-
重要操作要记日志:对关键业务逻辑和异常情况记录详细日志,包括操作时间、输入参数、执行结果等信息。日志级别需合理划分,重要操作采用INFO级别,错误场景采用ERROR级别。日志内容应当结构化,便于后续检索分析,同时注意避免记录敏感信息。
-
使用SECURITY DEFINER:对于数据库函数,使用SECURITY DEFINER特性可以精确控制执行权限。该模式下函数以定义者权限运行,而非调用者权限。需谨慎授予函数权限,仅开放必要的数据访问能力。结合角色权限管理,实现最小权限原则,降低安全风险。
-
函数名要见名知义:函数命名应当准确反映功能,采用动词+名词的命名风格。参数设计遵循单一职责原则,避免过多参数。为常用参数设置合理默认值,减少调用复杂度。参数列表按重要性排序,将必选参数前置,可选参数后置。通过参数命名体现业务含义,提升代码可读性。
3.2 存储过程:事务操作的完美封装
存储过程适合封装需要事务支持的复杂操作。和函数不同,存储过程没有返回值,但可以有输出参数,更适合做数据修改。
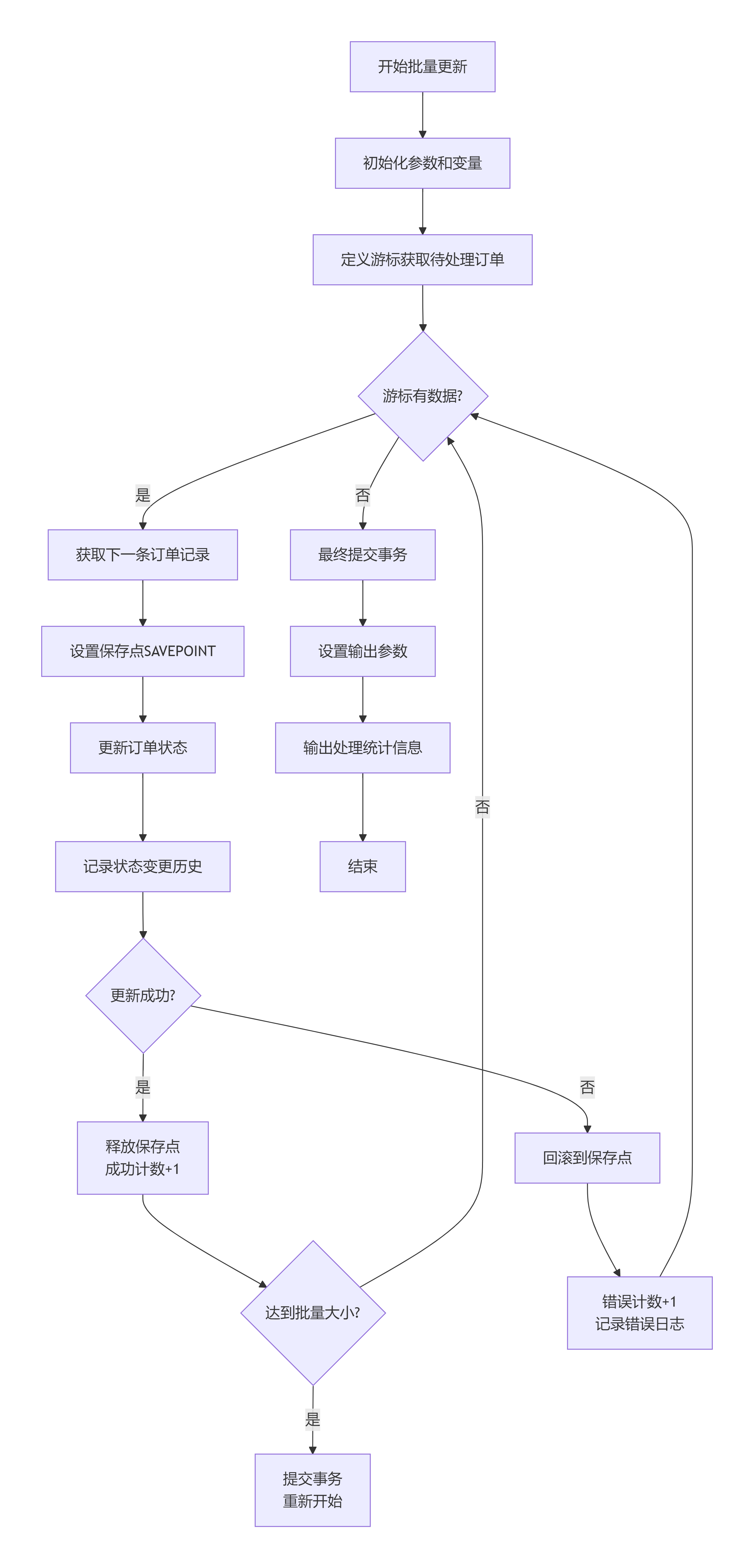
实战:批量订单状态更新
企业应用中经常需要批量操作,比如月度结算、数据迁移、报表生成等:
CREATE OR REPLACE PROCEDURE batch_update_order_status(
p_status_from VARCHAR(20),
p_status_to VARCHAR(20),
p_before_date DATE,
p_max_rows INTEGER DEFAULT 1000,
OUT p_processed_count INTEGER,
OUT p_error_count INTEGER
) AS $$
DECLARE
v_order_record RECORD;
v_success_count INTEGER := 0;
v_fail_count INTEGER := 0;
v_batch_size INTEGER := 100; -- 每批处理100条
-- 定义游标获取要更新的订单
order_cursor CURSOR FOR
SELECT order_id, customer_id, order_date
FROM orders
WHERE order_status = p_status_from
AND order_date < p_before_date
ORDER BY order_date
LIMIT p_max_rows;
BEGIN
-- 初始化输出参数
p_processed_count := 0;
p_error_count := 0;
RAISE NOTICE '开始批量更新:从%到%,截止%',
p_status_from, p_status_to, p_before_date;
-- 一批批处理
FOR v_order_record IN order_cursor LOOP
BEGIN
-- 设置保存点
SAVEPOINT order_update;
-- 更新订单状态
UPDATE orders
SET order_status = p_status_to,
updated_at = CURRENT_TIMESTAMP
WHERE order_id = v_order_record.order_id
AND order_status = p_status_from; -- 乐观锁检查
-- 记录状态变更
INSERT INTO order_status_history (
order_id, old_status, new_status, changed_by, change_reason
) VALUES (
v_order_record.order_id, p_status_from, p_status_to,
current_user, '批量更新'
);
-- 释放保存点
RELEASE SAVEPOINT order_update;
v_success_count := v_success_count + 1;
-- 每处理100条提交一次
IF v_success_count % v_batch_size = 0 THEN
COMMIT;
RAISE NOTICE '已处理 % 条', v_success_count;
-- 重新开始事务
BEGIN;
END IF;
EXCEPTION
WHEN OTHERS THEN
-- 回滚当前订单
ROLLBACK TO SAVEPOINT order_update;
v_fail_count := v_fail_count + 1;
-- 记录失败信息
INSERT INTO batch_process_errors (
process_name, record_id, error_message, error_time
) VALUES (
'batch_update_order_status',
v_order_record.order_id,
SQLERRM,
CURRENT_TIMESTAMP
);
RAISE WARNING '订单 % 失败: %',
v_order_record.order_id, SQLERRM;
END;
END LOOP;
-- 最终提交
COMMIT;
-- 设置输出参数
p_processed_count := v_success_count;
p_error_count := v_fail_count;
RAISE NOTICE '完成:成功 % 条,失败 % 条',
v_success_count, v_fail_count;
EXCEPTION
WHEN OTHERS THEN
ROLLBACK;
RAISE EXCEPTION '批量更新失败: %', SQLERRM;
END;
$$ LANGUAGE plpgsql;存储过程设计要点:
-
批量操作要分批次提交,避免事务过大
-
用游标处理大量数据,避免内存溢出
-
要有完整的异常处理和日志记录
-
输出参数要明确处理结果
-
设置合理的超时和重试机制
4. 高级索引策略与查询优化
4.1 智能索引设计:平衡性能与成本
索引是数据库的"双刃剑":用好了查询快百倍,用不好拖慢更新还占空间。关键是要懂各种索引的适用场景。
复合索引的顺序很重要 ,要遵循"最左前缀匹配"原则。比如对于WHERE department_id = ? AND hire_date > ?,索引(department_id, hire_date)就比(hire_date, department_id)有效得多。
-- 几种实用的索引技巧
-- 1. 部分索引:只索引需要的数据
CREATE INDEX idx_active_high_value_orders ON orders (order_date, customer_id)
WHERE order_status = 'ACTIVE' AND total_amount > 10000;
-- 2. 函数索引:优化表达式查询
CREATE INDEX idx_case_insensitive_name ON customers (LOWER(customer_name));
-- 3. 包含列索引:减少回表
CREATE INDEX idx_order_summary ON orders (order_date, order_status)
INCLUDE (total_amount, customer_id);
-- 4. 多列统计信息
CREATE STATISTICS stats_dept_salary_correlation
ON (department_id, salary) FROM employees;GIN索引处理复杂数据:对于JSONB、数组、全文搜索,GIN索引效率最高。
-- JSONB数据的高效查询
CREATE TABLE product_catalog (
product_id SERIAL PRIMARY KEY,
product_data JSONB NOT NULL,
-- 自动提取常用字段
category VARCHAR(50) GENERATED ALWAYS AS (product_data->>'category') STORED,
price DECIMAL(10,2) GENERATED ALWAYS AS ((product_data->>'price')::DECIMAL) STORED
);
-- 为不同查询创建不同索引
CREATE INDEX idx_gin_product_data ON product_catalog USING GIN (product_data);
CREATE INDEX idx_product_price ON product_catalog (price);
-- 高效的JSONB查询
SELECT product_id, product_data->>'name' as product_name
FROM product_catalog
WHERE product_data @> '{"category": "electronics", "attributes": {"brand": "Kingbase"}}'
AND (product_data->>'price')::DECIMAL BETWEEN 1000 AND 5000
AND product_data->'tags' ? 'promotion';4.2 执行计划深度解读
理解执行计划是优化的第一步。KingbaseES提供了详细的执行计划分析工具。
执行计划分析实战:
-- 开启详细执行计划
SET explain_perf_mode = normal;
-- 分析复杂查询
EXPLAIN (ANALYZE, BUFFERS, FORMAT YAML)
SELECT
c.customer_name,
c.customer_type,
COUNT(DISTINCT o.order_id) as order_count,
SUM(oi.quantity * oi.unit_price) as total_spent,
AVG(oi.quantity * oi.unit_price) as avg_order_value
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id
AND o.order_date >= CURRENT_DATE - INTERVAL '1 year'
LEFT JOIN order_items oi ON o.order_id = oi.order_id
WHERE c.registration_date >= '2022-01-01'
AND EXISTS (
SELECT 1 FROM customer_segments cs
WHERE cs.customer_id = c.customer_id
AND cs.segment_name IN ('VIP', 'FREQUENT_BUYER')
)
GROUP BY c.customer_id, c.customer_name, c.customer_type
HAVING SUM(oi.quantity * oi.unit_price) > 10000
OR COUNT(DISTINCT o.order_id) > 5
ORDER BY total_spent DESC
LIMIT 100;关键指标要看懂:
1.执行时间分析:对比每个步骤的耗时,揪出查询中的拖后腿操作。全表扫描、排序或哈希连接这类操作往往是重灾区。如果某个步骤的执行时间明显比其他步骤长一截,得检查它的执行计划是不是跑偏了。
2.行数估计准确性:优化器预估的行数和实际行数对不上号?这会导致执行计划选错路。如果发现预估和实际差出10倍以上,赶紧更新统计信息(跑ANALYZE),或者看看查询条件是不是写岔了。比如缺索引、过滤条件没写好,都会让优化器算错账。
3.内存使用评估 :work_mem不够用?排序、哈希聚合这些操作会直接跪。如果发现磁盘临时文件(比如temp files日志),就是内存告警的信号。调整内存有个参考公式:
work_mem = (总内存 - shared_buffers) / max_connections
记得留20%的余量,别卡太死。
4.索引使用有效性 :查询有没有走对索引?
常见坑点包括:
- 该用索引却没走:检查条件列和索引定义是否匹配
- 索引失效:比如隐式类型转换或函数调用让索引罢工
- 部分索引不覆盖:确保高频查询条件被索引覆盖
5.连接顺序优化:连接顺序决定了中间结果集的大小。优化器可能因为统计信息不准选了个笨顺序。通过EXPLAIN ANALYZE观察中间行数,必要时手动指定连接顺序(比如调JOIN顺序,或者设join_collapse_limit=1强制按写法执行)。
6.扩展诊断工具
- EXPLAIN (ANALYZE, BUFFERS) 看缓存命中率
- 开auto_explain模块抓慢查询计划
- 用pg_stat_statements逮住高频低效查询
查询重写优化:
-- 原查询(有性能问题)
SELECT product_id, product_name
FROM products
WHERE product_id IN (
SELECT product_id FROM order_items
WHERE order_id IN (
SELECT order_id FROM orders
WHERE order_date >= '2023-01-01'
)
);
-- 优化1:用EXISTS替代IN
SELECT p.product_id, p.product_name
FROM products p
WHERE EXISTS (
SELECT 1 FROM order_items oi
JOIN orders o ON oi.order_id = o.order_id
WHERE oi.product_id = p.product_id
AND o.order_date >= '2023-01-01'
);
-- 优化2:用JOIN重写
SELECT DISTINCT p.product_id, p.product_name
FROM products p
JOIN order_items oi ON p.product_id = oi.product_id
JOIN orders o ON oi.order_id = o.order_id
WHERE o.order_date >= '2023-01-01';
-- 优化3:用LATERAL JOIN
SELECT p.product_id, p.product_name
FROM products p,
LATERAL (
SELECT 1 FROM order_items oi
JOIN orders o ON oi.order_id = o.order_id
WHERE oi.product_id = p.product_id
AND o.order_date >= '2023-01-01'
LIMIT 1
) recent_orders
WHERE recent_orders IS NOT NULL;5. 事务管理与并发控制
5.1 多粒度锁策略
并发控制是数据库的核心难题。KingbaseES提供了多粒度锁机制,要根据业务特点选择合适的策略。
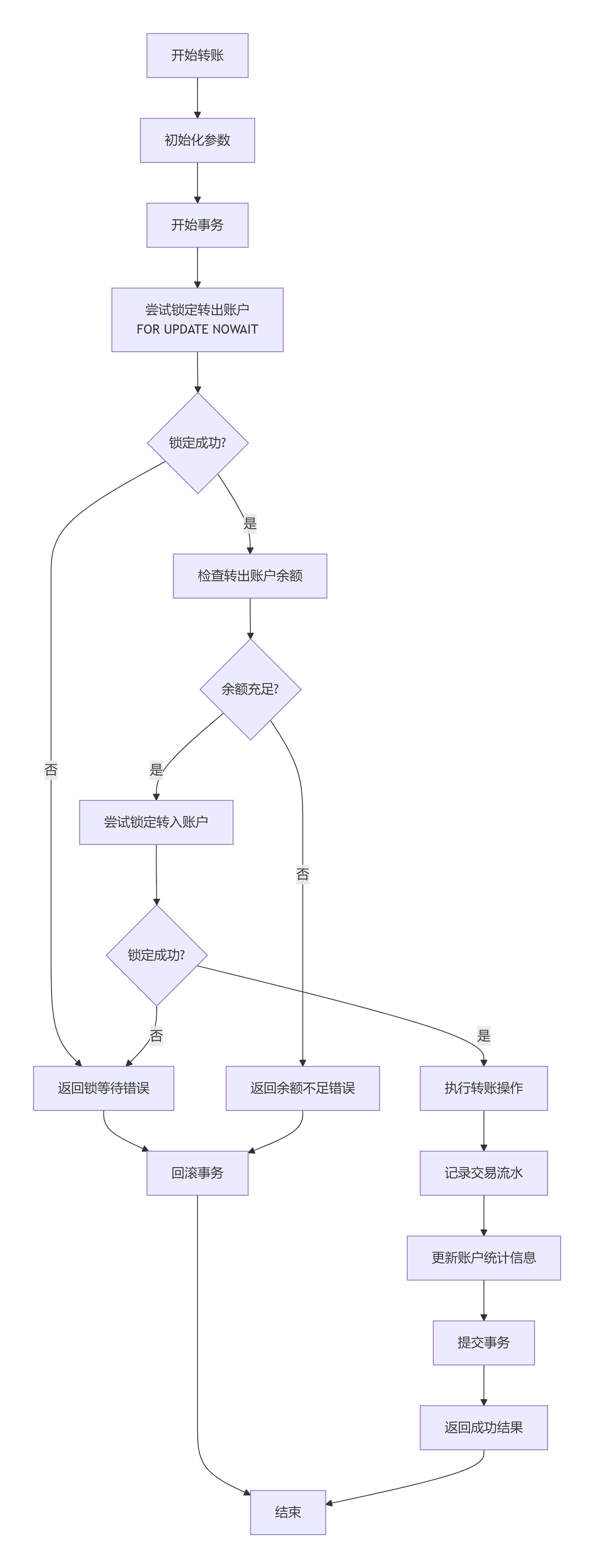
悲观锁实战:适合竞争激烈的场景,比如库存扣减、转账。
-- 银行转账完整示例
CREATE OR REPLACE PROCEDURE transfer_funds(
p_from_account VARCHAR(20),
p_to_account VARCHAR(20),
p_amount DECIMAL(12,2),
p_transaction_id VARCHAR(50),
OUT p_result_code INTEGER,
OUT p_result_msg VARCHAR(200)
) AS $$
DECLARE
v_from_balance DECIMAL(12,2);
v_to_balance DECIMAL(12,2);
v_current_time TIMESTAMP := CURRENT_TIMESTAMP;
BEGIN
p_result_code := 0;
p_result_msg := '成功';
BEGIN
-- 1. 锁定转出账户(不等待)
SELECT balance INTO v_from_balance
FROM accounts
WHERE account_no = p_from_account
FOR UPDATE NOWAIT;
-- 2. 检查余额
IF v_from_balance < p_amount THEN
p_result_code := 1001;
p_result_msg := '余额不足';
ROLLBACK;
RETURN;
END IF;
-- 3. 锁定转入账户
SELECT balance INTO v_to_balance
FROM accounts
WHERE account_no = p_to_account
FOR UPDATE NOWAIT;
-- 4. 执行转账
UPDATE accounts
SET balance = balance - p_amount,
updated_at = v_current_time
WHERE account_no = p_from_account;
UPDATE accounts
SET balance = balance + p_amount,
updated_at = v_current_time
WHERE account_no = p_to_account;
-- 5. 记录流水
INSERT INTO transaction_records (
transaction_id, from_account, to_account,
amount, transaction_type, status, created_at
) VALUES (
p_transaction_id, p_from_account, p_to_account,
p_amount, 'TRANSFER', 'SUCCESS', v_current_time
);
COMMIT;
EXCEPTION
WHEN LOCK_NOT_AVAILABLE THEN
p_result_code := 1002;
p_result_msg := '账户正忙,请稍后重试';
ROLLBACK;
WHEN OTHERS THEN
p_result_code := 9999;
p_result_msg := '系统错误: ' || SQLERRM;
ROLLBACK;
END;
END;
$$ LANGUAGE plpgsql;乐观锁实现:适合读多写少、冲突少的场景。
-- 用版本号的乐观锁
CREATE TABLE inventory_items (
item_id INTEGER PRIMARY KEY,
item_name VARCHAR(100) NOT NULL,
current_stock INTEGER NOT NULL CHECK (current_stock >= 0),
reserved_stock INTEGER DEFAULT 0 CHECK (reserved_stock >= 0),
version INTEGER DEFAULT 0,
last_updated TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 库存预留实现
CREATE OR REPLACE FUNCTION reserve_inventory(
p_item_id INTEGER,
p_quantity INTEGER,
p_session_id VARCHAR(50)
) RETURNS BOOLEAN AS $$
DECLARE
v_current_version INTEGER;
v_available_stock INTEGER;
BEGIN
-- 获取当前版本和库存
SELECT current_stock - reserved_stock, version
INTO v_available_stock, v_current_version
FROM inventory_items
WHERE item_id = p_item_id;
IF NOT FOUND THEN
RAISE EXCEPTION '商品不存在';
END IF;
IF v_available_stock < p_quantity THEN
RAISE EXCEPTION '库存不足,可用:%', v_available_stock;
END IF;
-- 尝试更新(乐观锁核心)
UPDATE inventory_items
SET reserved_stock = reserved_stock + p_quantity,
version = version + 1,
last_updated = CURRENT_TIMESTAMP
WHERE item_id = p_item_id
AND version = v_current_version; -- 版本号必须匹配
IF NOT FOUND THEN
RAISE EXCEPTION '库存信息已变更,请重新尝试';
END IF;
-- 记录预留
INSERT INTO inventory_reservations (
item_id, quantity, session_id, reserved_at, expires_at
) VALUES (
p_item_id, p_quantity, p_session_id,
CURRENT_TIMESTAMP, CURRENT_TIMESTAMP + INTERVAL '30 minutes'
);
RETURN TRUE;
END;
$$ LANGUAGE plpgsql;5.2 死锁预防与处理
死锁难以完全避免,关键是如何预防和快速恢复。
死锁预防策略:
-- 1. 统一锁获取顺序
CREATE OR REPLACE PROCEDURE update_related_accounts(
p_account1 VARCHAR(20),
p_account2 VARCHAR(20)
) AS $$
DECLARE
v_accounts VARCHAR(20)[];
BEGIN
-- 按账号排序,确保顺序一致
v_accounts := ARRAY[p_account1, p_account2];
SELECT ARRAY(SELECT unnest(v_accounts) ORDER BY 1) INTO v_accounts;
-- 按顺序锁定
FOR i IN 1..array_length(v_accounts, 1) LOOP
PERFORM 1 FROM accounts
WHERE account_no = v_accounts[i]
FOR UPDATE NOWAIT;
END LOOP;
-- 执行业务
COMMIT;
END;
$$ LANGUAGE plpgsql;
-- 2. 设置超时
SET lock_timeout = '5s'; -- 锁等待超时
SET statement_timeout = '30s'; -- 语句执行超时
-- 3. 死锁检测和重试
CREATE OR REPLACE FUNCTION safe_update_with_retry(
p_update_sql TEXT,
p_max_retries INTEGER DEFAULT 3
) RETURNS BOOLEAN AS $$
DECLARE
v_retry_count INTEGER := 0;
v_success BOOLEAN := FALSE;
BEGIN
WHILE v_retry_count < p_max_retries AND NOT v_success LOOP
BEGIN
EXECUTE p_update_sql;
v_success := TRUE;
EXCEPTION
WHEN deadlock_detected THEN
v_retry_count := v_retry_count + 1;
RAISE NOTICE '检测到死锁,第 % 次重试', v_retry_count;
-- 指数退避等待
PERFORM pg_sleep(LEAST(0.1 * POWER(2, v_retry_count), 5));
WHEN OTHERS THEN
RAISE;
END;
END LOOP;
RETURN v_success;
END;
$$ LANGUAGE plpgsql;6. 高级数据类型实战
6.1 JSONB深度应用
JSONB让KingbaseES能处理半结构化数据,在微服务、配置管理、用户属性等场景特别有用。
JSONB高级操作:
-- 创建电商商品表
CREATE TABLE ecommerce_products (
product_id BIGSERIAL PRIMARY KEY,
sku VARCHAR(50) UNIQUE NOT NULL,
category_id INTEGER NOT NULL,
base_price DECIMAL(10,2) NOT NULL,
-- 扩展属性用JSONB
attributes JSONB NOT NULL DEFAULT '{}',
-- 自动生成的辅助列
attribute_keys VARCHAR(50)[] GENERATED ALWAYS AS (
ARRAY(SELECT jsonb_object_keys(attributes))
) STORED,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建优化索引
CREATE INDEX idx_product_category ON ecommerce_products (category_id);
CREATE INDEX idx_gin_attributes ON ecommerce_products USING GIN (attributes);
-- JSONB高级查询
WITH product_analysis AS (
SELECT
product_id,
sku,
base_price,
attributes,
-- 提取变体价格
jsonb_path_query_array(attributes, '$.variants[*].price') as variant_prices,
-- 检查促销
attributes->>'on_promotion' as on_promotion
FROM ecommerce_products
WHERE category_id = 101
AND attributes @> '{"brand": "Kingbase"}'
)
SELECT
product_id,
sku,
base_price,
-- 最低变体价格
(
SELECT MIN(value::DECIMAL)
FROM jsonb_array_elements_text(variant_prices) as value
) as min_variant_price,
-- 规格标签
(
SELECT array_agg(value::TEXT)
FROM jsonb_array_elements_text(attributes->'specifications'->'tags') as value
) as specification_tags
FROM product_analysis;
-- JSONB更新
UPDATE ecommerce_products
SET attributes = jsonb_set(
jsonb_set(
attributes,
'{price_history}',
COALESCE(attributes->'price_history', '[]'::jsonb) ||
jsonb_build_object(
'date', CURRENT_DATE,
'price', base_price
)
),
'{last_updated}',
to_jsonb(CURRENT_TIMESTAMP)
)
WHERE product_id = 1001;6.2 数组与范围类型
数组适合存有序的同质数据,范围类型能优雅处理连续值域。
数组操作实战:
-- 用户标签系统
CREATE TABLE user_profiles (
user_id BIGSERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
-- 用户标签数组
tags VARCHAR(30)[] DEFAULT '{}',
-- 兴趣得分
interests JSONB DEFAULT '[]',
-- 活跃时段范围
active_hours INT4RANGE DEFAULT '[9,18]'::INT4RANGE
);
-- 数组查询分析
SELECT
user_id,
username,
-- 数组长度
array_length(tags, 1) as tag_count,
-- 包含特定标签
'科技' = ANY(tags) as tech_interested,
-- 数组交集
tags && ARRAY['阅读','旅游'] as shares_interests,
-- 数组差集
tags - ARRAY['美食','旅游'] as unique_tags
FROM user_profiles
WHERE tags @> ARRAY['科技'] -- 包含科技标签
ORDER BY tag_count DESC;
-- 范围类型应用
CREATE TABLE room_reservations (
reservation_id BIGSERIAL PRIMARY KEY,
room_id INTEGER NOT NULL,
-- 时间范围
reservation_period TSRANGE NOT NULL,
-- 排除重叠预订
EXCLUDE USING gist (room_id WITH =, reservation_period WITH &&)
);
-- 范围查询
SELECT
room_id,
reservation_period,
-- 是否重叠
reservation_period && '[2024-06-01 09:00, 2024-06-01 12:00]'::TSRANGE as conflicts_with_morning
FROM room_reservations
WHERE reservation_period @> '2024-06-01 10:00'::TIMESTAMP
ORDER BY room_id;7. 分区表高级管理
7.1 多级分区策略
数据量大时,合理分区是关键。KingbaseES支持多种分区方式,可以组合使用。
复合分区表示例:
-- 电商订单系统的分区设计
CREATE TABLE order_system.orders (
order_id BIGINT NOT NULL,
customer_id BIGINT NOT NULL,
order_date DATE NOT NULL,
order_status VARCHAR(20) NOT NULL,
total_amount DECIMAL(12,2) NOT NULL,
shipping_region VARCHAR(50) NOT NULL,
-- 主键要包含分区键
PRIMARY KEY (order_date, order_id)
) PARTITION BY RANGE (order_date) -- 一级按日期
SUBPARTITION BY LIST (shipping_region); -- 二级按地区
-- 创建2024年分区
CREATE TABLE order_system.orders_2024
PARTITION OF order_system.orders
FOR VALUES FROM ('2024-01-01') TO ('2025-01-01')
PARTITION BY LIST (shipping_region);
-- 创建地区子分区
CREATE TABLE order_system.orders_2024_east
PARTITION OF order_system.orders_2024
FOR VALUES IN ('北京', '上海', '江苏', '浙江', '安徽');
-- 自动分区管理
CREATE OR REPLACE PROCEDURE order_system.manage_order_partitions(
p_months_ahead INTEGER DEFAULT 3
) AS $$
DECLARE
v_current_date DATE := CURRENT_DATE;
v_partition_date DATE;
v_partition_name TEXT;
BEGIN
-- 创建未来分区
FOR i IN 0..p_months_ahead LOOP
v_partition_date := v_current_date + (i || ' months')::INTERVAL;
v_partition_name := 'orders_' || to_char(v_partition_date, 'YYYY_mm');
IF NOT EXISTS (
SELECT 1 FROM sys_tables
WHERE schemaname = 'order_system'
AND tablename = v_partition_name
) THEN
EXECUTE format('
CREATE TABLE order_system.%I
PARTITION OF order_system.orders
FOR VALUES FROM (%L) TO (%L)
', v_partition_name, date_trunc('month', v_partition_date),
date_trunc('month', v_partition_date) + INTERVAL '1 month');
END IF;
END LOOP;
END;
$$ LANGUAGE plpgsql;7.2 分区表性能优化
分区键选择原则:
-
经常用于查询条件的列
-
数据分布均匀的列
-
避免频繁更新的列
-
考虑业务的时间范围
分区查询优化:
-- 开启分区智能修剪
SET enable_partition_pruning = on;
-- 分区级统计信息
ANALYZE order_system.orders_2024_east;
-- 并行查询优化
SET max_parallel_workers_per_gather = 4;
-- 分区级查询
EXPLAIN (ANALYZE, BUFFERS)
SELECT
shipping_region,
order_status,
COUNT(*) as order_count,
SUM(total_amount) as total_revenue
FROM order_system.orders
WHERE order_date BETWEEN '2024-01-01' AND '2024-03-31'
AND shipping_region IN ('北京', '上海', '江苏')
GROUP BY shipping_region, order_status;8. 综合实战:电商数据分析平台
8.1 完整系统设计
-- 电商数据分析平台
CREATE SCHEMA ecommerce_analytics;
-- 时间维度表
CREATE TABLE ecommerce_analytics.dim_date (
date_id SERIAL PRIMARY KEY,
full_date DATE UNIQUE NOT NULL,
year INTEGER NOT NULL,
month INTEGER NOT NULL,
day_of_month INTEGER NOT NULL
);
-- 销售事实表
CREATE TABLE ecommerce_analytics.fact_sales (
sales_id BIGSERIAL,
date_id INTEGER NOT NULL,
product_id BIGINT NOT NULL,
customer_id BIGINT NOT NULL,
quantity INTEGER NOT NULL,
unit_price DECIMAL(10,2) NOT NULL,
discount_amount DECIMAL(10,2) DEFAULT 0,
net_sales DECIMAL(12,2) GENERATED ALWAYS AS
(quantity * unit_price - discount_amount) STORED,
PRIMARY KEY (date_id, sales_id)
) PARTITION BY RANGE (date_id);
-- 每日销售汇总
CREATE TABLE ecommerce_analytics.agg_daily_sales (
date_id INTEGER PRIMARY KEY,
total_orders INTEGER NOT NULL DEFAULT 0,
total_net_sales DECIMAL(15,2) NOT NULL DEFAULT 0,
new_customers INTEGER NOT NULL DEFAULT 0
);
-- 数据刷新存储过程
CREATE OR REPLACE PROCEDURE ecommerce_analytics.refresh_sales_aggregations() AS $$
DECLARE
v_start_date DATE := CURRENT_DATE - INTERVAL '7 days';
v_end_date DATE := CURRENT_DATE;
BEGIN
-- 清理旧数据
DELETE FROM ecommerce_analytics.agg_daily_sales ag
USING ecommerce_analytics.dim_date dd
WHERE ag.date_id = dd.date_id
AND dd.full_date BETWEEN v_start_date AND v_end_date;
-- 计算聚合数据
INSERT INTO ecommerce_analytics.agg_daily_sales
SELECT
dd.date_id,
COUNT(DISTINCT fs.order_id) as total_orders,
SUM(fs.net_sales) as total_net_sales,
COUNT(DISTINCT CASE
WHEN dc.registration_date = dd.full_date
THEN fs.customer_id
END) as new_customers
FROM ecommerce_analytics.fact_sales fs
JOIN ecommerce_analytics.dim_date dd ON fs.date_id = dd.date_id
JOIN ecommerce_analytics.dim_customer dc ON fs.customer_id = dc.customer_id
WHERE dd.full_date BETWEEN v_start_date AND v_end_date
GROUP BY dd.date_id;
END;
$$ LANGUAGE plpgsql;8.2 高级分析查询
RFM客户分析:
WITH customer_rfm AS (
SELECT
customer_id,
-- 最近购买时间
CURRENT_DATE - MAX(dd.full_date) as recency_days,
-- 购买频率
COUNT(DISTINCT fs.order_id) as frequency,
-- 购买金额
SUM(fs.net_sales) as monetary_value
FROM ecommerce_analytics.fact_sales fs
JOIN ecommerce_analytics.dim_date dd ON fs.date_id = dd.date_id
WHERE dd.full_date >= CURRENT_DATE - INTERVAL '1 year'
GROUP BY customer_id
)
SELECT
-- 客户分群
CASE
WHEN recency_days <= 30 AND frequency >= 10 AND monetary_value >= 10000
THEN '高价值客户'
WHEN recency_days <= 60 AND frequency >= 5
THEN '忠诚客户'
WHEN recency_days <= 30 AND monetary_value >= 5000
THEN '新贵客户'
WHEN recency_days > 180 AND frequency <= 2
THEN '流失风险客户'
WHEN monetary_value <= 1000
THEN '低价值客户'
ELSE '一般客户'
END as customer_segment,
COUNT(*) as customer_count,
AVG(monetary_value) as avg_value
FROM customer_rfm
GROUP BY 1
ORDER BY avg_value DESC;9. 性能监控与故障排查
9.1 系统性能监控
-- 实时性能监控
CREATE VIEW admin.performance_monitor AS
SELECT
now() as check_time,
(SELECT COUNT(*) FROM sys_stat_activity) as active_connections,
(SELECT COUNT(*) FROM sys_stat_activity WHERE state = 'active') as active_queries,
-- 缓存命中率
(SELECT ROUND(blks_hit * 100.0 / NULLIF(blks_hit + blks_read, 0), 2)
FROM sys_stat_database
WHERE datname = current_database()) as cache_hit_rate,
-- 锁监控
(SELECT COUNT(*) FROM sys_locks WHERE mode LIKE '%ExclusiveLock%') as exclusive_locks
FROM sys_stat_database
WHERE datname = current_database();
-- 慢查询日志
CREATE TABLE admin.slow_query_log (
log_id BIGSERIAL PRIMARY KEY,
query_text TEXT NOT NULL,
execution_time INTERVAL NOT NULL,
user_name NAME,
log_time TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);10. 总结与最佳实践建议

通过本指南的学习,您已经掌握了KingbaseES中级语法的核心内容。在实际工作中,建议遵循以下最佳实践:
-
设计优先原则:在编写复杂SQL之前,先设计好数据模型和索引策略
-
性能意识:始终关注查询性能,定期分析执行计划
-
代码可维护性:使用CTE、视图、函数提高代码的可读性和重用性
-
错误处理:为所有存储过程和函数添加完善的异常处理
-
监控与优化:建立性能监控机制,及时发现和解决性能问题
-
安全考虑:合理设置权限,防止SQL注入和数据泄露
KingbaseES作为国产数据库的领军者,其丰富的中级功能为企业级应用开发提供了坚实的技术基础。掌握这些技术,将使您能够设计出更高效、更稳定、更安全的数据库系统,为企业的数字化转型提供有力支撑。
随着技术的不断发展,建议持续关注KingbaseES的新版本特性和最佳实践更新,不断提升自己的技术水平,在实际项目中创造更大价值。如果想链接更多关于金仓数据库,请查看以下两个官网:
-
金仓官网网址:https://kingbase.com.cn
-
金仓社区链接:https://bbs.kingbase.com.cn/
关于本文,博主还写了相关文章,欢迎关注《电科金仓》分类:
第一章:基础与入门(15篇)
1、【金仓数据库征文】政府项目数据库迁移:从MySQL 5.7到KingbaseES的蜕变之路
2、【金仓数据库征文】学校AI数字人:从Sql Server到KingbaseES的数据库转型之路
3、电科金仓2025发布会,国产数据库的AI融合进化与智领未来
5、《一行代码不改动!用KES V9 2025完成SQL Server → 金仓"平替"迁移并启用向量检索》
6、《赤兔引擎×的卢智能体:电科金仓如何用"三骏架构"重塑AI原生数据库一体机》
7、探秘KingbaseES在线体验平台:技术盛宴还是虚有其表?
9、KDMS V4 一键搞定国产化迁移:零代码、零事故、零熬夜------金仓社区发布史上最省心数据库迁移评估神器
10、KingbaseES V009版本发布:国产数据库的新飞跃
11、从LIS到全院云:浙江省人民医院用KingbaseES打造国内首个多院区异构多活信创样板
12、异构多活+零丢失:金仓KingbaseES在浙人医LIS国产化中的容灾实践
13、金仓KingbaseES数据库:迁移、运维与成本优化的全面解析
14、部署即巅峰,安全到字段:金仓数据库如何成为企业数字化转型的战略级引擎
15、电科金仓 KEMCC-V003R002C001B0001 在CentOS7系统环境内测体验:安装部署与功能实操全记录
第二章:能力与提升(10篇)
1、零改造迁移实录:2000+存储过程从SQL Server滑入KingbaseES V9R4C12的72小时
3、在Ubuntu服务器上安装KingbaseES V009R002C012(Orable兼容版)数据库过程详细记录
4、金仓数据库迁移评估系统(KDMS)V4 正式上线:国产化替代的技术底气
5、Ubuntu系统下Python连接国产KingbaseES数据库实现增删改查
7、Java连接电科金仓数据库(KingbaseES)实战指南
8、使用 Docker 快速部署 KingbaseES 国产数据库:亲测全过程分享
9、【金仓数据库产品体验官】Oracle兼容性深度体验:从SQL到PL/SQL,金仓KingbaseES如何无缝平替Oracle?
10、KingbaseES在Alibaba Cloud Linux 3 的深度体验,从部署到性能实战
第三章:实践与突破(13篇)
2、【金仓数据库产品体验官】实战测评:电科金仓数据库接口兼容性深度体验
3、KingbaseES与MongoDB全面对比:一篇从理论到实战的国产化迁移指南
4、从SQL Server到KingbaseES:一步到位的跨平台迁移与性能优化指南
5、ksycopg2实战:Python连接KingbaseES数据库的完整指南
6、KingbaseES:从MySQL兼容到权限隔离与安全增强的跨越
7、电科金仓KingbaseES数据库全面语法解析与应用实践
8、电科金仓国产数据库KingBaseES深度解析:五个一体化的技术架构与实践指南
9、电科金仓自主创新数据库KingbaseES在医疗行业的创新实践与深度应用
11、金仓数据库引领新能源行业数字化转型:案例深度解析与领导力展现
13、Oracle迁移实战:从兼容性挑战到平滑过渡金仓数据库的解决方案
第四章:重点与难点(13篇)
1、从Oracle到金仓KES:PL/SQL兼容性与高级JSON处理实战解析
2、Oracle迁移的十字路口:金仓KES vs 达梦 vs OceanBase核心能力深度横评
3、Oracle迁移至金仓数据库:PL/SQL匿名块执行失败的深度排查指南
4、【金仓数据库产品体验官】Oracle迁移实战:深度剖析金仓V9R2C13性能优化三大核心场景,代码与数据说话!
5、金仓数据库MongoDB兼容深度解析:多模融合架构与高性能实战
后期作品正在准备中,敬请关注......