摘要:医学图像分割对于临床诊断至关重要,但现有模型受限于对明确人工指令的依赖且,缺乏理解复杂临床问题的主动推理能力。尽管近期多模态大语言模型(MLLMs)的进展提升了医学问答(QA)任务的表现,但大多数方法难以生成精确的分割掩码,限制了其在自动医学诊断中的应用。本文中,我们提出了医学图像推理分割这一新颖任务,旨在根据复杂且隐含的医学指令生成分割掩码。**为解决这一问题,我们提出了 MedSeg - R,这是一个端到端的框架,它利用 MLLMs 的推理能力来解读临床问题,同时能够为医学图像生成相应的精确分割掩码。**它基于两个核心组件构建:1)一个全局上下文理解模块,该模块解读图像并理解复杂的医学指令,以生成多模态中间令牌;2)一个像素级定位模块,该模块对这些令牌进行解码,以生成精确的分割掩码和文本响应。此外,我们还推出了 MedSeg - QA,这是一个专门为医学图像推理分割任务定制的大规模数据集。它包含超过 10000 对图像 - 掩码以及多轮对话,这些数据使用大语言模型自动标注,并经过医生审核完善。实验表明,MedSeg - R 在多个基准测试中表现卓越,实现了高分割准确率,并能对医学图像进行可解释的文本分析。
1 引言
医学图像分割在临床诊断和现实世界的医疗决策中起着至关重要的作用。近期的分割模型 19,31,29,11,22,21 在勾勒各种解剖结构和病理区域方面已展现出较高的准确性。然而,尽管这些模型在对预定义类别内的图像进行分割方面表现出色,但它们仍然严重依赖人类的明确指令,例如"识别新冠肺炎感染区域",这类指令提供了像"新冠肺炎"这样明确的参考。在理想的自主医学诊断系统中,医生会提出更开放性的问题,例如"这次检查表明可能存在哪些病症?" 作为回应,系统需要能够提供对患者病情的详细描述以及相应的分割结果(见图 1(a))。然而,当前的模型往往缺乏这种推理能力,这在应对临床问题的复杂性和多变性时构成了重大挑战。
近期,多模态大语言模型(MLLMs) 28,7,31,17,25 在医学领域的快速发展为研究和开发开辟了新途径。这些模型在理解和处理复杂的视觉 - 语言指令以及利用先进的推理机制来改进下游任务方面表现出卓越的能力。因此,多模态大语言模型在各种视觉 - 语言应用中展现出了显著的性能,包括生物医学视觉问答(VQA)和图像标注(如图 1(b)所示)。然而,如表 1 所示,大多数此类模型旨在生成文本响应,因此缺乏像素级定位能力。尽管已经提出了一些具有推理能力的分割模型,如 LISA 15,但它们仍然主要产生文本响应,例如"当然,它是 SEG.1 "。这表明,利用多模态大语言模型的推理能力来完成像素级定位任务(如医学图像分割)的潜力在很大程度上仍有待探索。
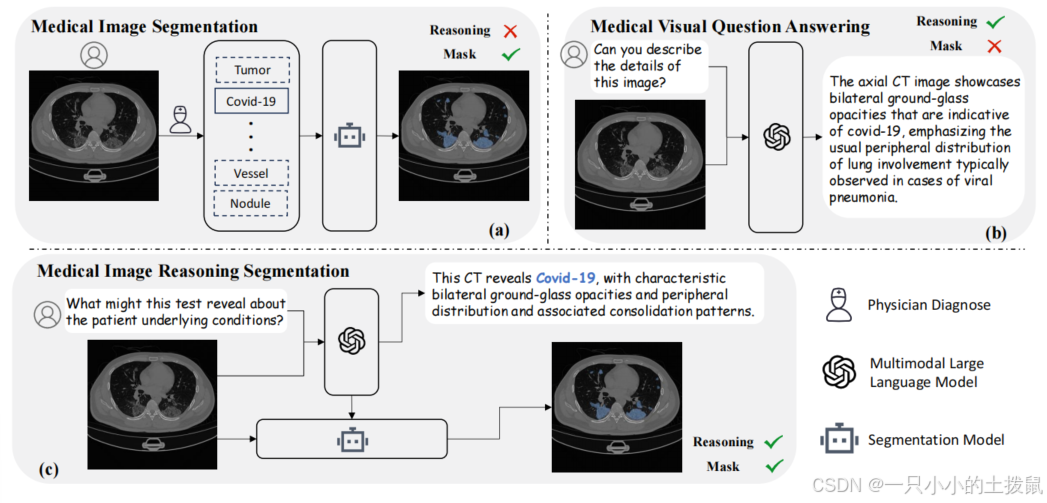
图 1. 医学图像分析中的不同任务。医学图像分割任务(a)严重依赖明确的人工指令来分割所需类别,而医学视觉问答任务缺乏像素级定位能力。我们提出的新任务------医学图像推理分割(c),要求模型同时生成文本响应和相应的分割掩码。
在本文中,我们介绍了一项新颖的任务------医学图像推理分割,该任务基于复杂且隐含的医学指令生成分割掩码。为实现这一目标,我们提出了 MedSeg - R,这是一个端到端的框架,旨在利用多模态大语言模型(MLLMs)的高级推理能力来增强医学图像分割模型(见图 1(c))。具体而言,MedSeg - R 包含两个关键组件:(1)一个全局上下文理解模块,用于处理和解读复杂的图像 - 文本指令对;(2)一个像素级定位模块,通过对多轮推理后的综合文本响应进行解码来生成精确的分割掩码。值得注意的是,MedSeg - R 能够理解隐含且复杂的医学指令,并自主生成相应的分割掩码。这一能力简化了诊断和分割过程,显著提高了医学图像分析的效率和准确性。为进一步增强 MedSeg - R 的推理分割能力并支持更广泛的医学领域,我们引入了 MedSeg - QA,这是一个专门为医学图像推理分割设计的图像 - 掩码 - 对话数据集。MedSeg - QA 通过一个三阶段的自动标注流程构建而成,并辅以医生审核的标注以确保高质量。该数据集包含超过 10000 对图像 - 掩码对,每对都配有详细的多轮对话,全面描述了医学图像的内容。这个丰富的数据集旨在推动医学领域推理分割模型的发展。
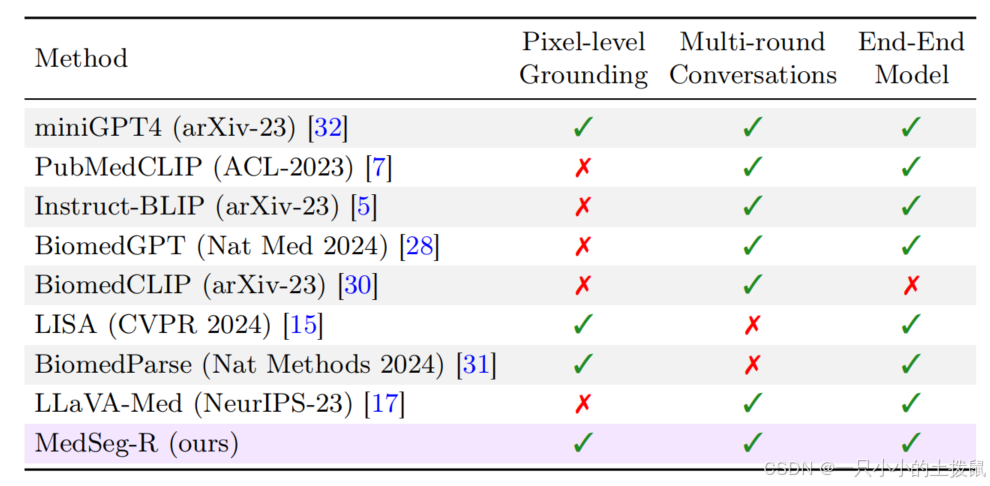
表 1. 近期医学大型多模态模型(LMMs)的比较。
像素级定位一栏突出显示了能够生成分割掩码的模型,而多轮对话则表示支持与用户进行交互式对话的模型。我们提出的模型的独特之处在于,它在端到端训练框架中整合了像素级定位和对话能力,从而能够进行更全面、更灵活的医学图像分析。
2 方法
在本节中,我们首先在 2.1 节定义医学图像推理分割任务,然后在 2.2 节详细介绍 MedSeg - R 的架构和训练目标,接着在 2.3 节描述我们的 MedSeg - QA 数据集的三阶段生成流程。
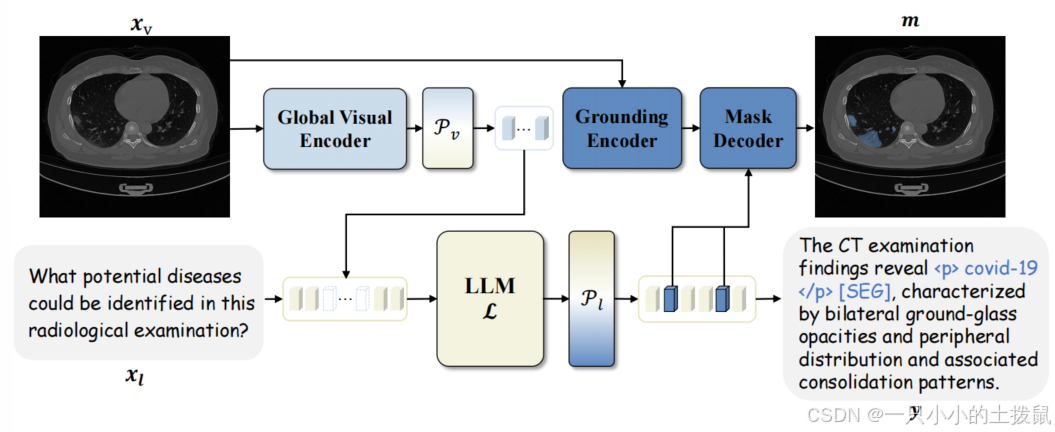
图2. MedSeg - R的架构。该图展示了我们模型利用大语言模型(LLM)的推理能力来生成详细文本响应y,并引导掩码解码器生成精确分割掩码m的能力。
2.1 医学图像推理分割
给定一张医学图像 xv 和一条文本指令 xl,医学图像推理分割任务旨在生成符合该指令的全面文本响应 y,同时生成与该响应对应的精确分割掩码 m。
2.2 MedSeg - R 架构
为解决医学图像推理分割任务,我们为 MedSeg - R 提出了一个综合架构,它由两个主要模块组成:全局上下文理解(GCU)模块和像素级定位(PG)模块。GCU 模块处理医学图像 xv 和文本指令 x_l,以生成一系列中间多模态标记 h_l。
然后将这些标记输入到文本投影层 Pl 以产生文本响应 y,其中包含特殊标记 t_{seg}。随后,这些标记用于指导 PG 模块生成相应的分割掩码。
全局上下文理解模块
GCU 模块由两个核心组件组成:一个全局视觉编码器(V),由采用 ViT - H/14 6 的 CLIP 23 图像编码器实现;以及一个大语言模型(LLM)(L),由 Mistral - 7B 12 模型实现。给定图像 xv 和文本指令 x_l,首先将图像编码为一系列图像标记 s_v = V(x_v)。然后,我们使用一个可训练的线性投影 P_v 将图像标记映射到文本嵌入空间,得到 αv = Pv(s_v)。LLM 将图像标记和文本指令结合起来,生成中间多模态标记 hl:
hl=L(αv,xl)
其中 hl 提供了对医学图像 xv 的全局上下文理解,有效地整合了视觉和文本信息。
像素级定位模块
像素级定位模块采用类似 SAM 的架构,包括一个定位编码器 G、一个文本投影层 Pl 和一个掩码解码器 M。定位编码器可以使用常见的分割骨干网络实现,如 SAM 13 或 Mask2Former 4。在这项工作中,我们应用采用 ViT - H 版本的 SAM 编码器来处理图像 x_v。
给定来自 GCU 的中间多模态输出 hl,h_l 通过 Pl 进行投影,得到文本响应 y = P_l(h_l)。随后,y 会包含特殊标记 t_{seg},例如 "<p> covid - 19 </p> SEG ",这些标记被输入到掩码解码器中,以指导分割掩码 m 的生成。这个过程可以用以下方程概括:
m=M(G(xv),tseg).
训练目标
遵循先前的工作 15,25,总体目标 L 是两个损失 Lt 和 Lm 的加权和,由 λt 和 λm 控制,定义如下方程:
L=λtLt+λmLm,
其中 Lt 表示自回归交叉熵损失,确保高质量的文本生成;Lm 结合二元交叉熵损失和 DICE 损失,以确保生成精确的分割掩码。
2.3 医学影像分割问答数据集生成流程
目前,标注良好的医学影像数据集通常分为两类:其一,包含详细诊断报告、图文说明或与医学影像匹配的多轮问答,但缺乏分割标注的数据集;其二,为医学影像分割任务设计的数据集,这类数据集包含精确的分割标注,但缺乏相应的文本描述。鉴于针对新的医学影像推理分割任务缺乏基准数据集,我们推出了 MedSeg - QA 数据集,该数据集包含 10000 多张带有精确掩码的图像,以及全面描述诊断情况和影像细节的对话内容。MedSeg - QA 涵盖了各种成像方式的医学影像,如 CT、组织学成像和光学成像,涉及广泛的解剖结构和疾病类型,包括肺结节、肿瘤、皮肤镜检查和病理切片等。该数据集通过三阶段流程生成:1)影像图文说明生成;2)影像图文说明优化;3)结构化对话生成。
**影像图文说明生成。**此阶段的目标是为现有的医学分割数据集24,14,2,26添加初步的医学影像图文说明。为实现这一目标,我们采用了最先进的多模态大语言模型 GPT - 41来生成初步的图文说明。具体而言,我们设计了特定于数据集的前缀,以确保图文说明在语境上恰当且与每个数据集高度相关。例如,对于 COVID - 19 CT 数据集24,特定于该数据集的前缀如下:"假设你是一位专业的 AI 胸部 CT 影像助手。医生需要诊断 COVID - 19,你负责分析影像并提供详细、有效且准确的诊断建议。"
然后,我们将这些特定于数据集的前缀,连同标准化的提示信息和影像一起发送给 GPT - 4,以生成初步的影像图文说明。、
**影像图文说明优化。**在这个阶段,我们会让医生进行全面审查,以评估初步影像图文说明的准确性。图文说明正确的影像将被保留,而图文说明有误的影像将重新提交给 GPT - 4,并调整提示信息进行第二轮生成。如果第二轮生成仍无法产生令人满意的结果,医生将对这些影像进行手动标注,以确保优化后的图文说明准确可靠。
**对话生成。**最后,我们基于优化后的图文说明生成多轮对话,以增强推理能力。具体来说,我们向 GPT - 4 提供预定义的问题列表和优化后的图文说明,促使它生成合适的对话,同时突出分割信息
3 结果与分析
3.1 MedSeg - QA 数据集的定性评估
为了展示 MedSeg - R 基于推理的分割能力,我们将 MedSeg - QA 数据集划分为训练集和验证集。图 3 展示了验证集中几个具有代表性的示例。
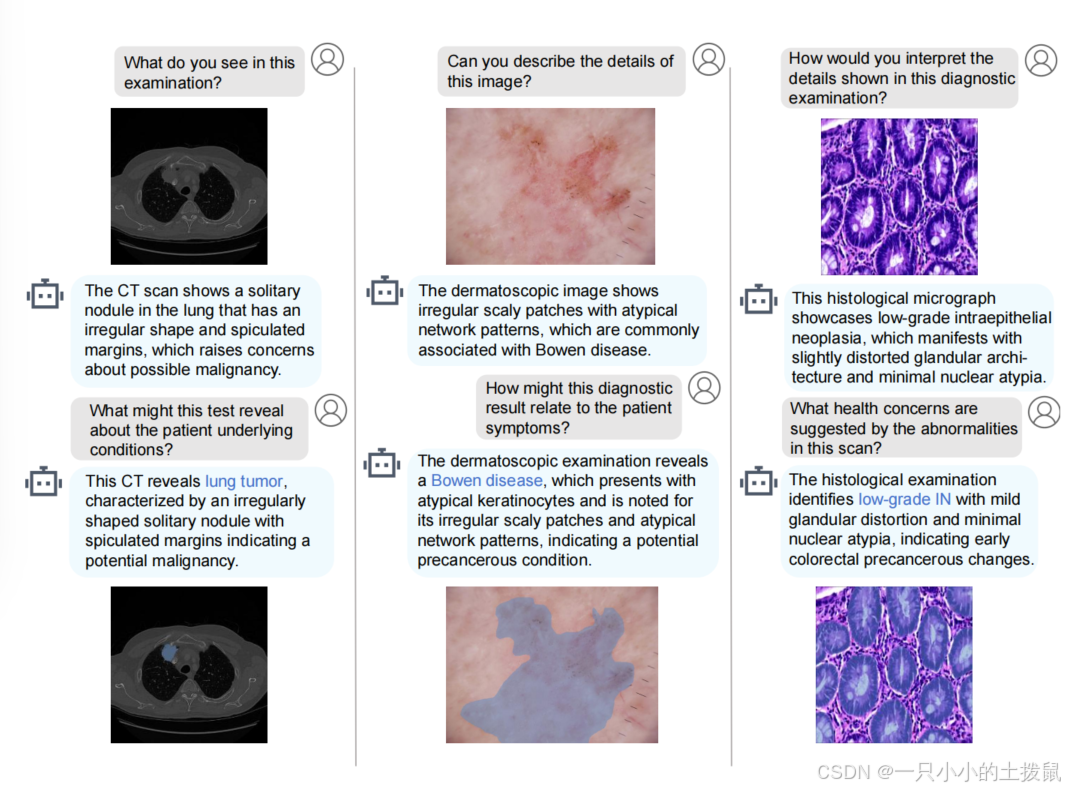
可以观察到,尽管用户的问题具有隐含性,但 MedSeg - R 能够生成详细且具有上下文感知的医学图像描述。此外,它能准确识别相应的异常区域并生成精确的分割掩码,这凸显了其有效将推理与像素级定位相结合的能力。
3.2 生物医学视觉问答和分割任务的评估
为了证明 MedSeg - R 在标准生物医学视觉问答(VQA)和分割任务中同样有效,我们在这两个任务上进行了实验,并取得了有前景的结果。
生物医学 VQA 任务上与最先进方法的比较 我们在三个广泛使用的生物医学 VQA 数据集上评估了我们的模型,数据集详情总结在表 2 中。对于封闭式问题,我们报告准确率作为评估指标,以评估模型正确分类预定义答案的能力。对于开放式问题,我们采用召回率,它衡量了生成响应中出现的真实标记的比例,确保对模型在医学 VQA 中的语言生成能力进行公平评估。结果如表 3 所示。
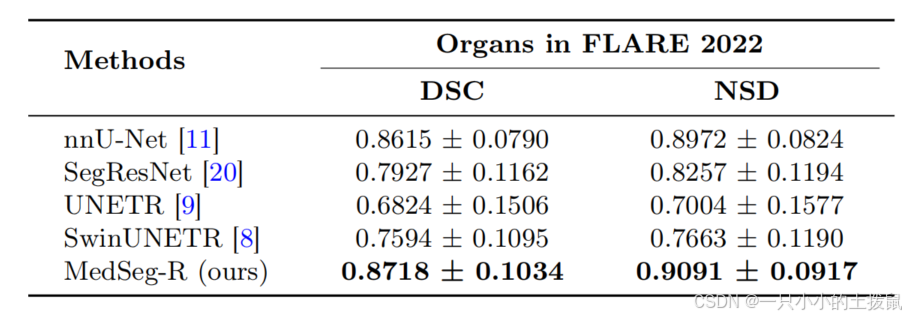
医学图像分割任务上与最先进方法的比较 为了评估我们的模型在医学图像分割中的性能,我们针对医学图像分割竞赛中常用的几种框架进行了比较分析。评估是在 FLARE 2022 数据集上进行的,该数据集包含 13 种不同腹部器官的 CT 扫描图像,使用了两个关键指标:骰子相似度系数(DSC)和归一化表面距离(NSD)。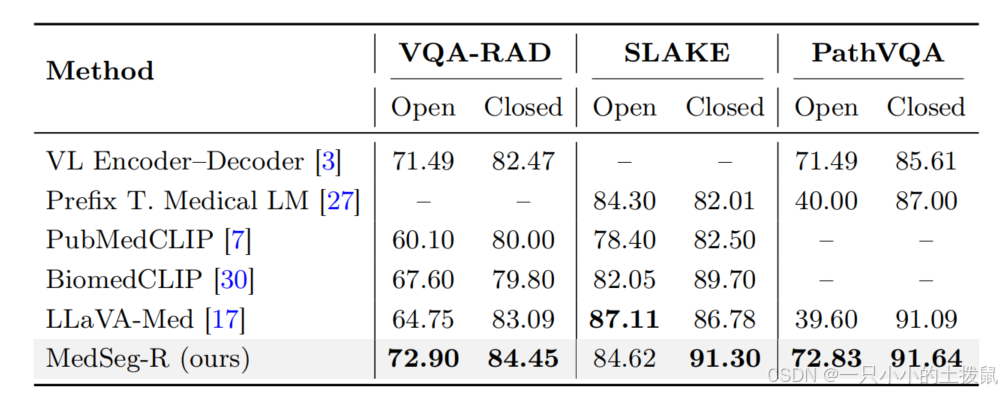
为了确保评估过程的一致性和公平性,我们采用了一个简单统一的文本指令来引导模型生成准确的分割掩码。使用的指令模板是:"请分割医学图像中的<类别名称>",其中"<类别名称>"代表数据集中 13 种腹部器官名称之一。模型的设计响应为:"当然,它是SEG"。在这种设置中,"SEG"标记作为特殊标记,使掩码解码器能够生成相应的分割掩码。
如表 4 中的结果所示,与当前最先进的方法相比,我们的模型保持了具有竞争力的分割性能。
4 结论
在本研究中,我们提出了 MedSeg - R,这是一个将多模态大语言模型集成在一起,通过先进推理来增强医学图像分割的端到端框架。我们还引入了 MedSeg - QA,这是一个拥有超过 10000 条经医生验证注释的大规模数据集。实验表明,MedSeg - R 在分割准确性和推理能力方面超越了现有模型,取得了最先进的成果。通过将医学推理与像素级精度相结合,MedSeg - R 推动了智能医学图像分析的发展,改善了临床诊断,并促进了实际应用。