记录一下我的课程论文中的操作:情感分析
本来我想用R语言实现的,但是我比较擅长python,于是我就开始尝试用python调用第三方平台来完成这个操作,经过一下午的尝试,我还真成功了,所以就出现了这篇文章。
我用的方法是用python调用百度智能云API,首先先进入它的官网:
然后我们要先看看技术文档,不然不知道怎么编写调用代码
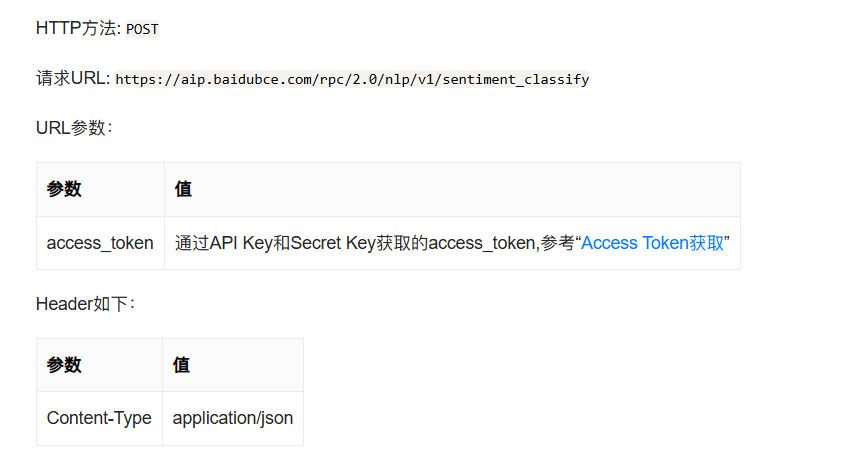
根据指示,我们要获取access_token,这时候我们就要看官方提供的示例代码了
python
import requests
import json
API_KEY = "kt3GJiqjEbDBmnRtXUOBkwBJ"
SECRET_KEY = "fAvEUHdY6ZWhjr3GezgJqCFUskjyhRU4"
def main():
url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token=" + get_access_token()
payload = json.dumps("", ensure_ascii=False)
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload.encode("utf-8"))
response.encoding = "utf-8"
print(response.text)
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
if __name__ == '__main__':
main()运行结果如下:

我们来解读一下结果:log_id是本次请求的唯一日志,用于定位和排查问题,然后就是我们的参数无效,说明我们要上传必要参数,也就是要获取access_token。
以下是我编写的获取access_token的代码(初始版):
python
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=kt3GJiqjEbDBmnRtXUOBkwBJ&client_secret=fAvEUHdY6ZWhjr3GezgJqCFUskjyhRU4"
url1 = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify"
payload = "你好"
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
if __name__ == '__main__':
main()运行结果中的access_token是这样的:

再看技术文档里的提示:
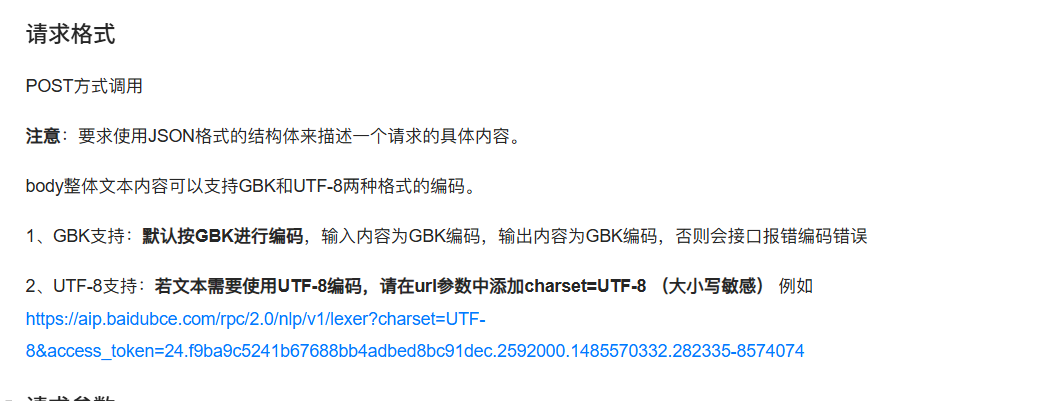
我们要自行拼接一下我们自己的网址:
python
def main():
url = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=kt3GJiqjEbDBmnRtXUOBkwBJ&client_secret=fAvEUHdY6ZWhjr3GezgJqCFUskjyhRU4"
url1 = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify"
payload = "你好"
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
print(response.json())
# print(type(response.json()))
# print(response.json()['access_token'])
mytoken = response.json()['access_token']
url2 = url1 + "?charset=UTF-8&access_token=" + mytoken
print(url2)
if __name__ == '__main__':
main()结果如下:

好的,我们的access_token就获取成功了。
接下来我们就到了重要步骤:在百度智能云上创建一个自己的项目,创建好之后就是下面的界面:
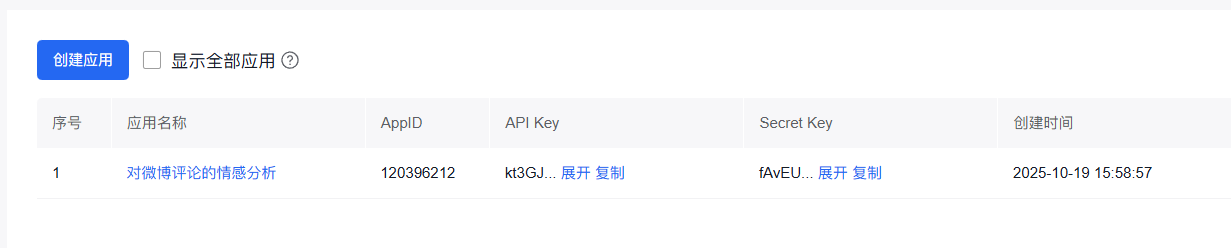
为什么要创建呢,是因为我们调用的时候需要用到上图中的API Key和Screct Key。
以下就是我的完工版本,只不过仅仅适用于单行数据分析:
python
import requests
import json
def main():
# 1. 获取Token
token_url = "https://aip.baidubce.com/oauth/2.0/token"
token_params = {
"grant_type": "client_credentials",
"client_id": "kt3GJiqjEbDBmnRtXUOBkwBJ",
"client_secret": "fAvEUHdY6ZWhjr3GezgJqCFUskjyhRU4"
}
token_response = requests.post(token_url, data=token_params)
token_data = token_response.json()
if "access_token" not in token_data:
print("获取Token失败:", token_data)
return
access_token = token_data["access_token"]
# 2. 情感分析请求
sentiment_url = "https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify"
sentiment_payload = {
"text": "你好"
}
# 修正:Content-Type 应该是 "application/json"
sentiment_headers = {
"Content-Type": "application/json",
"Accept": "application/json"
}
# 拼接Token到URL
request_url = f"{sentiment_url}?access_token={access_token}"
# 发送请求
sentiment_response = requests.post(
request_url,
headers=sentiment_headers,
data=json.dumps(sentiment_payload, ensure_ascii=False).encode("utf-8") # 确保中文正确编码
)
print("情感分析结果:", sentiment_response.json())
if __name__ == "__main__":
main()这里我设置的文本是"你好",接下来对其进行分析,运行结果如下:

处理单行数据的都搞定了,那就得试试多行数据的了,毕竟我们不可能一行一行地分析,以下是我写的版本。
python
import pandas as pd
import requests
import json
# 1. 读取Excel数据
df = pd.read_excel("clean_text.xlsx")
text_list = df["clean_text"].tolist()
# 2. 获取百度API的Access Token
def get_access_token():
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": "kt3GJiqjEbDBmnRtXUOBkwBJ",
"client_secret": "fAvEUHdY6ZWhjr3GezgJqCFUskjyhRU4"
}
response = requests.post(url, data=params)
return response.json().get("access_token")
access_token = get_access_token()
if not access_token:
print("获取Token失败!")
exit()
# 3. 情感分析函数
def get_sentiment(text, token):
url = f"https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?access_token={token}"
payload = json.dumps({"text": text})
headers = {"Content-Type": "application/json"}
try:
response = requests.post(url, headers=headers, data=payload)
return response.json()
except Exception as e:
print(f"请求失败: {e}")
return None
# 4. 批量分析文本情感
results = []
for text in text_list:
result = get_sentiment(text, access_token)
if result:
print(f"文本: {text} -> 结果: {result}")
results.append(result)
else:
results.append({"error": "分析失败"})
# 5. 结果写回Excel
df["情感分析结果"] = results
df.to_excel("result_with_sentiment.xlsx", index=False)
print("分析完成,结果已保存到 result_with_sentiment.xlsx")接下来回到技术文档,以下是返回参数:
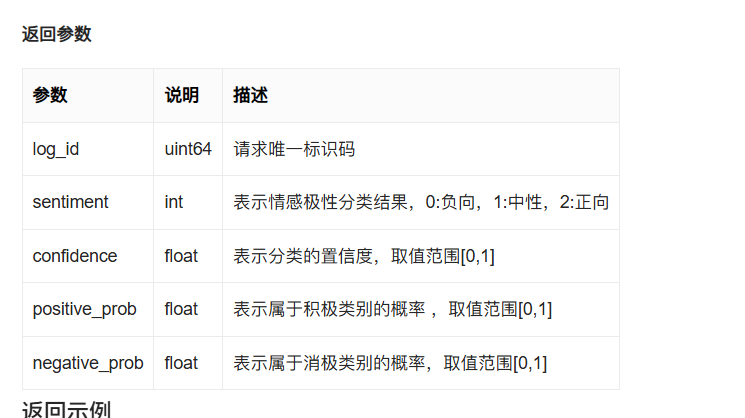
顾名思义,我们的结果中会出现这些结果,也就是我的代码运行效果:

每条数据的分析结果都是这样的,这里是一部分截图。
有了每条数据的分析结果,我们来继续分析总体效果。因为我的每一步都要有操作结果,所以我把代码编辑器换成了jupyter nootbook,以下是我的分析过程及结果:
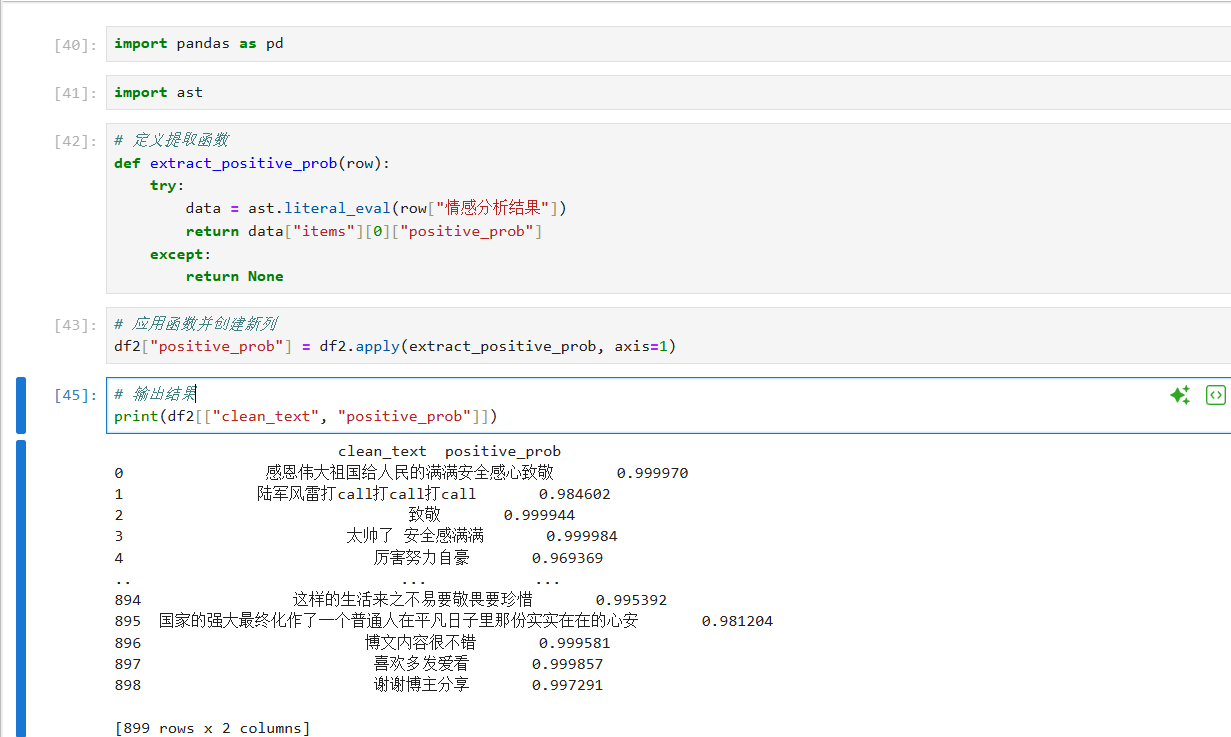
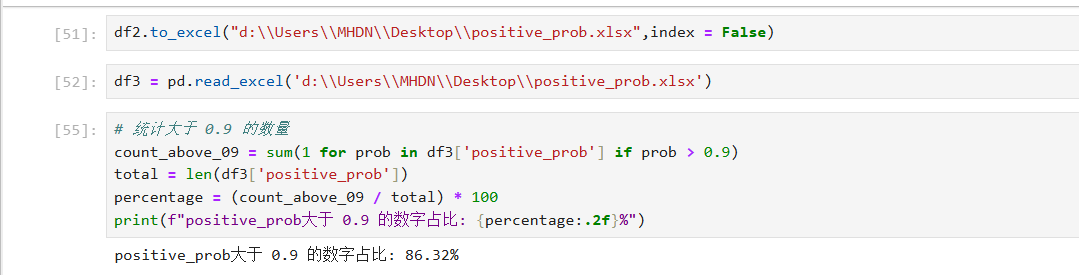
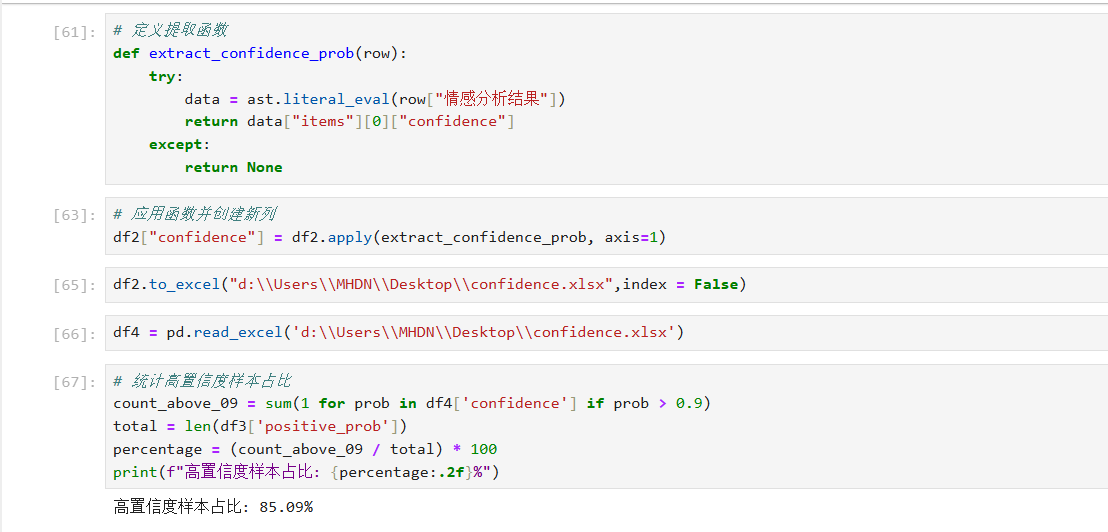
ok,所以我本次的情感分析也就完成了,我写的可能不是很好,有兴趣的同学可以和我探讨一下,内容仅供参考。