噗,这个标题是不是有点AI味?哈哈,确实有让AI起名,但只是起了个名,我原来的标题是:"给你的数据接口提提速,聊聊二级缓存的架构设计"
前言
前阵子给项目做了点性能优化,最核心的手段就是加上了二级缓存的设计,趁着今天有机会,我想好好聊聊这个话题。
事实上,我们的业务系统一直在采用这一套基于Redis的缓存策略,但最近我们上线的这套系统,是一个可预见的高并发系统,顺利上线的话,可能比以往任何系统的并发量都要高,所以我觉得仅靠Redis就显得有些力不从心了。在大规模流量冲击下,Redis 的网络 I/O、内网带宽以及频繁的反序列化开销,会逐渐成为压垮 Web 服务器CPU的最后一根稻草。
为了提早消除隐患,我稍微改造了一下原有的缓存架构,增加了二级缓存的设计,这其中也踩了点小坑,拿出来一看聊聊。
架构设计
我这里的系统,缓存架构是基于EasyCaching这个第三方库构建的,当然这个不是核心,如果你不喜欢第三方库,完全可以基于原生api自行构造。
一级缓存(L1)
一级缓存的载体就是内存,这是超高并发场景下最有效的防护罩,从计算机硬件上,它离CPU最近,执行速度极快,也没有网络开销,我觉得市面上所有多级缓存的架构设计,第一层基本都得是内存吧。
二级缓存(L2)
二级缓存就是Redis了,它负责数据共享和持久化支撑,是一级缓存穿透后的坚实后盾。因为我们的系统基本都是分布式部署的,所以为了保证架构的简单性,之前的项目里都是直接用Redis做缓存的,引入L1后,它也如释重负了,在高并发的场景下,它的核心作用主要是确保高可用和平衡多个服务节点的数据一致性了。
三级缓存(L3)
其实三级就不叫缓存,就直接落到数据库了,当二级缓存失效,请求最终还是会来到数据库,我们之前写过的检索逻辑还是一切如常,不需要为多级缓存的设计过度修改,但此时它的压力就更小了,在前面两层防护的保护下,即便是高并发的场景,应付起来也能游刃有余。
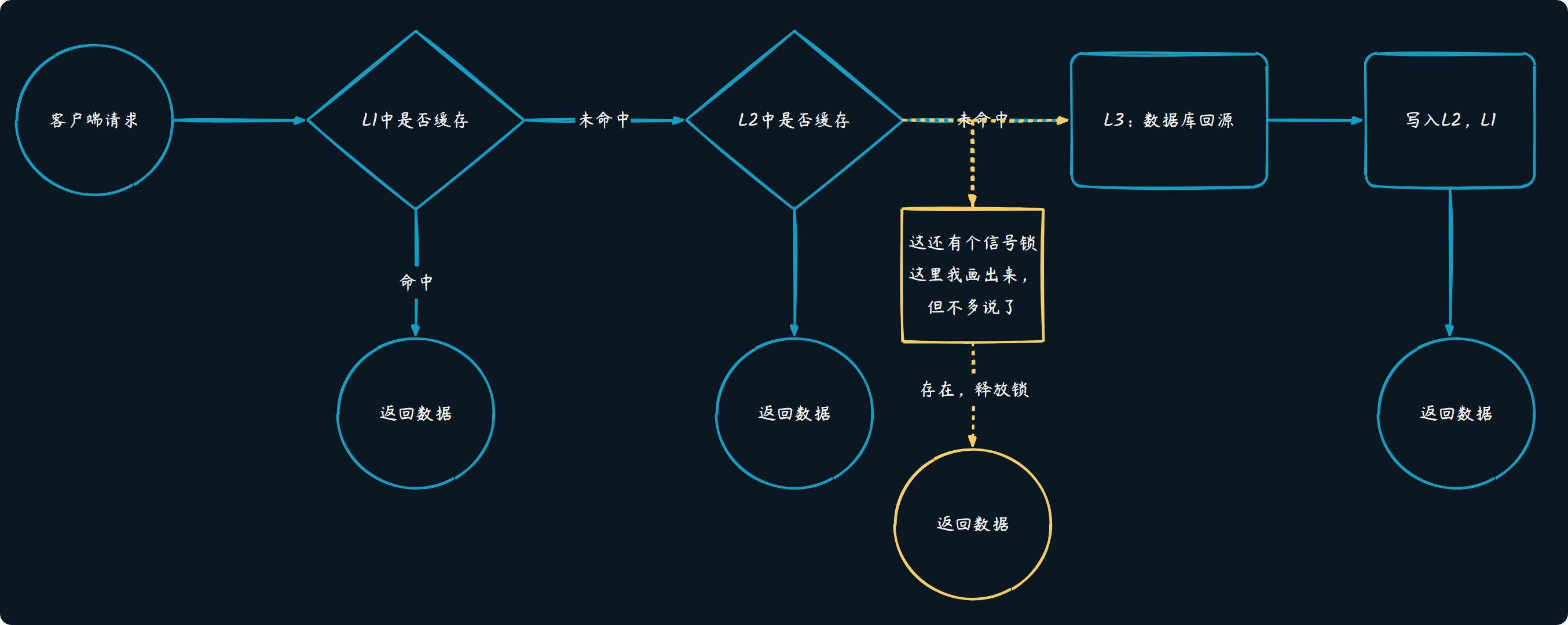
架构图*
这个架构图如下,需要说明的是,当2级缓存没有命中的话,并不是直接去数据库查询,因为这里还设计了一个信号锁,而关于信号锁的作用主要是预防缓存击穿,当某个热点Key过期后,只有1个线程去查数据库,其他线程会在信号量处等待,然后直接读取第一个线程查出来的缓存。更多的内容大家可以自行GPT一下。实际理解起来,可以跳过这点,认为L2失效就是打到数据库就可以了。
代码
安装依赖
因为我这里依赖了EasyCaching的生态,所以需要先引入EasyCaching.Memory和EasyCaching.CSRedis。
注意EasyCaching对于Redis的封装包有两个,CSRedis和Redis,CSRedis是国人封装的,对中文系统应该来说更接地气一点,配置更简单,而Redis就是基于StackExchange.Redis,底层实现虽有差别,但在EasyCaching里提供的抽象接口都是一致的,所以用谁都可以。
xml
<PackageReference Include="EasyCaching.InMemory" Version="1.9.2" />
<PackageReference Include="EasyCaching.CSRedis" Version="1.9.2" />注入服务
csharp
services.AddEasyCaching(options =>
{
options.UseCSRedis(configuration, "redis", "Easycaching:redisSentinel")
options.UseInMemory(conf =>
{
conf.MaxRdSecond = 2;
conf.EnableLogging = false;
conf.DBConfig = new EasyCaching.InMemory.InMemoryCachingOptions
{
SizeLimit = 1024
};
}, "memory");
});我这里redis是以哨兵集群的方式接入,配置文件如下
json
"redisSentinel": {
"MaxRdSecond": 5,
"EnableLogging": false,
"LockMs": 5000,
"SleepMs": 300,
"SerializerName": "redis",
"dbconfig": {
"ConnectionStrings": [
"略"
],
"Sentinels": [
"节点1",
"节点2",
"节点3"
],
"ReadOnly": false
}
},需要注意MaxRdSecond这个参数,我这里设置的默认值在redis里是5,内存里是2,这个参数的意义是EasyCaching为了预防出现缓存雪崩的一个小设计,在写入缓存的时候随机加入一个不大于这个MaxRdSecond的时长,所以这个值是多少,或者需不需要用,还是要看你的项目场景。
接口和实现
csharp
public interface IMultiLevelCacheService
{
Task<T> GetOrCreateAsync<T>(string key, Func<Task<T>> factory, int? l2Seconds = null, CancellationToken ct = default);
Task<Result<T>> GetOrCreateForResultAsync<T>(string key, Func<Task<Result<T>>> factory, int? l2Seconds = null, CancellationToken ct = default);
Task RemoveAsync(string key, CancellationToken ct = default);
}
public class MultiLevelCacheService : IMultiLevelCacheService
{
private readonly IEasyCachingProvider _l2Provider; // Redis
private readonly IEasyCachingProvider _l1Provider; // Memory
private readonly ILogger<MultiLevelCacheService> _logger;
private readonly MultiLevelCacheOptions _options;
//本地锁,防止同一个 Key 的缓存失效时,大量请求同时冲向数据库(防击穿)
private static readonly ConcurrentDictionary<string, SemaphoreSlim> _locks = new();
public MultiLevelCacheService(
IEasyCachingProviderFactory factory,
IOptions<MultiLevelCacheOptions> options,
ILogger<MultiLevelCacheService> logger)
{
_l2Provider = factory.GetCachingProvider("redis");
_l1Provider = factory.GetCachingProvider("memory");
_logger = logger;
_options = options.Value;
}
public async Task<Result<T>> GetOrCreateForResultAsync<T>(
string key,
Func<Task<Result<T>>> factory,
int? l2Seconds = null,
CancellationToken ct = default)
{
//预处理过期时间
NormalizeL2Seconds(ref l2Seconds);
var l1Seconds = CalculateL1Seconds(l2Seconds!.Value);
//尝试从一级缓存读取 (最快)
var l1Result = await _l1Provider.GetAsync<T>(key, ct);
if (l1Result.HasValue)
{
ConsoleHelper.WriteLine("1级缓存命中:" + key, ConsoleColor.DarkGreen);
return Result<T>.Success(l1Result.Value);
}
//尝试从二级缓存读取
try
{
var l2Result = await _l2Provider.GetAsync<T>(key, ct);
if (l2Result.HasValue)
{
ConsoleHelper.WriteLine("2级缓存命中:" + key, ConsoleColor.DarkBlue);
//取 Redis 剩余 TTL 和配置上限的最小值,塞回L1
var ttl = await _l2Provider.GetExpirationAsync(key, ct);
var remainingL1 = NormalizeRemainingSeconds(ttl, l1Seconds);
await _l1Provider.SetAsync(key, l2Result.Value, TimeSpan.FromSeconds(remainingL1), ct);
return Result<T>.Success(l2Result.Value);
}
}
catch (Exception ex)
{
_logger.LogWarning(ex, "L2 缓存读取异常,Key: {Key}", key);
}
//防击穿加锁回源获取或创建针对该 Key 的信号量
var semaphore = _locks.GetOrAdd(key, _ => new SemaphoreSlim(1, 1));
await semaphore.WaitAsync(ct);
try
{
//在获取锁的期间,可能上一个线程已经把缓存写好了
var doubleCheck = await _l1Provider.GetAsync<T>(key, ct);
if (doubleCheck.HasValue) return Result<T>.Success(doubleCheck.Value);
ConsoleHelper.WriteLine("缓存未命中,回源加载数据:" + key, ConsoleColor.DarkYellow);
//执行回源业务逻辑
var freshResult = await factory();
//成功则写入双级缓存
if (freshResult.IsSuccess)
{
await WriteBothAsync(key, freshResult.Value, l2Seconds.Value, l1Seconds, ct);
}
return freshResult;
}
finally
{
semaphore.Release();
//如果没有人在等待这个锁了,可以从字典中移除(节省内存)
if (semaphore.CurrentCount > 0) _locks.TryRemove(key, out _);
}
}
public async Task<T> GetOrCreateAsync<T>(string key, Func<Task<T>> factory, int? l2Seconds = null, CancellationToken ct = default)
{
//逻辑与上面类似,仅返回值处理不同,此处略
var result = await GetOrCreateForResultAsync(key, async () => {
var val = await factory();
return Result<T>.Success(val);
}, l2Seconds, ct);
return result.Value;
}
public async Task RemoveAsync(string key, CancellationToken ct = default)
{
await Task.WhenAll(
_l1Provider.RemoveAsync(key, ct),
_l2Provider.RemoveAsync(key, ct)
);
}
}大概解释下,我这里主要用到的方法实现是GetOrCreateForResultAsync,因为我的数据接口场景里,数据回传到接口层时,外层包了一个统一的Result,接口案例如下
csharp
[HttpGet("GetArticleDetail/{id}")]
public async Task<IActionResult> GetArticleDetail(long id)
{
string cacheKey = ApiCachePrefixKeys.BuildKey(ApiCachePrefixKeys.DecArticles, id); ;
var result = await _multiLevelCacheService.GetOrCreateForResultAsync(
cacheKey,
() => _decArticleRepo.GetArticleDetail(id));
//不用缓存时
//var result = await _decArticleRepo.GetArticleDetail(id);
if (result.IsSuccess)
{
return Ok(ApiResult.Success(result));
}
return Accepted(ResultExtensions.ToApiResult(result));
}这是一个读取文章的案例,增加缓存机制后,需要将编译后的委托缓存起来,所以写法看起来是现在这个样子。
如果不需要外层包Result,直接拿到数据对象,那就可以直接使用GetOrCreateAsync就好。
执行效果
最后,看一下执行的效果,第一次请求数据,未命中缓存
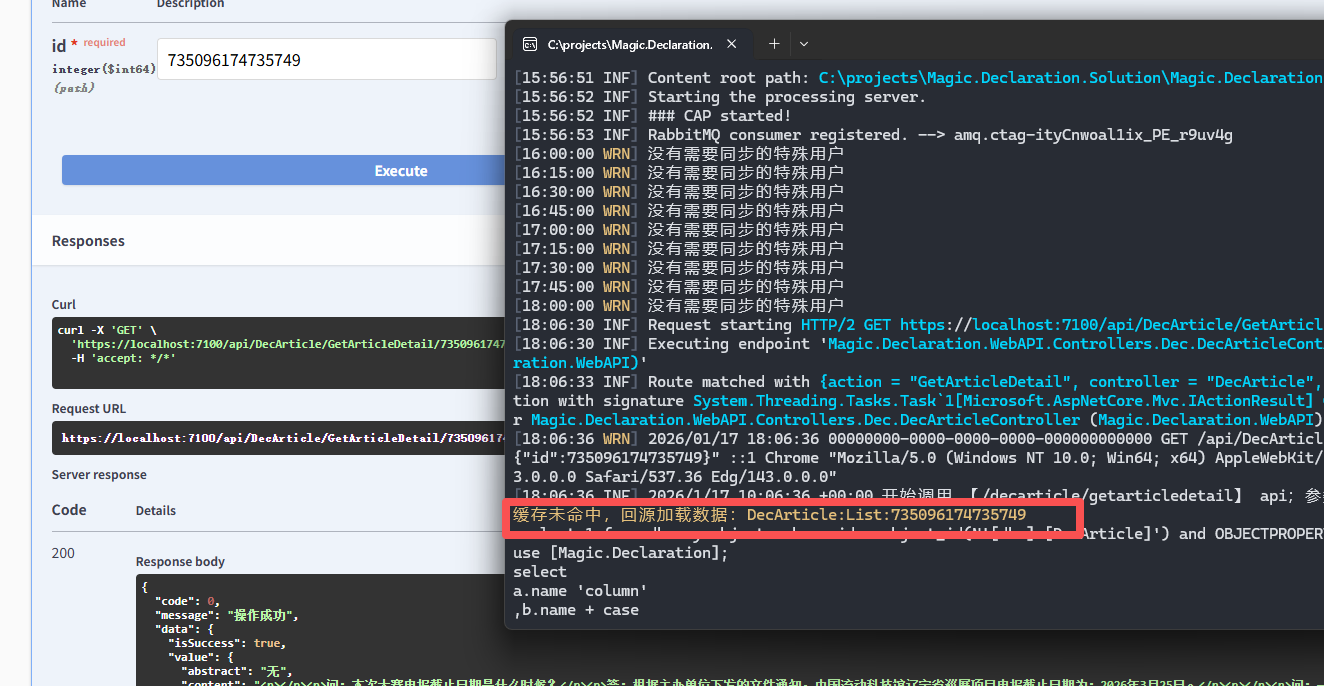
此时Redis里可以看到我们刚刚缓存的数据

接下来马上进行第二次请求,如期命中一级缓存L1

再过一小会儿,在请求,按预期命中二级缓存L2

至此,我们的缓存架构就基本完成了,而删除缓存的案例就不演示了,
一个小坑*
如同我前面说到我的场景里特殊的返回值类型,目前是缓存的编译后的委托,而在这之前,为了追求方便我使用的表达式函数,像下面这样
csharp
var freshResult = await methodCall.Compile()();看起来也不错,而且注意这是2个括号,第一个括号是把表达式函数编译成委托,返回一个Func<Task>,第二个括号才是的到这个函数之后的执行。而问题也就出在这两个"括号"上,这样看起来优雅,实际上隐藏着很大的性能隐患,就在第一个括号执行的时候,会调用CPU执行IL编译,尽管有前面2层缓存做防护,真到了高并发的场景,一下子多次执行编译工作,CPU也得冒烟,这就得不偿失了,最后改成了现在的样子。当然肯定不是所有小伙伴都能遇到这个问题,但如果恰好遇到,又恰好也看到这,只能说咱们太有缘了,点个关注吧哈哈。
结语
最后,我经常听到一些阴阳怪气的声音,什么"就你这业务量,还搞多级缓存?""不想着早点交差,一天在这些地方浪费时间有什么用"...巴拉巴拉。
我说想,有这种声音的人,如果你真的理解技术,理解业务,也亲身验证过这个技术不适合你的业务,那你说什么都OK。
而现实情况是,大部分所谓的专家,基本都不做验证性工作,他们只想着交差,恨不得代码写完再也不改,连自己写的代码都不想多看一眼。。。这种人发出的这种声音,我的态度是,当放屁就好,千万别让他们阻挡了我们的好奇心,对自己产生怀疑,他们的话不值一提。
再聊回多级缓存,这从来都不是高深技术,哪怕是一个日活几百的小系统,只要存在重复读、热点数据或对响应速度有要求,或者作为开发者的你不甘于只做简单架构,那从设计一个多级缓存模块开始吧,它一定可以给你和你的系统带来立竿见影的体验提升。
还有,即便是小项目,你能保证它一辈子当个"小项目"吗?架构设计不是一锤子买卖,而是在演进中预留弹性,提前埋下合理的扩展点,这远比在流量突增时连滚带爬的救火要从容得多。有偏见的开发者,永远写不出好用的系统。
好了,至此,这个多级缓存的话题差不多就聊完了,下次再见。