文章目录
- 一、深度学习图像任务的完整分类
-
- [1. 感知层(Low-level Vision)](#1. 感知层(Low-level Vision))
- [2. 理解层(Middle-level Vision)](#2. 理解层(Middle-level Vision))
- [3. 高级理解层(High-level Vision)](#3. 高级理解层(High-level Vision))
- [4. 决策层(Decision-making)](#4. 决策层(Decision-making))
- 二、图像任务的关系与层次结构
-
- [1. 任务层次关系](#1. 任务层次关系)
- [2. 技术依赖关系](#2. 技术依赖关系)
- [3. 模型架构演进关系](#3. 模型架构演进关系)
- 三、图像任务的输入输出机制与示例
-
- [1. 图像分类](#1. 图像分类)
- [2. 目标检测](#2. 目标检测)
- [3. 语义分割](#3. 语义分割)
- [4. 实例分割](#4. 实例分割)
- [5. 图像生成](#5. 图像生成)
一、深度学习图像任务的完整分类
根据计算机视觉任务的层次结构和功能特性,我们可以将深度学习图像任务分为四大层次,每个层次包含多个具体任务:
1. 感知层(Low-level Vision)
感知层任务关注图像的基础处理和特征提取,解决图像质量改善和基础表示问题:
- 图像重建:修复破损或缺失部分的图像(如医学图像修复)
- 图像去噪:去除图像中的噪声,提高图像质量
- 图像超分辨率:从低分辨率图像生成高分辨率图像
- 图像配准:将不同来源或时间的图像对齐到同一坐标系
- 图像压缩:以较少的比特表示原像素矩阵,减少存储和传输开销
- 图像隐写:在图像中隐藏秘密信息,如LSB技术
2. 理解层(Middle-level Vision)
理解层任务关注图像内容的识别和定位,建立对图像的初步认知:
- 图像分类:判断图像的整体类别(如识别手写数字0-9)
- 目标检测:在图像中定位并识别多个物体
- 语义分割:为图像中每个像素分配语义类别标签
- 实例分割:区分图像中同一类别的不同实例
- 目标跟踪:在视频序列中持续追踪特定目标
- 图像生成:基于模型生成新的图像内容(如GAN、VAE)
- 图像翻译:将图像从一个域转换到另一个域(如CycleGAN)
- 图像风格迁移:将一张图像的风格应用到另一张图像上
3. 高级理解层(High-level Vision)
高级理解层任务关注图像内容的深度理解和推理:
- 视觉关系检测:识别图像中物体之间的关系或相互作用
- 视觉问答(VQA):根据图像和问题生成文本答案
- 图像描述生成:为图像生成自然语言描述
- 3D视觉任务 :
- 3D目标检测
- 3D场景重建(如NeRF)
- 3D位姿估计(如手部姿态估计)
- 3D视觉定位(如点云中的物体定位)
- 医学影像特有任务 :
- 病灶分割(如U-Net用于肿瘤分割)
- 医学图像重建(如CT去伪影)
- 医学图像配准
4. 决策层(Decision-making)
决策层任务关注基于视觉理解的决策和行动规划:
- 自动驾驶感知:环境理解与路径规划
- 机器人视觉:物体抓取与场景交互
- 视频分析 :
- 视频分类
- 视频目标检测
- 行为识别
- 视频超分辨率
- 多模态任务融合:结合视觉、文本、语音等多模态信息进行推理
二、图像任务的关系与层次结构
1. 任务层次关系
计算机视觉任务形成了清晰的层次结构,从低级到高级逐步提升认知能力:
图像像素 → 感知层 → 理解层 → 高级理解层 → 决策层
感知层 是视觉处理的基础,通过改进图像质量(如去噪、超分辨率)和提取基础特征,为后续任务提供良好输入。理解层 在此基础上进行物体识别和定位,如分类、检测和分割任务。高级理解层 则利用理解层的结果,进行更复杂的场景理解、关系推理和3D重建。决策层将视觉理解与其他模态信息结合,做出最终决策。
2. 技术依赖关系
许多高级任务直接依赖于基础任务的输出:
- 实例分割 依赖于目标检测,在检测框基础上生成像素级掩码
- 视觉关系检测 需要目标检测的结果作为输入,识别物体间关系
- 3D位姿估计 通常需要目标检测 或实例分割的2D位置信息
- 视觉问答 需要结合目标检测 、语义分割和自然语言处理
- 视频目标检测 是图像目标检测的时序扩展,需处理连续帧序列
3. 模型架构演进关系
深度学习模型架构也呈现从基础到高级的演进关系:
- 全连接网络(如用于MNIST分类)是最简单的网络结构,将图像展平为一维向量处理
- 卷积神经网络(CNN)(如ResNet、VGG)是图像处理的核心架构,通过局部感受野提取空间特征
- Transformer架构(如DETR、Swin Transformer)提供了全局依赖建模能力,用于复杂场景理解
- 扩散模型(如Stable Diffusion)和**神经辐射场(NeRF)**代表了最新的生成和3D重建技术
三、图像任务的输入输出机制与示例
1. 图像分类
任务定义:将图像分为不同的类别,如识别手写数字0-9。
简单示例:全连接网络处理MNIST数据集
python
import torch
import torch.nn as nn
class SimpleClassifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(28*28, 128) # 输入层:784维 → 隐藏层:128维
self.relu = nn.ReLU() # ReLU激活函数
self.fc2 = nn.Linear(128, 10) # 输出层:128维 → 10个类别
def forward(self, x):
x = x.view(-1, 28*28) # 将28x28图像展平为784维向量
x = self.relu(self.fc1(x)) # 隐藏层前向传播
x = self.fc2(x) # 输出层前向传播
return x
示例输入输出
image = torch.randn(1, 1, 28, 28) # MNIST图像形状为(1,28,28)
model = SimpleClassifier()
output = model(image) # 输出形状为(1,10),表示每个数字的概率
print(output.shape) # torch.Size([1, 10])
**流行算法示例**:ResNet(残差网络)
import torchvision.models as models
加载预训练的ResNet-50模型
model = models.resnet50(pretrained=True)
示例输入输出
image = torch.randn(1, 3, 224, 224) # 彩色图像形状为(3,224,224)
output = model(image) # 输出形状为(1,1000),表示ImageNet数据集的1000个类别的概率
print(output.shape) # torch.Size([1, 1000])2. 目标检测
任务定义:在图像中定位并识别多个物体,输出边界框及其类别标签。
简单示例:目标检测的基本结构
python
import torch
import torch.nn as nn
class SimpleYOLO(nn.Module):
def __init__(self, num_classes=10):
super().__init__()
self.backbone = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=2),
nn.ReLU(),
nn.Conv2d(16, 32, kernel_size=3, stride=2),
nn.ReLU()
)
self.detection_head = nn.Conv2d(32, num_classes*5, kernel_size=1) # 5个输出:x,y,w,h,confidence
def forward(self, x):
features = self.backbone(x) # 提取特征
predictions = self.detection_head(features) # 预测边界框和类别
return predictions3. 语义分割
任务定义:为图像中每个像素分配语义类别标签,如将图像中的每个像素分为"人"、"车"或"背景"等类别。
简单示例:UNet的基本结构
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""两次连续的卷积层(卷积+BN+ReLU)"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, in_channels=3, out_channels=2):
"""
参数:
in_channels: 输入通道数 (RGB=3, 灰度=1)
out_channels: 输出通道数 (等于类别数)
"""
super().__init__()
# 编码器 (下采样路径)
self.encoder1 = DoubleConv(in_channels, 64) # 1/1
self.encoder2 = DoubleConv(64, 128) # 1/2
self.encoder3 = DoubleConv(128, 256) # 1/4
self.encoder4 = DoubleConv(256, 512) # 1/8
# 下采样
self.pool = nn.MaxPool2d(2)
# 底部
self.bottleneck = DoubleConv(512, 1024) # 1/16
# 解码器 (上采样路径)
self.upconv4 = nn.ConvTranspose2d(1024, 512, 2, stride=2)
self.decoder4 = DoubleConv(1024, 512) # 1024=上采样512+跳跃连接512
self.upconv3 = nn.ConvTranspose2d(512, 256, 2, stride=2)
self.decoder3 = DoubleConv(512, 256) # 512=上采样256+跳跃连接256
self.upconv2 = nn.ConvTranspose2d(256, 128, 2, stride=2)
self.decoder2 = DoubleConv(256, 128) # 256=上采样128+跳跃连接128
self.upconv1 = nn.ConvTranspose2d(128, 64, 2, stride=2)
self.decoder1 = DoubleConv(128, 64) # 128=上采样64+跳跃连接64
# 输出层
self.output = nn.Conv2d(64, out_channels, 1) # 1x1卷积,将特征映射到类别数
def forward(self, x):
"""前向传播过程"""
# 保存编码器的特征图用于跳跃连接
e1 = self.encoder1(x) # 通道: 3->64
e2 = self.encoder2(self.pool(e1)) # 下采样,通道: 64->128
e3 = self.encoder3(self.pool(e2)) # 下采样,通道: 128->256
e4 = self.encoder4(self.pool(e3)) # 下采样,通道: 256->512
# 瓶颈层
b = self.bottleneck(self.pool(e4)) # 下采样,通道: 512->1024
# 解码器,通过跳跃连接融合特征
d4 = self.upconv4(b) # 上采样,1024->512
d4 = torch.cat([e4, d4], dim=1) # 跳跃连接:拼接e4和上采样结果
d4 = self.decoder4(d4) # 512+512=1024 -> 512
d3 = self.upconv3(d4) # 上采样,512->256
d3 = torch.cat([e3, d3], dim=1) # 跳跃连接
d3 = self.decoder3(d3) # 256+256=512 -> 256
d2 = self.upconv2(d3) # 上采样,256->128
d2 = torch.cat([e2, d2], dim=1) # 跳跃连接
d2 = self.decoder2(d2) # 128+128=256 -> 128
d1 = self.upconv1(d2) # 上采样,128->64
d1 = torch.cat([e1, d1], dim=1) # 跳跃连接
d1 = self.decoder1(d1) # 64+64=128 -> 64
# 输出
output = self.output(d1) # 64 -> 类别数
return output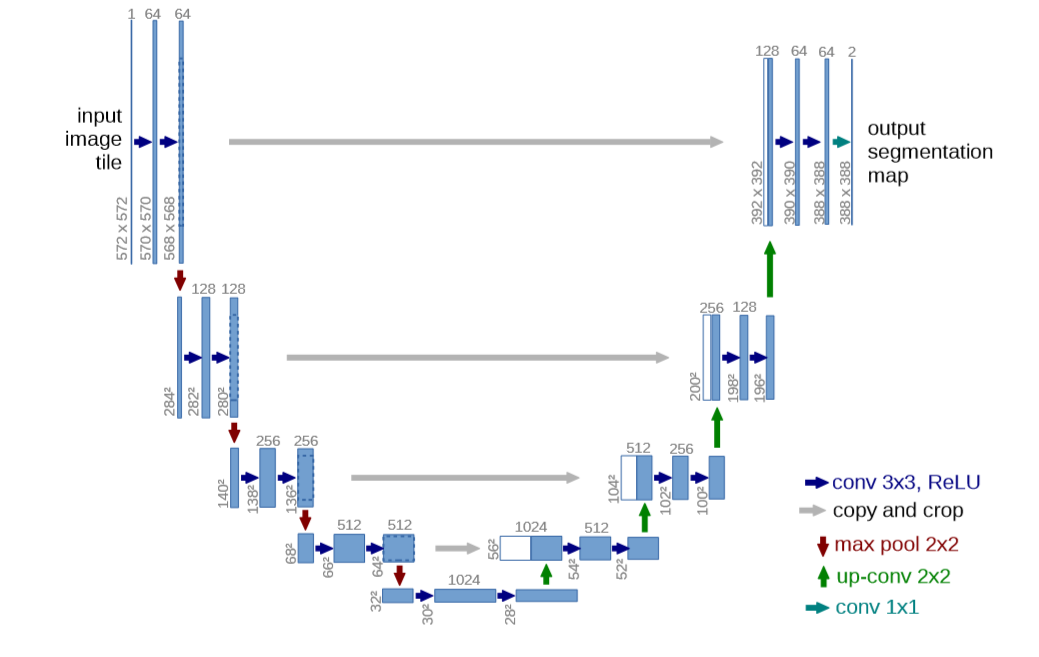
参考文章:
U-Net呈现为一个经典的"U"形编码器-解码器结构。左侧为编码器(收缩路径),它像是一个特征提取器,通过卷积和下采样逐步压缩图像尺寸、增加通道数,以捕获图像的深层语义信息。右侧为解码器(扩展路径),其过程相反,通过上采样和卷积逐步恢复图像的空间细节。连接左右两侧同层级特征的灰色跳跃连接是U-Net设计的精髓,它能将编码器捕捉到的精细纹理和位置信息直接传递给解码器,从而在恢复大尺寸图像时,能同时利用浅层的细节与深层的语义,实现精准的像素级定位。
图中不同颜色的箭头代表了核心操作:
• 蓝紫箭头 (3×3卷积 + ReLU):是特征提取的基本单元。以最左上角输入为例,一张572×572的图像,经过第一层"3×3卷积→ReLU"后,由于卷积操作的特性,尺寸会略微缩小,得到570×570的特征图;再经过一次相同操作,得到568×568的特征图。此过程不改变通道数的本质,而是通过多组卷积核来生成新的特征表达。
• 红色箭头 (2×2最大池化/下采样):在每提取两次特征后,它会将特征图尺寸减半(如从568×568变为284×284),此举在扩大后续卷积感受野的同时,实现了数据压缩和一定程度的平移不变性。
• 绿色箭头 (2×2反卷积/上采样):位于解码器,功能是进行"解码"以恢复分辨率。例如,将196×196的低分辨率特征图,通过2×2的反卷积核进行上采样,尺寸放大一倍至392×392。
• 灰色箭头 (裁剪与复制):即跳跃连接的具体实现。由于编码器每次卷积会导致特征图边界丢失,其输出尺寸(如568×568)通常大于解码器对应层上采样后的尺寸(如392×392)。因此,需要将编码器输出的特征图裁剪中心部分,再复制到解码器,与上采样结果在通道维度上进行拼接(如上例中,392×392×64 + 392×392×64 = 392×392×128),从而融合多尺度信息。
• 青蓝箭头(1×1卷积):位于网络最末端。它不改变特征图的空间尺寸,但负责将高维特征通道(如64通道)映射到目标类别数(如2通道),其输出388×388×2的每个空间位置都对应输入图像一个像素点的类别概率分布,最终实现语义分割。
4. 实例分割
任务定义:不仅识别图像中的物体类别,还需区分同一类别的不同实例。
简单示例:结合目标检测和语义分割的简单实例分割模型
python
import torch
import torch.nn as nn
import numpy as np
import cv2
from scipy import ndimage
from skimage import measure, morphology
import matplotlib.pyplot as plt
class SimpleInstanceSegmentation(nn.Module):
"""
基于距离变换的简单实例分割模型
1. 语义分割:分离前景(细胞)和背景
2. 距离变换:计算每个前景像素到最近背景像素的距离
3. 分水岭分割:分离相互接触的细胞
"""
def __init__(self, in_channels=3, out_channels=1):
super().__init__()
# 简单的编码器-解码器结构
self.encoder = nn.Sequential(
nn.Conv2d(in_channels, 16, 3, padding=1), # 输入: 3通道RGB
nn.ReLU(),
nn.MaxPool2d(2), # 下采样
nn.Conv2d(16, 32, 3, padding=1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(32, 16, 2, stride=2), # 上采样
nn.ReLU(),
nn.ConvTranspose2d(16, 8, 2, stride=2), # 上采样
nn.ReLU(),
nn.Conv2d(8, out_channels, 1) # 1x1卷积,输出分割掩码
)
# 可选:距离变换头
self.distance_head = nn.Conv2d(32, 1, 1) # 预测距离变换图
def forward(self, x):
"""前向传播:语义分割"""
features = self.encoder(x)
semantic_mask = torch.sigmoid(self.decoder(features)) # 二值掩码
# 可选:同时预测距离变换
distance_map = self.distance_head(features)
return semantic_mask, distance_map
def separate_instances(self, semantic_mask, min_size=50):
"""
将语义分割结果分离为各个实例
参数:
semantic_mask: 语义分割掩码 (H, W),值为0或1
min_size: 最小实例大小(过滤小区域)
返回:
instance_mask: 实例掩码 (H, W),每个实例有唯一ID
"""
if isinstance(semantic_mask, torch.Tensor):
semantic_mask = semantic_mask.detach().cpu().numpy()
# 确保是二值图像
binary_mask = (semantic_mask > 0.5).astype(np.uint8)
# 步骤1: 距离变换
# 计算每个前景像素到最近背景像素的欧几里得距离
distance = ndimage.distance_transform_edt(binary_mask)
# 步骤2: 寻找局部最大值(细胞中心)
# 使用最大值滤波找到局部最大值
local_max = self._find_local_maxima(distance, min_distance=10)
# 标记局部最大值为种子点
markers, num_seeds = ndimage.label(local_max)
# 步骤3: 分水岭分割
# 将距离图的负值作为地形高度
elevation_map = -distance
# 应用分水岭算法
segmentation = morphology.watershed(
elevation_map,
markers,
mask=binary_mask
)
# 步骤4: 过滤小区域
filtered_segmentation = np.zeros_like(segmentation)
for region in measure.regionprops(segmentation):
if region.area >= min_size:
filtered_segmentation[segmentation == region.label] = region.label
return filtered_segmentation
def _find_local_maxima(self, distance, min_distance=5):
"""寻找局部最大值点"""
# 使用最大值滤波
size = 2 * min_distance + 1
kernel = np.ones((size, size), dtype=bool)
local_max = ndimage.maximum_filter(distance, footprint=kernel) == distance
# 只在前景区域寻找
local_max[distance == 0] = 0
return local_max代码实现了一个简化的实例分割模型,其编码器-解码器主干网络与图中描述的U-Net核心思想一脉相承。具体来看:
-
编码器(左侧收缩路径):代码中的self.encoder依次执行"蓝紫箭头"所示的3×3卷积+ReLU操作,以及"红色箭头"所示的2×2最大池化/下采样,这与图中左上角描述的流程(572×572 → 卷积 → 568×568 → 池化 → 284×284)完全对应,目的都是逐步提取深层语义特征。
-
解码器(右侧扩展路径):代码中的self.decoder通过"绿色箭头"所示的2×2转置卷积(反卷积) 进行上采样,逐步恢复特征图的空间分辨率,最终通过"青蓝箭头"所示的1×1卷积输出每个像素的语义类别(前景/背景),对应图中最右侧将特征映射到类别空间的过程。
-
关键差异与实例分割实现:在获得二值语义掩码后,通过距离变换找到细胞中心,再使用分水岭算法(以距离图的负值为地形)将从中心扩散的"水域"分离,从而将连成一片的前景分割成具有独立ID的多个实例,完成了从"像素是什么"到"像素属于哪个物体"的实例分割任务。
5. 图像生成
任务定义 :生成符合某些条件的图像,如从噪声中生成真实图像。### (1)GAN网络 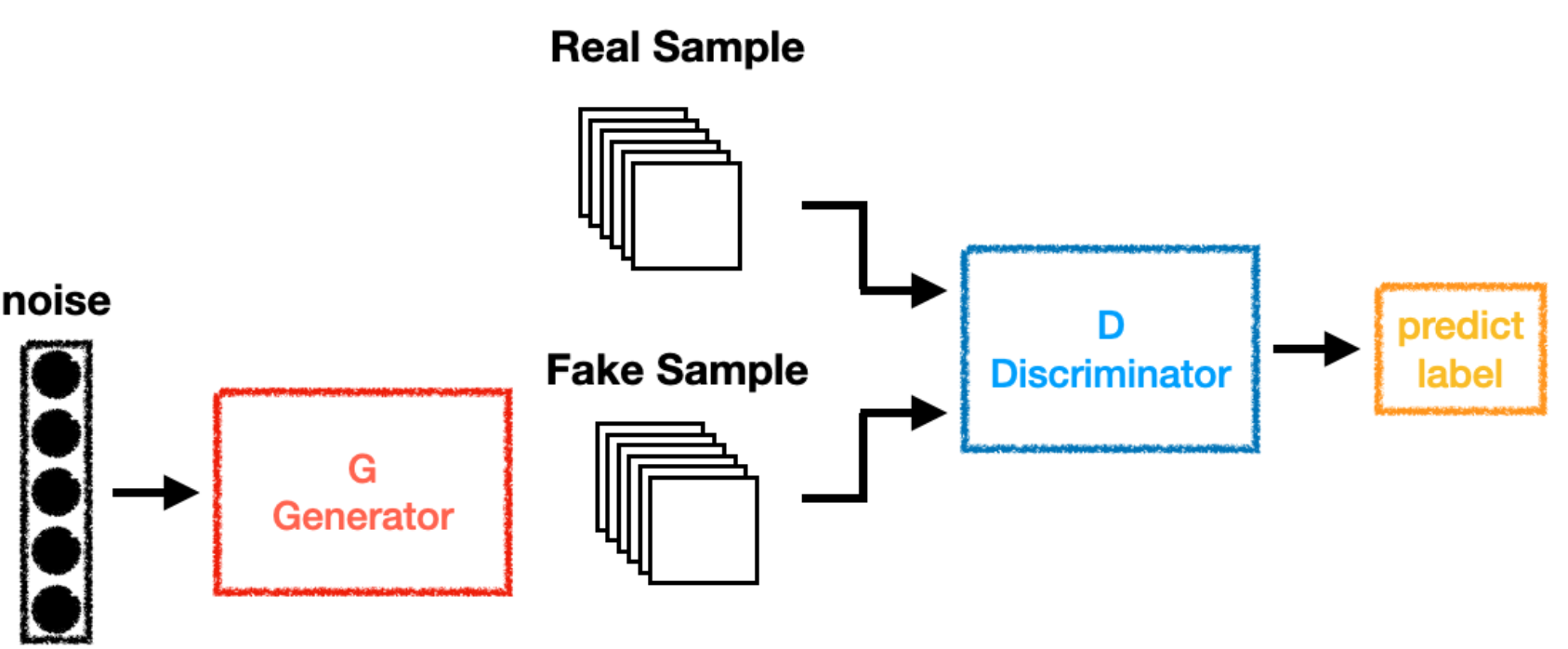
GAN(生成对抗网络)的完整工作流程与核心对抗思想。从最左侧的"noise"(噪声) 开始,这通常是随机生成的一组数字(如100维高斯噪声向量),它作为生成器G(Generator) 的"种子"或创意来源。生成器(红色框G) 的核心任务是一个"造假者":它接收这片混沌的噪声,并通过一个复杂的神经网络(通常是全连接层和转置卷积层)进行学习与变换,最终"无中生有"地输出一批"Fake Sample"(假样本),如图中叠放的生成图像。
与此同时,从数据集来的"Real Sample"(真实样本) 被提供在流程上方。真假两路样本在此汇合,共同输入给"检验员"------判别器D(Discriminator,蓝色框)。判别器的职责是一个"鉴定家":它需要仔细观察和分析输入样本的特征,并通过另一个神经网络(通常是卷积网络)进行判断,最终输出一个"predict label"(预测标签),即一个概率值(比如0.8表示"很可能为真",0.1表示"很可能是假")。
GAN的精髓在于图中箭头所描绘的、贯穿始终的动态对抗博弈:
- 生成器G的目标是:不断学习,使自己生成的"假样本"越来越逼真,直到能"以假乱真",成功骗过判别器D(让D对假样本也输出高的真实概率)。
- 判别器D的目标是:不断进化自己的鉴定能力,越来越精准地区分真假样本。
在训练初期,生成器水平很差,判别器很容易识破。但随着训练进行,判别器给出的反馈(预测标签)会作为关键信号,通过反向传播"指导"生成器改进。这个过程循环往复,如同"造假工艺"与"鉴定技术"在相互比拼中不断升级。最终,理想状态下双方会达到一个平衡点(纳什均衡),此时生成器能产生足以乱真的高质量样本,而判别器则难以判断(真假概率都接近0.5)。因此,整个系统的输入是随机噪声和真实数据,而输出则是一个能够从噪声中生成逼真数据的、训练好的生成器模型。
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# ==================== 1. 生成器 (G Generator) ====================
# 对应图中的红色虚线框"G Generator"
class Generator(nn.Module):
"""
生成器:从噪声生成假样本
输入: 噪声向量 (noise) → 输出: 假样本 (Fake Sample)
对应图中: noise → 红色箭头 → G Generator → 黑色箭头 → Fake Sample
"""
def __init__(self, noise_dim=100, img_channels=1, img_size=28):
super(Generator, self).__init__()
self.noise_dim = noise_dim
# 将噪声向量逐步上采样为图像
self.model = nn.Sequential(
# 第一层: 全连接层,将噪声向量展开
nn.Linear(noise_dim, 128),
nn.ReLU(),
# 第二层: 进一步扩展特征
nn.Linear(128, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
# 第三层: 扩展到与图像尺寸匹配
nn.Linear(256, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
# 输出层: 映射到图像空间
nn.Linear(512, img_channels * img_size * img_size),
nn.Tanh() # 输出值在[-1, 1]之间,对应归一化的图像
)
self.img_channels = img_channels
self.img_size = img_size
def forward(self, noise):
"""
前向传播: 从噪声生成假样本
对应图中流程: noise → G → Fake Sample
"""
# 输入: noise (batch_size, noise_dim)
batch_size = noise.shape[0]
# 通过生成器网络
output = self.model(noise) # 形状: (batch_size, img_channels*img_size*img_size)
# 重塑为图像格式
fake_images = output.view(batch_size, self.img_channels, self.img_size, self.img_size)
return fake_images # 输出: Fake Sample
# ==================== 2. 判别器 (D Discriminator) ====================
# 对应图中的蓝色虚线框"D Discriminator"
class Discriminator(nn.Module):
"""
判别器:判断输入样本是真实还是虚假
输入: 真实样本(Real Sample) 或 假样本(Fake Sample)
输出: 预测标签(predict label) - 样本为真的概率
对应图中: Real Sample/Fake Sample → 黑色箭头 → D Discriminator → 黑色箭头 → predict label
"""
def __init__(self, img_channels=1, img_size=28):
super(Discriminator, self).__init__()
# 将图像展平为向量
self.input_dim = img_channels * img_size * img_size
# 判别器网络结构
self.model = nn.Sequential(
# 第一层: 处理展平的图像
nn.Linear(self.input_dim, 512),
nn.LeakyReLU(0.2), # 使用LeakyReLU防止梯度消失
# 第二层: 提取特征
nn.Linear(512, 256),
nn.LeakyReLU(0.2),
# 第三层: 进一步提取特征
nn.Linear(256, 128),
nn.LeakyReLU(0.2),
# 输出层: 输出一个概率值
nn.Linear(128, 1),
nn.Sigmoid() # 输出0-1之间的概率,对应"predict label"
)
def forward(self, img):
"""
前向传播: 判断图像是真实还是生成
对应图中流程: Real Sample/Fake Sample → D → predict label
"""
# 输入: img (batch_size, img_channels, img_size, img_size)
batch_size = img.shape[0]
# 将图像展平为向量
flattened = img.view(batch_size, -1) # 形状: (batch_size, img_channels*img_size*img_size)
# 通过判别器网络
validity = self.model(flattened) # 形状: (batch_size, 1)
return validity # 输出: predict label (概率值)
# ==================== 3. 完整的GAN模型 ====================
class GAN(nn.Module):
"""
完整的GAN模型,整合生成器和判别器
实现图中所示的完整数据流
"""
def __init__(self, noise_dim=100, img_channels=1, img_size=28):
super(GAN, self).__init__()
self.noise_dim = noise_dim
self.generator = Generator(noise_dim, img_channels, img_size)
self.discriminator = Discriminator(img_channels, img_size)
def generate_fake_samples(self, batch_size, device='cpu'):
"""
生成假样本
对应图中: noise → G → Fake Sample
"""
# 1. 生成随机噪声 (对应图中"noise")
noise = torch.randn(batch_size, self.noise_dim).to(device)
# 2. 通过生成器生成假样本 (对应图中G Generator)
fake_samples = self.generator(noise) # 输出Fake Sample
return fake_samples
def discriminate(self, samples):
"""
判别样本
对应图中: Real Sample/Fake Sample → D → predict label
"""
# 通过判别器得到预测标签
predictions = self.discriminator(samples) # 输出predict label
return predictions
# ==================== 4. 训练过程示例 ====================
def train_gan_step_by_step():
"""
逐步演示GAN的训练过程,对应图中完整的数据流
"""
# 设置参数
batch_size = 64
noise_dim = 100
img_size = 28
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 初始化模型
gan = GAN(noise_dim=noise_dim, img_channels=1, img_size=img_size)
gan.generator.to(device)
gan.discriminator.to(device)
# 定义损失函数和优化器
adversarial_loss = nn.BCELoss() # 二分类交叉熵损失
optimizer_G = optim.Adam(gan.generator.parameters(), lr=0.0002, betas=(0.5, 0.999))
optimizer_D = optim.Adam(gan.discriminator.parameters(), lr=0.0002, betas=(0.5, 0.999))
# 模拟一批真实样本 (对应图中"Real Sample")
real_samples = torch.randn(batch_size, 1, img_size, img_size).to(device)
real_labels = torch.ones(batch_size, 1).to(device) # 真实样本标签为1
print("=" * 60)
print("GAN训练步骤 - 对应图中的数据流")
print("=" * 60)
# 第一步: 生成假样本 (对应图中上半部分流程)
print("\n1. 生成假样本 (对应图中: noise → G → Fake Sample):")
# 生成随机噪声 (对应图中"noise"的五个黑点)
noise = torch.randn(batch_size, noise_dim).to(device)
print(f" 输入噪声形状: {noise.shape} (对应图中的'noise')")
# 通过生成器生成假样本
fake_samples = gan.generator(noise)
print(f" 生成假样本形状: {fake_samples.shape} (对应图中的'Fake Sample')")
# 第二步: 判别真实样本 (对应图中右上部分流程)
print("\n2. 判别真实样本 (对应图中: Real Sample → D → predict label):")
# 判别器处理真实样本
real_validity = gan.discriminator(real_samples)
print(f" 真实样本预测: {real_validity[:5].squeeze().detach().cpu().numpy()} (对应图中的'predict label')")
# 第三步: 判别假样本 (对应图中右下部分流程)
print("\n3. 判别假样本 (对应图中: Fake Sample → D → predict label):")
# 判别器处理假样本
fake_validity = gan.discriminator(fake_samples.detach())
print(f" 假样本预测: {fake_validity[:5].squeeze().detach().cpu().numpy()} (对应图中的'predict label')")
# 第四步: 训练判别器
print("\n4. 训练判别器:")
optimizer_D.zero_grad()
# 计算真实样本的损失
real_loss = adversarial_loss(real_validity, real_labels)
print(f" 真实样本损失: {real_loss.item():.4f}")
# 计算假样本的损失
fake_labels = torch.zeros(batch_size, 1).to(device)
fake_loss = adversarial_loss(fake_validity, fake_labels)
print(f" 假样本损失: {fake_loss.item():.4f}")
# 总判别器损失
d_loss = real_loss + fake_loss
d_loss.backward()
optimizer_D.step()
print(f" 判别器总损失: {d_loss.item():.4f}")
# 第五步: 训练生成器
print("\n5. 训练生成器 (对应完整流程: noise → G → Fake Sample → D → predict label):")
optimizer_G.zero_grad()
# 重新生成假样本
fake_samples = gan.generator(noise)
# 判别器对生成样本的预测
validity = gan.discriminator(fake_samples)
# 生成器希望判别器将假样本判断为真
g_loss = adversarial_loss(validity, real_labels)
g_loss.backward()
optimizer_G.step()
print(f" 生成器损失: {g_loss.item():.4f} (目标: 使判别器输出接近1)")
print(f" 最终流程完成: noise → G → Fake Sample → D → predict label = {validity.mean().item():.4f}")
return gan