在机器资源紧张的场景下,无需多台设备也能搭建ClickHouse(简称CK)多分片多副本集群------本文将详细介绍如何用3台机器实现这一架构,重点讲解环形复制的原理、环境配置、表结构设计及高可用验证,帮助开发者快速落地CK集群部署。
一、ClickHouse环形复制集群架构解析
1. 架构核心逻辑
3台机器搭建的CK环形集群采用"3分片2副本"设计,分片与节点的对应关系如下:
- 分片1:分布在节点1(192.168.184.151)和节点2(192.168.184.152)
- 分片2:分布在节点2和节点3(192.168.184.153)
- 分片3:分布在节点3和节点1
2. 数据冲突解决方案
同一节点需存储两个分片的数据,若共用一个数据库会导致冲突。CK通过default_database配置解决该问题:为每个分片指定独立默认库,例如分片1对应testcluster_shard_1、分片2对应testcluster_shard_2,确保不同分片数据在节点内隔离存储。
二、基础环境准备
在开始集群配置前,需完成ZooKeeper安装、旧CK环境清理及新CK安装,确保基础依赖就绪。
1. ZooKeeper安装
CK集群依赖ZooKeeper实现分布式协调,此处需确保3台节点的ZooKeeper服务正常运行(默认端口2181)。
- 下载zookeeper
bash
# 创建目录并下载安装包
mkdir /data/zookeeper
cd /data/zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.9.4/apache-zookeeper-3.9.4-bin.tar.gz
# 解压
tar zxvf apache-zookeeper-3.9.4-bin.tar.gz
# 进入配置目录
cd apache-zookeeper-3.9.4-bin/conf/
# 复制配置文件
cp zoo_sample.cfg zoo.cfg- 修改配置
bash
vim /data/zookeeper/apache-zookeeper-3.9.4-bin/conf/zoo.cfg添加
bash
server.1=192.168.184.151:2888:3888
server.2=192.168.184.152:2888:3888
server.3=192.168.184.153:2888:3888- 配置唯一标识
bash
mkdir /tmp/zookeeper/
节点 1 执行
echo 1 >/tmp/zookeeper/myid
节点 2、3 分别设为 2、3- 启动服务
bash
/data/zookeeper/apache-zookeeper-3.9.4-bin/bin/zkServer.sh start确保默认端口 2181 正常运行。
2. 清理旧CK环境
若节点曾安装过CK,需先彻底清理残留文件,避免配置冲突:
bash
# 停止CK服务
/etc/init.d/clickhouse-server stop
# 卸载CK服务
yum remove clickhouse-server
# 删除数据目录和配置目录
rm -rf /var/lib/clickhouse/
rm -rf /etc/clickhouse-server/3. 安装ClickHouse
通过YUM命令重新安装CK服务,操作如下:
bash
yum install -y clickhouse-server三、分片配置与集群初始化
这一步是集群搭建的核心,需修改CK配置文件、配置ZooKeeper节点映射,并验证集群状态。
1. 修改CK主配置文件(config.xml)
编辑/etc/clickhouse-server/config.xml,主要完成3项配置:
- 允许外部访问:将
<listen_host>改为0.0.0.0,确保跨节点通信; - 配置ZooKeeper集群:添加3台节点的ZooKeeper地址;
- 配置分片与副本:定义
cluster_maria集群的3个分片及每个分片的2个副本。
配置代码需修改内容如下:
xml
<!-- 允许外部访问 -->
<listen_host>0.0.0.0</listen_host>
<!-- ZooKeeper集群配置 -->
<zookeeper>
<node>
<host>maria-01</host>
<port>2181</port>
</node>
<node>
<host>maria-02</host>
<port>2181</port>
</node>
<node>
<host>maria-03</host>
<port>2181</port>
</node>
</zookeeper>
<!-- 分片与副本配置(3分片2副本) -->
<remote_servers>
<cluster_maria>
<!-- 分片1 -->
<shard>
<weight>1</weight> <!-- 分片权重,默认1 -->
<internal_replication>true</internal_replication> <!-- 仅写入1个副本 -->
<replica>
<host>192.168.184.151</host>
<port>9000</port>
<default_database>testcluster_shard_1</default_database>
</replica>
<replica>
<host>192.168.184.152</host>
<port>9000</port>
<default_database>testcluster_shard_1</default_database>
</replica>
</shard>
<!-- 分片2 -->
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.184.152</host>
<port>9000</port>
<default_database>testcluster_shard_2</default_database>
</replica>
<replica>
<host>192.168.184.153</host>
<port>9000</port>
<default_database>testcluster_shard_2</default_database>
</replica>
</shard>
<!-- 分片3 -->
<shard>
<weight>1</weight>
<internal_replication>true</internal_replication>
<replica>
<host>192.168.184.153</host>
<port>9000</port>
<default_database>testcluster_shard_3</default_database>
</replica>
<replica>
<host>192.168.184.151</host>
<port>9000</port>
<default_database>testcluster_shard_3</default_database>
</replica>
</shard>
</cluster_maria>
</remote_servers>2. 配置节点Host映射
编辑/etc/hosts文件,添加3台节点的IP与主机名映射,避免IP直接引用导致的配置维护困难:
bash
vim /etc/hosts
# 添加以下内容
192.168.184.151 maria-01
192.168.184.152 maria-02
192.168.184.153 maria-033. 启动CK服务并验证集群
- 重启CK服务,使配置生效:
bash
/etc/init.d/clickhouse-server restart
- 登录任意节点的CK客户端(启用多行模式
-m):
bash
clickhouse-client -m- 查询集群信息,验证配置是否成功:
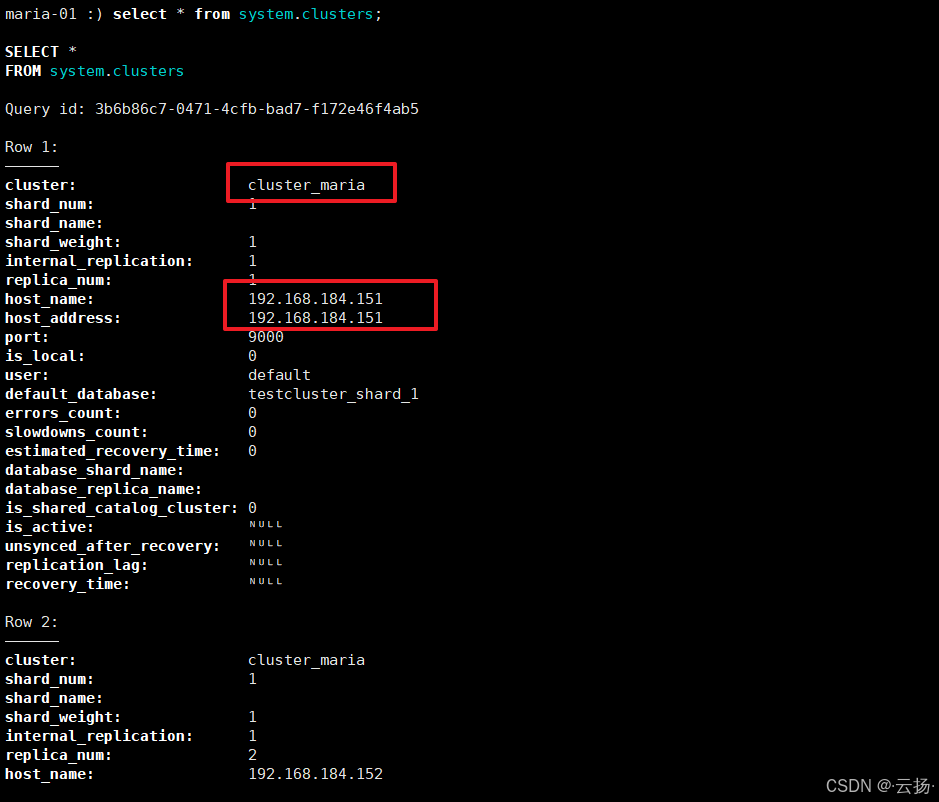
sql
# 方式1:表格形式查看
select * from system.clusters;
# 方式2:垂直形式查看(更清晰)
select * from system.clusters FORMAT Vertical;若查询结果包含cluster_maria集群及3个分片的信息,说明集群初始化成功。
四、创建本地表与分布式总表
CK集群需通过"本地表+分布式表"实现数据分片存储与统一查询:本地表存储节点本地的分片数据,分布式表作为"入口",负责将请求路由到各分片。
1. 分节点创建数据库
根据default_database配置,为每个节点创建对应的分片数据库(需在3台节点分别执行):
- 节点1(maria-01):
sql
CREATE DATABASE testcluster_shard_1;
CREATE DATABASE testcluster_shard_3;- 节点2(maria-02):
sql
CREATE DATABASE testcluster_shard_1;
CREATE DATABASE testcluster_shard_2;- 节点3(maria-03):
sql
CREATE DATABASE testcluster_shard_2;
CREATE DATABASE testcluster_shard_3;2. 创建本地表(ReplicatedMergeTree引擎)
本地表需使用ReplicatedMergeTree引擎,该引擎支持数据副本同步,需指定ZooKeeper路径(zk_path)和副本名称(replica_name)。
引擎参数说明
sql
ENGINE = ReplicatedMergeTree(zk_path, replica_name)
# zk_path格式:/clickhouse/集群名/分片编号/表名
# 例如:/clickhouse/cluster_maria/shard_01/cluster_table_local各节点本地表创建语句
- 节点1:
sql
-- 分片1的本地表(replica_01)
CREATE TABLE testcluster_shard_1.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_01/cluster_table_local', 'replica_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));
-- 分片3的本地表(replica_02)
CREATE TABLE testcluster_shard_3.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_03/cluster_table_local', 'replica_02')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));- 节点2:
sql
-- 分片2的本地表(replica_01)
CREATE TABLE testcluster_shard_2.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_02/cluster_table_local', 'replica_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));
-- 分片1的本地表(replica_02)
CREATE TABLE testcluster_shard_1.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_01/cluster_table_local', 'replica_02')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));- 节点3:
sql
-- 分片3的本地表(replica_01)
CREATE TABLE testcluster_shard_3.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_03/cluster_table_local', 'replica_01')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));
-- 分片2的本地表(replica_02)
CREATE TABLE testcluster_shard_2.cluster_table_local
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = ReplicatedMergeTree('/clickhouse/tables/shard_02/cluster_table_local', 'replica_02')
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID));3. 创建分布式总表
分布式表需在所有节点创建,作为统一的数据读写入口,使用Distributed引擎,指定集群名、分片映射规则。
sql
-- 1. 创建统一数据库(所有节点执行)
create database cluster_all;
-- 2. 创建分布式总表(所有节点执行)
CREATE TABLE cluster_all.cluster_table_all
(
EventDate DateTime,
CounterID UInt32,
UserID UInt32
) ENGINE = Distributed(
cluster_maria, -- 集群名(与config.xml中一致)
'', -- 数据库名(空表示自动匹配各分片的默认库)
cluster_table_local, -- 映射的本地表名
rand() -- 分片规则(rand()表示随机分片)
);五、数据分布与高可用测试
配置完成后,需验证数据是否能正常分片存储,以及集群在节点故障时是否保持可用。
1. 数据分布测试
步骤1:写入测试数据
在任意节点的CK客户端,向分布式总表写入数据:
sql
insert into cluster_all.cluster_table_all values
('2030-01-01 12:00:00',1,1),
('2030-02-01 12:00:00',2,2),
('2030-03-01 12:00:00',3,3),
('2030-04-01 12:00:00',4,4);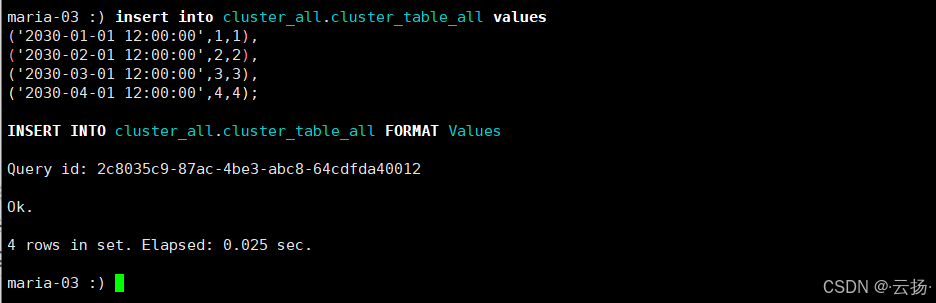
步骤2:验证数据查询
- 查询总表:通过分布式表可查询所有分片的数据,验证数据完整性:
sql
select * from cluster_all.cluster_table_all;
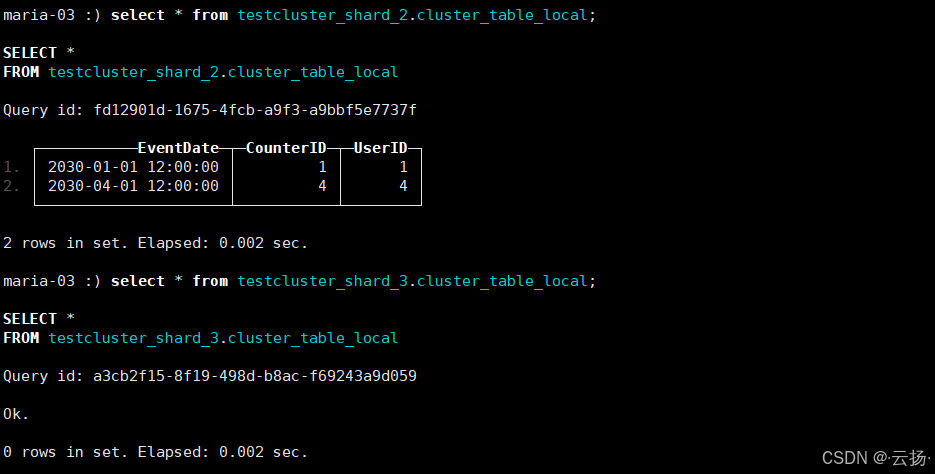
- 查询本地表 :分别在3个节点查询对应分片的本地表,验证数据是否按规则分片存储:
-
节点1:查询
testcluster_shard_1.cluster_table_local和testcluster_shard_3.cluster_table_local
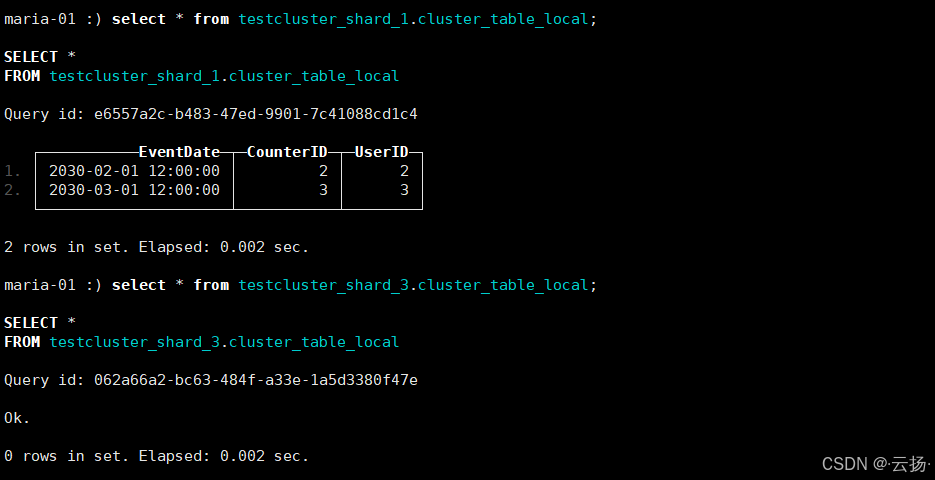
-
节点2:查询
testcluster_shard_1.cluster_table_local和testcluster_shard_2.cluster_table_local
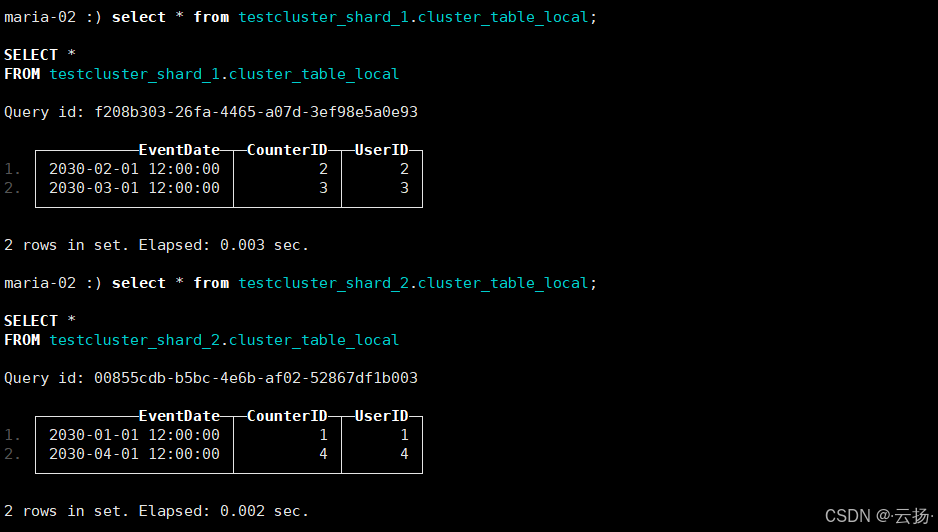
-
节点3:查询
testcluster_shard_2.cluster_table_local和testcluster_shard_3.cluster_table_local
-
2. 高可用测试
步骤1:停止一个节点
停掉节点1(192.168.184.151)的CK服务,模拟节点故障:
bash
/etc/init.d/clickhouse-server stop
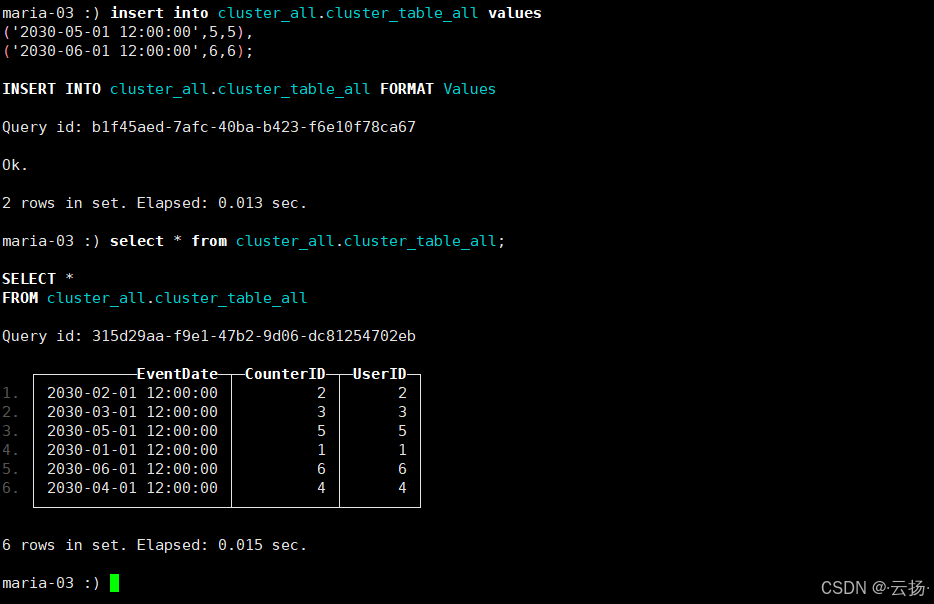
步骤2:测试写入与查询
在节点2或节点3的CK客户端,继续向分布式总表写入数据并查询:
sql
-- 写入新数据
insert into cluster_all.cluster_table_all values
('2030-05-01 12:00:00',5,5),
('2030-06-01 12:00:00',6,6);
-- 查询所有数据(应包含旧数据和新数据)
select * from cluster_all.cluster_table_all;若能正常写入和查询,说明集群具备高可用能力------故障节点的分片数据可通过副本节点访问,不影响整体服务。
总结
本文通过3台机器实现了ClickHouse环形复制集群,核心优势在于:
- 资源高效:无需大量机器,3台即可实现"3分片2副本",平衡性能与冗余;
- 高可用:节点故障时,副本节点接管服务,确保数据不丢失、服务不中断;
- 易维护:通过
default_database隔离分片数据,通过分布式表简化读写操作。
若需进一步优化,可调整分片权重(weight)分配负载,或修改分片规则(如按UserID哈希)实现数据定向存储,满足不同业务场景需求。