欢迎来到我的博客,代码的世界里,每一行都是一个故事

🎏:你只管努力,剩下的交给时间
🏠 :小破站
多模数据库技术解析:以KingbaseES MongoDB兼容版为例
前言
文档数据库凭借对半结构化数据的灵活处理能力,已成为现代应用开发的重要选择。与传统关系型数据库相比,文档数据库在处理JSON/BSON格式数据时具有天然优势,无需预定义严格的表结构,可以灵活应对业务变化。
随着信创需求的增长,国产数据库厂商也在这一领域持续发力。本文以电科金仓的KingbaseES MongoDB兼容版为例,从技术角度分析多模数据库的实现思路、兼容性表现和实际应用场景。
什么是多模数据库
在深入分析之前,先明确一下"多模数据库"的概念。传统上,不同的数据模型需要不同的数据库系统来支撑:
| 数据模型 | 典型数据库 | 适用场景 |
|---|---|---|
| 关系模型 | MySQL、PostgreSQL、Oracle | 结构化数据、事务处理 |
| 文档模型 | MongoDB、CouchDB | 半结构化数据、内容管理 |
| 键值模型 | Redis、Memcached | 缓存、会话管理 |
| 图模型 | Neo4j、JanusGraph | 社交网络、知识图谱 |
| 向量模型 | Milvus、Pinecone | AI应用、相似性搜索 |
多模数据库的思路是在一个数据库内核中支持多种数据模型,减少技术栈复杂度。这种架构有利有弊:
优势:
- 统一运维,降低管理成本
- 跨模型查询更方便
- 事务一致性更容易保证
劣势:
- 单一模型的极致性能可能不如专用数据库
- 功能覆盖面广但深度可能有限
性能测试数据分析
根据官方公布的YCSB基准测试结果,KingbaseES MongoDB兼容版与MongoDB 7.0在六种典型负载场景下进行了对比测试。
YCSB(Yahoo! Cloud Serving Benchmark)是业界广泛使用的NoSQL数据库基准测试工具,包含以下标准负载:
- Workload A:50%读 + 50%更新(更新密集型)
- Workload B:95%读 + 5%更新(读密集型)
- Workload C:100%读(只读)
- Workload D:95%读 + 5%插入(读最新数据)
- Workload E:95%扫描 + 5%插入(短范围扫描)
- Workload F:50%读 + 50%读-修改-写(读改写)
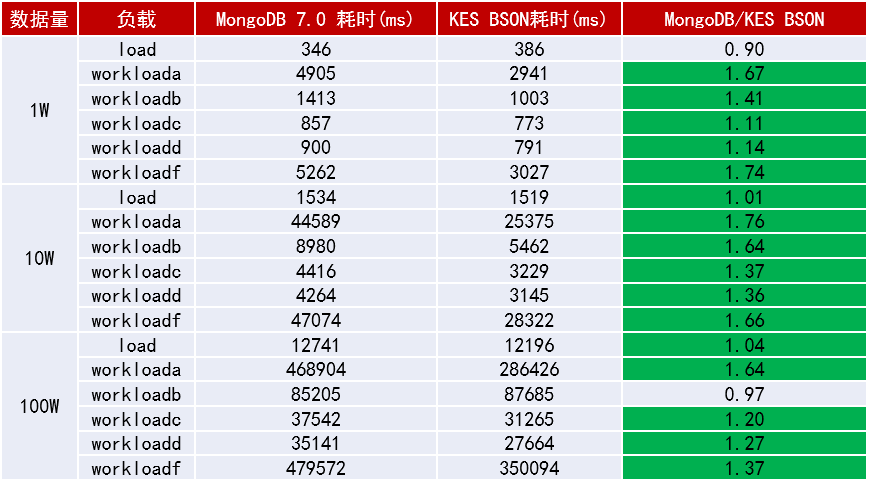
图1-KingbaseES MongoDB兼容版 vs MongoDB 7.0 性能对比
从测试数据来看,在混合读写(Workload A、F)和插入后读取(Workload D)场景中表现较好,其他场景基本持平。需要注意的是:
- 基准测试环境与生产环境存在差异
- 数据量、并发数、硬件配置都会影响结果
- 建议在实际业务场景下进行压测验证
另一组测试对比了BSON与Oracle OSON格式在嵌套文档更新场景下的性能:
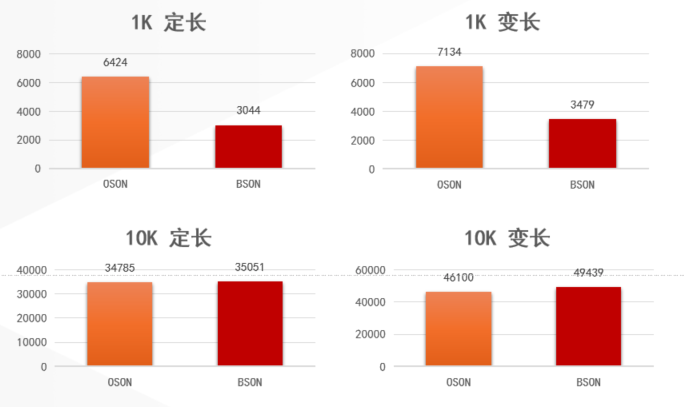
图2-KingbaseES (BSON) vs Oracle 21.3 (OSON) 性能对比
BSON vs OSON 格式对比:
| 特性 | BSON (Binary JSON) | OSON (Oracle JSON) |
|---|---|---|
| 来源 | MongoDB原生格式 | Oracle 21c引入 |
| 存储方式 | 二进制编码 | 二进制编码 |
| 类型支持 | Date、ObjectId、BinData等 | SQL类型映射 |
| 解析效率 | 无需文本解析 | 无需文本解析 |
在小数据量JSON场景下BSON处理效率较高,但随着数据量增大差距会缩小。这与两种格式的设计取舍有关,BSON针对文档操作做了专门优化,而OSON更侧重与SQL生态的融合。
技术架构分析
KingbaseES采用的是"原生扩展"路线,将文档模型能力集成到统一内核中,而非独立部署一套文档数据库。这种架构设计有几个技术特点:
统一存储引擎
底层使用统一的存储引擎管理不同类型的数据,文档数据以BSON格式存储,但共享关系型数据库的缓冲池、日志系统和检查点机制。
查询优化
统一的查询优化器可以为不同数据模型生成执行计划。对于文档查询,优化器会:
- 解析MongoDB查询语法
- 转换为内部执行计划
- 根据索引和统计信息选择最优路径
- 执行并返回结果
索引支持
索引框架支持多种类型,可以根据查询模式选择:
| 索引类型 | 适用场景 | 文档数据库应用 |
|---|---|---|
| B-Tree | 等值查询、范围查询 | 字段精确匹配 |
| Hash | 等值查询 | 主键查找 |
| GIN | 数组、全文检索 | 数组字段、文本搜索 |
| GiST | 空间数据 | 地理位置查询 |
MongoDB协议兼容性详解
官方宣称对MongoDB常用命令和操作符兼容度接近100%,支持MongoDB 5.0+通信协议。下面通过具体示例来验证兼容性。
数据库和集合操作
javascript
// 查看所有数据库
show dbs
// 切换/创建数据库
use mydb
// 查看当前数据库的集合
show collections
// 创建集合(显式创建)
db.createCollection("orders", {
validator: {
$jsonSchema: {
bsonType: "object",
required: ["orderId", "customer", "totalAmount"],
properties: {
orderId: { bsonType: "string" },
totalAmount: { bsonType: "number", minimum: 0 }
}
}
}
})
// 删除集合
db.orders.drop()文档CRUD操作
插入操作:
javascript
// 单文档插入
db.orders.insertOne({
orderId: "ORD-2024-001",
customer: {
name: "张三",
phone: "138****1234",
address: {
province: "北京市",
city: "北京市",
district: "海淀区",
street: "中关村大街1号"
}
},
items: [
{ productId: "P001", name: "电子证照打印机", qty: 2, price: 3500 },
{ productId: "P002", name: "高拍仪", qty: 1, price: 1200 }
],
totalAmount: 8200,
status: "pending",
tags: ["政务", "信创", "紧急"],
createTime: new Date(),
updateTime: new Date()
})
// 批量插入
db.orders.insertMany([
{
orderId: "ORD-2024-002",
customer: { name: "李四", phone: "139****5678" },
totalAmount: 5600,
status: "completed",
createTime: new Date("2024-01-15")
},
{
orderId: "ORD-2024-003",
customer: { name: "王五", phone: "137****9012" },
totalAmount: 12800,
status: "pending",
createTime: new Date("2024-01-16")
},
{
orderId: "ORD-2024-004",
customer: { name: "赵六", phone: "136****3456" },
totalAmount: 3200,
status: "cancelled",
createTime: new Date("2024-01-17")
}
])查询操作:
javascript
// 基本查询
db.orders.find({ status: "pending" })
// 嵌套文档查询(点号表示法)
db.orders.find({ "customer.name": "张三" })
// 深层嵌套查询
db.orders.find({ "customer.address.district": "海淀区" })
// 比较操作符
db.orders.find({
totalAmount: { $gte: 5000, $lte: 10000 }
})
// 逻辑操作符
db.orders.find({
$or: [
{ status: "pending" },
{ totalAmount: { $gt: 10000 } }
]
})
// 数组查询
db.orders.find({ tags: "信创" }) // 数组包含某元素
db.orders.find({ tags: { $all: ["政务", "信创"] } }) // 数组包含所有指定元素
db.orders.find({ "items.0.productId": "P001" }) // 数组特定位置
// 正则表达式
db.orders.find({ "customer.name": /^张/ })
// 投影(只返回指定字段)
db.orders.find(
{ status: "pending" },
{ orderId: 1, "customer.name": 1, totalAmount: 1, _id: 0 }
)
// 排序和分页
db.orders.find({ status: "pending" })
.sort({ createTime: -1 })
.skip(0)
.limit(10)
// 统计数量
db.orders.countDocuments({ status: "pending" })更新操作:
javascript
// 更新单个文档
db.orders.updateOne(
{ orderId: "ORD-2024-001" },
{
$set: {
status: "processing",
"customer.address.street": "中关村大街100号"
},
$currentDate: { updateTime: true }
}
)
// 更新多个文档
db.orders.updateMany(
{ status: "pending" },
{ $set: { status: "processing" } }
)
// 数组操作
db.orders.updateOne(
{ orderId: "ORD-2024-001" },
{
$push: { tags: "已审核" }, // 添加元素
$inc: { "items.0.qty": 1 } // 数值增加
}
)
// 数组批量操作
db.orders.updateOne(
{ orderId: "ORD-2024-001" },
{
$addToSet: { tags: { $each: ["优先", "VIP"] } } // 添加多个不重复元素
}
)
// upsert(不存在则插入)
db.orders.updateOne(
{ orderId: "ORD-2024-999" },
{
$set: { customer: { name: "新客户" }, totalAmount: 1000 },
$setOnInsert: { createTime: new Date() }
},
{ upsert: true }
)
// 替换整个文档
db.orders.replaceOne(
{ orderId: "ORD-2024-004" },
{
orderId: "ORD-2024-004",
customer: { name: "赵六(已更新)" },
totalAmount: 4500,
status: "completed"
}
)删除操作:
javascript
// 删除单个文档
db.orders.deleteOne({ orderId: "ORD-2024-004" })
// 删除多个文档
db.orders.deleteMany({ status: "cancelled" })
// 删除所有文档(保留集合)
db.orders.deleteMany({})聚合管道详解
聚合管道是MongoDB最强大的数据处理功能之一,支持多阶段数据转换和分析:
javascript
// 完整的聚合管道示例:订单统计分析
db.orders.aggregate([
// 阶段1:筛选时间范围
{
$match: {
createTime: {
$gte: ISODate("2024-01-01"),
$lt: ISODate("2025-01-01")
},
status: { $ne: "cancelled" }
}
},
// 阶段2:添加计算字段
{
$addFields: {
month: { $month: "$createTime" },
itemCount: { $size: "$items" },
hasDiscount: { $lt: ["$totalAmount", 5000] }
}
},
// 阶段3:按月份和状态分组统计
{
$group: {
_id: { month: "$month", status: "$status" },
orderCount: { $sum: 1 },
totalRevenue: { $sum: "$totalAmount" },
avgOrderValue: { $avg: "$totalAmount" },
maxOrder: { $max: "$totalAmount" },
minOrder: { $min: "$totalAmount" },
customers: { $addToSet: "$customer.name" }
}
},
// 阶段4:格式化输出
{
$project: {
_id: 0,
month: "$_id.month",
status: "$_id.status",
orderCount: 1,
totalRevenue: 1,
avgOrderValue: { $round: ["$avgOrderValue", 2] },
maxOrder: 1,
minOrder: 1,
uniqueCustomers: { $size: "$customers" }
}
},
// 阶段5:排序
{ $sort: { month: 1, totalRevenue: -1 } },
// 阶段6:限制结果数量
{ $limit: 20 }
])常用聚合操作符:
javascript
// $lookup - 关联查询(类似SQL JOIN)
db.orders.aggregate([
{
$lookup: {
from: "customers", // 关联的集合
localField: "customerId", // 本集合的字段
foreignField: "_id", // 关联集合的字段
as: "customerInfo" // 输出字段名
}
},
{ $unwind: "$customerInfo" } // 展开数组
])
// $unwind - 展开数组
db.orders.aggregate([
{ $unwind: "$items" },
{
$group: {
_id: "$items.productId",
totalQty: { $sum: "$items.qty" },
totalRevenue: { $sum: { $multiply: ["$items.qty", "$items.price"] } }
}
}
])
// $bucket - 分桶统计
db.orders.aggregate([
{
$bucket: {
groupBy: "$totalAmount",
boundaries: [0, 1000, 5000, 10000, 50000],
default: "50000+",
output: {
count: { $sum: 1 },
orders: { $push: "$orderId" }
}
}
}
])
// $facet - 多维度并行聚合
db.orders.aggregate([
{
$facet: {
"byStatus": [
{ $group: { _id: "$status", count: { $sum: 1 } } }
],
"byMonth": [
{ $group: { _id: { $month: "$createTime" }, count: { $sum: 1 } } }
],
"topCustomers": [
{ $group: { _id: "$customer.name", total: { $sum: "$totalAmount" } } },
{ $sort: { total: -1 } },
{ $limit: 5 }
]
}
}
])GridFS大文件存储
GridFS是MongoDB处理大文件的标准方案,将超过16MB的文件分块存储。这在电子证照、影像资料等场景中很常用:
javascript
// GridFS存储结构说明
// 1. fs.files集合 - 存储文件元数据
{
"_id": ObjectId("507f1f77bcf86cd799439011"),
"length": 52428800, // 文件总大小(字节)
"chunkSize": 261120, // 每个块的大小(默认255KB)
"uploadDate": ISODate("2024-06-15T08:30:00Z"),
"filename": "business_license_001.pdf",
"contentType": "application/pdf",
"metadata": { // 自定义元数据
"licenseNo": "91110108MA01XXXXX",
"companyName": "某某科技有限公司",
"uploadUser": "admin",
"department": "工商局",
"expiryDate": ISODate("2029-06-15")
}
}
// 2. fs.chunks集合 - 存储文件分块数据
{
"_id": ObjectId("507f1f77bcf86cd799439012"),
"files_id": ObjectId("507f1f77bcf86cd799439011"), // 关联files集合
"n": 0, // 块序号(从0开始)
"data": BinData(0, "...") // 二进制数据
}
// 创建必要的索引
db.fs.files.createIndex({ filename: 1, uploadDate: 1 })
db.fs.chunks.createIndex({ files_id: 1, n: 1 }, { unique: true })
// 查询文件元数据
db.fs.files.find({
"metadata.department": "工商局",
uploadDate: { $gte: ISODate("2024-01-01") }
})
// 统计各部门文件数量和大小
db.fs.files.aggregate([
{
$group: {
_id: "$metadata.department",
fileCount: { $sum: 1 },
totalSize: { $sum: "$length" }
}
},
{
$project: {
department: "$_id",
fileCount: 1,
totalSizeMB: { $round: [{ $divide: ["$totalSize", 1048576] }, 2] }
}
}
])索引策略与优化
合理的索引设计对查询性能至关重要:
javascript
// 1. 单字段索引
db.orders.createIndex({ orderId: 1 }) // 升序
db.orders.createIndex({ createTime: -1 }) // 降序
// 2. 复合索引(注意字段顺序)
// 遵循ESR原则:Equality -> Sort -> Range
db.orders.createIndex({ status: 1, createTime: -1, totalAmount: 1 })
// 3. 嵌套字段索引
db.orders.createIndex({ "customer.name": 1 })
db.orders.createIndex({ "customer.address.city": 1 })
// 4. 数组字段索引(多键索引)
db.orders.createIndex({ tags: 1 })
db.orders.createIndex({ "items.productId": 1 })
// 5. 文本索引(全文检索)
db.products.createIndex({
name: "text",
description: "text"
}, {
weights: { name: 10, description: 5 }, // 权重设置
default_language: "none" // 禁用词干提取(中文场景)
})
// 文本搜索查询
db.products.find({
$text: { $search: "打印机 证照" }
}, {
score: { $meta: "textScore" }
}).sort({ score: { $meta: "textScore" } })
// 6. 唯一索引
db.orders.createIndex({ orderId: 1 }, { unique: true })
// 7. 稀疏索引(只索引存在该字段的文档)
db.orders.createIndex({ discountCode: 1 }, { sparse: true })
// 8. TTL索引(自动过期删除)
db.logs.createIndex({ createTime: 1 }, { expireAfterSeconds: 2592000 }) // 30天后过期
// 9. 部分索引(只索引符合条件的文档)
db.orders.createIndex(
{ totalAmount: 1 },
{ partialFilterExpression: { status: "completed" } }
)
// 查看集合的所有索引
db.orders.getIndexes()
// 查看索引使用情况
db.orders.find({ status: "pending" }).explain("executionStats")
// 删除索引
db.orders.dropIndex("status_1_createTime_-1")索引优化建议:
| 场景 | 推荐索引类型 | 说明 |
|---|---|---|
| 主键查询 | 单字段唯一索引 | _id默认有索引 |
| 多条件查询 | 复合索引 | 注意字段顺序 |
| 范围+排序 | 复合索引 | 排序字段放最后 |
| 数组元素查询 | 多键索引 | 自动创建 |
| 全文搜索 | 文本索引 | 每个集合只能有一个 |
| 日志类数据 | TTL索引 | 自动清理过期数据 |
高可用架构
KingbaseES的读写分离集群(RWC)提供以下能力:
| 指标 | 参数 | 说明 |
|---|---|---|
| 故障切换时间(RTO) | < 30秒 | 主节点故障后自动切换 |
| 数据丢失(RPO) | 0 | 同步复制保证数据不丢失 |
| 部署模式 | 同城双活、两地三中心 | 支持多种容灾架构 |
应用连接示例
使用标准MongoDB驱动即可连接,修改连接地址即可完成迁移:
Node.js连接示例:
javascript
const { MongoClient } = require('mongodb');
// 连接配置
const uri = "mongodb://user:password@kingbase-host:27017/mydb";
const options = {
maxPoolSize: 50, // 连接池大小
wtimeoutMS: 2500, // 写超时
retryWrites: true, // 自动重试写操作
retryReads: true // 自动重试读操作
};
const client = new MongoClient(uri, options);
async function main() {
try {
await client.connect();
console.log("Connected successfully");
const db = client.db("certificate_db");
const collection = db.collection("certificates");
// 插入文档
const insertResult = await collection.insertOne({
certNo: "CERT-2024-001",
certType: "营业执照",
holder: "某某公司",
issueDate: new Date(),
status: "valid"
});
console.log("Inserted:", insertResult.insertedId);
// 查询文档
const doc = await collection.findOne({ certNo: "CERT-2024-001" });
console.log("Found:", doc);
// 聚合查询
const stats = await collection.aggregate([
{ $match: { status: "valid" } },
{ $group: { _id: "$certType", count: { $sum: 1 } } }
]).toArray();
console.log("Stats:", stats);
} finally {
await client.close();
}
}
main().catch(console.error);Python PyMongo连接示例:
python
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
from datetime import datetime
# 连接配置
uri = "mongodb://user:password@kingbase-host:27017/"
client = MongoClient(
uri,
maxPoolSize=50,
wtimeoutMS=2500,
retryWrites=True,
retryReads=True
)
# 测试连接
try:
client.admin.command('ping')
print("Connected successfully")
except ConnectionFailure:
print("Connection failed")
db = client["certificate_db"]
collection = db["certificates"]
# 插入文档
doc = {
"certNo": "CERT-2024-002",
"certType": "营业执照",
"holder": "某某公司",
"issueDate": datetime.now(),
"status": "valid"
}
result = collection.insert_one(doc)
print(f"Inserted: {result.inserted_id}")
# 查询文档
found = collection.find_one({"certNo": "CERT-2024-002"})
print(f"Found: {found}")
# 聚合查询
pipeline = [
{"$match": {"status": "valid"}},
{"$group": {"_id": "$certType", "count": {"$sum": 1}}}
]
stats = list(collection.aggregate(pipeline))
print(f"Stats: {stats}")
# 关闭连接
client.close()Java连接示例:
java
import com.mongodb.client.*;
import com.mongodb.ConnectionString;
import com.mongodb.MongoClientSettings;
import org.bson.Document;
import java.util.Arrays;
import java.util.concurrent.TimeUnit;
public class KingbaseMongoExample {
public static void main(String[] args) {
// 连接配置
ConnectionString connString = new ConnectionString(
"mongodb://user:password@kingbase-host:27017/mydb"
);
MongoClientSettings settings = MongoClientSettings.builder()
.applyConnectionString(connString)
.applyToConnectionPoolSettings(builder ->
builder.maxSize(50)
.maxWaitTime(2500, TimeUnit.MILLISECONDS))
.retryWrites(true)
.retryReads(true)
.build();
try (MongoClient client = MongoClients.create(settings)) {
MongoDatabase db = client.getDatabase("certificate_db");
MongoCollection<Document> collection = db.getCollection("certificates");
// 插入文档
Document doc = new Document()
.append("certNo", "CERT-2024-003")
.append("certType", "营业执照")
.append("holder", "某某公司")
.append("status", "valid");
collection.insertOne(doc);
// 查询文档
Document found = collection.find(new Document("certNo", "CERT-2024-003")).first();
System.out.println("Found: " + found.toJson());
// 聚合查询
collection.aggregate(Arrays.asList(
new Document("$match", new Document("status", "valid")),
new Document("$group", new Document("_id", "$certType")
.append("count", new Document("$sum", 1)))
)).forEach(d -> System.out.println(d.toJson()));
}
}
}迁移实践参考
迁移前评估清单
在进行MongoDB到KingbaseES的迁移前,建议完成以下评估:
| 评估项 | 检查内容 | 风险等级 |
|---|---|---|
| 版本兼容性 | MongoDB版本是否在5.0+范围内 | 高 |
| 命令覆盖 | 使用的命令是否在兼容列表中 | 高 |
| 驱动版本 | 应用使用的驱动版本 | 中 |
| 数据量 | 总数据量、单集合最大数据量 | 中 |
| 索引策略 | 现有索引是否都支持 | 中 |
| 特殊功能 | Change Streams、事务等 | 高 |
迁移步骤建议
bash
# 1. 导出MongoDB数据
mongodump --uri="mongodb://source-host:27017/mydb" --out=/backup/
# 2. 导入到KingbaseES
mongorestore --uri="mongodb://kingbase-host:27017/mydb" /backup/mydb/
# 3. 验证数据完整性
# 对比文档数量
mongo source-host:27017/mydb --eval "db.orders.countDocuments({})"
mongo kingbase-host:27017/mydb --eval "db.orders.countDocuments({})"
# 4. 重建索引(如有必要)
mongo kingbase-host:27017/mydb --eval "db.orders.reIndex()"兼容性测试脚本
javascript
// 兼容性测试脚本
// 在迁移前后分别运行,对比结果
const testCases = [
// 基本CRUD
{ name: "insertOne", fn: () => db.test.insertOne({ a: 1 }) },
{ name: "findOne", fn: () => db.test.findOne({ a: 1 }) },
{ name: "updateOne", fn: () => db.test.updateOne({ a: 1 }, { $set: { b: 2 } }) },
{ name: "deleteOne", fn: () => db.test.deleteOne({ a: 1 }) },
// 聚合
{ name: "aggregate", fn: () => db.test.aggregate([
{ $match: { status: "active" } },
{ $group: { _id: "$type", count: { $sum: 1 } } }
]).toArray() },
// 索引
{ name: "createIndex", fn: () => db.test.createIndex({ field: 1 }) },
{ name: "getIndexes", fn: () => db.test.getIndexes() },
// 其他
{ name: "distinct", fn: () => db.test.distinct("type") },
{ name: "countDocuments", fn: () => db.test.countDocuments({}) }
];
testCases.forEach(tc => {
try {
const result = tc.fn();
print(`✓ ${tc.name}: PASS`);
} catch (e) {
print(`✗ ${tc.name}: FAIL - ${e.message}`);
}
});案例参考
官方披露的一个案例是福建某地市电子证照系统的迁移:
项目背景:
- 原系统:MongoDB
- 数据规模:2TB+
- 并发压力:1000+ QPS
- 业务类型:电子证照存储与查询
迁移过程:
- 兼容性评估:验证现有查询语句兼容性
- 数据迁移:使用mongodump/mongorestore工具
- 应用改造:仅修改连接字符串
- 性能调优:针对高频查询优化索引
运行效果:
- 已稳定运行6个月以上
- 支撑500余家单位的证照共享服务
- 部分复杂查询响应时间从秒级降到毫秒级
这类案例可以作为评估参考,但每个系统的业务特点不同,实际迁移前建议:
- 在测试环境完整验证兼容性
- 进行压力测试,对比迁移前后性能
- 制定回滚方案
- 分阶段上线,先非核心业务
总结
多模数据库是一个值得关注的技术方向,将关系、文档、向量等能力整合到统一内核中,可以简化技术栈复杂度。本文以KingbaseES MongoDB兼容版为例,分析了其技术架构、兼容性表现和使用方法。
适用场景:
- 有信创合规要求的政企用户
- 希望简化多数据库运维的团队
- MongoDB迁移需求且对兼容性要求较高
需要注意:
- 基准测试数据仅供参考,实际性能需压测验证
- 部分高级功能(如Change Streams)的兼容性需单独确认
- 建议从非核心业务开始试点
技术选型最终还是要看具体场景和实测结果,希望本文的分析对有相关需求的读者有所帮助。