目录
[1. 数据模型设计思想](#1. 数据模型设计思想)
[2. 关键实体模型](#2. 关键实体模型)
[3. 技术选型建议](#3. 技术选型建议)
[1. 数据模型核心目标](#1. 数据模型核心目标)
[2. 聚合设计](#2. 聚合设计)
[3. 技术选型建议](#3. 技术选型建议)
[1. 为什么价格必须独立建模](#1. 为什么价格必须独立建模)
[2. 数据模型设计](#2. 数据模型设计)
[3. 技术选型建议](#3. 技术选型建议)
[1. 库存的核心建模原则](#1. 库存的核心建模原则)
[2. 数据模型示意](#2. 数据模型示意)
[3. 技术选型建议](#3. 技术选型建议)
[1. 数据模型特点](#1. 数据模型特点)
[2. 模型设计](#2. 模型设计)
[3. 技术选型](#3. 技术选型)
[1. 标签是"反模型化"设计](#1. 标签是“反模型化”设计)
[2. 数据模型设计](#2. 数据模型设计)
[3. 技术选型](#3. 技术选型)
[1. 设计目标](#1. 设计目标)
[2. 技术实现](#2. 技术实现)
[1. 为什么必须事件驱动](#1. 为什么必须事件驱动)
[2. 事件设计规范](#2. 事件设计规范)
[3. 技术选型](#3. 技术选型)
[1. 典型的领域事件触发点](#1. 典型的领域事件触发点)
[2. 事件定义:ProductPublished](#2. 事件定义:ProductPublished)
[1. 门店商品子域:生成门店商品](#1. 门店商品子域:生成门店商品)
[2. 价格子域:初始化价格体系](#2. 价格子域:初始化价格体系)
[3. 库存子域:创建库存主档](#3. 库存子域:创建库存主档)
干货分享,感谢您的阅读!
在商品供给体系中,一个常见误区是:先谈技术框架,再谈业务模型。
例如:
-
先确定用 MySQL 还是 NoSQL
-
先决定是否上 Kafka
-
先规划微服务拆分数量
但在复杂商品系统中,真正决定系统复杂度与稳定性的,并不是"技术先进程度",而是领域结构是否清晰、模型是否稳定、变更是否可控。
因此,本文遵循以下原则:
技术选型必须围绕数据模型服务,
数据模型必须围绕领域边界设计,
领域之间通过事件进行协作,而不是表关联。
一、商品供给域的技术选型总体原则
在进入子域级别之前,先明确几条全局性的技术选型原则:
(一)原则一:核心域优先一致性,非核心域优先扩展性
-
商品、SKU、价格、库存等核心数据
→ 强一致 / 明确事务边界
-
标签、质量、日志、通知
→ 最终一致 / 事件驱动
(二)原则二:数据形态决定存储技术,而不是反过来
-
强结构化、强约束数据 → 关系型数据库
-
高维、弱结构、频繁变更 → 文档型 / KV
-
高吞吐事件流 → 消息中间件
(三)原则三:领域之间只通过"语言"通信
这里的"语言",指的是:
-
明确的领域事件
-
稳定的事件契约(Schema)
而不是:
-
直接查别人的表
-
共享数据库
-
RPC 里塞一堆字段
二、核心域的数据模型设计深化
这部分的思考来自我们一开始对于基本的领域划分思考商品供给域的领域化拆解与系统化设计:
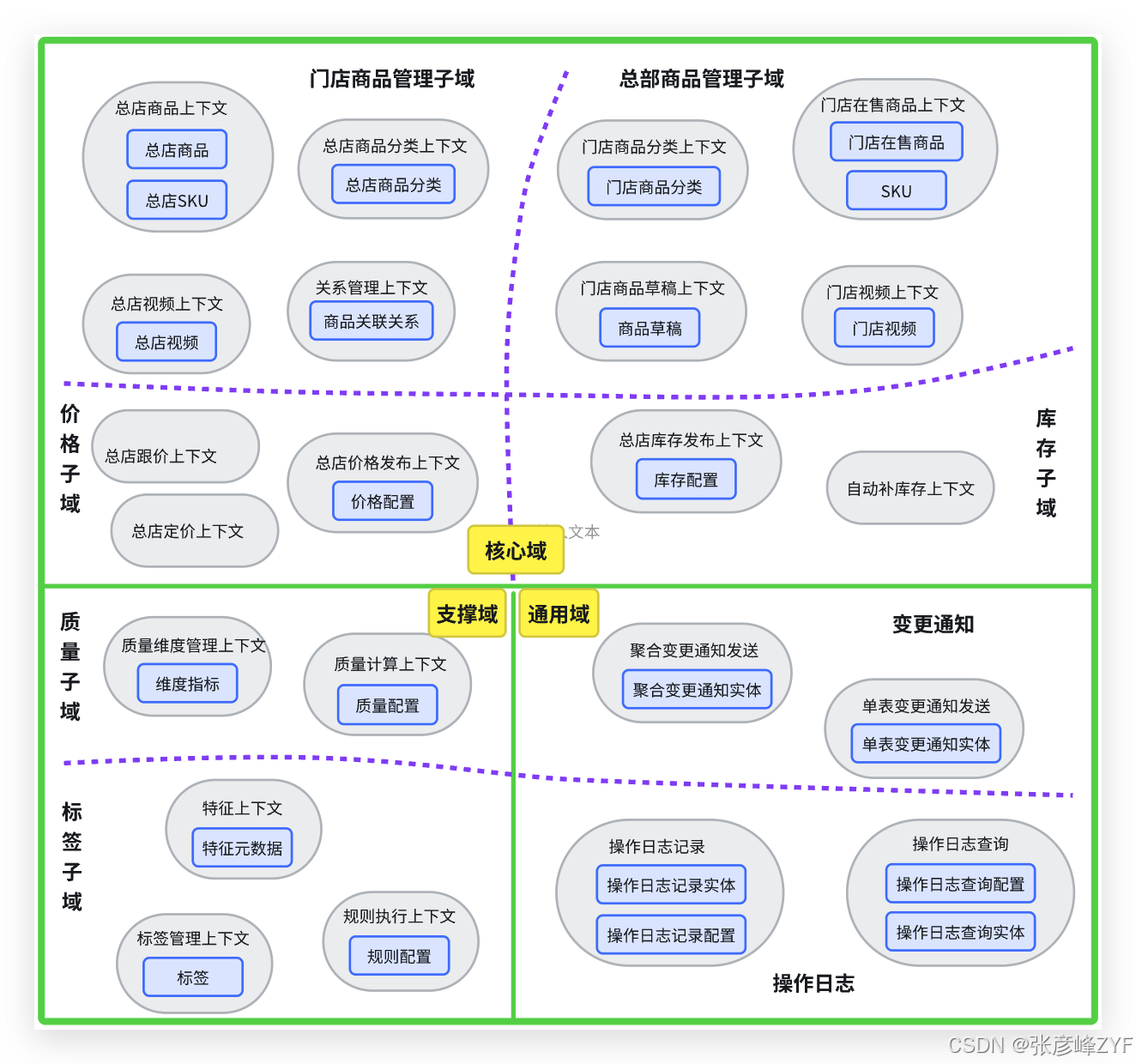
(一)门店商品管理子域
1. 数据模型设计思想
门店商品不是"商品表 + 门店ID",而是一个独立的领域实体。
核心建模思想:
-
门店商品 = 总店商品在门店上下文中的投影
-
门店维度属性必须显式建模
2. 关键实体模型
门店商品(StoreProduct)
-
store_product_id
-
store_id
-
product_id(总店商品ID)
-
status(上架 / 下架 / 禁售)
-
sale_channel
-
display_config
-
created_at / updated_at
门店 SKU(StoreSKU)
-
store_sku_id
-
store_product_id
-
sku_id
-
sale_status
-
limit_rule
关键点:禁止在门店商品表中复制总店商品的完整属性,否则模型会迅速失控。
3. 技术选型建议
-
存储:MySQL / PostgreSQL
-
ORM:明确禁止"自动字段映射继承"
-
缓存:以 store_id + sku_id 为 Key
(二)总店商品管理子域
1. 数据模型核心目标
总店商品的核心使命是:
成为企业级商品资产的唯一权威来源。
因此模型设计必须具备:
-
高稳定性
-
强语义
-
低变更频率
2. 聚合设计
商品聚合(Product Aggregate)
-
Product(商品)
-
SKU(规格)
-
属性集(Attributes)
SKU 永远属于商品聚合内部,而不是独立聚合。
3. 技术选型建议
-
存储:关系型数据库
-
表设计:
-
商品表
-
SKU 表
-
商品-类目关系表
-
-
严禁跨子域 JOIN
(三)价格子域
1. 为什么价格必须独立建模
价格具备以下特征:
-
变化频率高
-
生命周期短
-
规则复杂
如果将价格字段直接放入商品或 SKU 表,会导致:
-
表锁频繁
-
逻辑耦合
-
难以支持历史回溯
2. 数据模型设计
价格配置(PriceConfig)
-
price_id
-
sku_id
-
price_type
-
value
-
effective_time
-
expire_time
价格发布(PricePublish)
-
publish_id
-
price_id
-
scope(门店 / 区域 / 渠道)
-
status
3. 技术选型建议
-
存储:
-
主数据:MySQL
-
计算态:Redis
-
-
规则引擎:Drools / 自研规则 DSL
(四)库存子域
1. 库存的核心建模原则
库存不是"数量",而是状态机。
典型库存状态包括:
-
可售库存
-
锁定库存
-
冻结库存
2. 数据模型示意
库存主表(Inventory)
-
sku_id
-
warehouse_id
-
available_qty
-
locked_qty
-
frozen_qty
库存流水(InventoryFlow)
-
flow_id
-
sku_id
-
change_type
-
change_qty
-
biz_id
3. 技术选型建议
-
强一致库存:关系型数据库 + 行锁
-
高并发场景:Redis + Lua + 异步回写
-
库存对外永远通过 API,而非直表
三、支撑域的数据模型与技术策略
(一)质量子域
1. 数据模型特点
质量数据本质是:
-
多维度
-
可配置
-
可计算
2. 模型设计
-
质量维度表
-
质量规则表
-
商品质量结果表
计算结果不反写商品表,而是作为独立投影。
3. 技术选型
-
规则计算:批处理 + 流式计算结合
-
存储:关系型 + OLAP(ClickHouse)
(二)标签子域
1. 标签是"反模型化"设计
标签存在的意义是:
避免频繁修改商品模型结构。
2. 数据模型设计
-
标签定义表
-
标签值表
-
对象-标签映射表
支持多对象类型(商品 / SKU / 门店商品)。
3. 技术选型
-
存储:
-
定义数据:MySQL
-
标签值:KV / ES
-
-
查询优化:Bitmap / 倒排索引
四、通用域的工程化设计
(一)操作日志子域
1. 设计目标
-
全链路可追溯
-
可审计
-
可配置
2. 技术实现
-
日志事件化
-
异步写入
-
查询走专用索引库(ES)
(二)变更通知子域
1. 为什么必须事件驱动
同步调用会导致:
-
强耦合
-
雪崩风险
-
演进困难
2. 事件设计规范
事件必须包含:
-
事件类型
-
领域实体 ID
-
变更摘要
-
版本号
示例:
php
{
"eventType": "StoreProductStatusChanged",
"storeProductId": "123",
"oldStatus": "OFF",
"newStatus": "ON",
"version": 5
}3. 技术选型
-
消息中间件:Kafka / Pulsar
-
Schema 管理:Schema Registry
-
消费模型:幂等 + 重放友好
五、领域事件在商品供给域中的协作模式
没有任何同步调用。
在复杂的零售系统中,商品供给域往往横跨多个业务子域:总店商品、门店商品、价格、库存、渠道、促销等。随着业务规模扩大,如果仍然依赖同步接口调用与强一致事务,系统将迅速演化为高耦合、难扩展、难演进的状态。
领域驱动设计(DDD)提出了一条清晰的演进路径:
通过领域事件(Domain Event),实现跨子域的解耦协作。
我们以"总店商品发布(ProductPublished)"这一关键业务动作为切入点,系统分析领域事件在商品供给域中的协作模式、技术实现要点及其背后的架构思想。
(一)问题背景:商品发布为何是一个"跨域事件"
1. 典型的领域事件触发点
在传统设计中,"商品发布"往往被视为一个简单的状态变更:
商品状态:草稿 → 已发布
但在真实业务中,一次"发布"意味着一系列跨领域行为的连锁触发:
-
门店是否能看到该商品?
-
商品是否具备初始售价?
-
是否允许下单?库存是否存在?
-
是否需要同步到搜索、推荐、营销系统?
如果把这些逻辑全部堆积在"发布接口"中,必然导致:
-
聚合根职责膨胀
-
跨子域强依赖
-
发布流程无法演进
因此,"商品发布"并不是一个简单的 CRUD 行为,而是一个典型的领域事件触发点。
2. 事件定义:ProductPublished
在 DDD 中,领域事件强调的是:"业务上已经发生,并且对系统其他部分具有重要意义的事实。"
因此,ProductPublished 的语义应当是:
总店商品已完成所有发布前校验,并被正式标记为可对外供给。
一个典型的事件模型如下:
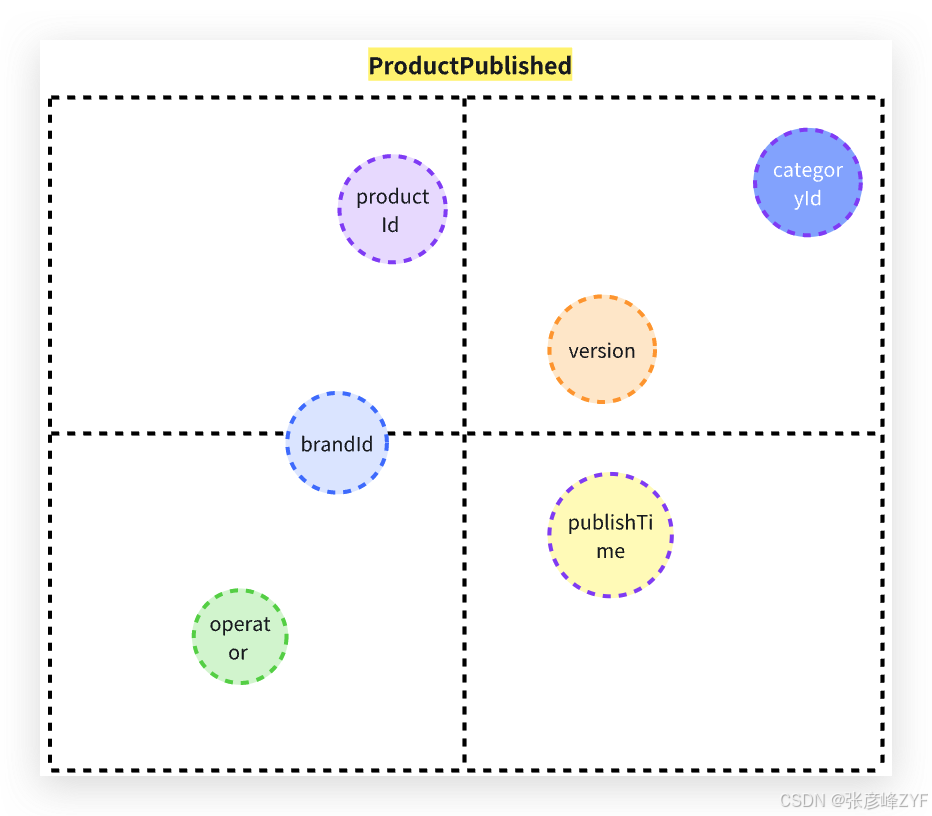
注意:
事件中不应包含具体业务决策逻辑,而是聚焦"事实本身"。
(二)事件驱动的跨子域协作模式
当 ProductPublished 事件被发布后,不同子域以订阅者(Consumer)的身份各自响应。
1. 门店商品子域:生成门店商品
**职责定位:**门店商品子域负责管理"某个门店是否经营某个商品"。
事件响应逻辑:ProductPublished → StoreProductCreated
-
监听
ProductPublished -
根据门店策略(全量铺货 / 白名单 / 区域规则)
-
生成门店商品记录(StoreProduct)
关键设计点
-
门店商品是独立聚合
-
不应依赖同步调用总店商品服务
-
允许门店商品创建延迟(最终一致)
2. 价格子域:初始化价格体系
**职责定位:**价格子域只关心商品是否进入"可定价"生命周期阶段。
事件响应逻辑:ProductPublished → PriceInitialized
-
消费
ProductPublished -
创建基础价格(如:指导价、默认售价)
-
价格规则可后续调整,不阻塞发布流程
架构收益
-
商品发布 ≠ 必须立刻可售
-
价格策略可以独立演进
-
避免"发布接口"中嵌入复杂价格逻辑
3. 库存子域:创建库存主档
职责定位: 库存子域负责库存维度建模,而非库存数量本身 。
事件响应逻辑:ProductPublished → InventoryCreated
-
消费
ProductPublished -
创建库存主档(SKU / 仓库 / 门店维度)
-
数量可以是 0,但结构必须存在
重要原则
-
"没有库存" ≠ "没有库存模型"
-
库存初始化是结构性动作,不是业务判断
(三)事件协作模式的整体视图
从系统视角看,一次商品发布的事件流可以抽象为:
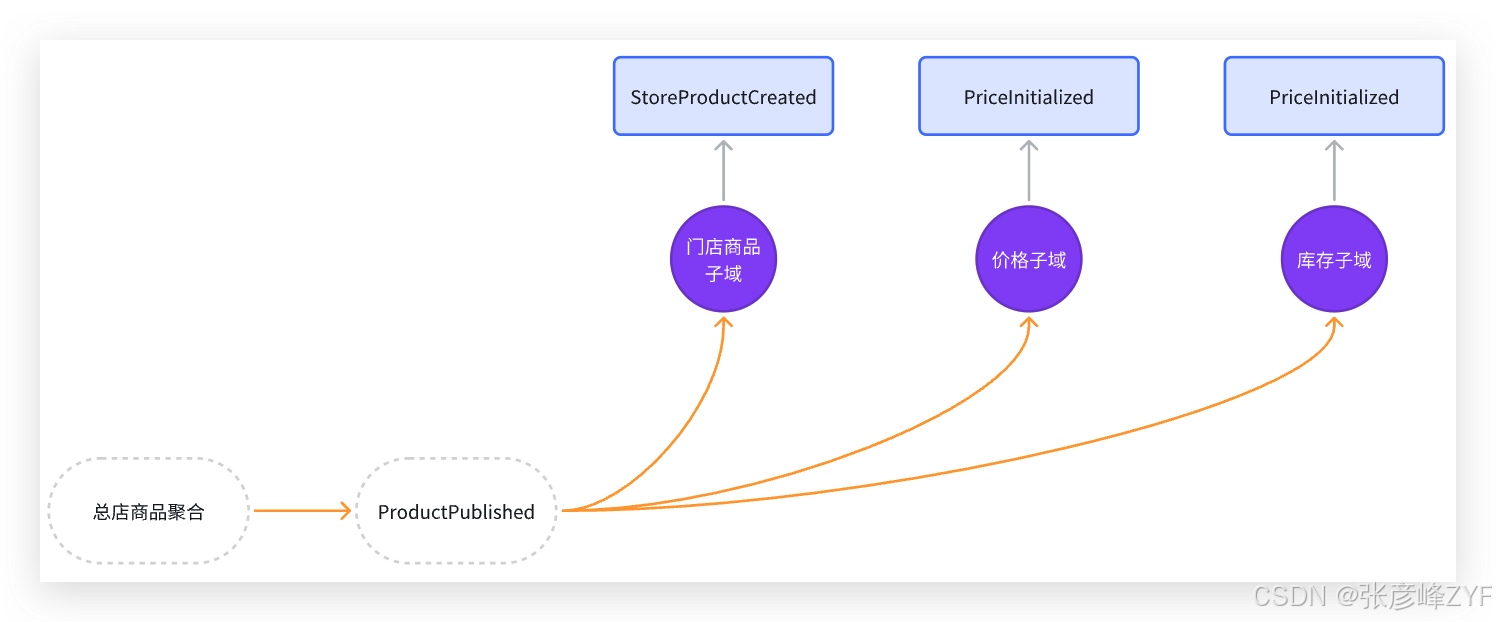
这是一个典型的扇出型事件协作模式(Fan-out Event Pattern)。
五、技术实现要点与工程实践
(一)事件发布的可靠性
常见实践包括:
-
本地事务 + 事件表(Outbox Pattern)
-
事务提交后异步投递消息
-
避免"先发消息,后提交事务"的不一致风险
(二)事件幂等与重复消费
所有事件消费者必须具备:
-
事件唯一标识
-
消费幂等校验
-
可重放能力
(三)最终一致性的接受与治理
-
不追求强一致
-
明确业务"可感知延迟"
-
对关键链路增加补偿与监控
六、与理论模型的对应关系
-
DDD:聚合之间通过领域事件解耦
-
EDA(Event-Driven Architecture):事件作为系统协作主线
-
CAP 理论:选择可用性 + 分区容错,接受最终一致
-
微服务设计原则:高内聚、低耦合、自治演进
这些思想在商品供给域中并非"学术概念",而是真实落地的工程选择。
七、总结
通过引入 ProductPublished 这一领域事件:
-
总店商品子域只关心"发布是否成立"
-
门店、价格、库存子域各自独立响应
-
系统从"过程驱动"转向"事件驱动"
-
架构获得了演进弹性与业务清晰度
在商品供给这样高度复杂、长期演进的领域中,领域事件不是锦上添花,而是必需基础设施。
六、总结:一个"可长期演进"的商品供给架构应具备什么
从技术视角总结,成熟的商品供给域应当具备:
-
清晰的子域边界
-
稳定的核心数据模型
-
高变动能力通过支撑域承载
-
子域之间通过事件解耦
-
技术选型服务于业务演进,而非炫技
这不是一蹴而就的系统,而是一套可以随着业务十年演进的架构骨架。
延伸参考
-
https://microservices.io/patterns/data/event-driven-architecture.html
-
https://www.thoughtworks.com/insights/articles/data-modeling-ddd
-
https://learn.microsoft.com/en-us/azure/architecture/guide/architecture-styles/event-driven
-
https://www.redhat.com/en/topics/integration/what-is-event-driven-architecture
-
https://www.infoq.com/articles/domain-driven-design-aggregates/
-
https://www.infoq.com/articles/microservices-event-sourcing/
-
https://www.thoughtworks.com/insights/articles/domain-driven-design-in-practice