架构与设计哲学 (Architecture & Philosophy)
为什么它这么快?它的核心价值观是什么?
在深入代码之前,我们需要先建立 Chonkie 的"世界观"。现有的切分库(如 LangChain 的 splitter)功能全面但往往像一辆满载的大巴车,而 Chonkie 的设计目标是做一辆F1 赛车。
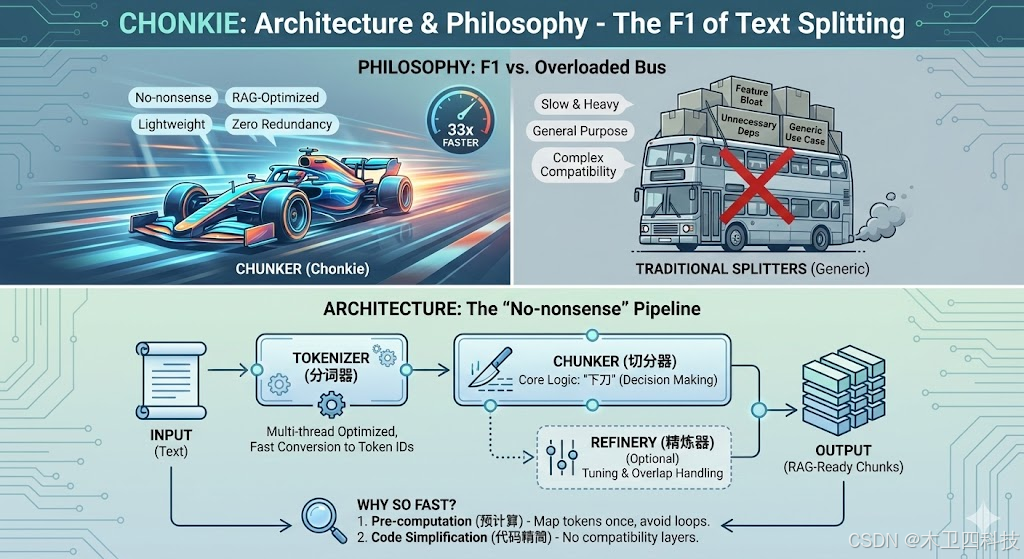
核心设计理念: "No-nonsense"(不说废话)
Chonkie 的官方座右铭是"轻量级、极速、无废话"。这体现在三个方面:
零冗余依赖:它极力避免引入沉重的第三方库(除非必要),这使得它在 Serverless 或边缘计算环境中极具优势。
面向 RAG 优化:它不是通用的文本处理工具,而是专门为检索增强生成 (RAG) 的上下文窗口优化的。
为什么它能快 33 倍?
这是 Chonkie 最引以为傲的数据。它的速度优势并非来自魔法,而是来自架构决策:
预计算 (Pre-computation):在实际切分前,预先计算好 Token 的映射关系,避免在循环中重复计算。
代码精简:移除了大量为了"兼容性"而存在的中间层逻辑。
核心组件图谱
我们可以把 Chonkie 想象成一个工厂流水线:
Input (输入):原始文本 (Text)
Tokenizer (分词器):负责快速将文本转化为 Token ID(Chonkie 在这一步做了多线程优化)。
Chunker (切分器):核心逻辑层,决定在哪里"下刀"。
Refinery (精炼器):可选组件,用于在切分后对上下文进行微调(比如重叠处理)。
核心切分算法详解 (The Chunkers)
Semantic vs Recursive vs SDPM,每种算法的内部原理图解
SemanticChunker:语义相似度的侦探 🕵️
SemanticChunker 的核心假设是:如果两句话讨论的是同一个话题,它们在向量空间中的距离应该很近。 一旦距离突然变远,就说明话题转换了,这正是"切一刀"的最佳时机。
核心原理图解
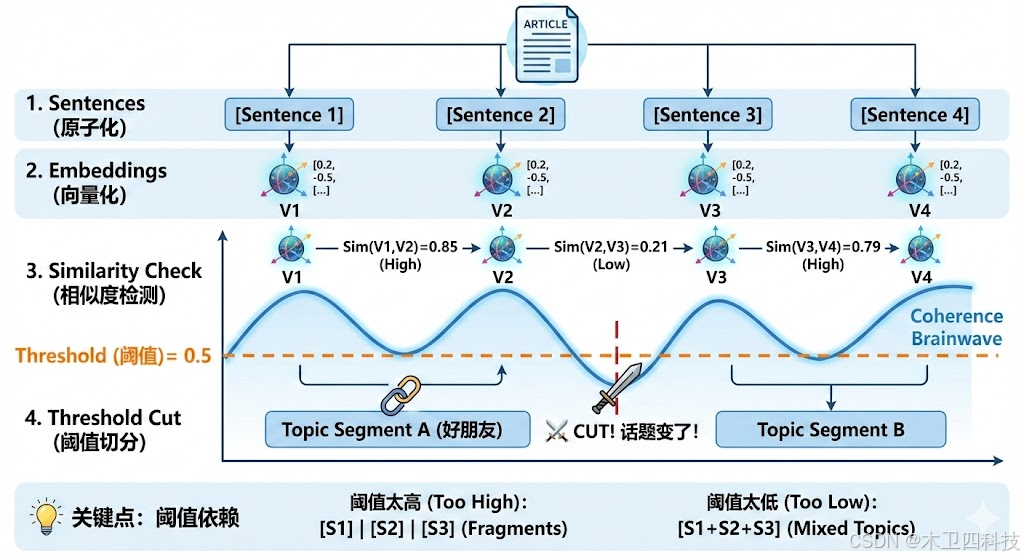
想象你在读一篇文章,你的脑电波随着内容的连贯性波动:
- Sentences (原子化):首先,将文本拆解成句子。
- Embeddings (向量化):快速计算每个句子的向量表示。
- Similarity Check (相似度检测):计算相邻句子之间的余弦相似度 (Cosine Similarity)。
- Threshold Cut (阈值切分):
- 如果 Sim(句1, 句2) > 阈值 ➡️ 它们是好朋友,合并在一起。
- 如果 Sim(句2, 句3) < 阈值 ➡️ 话题变了!⚔️ 在这里切断!
💡 关键点:这个算法极其依赖 threshold(阈值)的设定。设得太高,碎片会很碎;设得太低,不同话题会混在一起。
SDPMChunker:双重遍历的建筑师 🏗️
这是 Chonkie 的旗舰算法。SDPM 全称是 Semantic Double-Pass Merge(语义双重遍历合并)。它比单纯的 SemanticChunker 更聪明,因为它结合了"语义连贯性"和"上下文窗口大小"的限制。
它的工作流程分为两遍(Double-Pass):
Pass 1: 原子分组 (Grouping)
它首先根据语义相似度,将句子组合成一个个小的"语义原子群"。
- 例子:句子A, 句子B 讲的是关于"苹果"的,它们作为一个原子群;句子C 讲的是"香蕉",它自己一个群。
Pass 2: 智能合并 (Merging)
这是魔法发生的地方。它尝试将这些"原子群"合并成最终的 Chunk,同时监控两个指标:
-
Token 计数:有没有超过 max_chunk_size?
-
语义跳变:如果合并下一个原子群会导致整体语义重心发生剧烈偏移,它就会停止合并。
为什么 SDPM 更强? 普通的 SemanticChunker 可能会因为一个句子不通顺就意外切断,而 SDPM 具有"平滑" (Smoothing)效果。它能容忍局部的微小语义波动,为了保证 Chunk 的完整性,尽量填满上下文窗口,同时不破坏大的语义边界。

性能优化秘籍 (Under the Hood)
预计算、SIMD 与多线程如何在 Python 中实现极致加速
让我们拆解这台 F1 赛车的三个核心加速引擎:
预计算与索引映射 (Pre-computation & Mapping)
这是 Chonkie 甚至不需要用 C++ 重写就能极快的第一大秘诀。
传统笨办法: 一边遍历 Token,一边解码成单词,一边判断是不是句号,一边计算长度。这就像你在读一本书,每读一个字都要停下来查字典、数笔画,效率极低。
Chonkie 的做法 (Mise-en-place): 在开始切分之前,Chonkie 会构建一组辅助索引数组。
-
Token-to-Word Map:哪个 Token 属于哪个单词?
-
Sentence Boundaries:哪些 Token 是句子的结束点?
通过预先计算这些"元数据",实际切分算法(如 SDPMChunker)运行时,不需要再看原始文本,只需要在整数数组上进行简单的切片(Slicing)和加法操作。
向量化与 SIMD (Vectorization)
虽然 Chonkie 是纯 Python 库,但它巧妙地利用了底层硬件的能力。
当我们需要计算大量 Token 的属性时,如果使用 Python 的 List,CPU 一次只能处理一个数字(SISD)。但如果利用 NumPy 这样的库(或者 Chonkie 内部类似的数组处理逻辑),我们可以激活 CPU 的 SIMD (Single Instruction, Multiple Data) 指令集。
-
SISD (单指令单数据):我要给 4 个数字加 1,我得发 4 次指令。
-
SIMD (单指令多数据):我有 4 个数字,我发 1 次指令"全部加 1",CPU 的向量寄存器一次性搞定。
Chonkie 在计算句子相似度或 Token 累加时,尽可能利用了这种"批量处理"的思维,而不是写 Python 级的循环。
绕过 GIL 的多线程 (Bypassing the GIL)
Python 有一个著名的瓶颈叫 GIL (全局解释器锁),它导致多线程通常无法利用多核 CPU。但是,Chonkie 知道如何"作弊"。
它依赖的 Tokenizer(通常是 tokenizers 库,基于 Rust 编写)在执行分词任务时,会释放 GIL。
这意味着:
-
当你在 Python 主线程中调用 chunk_batch(documents) 时,Chonkie 会将繁重的分词任务交给底层的 Rust 代码。
-
Rust 代码在所有 CPU 核心上并行狂奔 🏃♂️🏃♀️。
-
Python 只需要在终点等待结果,然后做最后轻量级的组装。
RAG 生产环境集成 (Integration Guide)
从数据清洗到向量库存储的最佳实践
与向量数据库的握手 🤝
Chonkie 的输出通常包含纯文本 (text) 和一些元数据(如 token_count)。大多数向量数据库(如 Qdrant, Milvus, Chroma)都需要你准备两个东西:
-
Vector: 文本经过模型生成的数字列表。
-
Payload/Metadata: 原始文本和辅助信息。
这是一个典型的集成模式(伪代码):
python
Python
from chonkie import SDPMChunker
from qdrant_client import QdrantClient
# 1. 初始化 Chonkie (切割工)
chunker = SDPMChunker(tokenizer_or_model="gpt-4", max_chunk_size=512)
# 2. 切分文档
chunks = chunker(my_long_document)
# Chonkie 返回的是对象列表,每个对象包含 text, start_index, end_index 等
# 3. 准备入库数据
points = []
for idx, chunk in enumerate(chunks):
# 生成向量 (假设你有一个 embedding_model)
vector = embedding_model.encode(chunk.text)
# 准备 Payload (Chonkie 的强项在于它保留了结构化信息)
payload = {
"text": chunk.text,
"token_count": chunk.token_count,
"source": "contract_v1.pdf"
}
points.append(PointStruct(id=idx, vector=vector, payload=payload))
# 4. 存入数据库
client.upsert(collection_name="rag_collection", points=points)💡 核心要点:Chonkie 的速度优势在这里体现为------它能极其快速地生成那个 chunks 列表,防止数据准备阶段成为瓶颈。
4.2 Refinery:上下文的润滑剂 🛢️
有时候,切得太"干脆"反而不是好事。
如果一句话被切断,或者一个代词("他说了...")与其指代的对象("马斯克")被分到了两个不同的 Chunk 里,检索效果就会大打折扣。
Refinery (精炼器) 的作用是在切分后,对 Chunk 进行微调。最常用的功能是 Overlap (重叠)。
-
没有 Refinery: Chunk A: ...讲完了原理。, Chunk B: 接着我们看代码...
-
有 Refinery (Overlap):
- Chunk A: "...讲完了原理。接着我们看代码..." (尾部包含 B 的开头)
- Chunk B: "**...讲完了原理。**接着我们看代码..." (头部包含 A 的结尾)
在 Chonkie 中,这通常作为切分器的一个参数或后处理步骤存在,确保每个切片都是"独立可理解"的。
- 一句话:专注智能网联汽车安全,推动行业从「安全」到「安心」
- 领域:网络安全 / 功能安全 / AI安全/机器人安全
- 底座:自主可控 + 数据与AI驱动+蝴蝶大模型+安全智能体群
- 产品:VSOC / VTI / TARA 合规智能体 / 用车安心Agent / 维修助手Agent