- memblock 是内核启动阶段独占的物理内存管理子系统 ,工作在伙伴系统初始化之前 ,只管理物理地址(无虚拟地址映射,此时 MMU / 页表未就绪);
- memblock 的设计核心是:以「连续物理内存区间」为单位管理内存,而非伙伴系统的「物理页框 (page frame)」;
- memblock 管理的核心逻辑:先记录系统所有物理内存,再标记「预留不可分配」的区间,剩余的就是「可分配可用」的物理内存。
- memblock 管理的核心逻辑:先记录系统所有物理内存,再标记「预留不可分配」的区间,剩余的就是「可分配可用」的物理内存。
memblock 三大核心数据结构
核心结构 1:struct memblock_region
【最小单元 - 单段物理内存区间】
struct memblock_region {
phys_addr_t base; // 物理内存区间的【起始物理地址】
phys_addr_t size; // 物理内存区间的【大小】(单位:字节)
unsigned long flags; // 内存区间的【属性标志位】
#ifdef CONFIG_HAVE_MEMBLOCK_NODE_MAP
int nid; // NUMA节点ID,多核/多节点架构使用,单机架构无
#endif };
base+size:组合定义了一段连续的物理内存区间 ,比如base=0x00100000,size=0x7FE00000表示从 0x100000 开始的 8GB 连续物理内存;这是 memblock 的最小管理粒度,所有物理内存都被拆分为 N 个这样的连续区间。flags:内存区间的属性,内核定义了专属宏,最常用的只有 2 个:MEMBLOCK_NONE:无特殊属性,普通可用物理内存;MEMBLOCK_RESERVED:预留内存,禁止分配(内核镜像、固件、硬件 DMA 区、页表等都标记此属性)。
- 补充:该结构体无链表节点,是一个「扁平的区间描述结构体」,通过数组方式批量管理。
- 核心特性:一个
memblock_region只描述一段连续、同属性的物理内存;物理内存中的「空洞、预留区、可用区」都会被封装为独立的该结构体实例。
核心结构 2:struct memblock_type
【分类管理 - 同类型内存区间的集合】
memblock.memory 管理全量物理内存,memblock.reserved 管理预留内存,可用内存 = 全量内存 - 预留内存;
struct memblock_type {
unsigned long cnt; // 当前已注册的「内存区间数量」(即regions数组的有效元素个数)
unsigned long max; // regions数组的「最大容量」(可容纳的最大区间数)
phys_addr_t total_size; // 该类型下「所有内存区间的总大小」(字节)
struct memblock_region *regions; // 核心:指向【memblock_region数组】的指针
char *name; // 该内存类型的名称,用于调试和日志打印 };
- 核心设计:对物理内存做「分类」,把同类型的
memblock_region放在同一个数组里管理,是 memblock 的「中层管理结构」; cnt&max:实现了「动态可扩容的数组」,内核启动时max有默认值,当内存区间数量超过max时,内核会自动扩容数组;total_size:内核预计算的该类型内存总大小,无需遍历数组求和,提升效率;name:字符串名称,源码中固定赋值 2 个关键值,对应 memblock 的核心分类,无其他取值 :"memory":表示「系统全部物理内存」(可用 + 预留);"reserved":表示「系统预留的物理内存」(内核 / 硬件占用,不可分配)。
核心特性:这是 memblock 最核心的「分类容器」,内核中只会实例化两个 该结构体,分别管理「全量内存」和「预留内存」,无第三个实例。
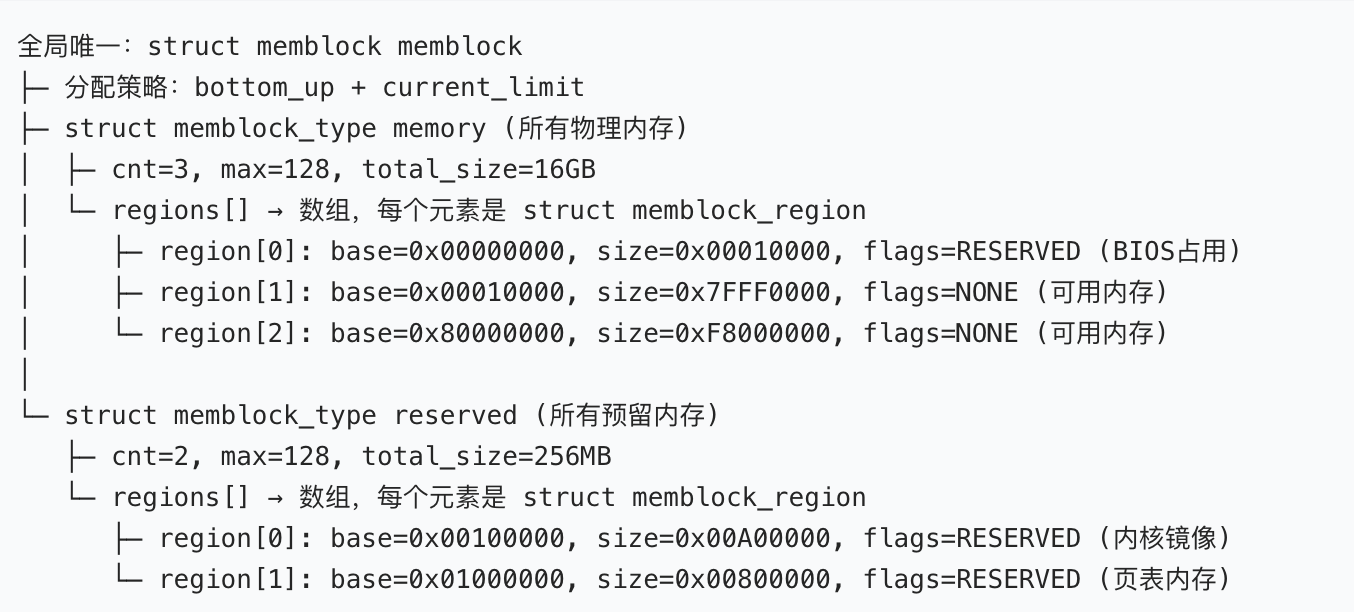
核心结构 3:struct memblock
【全局总控 - memblock 的顶层管理结构体】
struct memblock {
bool bottom_up; // 内存分配方向:true=低地址→高地址;false=高地址→低地址
phys_addr_t current_limit; // 本次内存分配的「物理地址上限」,限制分配的最高地址
struct memblock_type memory; // 核心:管理【系统所有物理内存】的memblock_type
struct memblock_type reserved;//核心:管理【系统所有预留内存】的memblock_type
#ifdef CONFIG_HAVE_MEMBLOCK_PHYS_MAP
struct memblock_type physmem;// 可选:部分架构(x86)使用,标记「真实存在的物理内存」
#endif };
// 全局唯一实例!!!整个内核只有这一个memblock对象,所有操作都基于它
extern struct memblock memblock;
这是 memblock 的根结构体 ,内核全局只有一个实例 memblock,所有 memblock 的 API 都是操作这个全局实例,无任何例外。
bottom_up:内存分配的方向策略,内核默认值是false(从高地址向低地址 分配),可通过memblock_set_bottom_up()修改;低地址内存是「黄金内存」:DMA 设备、BIOS / 固件、内核镜像都占用低地址,所以默认从高地址分配,避免挤占低地址关键内存。current_limit:分配内存时的「最高物理地址阈值」,内核只会在[0,current_limit]区间内分配内存,默认是物理内存最大值。
memblock.memory:- name =
"memory"; - 存储系统能识别的所有物理内存区间,包含:可用内存、预留内存、硬件空洞、内核镜像区等;
- 这个结构体的
total_size就是系统的物理内存总大小 (和cat /proc/meminfo | grep MemTotal一致)。
- name =
memblock.reserved:- name =
"reserved"; - 存储所有被标记为「不可分配」的物理内存区间,包含:内核镜像本身、页表内存、DMA 缓冲区、硬件预留区、固件占用区等;
- 只要是被
memblock_reserve()标记过的内存,都会被加入这个数组。
- name =
核心特性
- 全局唯一:整个内核只有一个
struct memblock实例,是 memblock 子系统的总入口; - 只读后期:伙伴系统初始化完成后,该结构体变为只读,不再修改,仅用于查询物理内存分布;
- 数据来源:
/proc/iomem命令的输出,就是直接遍历该结构体的memory和reserved字段生成的。
memblock 的核心内存计算逻辑
系统可分配的物理内存 = memblock.memory - memblock.reserved
系统可分配的物理内存解释:从「全量物理内存」中剔除「预留内存」,剩下的就是 memblock 可以分配的空闲物理内存。
三个核心结构的「层级关系」
内核把「所有物理内存」拆成多个 memblock_region 区间,按「是否预留」分为两类,分别放入两个 memblock_type 容器,最后由一个全局的 memblock 结构体统一管理。
memblock 高频关联宏
这些宏是 memblock 数据结构的「配套属性 / 操作」,源码中随处可见,和核心结构绑定出现,必须记住:
MEMBLOCK_NONE:内存区间无属性,可用内存;MEMBLOCK_RESERVED:内存区间是预留内存,禁止分配;MEMBLOCK_ALLOC_ANYWHERE:分配内存时无地址限制,默认策略;MEMBLOCK_ALLOC_ACCESSIBLE:仅在「内核可直接访问的物理内存」中分配。
memblock 数据结构的核心设计优势
内核要设计这套三层结构,而不是简单的链表,其核心原因是适配「内核启动早期的极端环境」:
- 无依赖:不依赖页表、MMU、伙伴系统、slab 分配器,纯物理地址操作,裸机环境即可运行;
- 高效:数组遍历的效率远高于链表,内核启动早期的内存区间数量极少,数组足够用;
- 简洁:三层结构职责清晰,无冗余字段,内核启动早期的内存管理只需要「添加、预留、分配」三个核心操作,这套结构完美适配。
memblock 解决「内核早期无内存管理」的刚需
- 内核启动初期,MMU 可能未开启、页表未建立、
struct page未定义,此时不可能有 mem_map; - memblock 是「极简设计」:无依赖、纯物理地址操作、支持大块分配,完美适配启动期的「裸机环境」;
- 没有 memblock,内核连「分配内存创建 mem_map」都做不到,这是先有鸡后有蛋的逻辑。
mem_map 解决「精细化内存管理」的刚需
- memblock 只能管理「连续的物理地址区间」,无法对「单个物理页」做精细化管理;
- 内核正常运行时,需要对物理页做「分配、释放、合并、标记属性、缓存管理」等复杂操作,这些都是 memblock 做不到的;
mem_map+ 伙伴系统,是内核为「精细化管理」设计的成熟方案,能支撑整个内核生命周期的内存需求。
memblock 结构 ↔ PAGE_OFFSET
- memblock 分配的「页表物理内存」,最终用于建立
PAGE_OFFSET的线性映射; - memblock 管理的是物理地址 ,PAGE_OFFSET 是虚拟地址边界 ,二者的关联公式:
内核虚拟地址 = PAGE_OFFSET + 物理地址,在 memblock 分配内存后,内核会用这个公式将物理地址转为虚拟地址。
memblock 结构 ↔ 伙伴系统
- memblock 是伙伴系统的「数据来源」:伙伴系统初始化时,会遍历 memblock 的
memory和reserved字段,构建struct page数组和空闲页链表; - memblock 分配的
struct page数组内存,是伙伴系统的核心数据结构,伙伴系统接管内存管理后,memblock 的结构就只读了。
memblock 与 mem_map 的核心关系
mem_map 的「物理内存空间」是由 memblock 分配的;mem_map 的「初始化数据」是由 memblock 提供的;memblock 是 mem_map 的「生父」,伙伴系统是 mem_map 的「养父」
时序关系 :memblock 先工作 → 分配内存创建 mem_map → 初始化 mem_map → memblock 移交内存管理权 → 伙伴系统接管 mem_map 工作 → memblock 退居二线(只读)。
二者的联动,是 Linux 内核物理内存管理的「权力交接核心流程」,所有架构(x86_64/ARM64/RISC-V)完全一致。
memblock 与 mem_map 的「完整联动流程」:
阶段 1:memblock 为 mem_map 分配「物理内存空间」:
- 内核先计算
mem_map的总大小:总大小 = 物理内存总页数 * sizeof(struct page);- 例:系统有 16GB 物理内存、4KB 页框 → 总页数 = 16GB/4KB = 4M →
mem_map大小 = 4M * sizeof (struct page)(约 64MB);
- 例:系统有 16GB 物理内存、4KB 页框 → 总页数 = 16GB/4KB = 4M →
- 内核调用
memblock_alloc()从memblock管理的「可用物理内存」中,分配一块 连续的、对齐的物理内存 ;- 分配的是「物理地址」,返回值是这段内存的物理起始地址 (记为
phys_mem_map); - 分配策略:
memblock默认从高地址分配,避免挤占低地址的 DMA 内存 / 内核镜像内存;
- 分配的是「物理地址」,返回值是这段内存的物理起始地址 (记为
- 这个物理内存块,后续专门存放
mem_map数组 ,内核会立刻调用memblock_reserve(phys_mem_map, size)将其标记为「预留内存」,禁止被二次分配。
阶段 2:将 mem_map 的物理地址映射为「内核虚拟地址」(绑定 PAGE_OFFSET):
memblock分配的是物理地址 ,此时内核已经开启 MMU、建立了「线性映射」(内核虚拟地址 =PAGE_OFFSET+ 物理地址);- 内核代码只能访问「虚拟地址」,无法直接访问物理地址,必须完成映射。
// 内核虚拟地址 = PAGE_OFFSET + 物理地址 (你必背的黄金公式)
virt_mem_map = (struct page *) __phys_to_virt(phys_mem_map);
mem_map = virt_mem_map;
阶段 3:memblock 为 mem_map 提供「初始化数据」,完成 mem_map 数组填充
mem_map 只是一个空的数组,此时里面全是脏数据,内核需要为每一个 struct page 元素填充正确的物理页信息 ,而填充的所有数据源,全部来自 memblock;
- 内核遍历
memblock.memory中记录的所有物理内存区间 (memblock_region数组); - 对区间内的每一个物理页框 ,执行如下操作:
- 根据物理页号,找到
mem_map数组中对应的下标:page = mem_map + pfn; - 初始化
page的核心字段:物理页号(pfn)、内存节点(nid)、页状态(PG_reserved/PG_free); - 如果该物理页属于
memblock.reserved标记的「预留区」→ 置位PG_reserved(预留页,不可分配); - 如果该物理页是「可用空闲区」→ 置位
PG_free(空闲页,可分配);
- 根据物理页号,找到
- 初始化完成后:
mem_map数组的每一个元素,都精准对应一个物理页框,且状态与memblock记录的物理内存分布完全一致。
核心结论:memblock 是 mem_map 的「数据源」,mem_map 对物理内存的所有认知,全部来自 memblock 的探测结果。
阶段 4:权力交接 - memblock 移交管理权,伙伴系统接管 mem_map
- 内核基于初始化完成的
mem_map,构建伙伴系统的「空闲页链表」和「内存域(ZONE_DMA/ZONE_NORMAL/ZONE_HIGHMEM)」; - 内核调用
memblock_free_all():遍历memblock中所有「可用物理内存」,将对应的struct page加入伙伴系统的空闲链表; - 至此:伙伴系统正式就绪 ,内核所有后续的内存分配(
__get_free_pages/kmalloc/vmalloc)全部通过伙伴系统操作mem_map完成; memblock的使命彻底完成,此后退化为 「只读状态」 :不再做任何内存分配 / 释放,仅保留物理内存分布的原始数据,供内核查询(如/proc/iomem的数据来源)。
memblock 与 NUMA的核心关系
NUMA 架构下,memblock 是内核第一个「按节点维度探测 / 管理物理内存」的子系统,是 NUMA 内存管理的根基。
UMA 架构下,memblock 只需要记录「全局物理内存区间」即可,所有内存平等无差异;但 NUMA 下,物理内存有明确的节点归属 ,内核必须从启动最早期就标记「哪段物理内存属于哪个 NUMA 节点」,否则后续伙伴系统 /mem_map无法按节点分配内存。
NUMA 的核心优化原则:CPU 优先分配本地节点内存,减少跨节点内存访问的性能损耗;这个原则的实现,依赖 memblock 在启动阶段提供的「内存 - 节点」绑定关系。
内核启动早期的关键内存分配(页表、mem_map数组、内核镜像),在 NUMA 下必须分配到「启动 CPU 所在的本地节点」,否则会导致启动失败 / 性能极差,而这个分配能力由memblock NUMA提供。
内核为了支持 NUMA,仅在原有结构上做了最小化扩展(无新增独立结构体),所有 NUMA 相关属性都是「条件编译 + 新增字段」;
内核控制宏:CONFIG_NUMA → 开启该宏则启用 memblock NUMA 支持,关闭则退化为 UMA 模式,所有 NUMA 字段失效。
- UMA:单节点内存架构,所有 CPU 共享同一片物理内存;
- NUMA:多节点内存架构,物理内存分属不同NUMA 节点 (Node),CPU 访问本地内存速度远快于远端;
- memblock:内核启动期探测 NUMA 节点 + 内存分布,为
pglist_data提供初始化数据; - mem_map:物理页描述符数组,NUMA 下每个节点有独立的 mem_map 子数组;
struct memblock_region,原有字段不变,仅新增 NUMA 专属属性,核心字段nid:
- 含义 :
node id,NUMA 节点的唯一编号,从0开始递增(node0、node1、node2...); - 核心规则 :一段连续的物理内存区间,只能归属一个 NUMA 节点 ,一个节点可以包含多个
memblock_region区间; - 特殊值 :
nid = NUMA_NO_NODE (-1)表示该内存区间无归属节点(UMA 模式 / 节点探测失败); - 关键特性 :这个字段让 memblock 的「最小内存管理粒度」,从「物理地址区间」升级为「节点 + 地址区间」,这是 memblock 支持 NUMA 的核心。
struct memblock 新增 NUMA 专属成员:
全局总控结构体memblock,原有核心字段不变,内核为 NUMA 新增了一个核心memblock_type 成员, 核心新增字段 numa_memory:
- 名称 :固定为
"numa_memory",仅在 NUMA 模式下生效; - 核心作用 :存储「按 NUMA 节点划分后的所有物理内存区间 」,每个
memblock_region的nid字段精准标记所属节点,无任何交叉; - 与
memory的区别 :memblock.memory是「全局所有内存」,memblock.numa_memory是「按节点拆分后的内存」,二者是总分关系,总大小完全相等。
NUMA 节点的核心描述符 struct pglist_data
struct pglist_data (pgdat) 是 Linux 内核中「一个 NUMA 节点的内存管理总管家」, 一个 NUMA 节点 = 一个 struct pglist_data 实例;UMA 架构下,系统只有1 个 NUMA 节点 (node0) ,因此内核中只有1 个 pgdat 实例;NUMA 架构下,有 N 个节点就有 N 个 pgdat 实例;
该结构体的核心目的:
- 无 pgdat 时,内核只能全局管理内存,无法区分「本地内存 / 远端内存」,NUMA 架构的性能优势完全无法发挥;
- pgdat 把一个 NUMA 节点的所有内存资源、内存管理策略、内存回收机制全部封装在一个结构体中,实现「节点自治」;
- 内核的内存分配 / 回收 / 规整等所有操作,全部基于 pgdat 执行,先找到 CPU 所属节点的 pgdat,再操作该节点的内存,完美适配 NUMA 的「本地优先」原则;
- 承接 memblock 的成果:memblock 在启动期探测的「节点 - 内存」分布数据,最终全部固化到对应节点的 pgdat 中,pgdat 是 memblock NUMA 数据的「最终承载体」。
该结构是 NUMA 内存管理的核心载体,与 memblock 强联动:
- 每个 NUMA 节点对应一个唯一的
struct pglist_data实例 (简称pgdat); - 作用:管理当前节点的所有物理内存,包含节点的
mem_map数组、伙伴系统空闲页链表、内存域(ZONE_DMA/ZONE_NORMAL)等; - 联动关系:memblock 探测到的「节点 - 内存」关系,最终会被初始化到对应节点的
pgdat中,pgdat是 memblock NUMA 数据的最终承接者。
memblock NUMA 的完整工作流程:
- 核心调用
memblock_add_node(base, size, nid):将「某节点的物理内存区间」添加到memblock.memory,并为该memblock_region的nid字段赋值为对应节点 ID;UMA 调用memblock_add(),NUMA 调用memblock_add_node(); - 内核调用
memblock_reserve_node(base, size, nid):标记「内核镜像、BIOS 固件、硬件预留区、页表内存」为预留内存,加入memblock.reserved; - 每个预留的
memblock_region同样携带nid字段,标记该预留内存属于哪个节点; - 内核调用
memblock_build_numa_maps():遍历memblock.memory中的所有区间,按nid字段拆分,将「同节点的内存区间」归类到memblock.numa_memory中,形成「节点 - 内存」的精准映射;此时,内核可以快速查询:node0 有哪些内存、node1 有哪些内存,无需全局遍历; - 内核获取「当前启动 CPU 所属的 NUMA 节点 ID」(记为
local_nid,通常是 node0);调用memblock_alloc_node(size, align, local_nid):仅从本地节点的可用内存中分配 ,为当前节点的pgdat、mem_map子数组、页表分配物理内存; - 对每一个 NUMA 节点,重复上述操作:为节点分配
pgdat和mem_map,并调用memblock_reserve_node()标记为预留,禁止二次分配; - 关键区别:UMA 全局只有一个
mem_map,NUMA 每个节点有独立的mem_map子数组,对应节点的物理页。 - 内核基于 memblock 的「节点 - 内存」数据,初始化每个节点的
mem_map子数组:物理页号对应mem_map下标,nid标记节点归属; - 为每个节点初始化
struct pglist_data,绑定该节点的mem_map和内存域; - 调用
memblock_free_all_nodes():将每个节点的可用内存,从 memblock 移交到对应节点的伙伴系统空闲链表中; - NUMA 下的伙伴系统正式就绪:内核后续的内存分配,会优先从「当前 CPU 的本地节点」分配,本地不足再分配远端节点;
memblock 的核心操作
添加内存区域:memblock_add()
int memblock_add(phys_addr_t base, phys_addr_t size);
- 将一段物理内存区域添加到
memblock.memory; - 自动合并相邻的内存区域,避免碎片化;
- 内核启动时,通过固件(BIOS/UEFI)获取物理内存信息后,调用此函数注册所有内存区域。
预留内存区域:memblock_reserve()
void memblock_reserve(phys_addr_t base, phys_addr_t size);
- 将一段物理内存区域添加到
memblock.reserved; - 标记该区域为 "预留",禁止后续分配;
- 内核用于标记自身镜像、页表、固件占用的内存区域。
分配内存:memblock_alloc()
phys_addr_t memblock_alloc(phys_addr_t size, phys_addr_t align);
- 从可用内存区域 分配一段大小为
size、对齐为align的物理内存; - 分配方向由
memblock.bottom_up决定; - 返回分配到的物理起始地址 ,失败返回
0; - 内核早期用于分配页表、
struct page数组等内存。
按地址范围分配:memblock_alloc_range()
- 在指定地址范围
[start, end]内分配内存,更灵活; - 适用于需要特定地址的场景(如 DMA 缓冲区需低地址内存)。
释放内存:memblock_free()
void memblock_free(phys_addr_t base, phys_addr_t size);
- 将一段已分配的内存释放回可用区域;
- 从
memblock.reserved中移除该区域; - 注意 :
memblock的释放操作较少使用,因为内核早期内存分配多为 "一次性"。
查询可用内存大小:memblock_phys_mem_size()
phys_addr_t memblock_phys_mem_size(void);
返回系统中所有物理内存的总大小(即 memblock.memory.total_size)。
查询最大可用内存块:memblock_find_in_range()
phys_addr_t memblock_find_in_range(phys_addr_t start, phys_addr_t end, phys_addr_t size, phys_addr_t align);
- 在
[start, end]范围内,查找一块大小为size、对齐为align的可用内存; - 只查询不分配,适用于预检查。
遍历内存区域:for_each_memblock()
#define for_each_memblock(type, region) \ for (...)
- 遍历
memblock中指定类型的所有内存区域; - 例如遍历所有可用内存:
for_each_memblock(memory, region)。
memblock 的工作流程
阶段 1:内核镜像加载与 memblock 初始化
- 引导程序(GRUB/UEFI)将内核镜像加载到物理内存的指定位置;
- 内核启动入口
start_kernel()调用memblock_init(),初始化全局memblock结构体; - 内核通过固件提供的内存信息(如 Device Tree),调用
memblock_add()将所有物理内存区域添加到memblock.memory。
阶段 2:标记预留内存区域
- 调用
memblock_reserve()标记内核镜像自身占用的内存区域; - 标记固件(UEFI/ACPI)占用的内存区域;
- 标记 DMA 缓冲区、硬件预留等特殊内存区域;
- 此时
memblock.reserved包含所有不可分配的内存,memory - reserved为可用内存。
阶段 3:使用 memblock 分配关键内存
- 分配页表内存 :内核调用
memblock_alloc()分配页表所需的物理内存,用于建立PAGE_OFFSET的线性映射; - 分配
struct page数组内存 :struct page是伙伴系统管理物理页的核心数据结构,内核调用memblock_alloc()分配连续物理内存,用于存储mem_map数组(每个物理页对应一个struct page); - 分配其他内核早期数据结构 :如
kobject核心结构、中断描述符表等。
阶段 4:伙伴系统初始化,memblock 交出管理权
- 内核调用
free_area_init()初始化伙伴系统,基于memblock提供的内存信息,构建struct page数组和空闲页链表; - 伙伴系统将
memblock管理的可用内存全部接管,此后内核使用__get_free_pages()/kmalloc()等接口分配内存; memblock退化为只读状态 ,仅用于查询物理内存分布(如/proc/iomem的数据来源)。
memblock关键点
memblock是内核探测和记录物理内存分布的第一个工具 ,/proc/iomem的输出数据直接来自memblock存储的内存区域信息;- 内核建立
PAGE_OFFSET线性映射的页表内存 ,是通过memblock_alloc()分配的; memblock管理的是物理地址,而PAGE_OFFSET是虚拟地址的起始边界,二者通过线性映射公式关联:虚拟地址 = PAGE_OFFSET + 物理地址。- 静态大页的预留是在伙伴系统初始化后 进行的,但预留的物理内存区域信息,依赖
memblock提供的物理内存分布数据; - 内核通过
memblock确认哪些物理内存区域是连续且可用的,从而完成大页的预留。