目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
** 选题指导:**
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于图像处理与注意力机制的输电线路绝缘子缺陷智能识别方法
选题意义背景
电力行业作为国民经济的基础产业,其安全稳定运行对社会发展和人民生活至关重要。随着我国电力需求持续增长,输电线路的规模不断扩大,输电线路的安全运维工作面临着前所未有的挑战。绝缘子作为输电线路中最重要的绝缘器件,其性能直接影响着输电线路的安全运行。由于长期暴露在恶劣的自然环境中,绝缘子容易出现老化、破损、污秽等缺陷,这些缺陷如不及时发现和处理,可能导致线路闪络、跳闸等事故,严重影响电力系统的稳定运行。

传统的绝缘子缺陷检测主要依靠人工巡检,这种方式存在效率低、成本高、安全性差等问题。随着无人机技术和计算机视觉技术的发展,基于无人机航拍图像的绝缘子缺陷自动检测技术逐渐成为研究热点。然而,在实际应用中,由于无人机航拍环境复杂多变,拍摄的绝缘子图像常常存在光照不均、背景复杂、目标较小等问题,严重影响了后续缺陷检测的准确性。
深度学习技术在计算机视觉领域取得了突破性进展,特别是目标检测算法如YOLO系列在各种场景中展现出优异的性能。这些技术为解决绝缘子缺陷检测问题提供了新的思路。然而,直接将现有深度学习算法应用于绝缘子缺陷检测仍面临诸多挑战。首先,绝缘子图像质量问题需要解决;其次,绝缘子目标较小且背景复杂,现有算法的检测精度有待提高;最后,实际应用中对检测速度和硬件资源消耗有较高要求
数据集
数据获取
本研究使用的绝缘子数据集主要来源于国家电网公司公开的真实拍摄绝缘子图像。为了构建一个全面、多样化的数据集,研究团队采用了多种方式获取和扩充数据:
-
原始数据集获取:从公开数据库中获取了张真实拍摄的绝缘子图像,这些图像涵盖了不同天气条件、不同光照环境、不同背景下的绝缘子样本。
-
数据扩充方法:由于原始数据集规模有限,为了提高模型的泛化能力和鲁棒性,研究团队采用了以下数据扩充技术:
-
翻转变换:包括水平翻转和垂直翻转,增加数据的多样性
-
缩放变换:对图像进行不同比例的放大和缩小
-
亮度调整:调整图像的亮度值,模拟不同光照条件
-
旋转变换:对图像进行不同角度的旋转
-
对比度调整:调整图像的对比度,增强目标特征
-
数据分割
为了保证模型训练和测试的有效性,研究团队采用了8:2的数据分割,即将6000张图像按照8:2的比例划分为训练集和测试集。具体来说:
-
训练集:4800张图像(包括正常绝缘子图像4704张,缺陷绝缘子图像96张)
-
测试集:1200张图像(包括正常绝缘子图像1176张,缺陷绝缘子图像24张)
这种分割方式确保了训练集和测试集中的类别分布相对一致,避免了模型训练过程中的类别不平衡问题。
数据预处理
在模型训练前,研究团队对数据集进行了以下预处理操作:
-
数据标注:使用Labelimg软件对所有图像进行标注,标注结果默认保存为PASCAL VOC格式的xml文件。标注时,研究人员仔细区分了绝缘子本体和绝缘子缺陷,并使用矩形框进行精确定位。
-
格式转换:为了适用于YOLOvs算法的训练,研究团队编写了Python脚本将xml格式的标注文件转换为txt格式。转换后的txt文件每行包含一个目标的类别信息和边界框坐标。
-
数据增强:除了上述离线数据扩充外,研究团队还在模型训练过程中使用了YOLOv5s自带的Mosaic数据增强技术。该技术通过随机裁剪、缩放和拼接四张输入图像,生成一张新的训练图像,有效提高了模型对复杂背景和多目标场景的适应能力。
-
数据标准化:对输入图像进行标准化处理,将像素值归一化到0-1之间,加速模型训练的收敛速度。
通过以上数据集的制作和预处理流程,研究团队构建了一个高质量、多样化的绝缘子缺陷检测数据集,为后续的算法改进和模型训练提供了坚实的数据基础。
功能模块介绍
目标检测模块
目标检测模块是系统的核心功能模块,负责对增强后的绝缘子图像进行目标识别和缺陷检测。该模块基于改进的YOLOvs算法,针对绝缘子缺陷检测的特点进行了多项优化。技术思路主要包括三个方面的改进:首先,将网络的主干部分(Backbone)替换为更加轻量化的ShuffleNetV2结构,降低模型大小,提高检测速度;其次,在主干网络的最后一层添加ECA通道注意力机制,增强网络对跨通道重要信息的捕捉能力,提高检测精度;最后,将网络的特征融合部分(Neck)由PANet结构改进为BiFPN结构,增强网络的特征融合能力,特别是对小目标的检测能力。模块的具体流程如下:首先,输入增强后的绝缘子图像,经过Backbone部分提取特征;然后,特征经过ECA注意力机制的处理,突出重要特征,抑制无关信息;接着,特征通过BiFPN结构进行多尺度融合,充分利用不同层级的特征信息;最后,经过Output部分生成检测结果,包括目标类别、置信度和边界框坐标。
实时检测系统模块
实时检测系统模块将前面两个模块集成并部署到嵌入式平台上,以实现绝缘子缺陷的实时检测。该模块主要包括硬件平台选择、环境配置、模型移植优化和人机交互界面设计等部分。技术思路方面,首先对比分析树莓派B和Jetson TX2两种嵌入式平台的性能特点,最终选择了更适合深度学习模型部署的Jetson TX2。接着,对Jetson TX2进行环境配置,安装CUDA、cuDNN和TensorRT等软件,并将经过训练的改进YOLOv5s模型移植到Jetson TX2上,通过TensorRT进行优化加速。最后,基于PyQt5设计了人机交互界面,实现检测结果的可视化展示。
模块的具体流程为:无人机采集的绝缘子图像通过无线传输发送到Jetson TX2平台,随后经过图像增强模块处理以提高质量,然后,增强后的图像输入到经过TensorRT优化的目标检测模型中进行检测,最后检测结果通过人机交互界面实时展示给操作人员。系统实现的功能包括实时图像接收和处理、绝缘子目标和缺陷的自动检测、检测结果的实时可视化展示、检测参数(如IoU阈值、置信度阈值等)的实时调整,以及检测结果的保存和回放。人机交互界面操作简单直观,能够清晰展示检测结果,便于操作人员实时监控和分析。
算法理论
Retinex图像增强算法理论
Retinex理论是基于人类视觉系统的图像增强理论,其核心思想是将图像分解为照明分量和反射分量,其中反射分量包含了图像的真实信息,而照明分量主要影响图像的亮度。通过处理照明分量,可以有效改善图像的对比度和细节表现。传统的Retinex算法主要包括三种实现方式:单尺度Retinex(SSR)、多尺度Retinex(MSR)和带颜色恢复的多尺度Retinex(MSRCR)。SSR算法使用单一尺度的高斯滤波器提取照明分量,计算简单但容易产生光晕效应;MSR算法使用多个不同尺度的高斯滤波器,在一定程度上改善了SSR的问题,但计算复杂度增加;MSRCR算法在MSR的基础上增加了颜色恢复步骤,更好地保持了图像的色彩一致性。
本研究中改进的Retinex算法针对绝缘子图像的特点进行了多项优化。首先,引入了反馈因子β来补偿反射分量数据丢失,通过调整β值可以有效控制增强的程度,避免过度增强。其次,采用分块处理策略,将图像分为多个小块,对每个小块自适应选择β值,更好地适应不同区域的光照变化。此外,结合Canny边缘检测算子来提高绝缘子与环境的辨识度,使增强后的图像中绝缘子目标更加突出。
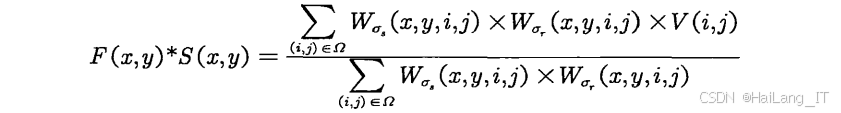
在细节分量处理方面,采用了区域自适应直方图均衡化算法,并引入亮度值影响因子ε和均衡因子α来调节增强效果。对于低亮度图像,还结合伽马校正进一步提升亮度,使图像细节更加清晰可见。
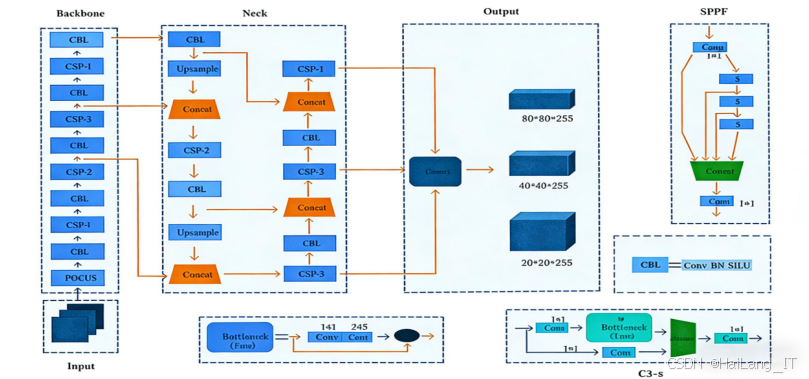
YOLOv5s目标检测算法理论
YOLOv5s是YOLO系列目标检测算法中的轻量级模型,具有检测速度快、精度较高的特点。其网络结构主要包括Input、Backbone、Neck和Output四个部分:
-
Input部分负责图像的预处理和数据增强,包括图像缩放、归一化和Mosaic数据增强等操作。Backbone部分是特征提取网络,由CSP模块、Focus模块、CBL模块和SPPF模块组成。其中,Focus模块通过切片操作将输入图像的通道数扩大4倍,增强特征提取能力;CBL模块由卷积层、批量归一化层和激活函数组成,用于特征提取和降维;C3模块是跨阶段局部网络,用于减少模型参数和计算量;SPPF模块是在SPP的基础上改进的空间金字塔池化模块,用于多尺度特征融合。
-
Neck部分采用PANet结构,由FPN和PAN组成,用于特征融合。FPN部分自上而下传递高层特征,PAN部分自下而上传递底层特征,两者结合可以充分利用不同层级的特征信息。Output部分负责生成检测结果,包括目标类别、置信度和边界框坐标。
TensorRT优化理论
TensorRT是NVIDIA推出的深度学习推理优化引擎,主要用于降低模型大小、提高推理速度。其优化原理主要包括以下几个方面:
-
精度优化:将位浮点数(FP32)转换为16位浮点数(FP16)或8位整数(INT8),在保证检测精度的前提下,减少模型大小和计算量。
-
层融合:将多个相邻的网络层融合为一个层,减少内存访问次数和 kernel 启动次数,提高计算效率。
-
内核自动调优:根据目标硬件平台的特点,自动选择最优的算法和参数,优化计算性能。
-
动态张量内存:智能管理内存使用,减少内存占用和数据传输开销。
-
多流执行 :支持多流并行处理,充分利用GPU的并行计算能力。
在本研究中,主要使用了TensorRT的精度优化和层融合功能,将训练好的改进YOLOv5s模型转换为TensorRT格式,并使用FP16精度进行推理,大幅提高了模型在Jetson TX2平台上的运行速度。
核心代码
改进Retinex图像增强算法代码
改进的Retinex图像增强算法,针对绝缘子图像的特点进行了多项优化。首先,代码将输入图像转换为浮点数并归一化,然后使用双边滤波器提取照明分量。接着,采用分块处理策略,将图像分成8×8的小块,对每个小块计算Canny边缘检测,根据边缘比例自适应调整beta值。这种自适应调整方式可以根据图像不同区域的特点选择合适的增强参数,有效避免光晕效应和过度增强问题。代码中还实现了边界缓冲处理机制,对块之间的过渡区域进行加权平均,避免块效应。最后,通过自适应直方图均衡化和伽马校正进一步增强图像对比度和亮度,使绝缘子目标特征更加明显。
python
def improved_retinex(image, beta=0.5, block_size=8, buffer_size=1):
# 转换为浮点数并归一化
img_float = np.float32(image) / 255.0
# 提取照明分量(使用双边滤波器)
sigma_color = 0.1
sigma_space = 5
illumination = cv2.bilateralFilter(img_float, 9, sigma_color, sigma_space)
# 分块处理
h, w = img_float.shape[:2]
result = np.zeros_like(img_float)
# 计算每个块的大小
block_h = h // block_size
block_w = w // block_size
for i in range(block_size):
for j in range(block_size):
# 计算块的边界
h_start = i * block_h
h_end = min((i + 1) * block_h, h)
w_start = j * block_w
w_end = min((j + 1) * block_w, w)
# 提取块区域
img_block = img_float[h_start:h_end, w_start:w_end]
illu_block = illumination[h_start:h_end, w_start:w_end]
# 计算Canny边缘检测
gray_block = cv2.cvtColor(img_block, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny((gray_block * 255).astype(np.uint8), 50, 150)
edge_ratio = np.sum(edges > 0) / (edges.shape[0] * edges.shape[1])
# 自适应调整beta值
adaptive_beta = beta * (1 + edge_ratio * 2)
# 计算反射分量
reflection = np.log1p(img_block) - np.log1p(illu_block + 1e-6)
# 应用反馈机制
enhanced_reflection = reflection * adaptive_beta
# 重建增强后的图像块
enhanced_block = np.expm1(enhanced_reflection) * illu_block
# 处理边界缓冲区域
if i > 0 and i < block_size - 1 and j > 0 and j < block_size - 1:
# 非边界块直接赋值
result[h_start:h_end, w_start:w_end] = enhanced_block
else:
# 边界块使用加权平均处理
if buffer_size > 0:
# 创建掩码
mask = np.ones_like(enhanced_block)
# 处理上下边界
if i == 0:
for k in range(buffer_size):
weight = (k + 1) / (buffer_size + 1)
if h_start + k < h:
mask[k, :] = weight
elif i == block_size - 1:
for k in range(buffer_size):
weight = (buffer_size - k) / (buffer_size + 1)
if h_end - k - 1 >= 0:
mask[-k-1, :] = weight
# 处理左右边界
if j == 0:
for k in range(buffer_size):
weight = (k + 1) / (buffer_size + 1)
if w_start + k < w:
mask[:, k] = weight
elif j == block_size - 1:
for k in range(buffer_size):
weight = (buffer_size - k) / (buffer_size + 1)
if w_end - k - 1 >= 0:
mask[:, -k-1] = weight
# 应用掩码
result[h_start:h_end, w_start:w_end] = enhanced_block * mask
else:
result[h_start:h_end, w_start:w_end] = enhanced_block
# 对比度增强(自适应直方图均衡化)
lab = cv2.cvtColor(np.uint8(result * 255), cv2.COLOR_BGR2LAB)
l, a, b = cv2.split(lab)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))
cl = clahe.apply(l)
limg = cv2.merge((cl, a, b))
result = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR) / 255.0
# 伽马校正
gamma = 0.8
result = np.power(result, gamma)
# 归一化到0-255
result = np.clip(result * 255, 0, 255).astype(np.uint8)
return result改进YOLOv5s模型定义代码
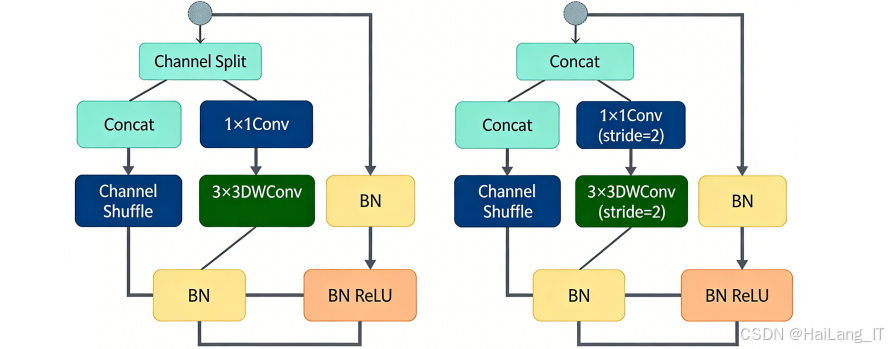
改进YOLOv5s模型的核心组件,包括ECA注意力机制、ShuffleNetV2基本模块和BiFPN特征融合模块。ECA注意力机制通过全局平均池化和1D卷积实现通道注意力,能够自适应地为不同通道分配权重,增强网络对重要特征的关注度。与传统的注意力机制相比,ECA注意力机制参数量更少,计算效率更高。ShuffleNetV2基本模块是一个轻量级的特征提取模块,通过通道切分和通道混洗操作降低计算复杂度。该模块将输入特征图分为两部分,一部分直接通过,另一部分经过一系列卷积操作,最后将两部分拼接并进行通道混洗。这种设计在保持精度的同时大幅降低了模型的参数量和计算量。BiFPN特征融合模块是一个高效的多尺度特征融合模块,通过添加跨尺度连接和加权融合,增强了特征融合能力。该模块实现了自上而下和自下而上的特征融合路径,并在融合过程中引入可学习的权重参数,使网络能够自动学习不同尺度特征的重要性。
python
import torch
import torch.nn as nn
# ECA注意力机制类
class ECA(nnModule):
def __init__(self, c1, k_size=3):
super(ECA, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=k_size, padding=(k_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 全局平均池化
y = self.avg_pool(x)
# 1D卷积
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
# Sigmoid激活
y = self.sigmoid(y)
# 乘法融合
return x * y.expand_as(x)
# ShuffleNetV的基本模块
class ShuffleV2Block(nn.Module):
def __init__(self, inp, oup, mid_channels, kernel_size, stride):
super(ShuffleV2Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.branch_main = [
# 1x1卷积
nn.Conv2d(inp // 2, mid_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# 3x3深度卷积
nn.Conv2d(mid_channels, mid_channels, kernel_size=kernel_size, stride=stride, padding=kernel_size//2, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
# 1x1卷积
nn.Conv2d(mid_channels, oup - inp // 2, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(oup - inp // 2),
nn.ReLU(inplace=True),
]
self.branch_main = nn.Sequential(*self.branch_main)
if stride == 2:
self.branch_proj = [
# 3x3平均池化
nn.AvgPool2d(kernel_size=3, stride=2, padding=1),
]
self.branch_proj = nn.Sequential(*self.branch_proj)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch_main(x2)), dim=1)
else:
out = torch.cat((self.branch_proj(x), self.branch_main(x)), dim=1)
# 通道混洗
out = self.channel_shuffle(out, 2)
return out
def channel_shuffle(self, x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
x = x.view(batchsize, groups, channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
return x
# BiFPN特征融合模块
class BiFPN(nnModule):
def __init__(self, channels, epsilon=1e-4):
super(BiFPN, self).__init__()
self.epsilon = epsilon
# 定义权重参数
self.w1 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.w2 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
self.w3 = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.w4 = nn.Parameter(torch.ones(3, dtype=torch.float32), requires_grad=True)
# 上采样和下采样操作
self.upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.downsample = nn.MaxPool2d(kernel_size=2, stride=2)
# 卷积层用于特征处理
self.conv1 = nn.Conv2d(channels, channels, kernel_size=1, stride=1, bias=False)
self.conv2 = nn.Conv2d(channels, channels, kernel_size=1, stride=1, bias=False)
self.conv3 = nn.Conv2d(channels, channels, kernel_size=1, stride=1, bias=False)
self.conv4 = nn.Conv2d(channels, channels, kernel_size=1, stride=1, bias=False)
# 批归一化和激活函数
self.bn1 = nn.BatchNorm2d(channels)
self.bn2 = nn.BatchNorm2d(channels)
self.bn3 = nn.BatchNorm2d(channels)
self.bn4 = nn.BatchNorm2d(channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, inputs):
# inputs[0]: P3, inputs[1]: P4, inputs[2]: P5
P3, P4, P5 = inputs
# 自上而下的特征融合
# 计算权重
w1 = self.w1 / (torch.sum(self.w1, dim=0) + self.epsilon)
w2 = self.w2 / (torch.sum(self.w2, dim=0) + self.epsilon)
# P5 -> P4
P5_upsampled = self.upsample(P5)
P4_mid = w1[0] * P4 + w1[1] * P5_upsampled
P4_mid = self.relu(self.bn1(self.conv1(P4_mid)))
# P4_mid -> P3
P4_mid_upsampled = self.upsample(P4_mid)
P3_out = w2[0] * P3 + w2[1] * P4_mid_upsampled + w2[2] * P3 # 增加直接连接
P3_out = self.relu(self.bn2(self.conv2(P3_out)))
# 自下而上的特征融合
# 计算权重
w3 = self.w3 / (torch.sum(self.w3, dim=0) + self.epsilon)
w4 = self.w4 / (torch.sum(self.w4, dim=0) + self.epsilon)
# P3_out -> P4
P3_out_downsampled = self.downsample(P3_out)
P4_out = w3[0] * P4_mid + w3[1] * P3_out_downsampled + w3[0] * P4 # 增加直接连接
P4_out = self.relu(self.bn3(self.conv3(P4_out)))
# P4_out -> P5
P4_out_downsampled = self.downsample(P4_out)
P5_out = w4[0] * P5 + w4[1] * P4_out_downsampled + w4[2] * P5 # 增加直接连接
P5_out = self.relu(self.bn4(self.conv4(P5_out)))
return [P3_out, P4_out, P5_out]
# 改进的YOLOvs模型(只展示主要组件)
def build_improved_yolov5s():
# 这里只展示模型的主要组件定义,完整实现需要结合YOLOv5的其他模块
# 使用ShuffleNetV2作为Backbone
# 在Backbone最后添加ECA注意力机制
# 使用BiFPN作为Neck部分
passTensorRT模型优化和推理代码
基于TensorRT的模型优化和推理功能,主要用于将训练好的PyTorch模型转换为TensorRT格式,并进行高效推理。定义了一个TensorRTInfer类,包含模型加载、配置、优化和推理等功能。在初始化方法中,代码从ONNX文件加载模型,配置TensorRT构建器,设置精度模式(支持FP16和INT8),然后构建并序列化引擎。preprocess方法负责对输入图像进行预处理,包括调整大小、格式转换、归一化和维度调整等操作,使其符合模型的输入要求。infer方法是核心的推理函数,它通过CUDA将数据从主机内存复制到设备内存,执行异步推理,然后将结果从设备内存复制回主机内存。postprocess方法负责对推理结果进行后处理,包括过滤低置信度检测框、执行非极大值抑制(NMS),以及将边界框坐标映射回原始图像尺寸。最后,do_inference方法整合了预处理、推理和后处理的完整流程,提供了一个简单的接口供外部调用。通过TensorRT的优化,该代码可以显著提高模型的推理速度,减少内存占用,使模型能够在嵌入式平台上高效运行,满足实时检测的要求。
python
import tensorrt as trt
import numpy as np
import cv2
import pycuda.driver as cuda
import pycuda.autoinit
class TensorRTInfer:
def __init__(self, onnx_file_path, precision_mode='fp16'):
self.logger = trt.Logger(trt.Logger.WARNING)
self.builder = trt.Builder(self.logger)
self.network = self.builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
self.parser = trt.OnnxParser(self.network, self.logger)
# 读取ONNX文件
with open(onnx_file_path, 'rb') as model:
if not self.parser.parse(model.read()):
for error in range(self.parser.num_errors):
print(self.parser.get_error(error))
raise RuntimeError("Failed to parse ONNX file")
# 配置构建器
self.config = self.builder.create_builder_config()
self.config.max_workspace_size = 1 << 30 # 1GB
# 设置精度模式
if precision_mode == 'fp16' and self.builder.platform_has_fast_fp16:
self.config.set_flag(trt.BuilderFlag.FP16)
elif precision_mode == 'int8' and self.builder.platform_has_fast_int8:
self.config.set_flag(trt.BuilderFlag.INT8)
# 需要提供校准数据
# 构建引擎
self.serialized_engine = self.builder.build_serialized_network(self.network, self.config)
self.runtime = trt.Runtime(self.logger)
self.engine = self.runtime.deserialize_cuda_engine(self.serialized_engine)
self.context = self.engine.create_execution_context()
# 获取输入输出信息
self.inputs = []
self.outputs = []
self.bindings = []
self.stream = cuda.Stream()
for binding in range(self.engine.num_bindings):
size = trt.volume(self.engine.get_binding_shape(binding)) * self.engine.max_batch_size
dtype = trt.nptype(self.engine.get_binding_dtype(binding))
# 分配主机和设备内存
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
self.bindings.append(int(device_mem))
if self.engine.binding_is_input(binding):
self.inputs.append({'host': host_mem, 'device': device_mem})
else:
self.outputs.append({'host': host_mem, 'device': device_mem})
def preprocess(self, image, input_shape):
# 调整图像大小
img = cv2.resize(image, (input_shape[1], input_shape[0]))
# 转换为RGB格式
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 归一化
img = img.astype(np.float32) / 255.0
# 调整维度顺序 (H, W, C) -> (C, H, W)
img = np.transpose(img, (2, 0, 1))
# 添加批次维度
img = np.expand_dims(img, axis=0)
# 复制到输入缓冲区
np.copyto(self.inputs[0]['host'], img.ravel())
def infer(self):
# 将输入数据从主机复制到设备
cuda.memcpy_htod_async(self.inputs[0]['device'], self.inputs[0]['host'], self.stream)
# 执行推理
self.context.execute_async_v2(bindings=self.bindings, stream_handle=self.stream.handle)
# 将输出数据从设备复制到主机
for output in self.outputs:
cuda.memcpy_dtoh_async(output['host'], output['device'], self.stream)
# 同步流
self.stream.synchronize()
# 返回输出
return [output['host'] for output in self.outputs]
def postprocess(self, outputs, input_shape, original_shape, conf_threshold=0.5, nms_threshold=0.45):
# 解析输出结果
# 这里假设输出格式为 [batch_size, num_detections, 7],其中7表示 [x1, y1, x2, y2, conf, class_id, ...]
detections = outputs[0].reshape(-1, 7)
# 过滤低置信度的检测结果
mask = detections[:, 4] > conf_threshold
detections = detections[mask]
if len(detections) == 0:
return []
# 执行非极大值抑制
boxes = detections[:, :4]
scores = detections[:, 4]
class_ids = detections[:, 5]
# 计算NMS
indices = cv2.dnn.NMSBoxes(boxes.tolist(), scores.tolist(), conf_threshold, nms_threshold)
results = []
if len(indices) > 0:
for i in indices.flatten():
# 调整边界框坐标到原始图像尺寸
x1, y1, x2, y2 = boxes[i]
x1 = int(x1 * original_shape[1] / input_shape[1])
y1 = int(y1 * original_shape[0] / input_shape[0])
x2 = int(x2 * original_shape[1] / input_shape[1])
y2 = int(y2 * original_shape[0] / input_shape[0])
results.append({
'box': [x1, y1, x2, y2],
'confidence': float(scores[i]),
'class_id': int(class_ids[i])
})
return results
def do_inference(self, image, conf_threshold=0.5, nms_threshold=0.45):
# 获取输入形状
input_shape = self.engine.get_binding_shape(0)[1:3]
original_shape = image.shape[:2]
# 预处理
self.preprocess(image, input_shape)
# 推理
outputs = self.infer()
# 后处理
results = self.postprocess(outputs, input_shape, original_shape, conf_threshold, nms_threshold)
return results重难点和创新点
研究难点
-
复杂环境下的绝缘子图像质量问题:无人机航拍的绝缘子图像常受到光照不均、背景复杂、目标较小等因素影响,导致图像质量不佳,严重影响后续缺陷检测的准确性。如何有效增强这些复杂环境下的绝缘子图像,是研究的第一个难点。
-
小目标缺陷检测精度问题:绝缘子缺陷通常较小,且与背景对比度低,传统目标检测算法在检测这类小目标时容易出现误检和漏检。如何提高对小目标缺陷的检测精度,是研究的第二个难点。
-
模型轻量化与实时性要求:实际应用中,缺陷检测系统需要在计算资源有限的嵌入式平台上实时运行。如何在保证检测精度的同时,实现模型的轻量化和高效推理,是研究的第三个难点。
-
嵌入式平台的部署优化:将深度学习模型部署到嵌入式平台涉及环境配置、模型转换、性能优化等多个方面,需要解决各种兼容性问题和性能瓶颈。如何优化模型在嵌入式平台上的运行性能,是研究的第四个难点。
创新点
-
改进的Retinex图像增强算法:针对传统Retinex算法在处理绝缘子图像时存在的光晕效应和过度增强问题,提出了一种局部自适应的分块光照补偿图像增强算法。该算法通过引入反馈因子β补偿反射分量数据丢失,采用分块处理策略自适应选择β值,并结合Canny边缘检测算子提高绝缘子与环境的辨识度。
-
基于ShuffleNetV的轻量化主干网络:为了解决模型轻量化问题,将YOLOv5s的Backbone部分替换为更加轻量化的ShuffleNetV2结构。ShuffleNetV2通过通道切分和通道混洗操作,在保持精度的同时大幅降低了模型的参数量和计算复杂度。
-
ECA注意力机制的引入:为了提高网络对重要特征的关注度,在Backbone的最后一层添加了ECA通道注意力机制。ECA注意力机制通过局部跨通道交互,自适应地为不同通道分配权重,能够有效增强网络对绝缘子缺陷特征的捕捉能力。
-
BiFPN特征融合结构的应用:为了增强网络的特征融合能力,特别是对小目标的检测能力,将YOLOv5s的Neck部分从PANet结构改进为BiFPN结构。BiFPN通过添加跨尺度连接和加权融合,增强了不同尺度特征之间的信息交互,提高了网络对小目标的检测能力。
-
TensorRT优化加速:为了进一步提高模型在嵌入式平台上的推理速度,使用TensorRT对模型进行了优化加速。通过精度优化和层融合等技术,将模型的推理速度从55FPS提高到92FPS,完全满足实时检测的要求。
参考文献
1 Wang Q, Wu B, Zhu P, et al. ECA-Net: Efficient channel attention for deep convolutional neural networksC//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 11534-11542.
2 Zhang Z, Lv G, Zhao G, et al. BSYOLOv5s: Insulator Defect Detection with Attention Mechanism and Multi-Scale FusionC//2023 IEEE International Conference on Image Processing (ICIP). IEEE, 2023: 2365-2369.
3 Wu W, Weng J, Zhang P, et al. URetinexNet: Retinex-based deep unfolding network for low-light image enhancementC//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022: 5901-5910.
4 Du F J, Jiao S J. Improvement of lightweight convolutional neural network model based on YOLO algorithm and its research in pavement defect detectionJ. Sensors, 2022, 22(9): 3537.
5 Terven J, Cordova-Esparza D M, Romero-Gonzalez J A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolochinanasJ. Machine Learning and Knowledge Extraction, 2023, 5(4): 1680-1716.
6 Wang C, Wang Q, Qian Y, et al. DP-YOLO: Effective Improvement Based on YOLO DetectorJ. Applied Sciences, 2023, 13(21): 11676.
7 Zheng Z, Wang P, Liu W, et al. Distance-IoU loss: Faster and better learning for bounding box regressionC//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(07): 12993-13000.