文章目录
- 简介
- 特点
- 主要功能
- 安装
- 初试
- 大小写
- 注释
- 列出
- [删除库或表 DROP](#删除库或表 DROP)
- [变更表名 ALTER](#变更表名 ALTER)
- 算法运算符
- 比较运算符
- 逻辑运算符
- 聚合函数
- [分组 GROUP BY](#分组 GROUP BY)
- [排序 ORDER BY](#排序 ORDER BY)
- 书写顺序
- [插入数据 INSERT](#插入数据 INSERT)
- [删除数据 DELETE](#删除数据 DELETE)
- [更新数据 UPDATE](#更新数据 UPDATE)
- 事务
- [ACID 特性](#ACID 特性)
- 视图
- 子查询
- 标量子查询
- 关联子查询
- 函数
- 谓词
- CASE表达式
- 集合运算
-
- [并集 UNION](#并集 UNION)
- [交集 INTERSECT](#交集 INTERSECT)
- 差集EXCEPT
- 联结
-
- [内联结 INNER JOIN](#内联结 INNER JOIN)
- [外联结 OUTER JOIN](#外联结 OUTER JOIN)
- 窗口函数
- 分组运算符
- [Python 驱动](#Python 驱动)
- [pgAdmin 4 设置](#pgAdmin 4 设置)
- [与 MySQL 的区别(https://xercis.blog.csdn.net/article/details/157068532)](#与 MySQL 的区别)
- [WSL 连接 Windows 的 PostgreSQL(https://juejin.cn/post/7431197219666575423)](#WSL 连接 Windows 的 PostgreSQL)
- 从MySQL迁移到PostgreSQL
- 为什么MySQL会丢数据,PostgreSQL不会丢数据?
- PostGIS
- 插件
- 术语
- 遇到的坑
- 参考文献

简介
PostgreSQL 号称世界上最先进的开源关系型数据库,念作 post-gress-Q-L,简称 Postgres 或 pg
PostgreSQL 源于 1977 年加洲大学伯克利分校的 Ingres 项目,1996 年发布第一个版本,至今已超过 35 年
PostgreSQL已连续两年超过MySQL成为最受欢迎的数据库
使用 PostgreSQL 的公司有:苹果、Instagram、Reddit、IMDb、Skype、NTT、亚马逊、NASA
每年有全球性技术大会,如 Postgres Conference,国内有 PostgreSQL 中国技术大会(至今已举办13届)
特点
- 最接近标准SQL且扩展了功能
- 稳定可靠:数据零丢失
- 开源省钱:基于BSD协议,在使用和二开上没有限制
- 支持广泛:支持大量主流语言,如用Python写存储过程
社区活跃:每三个月推出一个补丁版本,官网首页有BUG提交入口,各种博客 - 强大的功能集,如地理空间数据库扩展 PostGIS
- 支持主流操作系统,Linux、macOS、Windows、BSD、Solaris
主要功能
- 数据类型
- 基本数据类型:Integer, Numeric, String, Boolean
- 结构数据类型:Date/Time, Array, Range / Multirange, UUID
- 文档数据类型:JSON/JSONB, XML, Key-value (Hstore)
- 几何数据类型:Point, Line, Circle, Polygon
- 自定义数据类型:Composite, Custom Types
- 数据完整性
- UNIQUE, NOT NULL
- 主键
- 外键
- 排除约束
- 显式锁、咨询锁
- 并发性、性能
- 索引:B树、多列、表达式、部分
- 高级索引:GiST, SP-Gist, KNN Gist, GIN, BRIN, Covering indexes, Bloom filters
- 复杂的查询规划器/优化器,仅索引扫描,多列统计
- 事务,嵌套事务
- 多版本并发控制(MVCC)
- 读取查询的并行化和B树索引的构建
- 表分区
- SQL标准中定义的所有事务隔离级别,包括序列化
- 表达式即时编译(JIT)
- 可靠性、灾难恢复
- 预写日志(WAL)
- 复制:异步、同步、逻辑
- 时间点恢复 (PITR)、主动待机
- 表空间
- 安全性
- 身份验证:GSSAPI、SSPI、LDAP、SCRAM-SHA-256、证书等
- 强大的访问控制系统
- 列级和行级安全
- 多因素身份验证
- 可扩展性
- 存储函数和过程
- 过程语言:PL/pgSQL、Perl、Python、Tcl。还有其他通过扩展可用的语言,例如 Java、JavaScript (V8)、R、Lua、Rust
- SQL/JSON构造函数、查询函数、路径表达式和 JSON_TABLE
- 外部数据包装器:使用标准SQL接口连接到其他数据库或流
- 可定制的表存储接口
- 更多插件,如 PostGIS
- 国际化,文本搜索
- 支持国际字符集,例如通过 ICU 排序
- 不区分大小写和重音的排序规则
- 全文搜索
安装
- 根据操作系统下载 PostgreSQL,本人使用的版本是 17(2024-09-26 发布)
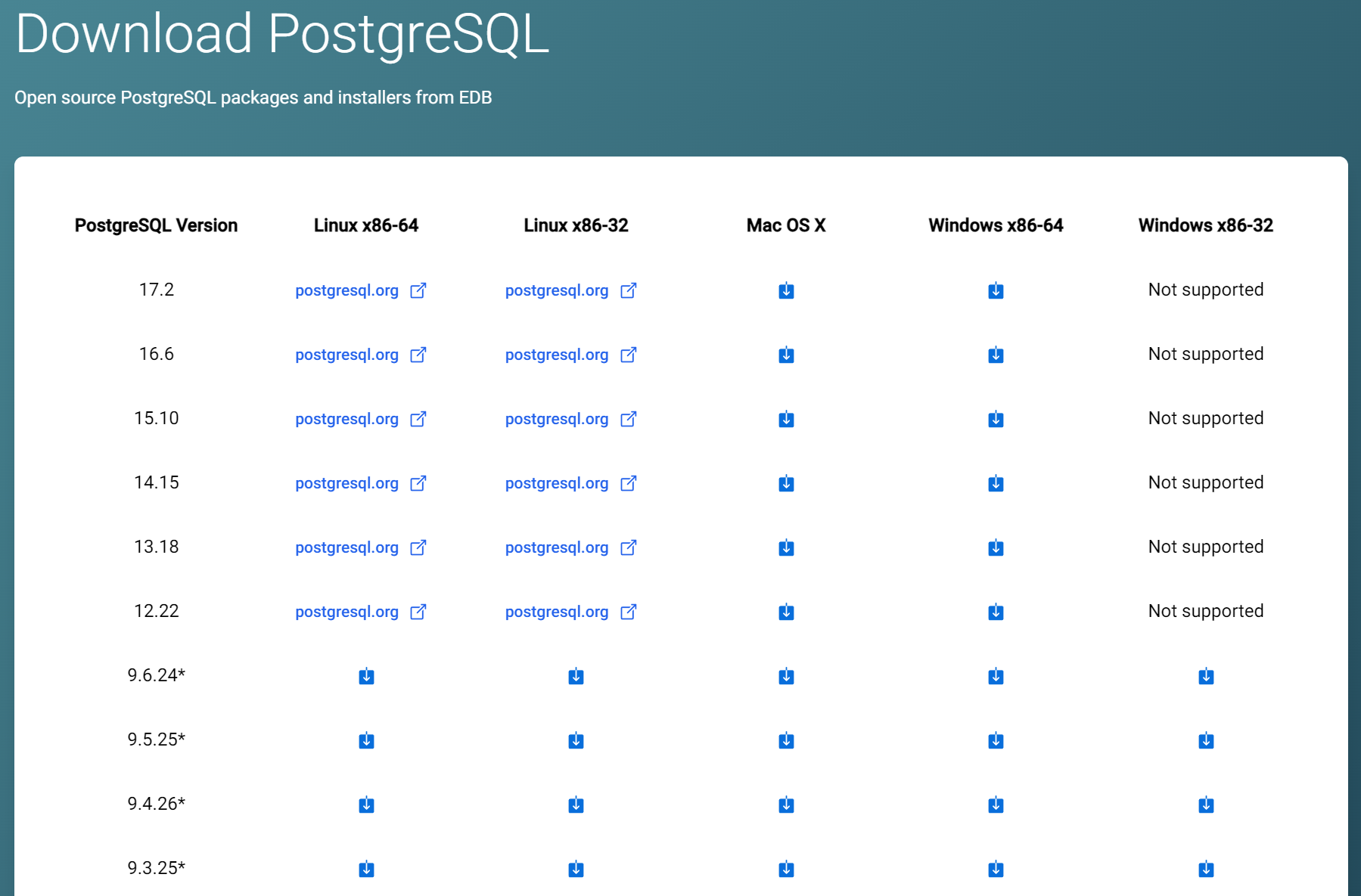
- 选择安装的组件
pgAdmin4:PostgreSQL 的数据库管理软件,类似 Navicat
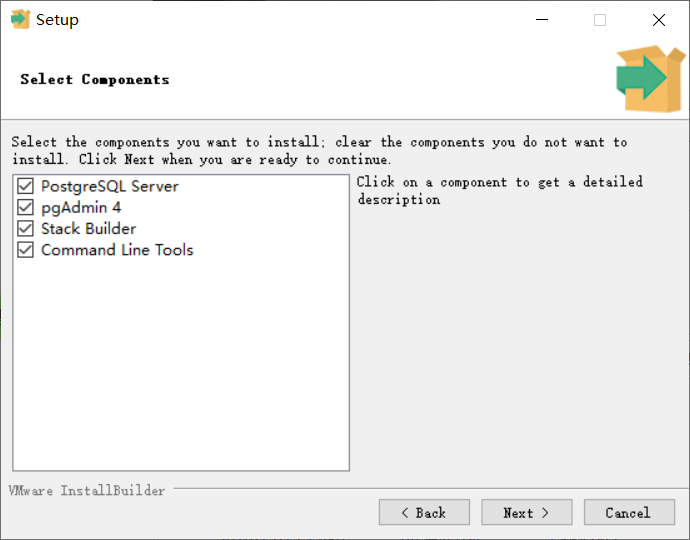
- 设置密码,本地开发可设
123456
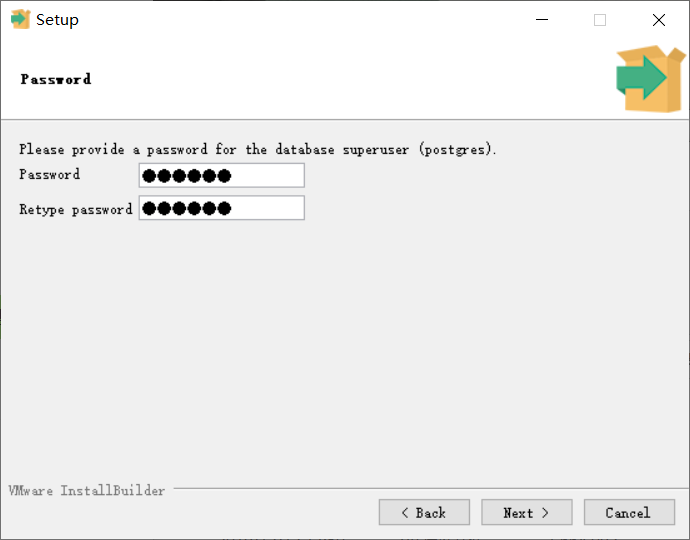
- 端口号默认为
5432
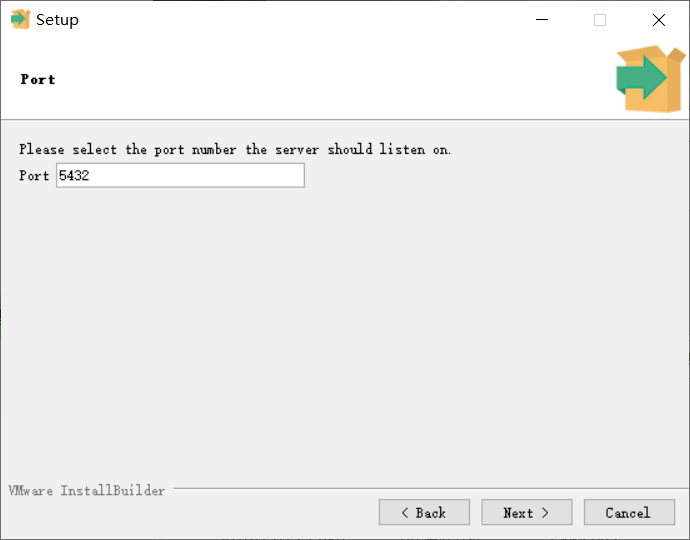
- 取消勾选
Stack Builder 是一个图形化工具,用于简化在 PostgreSQL 安装环境中添加额外功能组件,如地理空间数据库扩展 PostGIS
-
配置环境变量 Path:
C:\Program Files\PostgreSQL\17\bin -
命令行
psql -d postgres -U postgres,-d 指定数据库,-U 指定用户名
-
打开 SQL Shell (psql)
-
打开 pgAmin 4 → Servers → PostgreSQL 17
初试
进入 SQL Shell (psql)
创建数据库
sql
CREATE DATABASE shop;连接数据库
sql
\c shop;创建表
sql
CREATE TABLE product (
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER,
purchase_price INTEGER,
regist_date date,
PRIMARY KEY (product_id)
);
COMMENT ON COLUMN product.product_id IS '商品编号';
COMMENT ON COLUMN product.product_name IS '商品名称';
COMMENT ON COLUMN product.product_type IS '商品种类';
COMMENT ON COLUMN product.sale_price IS '销售单价';
COMMENT ON COLUMN product.purchase_price IS '进货单价';
COMMENT ON COLUMN product.regist_date IS '登记日期';表定义的更新(添加列)
sql
ALTER TABLE product ADD COLUMN product_name_pinyin VARCHAR(100);表定义的更新(删除列)
sql
ALTER TABLE product DROP COLUMN product_name_pinyin;插入数据
sql
BEGIN TRANSACTION;
INSERT INTO product VALUES ('0001', 'T恤' ,'衣服', 1000, 500, '2009-09-20');
INSERT INTO product VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO product VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO product VALUES ('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
INSERT INTO product VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
INSERT INTO product VALUES ('0006', '叉子', '厨房用具', 500, NULL, '2009-09-20');
INSERT INTO product VALUES ('0007', '擦菜板', '厨房用具', 880, 790, '2008-04-28');
INSERT INTO product VALUES ('0008', '圆珠笔', '办公用品', 100, NULL, '2009-11-11');
COMMIT;查询全部列
sql
SELECT * FROM product;查询某些列,设别名
sql
SELECT product_id AS id, product_name AS name, purchase_price AS price FROM product;查询商品种类(删除重复行)
sql
SELECT DISTINCT product_type FROM product;查询商品种类为衣服的商品名称
sql
SELECT product_name, product_type FROM product WHERE product_type='衣服';大小写
- 建库时自动转成小写,除非用双引号
- 建表时自动转成小写,除非用双引号
- 建字段时自动转成小写,除非用双引号
注意:执行SQL要加分号!!!
注释
sql
-- 单行注释
/*多行注释
多行注释
多行注释
多行注释
多行注释
多行注释*/列出
数据库
sql
\l
SELECT datname FROM pg_database;数据表
sql
\dt删除库或表 DROP
数据库
sql
DROP DATABASE test;数据表
sql
DROP TABLE product;变更表名 ALTER
sql
ALTER TABLE poduct RENAME TO product;算法运算符
所有包含 NULL 的计算,结果都是 NULL
sql
SELECT NULL+5;比较运算符
等于 =,不等于 !=
大于 >,小于 <
大于等于 >=,小于等于 <=
2 和 '2' 不一样,字符串类型的比较按照字典顺序
不能对 NULL 使用比较运算符,要用 IS NULL 或 IS NOT NULL
sql
-- 查不出数据
SELECT * FROM product WHERE purchase_price=NULL;
-- 能查到数据
SELECT * FROM product WHERE purchase_price IS NULL;逻辑运算符
与:AND
或:OR
非:NOT
AND 优先于 OR,可使用括号提高优先级
聚合函数
统计:COUNT
求和:SUM
平均值:AVG
最大值:MAX
最小值:MIN
sql
-- 全部行数
SELECT COUNT(*) FROM product;
-- 进货单价的非空行数
SELECT COUNT(purchase_price) FROM product;
-- 产品种类数
SELECT COUNT(DISTINCT product_type) FROM product;
-- 销售单价的求和
SELECT SUM(sale_price) FROM product;
-- 销售单价的平均值
SELECT AVG(sale_price) FROM product;
-- 销售单价的最大值
SELECT MAX(sale_price) FROM product;
-- 销售单价的最小值
SELECT MIN(sale_price) FROM product;分组 GROUP BY
GROUP BY,要写在 FROM 和 WHERE 之后
对分组后的结果指定条件用 HAVING,要写在 GROUP BY 之后
sql
-- 不同产品种类的数量
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type;
-- 产品数为2的产品种类
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type
HAVING COUNT(*)=2;GROUP BY 常见错误
- 在 SELECT 中写了非分组列的列
- 使用了列的别名
- 在 WHERE 子句中使用聚合函数,应该在 HAVING 中使用
WHERE 的执行速度比 HAVING 快
排序 ORDER BY
ORDER BY
升序:ASC(默认)
降序:DESC
排序键中包含 NULL 时,会在末尾汇总
sql
-- 按销售单价从低到高排(升序)
SELECT * FROM product ORDER BY sale_price;
-- 按销售单价从高到低排(降序)
SELECT * FROM product ORDER BY sale_price DESC;
-- 按销售单价和商品编号从低到高排(升序)
SELECT * FROM product ORDER BY sale_price, product_id;
-- NULL会在末尾汇总
SELECT * FROM product ORDER BY purchase_price;书写顺序
查询:SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY
插入数据 INSERT
sql
-- 建表
CREATE TABLE productins (
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER DEFAULT 0,
purchase_price INTEGER,
regist_date date,
PRIMARY KEY (product_id)
);
sql
-- 使用列清单
INSERT INTO productins (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
-- 使用值清单,需要保证列数一致
INSERT INTO productins VALUES ('0005', '高压锅', '厨房用具', 6800, 5000, '2009-01-15');
-- 插入多行
INSERT INTO productins VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11'),
('0003', '运动T恤', '衣服', 4000, 2800, NULL),
('0004', '菜刀', '厨房用具', 3000, 2800, '2009-09-20');
-- 显式插入默认值DEFAULT
INSERT INTO productins (product_id, product_name, product_type, sale_price, purchase_price, regist_date) VALUES ('0007', '擦菜板', '厨房用具', DEFAULT, 790, '2009-04-28');
-- 隐式插入默认值
INSERT INTO productins (product_id, product_name, product_type, purchase_price, regist_date) VALUES ('0007', '擦菜板', '厨房用具', 790, '2009-04-28');从其他表中复制数据
sql
CREATE TABLE productcopy (
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER,
purchase_price INTEGER,
regist_date date,
PRIMARY KEY (product_id)
);
-- 将商品表中的数据复制到复制商品表中
INSERT INTO productcopy (product_id, product_name, product_type, sale_price, purchase_price, regist_date)
SELECT product_id, product_name, product_type, sale_price, purchase_price, regist_date
FROM product;
-- 确认复制行
SELECT * FROM ProductCopy;删除数据 DELETE
sql
-- 清空表(表还在)
DELETE FROM product;
-- 删除销售单价大于4000的数据
DELETE FROM product
WHERE sale_price>4000;TRUNCATE 可以快速清空表中所有数据,但无法做过滤
更新数据 UPDATE
sql
-- 将登记日期全部更新为2019-10-10
UPDATE product
SET regist_date='2009-10-10';
-- 将厨房用具的销售单价更新为原来的10倍
UPDATE product
SET sale_price=sale_price*10
WHERE product_type='厨房用具';
-- 多列更新
UPDATE product
SET sale_price=sale_price*10,
purchase_price=purchase_price/2
WHERE product_type='厨房用具';事务
- 事务(transaction)是需要在同一个处理单元中执行的一系列更新处理的集合。
- 通过事务,可以对数据库中的数据更新处理的提交和取消进行管理。
- 事务处理的终止命令有提交
COMMIT和回滚ROLLBACK - DBMS 的事务具有原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),统称 ACID。
sql
BEGIN transaction;
-- 运动T恤的销售单价下调1000
UPDATE product
SET sale_price=sale_price-1000
WHERE product_name='运动T恤';
-- T恤的销售单价上浮1000日元
UPDATE product
SET sale_price=sale_price+1000
WHERE product_name='T恤';
-- 查看更新后的结果
SELECT * FROM product WHERE product_name='运动T恤';
SELECT * FROM product WHERE product_name='T恤';
-- 失败则回滚事务,撤销更新操作
ROLLBACK;
-- 成功则提交事务,使更新永久生效
COMMIT;ACID 特性
- 原子性(Atomicity)
要么全部执行,要么全部不执行。如,事务会保证运动T恤价格下降,T恤的价格也下降。 - 一致性(Consistency)
处理满足数据库约束。如,设置了NOT NULL的列不会被更新为NULL。 - 隔离性(Isolation)
不同事务之间互不干扰。 - 持久性(Durability)
事务结束后,数据状态会被保存。
视图
- 表保存的是实际的数据,视图保存的是 SELECT 语句(视图本身不保存数据)
- 可以将常用的 SELECT 语句做成视图使用
- 尽量避免在视图的基础上创建视图,因为多重视图会降低 SQL 性能,最好使用单一视图
- 视图不能使用
ORDER BY
sql
-- 创建视图
CREATE VIEW productsum (product_type, cnt_product) AS
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type;
sql
-- 使用视图
SELECT product_type, cnt_product FROM productsum;
sql
-- 删除视图
DROP VIEW productsum;
-- 删除关联视图
DROP VIEW productsum CASCADE;子查询
- 子查询可以理解为一次性视图
- 子查询需要命名
- 尽量避免使用多层嵌套的子查询
sql
CREATE VIEW productsum (product_type, cnt_product) AS
SELECT product_type, COUNT(*)
FROM product
GROUP BY product_type;
SELECT product_type, cnt_product FROM productsum;
-- 两种方法效果相同
SELECT product_type, cnt_product
FROM (SELECT product_type, COUNT(*) AS cnt_product
FROM product
GROUP BY product_type) AS productsum标量子查询
标量子查询只返回某个值
sql
-- 报错
SELECT * FROM product
WHERE sale_price > AVG(sale_price);
-- 查询销售单价高于均值的产品
SELECT * FROM product
WHERE sale_price > (SELECT AVG(sale_price) FROM product);关联子查询
- 关联子查询在细分的组内进行比较时使用
- 关联子查询和
GROUP BY子句一样,可以对表中的数据进行切分 - 关联子查询的结合条件如果未出现在子查询之中会发生错误
- 结合条件一定要写在子查询中
按商品种类分组,并查询大于其种类平均销售单价的商品
sql
SELECT * FROM product AS p1
WHERE
sale_price>(
SELECT AVG(sale_price)
FROM product AS p2
WHERE p1.product_type=p2.product_type
GROUP BY product_type
);函数
| 算术函数 | 功能 |
|---|---|
ABS |
绝对值 |
MOD |
求余 |
ROUND |
四舍五入 |
sql
SELECT ABS(-100);
-- 100
SELECT MOD(7, 3);
-- 1
SELECT ROUND(5.555, 2);
-- 5.56| 字符串函数 | 功能 |
|---|---|
| ` | |
LENGTH |
字符串长度 |
LOWER |
小写转换 |
UPPER |
大写转换 |
REPLACE |
字符串替换 |
SUBSTRING |
字符串截取 |
sql
SELECT 'Hello '||'World'||'!';
-- Hello World!
SELECT LENGTH('Hello');
-- 5
SELECT LOWER('Hello'), UPPER('Hello');
-- hello HELLO
SELECT REPLACE('Hello', 'ell', 'ooo');
-- Hoooo
SELECT SUBSTRING('Hello' FROM 3 FOR 2);
-- ll| 日期函数 | 功能 |
|---|---|
CURRENT_DATE |
当前日期 |
CURRENT_TIME |
当前时间 |
CURRENT_TIMESTAMP |
当前时间和日期 |
EXTRACT |
截取日期元素 |
sql
SELECT CURRENT_DATE;
-- 2025-01-09
SELECT CURRENT_TIME;
-- 17:41:19.841152+08:00
SELECT CURRENT_TIMESTAMP;
-- 2025-01-09 17:41:20.750016+08
SELECT EXTRACT(YEAR FROM CURRENT_TIMESTAMP),
EXTRACT(MONTH FROM CURRENT_TIMESTAMP),
EXTRACT(DAY FROM CURRENT_TIMESTAMP),
EXTRACT(HOUR FROM CURRENT_TIMESTAMP),
EXTRACT(MINUTE FROM CURRENT_TIMESTAMP),
EXTRACT(SECOND FROM CURRENT_TIMESTAMP);
-- 2025 1 9 17 41 20.750016| 转换函数 | 功能 |
|---|---|
CAST |
类型转换 |
COALESCE |
将 NULL 转换为其他值 |
sql
SELECT CAST('0001' AS INTEGER);
-- 1
SELECT CAST('2025-01-09' AS DATE);
-- 2025-01-09
SELECT COALESCE(NULL, 1);
-- 1谓词
LIKE:字符串部分一致- 前方一致
- 中间一致
- 后方一致
%:长度大于等于0的任意字符串_:任意1个字符
以下结果均为 true
sql
-- 前方一致
SELECT 'dddabc' LIKE 'ddd%';
-- 中间一致
SELECT 'abcddd' LIKE '%ddd%',
'dddabc' LIKE '%ddd%',
'abdddc' LIKE '%ddd%';
-- 后方一致
SELECT 'abcddd' LIKE 'ddd%';
-- abc+任意3个字符
SELECT 'abcddd' LIKE 'abc___';BETWEEN:范围查询
sql
-- 销售单价100~1000的商品(包含)
SELECT *
FROM product
WHERE sale_price BETWEEN 100 AND 1000;
-- 销售单价100~1000的商品(不包含)
SELECT *
FROM product
WHERE sale_price>100 AND sale_price<1000;IS NULL、IS NOT NULL:判断是否为 NULL(不能用 =)
sql
SELECT *
FROM product
WHERE purchase_price IS NULL;IN、NOT IN:使用子查询作为其参数
sql
CREATE TABLE shopproduct (
shop_id CHAR(4) NOT NULL,
shop_name VARCHAR(200) NOT NULL,
product_id CHAR(4) NOT NULL,
quantity INTEGER NOT NULL,
PRIMARY KEY (shop_id, product_id)
);
BEGIN TRANSACTION;
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0001', 30);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0002', 50);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000A', '东京', '0003', 15);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0002', 30);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0003', 120);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0004', 20);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0006', 10);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000B', '名古屋', '0007', 40);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0003', 20);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0004', 50);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0006', 90);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000C', '大阪', '0007', 70);
INSERT INTO ShopProduct (shop_id, shop_name, product_id, quantity) VALUES ('000D', '福冈', '0001', 100);
COMMIT;
sql
SELECT *
FROM product
WHERE product_id IN ('0003', '0004', '0006', '0007');
SELECT *
FROM product
WHERE product_id IN (
SELECT product_id
FROM shopproduct
WHERE shop_id='000C'
);EXISTS:较难理解,实际上可以用IN或NOT IN替代
sql
SELECT *
FROM product AS p
WHERE EXISTS (
SELECT *
FROM shopproduct AS sp
WHERE sp.shop_id='000C'
AND sp.product_id=p.product_id
);CASE表达式
- 相当于编程中的条件分支
- CASE 表达式中的 ELSE 可以省略,但为了可读性最好别省略
- CASE 表达式中的 END 不能省略
sql
SELECT product_name,
CASE
WHEN product_type='衣服' THEN 'A:'||product_type
WHEN product_type='办公用品' THEN 'B:'||product_type
WHEN product_type='厨房用具' THEN 'C:'||product_type
ELSE NULL
END AS abc_product_type
FROM product;行、列转换
sql
-- 行的形式
SELECT product_type, SUM(sale_price)
FROM product
GROUP BY product_type;
sql
--列的形式
SELECT
SUM(CASE WHEN product_type='衣服'
THEN sale_price
ELSE 0
END
) AS sum_price_clothes,
SUM(CASE WHEN product_type='办公用品'
THEN sale_price
ELSE 0
END
) AS sum_price_office,
SUM(CASE WHEN product_type='厨房用具'
THEN sale_price
ELSE 0
END
) AS sum_price_kitchen
FROM product;集合运算
- 集合运算以行为单位进行操作
- 集合运算符有:并集
UNION、交集INTERSECT、差集EXCEPT - 集合运算符可以去除重复行
- 保留重复行使用
ALL
数据准备
sql
CREATE TABLE product2 (
product_id CHAR(4) NOT NULL,
product_name VARCHAR(100) NOT NULL,
product_type VARCHAR(32) NOT NULL,
sale_price INTEGER,
purchase_price INTEGER,
regist_date date,
PRIMARY KEY (product_id)
);
BEGIN TRANSACTION;
INSERT INTO product2 VALUES ('0001', 'T恤', '衣服', 1000, 500, '2009-09-20');
INSERT INTO product2 VALUES ('0002', '打孔器', '办公用品', 500, 320, '2009-09-11');
INSERT INTO product2 VALUES ('0003', '运动T恤', '衣服', 4000, 2800, NULL);
INSERT INTO product2 VALUES ('0009', '手套', '衣服', 800, 500, NULL);
INSERT INTO product2 VALUES ('0010', '水壶', '厨房用具', 2000, 1700, '2009-09-20');
COMMIT;并集 UNION
加法运算(并集)
- 列数必须相同
- 类型必须一致(可用
CAST转换类型) ORDER BY只能在最后使用一次
sql
-- 两表相加(去重)
SELECT product_id, product_name
FROM product
UNION
SELECT product_id, product_name
FROM product2
ORDER BY product_id;
-- 两表相加(不去重)
SELECT product_id, product_name
FROM product
UNION ALL
SELECT product_id, product_name
FROM product2
ORDER BY product_id;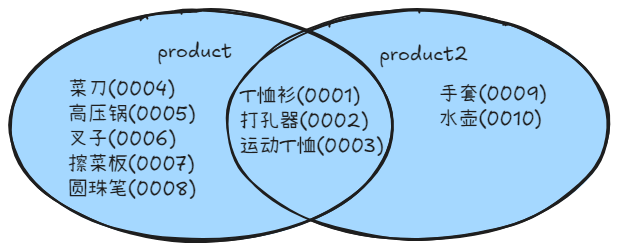
交集 INTERSECT
选取共有的部分
sql
SELECT product_id, product_name
FROM product
INTERSECT
SELECT product_id, product_name
FROM product2
ORDER BY product_id;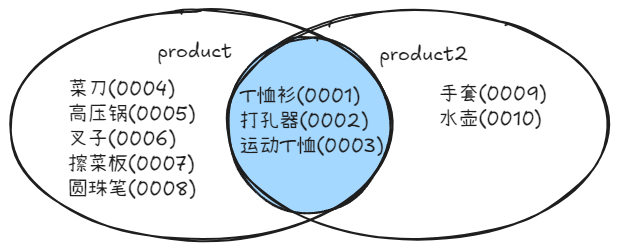
差集EXCEPT
sql
SELECT product_id, product_name
FROM product
EXCEPT
SELECT product_id, product_name
FROM product2
ORDER BY product_id;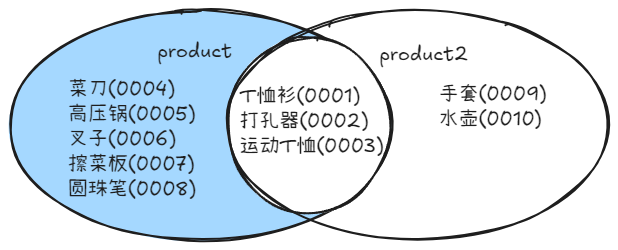
联结
- 以列为单位进行操作
- 内联结
INNER JOIN,最常用,INNER 可以省略 - 外联结
OUTER JOIN - 别名不是必须的
ON必须写在FROM和WHERE之间
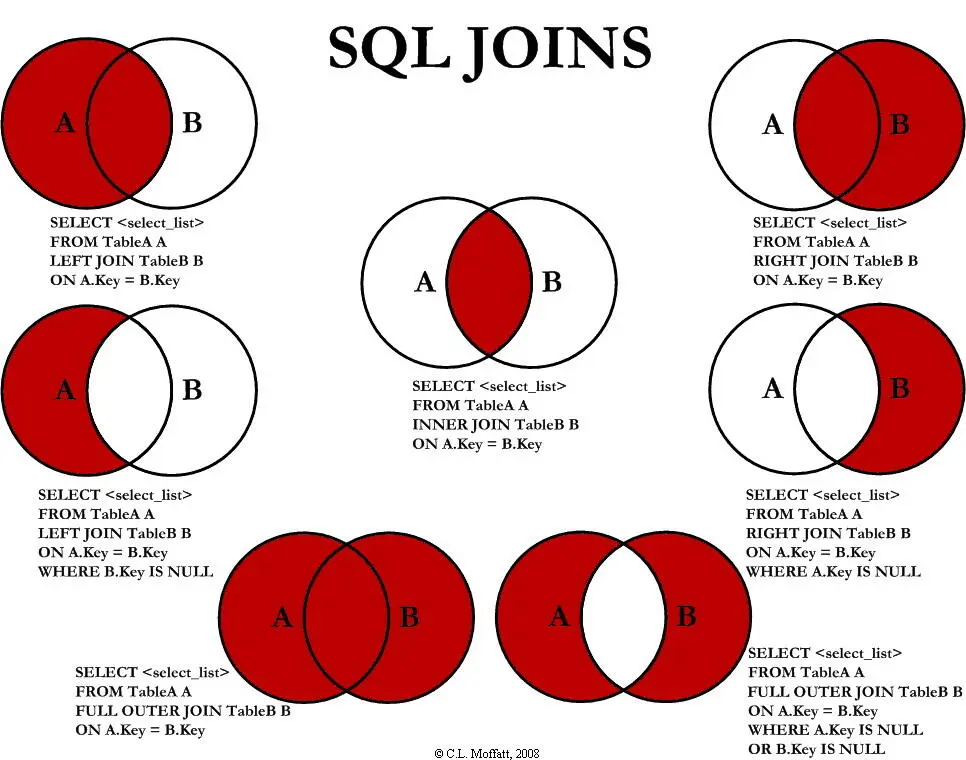
两张表包含的列
| product | shopproduct | |
|---|---|---|
| 商品编号 | ✓ | ✓ |
| 商品名称 | ✓ | |
| 商品种类 | ✓ | |
| 销售单价 | ✓ | |
| 进货单价 | ✓ | |
| 登记日期 | ✓ | |
| 商店编号 | ✓ | |
| 商店名称 | ✓ | |
| 商品数量 | ✓ |
内联结 INNER JOIN
sql
-- 各商店的商品信息
SELECT sp.shop_id, sp.shop_name, sp.product_id,
p.product_name, p.sale_price
FROM shopproduct AS sp
INNER JOIN product AS p
ON sp.product_id=p.product_id;外联结 OUTER JOIN
- 相对于内联结来说,只要数据存在于某一张表中,就能够取出来
- 指定主表的关键字是
LEFT和RIGHT,决定会包含哪一张的全部信息 - 一般用
LEFT比较多
sql
-- 各商店的商品信息(含没商店归属的商品)
SELECT sp.shop_id, sp.shop_name, sp.product_id,
p.product_name, p.sale_price
FROM shopproduct AS sp
RIGHT OUTER JOIN product AS p
ON sp.product_id=p.product_id;窗口函数
窗口函数也叫 OLAP 函数,对数据库数据进行实时分析处理。
PARTITION BY:分组依据
sql
-- 对销售单价从低到高排序
SELECT product_name, product_type, sale_price,
RANK() OVER (ORDER BY sale_price) AS ranking
FROM product;
-- 根据产品种类分组,对销售单价从低到高排序
SELECT product_name, product_type, sale_price,
RANK() OVER (PARTITION BY product_type
ORDER BY sale_price) AS ranking
FROM product;专用窗口函数
RANK:跳过之后的次位,如有3条记录在第1位时,1位、1位、1位、4位......DENSE_RANK:不跳过之后的次位,如有3条记录在第1位时,1位、1位、1位、2位......ROW_NUMBER:唯一的连续次位,如1位、2位、3位、4位
sql
SELECT product_name, product_type, sale_price,
RANK() OVER (ORDER BY sale_price) AS ranking,
DENSE_RANK() OVER (ORDER BY sale_price) AS dense_ranking,
ROW_NUMBER() OVER (ORDER BY sale_price) AS row_num
FROM product;累计
sql
-- 商品编号小于等于自己的销售单价合计值
SELECT product_id, product_name, product_type, sale_price,
SUM(sale_price) OVER (ORDER BY product_id) AS current_sum
FROM product;
-- 商品编号小于等于自己的销售单价平均值
SELECT product_id, product_name, product_type, sale_price,
AVG(sale_price) OVER (ORDER BY product_id) AS current_sum
FROM product;移动平均
ROWS:行PRECEDING:之前FOLLOWING:之后CURRENT ROW:当前行UNBOUNDED FOLLOWING:最后一行
sql
-- 商品编号小于等于自己的最近3个的销售单价平均值
SELECT product_id, product_name, product_type, sale_price,
AVG(sale_price) OVER (ORDER BY product_id
ROWS 2 PRECEDING) AS current_sum
FROM product;
-- 商品编号包含自己最近3个的销售单价平均值
SELECT product_id, product_name, product_type, sale_price,
AVG(sale_price) OVER (ORDER BY product_id
ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS current_sum
FROM product;分组运算符
GROUP BY:按列分组,然后对每个组应用聚合函数GROUP BY ROLLUP():同时得出合计和小计GROUPING:分辨出是分组产生的NULL还是数据本身的NULLCUBE:比ROLLUP更全面的分组,生成所有可能的分组汇总GROUPING SETS:精确指定想要的分组
sql
-- 分别算出合计和各类汇总
SELECT '合计' AS product_type, SUM(sale_price)
FROM product
UNION ALL
SELECT product_type, SUM(sale_price)
FROM product
GROUP BY product_type;更简便的方法
sql
SELECT product_type, SUM(sale_price)
FROM product
GROUP BY rollup (product_type);分别算出合计、商品种类、登记日期的汇总
sql
SELECT product_type, regist_date, SUM(sale_price)
FROM product
GROUP BY rollup (product_type, regist_date)
ORDER BY product_type DESC;会发现衣服的汇总很奇怪,有两条 regist_date 为 NULL 的汇总信息。因为其中一条衣服的 regist_date 是 NULL,无法区分出是汇总后产生的 NULL 还是数据本身是 NULL。
sql
-- 使用GROUPING来区分
SELECT GROUPING(product_type), GROUPING(regist_date), SUM(sale_price)
FROM product
GROUP BY rollup (product_type, regist_date)
ORDER BY product_type DESC;
-- 插入恰当的字符串
SELECT CASE WHEN GROUPING(product_type)=1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date)=1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price)
FROM product
GROUP BY rollup (product_type, regist_date);更全面的分组汇总
sql
SELECT CASE WHEN GROUPING(product_type)=1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date)=1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price)
FROM product
GROUP BY rollup (product_type, regist_date)
ORDER BY GROUPING(product_type), GROUPING(regist_date);更精确的分组汇总
sql
-- 按商品种类和登记日期分组+总计
SELECT product_type, regist_date, SUM(sale_price)
FROM product
GROUP BY GROUPING SETS ((product_type, regist_date), ());Python 驱动
安装
shell
pip install psycopg2代码
python
import psycopg2
conn = psycopg2.connect(database='postgres', user='postgres', password='123456', host='127.0.0.1', port=5432)
cur = conn.cursor()
cur.execute('SELECT * FROM bookings;')
records = cur.fetchall()
print(records)
if 10 not in {i[0] for i in records}:
cur.execute('INSERT INTO bookings (bookid, facid, memid, starttime, slots) VALUES (%s, %s, %s, %s, %s);',
(10, 4, 0, '2012-07-04 16:00:00', 3))
conn.commit()pgAdmin 4 设置
File → Preferences
- Query Tool
- SQL formatting
- Identifier case:Lower case
- 取消勾选 Spaces around operators
- 勾选 Use spaces
- SQL formatting
与 MySQL 的区别
WSL 连接 Windows 的 PostgreSQL
Windows 配置
-
打开【高级安全 Windows Defender 防火墙】
-
入站规则 → 新建规则 → 端口 → 下一页
-
TCP → 填【5432】
-
全部下一步 → 名称填 PostgreSQL
-
修改
C:\Program Files\PostgreSQL\17\data\pg_hba.conf,添加host all all 172.0.0.0/8 scram-sha-256
host all all 192.0.0.0/8 scram-sha-256 -
重启服务 postgresql-x64-17
-
查看主机 IP:
ipconfig
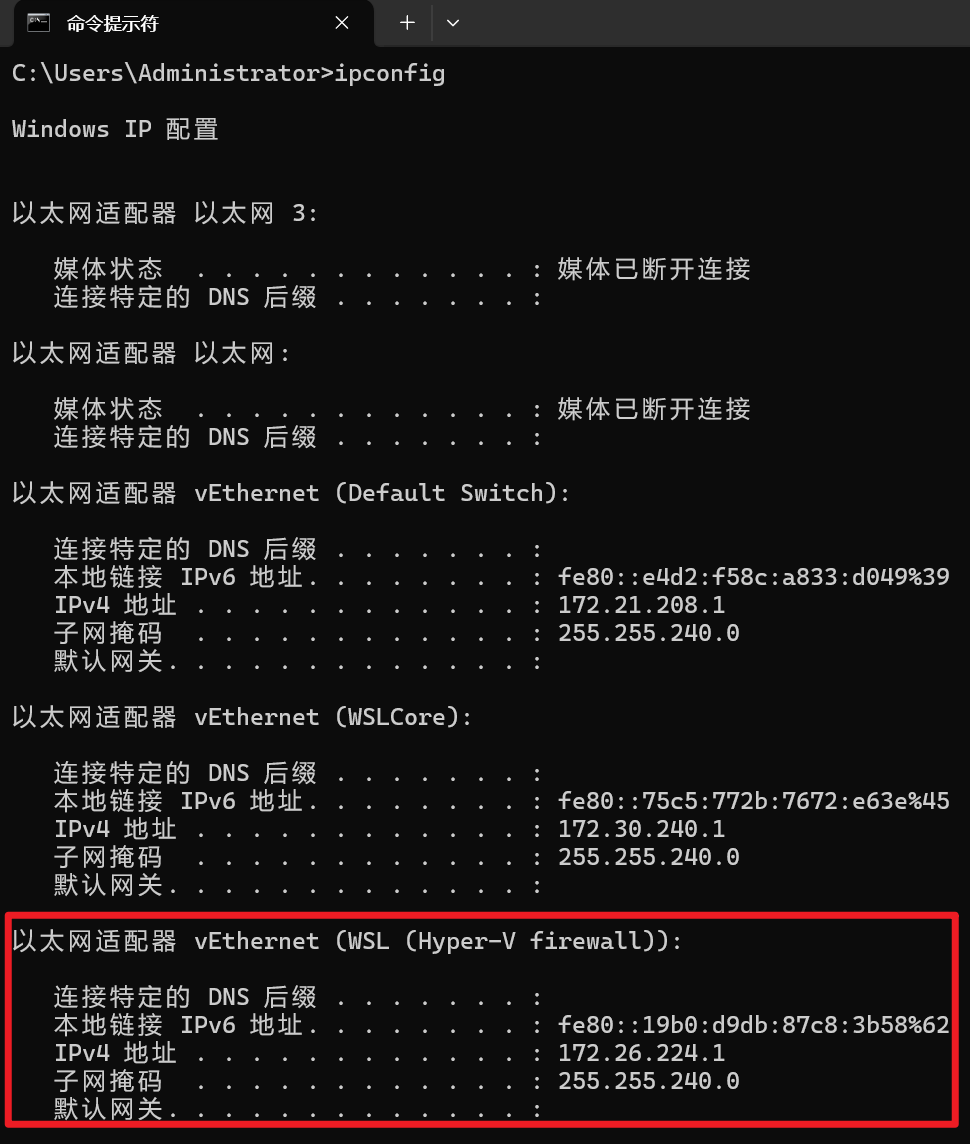
WSL 连接
shell
sudo apt-get update
sudo apt-get install postgresql-client
psql -h 172.26.224.1 -p 5432 -U postgres -d postgres从MySQL迁移到PostgreSQL
mysqldump 导出数据
shell
mysqldump --host host --port port -u user -p databasename tablename > table.sql
mysqldump -u <mysql_username> -p <mysql_password> --no-create-info <mysql_database_name> > mysql_data.sql目前 pgloader 版本只到 2022 发布的 3.6.9,不足以支持 PostgreSQL 17
安装 pgloader
shell
sudo apt-get update
sudo apt-get install pgloader
shell
docker pull dimitri/pgloader
docker run -it dimitri/pgloader
pgloader --version迁移表结构
shell
pgloader -v 'mysql://user:pass@host:port/dbname' 'postgresql://user:pass@host:port/dbname'
# 批量
--with 'batch rows=1000'如果报错Heap exhausted during allocation,表示内存不足,增加内存来启动
docker run -it --memory=8g dimitri/pgloader
使用 Docker 启动 pgloader 非常容易报错,建议自行编译
shell
# 拉代码
git clone https://github.com/dimitri/pgloader.git
cd pgloader
# 安装编译工具
sudo apt-get update
sudo apt-get install sbcl
sudo apt-get install make
# 编译软件并安装到系统中
make
sudo make install
find . -type f -executable -iname "pgloader"为什么MySQL会丢数据,PostgreSQL不会丢数据?
| 项目 | MySQL | PostgreSQL |
|---|---|---|
| 事务的持久性 | innodb_flush_log_at_trx_commit 默认为 1 ,每次事务提交都强制写日志到磁盘 0 或 2,异步刷盘,性能更高但可能丢 1 秒的事务 | fsync 默认为 on,确保每个事务提交后 WAL 日志立即写入磁盘 |
| 存储引擎 | 已淘汰的 MyISAM 不支持事务,留下坏印象 | 统一存储,数据变更先写 WAL 日志,再异步刷数据页 |
| 复制机制 | 默认异步复制,主库提交后立即返回,备库存在延迟,主库宕机会丢最新数据 | 默认同步复制,确保事务在一个备库持久化后才视为成功 |
| 故障策略 | 依赖 Binlog,没开启的话无法恢复 | WAL 比数据页优先写入,若使用时间点恢复,可恢复到任意时间点 |
| 不丢数据配置 | innodb_flush_log_at_trx_commit=1 + sync_binlog=1 + 双写缓冲 | 默认配置即强调数据安全 |
结论:正确配置是关键
Q:如果备库断电,主库会一直等待吗?
A:当备库断电,主库在等待一段时间后(synchronous_commit 和 synchronous_standby_names ),仍然没有收到备库的确认信息,主库会根据配置进行相应处理。默认情况下,主库会将复制机制降级为异步复制,继续处理新的事务,避免长时间阻塞。当备库恢复后,会重新建立同步复制关系并追赶数据。
PostGIS
安装PostGIS
启用扩展
sql
CREATE EXTENSION postgis;查看版本
sql
SELECT PostGIS_Full_Version();
SELECT * FROM pg_available_extensions WHERE name = 'postgis';创建空间数据表
sql
CREATE TABLE city (
id SERIAL PRIMARY KEY,
name VARCHAR(50),
location GEOMETRY(Point, 4326)
);插入数据
sql
INSERT INTO city (name, location)
VALUES
('深圳', ST_SetSRID(ST_MakePoint(114.0596, 22.5429), 4326)),
('广州', ST_SetSRID(ST_MakePoint(113.2644, 23.1291), 4326)),
('武汉', ST_SetSRID(ST_MakePoint(114.3052, 30.5928), 4326)),
('青岛', ST_SetSRID(ST_MakePoint(120.3830, 36.0662), 4326)),
('北京', ST_SetSRID(ST_MakePoint(116.4074, 39.9042), 4326));查询两个城市之间的距离
sql
# EPSG:4527:基于国家大地坐标系的投影坐标系
SELECT ST_Distance(
ST_Transform((SELECT location FROM city WHERE name = '深圳'), 4527),
ST_Transform((SELECT location FROM city WHERE name = '北京'), 4527));查询200公里内的城市
sql
SELECT name
FROM city
WHERE ST_DWithin(
ST_Transform(location, 4527),
ST_Transform((SELECT location FROM city WHERE name = '深圳'), 4527),
200000);EPSG:4326:WGS84 坐标系,全球通用
EPSG:3857:伪墨卡托投影(Web Mercator),为网络地图应用设计的投影坐标系
EPSG:4490:CGCS2000 坐标系(China Geodetic Coordinate System 2000),国家大地坐标系
EPSG:4527:基于CGCS2000的投影坐标系,便于地理数据测量、分析和制图
EPSG:32650:通用横轴墨卡托投影(Universal Transverse Mercator,UTM)坐标系的一部分。UTM 投影将地球划分为 60 个投影带,每个投影带的经度跨度为 6 度,EPSG:32650 指的是第 50 个投影带(Zone 50),适用于北半球,能在局部地区提供高精度的坐标基准,确保测量结果的准确性和可靠性。
插件
术语
- DBMS(Database Management System):数据库管理系统
- RDBMS(Relational Database Management System):关系型数据库管理系统
- DML(Data Manipulation Language):数据操纵语言
- DDL(Data Definition Language):数据定义语言
- OLAP(OnLine Analytical Processing):联机分析处理
- ODBC(Open DataBase Connectivity):一种标准的应用程序编程接口(API),允许应用程序访问不同的数据库管理系统(DBMS),而无需关心所使用的数据库的具体细节
- JDBC(Java DataBase Connectivity):Java 版本的 ODBC
- RBAC(Role-Based Access Control):基于角色的访问控制
- RLS(Row-Level Security):行级安全
- CTE(Common Table Expressions):公共表表达式,允许在SQL查询中创建临时结果集
- RDS(Relational Database Service):关系型数据库服务,是一种基于云计算技术的数据库服务模式,为用户提供了便捷、高效、可扩展的关系型数据库管理解决方案
- WAL(Write-Ahead Logging):预写式日志,对数据库中的数据进行修改前,先将操作记录到日志文件中,用于保证数据的持久性和事务的原子性
遇到的坑
- Navicat 12 for PostgreSQL 表为空,但可以通过 SELECT 语句检索出来
更新版本 12 为 15 。 - 启动 postgresql-x64-17 服务报错:本地计算机上的 postgreql-x64-17 服务启动后停止。某些服务在未有其他服务或程序使用时将自动停止。
删除C:\Program Files\PostgreSQL\17\data\postmaster.pid,重启服务。
不行的话,在计算机管理 → 系统工具 → 事件查看器 → Windows 日志 → 应用程序中,查看对应的日志。
可尝试重装。 - Navicat 15 for PostgreSQL 打开连接时报错:字段 "datlaastsysoid" 不存在
参考文献
- PostgreSQL 官网
- PostgreSQL | 菜鸟教程
- PostgreSQL 与 MySQL 相比,优势何在?
- postgreSQL psql工具使用详解
- Psycopg Documentation
- PostgreSQL Tutorials
- SQL基础教程(第2版)
- SQL基础教程(第2版) (豆瓣)
- SQL进阶教程
- SQL进阶教程 (豆瓣)
- postgres_books GitHub
- 全方位对比 Postgres 和 MySQL (2023 版)
- Postgres vs. MySQL: a Complete Comparison in 2024
- MySQL vs Postgres in 2024.
- 阿里云数据库RDS PostgreSQL
- PostgreSQL 在国内公司应用的多吗? - 知乎
- PostgreSQL中文社区
- Planet PostgreSQL
- PostgreSQL新手入门 - 阮一峰的网络日志
- 国产数据库清单(2020年第1季度) - 墨天轮
- PostgreSQL与MySQL优劣势比较浅谈
- MySQL vs PostgreSQL:数据库巨头之争,哪个更适合你的业务?
- 为什么PostgreSQL是最成功的数据库? - 知乎
- PostgreSQL vs MySQL performance benchmarking
- The Part of PostgreSQL We Hate the Most
- MySQL与PostgreSQL比较,哪个更好、我们该选用哪个?
- PostgreSQL 规约(2024版)
- Postgres与MySQL比较 - 极道
- PgSQL · 最佳实践 · EXPLAIN 使用浅析(优化器,查询计划)
- 弱水三千,只取一瓢,当图像搜索遇见PostgreSQL
- awesome-postgres: A curated list of awesome PostgreSQL software, libraries, tools and resources
- Managed Databases Connection Pools and PostgreSQL Benchmarking Using pgbench
- 都说MySQL快,为什么我的测试是PostgreSQL要快呢? - 知乎
- pgtpc: TPC B/C/H Benchmark for PostgreSQL
- dimitri/pgloader - Docker Image | Docker Hub
- pgloader Documentation
- Mysql迁移至pgsql分享
- Gis坐标系4326与3857及高德百度坐标系转换
- 超详细讲解GIS中常用的坐标系及在软件中的判别与操作
- PostGIS 距离计算建议
- 地图坐标系间的坐标转换及坐标距离计算
- <>
- <>
- <>
- <>