分布式编程容易出现的问题
1.活锁。活锁定义:在程序里,由于某些条件的发生碰撞,导致重新执行,再碰撞=》再执 行,如此循环往复,就形成了活锁。活锁的危害:多个线程争用一个资源,但是没有任何一个 线程能拿到这个资源。(死锁是有一个线程拿到资源,但相互等待互不释放造成死锁),活锁 是死锁的变种。补充:活锁更深层次的危害,很耗尽Cpu资源(在做无意义的调度)。
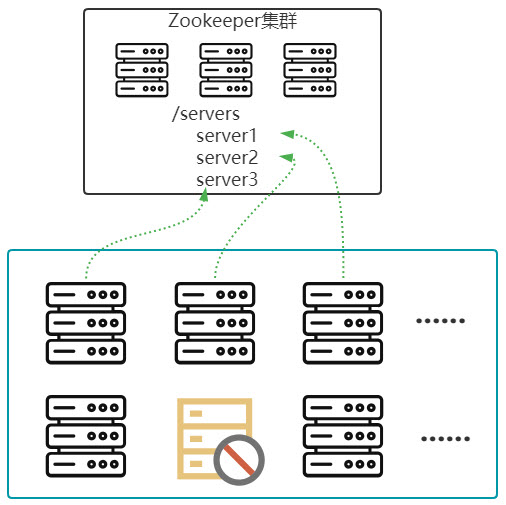
2.需要考虑集群的管理问题,需要有一套机制来检测到集群里节点的状态变化。
3.如果用一台机器做集群管理,存在单点故障问题,所以针对集群管理,也需要形成一个集群。
4.管理集群里Leader的选举问题(要根据一定的算法和规则来选举),包括要考虑Leader挂掉 之后,如何从剩余的follower里选出Leader。
5.分布式锁的实现。
ZooKeeper概述
ZooKeeper简介
ZooKeeper是分布式应用程序的协调服务框架,是Hadoop的重要组件。ZooKeeper是Google的Chubby一个开源的实现,是Hadoop的分布式协调服务,包含一个简单的原语集,分布式应用程序可以基于它实现。
具体应用场景
1.Hadoop,使用ZooKeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等.
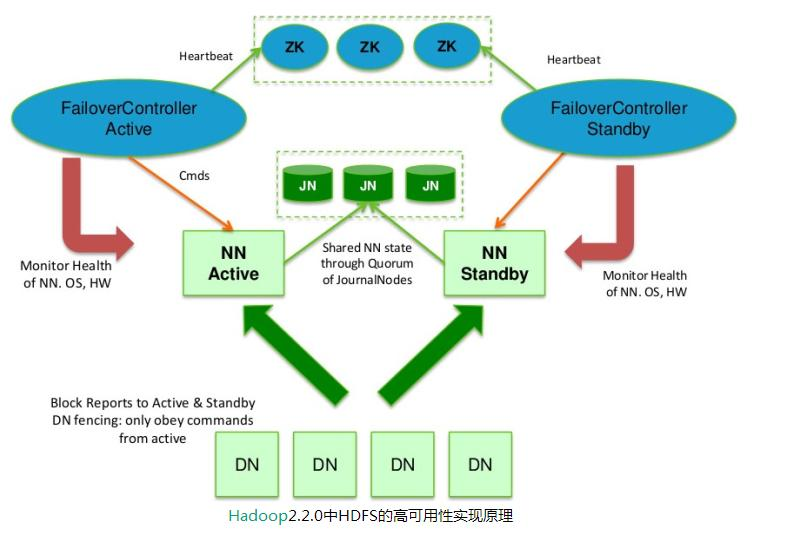
2.HBase,使用ZooKeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
3.分布式环境下的统一命名服务
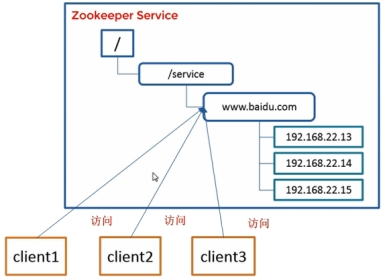
4.分布式环境下的配置管理
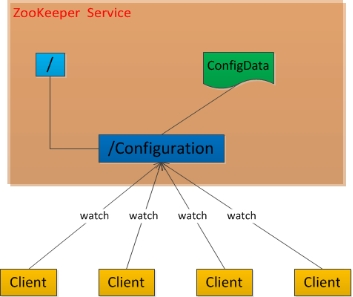
5.数据发布/订阅
6.分布式环境下的分布式锁
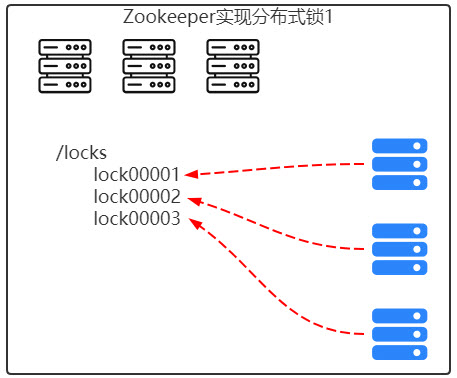
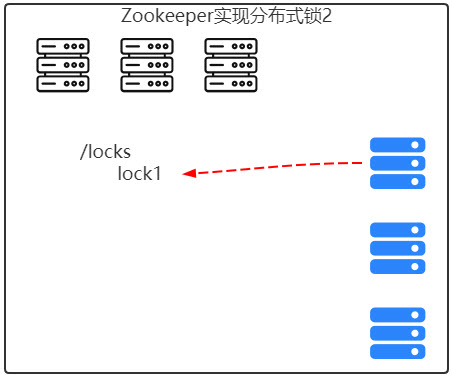
7.集群管理
ZooKeeper的类比理解
| 生活场景(小区) | ZooKeeper 对应(分布式集群) |
|---|---|
| 物业管理员 | ZooKeeper 集群 |
| 业主(每家每户) | 集群节点(NameNode/DataNode 等) |
| 物业公告栏 | ZNode(存储配置 / 状态的节点) |
| 公共设施预约登记 | 分布式锁 |
| 住户在家状态登记 | 临时节点 + 心跳检测 |
| 楼长选举 | Leader 选举 |
1. 分布式配置管理 → 物业发通知
-
生活场景 :小区要停水检修,物业不需要挨家挨户敲门,只需要把通知贴在公告栏上,所有业主路过看到就知道了,不用重复沟通。
-
ZooKeeper 对应:集群的公共配置(比如 Hadoop 的 NameNode 地址、Kafka 的 broker 端口)存在 ZooKeeper 的 ZNode 里,所有节点启动时去 ZooKeeper 读取配置,配置变更时 ZooKeeper 主动通知所有节点,不用逐个修改节点配置。
- 分布式锁 → 物业管公共设施预约
-
生活场景 :小区的公共健身房 / 会议室只有 1 个,业主想使用必须先去物业登记预约,物业保证同一时间只有 1 户能用,避免冲突。
-
ZooKeeper 对应 :集群中多个节点要抢同一个临界资源(比如 Hadoop HA 中抢 Active NN 身份),会去 ZooKeeper 创建临时有序节点,ZooKeeper 保证同一时间只有 1 个节点能拿到 "锁",其他节点排队等待,防止脑裂。
- 节点状态管理 → 物业查岗(住户是否在家)
-
生活场景:物业统计哪些住户在家,让业主出门前在门口贴 "在家" 条,回家后更新;如果住户长期不更新,物业就知道这户可能没人(节点故障)。
-
ZooKeeper 对应 :集群节点启动时,会在 ZooKeeper 创建临时节点,并定期发送心跳(更新节点状态);如果节点故障,心跳中断,临时节点会自动删除,ZooKeeper 会通知其他节点 "这个节点挂了",触发故障转移。
- 命名服务 → 物业帮查住户门牌号
-
生活场景:快递员不知道 "张三" 住哪栋哪户,去物业查一下登记信息,就能快速找到地址,不用在小区里瞎转。
-
ZooKeeper 对应:集群中的节点(比如 DataNode)不知道 Active NameNode 的具体地址,去 ZooKeeper 查一下 "NameNode 地址" 的 ZNode,就能直接获取,实现节点间的快速发现。
- 集群选举 → 物业选楼长
-
生活场景 :小区要选楼长,物业组织投票,保证超过半数业主同意的人才能当选;楼长离职后,物业再组织重新选举,保证楼栋管理不中断。
-
ZooKeeper 对应 :集群启动时,ZooKeeper 组织 Leader 选举,保证超过半数节点投票的节点成为 Leader;Leader 故障后,ZooKeeper 触发重新选举,保证集群高可用。
ZooKeeper 架构与核心原理
集群角色划分
ZooKeeper 集群是主从架构 ,节点分 3 种角色,通常部署奇数个节点(3/5/7):
| 角色 | 作用 |
|---|---|
| Leader(领导者) | 唯一主节点,负责处理所有写请求,并通过 ZAB 协议同步数据到 Follower;主持 Leader 选举。 |
| Follower(跟随者) | 处理读请求,参与 Leader 选举,接收 Leader 的数据同步;写请求会转发给 Leader。 |
| Observer(观察者) | 功能和 Follower 一致,但不参与 Leader 选举;用于扩展读性能,适合读多写少场景。 |
核心协议:ZAB 协议
ZAB(ZooKeeper Atomic Broadcast)协议是 ZooKeeper 专属的原子广播协议, 是 ZooKeeper 实现数据一致性的核心,你可以理解为 "Paxos 协议的工程化实现"。 其核心目标为数据一致性(保证 Leader 节点的所有事务提案,能被集群中过半节点以相同的顺序执行,最终所有节点的内存数据(ZNode 树形结构)完全一致。)和高可用。主要分为两个阶段:崩溃恢复和消息广播。
阶段 1:崩溃恢复(Leader 故障时触发)
当集群启动、或 Leader 节点宕机 / 失联时,ZAB 协议进入崩溃恢复阶段 ,核心任务是选举出全新的 Leader 节点 ,并保证新 Leader 拥有集群中最全的事务数据。流程拆解:
- 触发条件:集群无 Leader,或 Follower 检测到 Leader 心跳超时。
- 选举规则
- 所有节点变为 Looking 状态,参与 Leader 竞选。
- 节点会投票给 ZXID 最大 (事务日志最新)且 SID(服务器 ID)最大 的节点(ZXID 优先级 > SID)。
- 当某节点获得超过半数节点的投票 ,则成为新 Leader,状态切换为 Leading ;其他节点变为 Following 状态。
- 数据同步:新 Leader 会让所有 Follower 上报自己的最大 ZXID,然后将 Follower 缺失的事务提案全部同步给它们,确保所有节点的数据和 Leader 完全一致。
- 退出恢复阶段 :当 Leader 确认过半 Follower 数据同步完成,集群进入消息广播阶段。
阶段 2:消息广播(正常运行时的核心流程)
集群稳定运行时,ZAB 协议处于消息广播阶段 ,核心任务是处理客户端的写请求,并保证所有节点数据一致。流程拆解:
- 提案封装 :客户端的写请求(如创建 ZNode、修改数据)只会发给 Leader,Leader 会将请求封装为事务提案 ,并分配一个全局唯一递增的 ZXID (由
epoch(任期)+ 计数器组成,保证提案顺序)。 - 广播提案:Leader 将提案广播给所有 Follower。
- Follower 持久化 + ACK 确认 :Follower 收到提案后,先写入本地事务日志 (防止宕机丢数据),再向 Leader 回复
ACK确认。 - 过半确认后提交 :当 Leader 收到超过半数 Follower 的 ACK ,说明提案可提交,会先在本地执行提案,再广播
Commit消息给所有 Follower。 - Follower 执行提案 :Follower 收到
Commit消息后,按 ZXID 顺序执行提案,更新内存数据,完成和 Leader 的数据同步。