1.文件系统
1.1 文件的分类
狭义文件:指保存在硬盘上的文件
广义文件:操作系统进行资源管理的一种机制,很多的软件、硬件资源抽象成"文件"来表示
从开发的角度也可分为其他两种(大前提是所有的文件都是二进制文件)
1.文本文件
2.二进制文件
在实际开发中如果要去判断文件是二进制还是文本 粗暴地用记事本打开 如果不乱码就是文本文件 反之就是二进制文件
1.2 文件的区分
一台计算机中能够保存的文件是很多的 该怎样去精确的找到我们所需的文件呢
我们此时就会利用到路径
路径是我们来定位到文件的一系列过程
计算机中目录采用树形结构
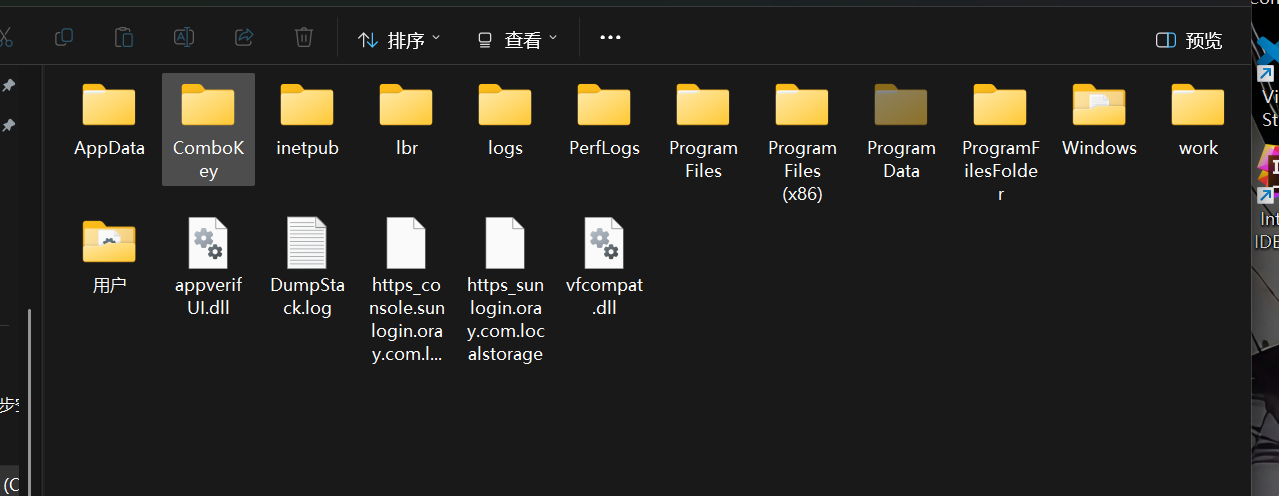
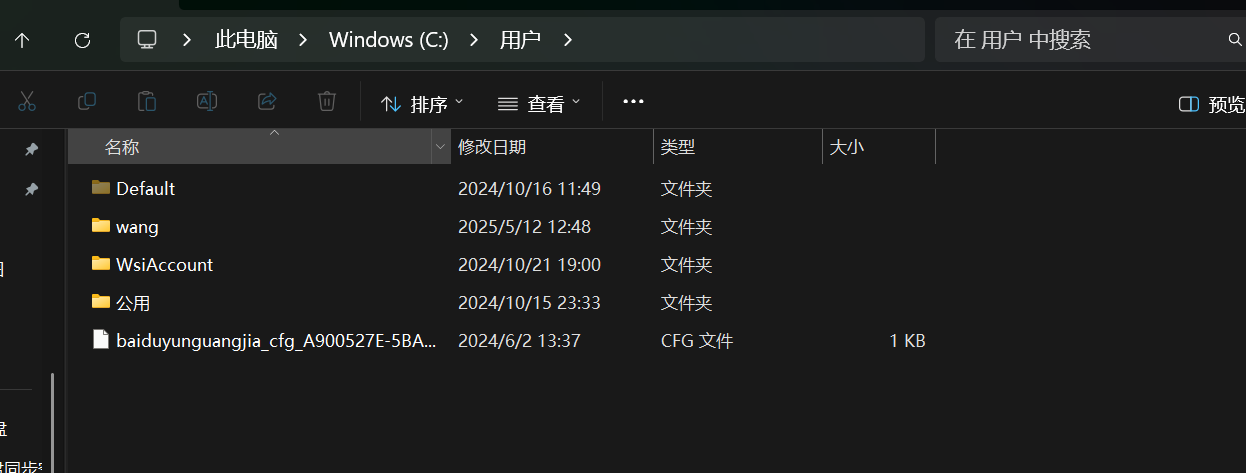
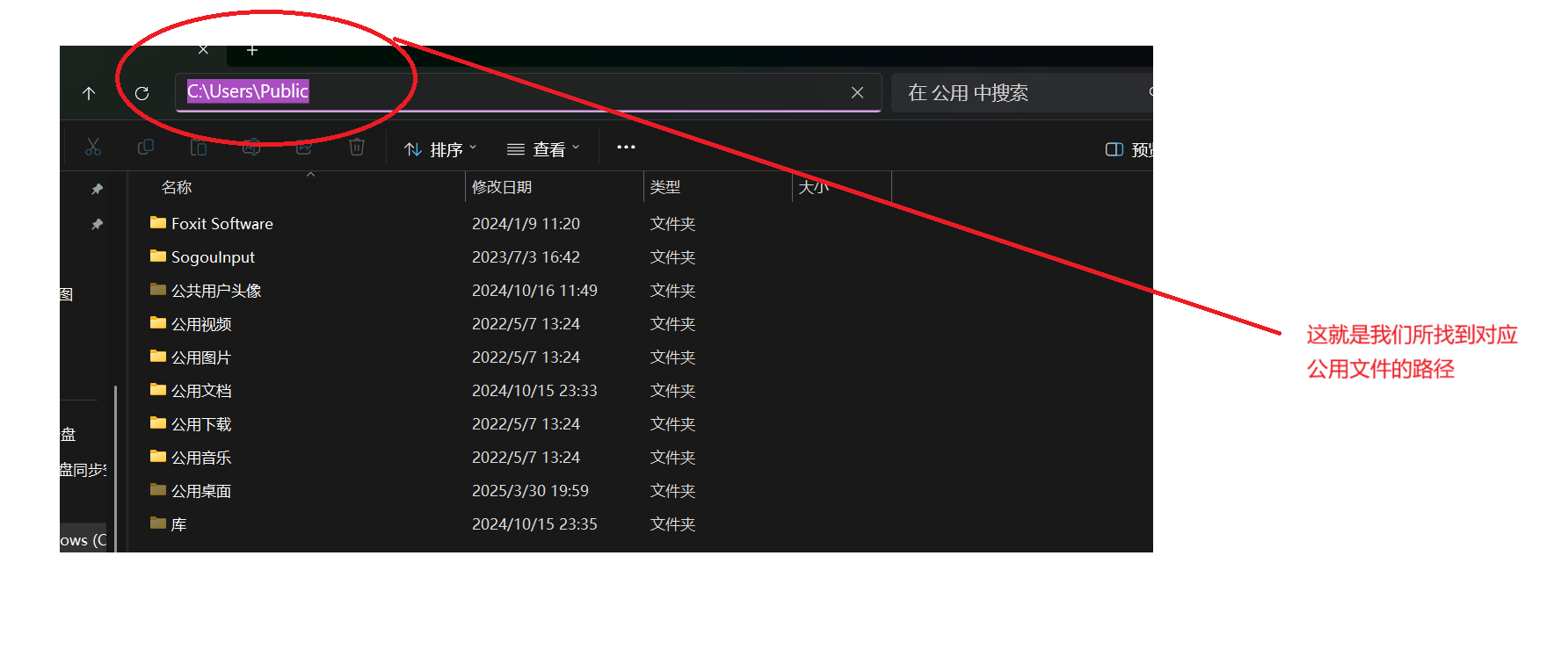
在路径的表示过程中 在主流操纵系统中都是以/作为分割符
而Windows系统是例外 windows对两种分隔符/ 与 \都支持 并且默认是\
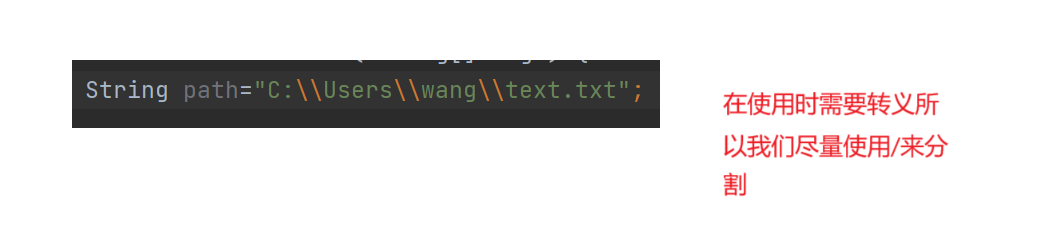
路径有相对路径和绝对路径
相对路径:相对路径是基于当前工作目录的路径。例如,如果当前工作目录是"C:\Users\15063\Desktop\lqf",并且需要引用同一目录下的另一个文件"1.txt",则可以使用相对路径"../1.txt"来指向它。这意味着从当前目录回退一级,然后访问"1.txt"文件
绝对路径:绝对路径是从根目录开始的完整路径。例如,如果有一个文件存储在硬盘的"C:\Users\15063\Desktop"目录下,那么该文件的绝对路径将是"C:\Users\15063\Desktop\1.txt"。无论当前位置在哪里,绝对路径都指向同一个文件位置
1.3 JAVA标准库提供了一系列的类操作文件
1.文件系统操作
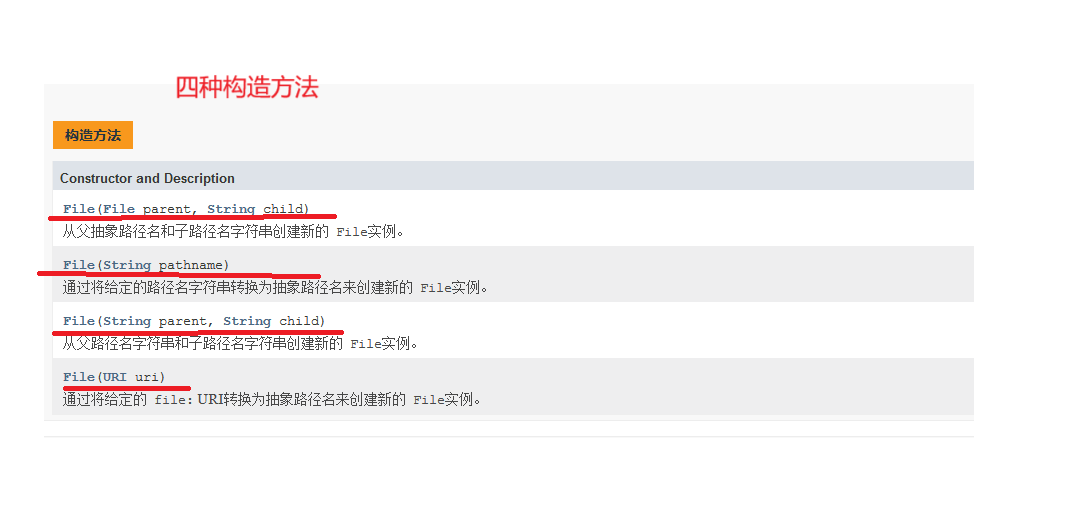
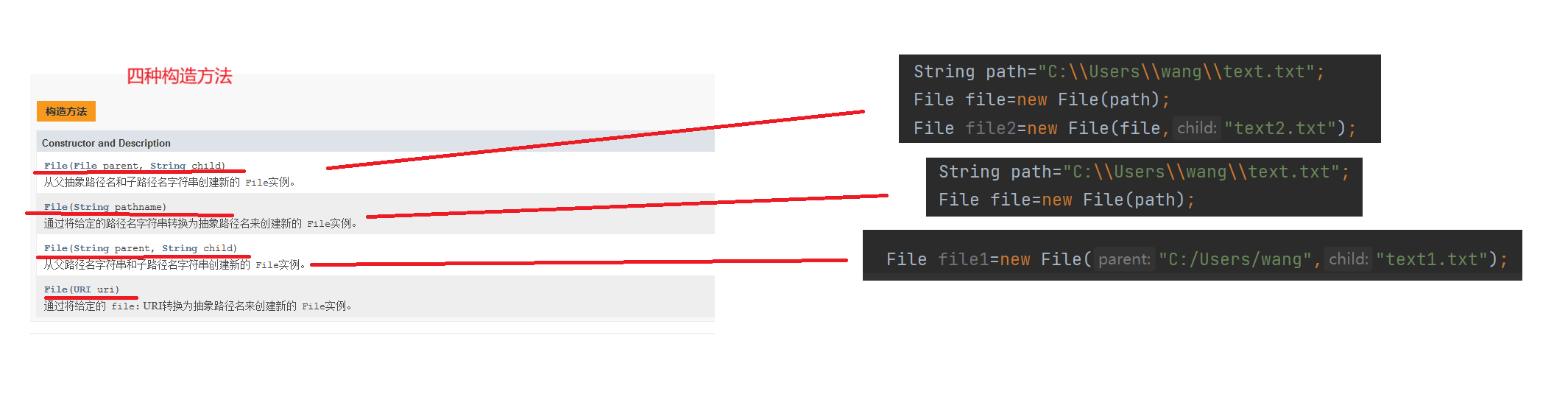
2.文件内容操作
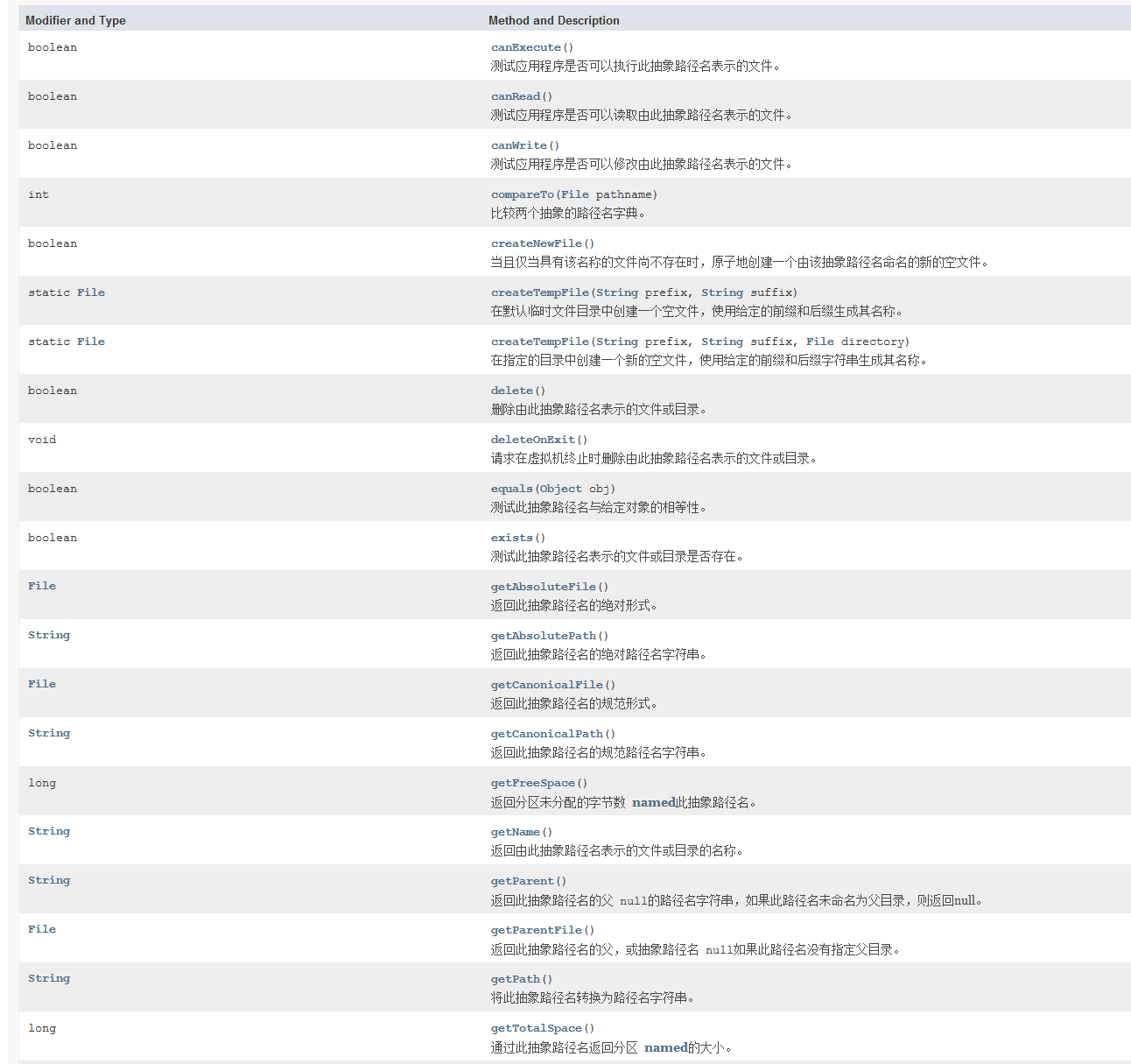
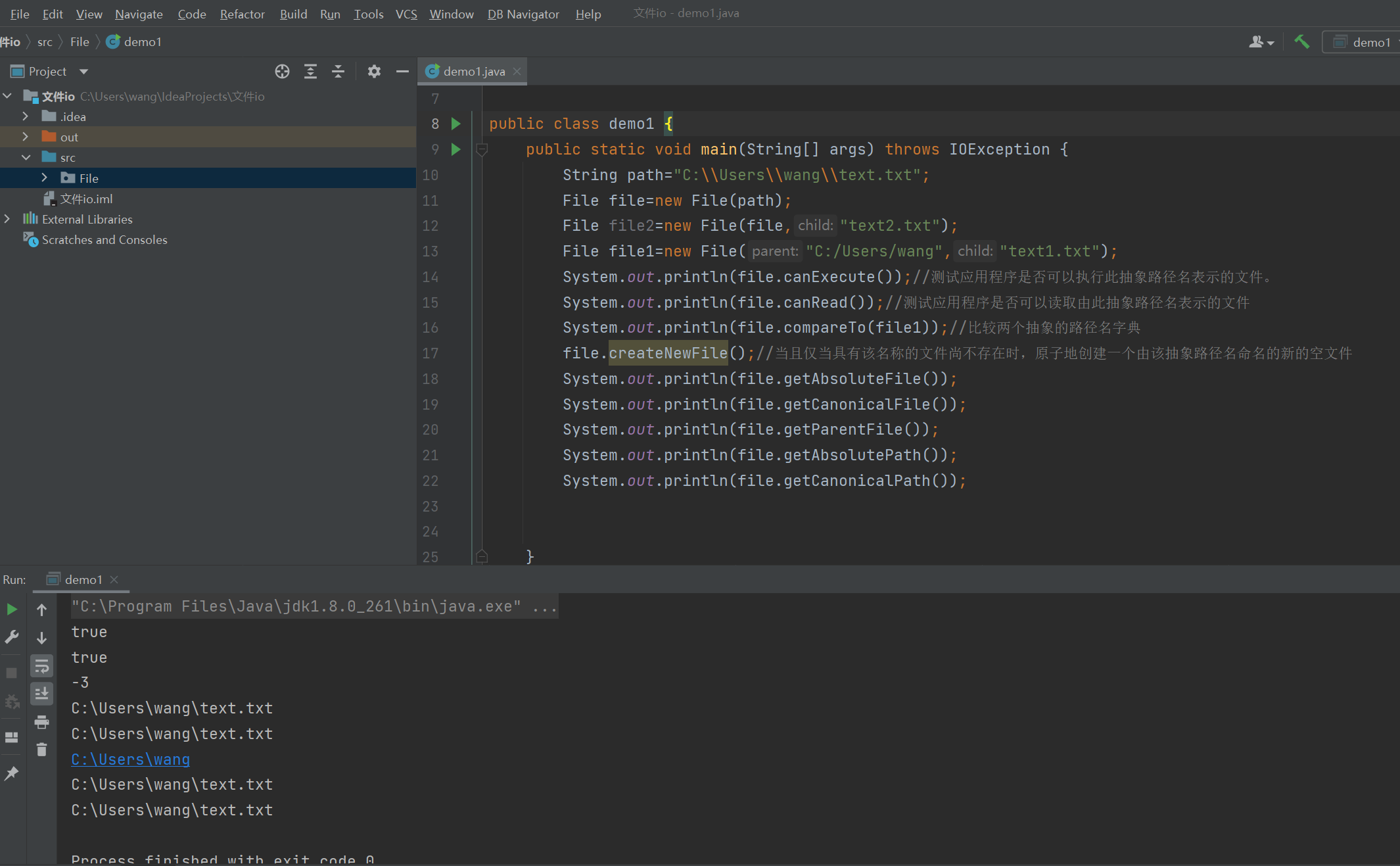
读者可根据需要查询对应文档 尝试利用
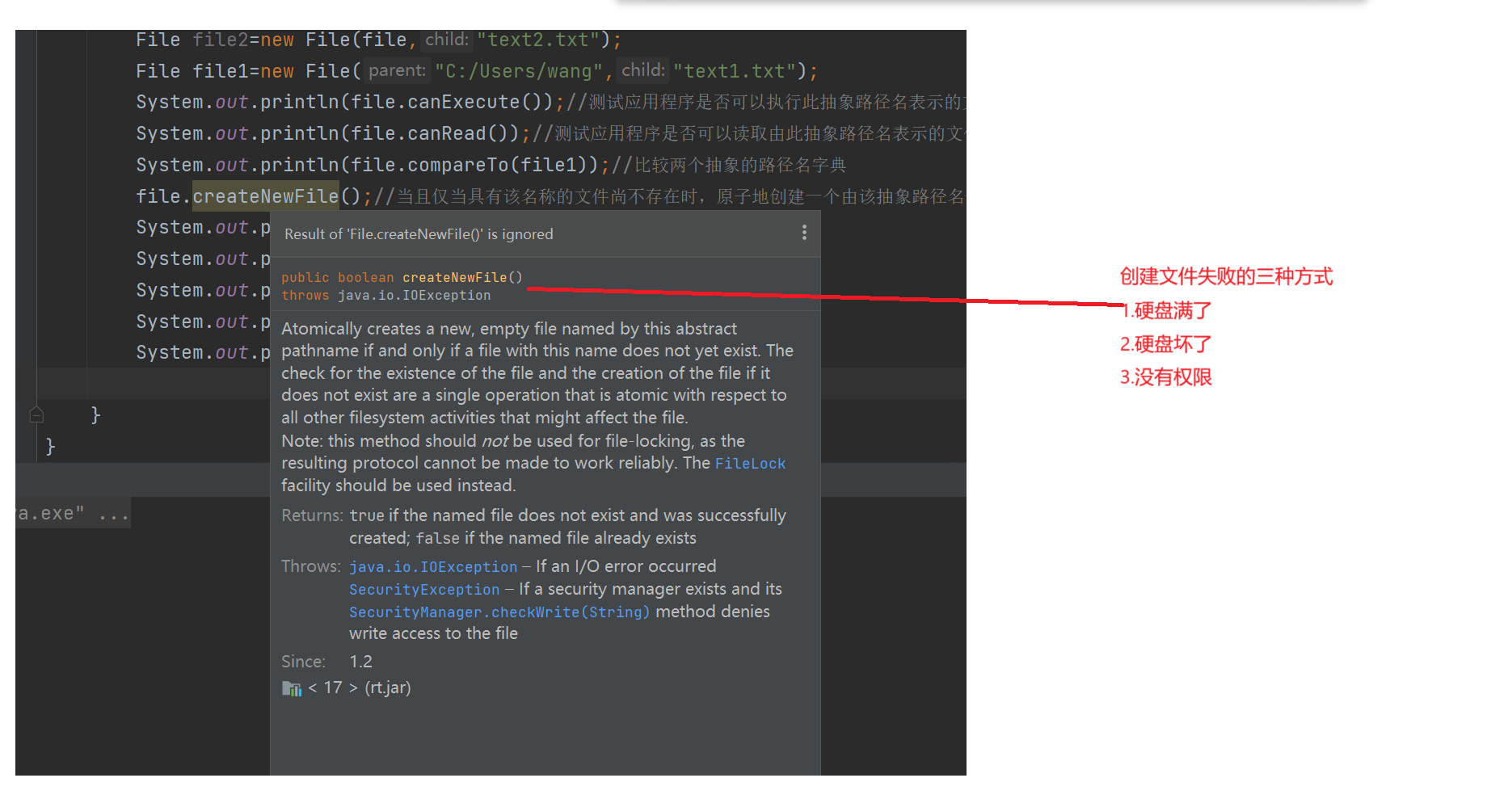
2.硬盘
硬盘分为两种
固态硬盘:通常读写速度一秒几个GB
机械硬盘:通常读写速度一秒几百MB
相应的固态硬盘的价值远超于机械硬盘的价值 现在的笔记本通常是固态硬盘
提到读写速度 我们不能不提内存和cpu寄存器
内存的读写速度是固态的成百上千倍
而cpu更是内存的成百上千倍

3.文件IO流(Stream)
Java中针对文件内容的操作主要是通过一组"流对象"来实现的
计算机中的"流"和水流非常相似
假如从文件中读取100字节数据
1次把100字节都读完'
分两次 一次五十字节
分十次 一次十字节
.......无数种读数据的方法
l流分为两大类别
1.字节流
读写文件,以字节为单位,针对二进制文件使用
InputStream 输入 从文件 读数据(从硬盘到cpu)
OutputStream 输出 往文件中写数据 (从cpu到硬盘)
字节流写入
我们根据代码即可看出 将要写入文件内容转为byte 然后通过write方法去写入文件
java
//使用字节流写入数据
try(FileOutputStream fileOutputStream=new FileOutputStream("text.txt")) {
String word="每个今天都是往后的明天";
byte[]bytes=word.getBytes();
fileOutputStream.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}但我们一次性全部写入的话 效率比较低 而且风险也较高 因此我们引入缓存写入文件
java
//加入缓冲区的字节流写入数据
try (FileOutputStream fileOutputStream1 = new FileOutputStream("text.txt",true);
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream1)){
String content = "晚上九点之后的样子,就是以后的样子";
byte[] bytes = content.getBytes();
bufferedOutputStream.write(bytes);
// 不需要手动flush,close()会自动flush
// 但如果有立即写入需求,可以调用 bufferedOutputStream.flush()
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}它在内存中开辟一块缓冲区(默认 8KB),写入数据时先存到缓冲区,只有当缓冲区写满、调用 flush() 或关闭流时,才会一次性把缓冲区的数据刷到磁盘 这样减少磁盘 I/O 次数,提升写入性能 减少了因频繁 I/O 中断导致的数据损坏概率
将bufferOutputStream写入try()里无须手动flush 随着文件的close而自动flush
写入数据覆盖问题
当我们如下图所示一样 进行写入数据 大家觉得 文件中所写入的数据是什么呢?
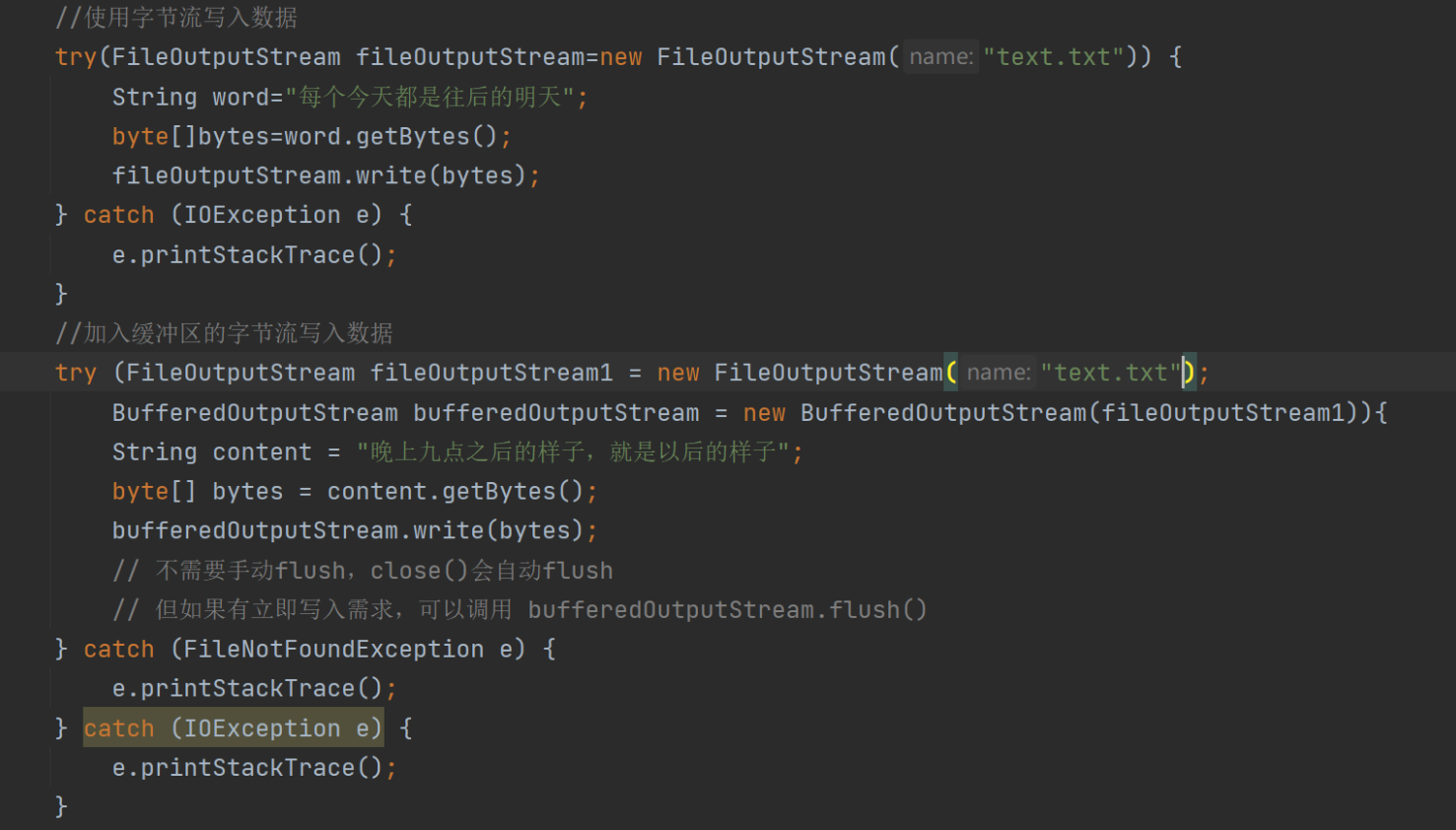
会发现结果与我们所希望逻辑不同 我们的本意是向文件中写入两次数据 将这两份数据都保存在文件中 可是结果已经告诉我们,只有第二次写入的数据得到了保存 这就是发生了数据 覆盖问题
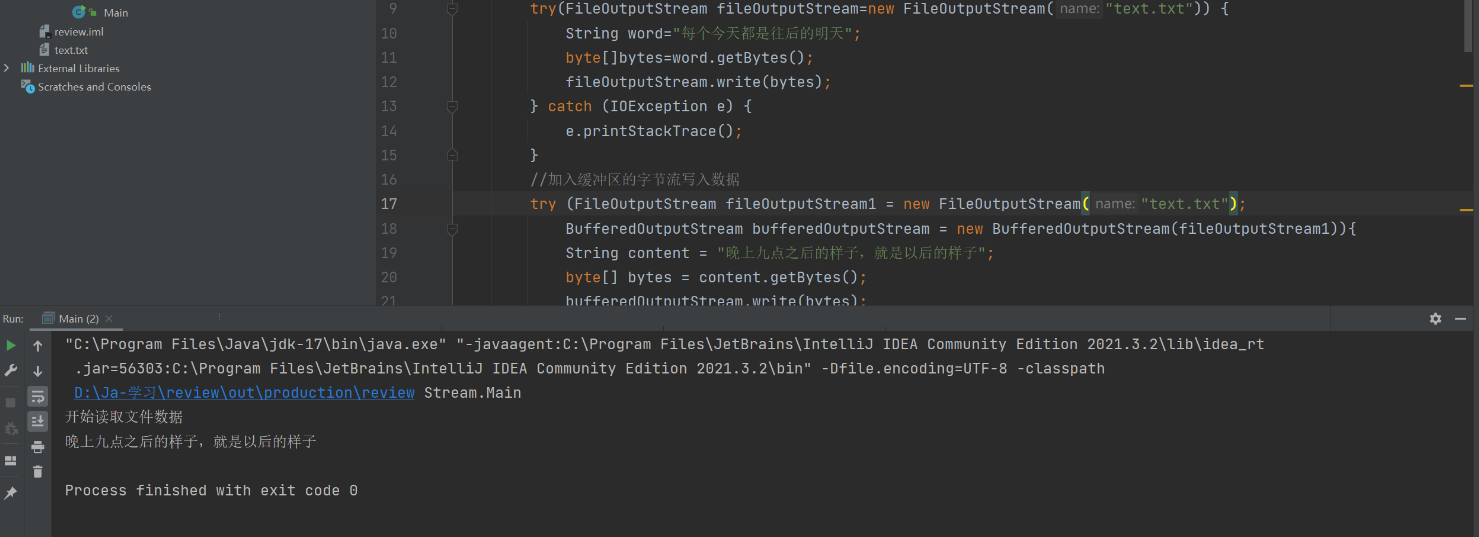
如果想让两句话都保留在文件里,需要在第二次打开文件时指定追加模式,要修改FileOutputStream 的构造方法
 这样的话呢就会进行追加写入 FileOutputStream默认是覆盖数据,在构造方法第二个参数加入true 就会变成追加模式
这样的话呢就会进行追加写入 FileOutputStream默认是覆盖数据,在构造方法第二个参数加入true 就会变成追加模式
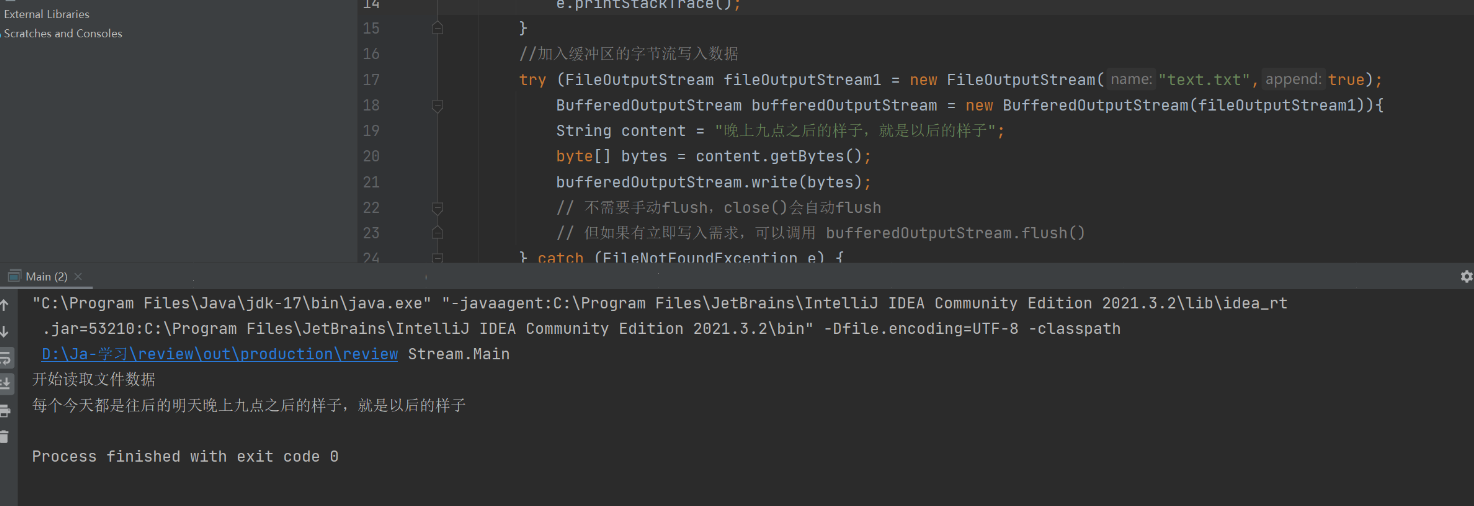
这时就解决了覆盖问题
字节流读取
字节流读取呢 就是读取文件字节数 根据读取字节数 去打印出文件数据
但我们需要注意几点
首先呢创建一个字节数组作为缓冲区,用于临时存储从文件中读取的字节数据 这个缓冲区呢是作为标杆 每次最多读取多大字节数 防止一次性读取大文件导致内存溢出
其次 我们要记录读取具体多少字节数 此时代码中的length就是用来接收 read方法返回的实际读取的字节数 因为实际读取字节数不一定等于缓存区的字节数
最后呢当读到问价末尾时 read方法会返回-1 此时就读取完成
但不知你是否会和我有一样的问题 就是"当读取到末尾时 返回-1,那假如最后一段读完了是-1 实际读取字节长度 那不是这最后一段就没有了吗?"
根据结果呢发现这样还没出现这样的问题 因此我带着疑惑去查询答案 终于让我发现蛛丝马迹
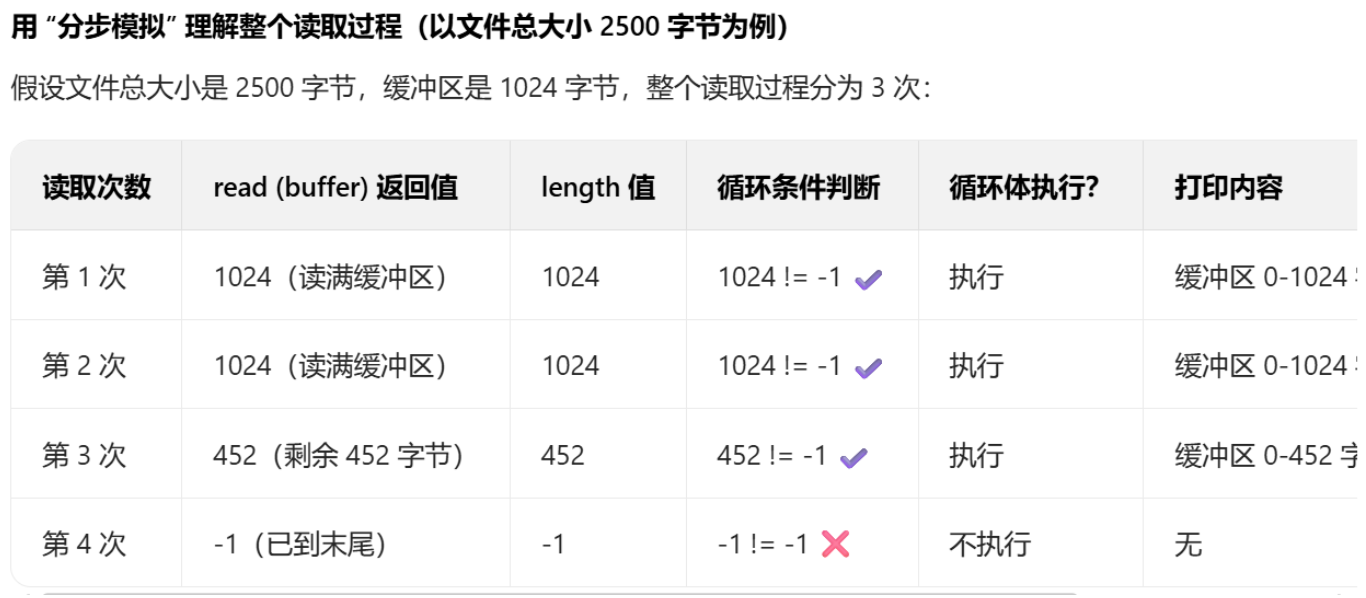
我不禁感慨真是聪明的读取逻辑 最后的一次是指它已到末尾 这样的话字节的读取并不会丢失
只有当已经没有任何字节可读取 时,read(buffer) 才会返回 - 1,此时循环终止,而这时候已经没有需要打印的内容了
java
//使用字节流读取数据
try(FileInputStream fileInputStream=new FileInputStream("text.txt")){
//设置一个缓存区来存放读取的数据
byte[]buffer=new byte[1024];
System.out.println("开始读取文件数据");
//存储每次从文件中实际读取到的字节数
int length;
//read(buffer) 方法返回的是 "实际读取的字节数"(不是缓冲区长度),当文件读到末尾时返回 -1
while((length=fileInputStream.read(buffer))!=-1){
System.out.println(new String(buffer,0,length));
}
} catch (FileNotFoundException ex) {
ex.printStackTrace();
} catch (IOException ex) {
ex.printStackTrace();
}字节流读取注意
1.read(buffer) 返回 - 1 的时机是没有任何字节可读取时,而非 "读取最后一段字节时",因此最后一段有效字节会被正常读取并打印。
2.循环条件 length != -1 保证了只有读取到有效字节时才会执行打印 ,循环体内的length永远是有效字节数,不会出现 - 1 的情况。
3.缓冲区的作用是 "批量读取" 提升效率,而length的作用是 "精准打印实际读取的字节",两者配合既高效又不会遗漏最后一段内容。
2.字符流
读写文件,以字符为单位 针对文本文件使用
Reader 输入 从文件中读数据
Writer 输出 往文件中写数据
字符流写入数据 和读取与字节流同理 使用缓存策略去写入和读取 减少对硬盘io的次数
我在字符流缓存方式读取数据时觉得他不是按照read 读一个写一个吗?我明明是一个字符一个字符读的,缓冲区到底在起什么作用?
但其实是这样的 看到的 read() 是应用层的调用 ,而 BufferedReader 的缓存机制是在底层 I/O 层面工作的

`BufferedReader` 真正的优势还在于它的 `readLine()` 方法,能直接按行读取文本,这在处理日志、配置文件等场景下非常方便,而且同样是基于缓冲区优化的 我在此篇博客并未使用readLine方法 但是不可否认在实际使用中readLine使用特别广泛 大家可以在后面去使用
java
//字符流写入数据
try(FileWriter fileWriter=new FileWriter("text.txt")){
fileWriter.write("你好");
fileWriter.write("wx");
fileWriter.write("欢迎你");
} catch (IOException e) {
e.printStackTrace();
}
//字符流引用缓存去写入数据
try(FileWriter fileWriter1=new FileWriter("text.txt");
BufferedWriter bufferedWriter=new BufferedWriter(fileWriter1,1024*16)){
//缓存区默认8K 此处指定为了16k
bufferedWriter.write("你好");
bufferedWriter.write("wx");
bufferedWriter.write("欢迎你");
} catch (IOException e) {
e.printStackTrace();
}
//字符流读取数据
try(FileReader fileReader=new FileReader("text.txt")){
System.out.println("文件内容读取:");
int tmp;
while((tmp=fileReader.read())!=-1){
System.out.println((char)tmp);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
//字符流读取数据使用缓存区
try(FileReader fileReader=new FileReader("text.txt");
BufferedReader bufferedReader=new BufferedReader(fileReader,1024*8)){
System.out.println("文件内容读取:");
int tmp;
while((tmp=bufferedReader.read())!=-1){
System.out.println((char)tmp);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}字节流与字符流的区别
字符流和字节流是 Java I/O 的两大基础体系,它们的本质区别在于处理的数据单元和编码能力
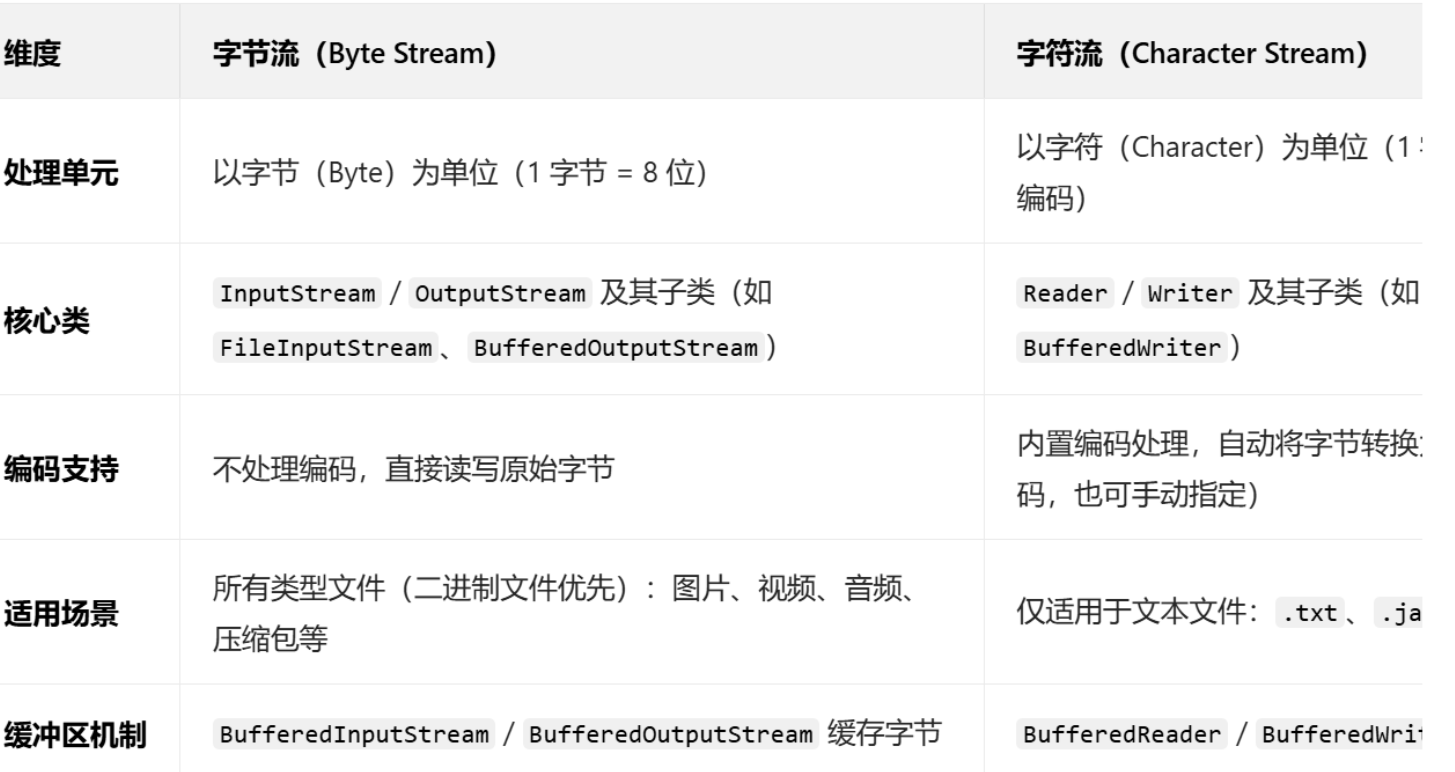
字节流:直接与磁盘交互,读写的是二进制数据,不关心内容是什么 读取一张图片时,字节流会原封不动地把图片的二进制数据读入内存
字符流:在字节流的基础上增加了编码解码层 读取时,先把字节读入缓冲区,再按指定编码(如 UTF-8)转成字符;写入时,先把字符按编码转成字节,再写入磁盘
因为其底层原理的不同应用场景也是不一样 对应应用场景 不用我过多说大家也都会清楚