文章目录
- 世界模型:AI大脑里的"物理模拟器"
-
- 引子:你能预测下一秒会发生什么吗?
- 什么是世界模型?
- [世界模型 vs 其他AI模型:有什么不同?](#世界模型 vs 其他AI模型:有什么不同?)
- 世界模型能做什么?三个让你眼前一亮的例子
- 世界模型的前世今生:从学术论文到产品爆发
- 业界大咖怎么看?李飞飞的"空间智能"
-
- 她是谁?
- 她提出的"空间智能"是什么?
- [World Labs做了什么?](#World Labs做了什么?)
- 为什么世界模型很重要?
- 世界模型的挑战与未来
- 总结
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
✈ 您的一键三连,是我创作的最大动力🌹
世界模型:AI大脑里的"物理模拟器"

引子:你能预测下一秒会发生什么吗?
想象一下这个场景:你正在过马路,余光瞥见一辆自行车从侧面驶来。你的大脑会在瞬间完成一系列"计算"------自行车的速度、行驶方向、你走过去需要的时间、可能的交汇点......然后,你做出判断:是加速走过去,还是停下来让一让?
这一切发生得如此自然,以至于你根本意识不到自己刚刚完成了一次复杂的"物理模拟"。
这就是人类大脑的神奇之处------我们能在脑海中"预演"即将发生的事情,然后做出最优的选择。
那么问题来了:AI能不能也拥有这种能力?
答案是:能。而实现这种能力的关键,就是今天我们要聊的主角------世界模型(World Model)。
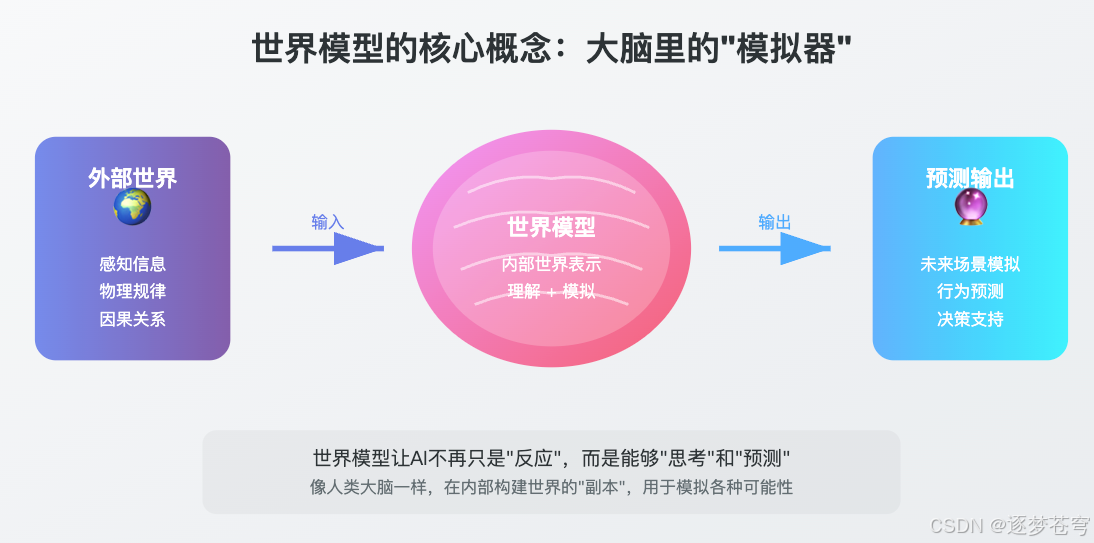
什么是世界模型?
如果要用一句话解释世界模型,我会说:它是AI大脑里的"物理模拟器"。
让我用一个更生动的比喻来解释。
你脑海中的"沙盘"
还记得小时候玩沙子吗?你可以在沙堆上建城堡、挖河道、做小山。当你想象"如果我在这里挖一条沟,水会流向哪里"的时候,你其实是在脑海中进行一次模拟。
人类的大脑天生就有这种能力。我们能想象:
- 把杯子推到桌边会怎样?(会掉下去摔碎)
- 往热水里加冰块会怎样?(水会变凉,冰会融化)
- 开车不踩刹车会怎样?(会撞上前面的车)
这些"想象"不是凭空猜测,而是基于我们对物理世界规律的理解。我们的大脑里,仿佛有一个微型的"世界副本",可以用来做各种模拟和预测。
世界模型,就是要让AI也拥有这样一个"脑内世界"。
关键区别:能"放电影",不只是"讲故事"
这里有个关键问题需要澄清。
你可能会问:ChatGPT不是也能预测吗?我问它"马路上有个球在滚,下一秒会在哪",它也能告诉我"会滚到马路对面"啊。那世界模型和它有什么区别?
区别在于输出形式:
- ChatGPT只能给你终点描述:"球会滚到马路对面"(一句话)
- 世界模型能给你完整过程:一段球滚动的视频,显示0.1秒时球在哪、0.2秒时球在哪、0.3秒时球在哪......
更精准的比喻:
- ChatGPT像一个看过无数剧本的编剧:它知道"球滚过马路"这个情节应该怎么写,但它写不出球每一秒具体在哪个位置。问它"0.5秒时球在哪",它答不上来。
- 世界模型像一个物理引擎(比如游戏引擎):它真正在"运算"球的轨迹,能生成每一帧的精确位置。
这就是为什么Sora能生成物理正确的视频------它不是在"描述"视频应该是什么样,而是在内部真正"模拟运算",然后把模拟结果渲染出来。
简单说:ChatGPT在讲故事,世界模型在放电影。
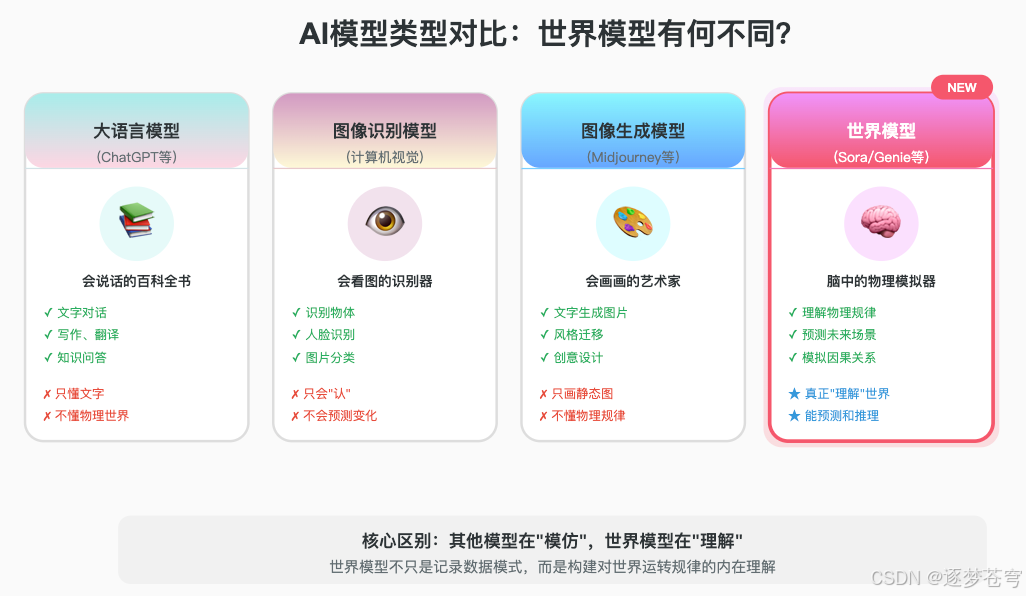
世界模型 vs 其他AI模型:有什么不同?
为了更好地理解世界模型的独特之处,让我们把它和其他常见的AI类型做个对比。
大语言模型:会说话的"百科全书"
你肯定听说过ChatGPT这样的产品。它们背后是大语言模型,可以理解人类语言,进行对话、写作、翻译。
但大语言模型有个特点:它们的知识来自于文字。它们读过无数的文章、书籍、网页,知道"苹果从树上掉下来"这件事,但它们可能并不真正"理解"为什么苹果会往下掉,而不是往上飞。
打个比方:大语言模型就像一个读了无数书的"学霸",可以用文字描述任何事情,但如果让它真的去做一道物理实验,它可能会手足无措。
图像识别模型:会看图的"识别器"
这类AI可以看懂图片里是什么------这是猫、那是狗、这是交通信号灯。
但它只会"认",不会"预测"。它可以认出这是一个正在滚动的球,但它不知道这个球下一秒会滚到哪里。
图像生成模型:会画画的"艺术家"
像Midjourney、Stable Diffusion这样的工具,可以根据文字描述生成精美的图片。
但生成的是静态的画面。它不理解画面中物体之间的因果关系。你让它画一杯倒了的水,它能画出来,但它不知道水为什么会往下流。
世界模型:脑中的"物理引擎"
前面我们说过,世界模型像物理引擎,ChatGPT像编剧。现在让我们用一个简单的测试来验证这个区别。
一个测试,区分两种AI
问题:一个球正在马路上滚动,滚到一半碰到一块石头,会发生什么?
| AI类型 | 工作方式 | 能给出的答案 |
|---|---|---|
| ChatGPT | 做阅读理解题 | "球可能会弹开或停下来"(语言猜测) |
| 世界模型 | 做物理实验 | 生成一段视频:球弹向左边30度,滚了2米后停下(精确模拟) |
为什么会有这种区别?
- ChatGPT的"预测"来自语言模式:它读过无数描述"碰撞"的文字,知道"弹开"和"碰撞"经常一起出现,所以它能说出"会弹开"。但它不知道具体弹向哪里。
- 世界模型的"预测"来自物理模拟:它在内部真正计算了球的速度、石头的位置、碰撞的角度,所以它能生成精确的轨迹。
再来一个测试:
问:如果球的初速度加快一倍,结果会怎样?
- ChatGPT:可能还是说"会弹开"(它的答案不会随条件精确变化)
- 世界模型:重新计算,生成一段新视频(球弹得更远,因为动能更大)
这就是本质区别:ChatGPT在做语言层面的"推理",世界模型在做物理层面的"模拟"。
| 模型类型 | 通俗理解 | 能做什么 | 核心特点 |
|---|---|---|---|
| 大语言模型 | 会说话的百科全书 | 文字对话、写作、问答 | 只能输出文字描述 |
| 图像识别模型 | 会看图的识别器 | 认出图片里是什么 | 只能识别静态画面 |
| 图像生成模型 | 会画画的艺术家 | 根据描述画出图片 | 只能画静态图 |
| 世界模型 | 脑中的物理引擎 | 模拟世界如何运转 | 能输出视频/动画/可交互环境 |
世界模型能做什么?三个让你眼前一亮的例子
说了这么多概念,让我们看看世界模型在现实中的应用。
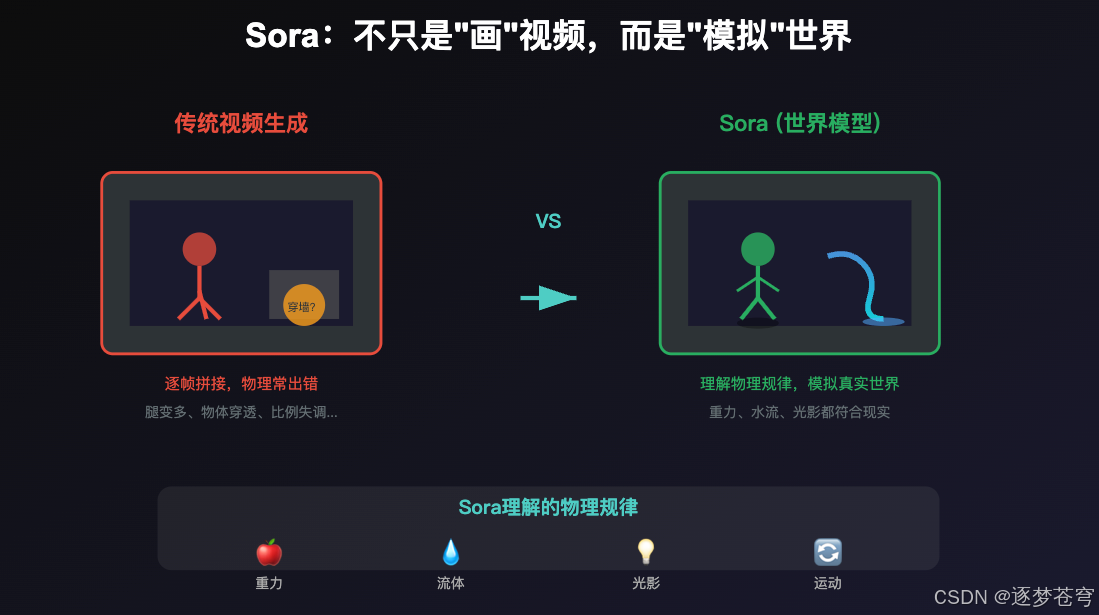
例子1:OpenAI的Sora------不只是画视频,而是"运行"世界
2024年,OpenAI发布了Sora,一个能生成视频的AI。但Sora和之前的视频生成工具有本质区别。
传统的视频生成AI怎么工作?
- 读懂你的文字描述("一个球在马路上滚动")
- 画出第1帧(球在这里)
- 画出第2帧(球应该在那里吧...)
- 画出第3帧(呃...大概在那里?)
- 结果:容易出现物理穿帮------人走着走着腿变成三条,物体穿透墙壁
Sora怎么工作?
- 在内部构建一个"虚拟世界"(有地面、有球、有物理规则)
- 在这个世界里"运行"物理模拟(球按照物理规律滚动)
- 把模拟过程"录制"成视频
这就像游戏和动画的区别:
- 动画师是一帧帧画的,可能画错物理(腿画多了、物体穿模)
- 游戏引擎是真正在计算物理,不可能出现穿模(因为物理规则不允许)
用OpenAI自己的话说:Sora不是在"画"视频,而是在"模拟"世界。这就是为什么它生成的视频里,水流、光影、物体运动都符合物理规律------因为它是真正在"运算"这些物理过程,而不是在"猜测"画面应该长什么样。
例子2:Google的Genie------凭空创造一个可玩的游戏世界
Google推出的Genie更加神奇。你给它一张图片,它就能生成一个可交互的游戏世界。
什么意思呢?不只是生成一张静态的游戏画面,而是创造出一个你可以操控角色在里面行动的游戏环境。角色可以跳跃、可以奔跑,而且动作效果符合"游戏物理"。
这背后同样是世界模型在起作用。AI不只是记住了"游戏长什么样",而是理解了"游戏世界中的因果关系"------按下跳跃键,角色会跃起;碰到障碍物,角色会被挡住。
例子3:自动驾驶------在脑中预演所有可能
自动驾驶是世界模型最直接的应用场景之一。
一辆自动驾驶汽车每时每刻都面临着无数决策:前面的行人会不会突然横穿马路?旁边的车会不会变道?如果我现在刹车,后面的车会不会追尾?
这些问题的答案,需要AI能够"预测未来"。而这正是世界模型的强项。
自动驾驶中的世界模型,会在内部快速"模拟"各种可能的场景------如果行人走过来、如果旁边的车加速、如果我踩刹车......然后选择最安全的应对方案。
世界模型的前世今生:从学术论文到产品爆发
你可能觉得世界模型是最近才火起来的概念,但实际上,它已经在学术界酝酿了30多年。
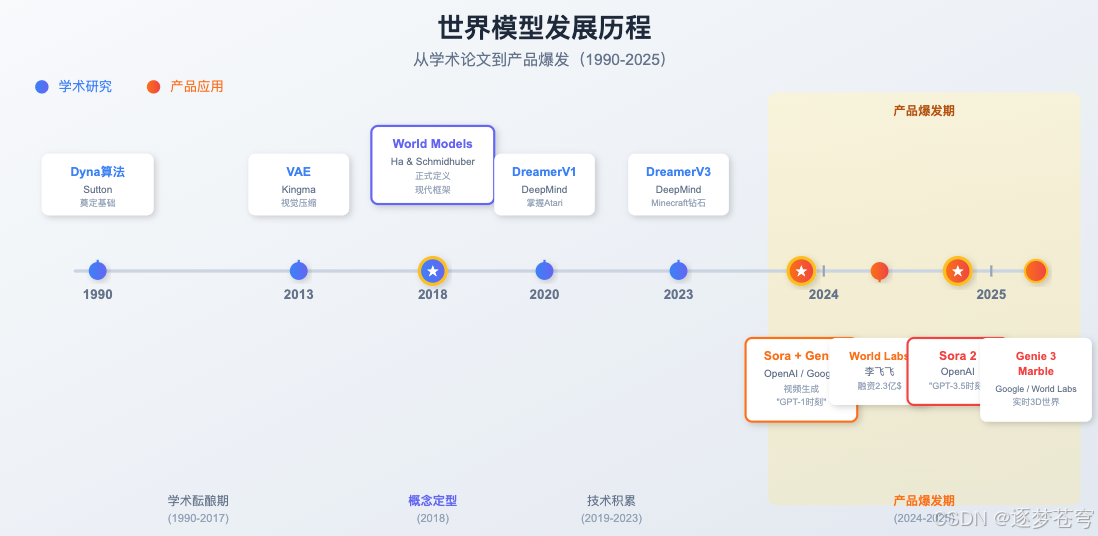
学术酝酿期(1990-2017)
早在1990年,AI科学家们就开始思考:能不能让AI在"脑子里"模拟环境,而不是只靠真实的试错来学习?
这个想法被称为"Dyna算法",由强化学习之父Richard Sutton提出。同年,Jürgen Schmidhuber开始用神经网络来建模环境的动态变化。
但那时候,计算能力太弱,这些想法只能停留在简单的实验中。
概念定型期(2018)
2018年是关键的一年。
David Ha和Schmidhuber发表了一篇名为《World Models》的论文,正式定义了现代世界模型的框架。他们的系统有三个部分:
- 视觉:把复杂画面压缩成简洁的"代码"
- 记忆:记住过去发生的事,预测接下来会发生什么
- 控制器:根据预测做出决策
更厉害的是,他们证明了AI可以完全在"想象"中学习------先在脑内模拟练习,再到真实环境中执行,而且效果一样好!
这就像你在脑海中反复演练一场演讲,真正上台时自然就流利了。
产品爆发期(2024-2025)
2024年开始,世界模型从论文走向产品:
| 时间 | 事件 | 意义 |
|---|---|---|
| 2024年2月 | OpenAI发布Sora | 视频生成的"GPT-1时刻" |
| 2024年2月 | Google发布Genie | 可交互游戏世界 |
| 2024年9月 | 李飞飞创立World Labs | 融资2.3亿美元 |
| 2025年9月 | Sora 2发布 | 视频的"GPT-3.5时刻" |
| 2025年10月 | Genie 3发布 | 实时3D世界生成 |
业界普遍认为:世界模型可能是通向AGI(通用人工智能)的关键一步。
OpenAI的Sam Altman说:"如果我们能建造真正优秀的世界模型,这对AGI的重要性将超出人们的想象。"
业界大咖怎么看?李飞飞的"空间智能"
说到世界模型,有一个人不得不提------李飞飞。
她是谁?
李飞飞是斯坦福大学教授,被誉为"AI教母"。她创建的ImageNet数据集,直接点燃了上一轮深度学习的爆发。可以说,今天我们用的ChatGPT、Midjourney,追根溯源都受益于她的工作。
2024年,李飞飞又开始了新的征程:她创立了World Labs公司,专注于研发世界模型。短短几个月,这家公司就融资2.3亿美元,估值超过10亿美元,投资方包括英伟达、a16z等顶级机构。
她提出的"空间智能"是什么?
李飞飞给世界模型取了一个更具体的名字:空间智能(Spatial Intelligence)。
她有一句很形象的话:
"大语言模型是言语华丽却缺乏实际经验的词匠------能说会道,但不懂真实世界。"
什么意思呢?ChatGPT可以用文字描述"如何倒咖啡",但它无法:
- 估计杯子和咖啡壶的距离
- 预测咖啡会以什么弧度流出
- 判断什么时候该停止倾倒
这些能力,就是"空间智能"------理解三维空间、预测物理变化、与真实世界交互的能力。
World Labs做了什么?
2024年12月,World Labs发布了一个惊人的能力:一张图片,生成一个可以"走进去"的3D世界。
不是生成一张3D渲染图,而是一个你可以用鼠标操控视角、在里面"漫游"的完整空间。这就是世界模型的魔力------它不只是"画"出世界,而是"构建"出世界。
李飞飞认为,这将是AI的下一个十年:从"会说话"进化到"会做事"。
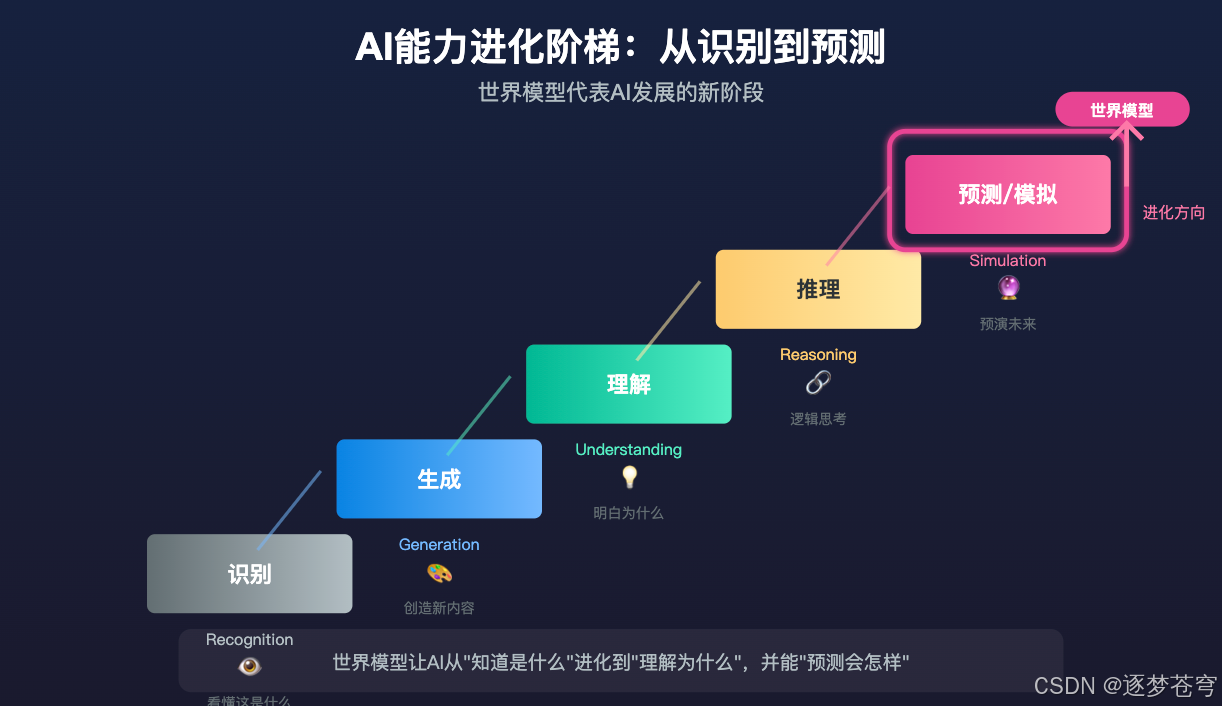
为什么世界模型很重要?
从"看懂"到"理解"的跨越
世界模型代表着AI发展的一个重要转折点。
过去的AI更像是一个"高级模仿者"------它学习大量的数据,模仿数据中的模式。但世界模型追求的是更深层次的东西:理解。
它不只是知道"苹果掉下来"这个现象,而是理解"为什么会掉下来"这个规律。这种理解让AI能够应对从未见过的新情况。
对产品设计的启发
如果你是产品经理或者AI产品经理,世界模型可能会改变你设计产品的思路。
想象一下:未来的AI助手,不再只是"你问我答",而是能够真正理解你的处境,预测可能的后果,给出有远见的建议。
比如你问:"我这周想去爬山",拥有世界模型的AI可能会综合考虑天气预报、你的身体状况、交通情况,然后告诉你:"周六下午可能会下雨,建议你周日上午出发,穿防滑的鞋子。"
它不再只是一个工具,而更像一个能替你"想一步"的搭档。
对普通人的意义
对于普通用户来说,世界模型带来的最直接变化是:AI会变得更"聪明"、更"懂事"。
它会更少出现"答非所问"的情况,更少犯常识性错误,更能理解你的真实意图。
世界模型的挑战与未来
当然,世界模型目前还有不少挑战需要克服。
首先,真实世界太复杂了。我们的物理世界有无数的细节和规律,要让AI全部理解和模拟,需要巨大的计算能力和更多的研究突破。
其次,评估一个世界模型是否真的"理解"了世界,本身就是个难题。它可能在某些场景下表现很好,但换个情境就"露馅"了。
不过,世界模型代表的方向是明确的:让AI从"知道是什么"进化到"理解为什么",从"模仿"进化到"推理"。
如果你对AI发展感兴趣,世界模型绝对是一个值得持续关注的方向。
总结
让我们回顾一下今天的核心要点:
-
世界模型是什么:AI大脑里的"物理引擎",能够真正模拟世界的运转过程。
-
与ChatGPT的本质区别:
- ChatGPT只能给你终点描述("球会滚到对面")
- 世界模型能给你完整过程(一段球滚动的视频)
- 简单说:ChatGPT在讲故事,世界模型在放电影。
-
如何区分两者:问"球碰到石头会怎样"------ChatGPT只能猜测"会弹开",世界模型能计算出具体弹向哪里、弹多远。
-
为什么重要:这让AI能做到真正的"预测",而不只是语言层面的"推测"。Sora能生成物理正确的视频,就是因为它在"运算"而不是"猜测"。
最后,留给你一个问题:现在你能解释"世界模型和ChatGPT有什么区别"吗? 如果能,说明你已经真正理解了这篇文章的核心。
欢迎在评论区分享你的想法!
如果这篇文章对你有帮助,欢迎点赞、收藏、分享,你的支持是我持续创作的动力!