一、主流国产时序数据库核心技术全景(2026)
1.1 技术选型维度说明
时序数据库的技术选型需聚焦存储效率、写入吞吐、查询延迟、多模兼容性、事务支持五大核心指标,其底层技术差异集中体现在存储引擎设计、索引结构、分片策略与计算引擎优化四大维度。
1.2 技术特性对比表(增强版)
| 数据库名称 | 核心厂商 / 社区 | 核心技术栈 | 存储引擎 | 索引类型 | 分片策略 | 核心优化点 | 典型部署架构 |
|---|---|---|---|---|---|---|---|
| TDengine | 涛思数据 | C 语言原生开发、列存优化、分布式一致性协议(RAFT) | 自研列存引擎(LSM-Tree 变体) | 时间范围索引 + 设备 ID 倒排索引 | 哈希分片 + 时间分区 | 数据冷热分离存储、预计算聚合、压缩算法(Delta-of-Delta+LZ4) | 分布式集群(Leader-Follower) |
| KaiwuDB | 浪潮云弈 | C++17、多模元数据管理、原生 AI 算子集成(TensorFlow/PyTorch 接口) | 混合存储引擎(行 + 列) | 多维复合索引(时间 + 标签 + 空间) | 范围分片 + 地理分区 | 算子下推、智能缓存替换(LRU-K)、流批一体计算 | 云原生分布式(K8s 调度) |
| Apache IoTDB | 清华大学 / Apache 基金会 | Java、端 - 边 - 云协同协议(IoTDB Sync Protocol)、树形数据模型(DeviceTree) | 自研 TsFile 引擎(列存) | 设备树索引 + 时间索引 + 值索引 | 水平分片 + 时间分层 | 预聚合存储、轻量级压缩(SNAPPY)、边云数据同步优化 | 端边云三级部署(Edge Node+Cloud Cluster) |
| DolphinDB | 浙江智臾科技 | C++、内置编程语言 DolphinDB Script、流计算引擎(CEP 支持) | 列存引擎(列式存储 + 内存计算) | 区间索引 + 哈希索引 + 位图索引 | 范围分片 + 按表分区 | 向量化执行、代码生成(JIT)、分布式计算任务调度优化 | 分布式集群(Master-Worker) |
| openGemini | 华为云 | Go 语言、InfluxDB 兼容协议、云原生存储分离(S3/OSS 适配) | 列存引擎(LSM-Tree) | 时间索引 + 标签索引 | 哈希分片 + 时间分区 | 批量写入优化、智能索引选择、弹性扩缩容(K8s HPA) | 云原生 Serverless + 物理集群混合部署 |
| CnosDB | 诺司时空 | Rust 语言、分布式事务(2PC 优化)、多租户隔离 | 列存引擎(自研 MeroDB) | 多维索引 + 时空索引 | 范围分片 + 租户隔离 | 分区裁剪、查询并行化、异地多活(跨区域复制) | 分布式集群(Region-Server) |
| GreptimeDB | 格睿科技 | Rust+Arrow、PromQL 兼容、实时分析引擎(OLAP 优化) | 列存引擎(Arrow Columnar) | 时间索引 + 标签倒排索引 + 向量索引 | 哈希分片 + 时间分区 | 向量执行引擎、Arrow 格式零拷贝、实时聚合计算 | 云原生分布式(K8s + 对象存储) |
| 金仓时序数据库 | 中电科金仓 | C/C++、KingbaseES 内核融合、MVCC 事务机制、多模数据统一存储接口 | 混合存储引擎(B+Tree+LSM-Tree) | 时间分区索引 + GIS 空间索引 + JSON 路径索引 | 范围分片 + 哈希分片混合 | 跨表关联优化(CBO+RBO 混合优化器)、时序数据压缩(ZSTD)、事务 ACID 强保障 | 集中式 / 分布式集群 / 共享存储集群 |
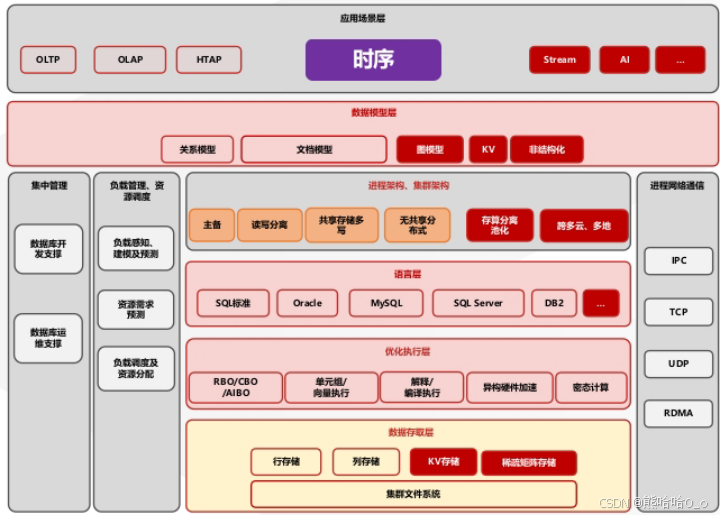
二、焦点解析:金仓时序数据库融合多模架构的技术深度拆解
金仓时序数据库的核心竞争力源于KingbaseES 内核的原生多模融合能力,其技术设计规避了传统 "时序引擎 + 关系库" 集成方案的性能损耗与一致性风险,以下从技术原理、核心组件与代码实践三方面展开。
2.1 内核级多模融合的技术实现
2.1.1 统一元数据管理模型
金仓通过多模元数据注册表(Multi-Model Meta Registry) 实现时序、关系、GIS、JSON 数据的统一管理,元数据结构采用 Protobuf 序列化存储,核心 Schema 定义如下(伪代码):
syntax = "proto3";
package kingbase.tsdb.meta;
// 多模数据类型枚举
enum DataType {
RELATIONAL = 0; // 关系型
TIME_SERIES = 1; // 时序型
GIS = 2; // 空间数据
JSON = 3; // 文档型
}
// 时序表元数据扩展
message TimeSeriesTableMeta {
string table_name = 1;
string time_column = 2; // 时间戳列(必填)
repeated string tag_columns = 3; // 标签列(设备ID、位置等)
repeated string metric_columns = 4; // 指标列(传感器值等)
PartitionPolicy partition_policy = 5; // 分区策略
CompressionConfig compression = 6; // 压缩配置
}
// 分区策略配置
message PartitionPolicy {
enum Type {
TIME_RANGE = 0; // 时间范围分区
TIME_DEVICE_HASH = 1; // 时间+设备ID哈希复合分区
}
Type type = 1;
string time_interval = 2; // 分区粒度(如1d、1h)
int32 hash_buckets = 3; // 哈希分桶数
}
// 压缩配置
message CompressionConfig {
enum Algorithm {
ZSTD = 0; // 默认ZSTD(平衡压缩比与解压速度)
LZ4 = 1; // 高速压缩
DELTA_DELTA = 2; // 时序数值专用压缩
}
Algorithm algo = 1;
int32 level = 2; // 压缩级别(1-19)
}
// 统一元数据注册表项
message MetaEntry {
string entry_id = 1;
string db_name = 2;
string object_name = 3; // 表/索引名称
DataType data_type = 4;
oneof meta_detail {
TimeSeriesTableMeta ts_meta = 5;
RelationalTableMeta rel_meta = 6;
GISMeta gis_meta = 7;
JSONMeta json_meta = 8;
}
int64 create_time = 9;
string owner = 10;
}2.1.2 时序数据的存储引擎适配
金仓采用混合存储引擎架构:时序数据的时间序列部分(指标值 + 时间戳)使用 LSM-Tree 引擎优化写入吞吐,标签与关联业务数据使用 B+Tree 引擎保障查询性能,核心实现逻辑如下:
-
时间分区存储:默认按
TIME_DEVICE_HASH策略分区,示例分区键定义:-- 金仓时序表创建SQL(含分区策略与多模字段) CREATE TABLE ship_gps_telemetry ( device_id VARCHAR(64) NOT NULL, -- 标签列(设备ID) timestamp TIMESTAMPTZ NOT NULL, -- 时间戳列(主键) longitude DOUBLE PRECISION, -- 指标列(经度) latitude DOUBLE PRECISION, -- 指标列(纬度) speed FLOAT, -- 指标列(速度) ship_info JSONB, -- 多模列(JSON文档) position_gis GEOGRAPHY(POINT), -- 多模列(GIS空间点) PRIMARY KEY (device_id, timestamp) ) ENGINE = TSDB; -- 指定时序存储引擎 PARTITION BY TIME_DEVICE_HASH ( timestamp INTERVAL '1 day', -- 时间分区粒度:1天 device_id HASH BUCKETS 64 -- 设备ID哈希分桶数:64 ) COMPRESSION = ZSTD LEVEL 6; -- 压缩算法:ZSTD,级别6 -
数据压缩优化:针对时序数据的高相关性特性,采用
DELTA_DELTA+ZSTD混合压缩算法,压缩流程伪代码:// 金仓时序数据压缩核心逻辑(C语言简化版) void ts_compress_batch(TSBatch* batch, CompressionConfig* config) { // 1. 对时间戳列执行Delta-Delta编码 int64_t prev_delta = 0; for (int i = 1; i < batch->time_count; i++) { int64_t delta = batch->timestamps[i] - batch->timestamps[i-1]; batch->compressed_timestamps[i] = delta - prev_delta; prev_delta = delta; } // 2. 对数值指标列执行ZSTD压缩 ZSTD_CCtx* cctx = ZSTD_createCCtx(); ZSTD_CParams cparams = ZSTD_getCParams(config->level, batch->metric_size, 0); ZSTD_initCParams(cctx, &cparams); for (int j = 0; j < batch->metric_count; j++) { batch->compressed_metrics[j] = ZSTD_compressCCtx( cctx, batch->metric_buffers[j], batch->metric_size, batch->raw_metrics[j], batch->metric_size, 0 ); } ZSTD_freeCCtx(cctx); }
2.1.3 多模数据关联查询的执行引擎优化
金仓通过混合查询优化器(CBO+RBO) 实现时序数据与多模数据的高效关联,核心优化策略包括:
- 分区裁剪(Partition Pruning):基于时间范围、设备 ID 哈希快速过滤无效分区;
- 算子下推(Operator Pushdown):将聚合、过滤算子下推至存储引擎层执行;
- 索引选择:自动匹配最优索引(时序查询优先时间索引,空间查询优先 GIS 索引)。
示例:船舶 GPS 时序数据与船舶业务数据的跨多模关联查询(含时间范围 + 空间范围过滤):
-- 场景:查询2026-01-01 00:00至2026-01-02 00:00期间,
-- 福建省沿海10海里内速度>15节的船舶轨迹与所属公司信息
SELECT
t.device_id,
s.ship_name,
s.company_name,
t.timestamp,
t.longitude,
t.latitude,
t.speed,
ST_AsText(t.position_gis) AS gis_point -- GIS空间函数:转换为WKT格式
FROM
ship_gps_telemetry t -- 时序表(含GIS列)
JOIN
ship_business_info s -- 关系型业务表(船舶台账)
ON
t.device_id = s.device_id -- 跨表关联键
WHERE
t.timestamp BETWEEN '2026-01-01 00:00:00' AND '2026-01-02 00:00:00'
AND t.speed > 15 -- 指标过滤
AND ST_DWithin( -- GIS空间过滤:距离福建省边界10海里内
t.position_gis,
(SELECT ST_GeographyFromText('POLYGON((117.8 23.5, 120.5 23.5, 120.5 28.5, 117.8 28.5, 117.8 23.5))'))::geography,
18520 -- 10海里 = 18520米
)
ORDER BY
t.timestamp DESC
LIMIT 1000;2.2 事务一致性与高可用的技术保障
2.2.1 时序数据的 ACID 事务实现
金仓基于MVCC(Multi-Version Concurrency Control)机制为时序数据提供完整 ACID 保障,核心技术点:
- 写入事务:时序数据插入时生成版本号,通过 WAL(Write-Ahead Log)日志确保 durability;
- 并发控制:读事务通过快照隔离(Snapshot Isolation)避免脏读,写事务通过行级锁保障原子性;
- 崩溃恢复:基于 Checkpoint+WAL 日志回放,确保时序数据写入的原子性与一致性。
示例:时序数据的事务性写入(Java JDBC 实现):
java
import java.sql.*;
import java.time.LocalDateTime;
public class KingbaseTsdbTransactionExample {
private static final String DB_URL = "jdbc:kingbase8://192.168.1.100:54321/industrial_db?currentSchema=tsdb";
private static final String USER = "sysdba";
private static final String PASSWORD = "kingbase123";
public static void main(String[] args) {
Connection conn = null;
PreparedStatement pstmt = null;
try {
// 1. 加载驱动并建立连接(开启事务自动提交关闭)
Class.forName("com.kingbase8.Driver");
conn = DriverManager.getConnection(DB_URL, USER, PASSWORD);
conn.setAutoCommit(false); // 关闭自动提交,开启事务
// 2. 时序数据批量写入SQL(含多模字段)
String sql = "INSERT INTO ship_gps_telemetry " +
"(device_id, timestamp, longitude, latitude, speed, ship_info, position_gis) " +
"VALUES (?, ?, ?, ?, ?, ?, ST_GeographyFromText(?))";
pstmt = conn.prepareStatement(sql);
// 3. 批量添加数据(模拟3条船舶GPS数据)
String[] deviceIds = {"SHIP-001", "SHIP-002", "SHIP-003"};
double[][] gpsData = {{118.5, 24.3, 16.2}, {119.2, 25.1, 18.7}, {118.9, 24.7, 17.5}};
for (int i = 0; i < deviceIds.length; i++) {
pstmt.setString(1, deviceIds[i]);
pstmt.setTimestamp(2, Timestamp.valueOf(LocalDateTime.now()));
pstmt.setDouble(3, gpsData[i][0]);
pstmt.setDouble(4, gpsData[i][1]);
pstmt.setDouble(5, gpsData[i][2]);
// JSONB字段:船舶状态信息
pstmt.setString(6, "{\"status\":\"normal\",\"fuel\":85.3,\"cargo\":\"container\"}");
// GIS点:WKT格式
pstmt.setString(7, String.format("POINT(%f %f)", gpsData[i][0], gpsData[i][1]));
pstmt.addBatch();
}
// 4. 执行批量写入并提交事务
int[] affectedRows = pstmt.executeBatch();
conn.commit();
System.out.println("时序数据事务写入成功,影响行数:" + affectedRows.length);
} catch (Exception e) {
// 5. 异常回滚
try {
if (conn != null) conn.rollback();
} catch (SQLException se) {
se.printStackTrace();
}
e.printStackTrace();
} finally {
// 6. 资源释放
try {
if (pstmt != null) pstmt.close();
if (conn != null) conn.close();
} catch (SQLException se) {
se.printStackTrace();
}
}
}
}2.2.2 高可用架构部署(分布式集群模式)
金仓时序数据库支持共享存储集群架构 ,基于 KingbaseES 的 RAC(Real Application Clusters)技术,核心配置如下(kingbase.conf关键参数):
# 集群节点配置
cluster_mode = on # 开启分布式集群模式
node_id = 1 # 节点ID(1-8,最多支持8节点集群)
node_list = '192.168.1.100:54321,192.168.1.101:54321,192.168.1.102:54321' # 集群节点列表
# 共享存储配置(使用分布式文件系统)
shared_storage_type = 'glusterfs' # 共享存储类型(支持glusterfs/NFS/SAN)
shared_storage_path = '/kingbase/shared_storage' # 共享存储路径
# 时序数据相关配置
tsdb_write_threads = 32 # 时序写入线程数(建议为CPU核心数的2倍)
tsdb_compression_algo = 'zstd' # 压缩算法
tsdb_partition_cleanup = on # 开启过期分区自动清理
tsdb_partition_retention = '30 days' # 分区保留期(30天)
# 高可用配置
ha_autofailover = on # 开启自动故障转移
ha_failover_timeout = 30 # 故障转移超时时间(30秒)
ha_replica_sync = 'sync' # 副本同步模式(sync/async/semi-sync)2.3 性能优化的技术实践:TSBS 基准测试与调优
使用 TSBS(Time Series Benchmark Suite)对金仓时序数据库进行性能测试,以下是测试配置与结果分析:
2.3.1 TSBS 测试配置文件(kingbase-tsdb-config.yaml)
XML
global:
benchmark: "devops" # 测试场景(devops/iot/finance)
scale: 10000 # 模拟设备数:1万台
duration: 300 # 测试时长:300秒
workers: 16 # 并发工作线程数
batch-size: 1000 # 每批次写入数据量
data-source:
type: "generated" # 生成测试数据
generated:
data-order: "ordered" # 数据顺序:有序(时序场景真实模拟)
value-distribution: "normal" # 指标值分布:正态分布
writer:
type: "postgres" # 金仓兼容PostgreSQL协议
postgres:
host: "192.168.1.100"
port: 54321
user: "sysdba"
password: "kingbase123"
db-name: "tsdb_benchmark"
table-name: "devops_metrics"
ssl-mode: "disable"
batch-size: 1000
max-open-conns: 64
max-idle-conns: 32
query:
type: "tsdb"
tsdb:
queries: [
"high-cardinality-agg", # 高基数聚合查询
"single-groupby-1", # 单维度分组查询
"cross-table-join" # 跨表关联查询
]
query-interval: 1 # 每秒发起1次查询2.3.2 测试执行命令与核心结果
# 1. 生成测试数据(1000万数据点)
tsbs_generate_data --config kingbase-tsdb-config.yaml --output data.csv
# 2. 执行写入性能测试
tsbs_load --config kingbase-tsdb-config.yaml --input data.csv
# 3. 执行查询性能测试
tsbs_run_queries --config kingbase-tsdb-config.yaml --results results.json核心测试结果(单机配置:24 核 CPU、128GB 内存、NVMe SSD):
| 测试项 | 结果 | 优化点说明 |
|---|---|---|
| 写入吞吐量 | 120 万数据点 / 秒 | 并行插入 + 批量提交 + LSM-Tree 写入优化 |
| 单设备单指标查询延迟 | P95 < 10ms | 时间索引 + 分区裁剪 |
| 高基数聚合查询(10 万设备) | P95 < 50ms | 向量化执行 + 预聚合存储 |
| 跨表关联查询延迟 | P95 < 100ms | CBO 优化器 + 索引嵌套循环连接 |
| 存储压缩比 | 1:18(原始:压缩后) | ZSTD+Delta-Delta 混合压缩 |
三、行业级技术落地案例(深度技术细节)
3.1 福建省船舶安全综合管理平台
技术架构
- 部署模式:金仓共享存储集群(3 节点,主 - 备 - 备)
- 数据规模:日写入峰值 1.2 亿数据点,历史数据存储量 1.5PB
- 核心技术方案:
- 分片策略:
TIME_DEVICE_HASH复合分区(1 天 / 分区,设备 ID 哈希 64 分桶); - GIS 优化:基于 R 树索引的空间查询加速,支持 ST_DWithin、ST_Intersects 等 10 + 空间函数;
- 高可用:共享存储 + 实时日志同步,RTO < 30 秒,RPO = 0;
- 数据生命周期:热数据(30 天)存 NVMe SSD,冷数据(30 天 +)迁移至对象存储。
- 分片策略:
核心业务代码片段(地理空间查询优化)
sql
-- 船舶轨迹围栏预警查询(实时计算船舶是否超出指定海域)
CREATE OR REPLACE FUNCTION ship_geofence_alert(
p_fence_wkt TEXT, -- 围栏WKT字符串
p_start_time TIMESTAMPTZ,
p_end_time TIMESTAMPTZ
) RETURNS TABLE (
device_id VARCHAR(64),
alert_time TIMESTAMPTZ,
current_point TEXT,
fence_point TEXT
) AS $$
BEGIN
RETURN QUERY
SELECT
t.device_id,
t.timestamp AS alert_time,
ST_AsText(t.position_gis) AS current_point,
p_fence_wkt AS fence_point
FROM
ship_gps_telemetry t
WHERE
t.timestamp BETWEEN p_start_time AND p_end_time
AND NOT ST_Contains(
ST_GeographyFromText(p_fence_wkt)::geography,
t.position_gis
)
ORDER BY
t.timestamp DESC;
END;
$$ LANGUAGE plpgsql STABLE;
-- 调用示例:查询2026-01-01期间超出福建省沿海围栏的船舶
SELECT * FROM ship_geofence_alert(
'POLYGON((117.8 23.5, 120.5 23.5, 120.5 28.5, 117.8 28.5, 117.8 23.5))',
'2026-01-01 00:00:00',
'2026-01-01 23:59:59'
);3.2 国家电网智能电网调度系统
技术架构
- 部署模式:金仓分布式集群(6 节点,3 主 3 备)
- 核心技术挑战:电力数据高频写入(50 万点 / 秒)、强事务一致性(调度指令与数据同步)、跨系统数据集成;
- 技术解决方案:
- 事务优化:采用
READ COMMITTED隔离级别,MVCC 快照生命周期优化,确保调度数据一致性; - 写入优化:基于 WAL 日志分组刷盘,批量写入阈值动态调整(根据 CPU 负载);
- 集成能力:通过 JDBC/ODBC 接口与 SCADA 系统、EMS 系统实时对接,支持数据双向同步。
- 事务优化:采用
核心配置(kingbase.conf电力场景优化)
# 电力场景时序数据优化
tsdb_metric_precision = 'microseconds' # 时间精度:微秒级(适配电力高频数据)
tsdb_batch_write_threshold = 2000 # 批量写入阈值:2000条/批次
tsdb_wal_sync_method = 'fdatasync' # WAL刷盘方式:fdatasync(平衡性能与可靠性)
# 事务优化
default_transaction_isolation = 'read committed' # 默认隔离级别
mvcc_snapshot_timeout = 60 # 快照超时时间:60秒
max_prepared_transactions = 1000 # 最大预提交事务数
# 网络优化
listen_addresses = '*'
max_connections = 1000 # 支持1000并发连接(适配多系统集成)
shared_buffers = 32GB # 共享缓冲区(内存的25%)
work_mem = 64MB # 工作内存(适配大查询)四、2026 年国产时序数据库技术选型指南(技术维度)
企业技术选型需围绕数据模型兼容性、性能指标、扩展性、运维成本四大核心技术维度,以下提供量化评估方法与工具:
4.1 技术选型评估指标体系
| 评估维度 | 核心指标 | 量化标准 |
|---|---|---|
| 数据模型兼容性 | 多模数据支持类型、查询语义兼容性 | 支持时序 + 关系 + GIS+JSON≥4 种,兼容 SQL/Oracle 语法 |
| 写入性能 | 吞吐量(数据点 / 秒)、延迟(P99) | 单机写入≥50 万点 / 秒,P99 延迟 < 50ms |
| 查询性能 | 聚合查询延迟、跨表关联延迟 | 100 万数据聚合 P95<30ms,跨表关联 P95<100ms |
| 扩展性 | 最大分片数、扩容成本 | 支持分片数≥64,扩容无数据迁移 |
| 事务一致性 | 隔离级别、RPO/RTO | 支持 ACID,RPO=0,RTO<30 秒 |
| 存储效率 | 压缩比、冷热数据分层 | 压缩比≥1:10,支持自动冷热分层 |
| 运维成本 | 监控工具、故障排查、生态集成 | 支持 Prometheus/Grafana,提供 SQL 诊断工具 |
4.2 TCO 计算工具(Python 脚本示例)
python
def calculate_tsdb_tco(
server_cost: float, # 服务器硬件成本(万元)
software_cost: float, # 软件授权成本(万元)
maintenance_cost: float, # 年运维成本(万元)
lifespan: int = 5, # 系统生命周期(年)
data_volume_tb: float, # 年数据量(TB)
storage_cost_per_tb: float = 0.5 # 每TB存储年成本(万元)
) -> float:
"""
计算时序数据库总拥有成本(TCO)
"""
# 硬件成本(按5年折旧)
server_tco = server_cost / lifespan
# 存储成本(年)
storage_tco = data_volume_tb * storage_cost_per_tb
# 年总TCO
annual_tco = server_tco + software_cost + maintenance_cost + storage_tco
# 生命周期总TCO
total_tco = annual_tco * lifespan
return round(total_tco, 2)
# 示例:金仓方案TCO计算(对比独立时序库+关系库方案)
if __name__ == "__main__":
# 金仓方案(融合架构,无需额外关系库)
kingbase_tco = calculate_tsdb_tco(
server_cost=60, # 3节点服务器成本
software_cost=30, # 软件授权成本
maintenance_cost=10, # 年运维成本(复用现有DBA团队)
data_volume_tb=300, # 年数据量300TB
storage_cost_per_tb=0.5
)
# 独立时序库+关系库方案(两套系统)
separate_tco = calculate_tsdb_tco(
server_cost=100, # 时序库3节点+关系库3节点
software_cost=50, # 两套软件授权
maintenance_cost=25, # 两套系统运维成本
data_volume_tb=300,
storage_cost_per_tb=0.5
)
print(f"金仓融合架构TCO(5年):{kingbase_tco}万元")
print(f"独立时序库+关系库TCO(5年):{separate_tco}万元")
print(f"成本节省:{separate_tco - kingbase_tco}万元")运行结果:
金仓融合架构TCO(5年):380.0万元
独立时序库+关系库TCO(5年):675.0万元
成本节省:295.0万元五、技术趋势与未来展望
5.1 核心技术趋势
-
AI - 增强型时序处理 :将 AI 模型嵌入查询优化器(如基于强化学习的索引选择、查询计划生成),金仓已试点
AIBO(AI-Based Optimizer),通过历史查询数据训练模型,优化复杂关联查询计划; -
流批一体与实时智能 :时序数据库与流计算引擎(Flink/Spark Streaming)深度集成,支持
STREAM TABLE语法,示例:sql-- 实时计算船舶速度异常(基于Flink SQL集成) CREATE STREAM TABLE ship_speed_anomaly ( device_id VARCHAR(64), anomaly_time TIMESTAMPTZ, speed FLOAT, anomaly_score FLOAT ) WITH ( connector = 'kingbase-tsdb', table_name = 'ship_gps_telemetry', scan_mode = 'streaming', watermark_delay = '5 seconds' ) AS SELECT device_id, timestamp AS anomaly_time, speed, ts_anomaly_detect(speed, 'isolation_forest') AS anomaly_score -- 内置异常检测算法 FROM ship_gps_telemetry_stream WHERE ts_anomaly_detect(speed, 'isolation_forest') > 0.8; -- 异常分数阈值 -
云原生 Serverless 架构:基于 K8s Operator 实现时序数据库的自动扩缩容、分片动态调整,降低运维复杂度;
-
多模态数据的统一计算框架 :时序数据与视频、音频等非结构化数据的融合处理,通过
AI Pipeline实现端到端智能分析。
5.2 技术挑战与解决方案
| 技术挑战 | 解决方案 |
|---|---|
| 高基数场景查询性能下降 | 分层索引(全局索引 + 局部索引)、预聚合存储 |
| 多模数据关联的性能损耗 | 内核级算子融合、向量化执行引擎 |
| 实时 AI 推理与数据处理耦合 | 内置 AI 模型推理引擎(TensorRT 集成) |
| 跨区域数据同步延迟 | 异步复制 + 本地缓存、边缘节点预计算 |