引言
在上一篇文章中,我们深入探讨了SurfaceFlinger的核心机制和显示系统的整体架构。本文将继续深入显示子系统的底层实现,重点解析图形缓冲区的管理机制和硬件合成的工作原理。
图形缓冲区(GraphicBuffer)是Android显示系统中承载像素数据的核心数据结构,而BufferQueue则实现了生产者-消费者模型来高效管理这些缓冲区。在Android 15中,这些机制经过多年演进已经非常成熟,配合Hardware Composer 3.0硬件合成器,实现了低功耗、高性能的显示输出。
本文将基于Android 15 (AOSP)实际源码,深入分析以下核心内容:
- GraphicBuffer与BufferQueue的生产者-消费者模型
- Gralloc HAL的内存分配与管理机制
- Hardware Composer 3.0的合成策略
- Fence同步机制保证GPU/Display协同工作
系列导航: 这是"Android 15 核心子系统深度解析"系列的第2篇文章。建议先阅读第1篇了解SurfaceFlinger基础。
一、GraphicBuffer与BufferQueue机制
1.1 BufferQueue生产者-消费者模型
BufferQueue是Android显示系统中最核心的组件之一,它实现了一个高效的生产者-消费者模型,用于在应用进程和SurfaceFlinger之间传递图形缓冲区。
架构概览
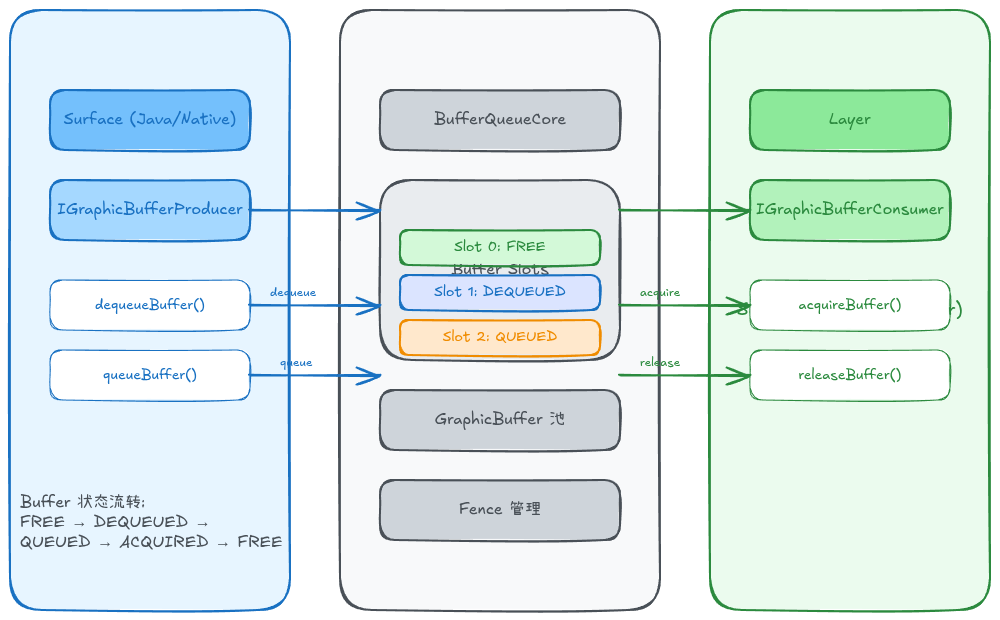
如上图所示,BufferQueue的核心架构包含三个主要部分:
1. 生产者端 (Application进程)
- Surface: 应用持有的绘图表面,封装了IGraphicBufferProducer接口
- IGraphicBufferProducer : Binder接口,提供
dequeueBuffer()、queueBuffer()等方法 - 应用通过Surface进行绘制,实际上是向BufferQueue中放入已渲染的缓冲区
2. BufferQueue核心
- BufferQueueCore: 管理缓冲区池的核心数据结构
- Buffer Slots: 通常包含3个槽位(Slot 0-2),每个槽位可处于不同状态
- 缓冲区状态: FREE(空闲) → DEQUEUED(已获取) → QUEUED(已提交) → ACQUIRED(已消费) → FREE
- GraphicBuffer Pool: 实际的共享内存缓冲区池
- Fence管理: 管理acquireFence和releaseFence,实现GPU/Display同步
3. 消费者端 (SurfaceFlinger进程)
- Layer: SurfaceFlinger中代表一个图层
- IGraphicBufferConsumer : Binder接口,提供
acquireBuffer()、releaseBuffer()等方法 - SurfaceFlinger从BufferQueue中取出缓冲区进行合成
BufferQueueCore源码分析
让我们看看BufferQueueCore的关键数据结构(源码位于frameworks/native/libs/gui/include/gui/BufferQueueCore.h):
cpp
class BufferQueueCore : public virtual RefBase {
friend class BufferQueueProducer;
friend class BufferQueueConsumer;
public:
// 无效槽位标记
enum { INVALID_BUFFER_SLOT = BufferItem::INVALID_BUFFER_SLOT };
// 最大可被acquire的缓冲区数量
enum { MAX_MAX_ACQUIRED_BUFFERS = BufferQueueDefs::NUM_BUFFER_SLOTS - 2 };
// FIFO队列,存储已提交的缓冲区
typedef Vector<BufferItem> Fifo;
BufferQueueCore();
virtual ~BufferQueueCore();
private:
mutable std::mutex mMutex; // 保护所有成员变量的互斥锁
// 缓冲区槽位管理
int getMinUndequeuedBufferCountLocked() const;
int getMaxBufferCountLocked() const;
void clearBufferSlotLocked(int slot);
void freeAllBuffersLocked();
// 核心成员变量
BufferQueueDefs::SlotsType mSlots; // 缓冲区槽位数组
Fifo mQueue; // 已提交的缓冲区队列
int mMaxAcquiredBufferCount; // 最大可acquire数量
int mDefaultWidth; // 默认宽度
int mDefaultHeight; // 默认高度
PixelFormat mDefaultBufferFormat; // 默认像素格式
uint64_t mConsumerUsageBits; // 消费者使用标志
// ...更多成员变量
};关键要点:
- BufferQueueCore使用
mSlots数组管理所有缓冲区槽位mQueue是一个FIFO队列,存储已提交但尚未被消费的缓冲区- 所有操作都通过
mMutex互斥锁保护,确保线程安全
1.2 GraphicBuffer内部结构
GraphicBuffer是对共享内存图形缓冲区的封装,提供了跨进程传递和内存管理的能力。
GraphicBuffer核心属性
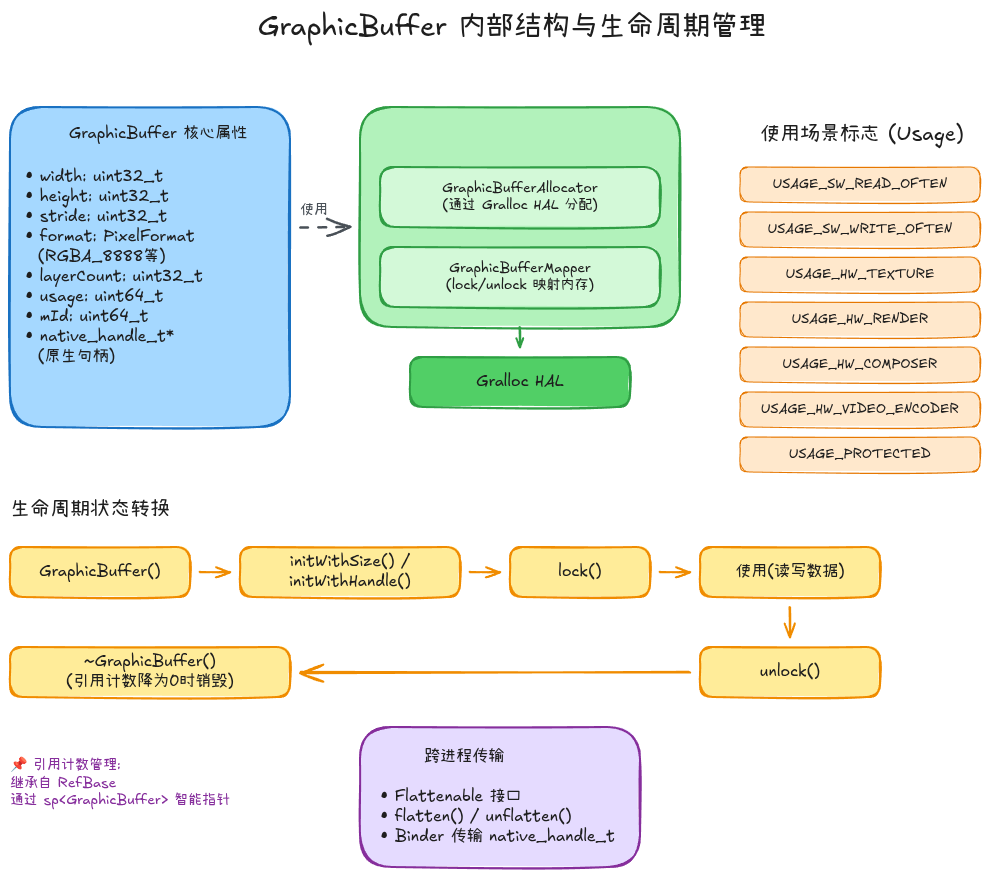
从上图可以看出,GraphicBuffer包含以下核心组件:
1. 核心属性
- width/height/stride: 缓冲区尺寸信息,stride是实际内存中每行的字节数(可能大于width)
- format: 像素格式,如RGBA_8888、YCbCr_420_888等
- layerCount: 图层数量,通常为1,VR场景可能大于1
- usage: 使用标志位,决定内存类型和访问权限
- mId: 全局唯一标识符
- native_handle_t: 原生句柄,指向实际的共享内存
2. 内存管理模块
- GraphicBufferAllocator: 负责通过Gralloc HAL分配内存
- GraphicBufferMapper: 提供lock/unlock方法,将物理内存映射到虚拟地址空间
3. Usage标志详解
GraphicBuffer的usage标志是一个64位的位掩码,决定了缓冲区的使用方式和内存类型:
cpp
enum {
// 软件访问标志
USAGE_SW_READ_NEVER = GRALLOC_USAGE_SW_READ_NEVER, // 软件不读
USAGE_SW_READ_RARELY = GRALLOC_USAGE_SW_READ_RARELY, // 软件偶尔读
USAGE_SW_READ_OFTEN = GRALLOC_USAGE_SW_READ_OFTEN, // 软件频繁读
USAGE_SW_WRITE_NEVER = GRALLOC_USAGE_SW_WRITE_NEVER, // 软件不写
USAGE_SW_WRITE_RARELY = GRALLOC_USAGE_SW_WRITE_RARELY, // 软件偶尔写
USAGE_SW_WRITE_OFTEN = GRALLOC_USAGE_SW_WRITE_OFTEN, // 软件频繁写
// 硬件访问标志
USAGE_HW_TEXTURE = GRALLOC_USAGE_HW_TEXTURE, // GPU纹理
USAGE_HW_RENDER = GRALLOC_USAGE_HW_RENDER, // GPU渲染
USAGE_HW_2D = GRALLOC_USAGE_HW_2D, // 2D硬件加速
USAGE_HW_COMPOSER = GRALLOC_USAGE_HW_COMPOSER, // 硬件合成器
USAGE_HW_VIDEO_ENCODER = GRALLOC_USAGE_HW_VIDEO_ENCODER, // 视频编码器
// 特殊用途标志
USAGE_PROTECTED = GRALLOC_USAGE_PROTECTED, // 安全内容(DRM)
USAGE_CURSOR = GRALLOC_USAGE_CURSOR, // 光标图层
};这些usage标志在内存分配时被Gralloc HAL解析,决定实际分配的物理内存类型(详见1.3节)。
4. 生命周期管理
GraphicBuffer继承自RefBase,使用智能指针sp<GraphicBuffer>进行引用计数管理:
GraphicBuffer创建
↓
initWithSize() / initWithHandle() // 初始化
↓
lock() // 锁定内存,映射到虚拟地址
↓
使用(CPU/GPU读写数据)
↓
unlock() // 解锁内存
↓
~GraphicBuffer() // 引用计数为0时销毁性能优化提示:
- 软件读写频繁的缓冲区应设置USAGE_SW_READ_OFTEN和USAGE_SW_WRITE_OFTEN,这会分配CPU cache友好的内存
- 纯GPU使用的缓冲区应只设置USAGE_HW_TEXTURE/RENDER,避免不必要的CPU缓存一致性开销
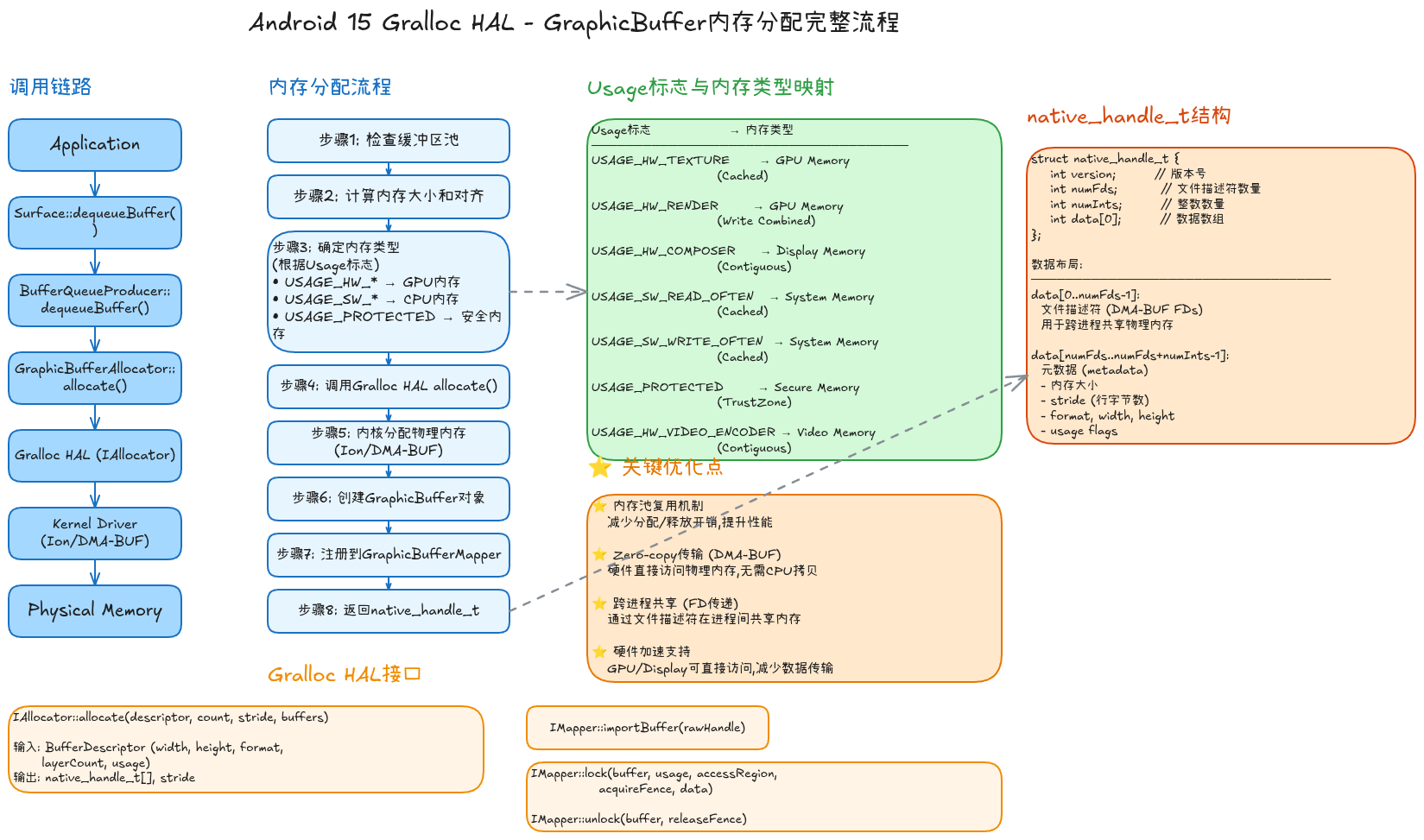
1.3 Gralloc HAL内存分配机制
Gralloc (Graphics Allocator) HAL是Android系统中负责分配图形内存的硬件抽象层接口。它根据usage标志分配不同类型的物理内存。
Gralloc分配流程
从应用请求缓冲区到实际物理内存分配的完整流程包括:
调用链路:
Application (dequeueBuffer)
↓
Surface::dequeueBuffer()
↓
BufferQueueProducer::dequeueBuffer()
↓
GraphicBufferAllocator::allocate()
↓
Gralloc HAL (IAllocator::allocate)
↓
Kernel Driver (Ion/DMA-BUF)
↓
Physical Memory详细步骤:
- 检查缓冲区池: BufferQueueProducer首先检查是否有可复用的缓冲区
- 计算内存大小和对齐: 根据width、height、format计算所需字节数和对齐要求
- 确定内存类型: 根据usage标志映射到具体的内存类型
- 调用Gralloc HAL: 通过IAllocator接口请求分配
- 内核分配物理内存: Gralloc HAL调用Ion或DMA-BUF驱动分配连续物理内存
- 创建GraphicBuffer对象: 封装native_handle_t
- 注册到GraphicBufferMapper: 建立handle到虚拟地址的映射关系
- 返回native_handle_t: 通过Binder传递文件描述符到应用进程
Usage标志到内存类型的映射
| Usage标志 | 内存类型 | 说明 |
|---|---|---|
| USAGE_HW_TEXTURE | GPU Memory (Cached) | GPU可直接访问,支持纹理读取 |
| USAGE_HW_RENDER | GPU Memory (Write Combined) | GPU渲染目标,优化写入性能 |
| USAGE_HW_COMPOSER | Display Memory (Contiguous) | 连续物理内存,Display直接扫描 |
| USAGE_SW_READ_OFTEN | System Memory (Cached) | CPU缓存友好,软件频繁读取 |
| USAGE_SW_WRITE_OFTEN | System Memory (Cached) | CPU缓存友好,软件频繁写入 |
| USAGE_PROTECTED | Secure Memory (TrustZone) | 安全内存,仅TrustZone可访问 |
| USAGE_HW_VIDEO_ENCODER | Video Memory (Contiguous) | 视频编码器专用,连续内存 |
Gralloc HAL接口(Android 15)
Android 15使用AIDL定义的Gralloc 5.0接口:
IAllocator接口 (内存分配):
cpp
// 分配缓冲区
status_t allocate(
const BufferDescriptor& descriptor, // 描述符(width/height/format/usage)
int32_t count, // 分配数量
int32_t* stride, // 返回实际stride
native_handle_t** buffers // 返回句柄数组
);IMapper接口 (内存映射):
cpp
// 导入缓冲区句柄
status_t importBuffer(const native_handle_t* rawHandle);
// 锁定缓冲区,获取虚拟地址
status_t lock(
buffer_handle_t buffer, // 缓冲区句柄
uint64_t usage, // 访问用途
const Rect& accessRegion, // 访问区域
int acquireFence, // 同步fence
void** data // 返回虚拟地址
);
// 解锁缓冲区
status_t unlock(
buffer_handle_t buffer, // 缓冲区句柄
int* releaseFence // 返回同步fence
);native_handle_t结构详解
native_handle_t是跨进程传递缓冲区的核心数据结构:
cpp
typedef struct native_handle {
int version; // 版本号,当前固定为sizeof(native_handle_t)
int numFds; // 文件描述符数量
int numInts; // 整数数量
int data[0]; // 柔性数组,实际数据
// data[0..numFds-1]: 文件描述符(DMA-BUF FDs)
// data[numFds..numFds+numInts-1]: 元数据(stride/format等)
} native_handle_t;关键机制:
- 文件描述符传递: 通过Binder传递FD,实现零拷贝的跨进程内存共享
- DMA-BUF: Linux内核的DMA-BUF机制允许多个设备(GPU/Display/Camera)直接访问同一块物理内存
- 元数据: 存储stride、format、offset等信息,无需额外查询
性能优化要点:
- ⭐ 内存池复用: BufferQueue维护缓冲区池,避免频繁分配/释放
- ⭐ Zero-copy传输: 使用DMA-BUF FD传递,无需内存拷贝
- ⭐ 跨进程共享: 通过Binder传递FD,多进程可访问同一物理内存
- ⭐ 硬件加速支持: GPU/Display可直接DMA访问,无需CPU干预
二、Hardware Composer 3.0硬件合成
2.1 HWC 3.0架构概览
Hardware Composer (HWC) 是Android显示系统中负责硬件合成的关键组件。在Android 15中,HWC已经升级到3.0版本,使用AIDL接口替代了之前的HIDL。
HWC的核心职责:
- 决定每个Layer使用GPU合成还是硬件Overlay合成
- 管理硬件Overlay资源(通常有限,如2-4个)
- 协调Display硬件进行最终输出
- 提供VSync和热插拔事件通知
2.2 合成类型与策略
Android 15定义了7种合成类型,每种对应不同的硬件处理方式。
合成类型详解
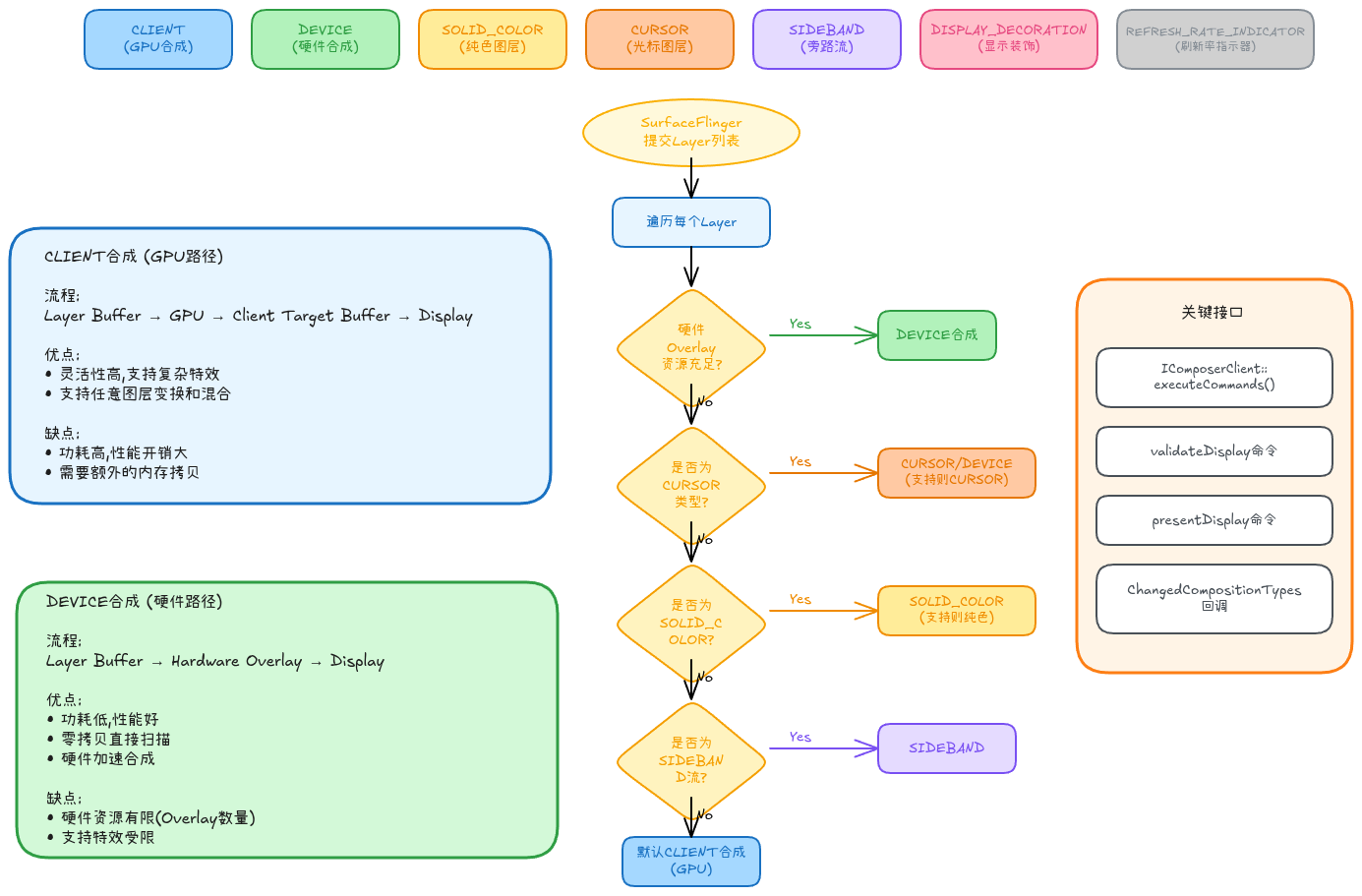
如上图所示,HWC 3.0定义的合成类型包括(源码位于hardware/interfaces/graphics/composer/aidl/android/hardware/graphics/composer3/Composition.aidl):
cpp
enum Composition {
INVALID = 0,
/**
* CLIENT: GPU合成
* SurfaceFlinger必须将此Layer合成到Client Target Buffer中
* HWC不得请求更改此类型
*/
CLIENT = 1,
/**
* DEVICE: 硬件Overlay合成
* HWC通过硬件Overlay或其他硬件方式处理
* validateDisplay时,HWC可以请求改为CLIENT
*/
DEVICE = 2,
/**
* SOLID_COLOR: 纯色图层
* HWC使用setLayerColor设置的颜色渲染
* 如果硬件不支持,HWC应请求改为CLIENT
*/
SOLID_COLOR = 3,
/**
* CURSOR: 光标图层
* 类似DEVICE,但支持通过setCursorPosition异步更新位置
* 如果不支持,HWC应请求改为DEVICE或CLIENT
*/
CURSOR = 4,
/**
* SIDEBAND: 旁路流
* HWC直接处理缓冲区更新和同步,无需SurfaceFlinger介入
* 仅在支持Capability.SIDEBAND_STREAM的设备上可用
*/
SIDEBAND = 5,
/**
* DISPLAY_DECORATION: 显示装饰层
* 用于屏幕刘海和圆角的抗锯齿处理
* 仅在getDisplayDecorationSupport返回有效值时可用
*/
DISPLAY_DECORATION = 6,
/**
* REFRESH_RATE_INDICATOR: 刷新率指示器
* 类似DEVICE,但更新不被视为"活动",不会重置省电模式计时器
*/
REFRESH_RATE_INDICATOR = 7,
}合成策略决策流程
SurfaceFlinger在每帧合成时,通过以下流程决定每个Layer的合成方式:
-
SurfaceFlinger提交Layer列表
- 调用
IComposerClient::executeCommands()提交所有Layer配置
- 调用
-
HWC遍历每个Layer,执行validateDisplay逻辑:
决策点1: 硬件Overlay资源是否充足?
- Yes → 标记为DEVICE合成(最优)
- No → 继续判断其他条件
决策点2: 是否为特殊类型Layer?
- CURSOR类型 → 检查硬件是否支持异步位置更新
- 支持 → CURSOR
- 不支持 → DEVICE或CLIENT
- SOLID_COLOR类型 → 检查硬件是否支持纯色渲染
- 支持 → SOLID_COLOR
- 不支持 → CLIENT
- SIDEBAND类型 → 检查是否支持旁路流
- 支持 → SIDEBAND
- 不支持 → DEVICE或CLIENT
默认 → CLIENT合成(通过GPU)
-
HWC返回ChangedCompositionTypes
- 如果某些Layer无法使用硬件合成,HWC会请求SurfaceFlinger改用CLIENT合成
-
SurfaceFlinger执行合成
- 对于CLIENT类型: 使用GPU合成到Client Target Buffer
- 对于DEVICE类型: 直接传递给Display硬件
CLIENT vs DEVICE合成对比
| 特性 | CLIENT合成(GPU) | DEVICE合成(硬件Overlay) |
|---|---|---|
| 执行路径 | Layer Buffer → GPU → Client Target → Display | Layer Buffer → Hardware Overlay → Display |
| 功耗 | 较高(GPU启动功耗大) | 较低(无需GPU参与) |
| 性能 | 取决于GPU负载 | 固定延迟,性能稳定 |
| 特效支持 | 支持任意复杂特效(旋转/缩放/混合) | 受硬件能力限制 |
| 内存拷贝 | 需要拷贝到Client Target | Zero-copy直接DMA |
| 资源限制 | 无限制(仅受GPU性能限制) | 硬件Overlay数量有限(通常2-4个) |
| 适用场景 | 多窗口/特效丰富/Layer数量超过Overlay数 | 全屏视频/简单UI |
实战经验:
- 全屏视频播放时,应优先使用DEVICE合成,显著降低功耗
- 多窗口场景下,由于Overlay数量限制,大部分Layer会退化为CLIENT合成
- CURSOR类型可以实现零延迟的鼠标移动(无需等待VSync)
2.3 validateDisplay与presentDisplay
HWC的核心工作流程包含两个关键阶段:
validateDisplay阶段
cpp
// SurfaceFlinger调用
CommandResultPayload[] executeCommands(DisplayCommand[] commands);在validateDisplay阶段,HWC执行以下工作:
-
检查每个Layer的合成类型请求
-
评估硬件资源(Overlay数量、格式支持、变换支持等)
-
决策合成策略 :
- 如果硬件资源充足且支持Layer属性 → 保持DEVICE
- 如果硬件资源不足或不支持 → 请求改为CLIENT
-
返回ChangedCompositionTypes :
cppstruct ChangedCompositionTypes { long display; ChangedCompositionLayer[] layers; // 需要改变类型的Layer列表 }
presentDisplay阶段
经过validateDisplay确认后,SurfaceFlinger调用presentDisplay提交最终合成:
cpp
// 提交Display输出
void presentDisplay(long display);在presentDisplay阶段:
- CLIENT类型Layer: SurfaceFlinger已经用GPU合成到Client Target Buffer
- DEVICE类型Layer: HWC直接配置硬件Overlay指向Layer Buffer
- Display硬件扫描输出 :
- Overlay层直接DMA读取Layer Buffer
- Client Target作为底层背景
- 硬件合成器将多个源混合输出到屏幕
2.4 IComposerClient关键接口
让我们看看HWC 3.0的核心接口(源码位于hardware/interfaces/graphics/composer/aidl/android/hardware/graphics/composer3/IComposerClient.aidl):
cpp
interface IComposerClient {
// 创建Layer
long createLayer(long display, int bufferSlotCount);
// 销毁Layer
void destroyLayer(long display, long layer);
// 执行命令(包含validateDisplay/presentDisplay等)
CommandResultPayload[] executeCommands(DisplayCommand[] commands);
// 获取显示能力
DisplayCapability[] getDisplayCapabilities(long display);
// 获取HDR能力
HdrCapabilities getHdrCapabilities(long display);
// 设置电源模式
void setPowerMode(long display, PowerMode mode);
// 设置VSync使能
void setVsyncEnabled(long display, boolean enabled);
// 注册回调(VSync/Hotplug/Refresh等)
void registerCallback(IComposerCallback callback);
// 获取Overlay支持信息
OverlayProperties getOverlaySupport();
}关键要点:
- executeCommands是批量操作接口,一次调用可执行多个命令,减少Binder调用开销
- registerCallback注册的回调会异步通知VSync、热插拔等事件
- Android 15新增了HDR转换能力查询(
getHdrConversionCapabilities)
三、Fence同步机制
3.1 Fence的作用
在异步的图形系统中,GPU渲染、SurfaceFlinger合成、Display扫描是并行执行的。Fence (同步栅栏) 机制用于协调这些异步操作,确保数据的正确性。
核心问题:
- GPU渲染完成前,SurfaceFlinger不能读取Buffer
- SurfaceFlinger合成完成前,Display不能扫描Buffer
- Display扫描完成前,Application不能重用Buffer
解决方案: 使用acquireFence和releaseFence标记关键同步点。
3.2 Fence同步时序图
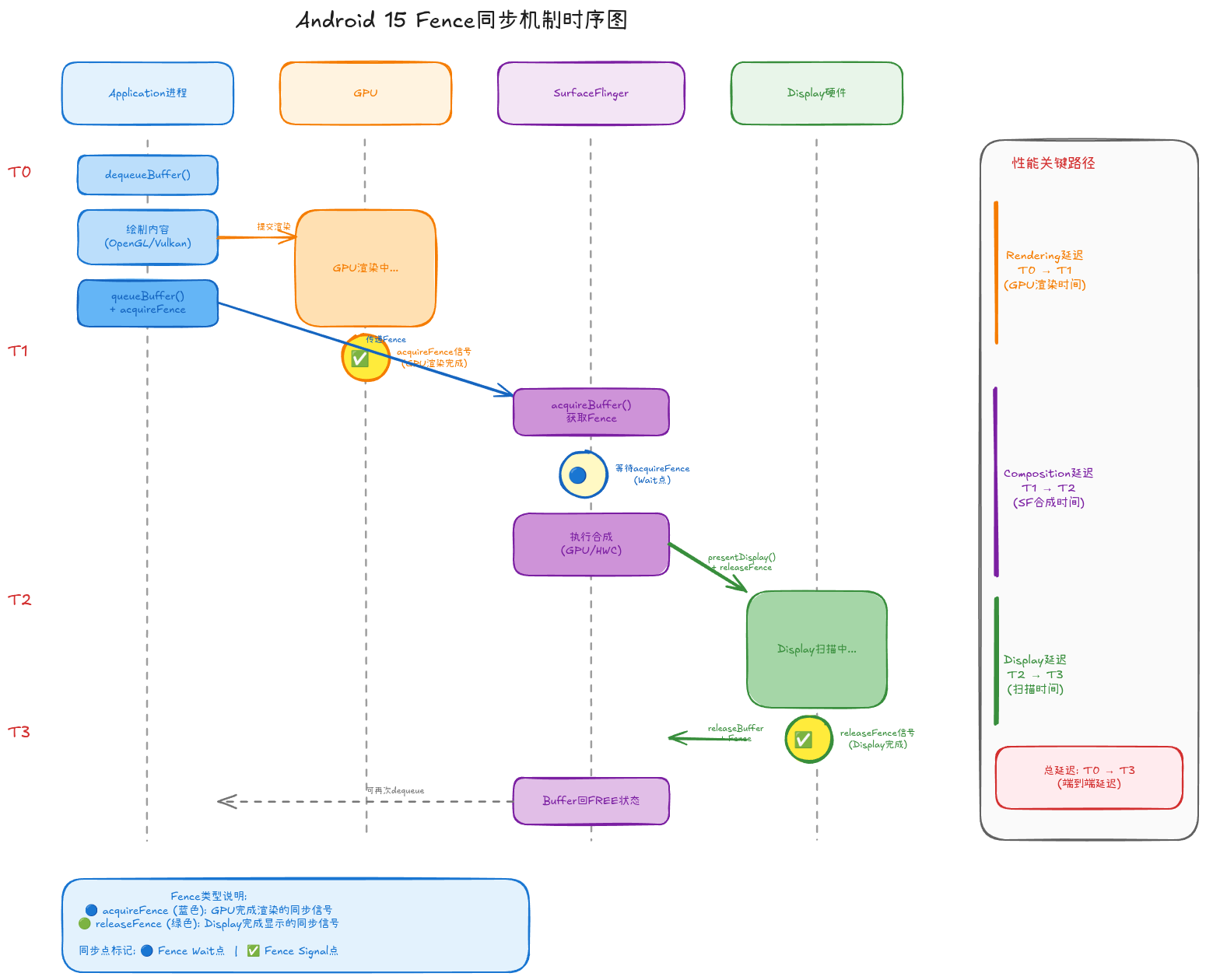
如上图所示,一个完整的帧从应用绘制到显示输出的Fence同步流程包括:
阶段1: 应用绘制 (T0)
cpp
// 1. 获取空闲Buffer
int slot;
sp<Fence> fence;
surface->dequeueBuffer(&slot, &fence);
// 2. 绘制内容(OpenGL ES / Vulkan)
// GPU异步执行渲染命令
// 3. 提交Buffer,创建acquireFence
sp<Fence> acquireFence = eglDupNativeFenceFDANDROID(display, sync);
surface->queueBuffer(slot, acquireFence);acquireFence的含义: GPU渲染完成的信号量
阶段2: 等待GPU完成 (T0 → T1)
- GPU异步执行渲染命令
- acquireFence处于未信号状态
- 当GPU渲染完成 → acquireFence发出信号 (✅ Signal点)
阶段3: SurfaceFlinger合成准备 (T1)
cpp
// 1. 获取Buffer
BufferItem item;
consumer->acquireBuffer(&item);
// 2. 等待acquireFence
item.mFence->wait(timeout); // 🔵 Fence Wait点
// 3. 执行合成(GPU合成或HWC合成)阶段4: 提交Display (T2)
cpp
// 1. 提交给Display硬件,创建releaseFence
sp<Fence> releaseFence = hwc->presentDisplay(display);
// 2. releaseFence: Display扫描完成的信号量releaseFence的含义: Display扫描完成的信号量
阶段5: Display扫描 (T2 → T3)
- Display硬件开始扫描输出
- releaseFence处于未信号状态
- 当Display扫描完成 → releaseFence发出信号 (✅ Signal点)
阶段6: 缓冲区回收 (T3)
cpp
// 1. 释放Buffer,传递releaseFence
consumer->releaseBuffer(slot, releaseFence);
// 2. Buffer回到FREE状态
// 3. Application可以再次dequeueBuffer获取此Buffer3.3 Fence的实现机制
Fence在Linux内核中通过Sync Framework实现,Android使用的是sync_file + 文件描述符机制。
Sync Timeline与Sync Point
Timeline: GPU Timeline
|
|---- Sync Point 1 (Frame 100) -----> acquireFence1 (FD=10)
|---- Sync Point 2 (Frame 101) -----> acquireFence2 (FD=11)
|---- Sync Point 3 (Frame 102) -----> acquireFence3 (FD=12)- Sync Timeline: 驱动维护的递增序列(如GPU命令序列号)
- Sync Point: Timeline上的某个点(如GPU完成Frame 100的渲染)
- Sync File : 对应一个Sync Point的文件描述符,可通过
poll()或wait()等待信号
Fence API
cpp
class Fence : public LightRefBase<Fence> {
public:
static const sp<Fence> NO_FENCE; // 无需等待的特殊Fence
// 等待Fence信号,可设置超时
status_t wait(int timeout);
// 非阻塞检查是否已信号
status_t getSignalTime(nsecs_t* signalTime);
// 获取文件描述符
int dup() const;
private:
int mFenceFd; // 内核sync_file的文件描述符
};性能优化提示:
- Fence wait是阻塞操作,应在单独的线程中执行,避免阻塞主线程
- 可以使用
merge()合并多个Fence,等待所有条件满足- 已信号的Fence可以用NO_FENCE替代,减少FD传递开销
3.4 延迟分析
从上述时序图可以提取出关键性能指标:
| 延迟类型 | 时间范围 | 典型值(60Hz) | 说明 |
|---|---|---|---|
| Rendering延迟 | T0 → T1 | 2-8ms | GPU渲染时间,取决于场景复杂度 |
| Composition延迟 | T1 → T2 | 1-3ms | SurfaceFlinger合成时间 |
| Display延迟 | T2 → T3 | 16.6ms | 一个VSync周期,Display扫描时间 |
| 总延迟 | T0 → T3 | 20-28ms | 端到端延迟,约1-2帧 |
优化建议:
- 减少Rendering延迟: 优化渲染命令,使用Vulkan替代OpenGL ES
- 减少Composition延迟: 优先使用DEVICE合成,减少GPU合成开销
- 减少Display延迟: 使用VRR(Variable Refresh Rate)技术,动态调整刷新率
四、实战调试技巧
4.1 查看BufferQueue状态
bash
# 查看所有Surface的BufferQueue状态
adb shell dumpsys SurfaceFlinger
# 查看特定应用的BufferQueue
adb shell dumpsys SurfaceFlinger --list | grep com.example.app
adb shell dumpsys SurfaceFlinger <layer_id>关键信息:
mQueue: 当前队列中的Buffer数量mMaxAcquiredBufferCount: 最大可acquire数量mBufferAge: Buffer的使用次数- Fence状态: 每个Buffer的acquireFence和releaseFence状态
4.2 查看HWC合成策略
bash
# 查看当前合成类型
adb shell dumpsys SurfaceFlinger --display-info
# 强制使用GPU合成(调试用)
adb shell service call SurfaceFlinger 1008 i32 1 # disable HWC
# 恢复硬件合成
adb shell service call SurfaceFlinger 1008 i32 0 # enable HWC输出示例:
Layer com.example.app/MainActivity:
Composition: DEVICE # 硬件Overlay合成
CompositionType: DEVICE
Layer StatusBar:
Composition: CLIENT # GPU合成
CompositionType: CLIENT4.3 查看Fence延迟
bash
# 查看Fence统计信息
adb shell dumpsys SurfaceFlinger --fences
# 查看GPU Timeline
adb shell cat /sys/kernel/debug/sync/sw_sync输出示例:
Fence: acquireFence FD=45
Signaled: Yes
Signal Time: 1234567890 (2.5ms ago)
Fence: releaseFence FD=46
Signaled: No
Timeout: 16ms4.4 抓取GraphicBuffer快照
bash
# 截取屏幕(包含所有Layer)
adb shell screencap -p /sdcard/screenshot.png
adb pull /sdcard/screenshot.png
# 抓取特定Layer的Buffer
adb shell dumpsys SurfaceFlinger --capture-layer <layer_name>4.5 监控内存使用
bash
# 查看Graphics内存统计
adb shell dumpsys meminfo <package_name> | grep Graphics
# 查看Gralloc分配情况
adb shell cat /sys/kernel/debug/ion/heaps/system输出示例:
Graphics: 52340 kB # GraphicBuffer占用内存
GL: 8192 kB # GPU驱动内存五、Android 15的新特性
5.1 Gralloc 5.0 AIDL接口
Android 15将Gralloc从HIDL迁移到AIDL,带来以下改进:
- 更好的版本兼容性
- 更低的Binder调用开销
- 支持跨语言实现(C++/Rust/Java)
5.2 HWC 3.0增强
- 新增
REFRESH_RATE_INDICATOR合成类型,用于自适应刷新率 - 支持
notifyExpectedPresent()早期提示,优化VRR场景 - 增强HDR转换能力查询和策略设置
5.3 BufferQueue优化
- 引入
setMaxDequeuedBufferCount()动态调整缓冲区数量 - 优化Triple-buffering策略,减少Jank
- 改进Fence等待机制,降低延迟
总结
本文深入分析了Android 15显示子系统的图形缓冲区管理和硬件合成机制:
- BufferQueue生产者-消费者模型是应用与SurfaceFlinger之间传递缓冲区的桥梁,通过状态机管理缓冲区生命周期
- GraphicBuffer封装了共享内存,通过native_handle_t实现零拷贝跨进程传递
- Gralloc HAL根据usage标志分配不同类型的物理内存,支持GPU/Display/CPU多方访问
- HWC 3.0智能决策合成策略,在硬件Overlay和GPU合成之间平衡性能与功耗
- Fence同步机制协调GPU/SurfaceFlinger/Display的异步操作,确保数据一致性
这些机制共同构成了Android显示系统的高性能基础。理解这些底层原理,能够帮助我们:
- 优化应用的渲染性能
- 诊断显示相关的疑难问题
- 进行系统级的性能调优
- 为后续的ROM定制和驱动开发打下基础
参考资源
源码路径(AOSP 15)
frameworks/native/libs/gui/ # BufferQueue实现
frameworks/native/libs/ui/ # GraphicBuffer实现
frameworks/native/services/surfaceflinger/ # SurfaceFlinger
hardware/interfaces/graphics/composer/ # HWC 3.0 AIDL接口
hardware/interfaces/graphics/allocator/ # Gralloc AIDL接口
system/core/libsync/ # Fence实现官方文档
推荐阅读
系列文章
欢迎来我中的个人主页找到更多有用的知识和有趣的产品