1.存储
存储过程就是一组特定的SQL语句集,说白了就是一个SQL集合,直接调用去操作
2.变量
变量有系统变量,用户自定义变量,局部变量
这个命令是查看所有的系统变量,也可以设置系统变量
SHOW GLOBAL\|SESSION VARIABLES
用户自定义变量,听名字就知道是用户自己定义的,当前会话有效
局部变量更小了,跟那个函数一样,理解一下
bash
-- 创建存储过程
CREATE PROCEDURE p2()
BEGIN
-- 定义初始分数变量
DECLARE score INT DEFAULT 86;
-- 定义等级结果变量
DECLARE result VARCHAR(10);
-- 判断
IF score >= 90 THEN
SET result := '优秀';
ELSEIF score >= 80 AND score < 90 THEN
SET result := '良好';
ELSEIF score >= 60 AND score < 80 THEN
SET result := '及格';
ELSE
SET result := '不及格';
END IF;
-- 查询结果
SELECT result;
END;
-- 调⽤存储过程
CALL p2();下面是重点日志
redolog物理日志
undolog事务日志
binlog逻辑日志
error log 错误日志
binlog是逻辑日志,记录了执行的SQL语句,但是不会记录查询和SHOW,记录了所有的DDL,和DML语句
拿到一个MySQL的二进制日志就拿到了这个MySQL的数据,就可以进行跨AZ恢复,所以随着数据库的运行,日志占用的空间越来越多,所以就需要把binlog定期清理,设置过期时间,过期自动清理
binlog有基于sql语句记录,基于行,混合
sql语句模式,记录sql语句,行模式记录变化前后的数据,混合就是混合的
binlog就可以通过行数据变更,binlog作为恢复日志,一定是要落盘的,binlog丢失,数据就无法进行回滚了,但是肯定有其他的日志可以进行回滚
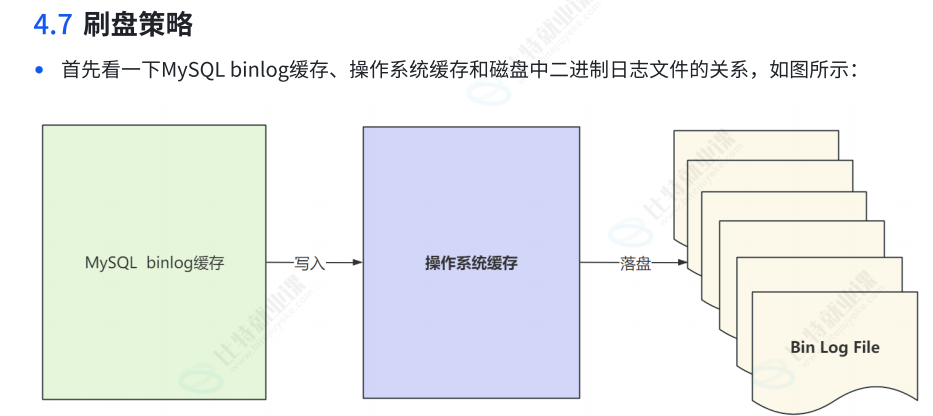
binlog里面记录了数据的变更,那么我们就可以得到这个数据完整的变更过程,就可以对它进行恢复等一系列操作了。
备份
数据库的备份是非常常见的,一份数据如果丢失,没有备份就很难办,逻辑备份就是生成sql语句,恢复的时候很简单啊,再次执行所有的SQL语句,物理备份,直接复制所有的文件。
逻辑复制复制的是sql语句,几乎可以全平台数据库通用,但是就比较慢,因为要解析SQL,执行一些列操作,SQL语句的底层也是代码执行,要涉及到各种锁什么的,恢复起来非常慢
物理复制直接就是简单粗暴的复制文件,同样的环境可以恢复,但是一旦换了环境,就很难了
mysql自带的mysqldump就是逻辑备份,记录的是SQL语句
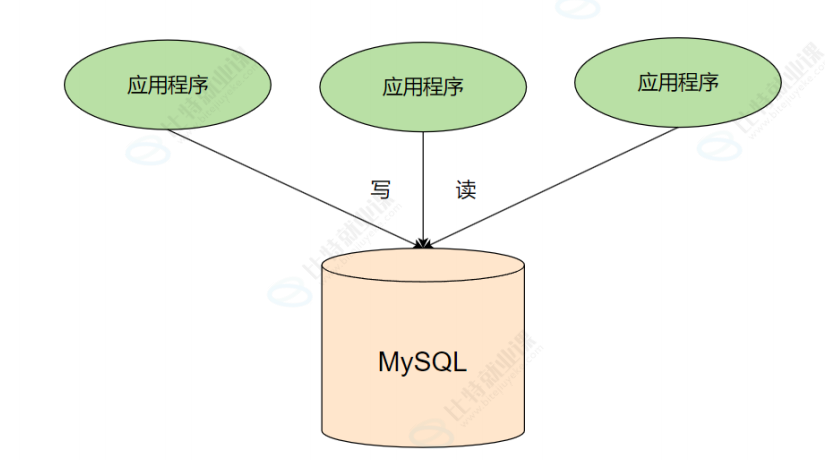
MySQL集群,MySQL集群是为了专门为高并发而生的一个集群,如果只有一个MySQL,多个应用程序都访问这一个数据库,随着流量的增加,数据库的压力越来越大
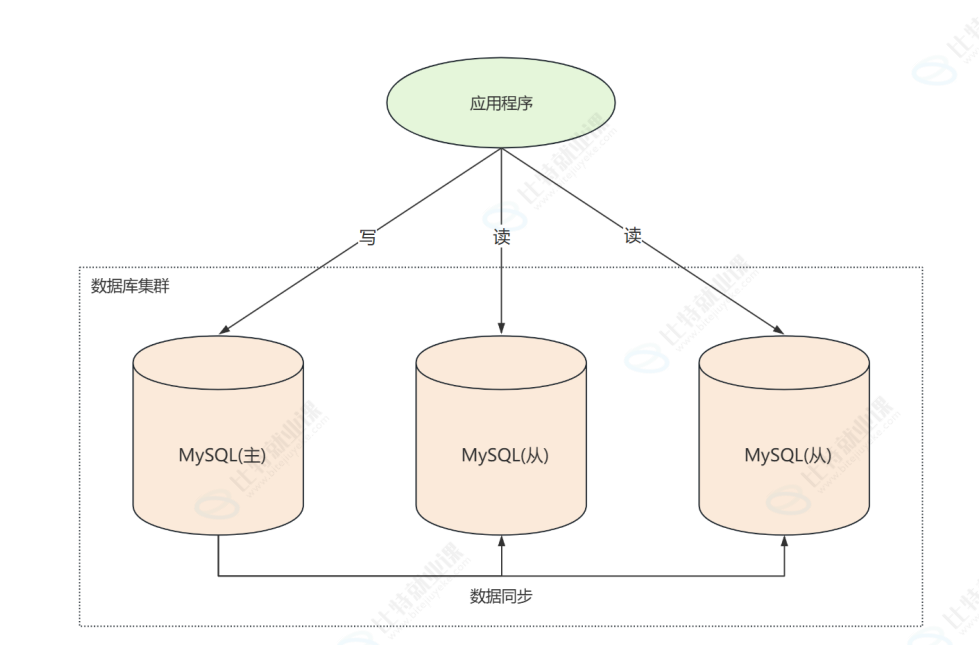
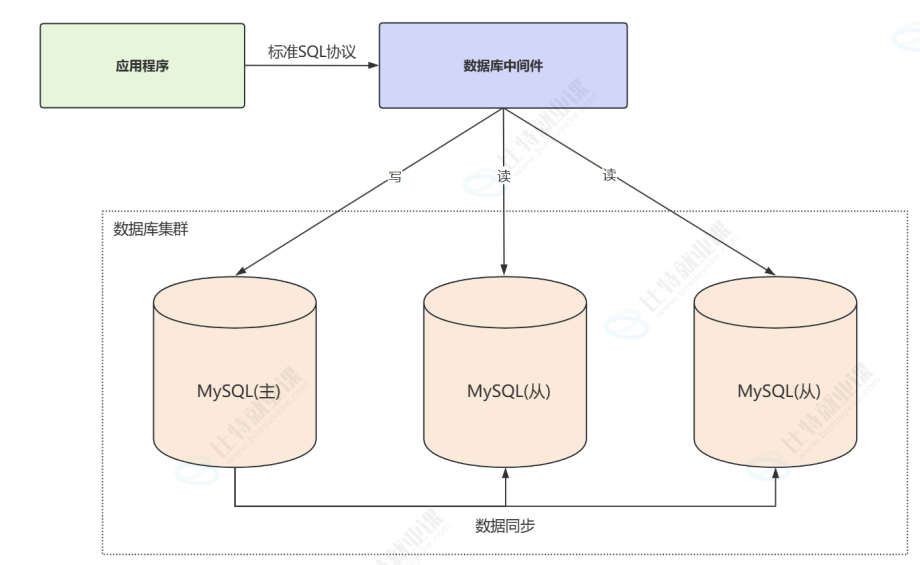
主服务器,主服务器负责写和简单查询的工作,从服务器负责备份和复杂查询,这就要进行主从复制了
主从复制可以保证从服务器与主服务器的数据⼀致,基本原理是:主服务器将DML和DDL操作记
录到binlog,从服务器通过复制主服务器的binlog,并且把binlog中记录的操作转换为SQL,在从服务
器进⾏回放(重新执⾏),从⽽保证从服务器数据库中的数据与主服务器数据库中的数把的⼀致性。
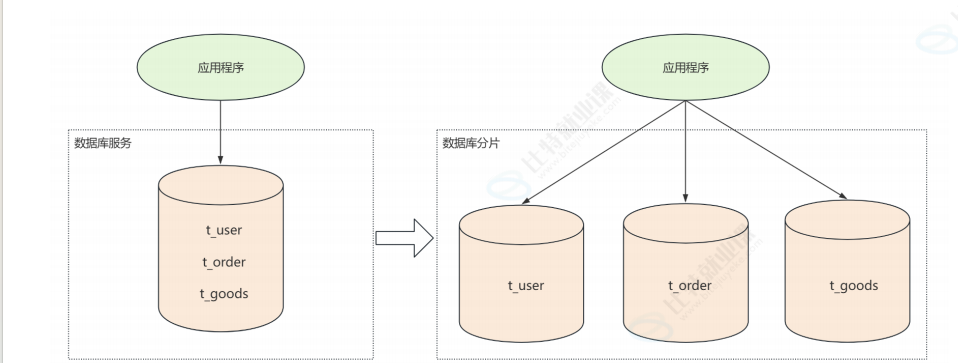
MySQL高性能一般是读写分离,架构主从负责一部分,还有就是分片,完整的数据拆分为小片数据每个数据库保存一小部分,这个就是数据库分片
数据备份和恢复:通过主从复制,可以实现实时数据备份,确保数据安全。当主服务器出现问题
时,从服务器可以随时接管服务,保证数据的⼀致性和业务的连续性。
•
读写分离:将写操作分发到主服务器,读操作分发到从服务器,减轻主服务器的压⼒,提⾼系统并
发处理能⼒。主从复制⽀持⼤规模⾼并发读写,同时有效地保护了物理服务器宕机场景的数据备
份。
•
负载均衡:由于主从数据节点都有完整的数据,可以通过⼀定的策略或规则,将负载分摊到多个不
同的数据节点,提⾼系统的负载均衡能⼒。
系统的可⽤性:当主数据库出现故障时,从数据库可以⽴即接管⼯作,保证系统的正常运⾏。
系统的可靠性:通过将数据复制到多个数据库中,可以避免单点故障,提⾼系统的可靠性。
系统的可扩展性:通过对等复制或分区复制,可以将⼀个⼤型数据库分成多个⼩型数据库,提⾼系统
的可扩展性。
把数据存在多个数据数据服务器中,每个数据库保存的数据⼀致,多个数据库可以同时对外
提供服务
主从分离带来很多的好处,一来可以实现负载均衡,主库在出现故障的时候也可以把数据转移到从库,主从库之间也可以进行数据同步
数据库也可以进行分片,把一份数据搞到多个服务器的MySQL上进行压力分摊,数据分片分为垂直分片,水平分片
读写分离就是主从分离了,主库master负责所有的修改数据操作,从负责查询,不就是分担压力了吗
再对从库进行负载均衡的算法实现,就可以对从库实现压力的均摊。
也可以进行故障转移,当主挂掉之后,从可以进行选举当选为新的主。
但是随之而来的,主库和从库之间会存在一定的延迟。
分库分表之后可以进行封装,加一个中间件,让上层访问的时候和访问正常的数据库是一样的,但是底层已经进行了分库分表的操作了。
CAP理论,C代表一致性,当主库执行写入操作后,主从数据需要保持一致,写入操作执行后,读的数据必须是最新的。
A可用性,数据库需要在故障的时候也要进行服务的提供
P网络故障的时候也要提供服务,就是节点间通信失败,也要提供服务
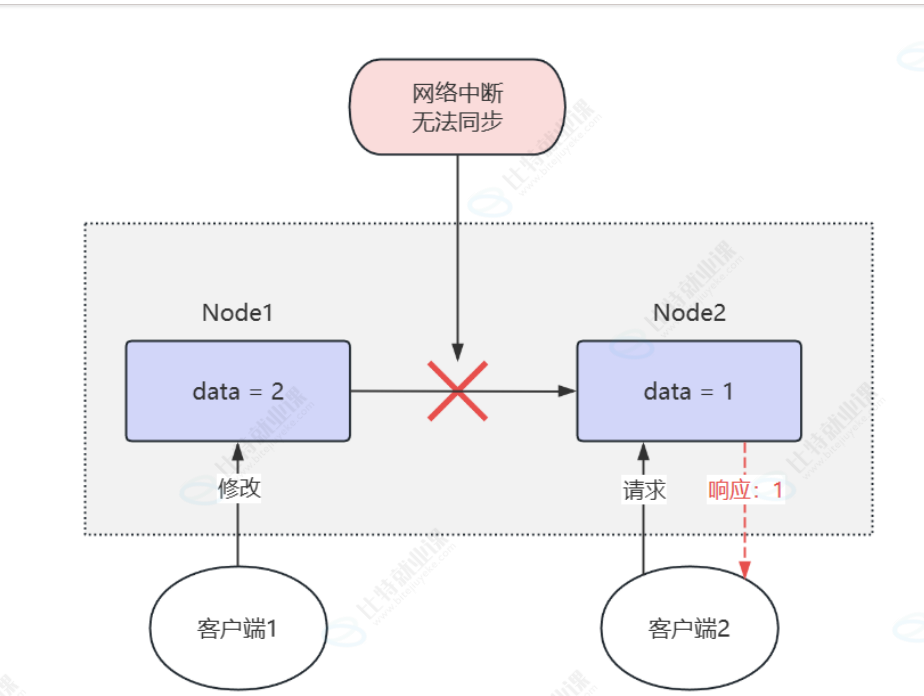
CAP理论认为CAP三个目标只能实现2个,所以要实现2个必须抛弃其他两个,但是网络问题在分布式数据库是必然会出现的问题,所以我们必须做出选择,抉择的时候到了,所以要么是CP,要么AP,要么是保证一致,当复制通道发生中断的时候,NODE1节点数据从1变成2,但是NODE2没有办法得知,所以NODE2还是1,所以当客户端请求数据的时候,需要返回ERROR,这个时候就无法对外提供服务了,保证了一致性,就无法保证可用性,比如银行这种强一致性的场景,钱扣掉宁可不提供服务,也不可以提供错误的数据。
高可用是即使复制通道挂掉,节点之间无法通信了,但是还要提供一个合理的值,就是AP,高可用和节点无法通信的做法,允许节点之间出现短暂的不一样