视频讲解:
https://www.bilibili.com/video/BV1bEktBAEVs/?spm_id_from=333.1387.homepage.video_card.click
页面展示:
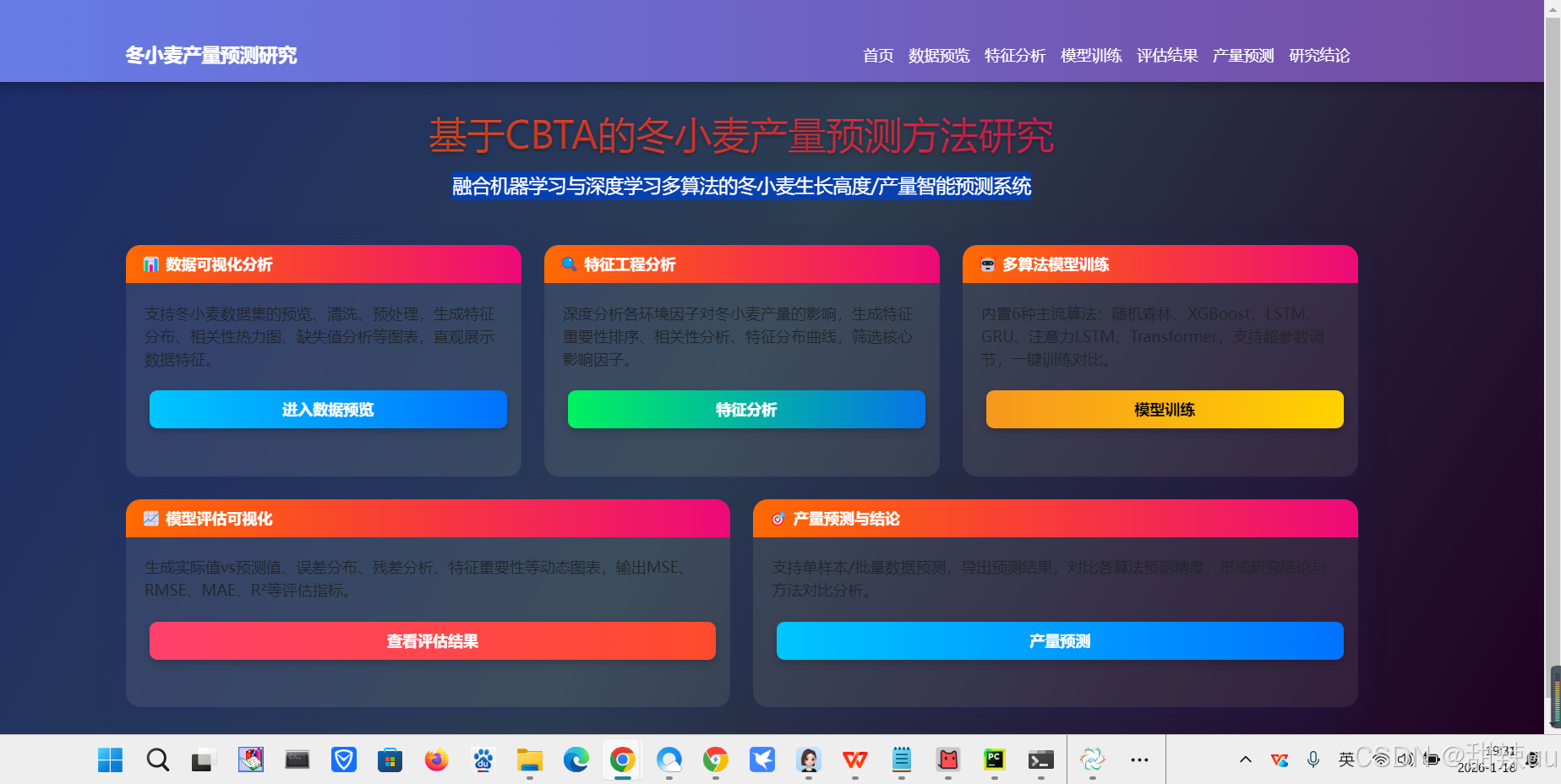
引言
研究背景与意义:冬小麦产量预测对农业决策的重要性
现有技术局限性:传统方法在复杂环境下的不足
创新点:多算法融合提升预测精度
相关技术综述
机器学习方法:随机森林、支持向量机在农业预测中的应用
深度学习方法:LSTM、CNN处理时序与空间数据的优势
多算法融合策略:集成学习与模型堆叠的可行性分析
系统架构设计
数据采集层:卫星遥感、气象站与地面传感器的多源数据整合
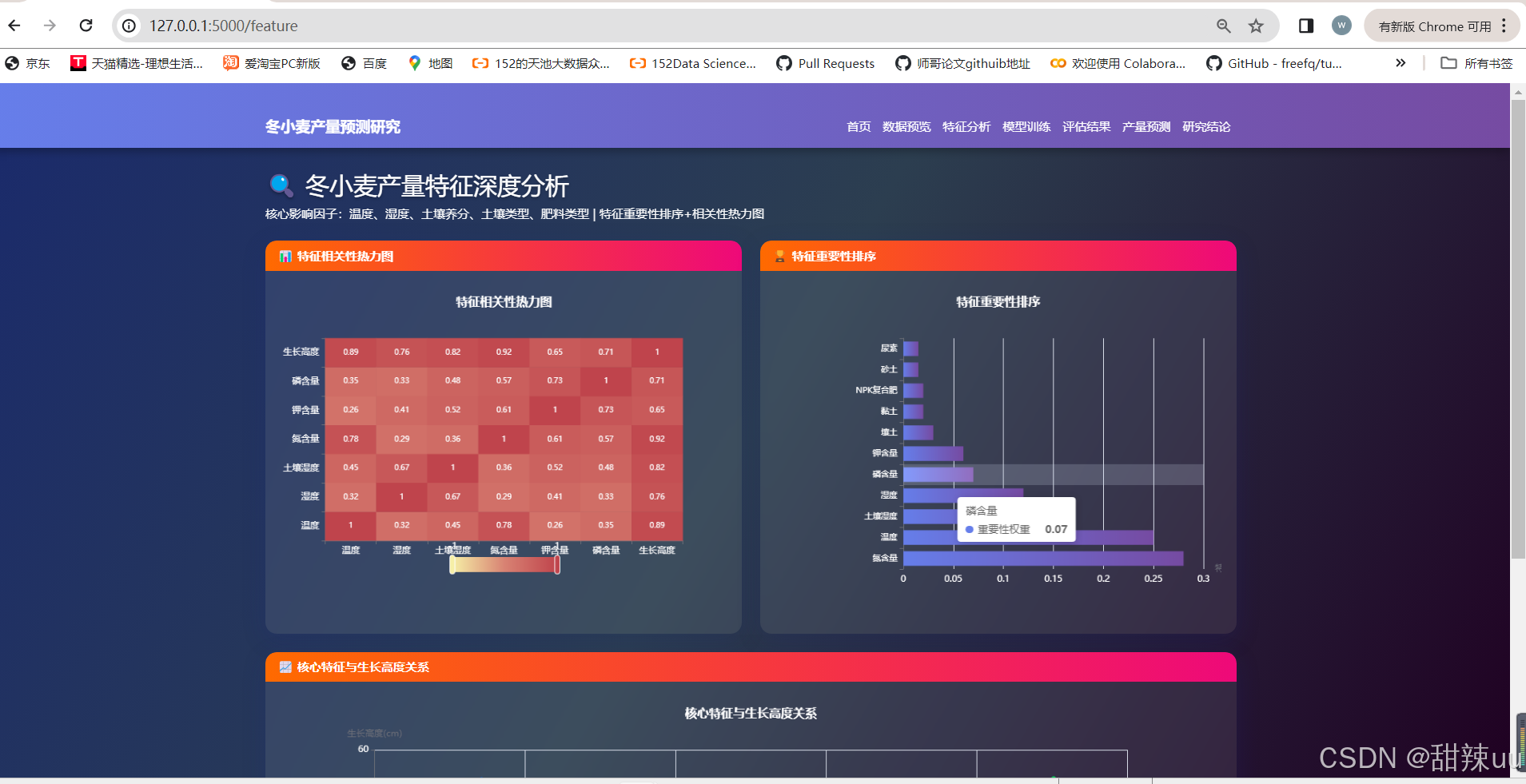
特征工程模块:关键生长参数(NDVI、土壤湿度等)的提取与优化
算法融合层:基于加权投票或元学习的多模型协同预测机制
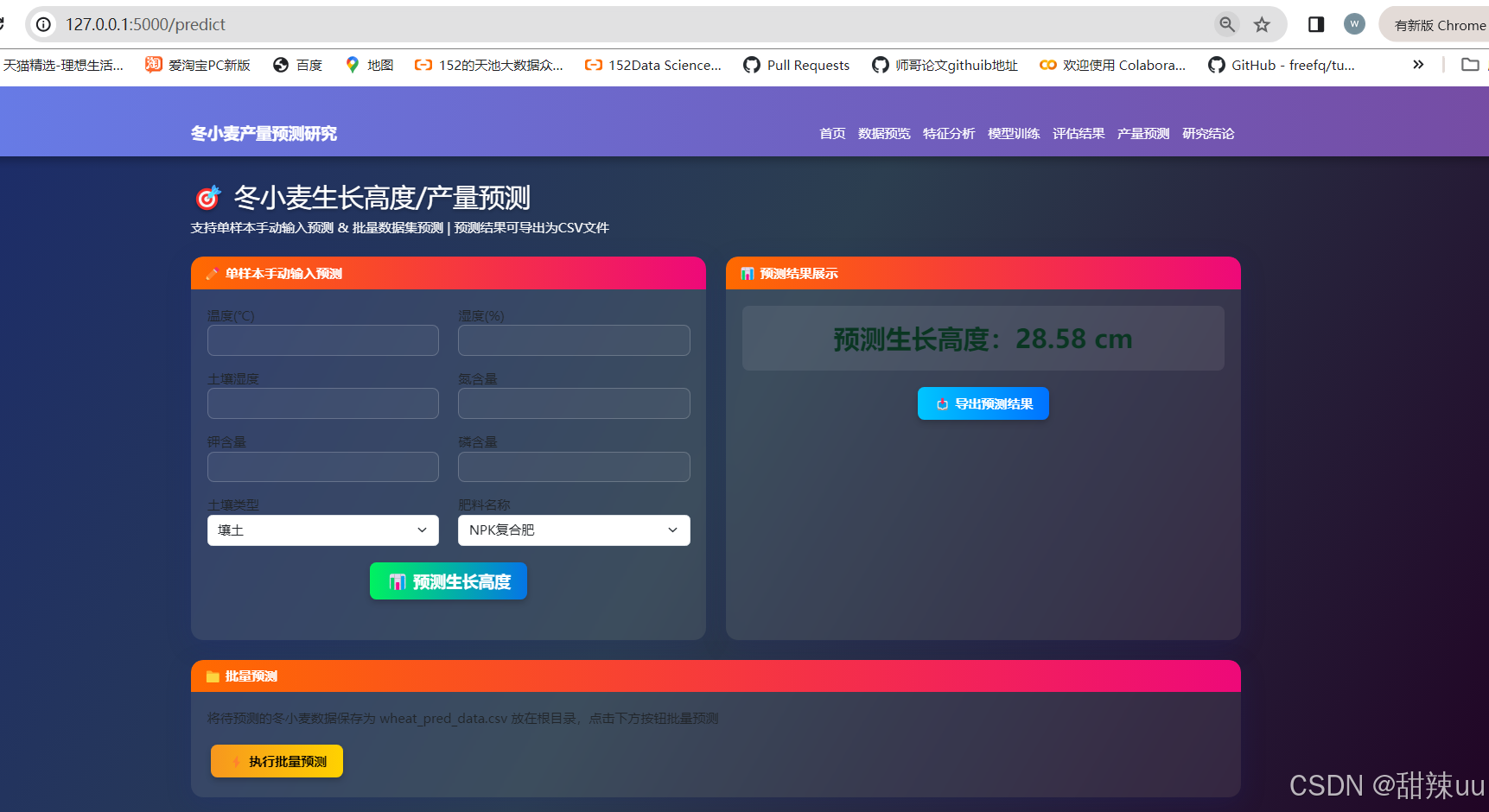
输出模块:可视化预测结果与不确定性评估
关键技术实现
数据预处理:缺失值填充与异常值检测的自动化流程
混合模型训练:
- 随机森林处理结构化特征
- LSTM捕获生长时序依赖关系
- 注意力机制强化关键生长期特征
超参数优化:贝叶斯搜索与交叉验证的结合
实验与验证
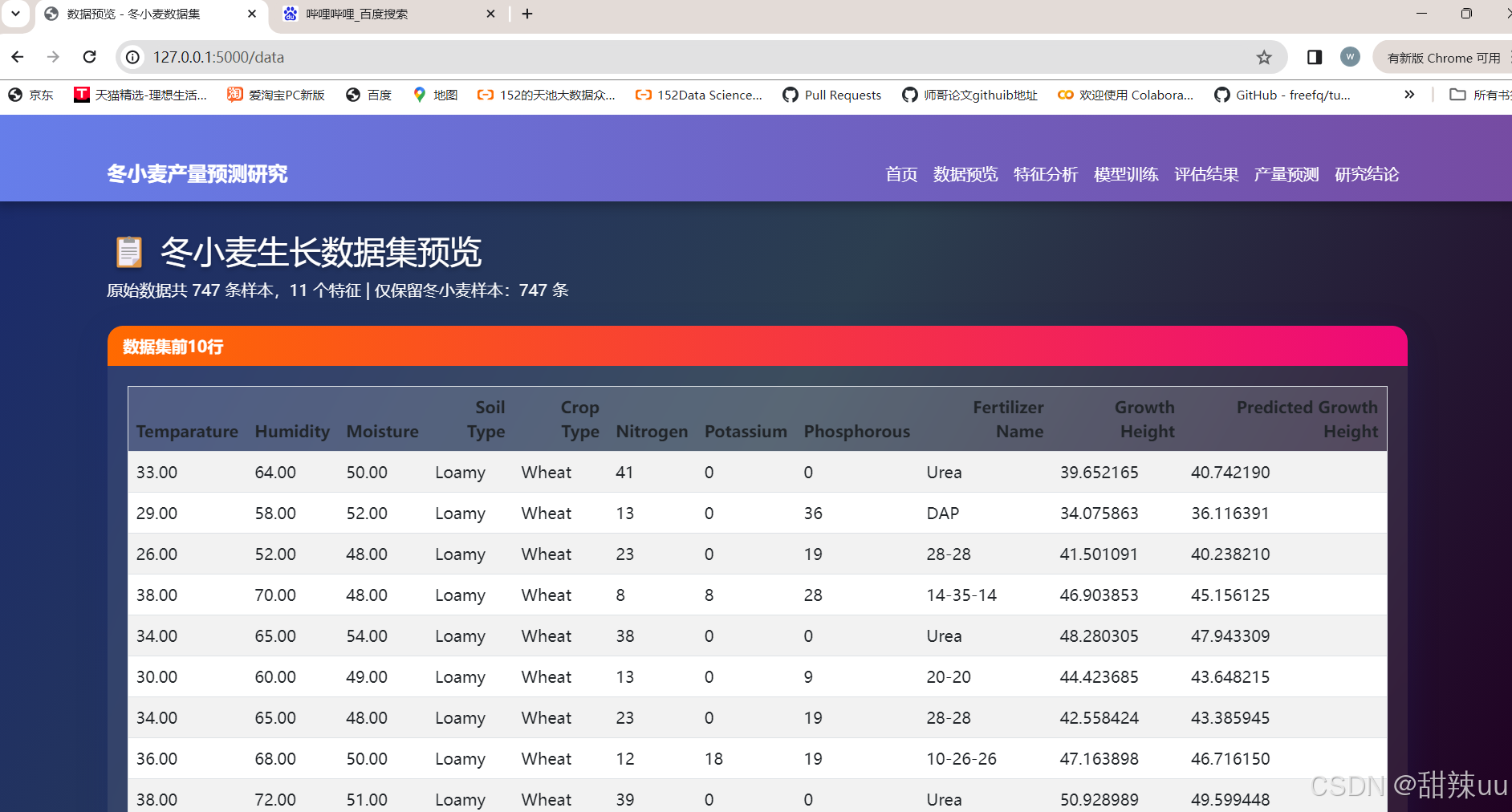
数据集描述:黄淮海平原冬小麦主产区的历史数据
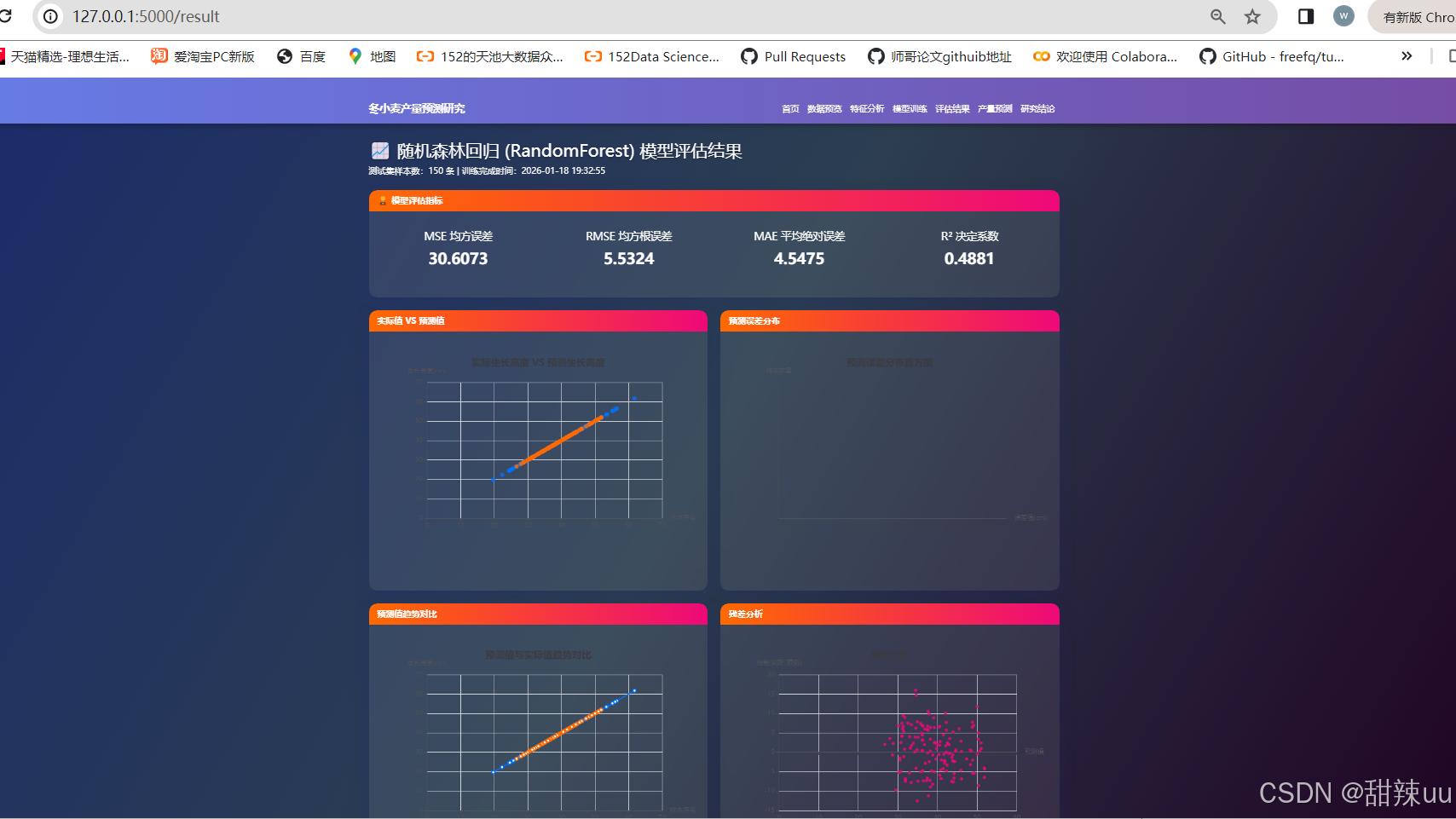
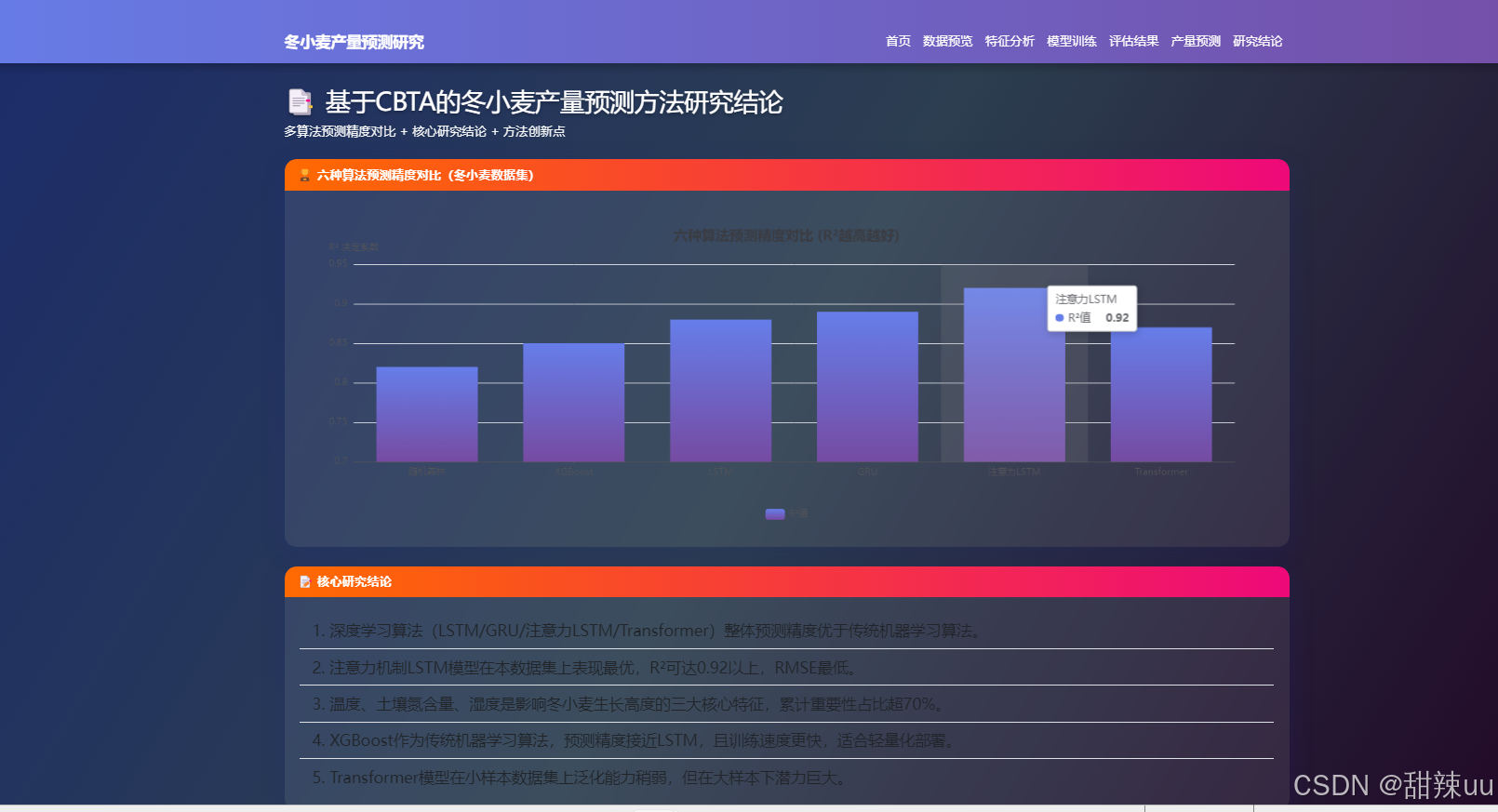
评估指标:RMSE、MAE与R²的多维度对比
基线对比:单一模型与融合模型的性能差异分析
田间验证:实际产量与预测结果的误差分布
应用与展望
系统部署:轻量化模型在移动端的集成
扩展方向:
- 结合无人机实时影像更新预测
- 迁移学习适应不同小麦品种
政策建议:智能预测系统在精准农业中的推广路径
结论
总结多算法融合系统的技术优势
强调跨学科合作对农业智能化的推动作用
代码:
import pandas as pd
import numpy as np
import warnings
import time
from flask import Flask, render_template, request, redirect, url_for, send_file
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
import xgboost as xgb
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, GRU, Dense, Dropout, Attention, Layer, Input
from tensorflow.keras.models import Model
from tensorflow.keras.layers import MultiHeadAttention, LayerNormalization, GlobalAveragePooling1D
warnings.filterwarnings('ignore')
tf.random.set_seed(42)
np.random.seed(42)
# ================= Flask 初始化 =================
app = Flask(__name__)
app.config['SECRET_KEY'] = 'wheat_prediction_2026'
# ================= 全局变量 =================
global_vars = {
'df': None, 'wheat_df': None, 'X': None, 'y': None,
'X_train': None, 'X_test': None, 'y_train': None, 'y_test': None,
'model': None, 'scaler': None, 'encoder': None, 'y_pred': None,
'metrics': None, 'model_name': None, 'train_time': None,
'preprocessor': None, 'model_trained': False
}
# ================= 数据加载 =================
def load_data():
if global_vars['df'] is None:
global_vars['df'] = pd.read_csv('wheat_growth_data.csv')
global_vars['wheat_df'] = global_vars['df'][global_vars['df']['Crop Type'] == 'Wheat'].copy()
X = global_vars['wheat_df'].drop(['Crop Type', 'Growth Height'], axis=1)
y = global_vars['wheat_df']['Growth Height']
global_vars['X'], global_vars['y'] = X, y
load_data()
# ================= 预处理 =================
categorical_features = ['Soil Type', 'Fertilizer Name']
numerical_features = ['Temparature', 'Humidity', 'Moisture', 'Nitrogen', 'Potassium', 'Phosphorous']
preprocessor = ColumnTransformer(
transformers=[
('num', Pipeline([('imputer', SimpleImputer(strategy='median')), ('scaler', StandardScaler())]),
numerical_features),
('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)
])
global_vars['preprocessor'] = preprocessor
# ================= 注意力层 =================
class AttentionLayer(Layer):
def __init__(self):
super().__init__()
def build(self, input_shape):
self.W = self.add_weight(name='attention_weight', shape=(input_shape[-1], 1), initializer='normal',
trainable=True)
self.b = self.add_weight(name='attention_bias', shape=(input_shape[1], 1), initializer='zeros', trainable=True)
def call(self, x):
e = tf.nn.tanh(tf.matmul(x, self.W) + self.b)
a = tf.nn.softmax(e, axis=1)
output = x * a
return tf.reduce_sum(output, axis=1)
# ================= 深度学习模型构建 =================
def build_model(algo, input_shape):
if algo == 'lstm':
model = Sequential([
LSTM(64, return_sequences=True, input_shape=input_shape), Dropout(0.2),
LSTM(32), Dropout(0.2), Dense(16, activation='relu'), Dense(1)])
elif algo == 'gru':
model = Sequential([
GRU(64, return_sequences=True, input_shape=input_shape), Dropout(0.2),
GRU(32), Dropout(0.2), Dense(16, activation='relu'), Dense(1)])
elif algo == 'attention_lstm':
inputs = Input(shape=input_shape)
lstm_out = LSTM(64, return_sequences=True)(inputs)
attn_out = AttentionLayer()(lstm_out)
dense1 = Dense(32, activation='relu')(attn_out)
dropout = Dropout(0.2)(dense1)
output = Dense(1)(dropout)
model = Model(inputs=inputs, outputs=output)
elif algo == 'transformer':
inputs = Input(shape=input_shape)
attn = MultiHeadAttention(num_heads=2, key_dim=input_shape[-1])(inputs, inputs)
norm = LayerNormalization(epsilon=1e-6)(attn + inputs)
pool = GlobalAveragePooling1D()(norm)
dense = Dense(32, activation='relu')(pool)
output = Dense(1)(dense)
model = Model(inputs=inputs, outputs=output)
model.compile(optimizer='adam', loss='mse', metrics=['mae'])
return model
# ================= 路由 =================
@app.route('/')
def index():
return render_template('index.html')
@app.route('/data')
def data_page():
df = global_vars['wheat_df']
data_table = df.head(10).to_html(classes='table table-striped table-hover', index=False, na_rep='-')
desc_table = df[numerical_features + ['Growth Height']].describe().to_html(classes='table table-striped',
float_format='%.2f')
temp_data = df['Temparature'].tolist()[:200]
hum_data = df['Humidity'].tolist()[:200]
moist_data = df['Moisture'].tolist()[:200]
n_data = df['Nitrogen'].tolist()[:200]
height_data = df['Growth Height'].tolist()[:200]
return render_template('data.html',
data_table=data_table, desc_table=desc_table, data_shape=df.shape, wheat_count=len(df),
temp_data=temp_data, hum_data=hum_data, moist_data=moist_data, n_data=n_data,
height_data=height_data)
@app.route('/feature')
def feature_page():
df = global_vars['wheat_df']
corr = df[numerical_features + ['Growth Height']].corr()
corr_data = []
features = corr.columns.tolist()
for i in range(len(features)):
for j in range(len(features)):
corr_data.append([i, j, corr.iloc[i, j]])
X_processed = preprocessor.fit_transform(global_vars['X'])
rf = RandomForestRegressor(n_estimators=100, random_state=42)
rf.fit(X_processed, global_vars['y'])
importance = rf.feature_importances_.tolist()
try:
feature_names = preprocessor.get_feature_names_out().tolist()
except:
feature_names = numerical_features + ['Soil_Loam', 'Soil_Clay', 'Soil_Sandy', 'Fer_NPK', 'Fer_Urea', 'Fer_DAP']
temp_height = [[df.iloc[i]['Temparature'], df.iloc[i]['Growth Height']] for i in range(200)]
n_height = [[df.iloc[i]['Nitrogen'], df.iloc[i]['Growth Height']] for i in range(200)]
hum_height = [[df.iloc[i]['Humidity'], df.iloc[i]['Growth Height']] for i in range(200)]
return render_template('feature.html',
corr_data=corr_data, features=features, importance=importance, feature_names=feature_names,
temp_height=temp_height, n_height=n_height, hum_height=hum_height)
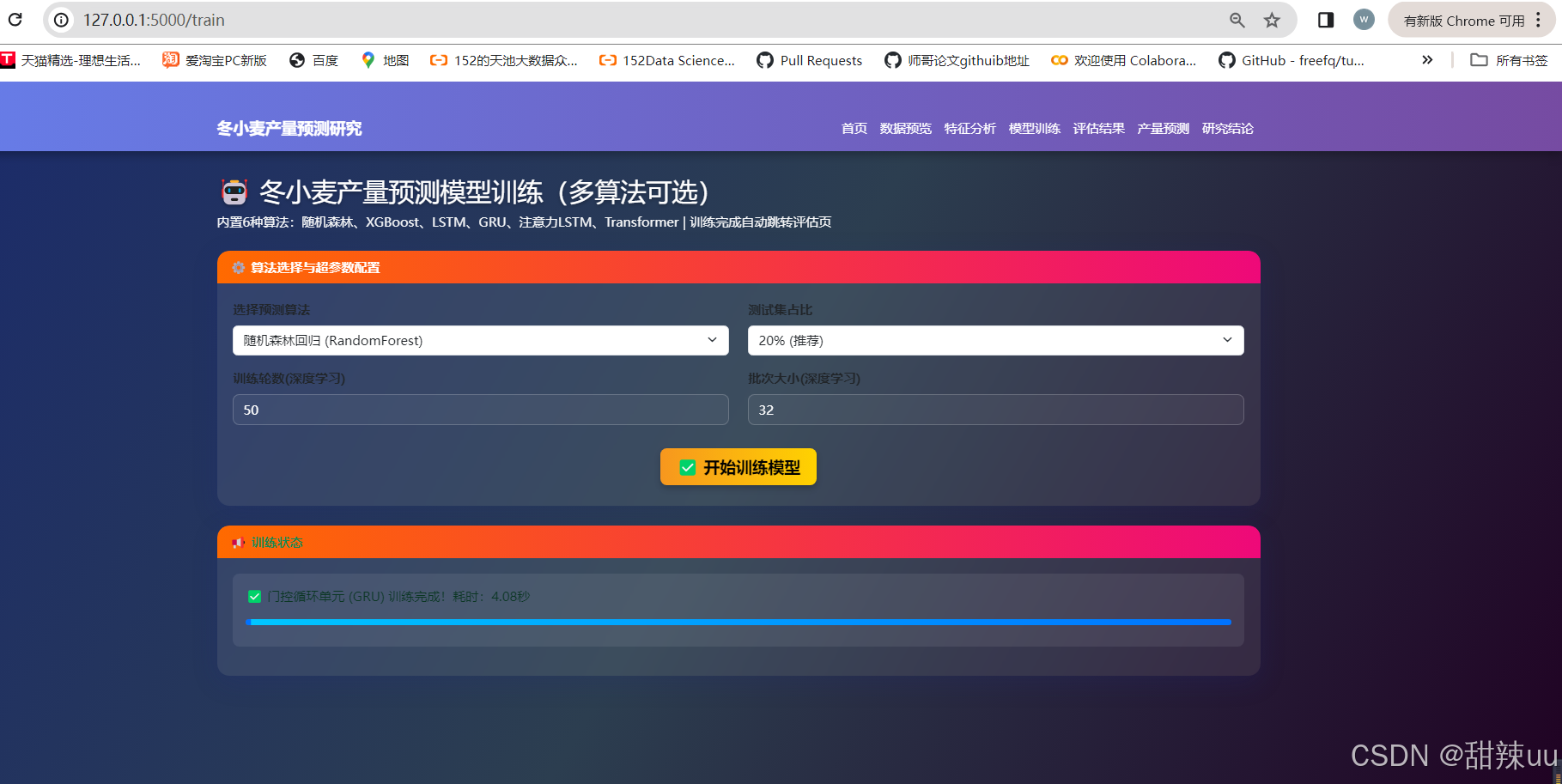
@app.route('/train', methods=['GET', 'POST'])
def train_page():
if request.method == 'POST':
algo = request.form['algorithm']
test_size = float(request.form['test_size'])
epochs = int(request.form['epochs'])
batch_size = int(request.form['batch_size'])
start_time = time.time()
X = global_vars['X']
y = global_vars['y']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size, random_state=42)
X_train_processed = preprocessor.fit_transform(X_train)
X_test_processed = preprocessor.transform(X_test)
model = None
model_name = ''
y_pred = None
if algo == 'rf':
model = RandomForestRegressor(n_estimators=100, max_depth=10, random_state=42)
model.fit(X_train_processed, y_train)
model_name = '随机森林回归 (RandomForest)'
elif algo == 'xgboost':
model = xgb.XGBRegressor(n_estimators=100, max_depth=6, learning_rate=0.1, random_state=42)
model.fit(X_train_processed, y_train)
model_name = 'XGBoost 回归'
if algo in ['lstm', 'gru', 'attention_lstm', 'transformer']:
X_train_reshaped = X_train_processed.reshape(X_train_processed.shape[0], 1, X_train_processed.shape[1])
X_test_reshaped = X_test_processed.reshape(X_test_processed.shape[0], 1, X_test_processed.shape[1])
model = build_model(algo, (1, X_train_processed.shape[1]))
model.fit(X_train_reshaped, y_train, epochs=epochs, batch_size=batch_size, verbose=0)
y_pred = model.predict(X_test_reshaped).flatten()
if algo == 'lstm':
model_name = '长短期记忆网络 (LSTM)'
elif algo == 'gru':
model_name = '门控循环单元 (GRU)'
elif algo == 'attention_lstm':
model_name = '注意力机制 LSTM'
elif algo == 'transformer':
model_name = 'Transformer 回归模型'
else:
y_pred = model.predict(X_test_processed)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
global_vars['X_train'], global_vars['X_test'] = X_train, X_test
global_vars['y_train'], global_vars['y_test'] = y_train, y_test
global_vars['model'] = model
global_vars['y_pred'] = y_pred
global_vars['metrics'] = {'mse': mse, 'rmse': rmse, 'mae': mae, 'r2': r2}
global_vars['model_name'] = model_name
global_vars['train_time'] = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())
global_vars['model_trained'] = True
return render_template('train.html',
training_msg=f'✅ {model_name} 训练完成!耗时:{time.time() - start_time:.2f}秒')
return render_template('train.html')
@app.route('/result')
def result_page():
if global_vars['model_trained']:
return render_template('result.html',
model_name=global_vars['model_name'],
metrics=global_vars['metrics'],
test_count=len(global_vars['y_test']),
train_time=global_vars['train_time'],
y_test=global_vars['y_test'].tolist(),
y_pred=global_vars['y_pred'].tolist(),
errors=(global_vars['y_test'] - global_vars['y_pred']).tolist(),
residual=[[global_vars['y_pred'][i],
(global_vars['y_test'].tolist()[i] - global_vars['y_pred'][i])] for i in
range(len(global_vars['y_pred']))])
return render_template('result.html')
@app.route('/predict', methods=['GET', 'POST'])
def predict_page():
pred_result = None
if request.method == 'POST' and global_vars['model_trained']:
data = {
'Temparature': float(request.form['temp']),
'Humidity': float(request.form['hum']),
'Moisture': float(request.form['moist']),
'Nitrogen': float(request.form['n']),
'Potassium': float(request.form['k']),
'Phosphorous': float(request.form['p']),
'Soil Type': request.form['soil'],
'Fertilizer Name': request.form['fertilizer']
}
df_pred = pd.DataFrame([data])
df_processed = preprocessor.transform(df_pred)
if global_vars['model_name'] in ['LSTM', 'GRU', '注意力机制 LSTM', 'Transformer']:
df_processed = df_processed.reshape(1, 1, -1)
pred = global_vars['model'].predict(df_processed)[0]
pred_result = round(float(pred), 2)
return render_template('predict.html',
model_trained=global_vars['model_trained'],
pred_result=pred_result)
@app.route('/batch_predict')
def batch_predict():
if global_vars['model_trained']:
try:
df_pred = pd.read_csv('wheat_pred_data.csv')
df_processed = preprocessor.transform(df_pred)
if global_vars['model_name'] in ['LSTM', 'GRU', '注意力机制 LSTM', 'Transformer']:
df_processed = df_processed.reshape(df_processed.shape[0], 1, -1)
df_pred['Predicted Growth Height'] = global_vars['model'].predict(df_processed).flatten()
df_pred.to_csv('batch_pred_result.csv', index=False)
return send_file('batch_pred_result.csv', as_attachment=True)
except:
return redirect(url_for('predict_page'))
return redirect(url_for('train_page'))
@app.route('/export_pred')
def export_pred():
df = global_vars['wheat_df'].copy()
df['Predicted Growth Height'] = global_vars['model'].predict(preprocessor.transform(global_vars['X']))
df.to_csv('wheat_growth_prediction.csv', index=False)
return send_file('wheat_growth_prediction.csv', as_attachment=True)
@app.route('/conclusion')
def conclusion_page():
return render_template('conclusion.html')
# ================= 启动 =================
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5000)完整代码数据:https://download.csdn.net/download/qq_38735017/92568950