一数据标注回顾
1.1整体思路
- 现在我们有txt和txtroiginal.
txt里面是标注数据,txtoriginal里面是原始数据,数据如下:
txt: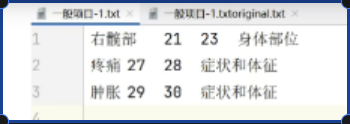
txtoriginal:

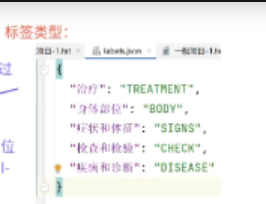
- 根据标注数据和标签类型构建字典
这是标签类型:
- 遍历原始数据,通过索引和标签的字典,给想引得位置打上标签.通过索引查字典,如果能查到则将对应的value作为标签,否则打上o的标签.
二代码实现
2.1使用路径拼接读取数据
python
import os
import json
cur = os.getcwd()
print(cur)
os.chdir('..')
cur = os.getcwd()
print(f'修改以后的目录{cur}')
path=os.path.join(cur,'data/labels.json')
print(f'拼接后的路径{path}')
labels=json.load(open(path,'r',encoding='utf-8'))
print(f'labels->{labels}')
2.1.1补充os.getcwd()方法:这个方法的缺陷是其他包在导入使用这个方法的包后,获取到的是其他包的路径,会导致读取数据出现错误
报错的原因是路径输出的是当前文件夹的路径,因为输出的不是导入的包的路径,所以找不到相关文件.
2.2.2使用os.path.abspath()的方法可以避免这个问题
python
import os
import json
# 如何设计,让这个代码在调用时,相对路径不随着调用位置变化而变化
file_path = os.path.abspath(__file__)
print(f'file_path-->{file_path}')
base_dir = os.path.dirname(file_path)
print(f'base_dir-->{base_dir}')
# 路径拼接
path = os.path.join(base_dir, '../data/labels.json')
print(f'拼接之后的路径2-->{path}')
# 读取json文件
labels = json.load(open(path, 'r', encoding='utf-8'))
print(f'labels-->{labels}')拼接好路径以后,使用os.walk()读取路径下的文件
这个方法返回的是可迭代对象,用循环的方法遍历,分别返回的是:文件夹路径,文件夹列表,文件列表
python
results = os.walk(os.path.join(base_dir, '../data_origin'))
print(f'results-->{results}')
for dir_path, dirs, files in results: # 路径、文件夹(列表)、文件(列表)
print('*'*50)
print(f'dir_path-->{dir_path}')
print(f'dirs-->{dirs}')
print(f'files-->{files}')2.2数据处理
先获取实体的英文名,然后用B-英文名或者I-英文名拼接,,得到每实体里面每个字的标签.
遍历原始文本,通过标签数据的索引给原始文本里面的字打标签,如果没有这个字的标签,就打O
2.2.1拼接的方法
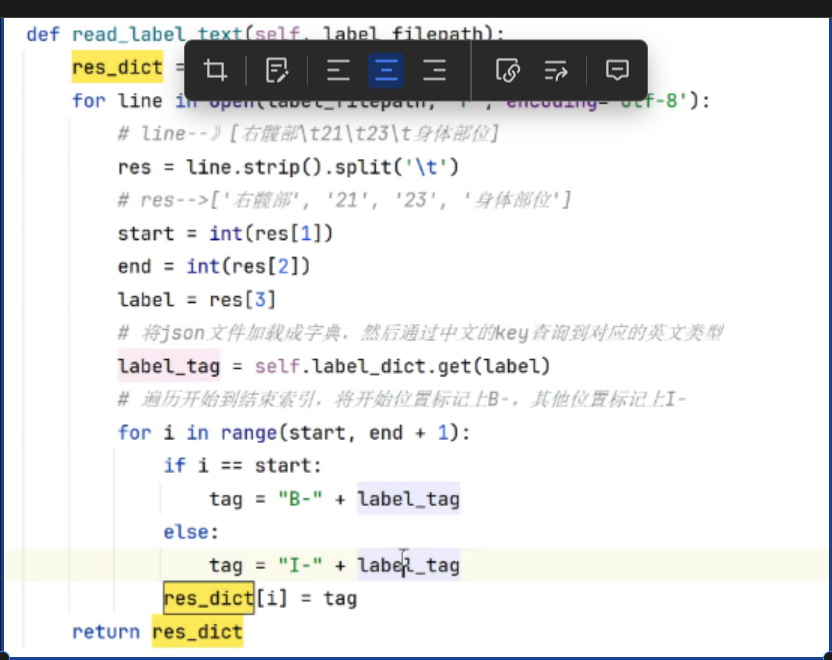
拼接结果:

2.2.2遍历原始文本,给实体打标签
找到索引提取value,找不到索引打O

2.2.3最终结果

