博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈
以Python作为核心开发语言,基于Django框架搭建系统整体架构,采用Neo4j图形数据库与MySQL数据库存储数据,整合Echarts可视化工具、协同过滤推荐算法,结合HTML技术完成前端页面的搭建。
功能模块
- 电影知识图谱管理
- 电影问答交互
- 电影列表展示
- 个人信息查看
- 电影详情展示
- 用户注册登录
- 后台电影数据管理
项目介绍
本系统是一款聚焦电影领域的知识图谱推荐问答系统,主要解决传统模式下电影信息获取效率低、推荐精准度不足的问题。前端采用HTML5、DIV+CSS布局方式,支持多终端访问;后端以Python+Django框架为核心,依托MySQL保障数据存储的安全性与稳定性,核心融合Neo4j知识图谱与协同过滤推荐算法,实现电影智能推荐与智能问答功能。系统涵盖用户注册登录、电影列表及详情展示、个人信息查看、问答交互、知识图谱管理、后台数据管控等功能,可精准推荐电影、高效解答用户问题,显著提升用户使用体验。
2、项目界面
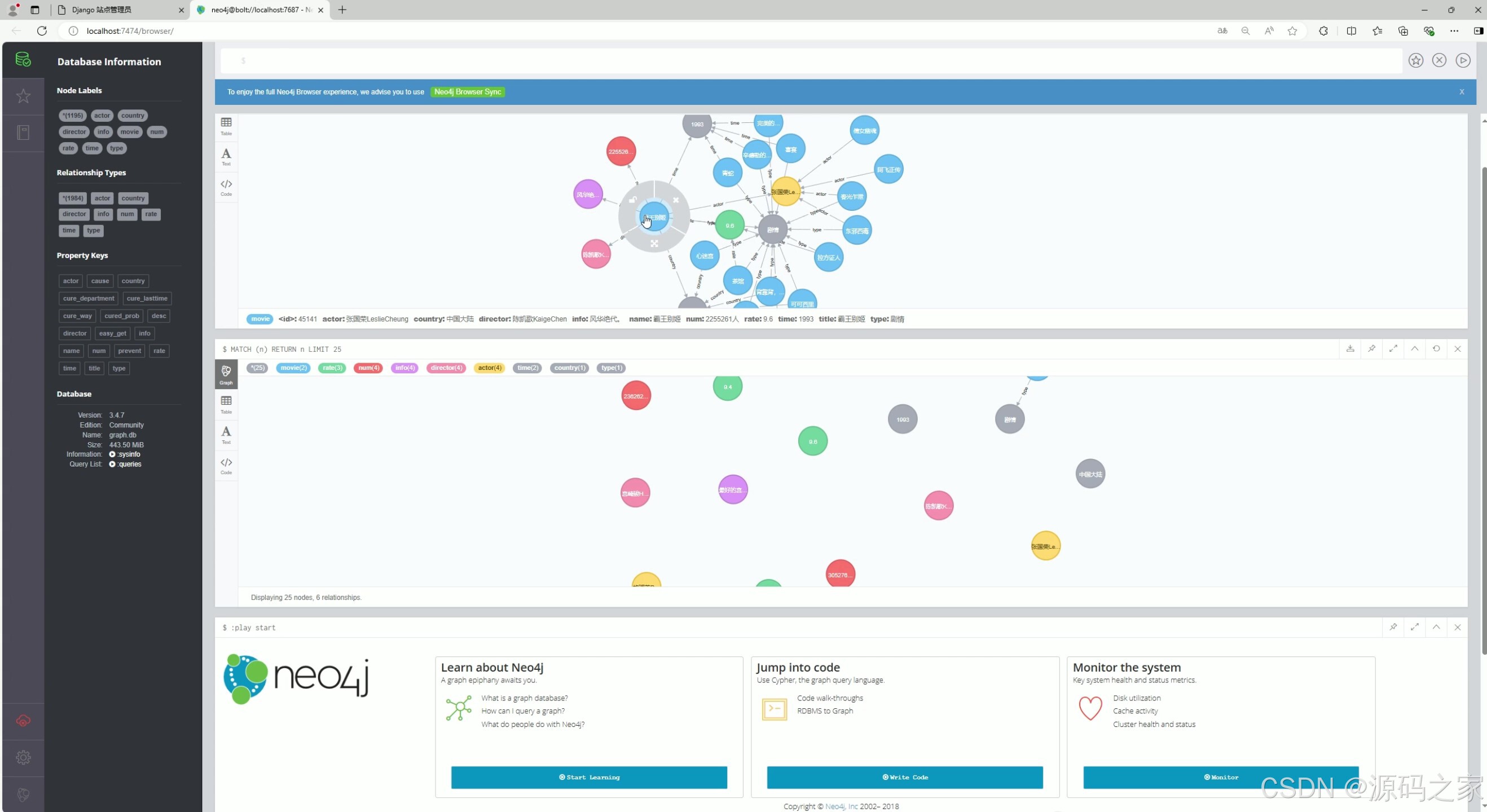
(1)电影知识图谱
展示电影相关节点与关系的可视化图谱,支持通过 Cypher 语句查询数据并呈现对应节点信息,同时提供数据库信息查看、节点标签与关系类型管理等功能,还包含学习与代码操作的引导入口,辅助用户管理和分析电影知识图谱数据。
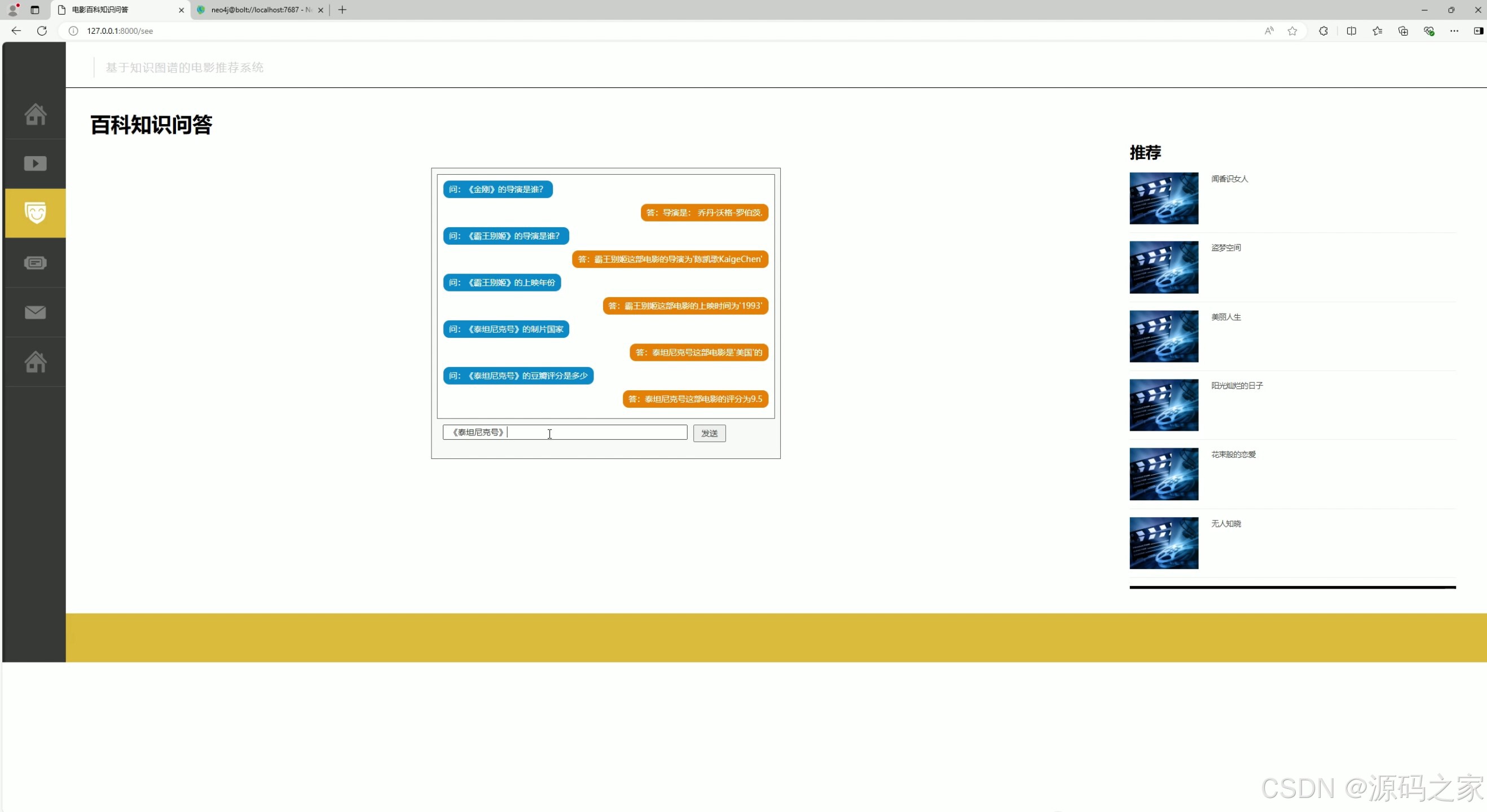
(2)电影问答系统
支持用户在输入框提交关于电影的问题并搜索,展示电影相关问题及对应回答内容,同时页面右侧设有电影推荐列表,辅助用户获取电影信息的同时提供观影推荐。
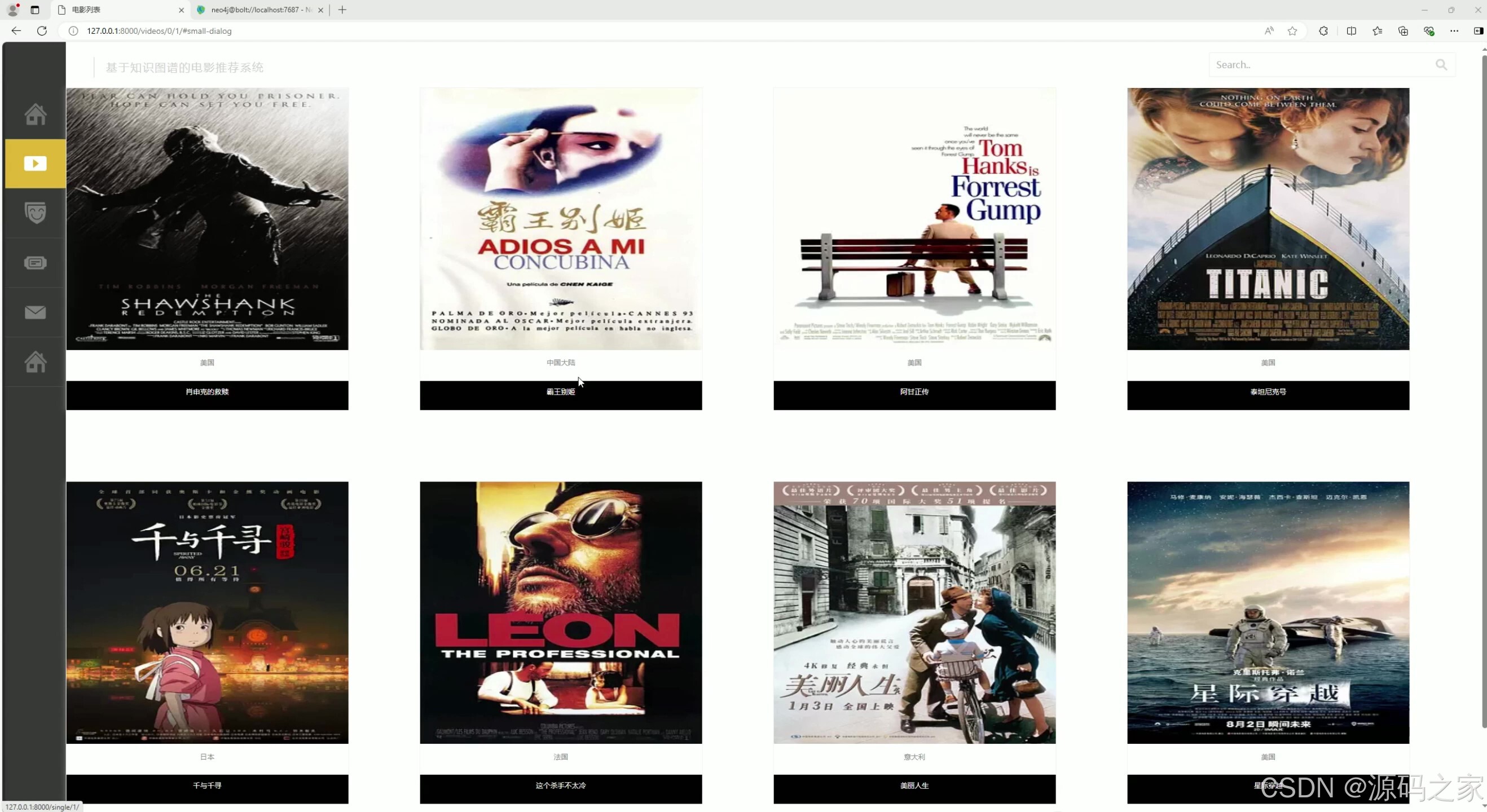
(3)电影列表
以海报形式展示多部电影,同时呈现电影名称与对应国家信息,支持用户浏览不同电影内容,结合系统的知识图谱能力,可辅助后续的推荐与信息查询,为用户提供直观的电影选择入口。
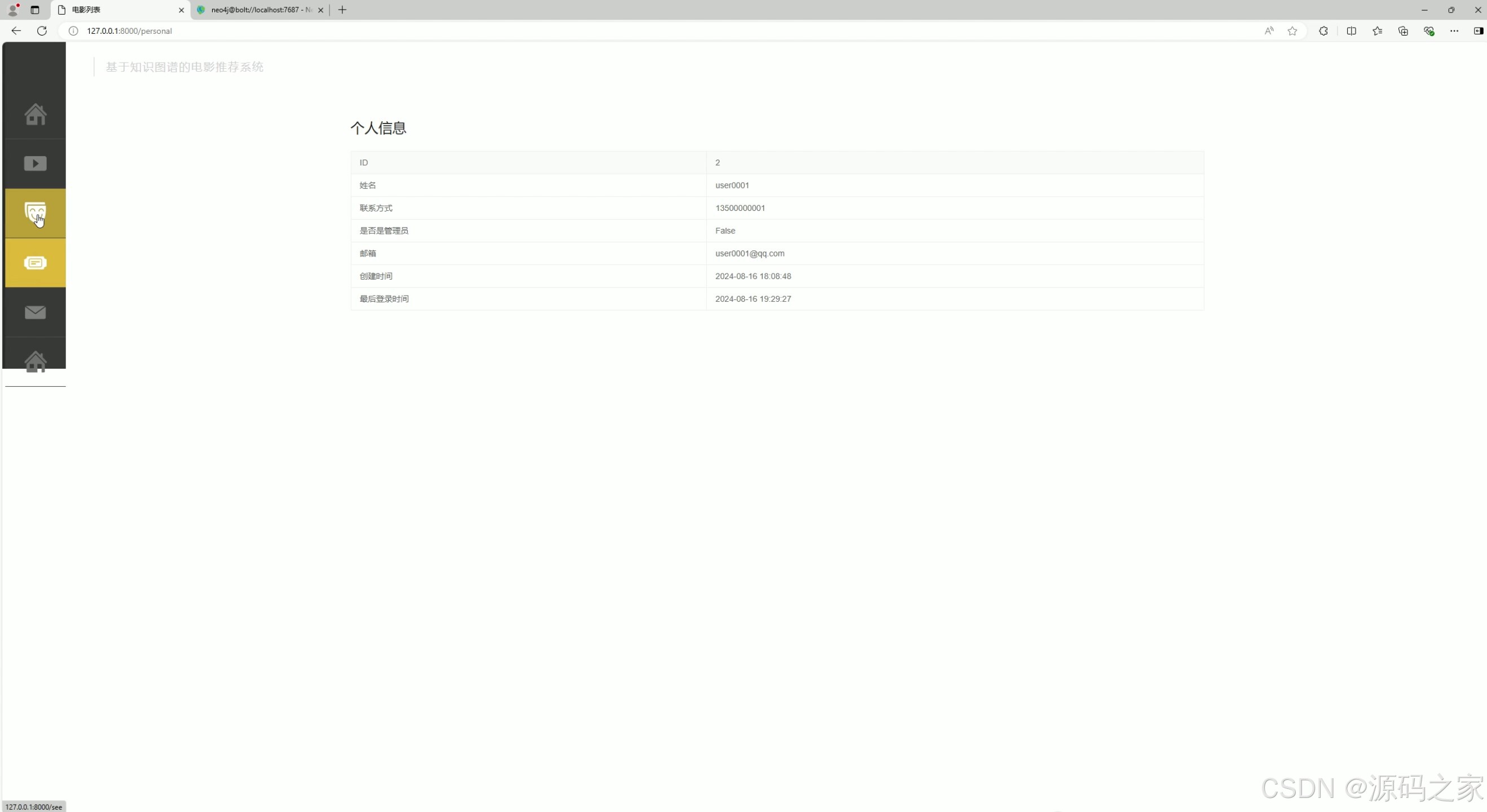
(4)个人信息
展示用户的 ID、账号、联系方式、是否管理员等个人信息内容,帮助用户查看自身在系统中的注册及身份相关数据,是系统中用户管理自身信息的展示入口。
(5)电影详情页
展示电影的名称、上映日期、演员、导演等基础信息,还有评分、用户想看数及故事简介,同时呈现评论数量,帮助用户全面了解该电影的相关内容,是系统中展示单部电影信息的核心页面。
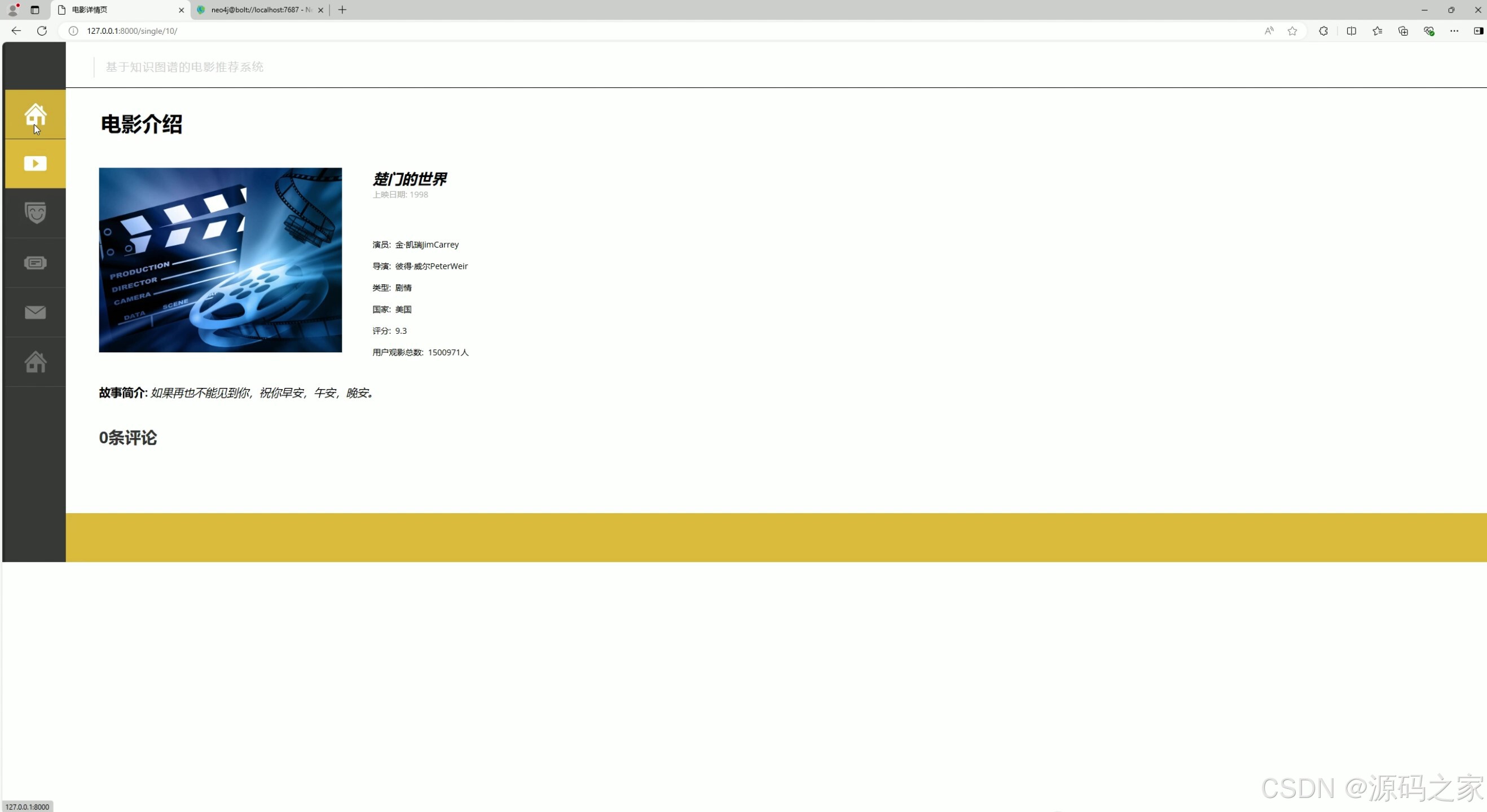
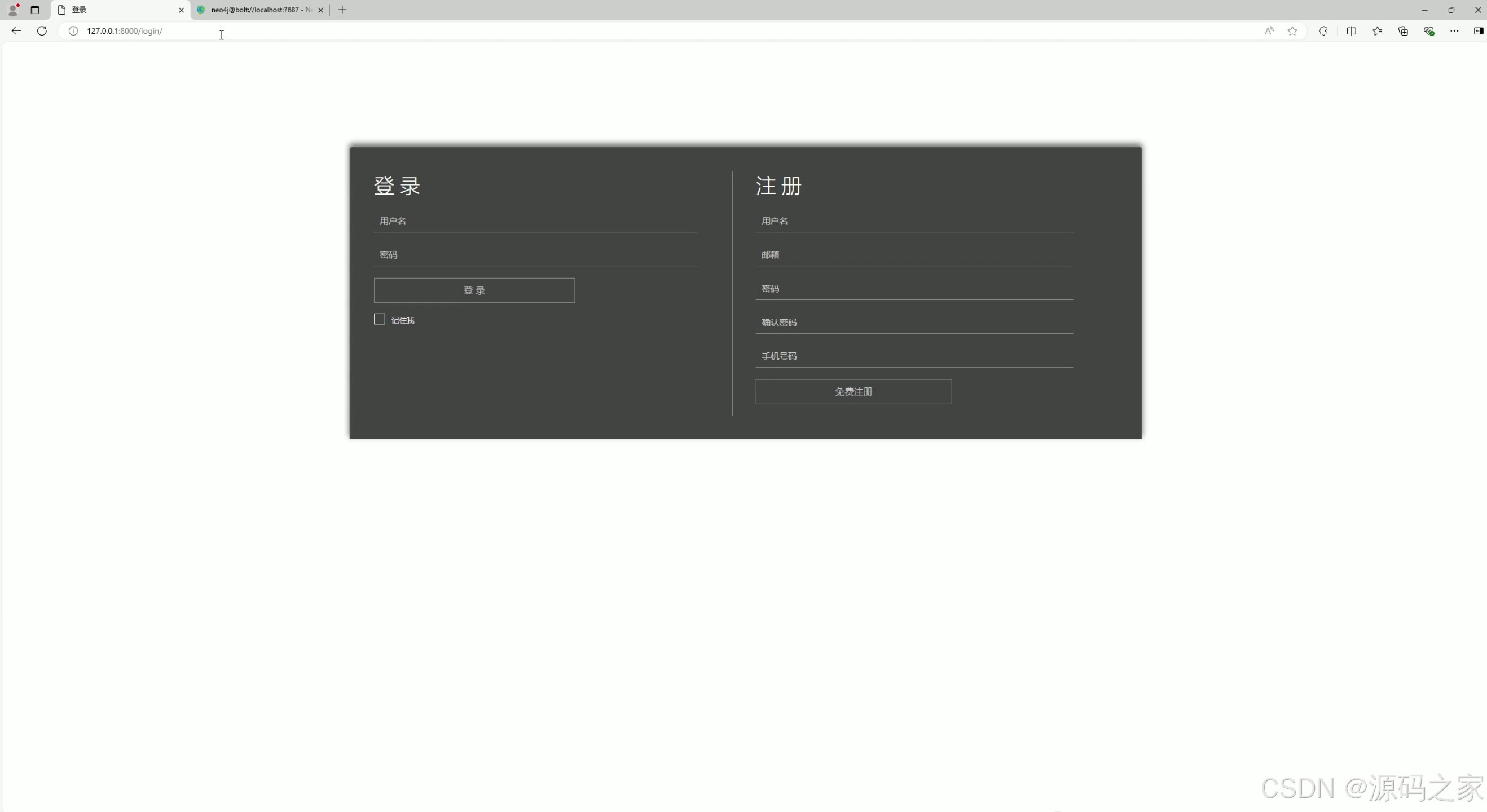
(6)注册登录
分为登录与注册两个板块,登录板块提供用户名、密码输入框及登录按钮,支持记住在线选项;注册板块包含用户名、邮箱、密码等输入项及注册按钮,是用户进入系统的身份验证与账号创建入口。
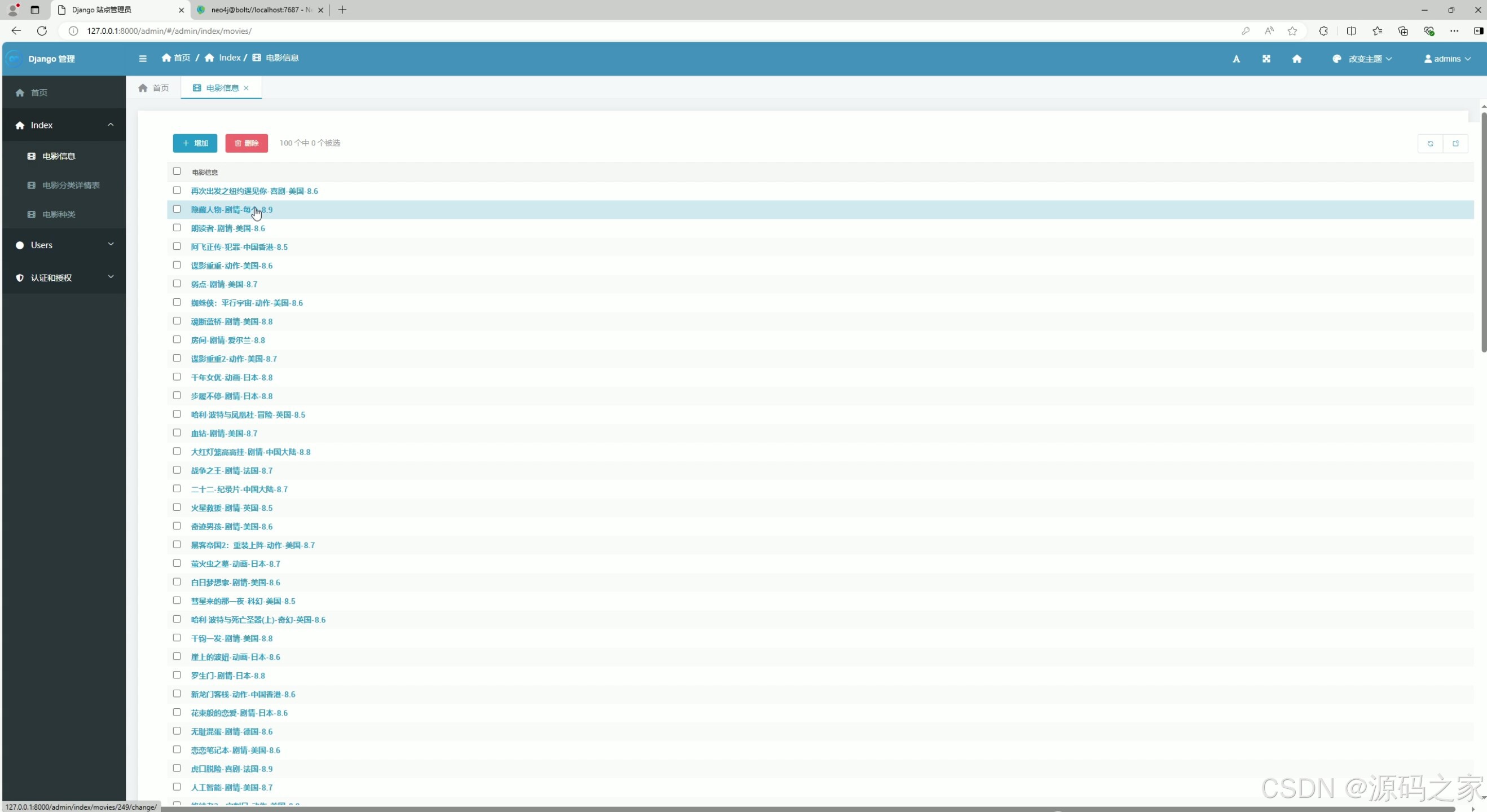
(7)后台管理
展示电影信息列表,包含电影名称、类型、评分等内容,支持对电影信息进行添加、删除操作,同时左侧设有功能导航栏,可切换至不同管理模块,辅助管理员管控系统内的电影数据。
3、项目说明
一、技术栈
本项目以Python为核心开发语言,基于Django框架搭建系统整体架构,采用Neo4j图形数据库与MySQL数据库存储数据,整合Echarts可视化工具、协同过滤推荐算法,结合HTML技术完成前端页面搭建。
二、功能模块详细介绍
- 电影知识图谱管理:展示电影相关节点与关系的可视化图谱,支持通过Cypher语句查询数据并呈现对应节点信息,提供数据库信息查看、节点标签与关系类型管理等功能,还包含学习与代码操作引导入口,辅助管理和分析电影知识图谱数据。
- 电影问答交互:支持用户在输入框提交电影相关问题并搜索,展示对应问题及回答内容,页面右侧设有电影推荐列表,帮助用户获取信息的同时提供观影推荐。
- 电影列表展示:以海报形式展示多部电影,呈现电影名称与所属国家信息,支持用户浏览不同影片内容,结合知识图谱能力辅助后续推荐与信息查询,提供直观的电影选择入口。
- 个人信息查看:展示用户ID、账号、联系方式、是否为管理员等信息,帮助用户查看自身在系统中的注册及身份相关数据,是用户管理个人信息的展示入口。
- 电影详情展示:展示电影名称、上映日期、演员、导演等基础信息,还有评分、用户想看数、故事简介及评论数量,帮助用户全面了解单部电影的相关内容。
- 用户注册登录:分为登录与注册板块,登录板块提供用户名、密码输入框及登录按钮,支持记住在线选项;注册板块包含用户名、邮箱、密码等输入项及注册按钮,是用户进入系统的身份验证与账号创建入口。
- 后台电影数据管理:展示电影信息列表,包含名称、类型、评分等内容,支持对电影信息进行添加、删除操作,左侧设有功能导航栏可切换不同管理模块,辅助管理员管控系统内的电影数据。
三、项目总结
本系统是面向电影领域的知识图谱推荐问答系统,旨在解决传统模式下电影信息获取效率低、推荐精准度欠佳的问题。前端采用HTML5、DIV+CSS布局适配多终端访问,后端依托Python+Django框架,结合MySQL保障数据存储安全稳定,核心融合Neo4j知识图谱与协同过滤推荐算法实现智能推荐与问答。系统覆盖注册登录、电影列表及详情展示、个人信息查看、问答交互、知识图谱管理、后台数据管控等功能,可精准推荐电影、高效解答用户问题,大幅提升用户使用体验。
4、核心代码
python
# -*- coding = utf-8 -*-
"""
User-based Collaborative filtering.
"""
import collections
from operator import itemgetter
import math
from collections import defaultdict
from . import similarity
from . import utils
from .utils import LogTime
class UserBasedCF:
"""
User-based Collaborative filtering.
Top-N recommendation.
"""
def __init__(self, k_sim_user=20, n_rec_movie=10, use_iif_similarity=False, save_model=True):
"""
Init UserBasedCF with n_sim_user and n_rec_movie.
@return: None
"""
print("UserBasedCF start...\n")
self.k_sim_user = k_sim_user
self.n_rec_movie = n_rec_movie
self.trainset = None
self.save_model = save_model
self.use_iif_similarity = use_iif_similarity
def fit(self, trainset):
"""
Fit the trainset by calculate user similarity matrix.
@param trainset: train dataset
@return: None
"""
model_manager = utils.ModelManager()
try:
self.user_sim_mat = model_manager.load_model(
'user_sim_mat-iif' if self.use_iif_similarity else 'user_sim_mat')
self.movie_popular = model_manager.load_model('movie_popular')
self.movie_count = model_manager.load_model('movie_count')
self.trainset = model_manager.load_model('trainset')
print('User origin similarity model has saved before.\nLoad model success...\n')
except OSError:
print('No model saved before.\nTrain a new model...')
self.user_sim_mat, self.movie_popular, self.movie_count = \
similarity.calculate_user_similarity(trainset=trainset,
use_iif_similarity=self.use_iif_similarity)
self.trainset = trainset
print('Train a new model success.')
if self.save_model:
model_manager.save_model(self.user_sim_mat,
'user_sim_mat-iif' if self.use_iif_similarity else 'user_sim_mat')
model_manager.save_model(self.movie_popular, 'movie_popular')
model_manager.save_model(self.movie_count, 'movie_count')
print('The new model has saved success.\n')
def recommend(self, user):
"""
Find K similar users and recommend N movies for the user.
@param user: The user we recommend movies to.
@return: the N best score movies
"""
if not self.user_sim_mat or not self.n_rec_movie or \
not self.trainset or not self.movie_popular or not self.movie_count:
raise NotImplementedError('UserCF has not init or fit method has not called yet.')
K = self.k_sim_user
N = self.n_rec_movie
predict_score = collections.defaultdict(int)
if user not in self.trainset:
print('The user (%s) not in trainset.' % user)
return
# print('Recommend movies to user start...')
watched_movies = self.trainset[user]
for similar_user, similarity_factor in sorted(self.user_sim_mat[user].items(),
key=itemgetter(1), reverse=True)[0:K]:
for movie, rating in self.trainset[similar_user].items():
if movie in watched_movies:
continue
# predict the user's "interest" for each movie
# the predict_score is sum(similarity_factor * rating) 预测分数为加权(相似度*评分)求和
predict_score[movie] += similarity_factor * rating
# log steps and times.
# print('Recommend movies to user success.')
# return the N best score movies
return [movie for movie, _ in sorted(predict_score.items(), key=itemgetter(1), reverse=True)[0:N]]
def test(self, testset):
"""
Test the recommendation system by recommending scores to all users in testset.
@param testset: test dataset
@return:
"""
if not self.n_rec_movie or not self.trainset or not self.movie_popular or not self.movie_count:
raise ValueError('UserCF has not init or fit method has not called yet.')
self.testset = testset
print('Test recommendation system start...')
N = self.n_rec_movie
# varables for precision and recall
hit = 0
rec_count = 0
test_count = 0
# varables for coverage
all_rec_movies = set()
# varables for popularity
popular_sum = 0
# record to calculate time has spent.
test_time = LogTime(print_step=1000)
for i, user in enumerate(self.trainset):
test_movies = self.testset.get(user, {})
rec_movies = self.recommend(user) # type:list
for movie in rec_movies:
if movie in test_movies:
hit += 1
all_rec_movies.add(movie)
popular_sum += math.log(1 + self.movie_popular[movie])
# log steps and times.
rec_count += N
test_count += len(test_movies)
# print time per 500 times.
test_time.count_time()
precision = hit / (1.0 * rec_count)
recall = hit / (1.0 * test_count)
coverage = len(all_rec_movies) / (1.0 * self.movie_count)
popularity = popular_sum / (1.0 * rec_count)
print('Test recommendation system success.')
test_time.finish()
print('precision=%.4f\trecall=%.4f\tcoverage=%.4f\tpopularity=%.4f\n' %
(precision, recall, coverage, popularity))
def predict(self, testset):
"""
Recommend movies to all users in testset.
:param testset: test dataset
:return: `dict` : recommend list for each user.
"""
movies_recommend = defaultdict(list)
print('Predict scores start...')
# record the calculate time has spent.
predict_time = LogTime(print_step=500)
for i, user in enumerate(testset):
rec_movies = self.recommend(user) # type:list
movies_recommend[user].append(rec_movies)
# log steps and times.
predict_time.count_time()
print('Predict scores success.')
predict_time.finish()
return movies_recommend5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看 👇🏻获取联系方式👇🏻